Annuaire d'articles
Préface
Lorsqu'il y a trop de CRUD, un certain état d'esprit se forme : les champs de données obtenus correspondent aux attributs de la classe d'entité un à un. Cela semble tout à fait satisfaisant et les choses doivent être faites selon les règles. Les champs du tableau correspondent-ils toujours aux attributs de la classe ?
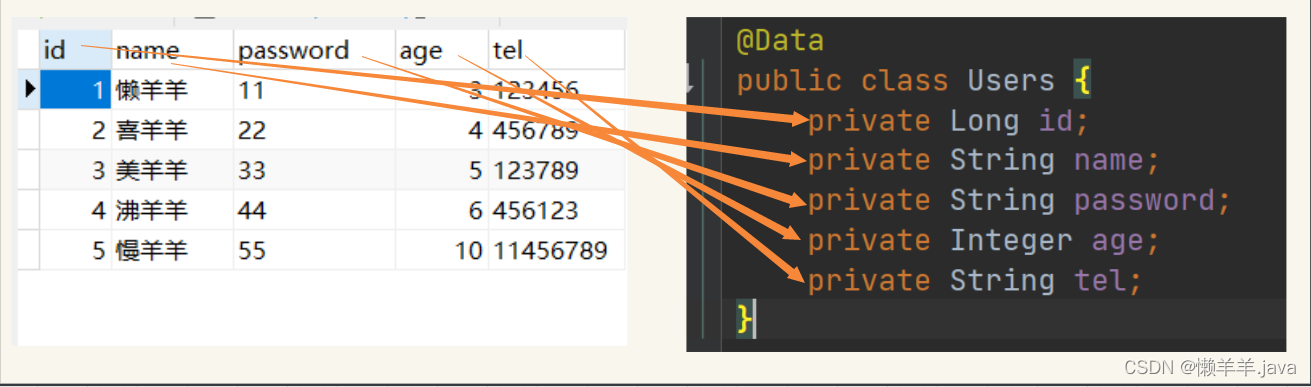
Ce qui précède est ce qu'on appelle la situation idéale, avec des champs et des attributs correspondant un à
un. Explorons le premier problème possible.
1. Les champs et les valeurs d'attribut sont différents
J'ai modifié les attributs de la classe d'entité pour voir quels résultats seraient rapportés lors de l'exécution d'une requête ordinaire.
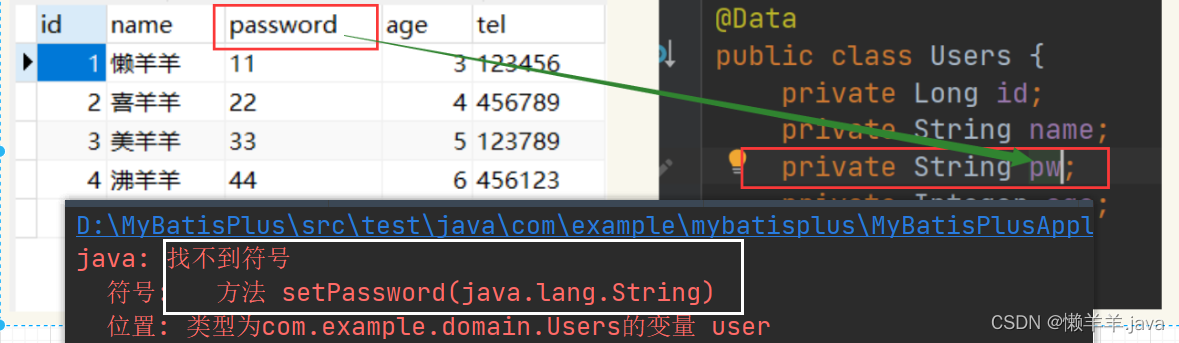
La requête a échoué !
