Seuls les pilotes de cartes graphiques utilisés en deep learning seront abordés.
Prenons NVIDIA-driver-515.105 et cuda-11.7 comme exemples
1. Désinstallez le pilote de la carte graphique
CentOS/RHEL
Méthode 1 : Recherchez l’ancienne version du fichier .run du pilote de la carte graphique :
sh NVIDIA-Linux-x86_64-418.126.02.run --uninstall
Méthode 2 : Effacer tous les fichiers et dépendances liés à NVIDIA
yum remove nvidia-*
Nettoyage supplémentaire (nettoyer tous les composants liés au pilote nvidia) :
rpm -qa|grep -i nvid|sort
yum remove kmod-nvidia-*
Effacer le cuda
yum remove "*nvidia*"
yum remove "*cublas*" "cuda*"
Désinstallez le pilote et redémarrez
sudo reboot
Ubuntu LTS
Il convient de noter qu'en raison des différents systèmes de noyau, les méthodes de commande adoptées sont différentes.
apt-get appartient à Ubuntu, l'outil de gestion de paquets de Debian,
yum, appartient à Redhat et l'outil de gestion de paquets Centos
. Lorsque vous choisissez la commande à utiliser pour supprimer, vous devrait d'abord déterminer votre propre quel est le système.
Si sudo apt-get purge nvidia-*à la placeyum remove nvidia-*
sudo apt-get purge nvidia-*
sudo apt-get --purge remove cuda
2. Installation du pilote de la carte graphique
notions de base
Que sont exactement les cartes graphiques, le pilote graphique, nvcc, le pilote cuda, cudatoolkit et cudnn ? - Zhihu
Ajoute probablement quelques connaissances.
Pilote CUDA : Le pilote CUDA est un composant logiciel utilisé pour communiquer avec le GPU. Il est chargé de gérer les ressources matérielles du GPU et d'exécuter les applications CUDA.
CUDA Toolkit : CUDA Toolkit est un progiciel permettant de développer et d'optimiser des applications CUDA, qui comprend des pilotes CUDA et des bibliothèques d'exécution CUDA.
Bibliothèque d'exécution CUDA : La bibliothèque d'exécution CUDA est un composant logiciel utilisé pour exécuter des applications CUDA sur le GPU. Il fournit un ensemble de fonctions API CUDA pour gérer la mémoire GPU et exécuter les noyaux CUDA.
Conditions préalables
Vérifiez si gcc, g++, tar et make sont installés sur le système. Sinon, configurez manuellement la source yum pour l'installation.
Vérifiez la commande de version de la carte graphique :
# 查看自己的显卡信息
lspci | grep -i nvidia
# GPU驱动版本,driverAPI(支持的最高cuda版本)
nvidia-smi
# 动态监控显卡状态
watch -t -n 1 nvidia-smi
# cuda版本,timeAPI(运行时API)
nvcc -V
Recherchez et sélectionnez la version correspondante du pilote de la carte graphique, CudaToolkit et cudnn :
recherchez la relation de version correspondante entre la carte graphique NVIDIA et cuda. Notes de version de NVIDIA CUDA ToolkitRechercher
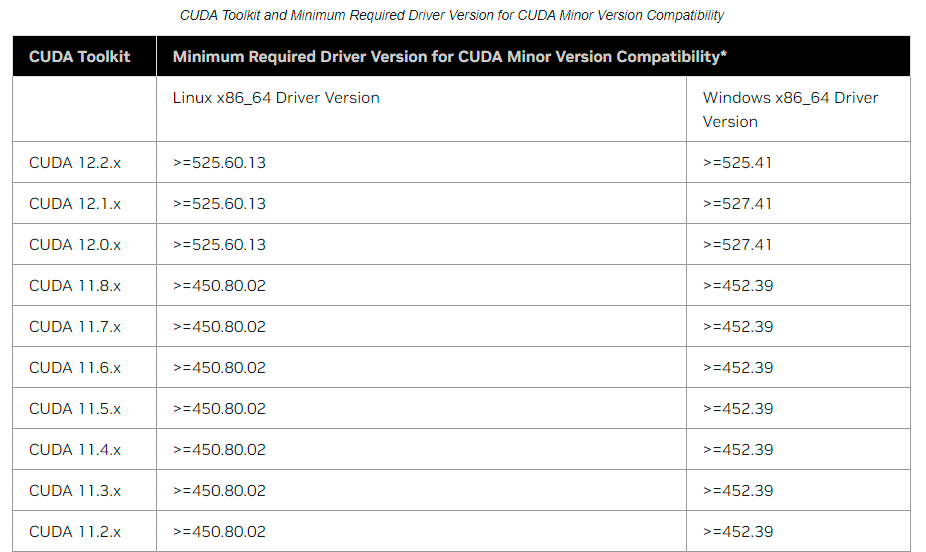
la relation de version correspondante entre PyTorch et cudaVersions précédentes de PyTorch
Cet article sélectionne NVIDIA-driver-515.105 plus cuda-11.7.
