Quels sont les points techniques pour mettre en œuvre une plateforme d’observabilité ?
- Compatible avec les sémaphores globaux
- Que sont les sémaphores dits globaux ?
- Outils de collecte et de téléchargement unifiés
- Back-end de stockage unifié
- Liberté d’explorer et de synthétiser les données
- Résumer
- Lecture recommandée "Ingénierie de l'observabilité"
- Aperçu de la diffusion en direct
- Réservez une diffusion en direct
- Méthode de loterie
Le concept d'observabilité étant profondément enraciné dans le cœur des gens, la plate-forme d'observabilité a commencé à entrer dans la phase de mise en œuvre et son avancement ne fait aucun doute ; et il y a une autre étape : comment peut-elle s'enraciner dans l'entreprise en tant qu'entreprise unifiée ? et plateforme intégrée ?
L’observabilité n’est pas seulement un mot à la mode, ni un mot clé à la mode. Vous pourriez aussi bien examiner l’évolution de la gestion de l’exploitation et de la maintenance telle que nous la connaissons, et mettre de côté les formalités administratives liées aux processus et aux personnes impliquées dans la gestion de l’exploitation et de la maintenance. Concentrons-nous uniquement sur : les évolutions de l’infrastructure et de l’architecture applicative, et sur les aspects de ces innombrables outils techniques.
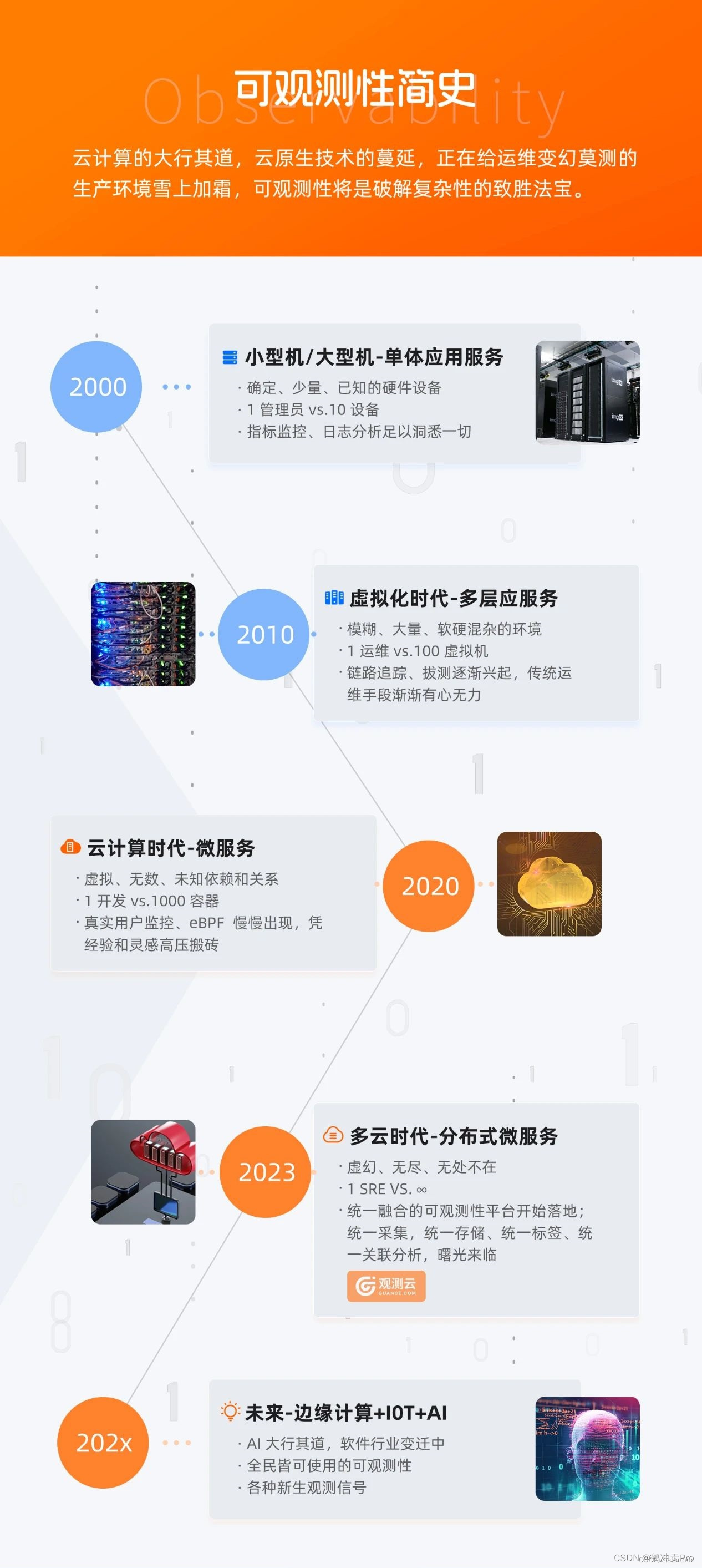
Compatible avec les sémaphores globaux
Du point de vue des méthodes de télémétrie : tout type de signal a son propre objectif et sa propre raison. C'est une idée relativement extrême de sélectionner arbitrairement l'un d'entre eux comme synonyme d'observabilité. Sur la voie du débogage de l'environnement de production, il nous est difficile de s'appuyer sur un seul signal. Nous devons choisir une combinaison SLI raisonnable en fonction des caractéristiques et des types de services des différents systèmes d'application, et utiliser des sémaphores appropriés pour couvrir le système d'application cible. L'objectif est de créer les « attributs d'observabilité » du système d'application lui-même. De cette façon, vous devez choisir, ajouter ou modifier