Bref aperçu : cet article explique les avantages et les inconvénients du choix d'un plus petit nombre de nœuds plus grands par rapport à un plus grand nombre de nœuds plus petits dans un cluster Kubernetes.
Lors de la création d'un cluster Kubernetes, l'une des premières questions est : « Quel type de nœuds de travail dois-je utiliser et de combien ai-je besoin ? »
Si vous construisez un cluster local, devriez-vous acheter des serveurs hautes performances de la génération précédente ou utiliser quelques anciennes machines inactives dans le centre de données ?
Ou, si vous utilisez un service Kubernetes géré comme Google Kubernetes Engine (GKE), devriez-vous choisir huit instances n1-standard-1 ou deux instances n1-standard-4 pour obtenir la puissance de calcul requise ?
Table des matières
-
capacité du cluster
-
Ressources réservées dans les nœuds de travail Kubernetes
-
Allocation des ressources et efficacité entre les nœuds de travail
-
Elasticité et réplication
-
Delta et délai de livraison étendus
-
Extraire l'image du conteneur
-
Kubelet et extension de l'API Kubernetes
-
Limites des nœuds et des clusters
-
stockage
-
Sommaire et conclusion
capacité du cluster
De manière générale, un cluster Kubernetes peut être considéré comme faisant abstraction d'un groupe de nœuds indépendants dans un grand « super nœud ». La puissance de calcul totale de ce super nœud (y compris le processeur et la mémoire) est la somme des capacités de tous les nœuds composants.
Il existe différentes manières d'y parvenir : par exemple, supposons qu'un cluster avec une puissance de calcul totale de 8 cœurs de processeur et 32 Go de mémoire soit requis. Voici deux modèles de conception de cluster possibles : divisé en deux machines ou quatre machines.
Petits et grands nœuds dans un cluster Kubernetes | Les deux options aboutissent à un cluster de même capacité. La sélection de gauche utilise quatre nœuds plus petits, tandis que la sélection de droite utilise deux nœuds plus grands.
La question est : quelle méthode est la meilleure ? ---Pour prendre des décisions éclairées, examinons de plus près la façon dont les ressources sont allouées entre les nœuds de travail.
Ressources réservées dans les nœuds de travail Kubernetes
Chaque nœud de travail d'un cluster Kubernetes est une unité informatique exécutant un kubelet (agent Kubernetes).
Le kubelet est un binaire qui se connecte au plan de contrôle et est utilisé pour synchroniser l'état actuel du nœud avec l'état du cluster.
Par exemple, lorsque le planificateur kubernetes attribue un pod à un nœud spécifique, il n'envoie pas de message directement au kubelet. Au lieu de cela, il crée un objet Binding et le stocke dans etcd.
Le kubelet vérifie périodiquement l'état du cluster. Une fois qu'il remarque un pod nouvellement attribué à son nœud, il commence à télécharger la spécification du pod et à la créer.
Les Kubelets sont généralement déployés en tant que services SystemD et exécutés dans le cadre du système d'exploitation.
kubelet, SystemDet les systèmes d'exploitation nécessitent des ressources, notamment du processeur et de la mémoire, pour fonctionner correctement.
Par conséquent, les ressources de tous les nœuds de travail ne sont pas utilisées uniquement pour exécuter des pods.
Les ressources CPU et mémoire sont généralement allouées comme suit :
système opérateur. Kubelet. Gousses. Seuil d’expulsion.
Allocation de ressources dans les nœuds Kubernetes
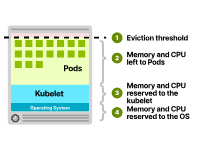
Vous vous demandez peut-être quelles ressources sont allouées à ces composants. Bien que les configurations spécifiques puissent varier, l'allocation du processeur suit généralement le modèle suivant :
6% du premier noyau. 1 % des cœurs suivants (jusqu'à 2 cœurs). 0,5% des deux cœurs suivants (jusqu'à 4 cœurs). 0,25 % pour tout cœur comportant plus de quatre cœurs. L'allocation de mémoire peut être la suivante :
Les machines avec moins de 1 Go de mémoire se voient attribuer 255 Mo de mémoire. 25 % des premiers 4 Go de mémoire. 20 % des 4 Go de mémoire suivants (jusqu'à 8 Go). 10 % des 8 Go de mémoire suivants (jusqu'à 16 Go). 6 % des 112 Go de mémoire suivants (jusqu'à 128 Go). 2 % de toute mémoire supérieure à 128 Go. Enfin, le seuil d'expulsion reste généralement à 100 Mo.
Seuil d'expulsion Le seuil d'expulsion représente un seuil d'utilisation de la mémoire. Si un nœud dépasse ce seuil, le kubelet commencera à expulser les pods car le nœud actuel manque de mémoire.