Installez le pilote de la carte graphique NVIDIA (pilote NVIDIA)
Téléchargez le pilote NVIDIA . Si vous êtes en ligne, vous pouvez utiliser wget pour le télécharger ou utiliser l'adresse de copie pour le télécharger et le copier sur le serveur.
Accordez les autorisations et installez.
chmod +x NVIDIA-Linux-x86_64-515.105.01.run
./NVIDIA-Linux-x86_64-515.105.01.run -no-x-check
Des questions peuvent apparaître pendant le processus d'installation, choisissez Node continuer.
Si un avertissement apparaît, vous pouvez l'ignorer et continuer jusqu'à ce que l'installation soit terminée.
> Install NVIDIA's 32-bit compatibillity libraries?
> Yes [No]

En cas de problème , vérifiez s'il faut désinstaller le pilote ou consultez la question 1 :./NVIDIA-Linux-x86_64-515.105.01.run -no-x-check
Testez si le pilote de la carte graphique est installé avec succès
nvidia-smi
Installer CUDA
Téléchargez l'adresse de téléchargement de CUDA Toolkit ou recherchez l'ancienne version pour télécharger l'adresse de téléchargement de l'ancienne version de CUDA Toolkit .
Accordez les autorisations et installez.
chmod +x cuda_11.7.1_515.65.01_linux.run
./cuda_11.7.1_515.65.01_linux.run
Pendant le processus d'installation, il vous sera demandé si vous devez télécharger le pilote (Drive). Dans des circonstances normales, veuillez ne pas le télécharger, c'est-à-dire sélectionner Non.
Annuler le
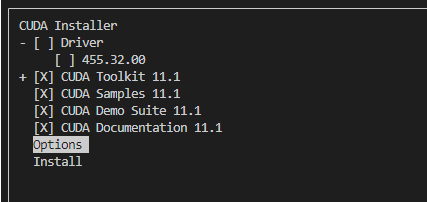
Après l'installation, les éléments suivants apparaîtront :
===========
= Summary =
===========
Driver: Not Selected
Toolkit: Installed in /usr/local/cuda-11.7/
Please make sure that
- PATH includes /usr/local/cuda-11.7/bin
- LD_LIBRARY_PATH includes /usr/local/cuda-11.7/lib64, or, add /usr/local/cuda-11.7/lib64 to /etc/ld.so.conf and run ldconfig as root
To uninstall the CUDA Toolkit, run the uninstall script in /usr/local/cuda-11.7/bin
Please see CUDA_Installation_Guide_Linux.pdf in /usr/local/cuda-11.7/doc/pdf for detailed information on setting up CUDA.
***WARNING: Incomplete installation! This installation did not install the CUDA Driver. A driver of version at least 515.105 is required for CUDA 11.7 functionality to work.
To install the driver using this installer, run the following command, replacing <CudaInstaller> with the name of this run file:
sudo <CudaInstaller>.run -silent -driver
Configurez les variables d'environnement et ajoutez le contenu suivant au ~/.bashrcfichier.
ouvrir un fichier
vim ~/.bashrc
Ajoutez les deux lignes suivantes à la fin du fichier pour remplacer cuda version 11.7 par la version installée, telle que cuda-12.2.
export PATH=/usr/local/cuda-11.7/bin${
PATH:+:${
PATH}}
export LD_LIBRARY_PATH=/usr/local/cuda-11.7/lib64${LD_LIBRARY_PATH:+:${LD_LIBRARY_PATH}}
Utilisez la commande suivante pour actualiser ~/.bashrcle fichier de configuration afin que la configuration prenne effet.
source ~/.bashrc
Testez et interrogez la version de nvcc pour vérifier si l'installation a réussi
nvcc -V
Installer Cudnn
Téléchargez l'adresse de téléchargement cuDNN .
rpm -i cudnn-local-repo-rhel7-8.9.2.26-1.0-1.x86_64.rpm
3. Adaptation de la carte graphique Docker
Version du logiciel :
Docker : Docker version 20.10.9, build c2ea9bc
CUDA : NVIDIA-SMI 515.105.01 Version du pilote : 515.105.01 Version CUDA : 11.7
Système : CentOS-7
Après la version 19.03, Docker n'a plus besoin d'installer nvidia-docker indépendamment pour prendre en charge les cartes graphiques. Il vous suffit de configurer Docker et l'environnement CUDA. Désormais, une nouvelle méthode est utilisée pour installer NVIDIA Container afin de prendre en charge Docker appelant la carte graphique.