judicieusement les types de signaux et être capable d’adapter le traitement en fonction de vos besoins. Ici, ce n'est pas que plus il y a de sources de données de surveillance, meilleure est la couverture aveuglément complète qui est également une approche qui permet d'obtenir deux fois le résultat avec moitié moins d'effort ; dans le scénario de traitement de données volumineuses d'exploitation et de maintenance de grande dimension et à cardinalité élevée, nous peut facilement conduire à une situation dans laquelle les coûts de stockage s'envolent et où des données de bruit invalides sont toujours présentes, ce qui peut considérablement diluer des points d'information précieux.
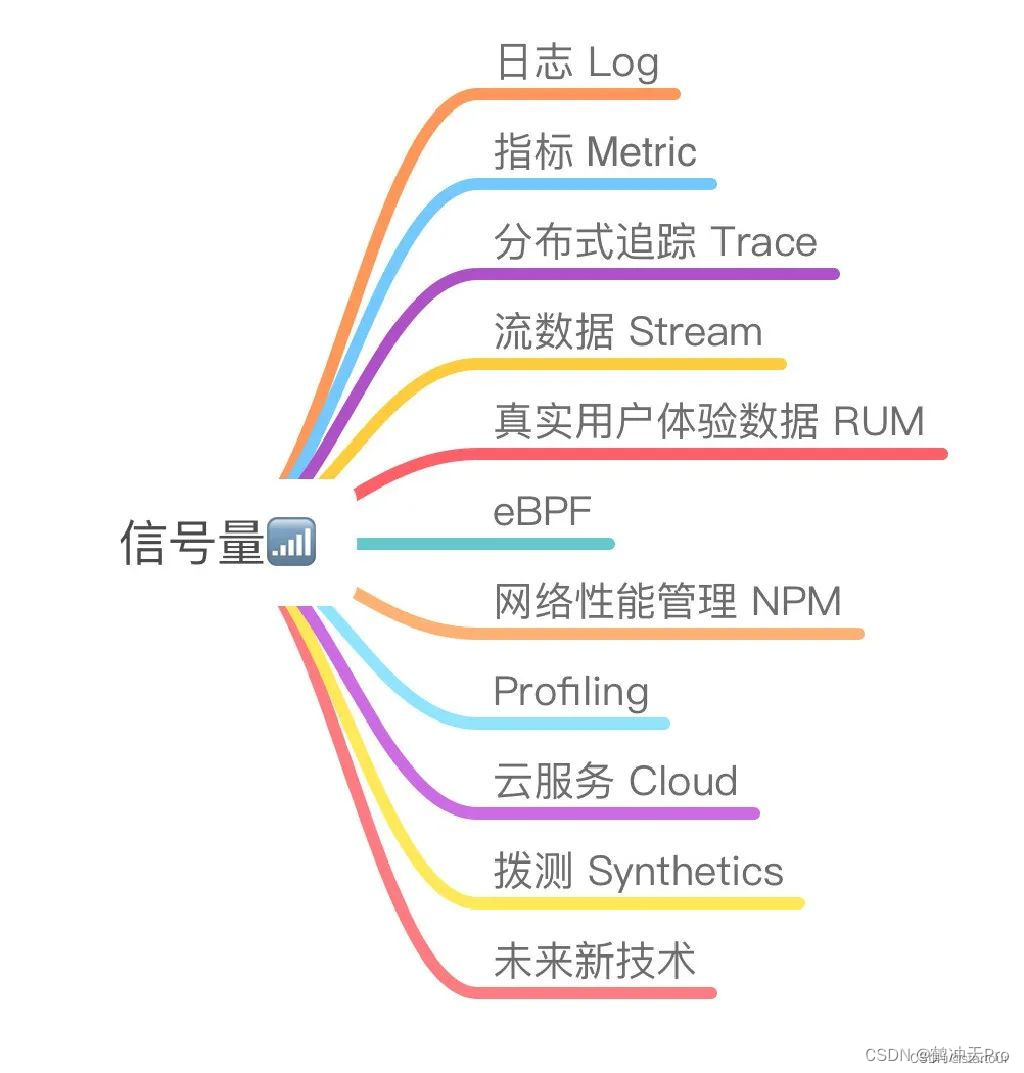
Que sont les sémaphores dits globaux ?
Journal : le texte enregistre les activités, les événements et les erreurs du système et des applications, fournissant un contexte détaillé.
Métrique : mesure quantitative des performances, telles que l'utilisation du processeur et le taux de requêtes, pour aider à surveiller l'état du système.
Traçage distribué Trace : suivez le chemin des requêtes et des goulots d'étranglement de performances dans le système distribué.
Données en streaming : données générées en temps réel, telles que le comportement des utilisateurs, pour une surveillance et une analyse en temps réel.
Données d'expérience utilisateur RUM : enregistre les interactions, les opérations et les réactions des utilisateurs dans l'application pour évaluer la qualité de l'expérience.
eBPF : étend le filtre de paquets Berkeley pour collecter des données au niveau du noyau à des fins d'analyse et de surveillance.
Gestion des performances du réseau NPM : surveillez la bande passante du réseau, la latence et l'état de la connexion, et optimisez les performances du réseau.
Profilage : analysez les caractéristiques de performances du code lors de son exécution pour aider à optimiser l'application.
Service cloud Cloud : surveillance des données obtenues auprès des fournisseurs de cloud pour suivre l'utilisation et les performances des ressources.
