Source : Xinzhiyuan Editeur : LRS
[Nouvelle introduction à Zhiyuan] Avec seulement quelques images et texte, vous pouvez générer des images de tout âge, et les commentaires des utilisateurs ont un taux de précision de 80 % !
Le « système de reconnaissance faciale » actuel a des capacités anti-âge très faibles. Le vieillissement du visage réduira considérablement les performances de reconnaissance et les données faciales doivent être remplacées de temps en temps.

L'amélioration de la robustesse du système de reconnaissance faciale nécessite de collecter des données de haute qualité sur le vieillissement individuel. Cependant, les ensembles de données publiés ces dernières années sont généralement de petite taille et pas assez longs (par exemple environ 5 ans), ou présentent des caractéristiques différentes telles que posture, éclairage et arrière-plan. Il y a eu des changements majeurs dans des aspects tels que les données du visage.
Récemment, des chercheurs de l'Université de New York ont proposé une méthode permettant de préserver les caractéristiques identitaires de différents âges grâce à un modèle de diffusion latente, qui ne nécessite que quelques échantillons de formation et peut utiliser intuitivement des « invites de texte » pour contrôler la sortie du modèle.

Lien papier : https://arxiv.org/pdf/2307.08585.pdf
Les chercheurs introduisent deux éléments clés : une perte de préservation de l'identité et un petit ensemble de régularisation (image, description) pour répondre aux limitations imposées par les méthodes existantes basées sur le GAN.
Dans les évaluations de deux ensembles de données de référence, CeleA et AgeDB, la méthode réduit le taux de fausses correspondances d'environ 44 % par rapport au modèle de base de pointe sur la métrique de fidélité biométrique couramment utilisée.
Suivre les changements d’âge des visages
Stand de rêve
La méthode proposée dans cet article s'appuie sur le modèle de diffusion latente DreamBooth, qui permet de placer un même sujet dans d'autres contextes (re-contextualisation) en affinant le modèle de diffusion de graphes vincentiens.
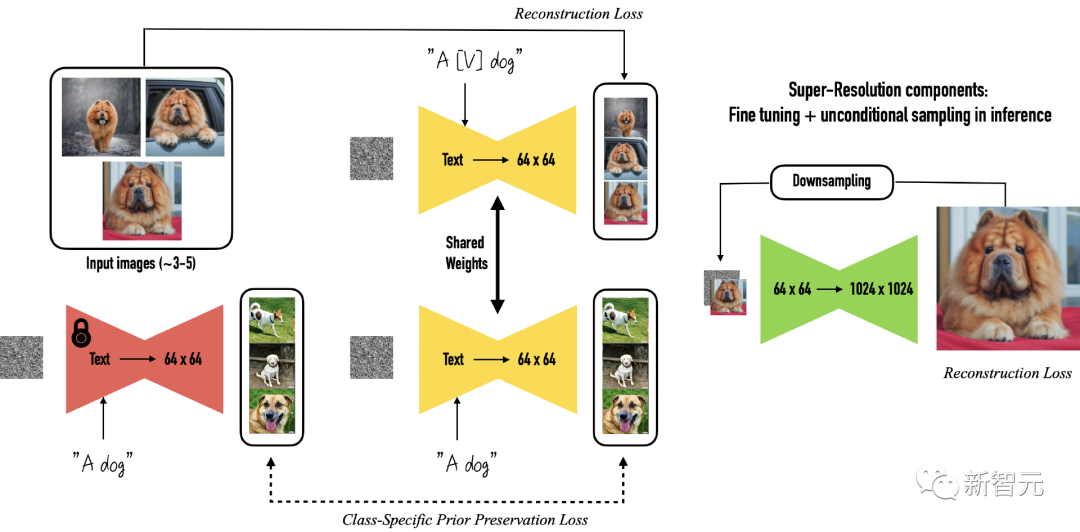
Les exigences d'entrée de Dreambooth sont plusieurs images du sujet cible, ainsi qu'une invite de texte contenant l'identifiant unique du sujet et une étiquette de classe, où l'étiquette de classe est une représentation de collection de plusieurs instances et le sujet correspond à un exemple spécifique appartenant à la classe.