L'installation de Nvidia-Docker nécessite l'installation de deux parties, Docker-CE et NVIDIA Container Toolkit, ce qui signifie que Docker-CE n'est plus requis.
Architecture NVIDIA-Container-Toolkit
Un aperçu de l'architecture du site officiel de NVIDIA peut être lu attentivement à l'aide du traducteur de pages Web intégré à Chrome. Cet article ne le présente que brièvement.
Les principaux composants de NVIDIA Container incluent nvidia-container-runtime, nvidia-container-toolkit, libnvidia-containerqui doivent être installés à l'avance lors de l'installation CUDA驱动;
après la version 3.6.0, le package d'exécution devient un toolkitpackage qui dépend uniquement du package (en faisant référence au conteneur-toolkit au lieu du kit d'outils nvidia CUDA ).Il est également souligné sur le site officiel, Pour les applications générales, nvidia-container-toolkitil peut répondre à la plupart des besoins.
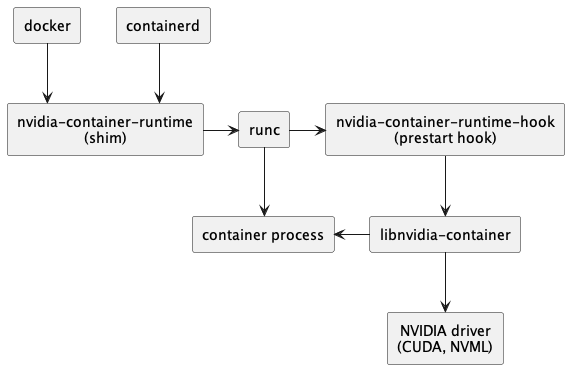
Installer les dépendances du package
Le diagramme de dépendance des documents du site officiel est le suivant.
├─ nvidia-container-toolkit (version)
│ ├─ libnvidia-container-tools (>= version)
│ └─ nvidia-container-toolkit-base (version)
│
├─ libnvidia-container-tools (version)
│ └─ libnvidia-container1 (>= version)
└─ libnvidia-container1 (version)
nvidia-container-toolkit-base est désormais inclus dans nvidia-container-toolkit et ne nécessite plus l'installation de nvidia-container-runtime. (Le précédent nvidia-docker nécessitait l'installation de deux packages supplémentaires, nvidia-container-runtime et nvidia-docker2.)
Selon les dépendances ci-dessus, installez les trois packages logiciels dans l'ordre de
libnvidia-container1 -> libnvidia-container-tools -> nvidia-container-toolkit
Téléchargement et installation hors ligne
Téléchargez le package d'installation ici pour une installation hors ligne.
Le site officiel fournit un lien GitHub :
1. Adresse de téléchargementnvidia-container-toolkit du package d'installation Recherchez le téléchargement du package d'installation correspondant à la version du système. Par exemple, sur le système CentOS7 que j'utilise, vous pouvez télécharger le package d'installation dans le répertoire ci-dessousnvidia-container-runtime/stable/centos7/x86_64/nvidia-container-toolkit-1.5.1-2.x86_64.rpm
2. libnvidia-container1Recherchez l' adresse de téléchargementlibnvidia-container-tools du package d'installation correspondant à la version du système. De même, pour le système CentOS7 que j'utilise, vous pouvez télécharger le package d'installation à partir du répertoire ci-dessous (cliquez sur le fichier et il y a un bouton ↓ Télécharger le fichier brut dans le coin supérieur droit . S'il n'y a pas de réponse, vérifiez si le réseau est scientifiquement connecté)nvidia-container-runtime/stable/centos7/x86_64/nvidia-container-toolkit-1.5.1-2.x86_64.rpm
Après avoir téléchargé les trois packages, importez-les dans le système et choisissez de les installer dans le dossier correspondant.
Méthode d'installation du package RPM, tous les packages d'installation RPM dans le dossier d'installation
rpm -ivh *.rpm
méthode d'installation du paquet deb
dpkg -i *.deb
Après l'installation, redémarrez le service Docker.
systemctl restart docker
systemctl status docker
succès! Vous pouvez --gpus alldémarrer un conteneur pour tester si le conteneur utilise le GPU normalement.