Données de test de numérotation Disponibilité/synthétiques : effectuez régulièrement des tests externes du système pour surveiller la disponibilité et les performances du système dans différents emplacements et conditions.
Nouvelles technologies du futur : types de données inconnus.
La « plateforme de gestion de l'observabilité » devrait être conçue avec un sémaphore inclusif et complet comme objectif initial de conception. Cela signifie que : dans l'ensemble du processus de collecte, de téléchargement, de stockage, d'affichage et d'analyse de corrélation des données d'observation, tous les types de données doivent être traités correctement, afin que la corrélation des données de type croisé puisse être effectuée de manière plus raisonnable et plus efficace ; dans l'exploration de données -down, Pendant le processus, vous pouvez librement sauter et explorer entre différentes chronologies.
Bien entendu, la surveillance des « inconnues » connues est une exigence de gestion de base, et vous devriez pouvoir utiliser une sorte de sémaphore pour y parvenir. L'observabilité consiste davantage à discuter : de la gestion des changements entre des états "inconnus" ; cela nécessite une "plate-forme d'observabilité" capable de gérer la grande "complexité" des environnements multi-niveaux, à haute dépendance, multi-cloud et des systèmes distribués. et l'accès à la demande aux sémaphores n'est souvent qu'une condition nécessaire.
Il existe déjà sur le marché de nombreuses plateformes de gestion d’exploitation et de maintenance qui se nomment elles-mêmes plateformes de gestion « d’observabilité ». Mais la plupart d’entre eux commencent par un type de surveillance spécifique et s’étendent progressivement pour couvrir d’autres types de signaux. En règle générale, seules les plates-formes capables de couvrir plus de 3 types de signaux sont susceptibles d'avoir d'excellents effets pratiques ; pour les produits "d'observabilité" qui ont déjà 3 à 5 ans, il est peu probable qu'ils obtiennent des résultats magnifiques à court terme. Même si vous retournez-vous, vous ne pourrez pas reconstruire votre produit à partir de zéro.