L'objectif de Dreambooth est d'associer un identifiant unique à chaque agent (une instance spécifique d'une classe) puis, guidé par des invites textuelles, de recréer des images du même agent dans différents contextes.
Les étiquettes de classe doivent tirer parti des connaissances préalables du cadre de diffusion pré-entraîné pour la catégorie spécifiée. Des étiquettes de classe incorrectes ou manquantes peuvent entraîner une qualité de sortie dégradée. Les jetons uniques agissent comme des références à des sujets spécifiques et doivent être suffisamment rares pour éviter les conflits avec d'autres. notions couramment utilisées.
L'auteur original a utilisé un ensemble de moins de 3 séquences de caractères Unicode comme jetons et a utilisé T5-XXL comme tokenizer.
DreamBooth utilise une perte de préservation préalable spécifique à la classe pour augmenter la variabilité des images générées tout en garantissant un écart minimal entre l'objet cible et l'image de sortie. La perte d'apprentissage originale est la suivante :
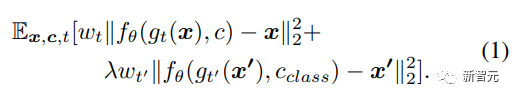
DreamBooth peut synthétiser efficacement des images de sujets tels que des chiens, des chats et des dessins animés à l'aide d'une préservation préalable. Cependant, cet article se concentre principalement sur les images de visages avec des structures plus complexes et des textures plus détaillées.

Bien que l’étiquette de classe « personne » puisse saisir des caractéristiques humaines, elle peut ne pas suffire à saisir les caractéristiques identitaires en raison des différences individuelles.
Par conséquent, les chercheurs ont introduit un terme de préservation de l’identité dans la fonction de perte, qui peut minimiser la distance entre l’image originale et les caractéristiques biométriques de l’image générée, et ont affiné le VAE avec la nouvelle fonction de perte.
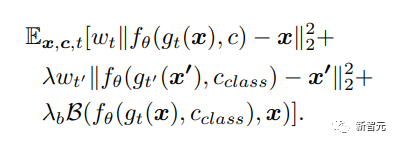
Le troisième terme de la formule représente la distance biométrique entre l'image réelle de l'objet photographié et l'image générée, où B représente la distance L1 des deux images. La même distance d'image est proche de 0. Plus la valeur est grande, plus la différence entre les deux sujets. , en utilisant VGGFace pré-entraîné comme extracteur de fonctionnalités.
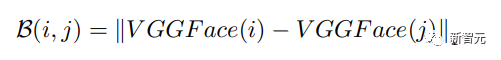
L'étape suivante consiste à l'affiner pour des objectifs spécifiques, en utilisant des VAE et des encodeurs de texte gelés tout en gardant le modèle U-Net non gelé.
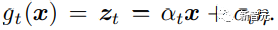
UNet débruite les représentations latentes produites par l'encodeur de VAE, entraînées à l'aide d'une perte contrastive préservant l'identité.
Les chercheurs ont adopté le cadre SimCLR et ont utilisé une perte d'entropie croisée normalisée à l'échelle de la température entre des paires d'échantillons positifs et négatifs pour améliorer la représentation latente, qui est la fonction S dans la formule suivante.
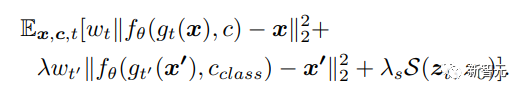
Calculez la perte de contraste entre les représentations latentes de l’entrée sans bruit (z0) et de la sortie débruitée (zt) avec le terme de pondération λs = 0,1 et la valeur de température = 0,5.
La perte contrastive entre les représentations latentes dans l'architecture U-Net permet au modèle d'affiner le modèle de diffusion pour différents sujets.
En plus de personnaliser la perte, les chercheurs ont également attribué les concepts de progression et de régression de l'âge du visage au modèle de diffusion latente à l'aide d'un ensemble de régularisation, où l'ensemble de régularisation comprend toutes les images représentatives d'une catégorie, dans ce cas pour une personne.