4. Testez
Utilisez docker run --gpus allpour démarrer un conteneur et entrez à l'intérieur du conteneur pour tester si le GPU est utilisé normalement.
La vérification en Python est également la méthode la plus couramment utilisée pour vérifier si le GPU est disponible (mais il se peut qu'il ne soit pas réellement utilisé)
import torch
torch.cuda.is_available()
# setting device on GPU if available, else CPU
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
print('Using device:', device)
print()
#Additional Info when using cuda
if device.type == 'cuda':
print(torch.cuda.get_device_name(0))
print('Memory Usage:')
print('Allocated:', round(torch.cuda.memory_allocated(0)/1024**3,1), 'GB')
print('Cached: ', round(torch.cuda.memory_reserved(0)/1024**3,1), 'GB')
5. Résumé des erreurs
1.ERREUR : vous semblez exécuter un serveur X ; veuillez quitter X avant l'installation. Pour plus de détails, …
Cette erreur se produit lors de l'installation du pilote NVIDA. Principalement en raison de l'installation de la télécommande lightgm provoquant le démarrage du serveur X.
Solution:
sudo chmod +x NVIDIA-Linux-X86_64-515.105.run
sudo ./NVIDIA-Linux-X86_64-515.105.run -no-x-check
Ajoutez -no-x-checkla commande à la fin sans vérifier le serveur X, et l'installation sera réussie !
Autres paramètres :
--no-opengl-files : Indique que seuls les fichiers du pilote seront installés et que les fichiers OpenGL ne seront pas installés. Ce paramètre ne peut pas être omis, sinon il provoquera une boucle infinie dans l'interface de connexion. En anglais, on l'appelle généralement « login loop » ou « Stuck in login ».
--no-x-check : Indique que le service X n'est pas vérifié lors de l'installation du pilote, ce n'est pas obligatoire.
--no-nouveau-check : Indique que nouveau n'est pas vérifié lors de l'installation du pilote, ce n'est pas obligatoire.
-Z, --disable-nouveau : Désactivez le nouveau. Ce paramètre n'est pas obligatoire car nouveau a été désactivé manuellement précédemment.
-A : Voir les options plus avancées.
Méthode 2 : Modifier le niveau d'exécution en mode texte : mettre à niveau le pilote nvidia - EchoZQN - Blog Park
2.Réponse d'erreur du démon : impossible de sélectionner le pilote de périphérique « » avec les capacités : [[gpu]]
Une fois Nvidia Docker installé, une erreur se produit lors de l'utilisation de l'image pour créer un conteneur. Le message d'erreur est :
Error response from daemon: could not select device driver "" with capabilities: [[gpu]]
Besoin d'installer :
le pilote nvidia du serveur NVIDIA Container Toolkit a été installé, l'utilisation du GPU ne pose aucun problème, mais Docker ne peut pas utiliser le GPU, vous devez alors vérifier si NVIDIA Container Toolkit a été installé. Le NVIDIA Container Toolkit permet aux utilisateurs de créer et d'exécuter des conteneurs Docker accélérés par GPU (après la version 19 de Docker, avant 18 à l'aide de la commande nvidia-docker), donc ce n'est qu'après l'avoir installé que vous pourrez utiliser le GPU dans Docker.
Selon votre système, recherchez la commande d'installation correspondante sur le site officiel.
Le site officiel de https://docs.nvidia.com/datacenter/cloud-native/container-toolkit/install-guide.html#docker
est très détaillé, suivez-le simplement étape par étape.
Le chapitre 3 est très détaillé
3.le fichier /usr/lib64/libnvidia-container.so.1 de l'installation de libnvidia-container1-1.13.5-1.x86_64 est en conflit avec le package de formulaire de fichier libnvidia-container1-1.0.0-0.1.beta.1.x86_64
Cette erreur signifie que le fichier "/usr/lib64/libnvidia-container.so.1" dans le package déjà installé "libnvidia-container1-1.0.0-0.1.beta.1.x86_64" est différent du package à installer " Conflit avec des fichiers du même nom dans libnvidia-container1-1.13.5-1.x86_64".
Cela peut être dû au fait que le gestionnaire de packages tente d'installer une nouvelle version d'un package sur votre système dont les fichiers sont en conflit avec les fichiers d'un package existant. Une façon de résoudre ce conflit consiste à désinstaller l'ancienne version du package ou à mettre à jour les fichiers en conflit en les mettant à jour ou en les remplaçant.