Outils de collecte et de téléchargement unifiés
À une époque où les machines physiques sont populaires, un hôte (machine virtuelle ou machine physique) est susceptible de jouer plusieurs rôles. De plus, selon les besoins de gestion des différentes équipes, une variété d'agents de surveillance de gestion seront installés dans leurs systèmes d'exploitation, tels que : indicateurs du système d'exploitation, journaux, bases de données, middleware, inspections de sécurité, etc. ; cette forme empilée fournit non seulement les opérateurs disposant de ressources système ont entraîné une consommation importante, et ont même apporté beaucoup de questions triviales à la gestion du serveur. Par exemple, l'agent de surveillance de la base de données doit également créer un compte utilisateur dédié, etc. Afin de résoudre ce problème, de nombreuses entreprises espèrent utiliser le moins d'agents de collecte uniques possible. Par exemple : le produit de surveillance Patrol de BMC dispose de divers modules de collecte KM (base de données, middleware, serveur Web, etc.), et les utilisateurs peuvent configuration selon les besoins sans qu'il soit nécessaire de déployer plusieurs agents de collecte. Cependant, BMC acquerra progressivement de nombreux nouveaux produits. Les produits ultérieurs incluent la gestion dynamique des performances de base, la gestion automatisée de la configuration, etc. Du point de vue des fabricants d’outils, ils ne peuvent pas réaliser une intégration rapide des produits et il est difficile de maintenir un agent de collecte unique.
Dans l'environnement de l'entreprise de la partie A, les différents départements achèteront différents outils de gestion en fonction de leurs propres besoins.Les différences entre les départements conduisent à la construction répétée d'outils et à la collecte répétée de données, et les données ne sont pas facilement partagées entre les départements. Cela entraîne non seulement le déploiement superposé d'outils de collecte sur le même hôte, mais conduit également au fonctionnement indépendant d'un grand nombre de bases de données d'exploitation et de maintenance d'îlots isolés avec des données en double. Cette situation a en outre conduit à d'autres problèmes. Par exemple, la même panne sur le même hôte déclenchera plusieurs événements d'alarme dans différents outils ; une tempête d'événements s'annonce. Cette situation chaotique donne aux outils AIOps la possibilité de survivre. Même si cela peut produire certains avantages en matière de convergence et de compression des événements, il existe une erreur évidente consistant à « traiter les symptômes mais pas la cause profonde ».
Le temps est passé à l’ère de la virtualisation et du cloud natif, et la situation ci-dessus n’a pas fondamentalement changé. Au lieu de cela, cela entraîne le dilemme d’une dépendance profonde semblable à celle d’une poupée gigogne. Nous n'exécuterons pas de fonctions Web, middleware, base de données, file d'attente de messages et autres fonctions dans un POD, mais après les avoir déployées indépendamment dans des sous-services (services de conteneurs) pouvant être étendus horizontalement, cela entraînera le nombre d'objets de gestion. poussée exponentielle. L'ère des conteneurs a apporté de nouveaux outils de surveillance, notamment : Prometheus, Grafana, FluntD, Graphite, cAdvisor, Loki, EFK, etc. On constate que les nouveaux outils ne changeront pas complètement la situation de coexistence et de superposition de multiples agents à fonction de collecte. Après avoir constaté le problème du déploiement de plusieurs programmes d'agents similaires, Elastic a rapidement intégré divers programmes Beats précédents (projets acquis plusieurs fois) dans un agent unifié Elastic Agent au cours des dernières années. Cependant, ce programme n'est actuellement qu'un agent polyvalent. (packaging shell) pour le programme Beats.
Non seulement plusieurs ensembles d'outils de collecte entraînent de nombreuses tâches de déploiement et de configuration sur les points de terminaison, mais leurs backends correspondent également à leurs propres déploiements de bases de données indépendants. Les descriptions de champs du même objet de gestion dans différentes bases de données sont fondamentalement différentes. Cela rend difficile pour les utilisateurs de l'ensemble d'outils de mettre en œuvre une analyse de corrélation dans diverses bases de données. Le cerveau humain transporte le contexte de débogage et effectue le débogage dans un ensemble de consoles. les tâches demandent beaucoup de travail, et l'alignement des délais et la surveillance des objets épuiseront rapidement la limite supérieure cognitive de l'individu.