Si l’objectif est de générer des images de visage réalistes, il suffit alors de sélectionner un ensemble régularisé d’images de visage sur Internet.
Cependant, la tâche de cet article est de laisser le modèle apprendre les concepts de vieillissement et de rajeunissement, et de les appliquer à différents individus. Les chercheurs ont donc choisi d'utiliser des images de visages de différents groupes d'âge, puis de les combiner avec un mot. légende ) à associer.
Les descriptions d'images correspondent à six tranches d'âge : enfants, adolescents, jeunes adultes, d'âge moyen, personnes âgées et personnes âgées.
Les descriptions d'âge fonctionnent mieux que les indices numériques (20, 40 ans) et le texte peut être utilisé pour inciter des modèles de diffusion à inférer ((photo d'un ⟨ jeton 〉 ⟨ étiquette de classe 〉 comme ⟨ groupe d'âge 〉)
Résultats expérimentaux
Montage expérimental
Les chercheurs ont mené des expériences en utilisant DreamBooth implémenté dans Stable Diffusion v1.4, en utilisant l'encodeur de texte CLIP (entraîné sur laion-aesthetics v2 5+) et la quantification vectorielle VAE pour compléter les changements d'âge. L'encodeur de texte est resté figé pendant l'entraînement du modèle de diffusion. État.
Les chercheurs ont utilisé 2 258 images de visages de 100 sujets dans l’ensemble de données CelebA et 659 images de 100 sujets dans l’ensemble de données AgeDB pour former l’ensemble de formation.

À l'exception de l'attribut binaire "Jeune", l'ensemble de données CelebA ne contient pas d'informations sur l'âge du sujet ; l'ensemble de données AgeDB contient des valeurs d'âge précises. Les chercheurs ont sélectionné le groupe d'âge avec le plus grand nombre d'images et l'ont utilisé comme ensemble d'entraînement, et le reste des images ont été utilisées pour l’ensemble de test (2 369 images au total).
Les chercheurs ont utilisé des paires de données (image, description) comme ensemble de régularisation, où chaque image de visage est associée à une légende indiquant son âge correspondant, en particulier les enfants de moins de 15 ans, les adolescents de 15 à 30 ans, les jeunes adultes de 30 à 40 ans. les personnes âgées, les personnes d'âge moyen de 40 à 50 ans, les personnes d'âge moyen de 50 à 65 ans et les personnes âgées de plus de 65 ans utilisent quatre jetons rares comme marqueurs : wzx, sks, ams, ukj
comparer les résultats
Les chercheurs ont utilisé IPCGAN, AttGAN et Talk-toEdit comme modèles de base pour l'évaluation et la comparaison.
Depuis qu'IPCGAN a été formé sur l'ensemble de données CACD, les chercheurs ont affiné 62 sujets de l'ensemble de données CACD et ont pu observer que FNMR=2 %, alors que la méthode proposée dans l'article FNMR (False NonMatch Rate)=11 %

On constate qu'IPCGAN ne peut pas effectuer d'opérations de vieillissement ou de rajeunissement par défaut, ce qui entraîne une valeur FNMR très faible.
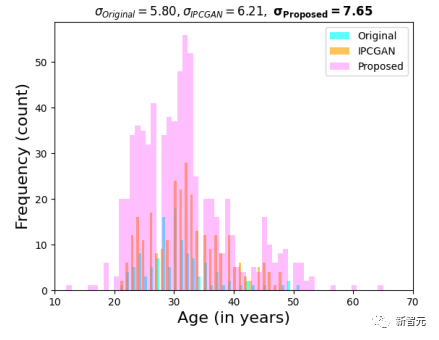
Les chercheurs ont utilisé le prédicteur d'âge DeepFace pour la prédiction automatique de l'âge. On peut observer que par rapport à l'image originale et à l'image générée par IPCGAN, l'image synthétisée par la méthode décrite dans l'article rendra la prédiction de l'âge plus dispersée, indiquant que l'âge l’opération d’édition a réussi.