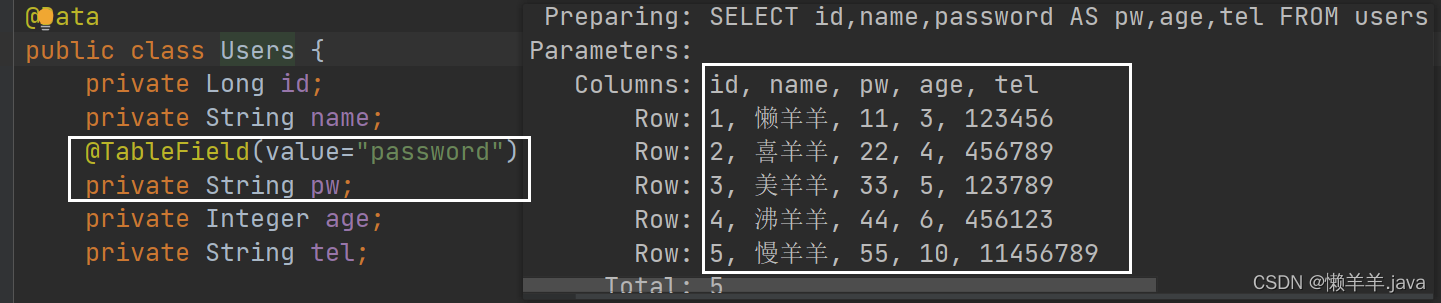
Par conséquent, lorsque les noms de colonnes de la table et les noms d'attributs de la classe de modèle sont incohérents, les données ne seront pas encapsulées dans l'objet de modèle. À ce stade, l'une des parties doit apporter des modifications. À ce stade, une annotation de MP nous a aidé à résoudre ce problème. MP
nous a donné Une annotation@TableField , qui peut être utilisée pour réaliser la relation de mappage entre le nom de l'attribut de classe de modèle et le nom de colonne de la table, comme ceci@TableField(value = "password")
2. Attributs qui n'existent pas dans le tableau
Lorsqu'un champ qui n'existe pas dans la table de la base de données apparaît dans la classe d'entité, l'instruction SQL générée interrogera le champ qui n'existe pas dans la base de données lors de la sélection. La solution spécifique utilise toujours des annotations, qui ont un attribut
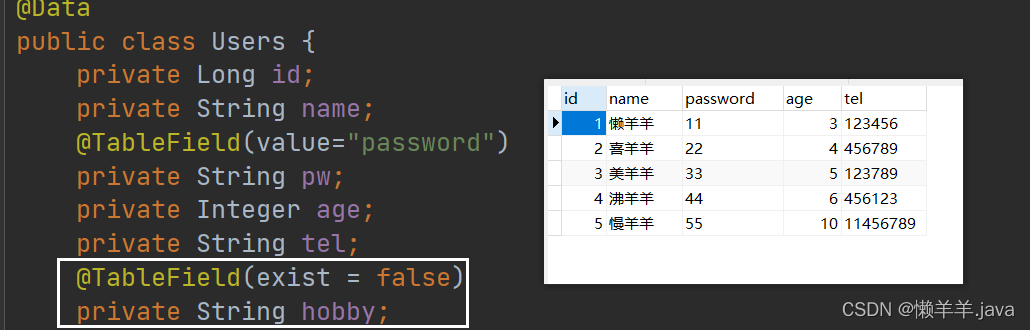
appelé , Définissez si le champ existe dans la table de base de données. S'il est défini sur false, il n'existe pas. Lors de la génération d'une requête d'instruction SQL, le champ ne sera plus interrogé.@TableFieldexist
3. Attributs qui n'existent pas dans le tableau
Après l'opération, certaines données sensibles peuvent être interrogées et renvoyées au front-end. À ce stade, nous devons limiter les champs qui ne doivent pas être interrogés par défaut. Selon le bon sens, les informations privées telles que les mots de passe ne doivent pas être interrogées ensemble. Comment pouvons-nous masquer ces champs ? ? Ou via l'annotation @TableField :
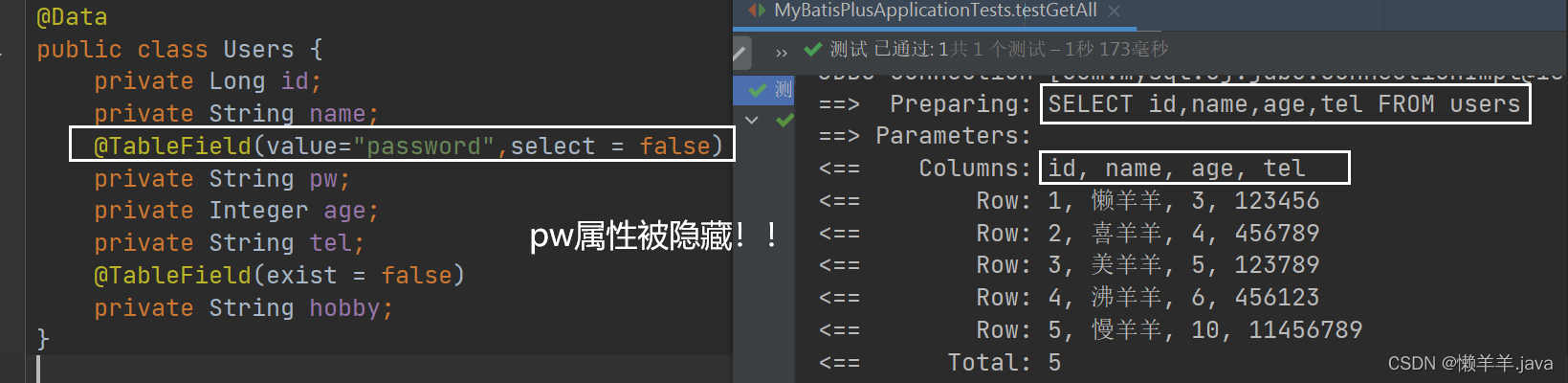
@TableField un des attributs de l'annotation est appeléselect. Cet attribut définit si la valeur du champ doit être interrogée par défaut. true (valeur par défaut) signifie que le champ est interrogé par défaut, et false signifie que le champ n'est pas interrogé par défaut.
| nom | @TableField |
|---|---|
| taper | Annotation de propriété |
| Emplacement | au-dessus de la définition de l'attribut de classe de modèle |