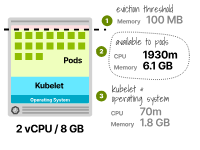
Prenons une instance avec 8 Go de mémoire et 2 processeurs virtuels. La répartition des ressources est la suivante :
Processeur virtuel de 70 millicore et 1,8 Go pour le kubelet et le système d'exploitation (généralement emballés ensemble). 100 Mo sont réservés au seuil d'expulsion. Les 6,1 Go de mémoire restants et 1 930 millicores peuvent être alloués aux pods. Seulement 75 % de la mémoire totale est utilisée pour exécuter la charge de travail.
Mais cela ne s'arrête pas là.
Vos nœuds peuvent avoir besoin de certains pods (tels que DaemonSets) exécutés sur chaque nœud pour garantir un fonctionnement correct, et ces pods consommeront également de la mémoire et des ressources CPU.
Par exemple, Kube-proxy, proxy de journalisation tel que Fluentd ou Fluent Bit, NodeLocal DNSCache ou pilote CSI, etc.
Il s'agit d'un coût fixe que vous devez payer quelle que soit la taille du nœud.
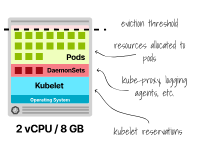
Allocation de ressources dans les nœuds Kubernetes avec DaemonSets Dans cet esprit, examinons les avantages et les inconvénients des deux approches diamétralement opposées du « plus petit nombre de nœuds plus grands » et du « plus grand nombre de nœuds plus petits ».
Notez que « nœud » dans cet article fait toujours référence aux nœuds de travail. Les choix concernant le nombre et la taille des nœuds du plan de contrôle sont un tout autre sujet.
Allocation des ressources et efficacité entre les nœuds de travail
À mesure que des instances plus grandes sont utilisées, les ressources réservées par le kubelet diminuent.
Regardons deux cas extrêmes.
Vous souhaitez déployer sept réplicas d'une application qui demande 0,3 vCPU et 2 Go de mémoire.
Dans le premier cas, vous utiliseriez un seul nœud de travail pour déployer toutes les répliques. Dans le second cas, vous déployez un réplica sur chaque nœud. Pour plus de simplicité, nous supposons qu’aucun DaemonSets n’est exécuté sur ces nœuds.
Les ressources totales requises pour sept réplicas sont de 2,1 vCPU et 14 Go de mémoire (soit 7 x 300 m = 2,1 vCPU et 7 x 2 Go = 14 Go).
Une instance dotée de 4 processeurs virtuels et de 16 Go de mémoire serait-elle capable d'exécuter ces charges de travail ?
Calculons la réservation CPU :
第一个核心的6% = 60m +
第二个核心的1% = 10m +
剩余核心的0.5% = 10m
总计 = 80m
Le processeur disponible pour exécuter le pod est de 3,9 vCPU (c'est-à-dire 4 000 m - 80 m) - plus que suffisant.
Jetons ensuite un œil à la mémoire réservée par kubelet :
前4GB内存的25% = 1GB
接下来的4GB内存的20% = 0.8GB
接下来的8GB内存的10% = 0.8GB
总计 = 2.8GB
La mémoire totale allouée au Pod est de 16 Go - (2,8 Go + 0,1 Go) - 0,1 Go prend ici en compte le seuil d'expulsion de 100 Mo.
Enfin, le Pod peut utiliser jusqu'à 13,1 Go de mémoire.
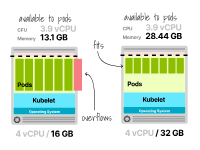
Allocation de ressources dans le nœud Kubernetes avec 2 vCPU et 16 Go de mémoire
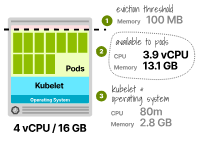
Malheureusement, cela ne suffit pas (c'est-à-dire que 7 réplicas nécessitent 14 Go de mémoire, mais vous ne disposez que de 13,1 Go) et vous devez fournir aux unités de calcul plus de mémoire pour déployer ces charges de travail.
Si vous utilisez un fournisseur de cloud, la prochaine unité de calcul incrémentielle disponible est de 4 vCPU et 32 Go de mémoire.
Un nœud avec 2 vCPU et 16 Go de mémoire ne suffit pas pour exécuter sept réplicas
Très bien!
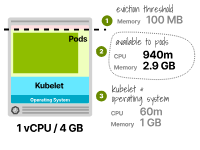
Examinons ensuite un autre scénario dans lequel nous essayons de trouver la plus petite instance pouvant tenir sur une réplique avec une demande de 0,3 vCPU et 2 Go de mémoire.
Nous avons essayé d'utiliser un type d'instance avec 1 vCPU et 4 Go de mémoire.
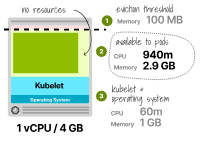
Le processeur réservé est de 6 %, soit 60 m au total, et le processeur disponible pour les pods est de 940 m.
