avant-propos
Avec l’essor des plateformes de commerce électronique, de plus en plus de personnes commencent à faire des achats en ligne. Pour les plateformes de commerce électronique, les données telles que les informations sur les produits, les prix et les avis sont très importantes. Par conséquent, la capture de données telles que les informations sur les produits, les prix et les avis sur les plateformes de commerce électronique est devenue une tâche très précieuse.
Ensuite, laissez-moi vous apprendre à utiliser Python pour écrire un programme d'exploration permettant de récupérer des informations sur les produits, les prix, les commentaires et d'autres données sur les plateformes de commerce électronique.

Cette affaire atteint l'objectif
- Données de base du livre
- Réaliser le tableau de visualisation
- Données de critique de livre
- Les commentaires peuvent implémenter une carte de nuages de mots
Le flux d'idées le plus basique : <Général>
1. Analyse des sources de données
1. Ce n'est que lorsque vous savez où et d'où vient le contenu des données que vous pouvez obtenir les données via la demande de code
2. Ouvrez l'outil de développement F12 pour l'analyse de la capture de paquets
3. Recherchez et interrogez le paquet de données par mot-clé pour demander le adresse URL
2. Processus des étapes de mise en œuvre du code : les quatre étapes de base de la mise en œuvre du code
1. Envoyez une requête, simulez le navigateur pour envoyer une requête pour l'adresse URL <l'adresse URL qui vient d'être analysée> 2.
Obtenez des données, demandez au serveur de renvoyer les données de réponse—> réponse dans l'outil de développement
3. Analysez les données et extraire le contenu des données que nous voulons -> Réserver les informations de base
4. Enregistrez les données, enregistrez le contenu des données dans le tableau

Code
Obtenir les détails du livre
envoyer une demande
url = f'http://bang.dangdang.com/books/bestsellers/01.00.00.00.00.00-recent7-0-0-1-1'
# 代码模拟浏览器发送请求 ---> headers请求头 <可以复制粘贴>
headers = {