CMDB peut être une solution, mais la conception et la construction de CMDB ne sont pas moins difficiles que la construction de n'importe quel projet de système de surveillance lui-même. Utiliser CMDB pour résoudre ce problème est difficile et coûteux à mettre en œuvre. La gouvernance des données sera également une pratique courante, et la solution pour faire de l'ELT et de la gouvernance des données entre ces collections de bases de données d'exploitation et de maintenance, et enfin réaliser la normalisation des informations hétérogènes d'exploitation et de maintenance, n'est qu'une étape impuissante. le personnel éprouvera certainement l'amertume de profiter de la situation pendant le projet.
Il semble que le modèle de données unifié (ECS) lancé pour la première fois par Elastic soit un moyen réalisable de déplacer les données vers des définitions standardisées. Nous l’avons également constaté : le projet OpenTelemetry a rapidement adopté Elastic ECS. La CNCF a ensuite lancé un modèle similaire de définition des données d’observation. Je crois que la CNCF a dû voir, dans son schéma technologique, la prospérité rapide d'outils similaires et similaires dans la classification d'observabilité et d'analyse. Ces normes ne peuvent qu’étancher notre soif, car nous n’avons pas encore vu la plupart des fabricants et un grand nombre de projets open source suivre rapidement l’implémentation et la mise en œuvre de la compatibilité.
Le DataKit d'Observation Cloud est un agent de collecte multifonctionnel conçu pour résoudre les problèmes ci-dessus. Il est déjà compatible et connecté à un écosystème technologique plus large. Une fois qu'un agent de collecte a collecté ou connecté les données cibles, il doit en fait traiter une série de détails, sinon il ne sera toujours pas en mesure de réaliser la « gouvernance des sources » et d'éviter le dilemme du « déchets dans les déchets ». Tout d'abord, lorsque DataKit organise et encapsule les données, la définition de tous les champs suit un dictionnaire de données défini par le cloud d'observation (équivalent à Elastic ECS) ; deuxièmement, avant que le package de données rapporté ne soit empaqueté, il peut également effectuer un traitement de pipeline de données, réaliser des données Problèmes tels que l'élimination des champs, le contrôle de la qualité, la gouvernance et la désensibilisation. Enfin, la collection de DataKit peut également être connectée à des écosystèmes open source et fermés, comme la réception des données de la sonde APM de DataDog, la connexion aux données OpenTelemetry, etc. Il peut également réaliser la transmission de données d'observation sur Internet et entre réseaux.
Back-end de stockage unifié
Dans le processus de construction d’une plateforme d’observabilité, chaque type de sémaphore mérite sa meilleure place :
Elasticsearch : Avec la bénédiction de l'ECS d'Elastic, cela semble être une solution tout-en-un très appropriée, mais le principe est que vous devez être en mesure de maintenir la rentabilité.
Base de données de séries chronologiques : non répertoriée une par une, adaptée aux données de séries chronologiques d'indicateurs.
Base de données de colonnes : une base de données de colonnes pour l'analyse des données en temps réel représentée par ClickHouse, compatible avec une variété de signaux.
Base de données relationnelle : POURQUOI PAS.
Du point de vue du stockage des données, configurer le meilleur type de base de données pour chaque sémaphore semble être une situation heureuse pour tout le monde. Cela ne déçoit pas la situation actuelle où fleurissent diverses bases de données open source.
Évitez les silos de données et les problèmes de gouvernance déjà mentionnés ci-dessus. Du point de vue des requêtes, les utilisateurs devront apprendre plusieurs langages de requête. Il existe n types de syntaxe SQL que vous devez apprendre, sinon vous devrez développer et maintenir une interface de requête un-à-plusieurs. Ne discutons pas ici de la façon dont vous allez mettre en œuvre une analyse de corrélation de données entre bases de données des données d'observabilité.
Question : Existe-t-il une base de données unifiée multimodale qui intègre plusieurs types de données de sémaphore dans un entrepôt de données unifié ?