Puisque l’application ne nécessite que 300 Mo de CPU, cela suffit.
La mémoire réservée par le kubelet est de 25 % ou 1 Go, plus un seuil d'expulsion supplémentaire de 0,1 Go.
La mémoire totale disponible pour le pod est de 2,9 Go ; puisque l'application ne nécessite que 2 Go, cette valeur est suffisante.
merveilleux!
Allocation de ressources dans le nœud Kubernetes avec 2 vCPU et 16 Go de mémoire Comparons maintenant ces deux configurations.
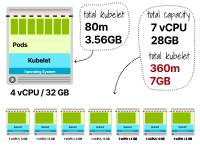
Les ressources totales du premier cluster ne représentent qu'un seul nœud : 4 vCPU et 32 Go.
Le deuxième cluster comporte sept instances, chacune avec 1 vCPU et 4 Go de mémoire (pour un total de 7 vCPU et 28 Go de mémoire).
Dans le premier exemple, 2,9 Go de mémoire et 80 Mo de CPU sont réservés à Kubernetes.
Dans le deuxième exemple, 7,7 Go (1,1 Go x 7 instances) de mémoire et 360 m (60 m x 7 instances) de CPU sont réservés.
Vous pouvez déjà remarquer que les ressources sont utilisées plus efficacement lors de la configuration de nœuds plus grands.
Comparez l'allocation des ressources entre un cluster à nœud unique et un cluster à nœuds multiples
Mais il y a plus.
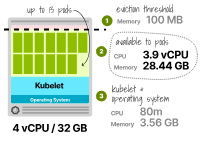
Les instances plus grandes ont encore de la place pour exécuter davantage de réplicas, mais combien ?
La mémoire réservée est de 3,66 Go (3,56 Go pour kubelet + seuil d'expulsion de 0,1 Go), et la mémoire totale disponible pour les Pods est de 28,44 Go. Le processeur réservé est toujours de 80 m et les pods peuvent en utiliser 3 920 m. À ce stade, vous pouvez trouver le nombre maximum de répliques pour la mémoire et le processeur en :
Total CPU 3920 /
Pod CPU 300
------------------
Max Pod 13.1
Vous pouvez répéter le calcul pour la mémoire :
总内存 28.44 /
Pod内存 2
最大Pod 14.22
Les chiffres ci-dessus montrent qu'en cas de manque de mémoire, il est possible de manquer de mémoire avant que le processeur puisse héberger jusqu'à 13 pods avec 4 processeurs virtuels et 32 Go de nœuds de travail.
Calcul de la capacité du pod pour 2 processeurs virtuels et des nœuds de travail de 32 Go Alors, qu'en est-il du deuxième cas ?
Y a-t-il de la place pour une expansion ?
Pas vraiment.
Bien que ces instances disposent encore de plus de processeur, elles ne disposent que de 0,9 Go de mémoire disponible après le déploiement du premier pod.
Calculer la capacité du pod pour 1 vCPU et 4 Go de nœud de travail En résumé, non seulement les nœuds plus grands utilisent mieux les ressources, mais ils minimisent également la fragmentation des ressources et augmentent l'efficacité.
Cela signifie-t-il que vous devez toujours fournir des instances plus grandes ?
Regardons un autre cas extrême : que se passe-t-il lorsqu'un nœud est perdu de manière inattendue ?
Elasticité et réplication
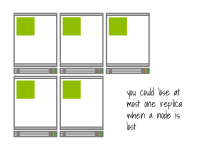
Un plus petit nombre de nœuds peut limiter l’efficacité de la réplication de votre application.
Par exemple, si vous disposez d'une application hautement disponible composée de 5 réplicas, mais seulement de deux nœuds, le degré de réplication effectif sera réduit à 2.
En effet, ces cinq réplicas ne peuvent être distribués que sur deux nœuds et si l'un des nœuds tombe en panne, plusieurs réplicas peuvent être perdus en même temps.
Un cluster avec deux nœuds et cinq réplicas a un facteur de réplication de deux

D'un autre côté, si vous disposez d'au moins cinq nœuds, chaque réplique peut s'exécuter sur un nœud distinct, et la défaillance d'un seul nœud entraînera l'échec d'au plus une réplique.
Par conséquent, si vous avez des exigences de haute disponibilité, vous devrez peut-être disposer d'un certain nombre de nœuds dans le cluster.
Un cluster comportant cinq nœuds et cinq réplicas a un facteur de réplication de 5. Vous devez également tenir compte de la taille des nœuds.
Lorsque des nœuds plus volumineux sont perdus, certaines répliques sont finalement reprogrammées vers d'autres nœuds.
Si le nœud est petit et n'héberge qu'une petite charge de travail, le planificateur ne réaffectera que quelques pods.
Même s'il est peu probable que vous rencontriez une limitation dans le planificateur, le redéploiement de nombreux réplicas peut déclencher l'autoscaler du cluster.