Essayez de résoudre le conflit à l'aide de la commande suivante :
sudo yum remove libnvidia-container1-1.0.0-0.1.beta.1.x86_64
4.ERREUR : Le pilote du noyau Nouveau est actuellement utilisé par votre système. Ce pilote est incompatible avec le pilote NVIDIA et doit être désactivé avant de continuer. Veuillez consulter le README du pilote NVIDIA et la documentation de votre distribution Linux…
Ce problème est dû au fait que le système utilise actuellement le pilote graphique Nouveau et que le pilote NVIDIA est incompatible avec le pilote Nouveau. Pour résoudre ce problème, le pilote Nouveau doit être désactivé.
Méthode 1 : Désactivez le pilote Nouveau via la liste noire
1) Ajoutez deux lignes à /usr/lib/modprobe.d/dist-blacklist.conf :
blacklist nouveau
options nouveau modeset=0
2) Faire une sauvegarde de l'image actuelle
mv /boot/initramfs-$(uname -r).img /boot/initramfs-$(uname -r).img.bak
3) Créer une nouvelle image
dracut /boot/initramfs-$(uname -r).img $(uname -r)
4) Redémarrer
sudo init 6
Méthode 2 : Ajouter des paramètres
Ajouter des paramètres--no-opengl-files
./NVIDIA-Linux-x86_64-515.105.01.run --no-opengl-files
5.docker : Réponse d'erreur du démon : échec de la création de l'exécution OCI : conteneur_linux.go:380 : démarrage du processus de conteneur provoqué : process_linux.go:545 : initialisation du conteneur provoqué : crochet d'exécution #0 : erreur d'exécution du crochet : état de sortie 1, sortie standard : , stderr : nvidia-container-cli : erreur d'initialisation : erreur rpc du pilote : délai d'attente : inconnu.
Une erreur très étrange, une erreur --gpus allsera signalée lors du chargement de la carte graphique au démarrage du conteneur. Ce lien donne la réponse . La raison est que la ressource de la carte graphique n'active pas le mode persistance.
Après avoir consulté de nombreuses informations, j'ai découvert qu'un grand expert d'Internet avait consulté NVIDIA. L'explication donnée par NVIDIA est la suivante : " La ressource de la carte graphique n'active pas le mode persistance ." Entrez la commande suivante pour résoudre le problème :
nvidia-smi -pm ENABLED
Si une invite apparaît après avoir appuyé sur Entrée dans la commande ci-dessus, suivez simplement les invites pour installer. Une fois l'installation terminée, exécutez à nouveau la commande ci-dessus et tout ira bien.
Contenu de référence
Adresse de téléchargement du pilote NVIDIA.cn
Adresse de téléchargement du pilote NVIDIA.com
Versions compatibles du pilote NVIDIA et de CUDA Toolkit et configuration minimale requise
Adresse de téléchargement de CUDA Toolkit
Adresse de téléchargement de l'ancienne version de CUDA Toolkit
Adresse de téléchargement de CUDA Toolkit 11.7.1
Adresse de téléchargement cuDNN
CentOS.7 Désinstaller et installer Nvidia Driver_centos Désinstaller le pilote nvidia_Aaron_Qin Blog de Feng-Blog CSDN
Linux Centos7 Installation et mise à jour du pilote GPU et cuda:_linux mise à niveau de la version cuda_Big data Blog de lsy-Blog CSDN
mise à niveau du pilote nvidia-EchoZQN -
Comment rétrograder la version cuda -
Environnement openpose de la station technologique Python pour créer le blog de ubuntu16.04+nvidia396.37+cuda9.2+cudnn7.1.4_tudou880306 - Blog CSDN
Comment vérifier les informations de version sous Linux - Fonctionnement et maintenance de Linux - PHP Site Web chinois
cuda, cudnn, cudatoolkit toutes les versions télécharger URL_cudnn download_QT-Smile's blog - Blog CSDN
python vérifier les informations de la carte graphique python vérifier le gpu
Installation hors ligne de Docker Nvidia-container-toolkit Implémentation du GPU appels dans le blog du conteneur_NekoTom-blog CSDN
docker : Réponse d'erreur du démon : impossible de sélectionner le pilote de périphérique "" avec des capacités : [[gpu]]Rapport d'erreurs_–gpus tous Rapport d'erreurs_Le blog de Da Meow qui veut s'allonger tous les jours-CSDN BlogError : vous semblez exécuter un serveur x
; veuillez quitter x avant d'installer. pour plus de détails_erreur : vous semblez exécuter
un problème. Difficultés rencontrées lors du processus_Applications logicielles_Qu'est-ce qui vaut la peine d'être acheté ?