| effet | Définir la relation de champ dans la table de base de données correspondant à l'attribut actuel |
valeur (par défaut) : définit le nom du champ de la table de base de données.
exist : définit si l'attribut existe dans le champ de la table de base de données. La valeur par défaut est true. Cet attribut ne peut pas être combiné avec la valeur. Sélectionner :
définit si l'attribut participe à la requête. L'attribut n'est pas configuré avec le mappage select().
4. Le nom de la classe et le nom de la table ne correspondent pas
Je me souviens que Lazy Yangyang a résolu un bug il y a quelque temps :

en bref, le nom de classe de la classe d'entité n'était pas cohérent avec le nom de la table dans la base de données, ce qui empêchait MP d'être mappé et associé à la table . De façon inattendue, j'ai appris que je pouvais utiliser des annotations pour résoudre le problème plus tard :
MP fournit une autre annotation @TableNamepour définir la relation correspondante entre les tables et les classes d'entités :

De cette façon, je n'ai plus à écrire délibérément des classes d'entités en fonction des noms de tables !
| nom | @Nom de la table |
|---|---|
| taper | Annotation de classe |
| Emplacement | Au-dessus de la définition de la classe modèle |
| effet | Définir la classe actuelle correspondant à la relation table de base de données |
| Propriétés associées | valeur (par défaut) : définit le nom de la table de la base de données |
5. Stratégie d'auto-incrémentation de l'ID
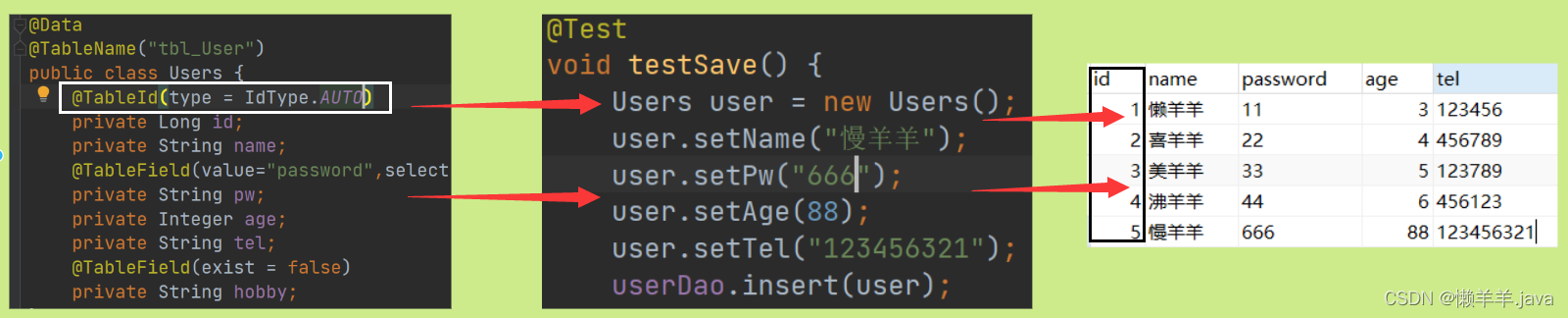
1.type = IdType.AUTO
Quand j'ai commencé à utiliser MP, j'ai écrit une méthode d'ajout, mais ce qui est étrange, c'est que l'ID de clé primaire des données ajoutées n'augmente pas séquentiellement, mais un nombre très étrange, comme ceci : une fois l'ajout réussi, l'ID de clé primaire

est une très longue chaîne de contenu. Ce que nous voulons de plus, c'est s'auto-incrémenter en fonction des champs de la table de la base de données, et différentes tables appliquent différentes stratégies de génération d'ID, telles que : log : auto-incrémentation (1, 2, 3, 4,. ..