Et selon votre configuration, cela peut entraîner des ralentissements supplémentaires.
Voyons pourquoi.
Delta et délai de livraison étendus
Vous pouvez faire évoluer les applications déployées sur Kubernetes à l'aide d'une combinaison de scalers horizontaux (c'est-à-dire en augmentant le nombre de réplicas) et d'autoscalers de cluster (c'est-à-dire en augmentant le nombre de nœuds).
En supposant que votre cluster atteigne sa capacité totale, comment la taille des nœuds affecte-t-elle l'autoscaling ?
Tout d’abord, il faut savoir que lorsque l’autoscaler du cluster déclenche l’autoscaling, il ne prend pas en compte la mémoire ni le CPU disponible.
En d’autres termes, l’utilisation globale du cluster ne déclenche pas l’autoscaler du cluster.
À l'inverse, lorsqu'un pod ne peut pas être planifié en raison de ressources insuffisantes, l'autoscaler du cluster crée davantage de nœuds.
À ce stade, l'autoscaler appelle l'API du fournisseur de cloud pour provisionner davantage de nœuds sur le cluster.
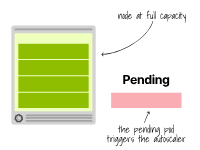
L'autoscaler de cluster fournit de nouveaux nœuds lorsque les pods sont suspendus en raison de ressources insuffisantes.
L'autoscaler de cluster fournit de nouveaux nœuds lorsque les pods sont suspendus en raison de ressources insuffisantes.

Malheureusement, la configuration des nœuds est généralement lente.
La création d'une nouvelle machine virtuelle peut prendre plusieurs minutes.
Le délai de provisionnement changera-t-il si je provisionne une instance plus grande ou plus petite ?
Non, normalement le temps de provisionnement est constant quelle que soit la taille de l'instance.
De plus, l'autoscaler de cluster ne se limite pas à ajouter un nœud à la fois ; il peut ajouter plusieurs nœuds à la fois.
Regardons un exemple.
Il existe deux clusters :
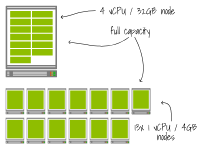
Le premier cluster possède un seul nœud avec 4 vCPU et 32 Go. Le deuxième cluster comporte 13 nœuds avec 1 vCPU et 4 Go. Une application avec 0,3 vCPU et 2 Go de mémoire est déployée dans un cluster et mise à l'échelle jusqu'à 13 réplicas.
Les deux installations ont atteint leur capacité totale
Que se passe-t-il lorsque le déploiement s'étend à 15 réplicas (c'est-à-dire deux réplicas supplémentaires) ?
Dans les deux clusters, l'autoscaler de cluster détecte que des pods supplémentaires ne peuvent pas être planifiés en raison de ressources insuffisantes et configure les éléments suivants :
Pour le premier cluster, ajoutez un nœud supplémentaire avec 4 vCPU et 32 Go de mémoire. Pour le deuxième cluster, ajoutez deux nœuds supplémentaires avec 1 vCPU et 4 Go de mémoire. Puisqu'il n'y a pas de différence de temps lors du provisionnement des ressources pour une grande ou une petite instance, les nœuds seront disponibles en même temps dans les deux cas.
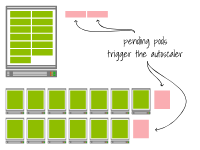
Cependant, voyez-vous une autre différence ?
Le premier cluster peut accueillir 11 pods supplémentaires puisque la capacité totale est de 13.
En revanche, le deuxième cluster a quand même atteint sa capacité maximale.
Vous pouvez considérer des incréments plus petits comme plus efficaces et moins chers, car vous n’ajoutez que les pièces dont vous avez besoin.
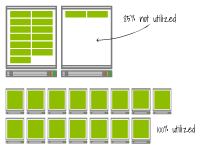
Mais observons ce qui se passe lorsque vous redimensionnez le déploiement, cette fois à 17 réplicas (soit une augmentation de deux réplicas).
Le premier cluster crée deux pods supplémentaires sur les nœuds existants. Et le deuxième cluster a atteint sa limite de capacité. Le pod est dans un état en attente, déclenchant l'autoscaler du cluster. À terme, il y aura deux nœuds de travail supplémentaires.
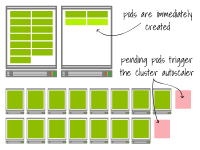
Dans le premier cluster, la mise à l’échelle a été presque instantanée.
Dans le deuxième cluster, vous devez attendre que les nœuds soient configurés avant que les Pods puissent commencer à fournir des services.
En d’autres termes, dans le premier cas, la mise à l’échelle est plus rapide, tandis que dans le second cas, elle prend plus de temps.
En règle générale, étant donné que les temps de configuration sont de l'ordre de quelques minutes, vous devez soigneusement réfléchir au moment de déclencher l'autoscaler du cluster pour éviter d'entraîner des temps d'attente de pod plus longs.