# User-Agent 用户代理 表示浏览器基本身份标识
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/101.0.0.0 Safari/537.36'
}
# 发送请求
response = requests.get(url=url, headers=headers)
Données analytiques
# 转换数据类型 ---> 可解析对象
selector = parsel.Selector(response.text)
# 第一次提取, 获取所有li标签
lis = selector.css('.bang_list_mode li') # 返回列表
# for循环遍历, 把列表里面的元素一个一个提取出来
for li in lis:
title = li.css('.name a::attr(title)').get() # 标题/书名
recommend = li.css('.tuijian::text').get().replace('推荐', '') # 推荐
star = li.css('.star a::text').get().replace('条评论', '') # 评价
author = li.css('div:nth-child(5) a:nth-child(1)::attr(title)').get() # 作者
date = li.css('div:nth-child(6) span::text').get() # 出版日期
press = li.css('div:nth-child(6) a::text').get() # 出版社
price_r = li.css('.price .price_r::text').get() # 原价
price_n = li.css('.price .price_n::text').get() # 售价
price_e = li.css('.price_e span::text').get() # 电子书价格
href = li.css('.name a::attr(href)').get() # 详情页
dit = {
'标题': title,
'推荐': recommend,
'评价': star,
'作者': author,
'出版日期': date,
'出版社': press,
'原价': price_r,
'售价': price_n,
'电子书价格': price_e,
'详情页': href,
}
csv_writer.writerow(dit)
print(dit)
enregistrer des données
f = open('书籍.csv', mode='a', encoding='utf-8', newline='')
csv_writer = csv.DictWriter(f, fieldnames=[
'标题',
'推荐',
'评价',
'作者',
'出版日期',
'出版社',
'原价',
'售价',
'电子书价格',
'详情页',
])
# 写入表头
csv_writer.writeheader()
Exécutez le code pour obtenir le résultat

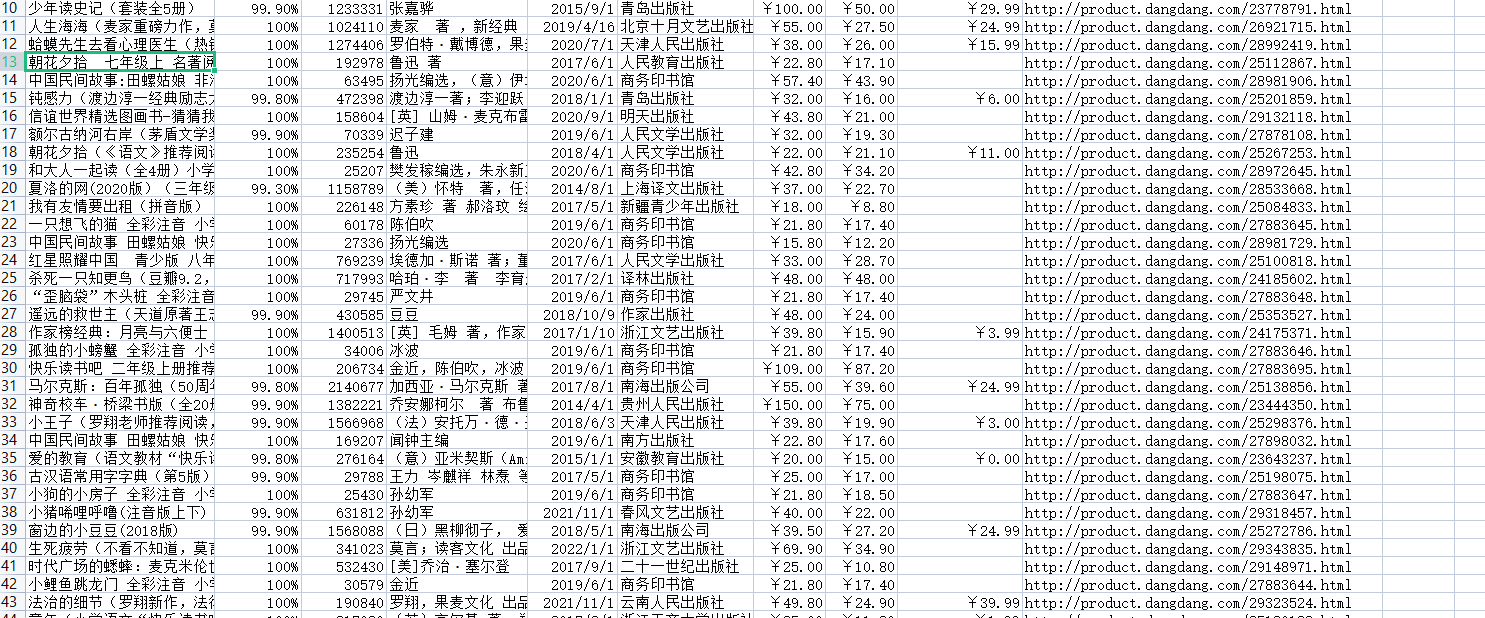

tableau de visualisation
Fourchette de prix globale des livres
python学习交流Q群:770699889 ###
pie1 = (
Pie(init_opts=opts.InitOpts(theme='dark',width='1000px',height='600px'))
.add('', datas_pair_1, radius=['35%', '60%'])
.set_series_opts(label_opts=opts.LabelOpts(formatter="{b}:{d}%"))
.set_global_opts(
title_opts=opts.TitleOpts(
title="当当网书籍\n\n原价价格区间",
pos_left='center',
pos_top='center',
title_textstyle_opts=opts.TextStyleOpts(
color='#F0F8FF',
font_size=20,
font_weight='bold'
),
)
)
.set_colors(['#EF9050', '#3B7BA9', '#6FB27C', '#FFAF34', '#D8BFD8', '#00BFFF', '#7FFFAA'])
)
pie1.render_notebook()