)
Commande : Règles particulières (FQ77948AK3982)
Commande à emporter : Date région associée et autres informations (50 22 24765314 87 44)
Prenons l'exemple de l'auto-incrémentation : annotation @TableId
| nom | @TableId |
|---|---|
| taper | Annotation de propriété |
| Emplacement | Au-dessus de la définition d'attribut dans la classe de modèle utilisée pour représenter la clé primaire |
| effet | Définir la stratégie de génération de l'attribut de clé primaire dans la classe actuelle |
| Propriétés associées | valeur (par défaut) : définit le nom de la clé primaire du type de table de base de données : définit la stratégie de génération de l'attribut de clé primaire, la valeur est basée sur la valeur d'énumération de IdType |
Il existe de nombreuses stratégies dans la classe d'énumération idType :
@Getter
public enum IdType {
/**
* 数据库ID自增
* <p>该类型请确保数据库设置了 ID自增 否则无效</p>
*/
AUTO(0),
/**
* 该类型为未设置主键类型(注解里等于跟随全局,全局里约等于 INPUT)
*/
NONE(1),
/**
* 用户输入ID
* <p>该类型可以通过自己注册自动填充插件进行填充</p>
*/
INPUT(2),
/* 以下2种类型、只有当插入对象ID 为空,才自动填充。 */
/**
* 分配ID (主键类型为number或string),
* 默认实现类 {@link com.baomidou.mybatisplus.core.incrementer.DefaultIdentifierGenerator}(雪花算法)
*
* @since 3.3.0
*/
ASSIGN_ID(3),
/**
* 分配UUID (主键类型为 string)
* 默认实现类 {@link com.baomidou.mybatisplus.core.incrementer.DefaultIdentifierGenerator}(UUID.replace("-",""))
*/
ASSIGN_UUID(4);
private final int key;
IdType(int key) {
this.key = key;
}
}
Examinons ensuite une autre stratégie
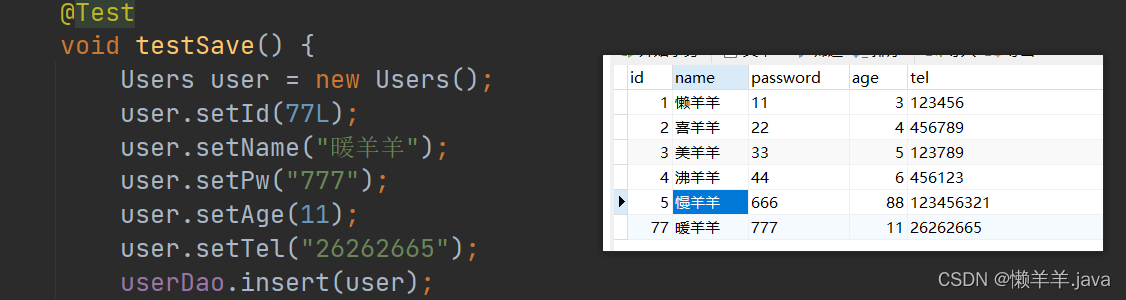
2.type = IdType.INPUT
Remplir automatiquement en vous inscrivant
Lorsque vous désactivez l'incrémentation automatique dans la base de données et que vous utilisez cette stratégie pour effectuer une opération d'ajout :
@TableId(type = IdType.INPUT)
@Test
void testSave() {
Users user = new Users();
user.setName("暖羊羊");
user.setPw("777");
user.setAge(11);
user.setTel("26262665");
userDao.insert(user);
}

Évidemment, les données ne peuvent pas être ajoutées. L'identifiant apparaît dans le SQL généré mais n'est pas transmis à la méthode, nous devons donc le remplir nous-mêmes :
@Test
void testSave() {
Users user = new Users();
user.setId(77L);
user.setName("暖羊羊");
user.setPw("777");
user.setAge(11);
user.setTel("26262665");
userDao.insert(user);
}
Enfin, l'ajout
| AUCUN | Ne pas définir de stratégie de génération d'identifiant |
|---|---|
| SAISIR | L'utilisateur saisit manuellement son identifiant |
| ASSIGN_ID | L'algorithme Snowflake génère un ID (compatible avec les types numériques et chaînes) |