En d’autres termes, si vous acceptez de sous-utiliser (potentiellement) vos ressources, vous pouvez évoluer plus rapidement en utilisant des nœuds plus gros.
Mais cela ne s'arrête pas là.
L'extraction d'images de conteneur affecte également la rapidité avec laquelle vous pouvez faire évoluer votre charge de travail, par rapport au nombre de nœuds dans votre cluster.
Extraire l'image du conteneur
Lorsqu'un Pod est créé dans Kubernetes, sa définition est stockée dans etcd.
Le travail du kubelet est de détecter le nœud auquel le Pod est affecté et de le créer.
Le kubelet va :
-
Téléchargez les définitions à partir du plan de contrôle.
-
Appelez la Container Runtime Interface (CRI) pour créer le bac à sable d'un pod. CRI appelle la Container Network Interface (CNI) pour connecter le Pod au réseau.
-
Appelez l'interface de stockage de conteneurs (CSI) pour monter n'importe quel volume de conteneur.
À la fin de ces étapes, le pod existe déjà et le kubelet peut continuer à vérifier les sondes d'activité et de préparation et mettre à jour le plan de contrôle pour refléter l'état du nouveau pod.
Une chose à noter concernant l'interface de Kubelet avec CRI, CSI et CNI est que lorsque CRI crée un conteneur dans un pod, il doit d'abord télécharger l'image du conteneur.
C'est bien sûr le cas si l'image du conteneur sur le nœud actuel n'est pas mise en cache.
Voyons comment cela affecte la mise à l'échelle des deux clusters suivants :
Le premier cluster possède un seul nœud avec 4 vCPU et 32 Go. Le deuxième cluster comporte 13 nœuds avec 1 vCPU et 4 Go. Déployons une application utilisant une image de conteneur basée sur OpenJDK utilisant 0,3 vCPU et 2 Go de mémoire avec 13 répliques d'une taille d'image de conteneur de 1 Go (seule la taille de l'image de base est de 775 Mo).
Qu’arrive-t-il à ces deux clusters ?
Dans le premier cluster, le runtime du conteneur télécharge l’image une seule fois et exécute 13 copies. Dans le deuxième cluster, chaque environnement d'exécution de conteneur télécharge et exécute l'image. Dans le premier scénario, seule une image de 1 Go doit être téléchargée.
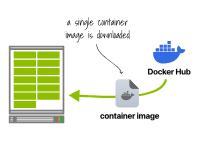
Le runtime du conteneur télécharge l'image du conteneur une fois et exécute 13 copies. Cependant, dans le deuxième scénario, vous devez télécharger l'image du conteneur de 13 Go.
Le deuxième cluster est plus lent que le premier à créer des réplicas en raison du temps nécessaire au téléchargement.
De plus, il utilise plus de bande passante et effectue plus de requêtes (c'est-à-dire au moins une requête par couche de mise en miroir, 13 au total), ce qui le rend plus vulnérable aux pannes de réseau.
Chacun des 13 environnements d'exécution de conteneur téléchargera une image. Notez que ce problème est étroitement lié à l'autoscaler du cluster.
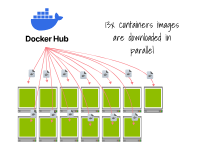
Si vos nœuds sont plus petits :
-
L'autoscaler de cluster configure plusieurs nœuds simultanément.
-
Une fois prêt, chaque nœud commence à télécharger l'image du conteneur.
-
Enfin, le Pod est créé.
Lorsque vous configurez un nœud plus grand, l'image du conteneur est probablement déjà mise en cache sur le nœud et les pods peuvent commencer à s'exécuter immédiatement.
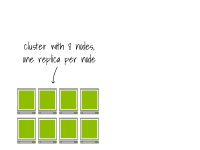
Imaginez un cluster avec 8 nœuds, une réplique sur chaque nœud.
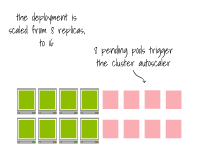
Finalement, le Pod sera créé sur le nœud.
Imaginez un cluster avec 8 nœuds, une réplique sur chaque nœud.
Le cluster est déjà plein ; l'extension du nombre de réplicas à 16 déclenche l'autoscaler du cluster.
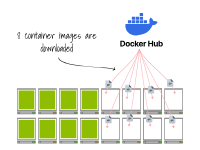
Une fois le nœud configuré, le runtime du conteneur télécharge l'image du conteneur.
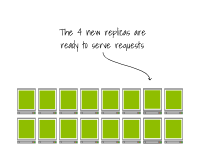
Finalement, les pods sont créés sur les nœuds.
Alors, devriez-vous toujours configurer des nœuds plus gros ?
Pas nécessairement.
Vous pouvez éviter aux nœuds de télécharger la même image de conteneur via un proxy de registre de conteneurs.