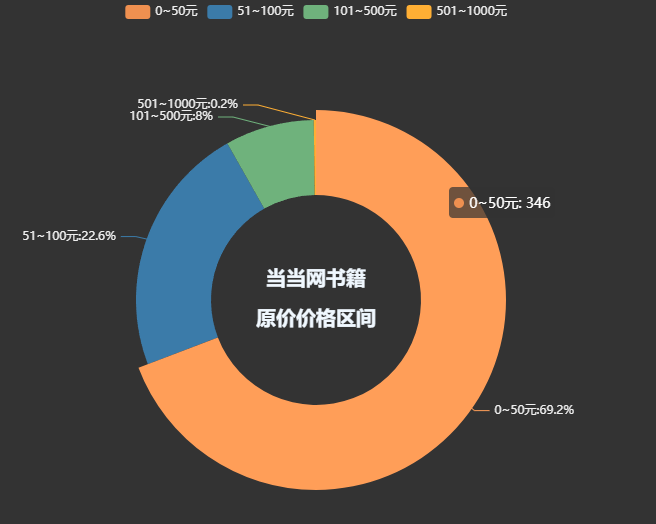
pie1 = (
Pie(init_opts=opts.InitOpts(theme='dark',width='1000px',height='600px'))
.add('', datas_pair_2, radius=['35%', '60%'])
.set_series_opts(label_opts=opts.LabelOpts(formatter="{b}:{d}%"))
.set_global_opts(
title_opts=opts.TitleOpts(
title="当当网书籍\n\n售价价格区间",
pos_left='center',
pos_top='center',
title_textstyle_opts=opts.TextStyleOpts(
color='#F0F8FF',
font_size=20,
font_weight='bold'
),
)
)
.set_colors(['#EF9050', '#3B7BA9', '#6FB27C', '#FFAF34', '#D8BFD8', '#00BFFF', '#7FFFAA'])
)
pie1.render_notebook()
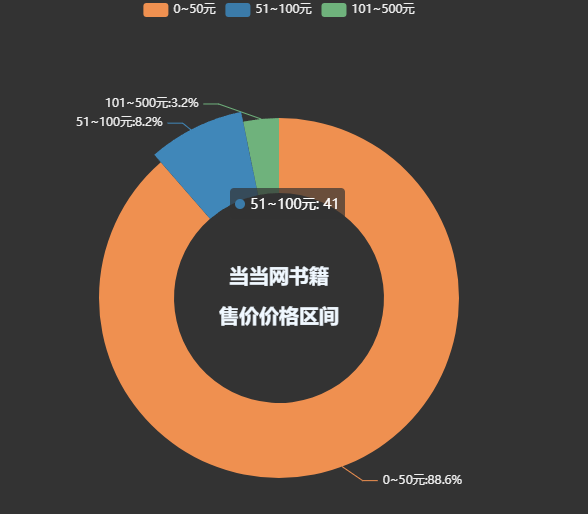
Histogramme du nombre de livres par maison d'édition
bar=(
Bar(init_opts=opts.InitOpts(height='500px',width='1000px',theme='dark'))
.add_xaxis(counts.index.tolist())
.add_yaxis(
'出版社书籍数量',
counts.values.tolist(),
label_opts=opts.LabelOpts(is_show=True,position='top'),
itemstyle_opts=opts.ItemStyleOpts(
color=JsCode("""new echarts.graphic.LinearGradient(
0, 0, 0, 1,[{
offset: 0,color: 'rgb(255,99,71)'}, {
offset: 1,color: 'rgb(32,178,170)'}])
"""
)
)
)
.set_global_opts(
title_opts=opts.TitleOpts(
title='各个出版社书籍数量柱状图'),
xaxis_opts=opts.AxisOpts(name='书籍名称',
type_='category',
axislabel_opts=opts.LabelOpts(rotate=90),
),
yaxis_opts=opts.AxisOpts(
name='数量',
min_=0,
max_=29.0,
splitline_opts=opts.SplitLineOpts(is_show=True,linestyle_opts=opts.LineStyleOpts(type_='dash'))
),
tooltip_opts=opts.TooltipOpts(trigger='axis',axis_pointer_type='cross')
)
.set_series_opts(
markline_opts=opts.MarkLineOpts(
data=[
opts.MarkLineItem(type_='average',name='均值'),
opts.MarkLineItem(type_='max',name='最大值'),
opts.MarkLineItem(type_='min',name='最小值'),
]
)
)
)
bar.render_notebook()
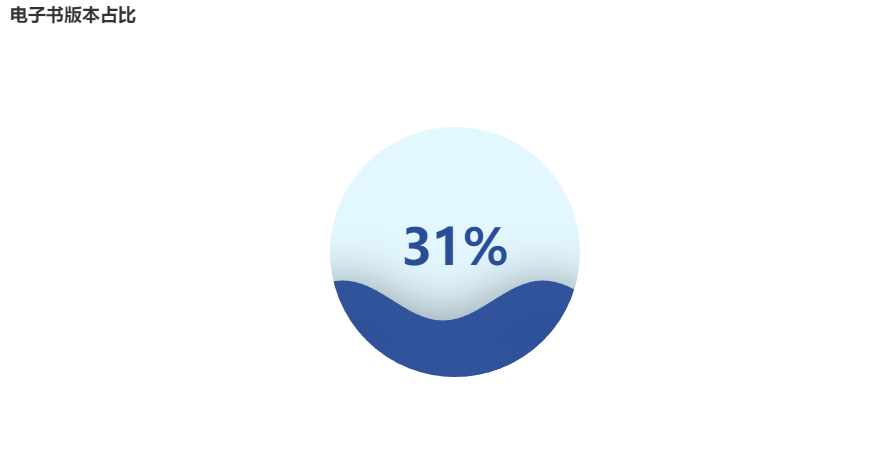
Proportion de versions de livres électroniques
c = (
Liquid()
.add("lq", [1-per], is_outline_show=False)
.set_global_opts(title_opts=opts.TitleOpts(title="电子书版本占比"))
)
c.render_notebook()
Données de critique de livre
源码点击文末名片获取
for page in range(1, 11):
time.sleep(1)
# 确定请求url地址
url = 'http://product.dangdang.com/index.php'
# 请求参数
data = {