En fait, les fournisseurs SaaS d'observabilité actuels ont fourni à leurs utilisateurs un tel backend de données unifié et intégré, du moins du point de vue de l'interrogation et de l'exploration de l'utilisation des données d'observabilité. L'Observation Cloud lance également une telle base de données pour répondre aux besoins de gestion de coexistence unifiée, intégrée et polymorphe ci-dessus. Les utilisateurs d'Observation Cloud pourront bientôt utiliser cette technologie dans les services SaaS et sur des produits déployés en privé.
Liberté d’explorer et de synthétiser les données
La valeur des données observables se reflète dans leur utilisation. Ce n'est qu'en étant capable d'explorer librement et d'utiliser de manière exhaustive diverses données que la valeur des données peut être amplifiée. Lors de l'examen des scénarios d'utilisation des données d'observabilité, l'éditeur recommande fortement d'utiliser les « premiers principes » pour réfléchir, afin d'éviter de se fier à l'expérience et d'exclure l'hypothèse selon laquelle les nouvelles technologies d'observabilité peuvent remplacer toutes les anciennes technologies. nous revenons à l’origine conceptuelle de la technologie d’observabilité.

Résumer
Cet article aborde les points techniques de la mise en œuvre d'une plateforme d'observabilité à partir de quatre niveaux avec une certaine profondeur et un certain laps de temps. Espoir : Dans votre environnement de travail, une plateforme d’observabilité unifiée et intégrée pourra bientôt être mise en œuvre. En portant deux bottes, vous pouvez échapper au dilemme précédent consistant à se battre pieds nus et à combattre les incendies pieds nus. Nous espérons que la plate-forme d'observabilité pourra aider tout le monde dans le pipeline de livraison de logiciels, utiliser l'observabilité pour compléter les opérations, augmenter la puissance du SRE et enhardir les développeurs.
Lecture recommandée "Ingénierie de l'observabilité"

Raison de la recommandation : rédigé par des experts principaux de Google SRE et des dirigeants de la communauté d'observabilité, et traduit avec amour par l'équipe de cloud d'observation des entreprises licornes nationales dans le domaine de l'observabilité. Un guide pour la mise en œuvre de la technologie d'observabilité, qui résout efficacement les problèmes liés à l'exploitation et à la maintenance difficiles des systèmes logiciels à l'ère du cloud natif. Promouvez les systèmes informatiques pour obtenir une livraison efficace, une exploitation et une maintenance unifiées et une optimisation durable.
Lien d'achat https://u.jd.com/nb2cA1B
Aperçu de la diffusion en direct
Thème de diffusion en direct :
Forum sur les nouvelles tendances du génie logiciel moderne et lancement du nouveau livre "Observability Engineering"
Heure de diffusion en direct
le 20 septembre (mercredi)
de 19h00 à 20h30
"Observability Engineering" a été publié en 2021 et a été largement salué à l'étranger. C'est un livre incontournable pour tout ingénieur qui souhaite comprendre la technologie d'observabilité. Le 20 septembre 2023 à 19h00, la branche Huazhang de Machinery Industry Press se joindra à « l'équipe Observation Cloud », le traducteur chinois de ce livre, pour organiser une conférence de lancement d'un nouveau livre en ligne pour explorer le développement de la technologie d'observabilité avec des invités dans le cercle.Nouvelles tendances et nouvel avenir.
Réservez une diffusion en direct
Numéro de vidéo : Rappel de réservation de diffusion en direct CSDN : "Conférence" - Nouvelles tendances de l'ingénierie logicielle moderne ; La salle de diffusion en direct du site officiel du CSDN sera également diffusée simultanément !

Méthode de loterie
-
Suivre+J'aime+Collecter les articles
-
Laissez un message dans la zone de commentaire : découvrez l'ensemble des connaissances et trouvez un gagnant (vous pouvez participer à la cagnotte en suivant et en laissant un message, chaque personne peut laisser un maximum de trois messages)
-
Tirage au sort dimanche à 20h
-
Cette fois, nous offrirons 2 à 5 livres [plus vous lisez, plus vous en offrirez]
500-1000 2 livres gratuits
1000-1500 3 livres gratuits
1500-2000 4 livres gratuits
2000+ 5 livres gratuits