Dans ce cas, l'image sera toujours téléchargée, mais depuis le registre local du réseau actuel.
Ou vous pouvez utiliser quelque chose comme Spegel pour réchauffer le cache du nœud.
Avec Spegel, les nœuds sont des pairs qui peuvent annoncer et partager des couches d'images de conteneurs.
Dans ce cas, l'image du conteneur est téléchargée depuis les autres nœuds de travail et le Pod peut être démarré presque immédiatement.
Cependant, la bande passante du conteneur n’est pas la seule bande passante que vous devez contrôler.
Extension de l'API Kubelet et Kubernetes
Le kubelet est conçu pour obtenir des informations du plan de contrôle.
Par conséquent, à intervalles réguliers, le kubelet envoie des requêtes à l'API Kubernetes pour vérifier l'état du cluster.
Mais l'avion de contrôle n'envoie-t-il pas des instructions au kubelet ?
Les modèles Pull sont plus faciles à mettre à l’échelle car :
-
Le plan de contrôle n'a pas besoin de transmettre des messages à chaque nœud de travail.
-
Les nœuds peuvent interroger indépendamment le serveur API à leur propre vitesse.
-
Le plan de contrôle n’a pas besoin de maintenir la connexion au kubelet ouverte.
Notez qu'il existe des exceptions notables. Par exemple, des commandes telles que
kubectl logsetkubectl execnécessitent la connexion du plan de contrôlekubelet(c'est-à-dire des modèles push).
Mais Kubelet ne sert pas uniquement à interroger des informations.
Il transmet également des informations au nœud maître.
Par exemple, le kubelet signale l'état des nœuds au cluster toutes les dix secondes.
De plus, le kubelet informe le plan de contrôle lorsque la préparation des sondes échoue (et les points de terminaison du pod doivent être supprimés du service).
Et kubelet maintiendra le plan de contrôle à jour grâce aux métriques du conteneur.
En d'autres termes, le kubelet maintient l'état requis pour que le nœud fonctionne correctement en émettant des requêtes depuis (c'est-à-dire vers et depuis le plan de contrôle).
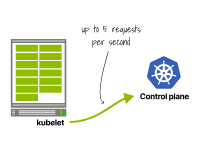
Dans Kubernetes 1.26 et versions antérieures, un kubelet pouvait émettre jusqu'à 5 requêtes par seconde (cette limite a été assouplie dans Kubernetes >1.27).
Donc, en supposant que votre kubelet fonctionne à sa capacité maximale (c'est-à-dire 5 requêtes par seconde), que se passe-t-il lorsque vous exécutez plusieurs nœuds plus petits plutôt qu'un seul grand nœud ?
Regardons nos deux clusters :
-
Le premier cluster possède un seul nœud avec 4 vCPU et 32 Go.
-
Le deuxième cluster comporte 13 nœuds avec 1 vCPU et 4 Go.
-
Le premier cluster génère 5 requêtes par seconde.
Un kubelet effectue 5 requêtes par seconde
Le deuxième cluster effectue 65 requêtes par seconde (soit 13 x 5).
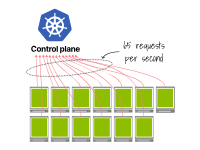
13 kubelets émettent chacun 5 requêtes par seconde
Lorsque vous exécutez un cluster avec de nombreux nœuds plus petits, vous devez faire évoluer votre serveur API pour gérer des requêtes plus fréquentes.
À son tour, cela signifie souvent exécuter le plan de contrôle sur une instance plus grande ou exécuter plusieurs plans de contrôle.
Limites des nœuds et des clusters
Y a-t-il une limite au nombre de nœuds dans un cluster Kubernetes ?
Kubernetes est conçu pour prendre en charge jusqu'à 5 000 nœuds.
Cependant, il ne s'agit pas d'une limite stricte, comme l'a démontré l'équipe de Google, permettant d'exécuter un cluster GKE sur 15 000 nœuds.
Pour la plupart des cas d'utilisation, 5 000 nœuds représentent un nombre important et ne seront probablement pas un facteur dans votre décision d'opter pour des nœuds plus grands ou plus petits.
À l’inverse, le nombre maximum de pods que vous pouvez exécuter dans un nœud peut vous amener à repenser votre architecture de cluster.
Alors, combien de pods pouvez-vous exécuter dans un nœud Kubernetes ?
La plupart des fournisseurs de cloud vous permettent d'exécuter 110 à 250 pods par nœud.
Si vous configurez le cluster vous-même, la valeur par défaut est 110.
Dans la plupart des cas, ce nombre ne représente pas une limite du kubelet, mais la tolérance du fournisseur de cloud concernant le risque de nouvelle réservation d'adresses IP.
Pour comprendre ce que cela signifie, prenons du recul et regardons comment les réseaux de clusters sont construits.