'r': 'comment/list',
'productId': '29129370',
'categoryPath': '01.43.79.01.00.00',
'mainProductId': '29129370',
'mediumId': '0',
'pageIndex': page,
'sortType': '1',
'filterType': '1',
'isSystem': '1',
'tagId': '0',
'tagFilterCount': '0',
'template': 'publish',
'long_or_short': 'short',
}
# headers 请求头
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/101.0.0.0 Safari/537.36'
}
# 发送请求
response = requests.get(url=url, params=data, headers=headers)
# response.json() 获取响应json字典数据 键值对取值 ---> 根据冒号左边的内容, 提取冒号右边的内容
html_data = response.json()['data']['list']['html']
content_list = re.findall("<span><a href=.*?' target='_blank'>(.*?)</a></span>", html_data)
with open('评论.txt', mode='a', encoding='utf-8') as f:
f.write('\n'.join(content_list))
f.write('\n')
print(content_list)

mot nuage
import jieba # 分词模块 pip install jieba
import wordcloud
import imageio
img = imageio.imread('123.png')
# wordcloud
# 1. 打开文件 获取弹幕数据
# mode='r' 一定要写吗 不一定 默认以 r
# encoding='' 要写吗? 肯定要的
f = open('评论.txt', mode='r', encoding='utf-8')
txt = f.read()
# print(txt)
# 2. jieba分词 分割词汇
txt_list = jieba.lcut(txt)
# print(txt_list)
# 列表转字符串怎么转
string = ' '.join(txt_list)
# print(string)
# 3. 词云图设置
wc = wordcloud.WordCloud(
width=800, # 宽度
height=500, # 高度
background_color='white', # 背景颜色
mask=img, # 设置图片样式
font_path='msyh.ttc',
scale=15,
stopwords={
'了', '的'},
contour_width=5,
contour_color='red'
)
# 4. 输入文字内容 (字符串的形式)
wc.generate(string)
# 5. 输出图片
wc.to_file('output2.png')

didacticiel vidéo
Une chose à dire sur cette affaire comme mon propre devoir Python, ça fait du bien
【Crawler+Visualisation】 Collectez des informations sur les données sur les produits Dangdang et effectuez une analyse visuelle
Très bien, le partage d'aujourd'hui est par ici~
Si vous avez des questions sur l'article, ou si vous avez d'autres questions sur Python, vous pouvez laisser un message dans la zone de commentaire ou m'envoyer un message privé. Si vous pensez que l'article que j'ai
partagé est bon, vous pouvez me suivre ou donner un coup de pouce à l'article. vers le haut (/≧▽≦)/