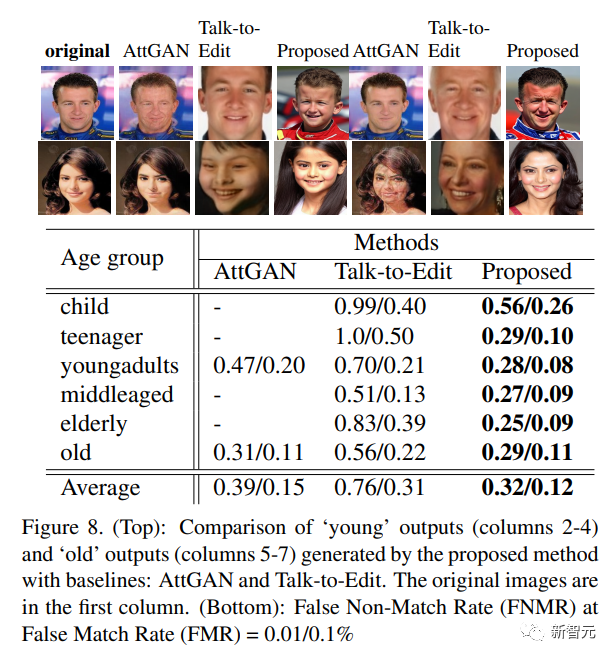
Lors de l'application d'AttGAN et de l'édition de dialogues sur l'ensemble de données CelebA, en termes de comparaison d'images et de performances de correspondance biométrique, on peut observer qu'à FMR=0,01, la méthode de l'article est 19 % meilleure qu'AttGAN sur les images de la catégorie "jeune". , et dans les images de la catégorie " 7 % mieux qu'AttGAN sur les anciens"
recherche d'utilisateurs
Les chercheurs ont collecté 26 retours d'utilisateurs et le taux de précision de la reconnaissance biométrique de premier rang (la moyenne du nombre total de réponses) a atteint 78,8 %. Les taux de précision de la reconnaissance correcte pour chaque tranche d'âge étaient : enfants = 99,6 %, adolescents = 72,7 % , adolescents = 68,1 %, personnes d'âge moyen = 70,7 %, personnes âgées = 93,8 %

Autrement dit, les utilisateurs ont réussi à différencier les images générées par différents groupes d’âge avec un degré de précision raisonnablement élevé.
Les références:
https://arxiv.org/abs/2307.08585
Suivez le compte public [Machine Learning and AI Generated Creation], des choses plus passionnantes vous attendent à lire
Une introduction simple à ControlNet, un algorithme de génération de peinture AIGC contrôlable !
Le GAN classique doit lire : StyleGAN
 Cliquez sur moi pour voir la série d'albums de GAN~ !
Cliquez sur moi pour voir la série d'albums de GAN~ !
Une tasse de thé au lait et devenez le pionnier de la vision AIGC+CV !
ECCV2022 | Résumé de quelques articles sur le Generative Adversarial Network GAN
CVPR 2022 | Plus de 25 directions, les 50 derniers articles du GAN
ICCV 2021 | Résumé de 35 articles thématiques du GAN
Plus de 110 articles ! Examen du document GAN le plus complet du CVPR 2021
Plus de 100 articles ! Examen du document GAN le plus complet du CVPR 2020
Déballage d'un nouveau GAN : représentation de découplage MixNMatch
StarGAN version 2 : génération d'images de diversité multi-domaines
Téléchargement ci-joint | "Apprentissage automatique explicable" version chinoise
Téléchargement ci-joint | "Pratique de l'algorithme d'apprentissage profond TensorFlow 2.0"
Téléchargement ci-joint | Partage de "Méthodes mathématiques en vision par ordinateur"
"Un examen des méthodes de détection des défauts de surface basées sur le Deep Learning"
"Un examen de la classification d'images à échantillon zéro : dix ans de progrès"
"Un examen de l'apprentissage sur quelques échantillons basé sur des réseaux de neurones profonds"
Le « Livre des Rites · Xue Ji » dit : Si vous étudiez seul sans amis, vous serez seul et ignorant.
Cliquez sur une tasse de thé au lait et devenez le pionnier de la vision AIGC+CV ! , rejoignez la planète de la création générée par l'IA et des connaissances en vision par ordinateur !