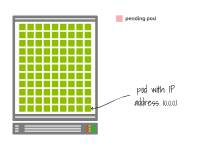
Dans la plupart des cas, chaque nœud de travail se voit attribuer un sous-réseau avec 256 adresses (par exemple 10.0.1.0/24).
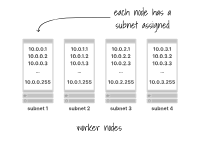
Chaque nœud de travail se voit attribuer un sous-réseau
Deux d'entre eux sont limités, vous pouvez en utiliser 254 pour exécuter vos Pods.
Considérez ce scénario dans lequel il y a 254 pods sur le même nœud.
Vous avez créé un pod supplémentaire, mais avez épuisé les adresses IP disponibles, il reste en attente.
Pour résoudre ce problème, vous décidez de réduire le nombre de réplicas à 253.
Alors, le Pod suspendu sera-t-il créé dans le cluster ?
Probablement pas.
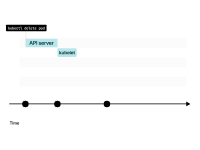
Lorsque vous supprimez un pod, son statut passe à En cours de terminaison.
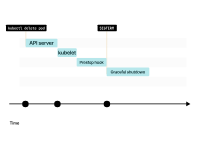
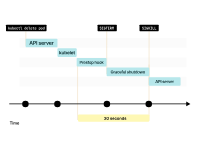
Le kubelet envoie le signal SIGTERM au pod (et appelle le hook de cycle de vie preStop (le cas échéant)) et attend que le conteneur s'arrête correctement.
Si le conteneur ne se termine pas dans les 30 secondes, kubelet enverra un signal SIGKILL au conteneur et forcera la fin du processus.
Pendant ce temps, le Pod n'a toujours pas divulgué l'adresse IP et le trafic peut toujours l'atteindre.
Lorsque le Pod est finalement supprimé, l'adresse IP est libérée.
Le kubelet informe le plan de contrôle que le Pod a été supprimé avec succès. L'adresse IP a enfin été dévoilée.
Imaginez que votre nœud utilise toutes les adresses IP disponibles.
Lorsqu'un Pod est supprimé, le kubelet est informé du changement.
Si le Pod dispose d’un hook preStop, il sera appelé en premier. Ensuite, le kubelet enverra le signal SIGTERM au conteneur.
Par défaut, les processus disposent de 30 secondes pour se terminer, y compris les hooks preStop. Si le processus ne se termine pas avant cela, kubelet enverra le signal SIGKILL pour terminer de force le processus.
Le kubelet informera le plan de contrôle que le Pod a été supprimé avec succès. L'adresse IP a finalement été divulguée.
Lorsqu'un Pod est supprimé, l'adresse IP n'est pas publiée immédiatement. Vous devez attendre un arrêt progressif.
Est-ce une bonne idée?
Eh bien, il n’y a pas d’autres adresses IP disponibles – vous n’avez donc pas le choix.
Imaginez que votre nœud utilise toutes les adresses IP disponibles.

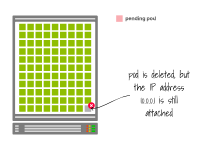
Une fois le Pod supprimé, l’adresse IP peut être réutilisée.
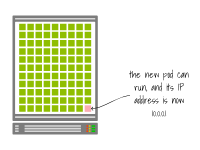
Le kubelet informe le plan de contrôle que le Pod a été supprimé avec succès. L'adresse IP a enfin été dévoilée.
À ce stade, le pod en attente peut être créé et se voir attribuer la même adresse IP que le précédent.
Imaginez que votre nœud utilise toutes les adresses IP disponibles.
Page suivante
Quelles seront les conséquences ?
Vous souvenez-vous que nous avons mentionné que les pods devaient s'arrêter correctement et traiter toutes les demandes en attente ?
Eh bien, si un pod est interrompu brusquement (c'est-à-dire sans arrêt progressif) et que l'adresse IP est immédiatement attribuée à un autre pod, alors toutes les applications existantes et les composants Kubernetes peuvent toujours ignorer le changement.
Le contrôleur d'entrée achemine le trafic vers une adresse IP.
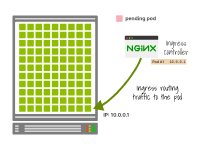
Si une adresse IP est récupérée et utilisée par un nouveau pod sans attendre un arrêt progressif, le contrôleur d'entrée peut toujours acheminer le trafic vers cette adresse IP.
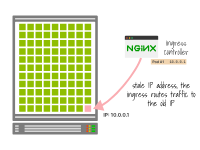
Par conséquent, une partie du trafic existant peut être envoyée de manière incorrecte au nouveau pod, car il possède la même adresse IP que l'ancien pod.
Pour éviter ce problème, vous pouvez allouer moins d'adresses IP (par exemple 110) et utiliser les adresses IP restantes comme tampon.
De cette façon, vous pouvez être quasiment certain que la même adresse IP ne sera pas immédiatement réutilisée.
stockage
Une unité de calcul a une limite quant au nombre de disques pouvant être connectés.