| ASSIGN_UUID | Utilisation de l'algorithme de génération d'UUID comme stratégie de génération d'identifiant |
J'ai également examiné les avantages et les inconvénients de diverses stratégies :
- NONE : Aucune stratégie de génération d'identifiant n'est définie. MP n'est pas généré automatiquement et est approximativement égal à INPUT. Par conséquent, les deux méthodes nécessitent que les utilisateurs le définissent manuellement. Cependant, le premier problème avec le paramètre manuel est qu'il est facile pour le même ID de provoquer un conflit de clé primaire. Afin de garantir que la clé primaire n'entre pas en conflit. Cela nécessite beaucoup de jugements et est plus compliqué à mettre en œuvre.
- AUTO : l'ID de base de données augmente automatiquement. Cette stratégie convient lorsqu'il n'y a qu'un seul serveur de base de données. Elle ne peut pas être utilisée comme ID distribué.
- ASSIGN_UUID : peut être utilisé dans des situations distribuées et peut garantir l'unicité, mais la clé primaire générée est une chaîne de 32 bits, qui est trop longue, prend de l'espace et ne peut pas être triée, et les performances de la requête sont également lentes.
- ASSIGN_ID : peut être utilisé dans une situation distribuée. Il génère des nombres de type long, qui peuvent être triés et ont des performances élevées. Cependant, la stratégie générée est liée à l'heure du serveur. Si l'heure du système est modifiée, cela peut conduire à une duplication de l'heure principale. clés.
3. Introduction à l'algorithme de flocon de neige
Utilisez un numéro de 64 bits comme identifiant unique au monde. Il est largement utilisé dans les systèmes distribués et l'ID introduit des horodatages. Fondamentalement, l' algorithme de flocon de neige auto-croissant est un binaire de 64 bits. Le bit 1 est le bit de signe, qui est le bit le plus élevé, qui est toujours 0. Cela n'a aucune signification.
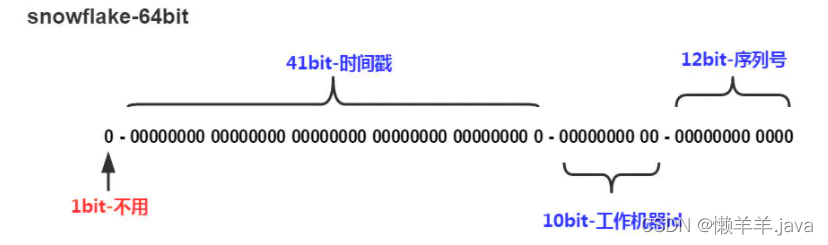
, car si le complément à deux du seul ordinateur est un nombre négatif, 0 est un nombre positif. 41 bits est l'horodatage, spécifique aux millisecondes. Le binaire de 41 bits peut être utilisé pendant 69 ans. Comme le temps augmente théoriquement pour toujours, il est possible de trier en fonction de cela.
4. Unifier la stratégie de clé primaire
Dans les projets futurs, afin de ne pas configurer séparément la stratégie de clé primaire de chaque classe d'entité, nous pouvons définir la stratégie progressive de manière unifiée, comme ceci :
mybatis-plus:
global-config:
db-config:
id-type: assign_id
De cette façon, la configuration peut être unifiée partout !