Par exemple, sur Azure, une instance Standard_D2_v5 avec 2 processeurs virtuels et 8 Go de mémoire peut avoir jusqu'à 4 disques de données connectés.
Si vous souhaitez déployer un StatefulSet sur des nœuds de travail à l'aide du type d'instance Standard_D2_v5, vous ne pourrez pas créer plus de quatre réplicas.
En effet, chaque réplique du StatefulSet est associée à un disque.
Une fois la cinquième réplique créée, le pod restera suspendu car la revendication de volume persistant ne peut pas être liée au volume persistant.
pourquoi ?
Étant donné que chaque volume persistant est un disque connecté, vous ne pouvez en avoir que 4 dans cette instance.
Quelles sont donc vos options?
Vous pouvez fournir une instance plus grande.
Ou vous pouvez réutiliser le même disque en utilisant un champ de sous-chemin différent.
Regardons un exemple.
Le volume persistant suivant nécessite un disque avec 16 Go d'espace :
Si vous soumettez cette ressource au cluster, vous verrez un volume persistant créé et lié à celui-ci.
$ kubectl get pv,pvc
Il existe une relation univoque entre les volumes persistants et les revendications de volumes persistants. Vous ne pouvez donc pas avoir de revendications de volumes persistants utilisant le même disque.
apiVersion: apps/v1
kind: Deployment
metadata:
name: app1
spec:
selector:
matchLabels:
name: app1
template:
metadata:
labels:
name: app1
spec:
volumes:
- name: pv-storage
persistentVolumeClaim:
claimName: shared
containers:
- name: main
image: busybox
volumeMounts:
- mountPath: '/data'
name: pv-storage
Si vous souhaitez utiliser cette déclaration dans votre Pod, vous pouvez procéder comme suit :
apiVersion: apps/v1
kind: Deployment
metadata:
name: app2
spec:
selector:
matchLabels:
name: app2
template:
metadata:
labels:
name: app2
spec:
volumes:
- name: pv-storage
persistentVolumeClaim:
claimName: shared
containers:
- name: main
image: busybox
volumeMounts:
- mountPath: '/data'
name: pv-storage
Vous pouvez avoir un autre déploiement qui utilise la même revendication de volume persistant :
Cependant, avec cette configuration, les deux Pods écriront leurs données dans le même dossier.
Vous pouvez contourner ce problème en utilisant des sous-répertoires dans subPath.
apiVersion: apps/v1
kind: Deployment
metadata:
name: app2
spec:
selector:
matchLabels:
name: app2
template:
metadata:
labels:
name: app2
spec:
volumes:
- name: pv-storage
persistentVolumeClaim:
claimName: shared
containers:
- name: main
image: busybox
volumeMounts:
- mountPath: '/data'
name: pv-storage
subPath: app2
Un déploiement écrira ses données sur les chemins suivants :
-
Pour le premier déploiement, il s'agit de /data/app1
-
Pour le deuxième déploiement, il s'agit de /data/app2
Cette solution de contournement n'est pas parfaite et présente certaines limites :
Tous les déploiements doivent se rappeler d'utiliser subPath. Si vous devez écrire sur un volume, vous devez choisir un volume accessible à partir de plusieurs nœuds Read-Write-Many. Celles-ci nécessitent souvent des prestations coûteuses. De plus, StatefulSetla même solution de contournement ne fonctionnera pas pour , car cela créera une toute nouvelle revendication de volume persistant (et un volume persistant) pour chaque réplica.
Sommaire et conclusion
Alors, utilisez-vous quelques gros nœuds ou plusieurs petits nœuds dans votre cluster ?
Ça dépend de la situation.
Quoi qu’il en soit, qu’est-ce qui est petit et qu’est-ce qui est grand ?
Cela dépend de la charge de travail que vous déployez dans le cluster.
Par exemple, si votre application nécessite 10 Go de mémoire, exécuter une instance avec 16 Go de mémoire équivaut à « exécuter un nœud plus petit ».
Pour une application qui ne nécessite que 64 Mo de mémoire, la même instance peut être considérée comme « volumineuse », car vous pouvez en gérer plusieurs.
Alors qu’en est-il des charges de travail mixtes avec des besoins en ressources différents ?
Dans Kubernetes, il n’existe aucune règle selon laquelle tous les nœuds doivent avoir la même taille.
Vous êtes totalement libre d'utiliser une combinaison de nœuds de différentes tailles dans votre cluster.
Cela pourrait vous amener à devoir faire un compromis entre les avantages et les inconvénients des deux approches.
Bien que vous puissiez trouver la réponse par essais et erreurs, nous avons également développé un outil pour vous aider dans ce processus.
Le calculateur d'instance Kubernetes vous permet d'explorer le meilleur type d'instance pour vos charges de travail spécifiques.
Assurez-vous d’essayer cet outil.