Cette série d'articles de blog sont des notes pour des articles sur l'apprentissage profond/la vision par ordinateur, veuillez indiquer la source de la réimpression
Lire : Reconstruction de visages en 3D à l'ère du Deep Learning : une enquête
Lire : Reconstruction de visages en 3D à l'ère du Deep Learning : une enquête - PubMed (nih.gov)
Résumé
Avec l’avènement du deep learning et la large application des unités de traitement graphique, la reconstruction faciale en 3D est devenue le sujet le plus fascinant de l’identification biométrique. Cet article explore divers aspects des techniques de reconstruction de visage en 3D. Cinq techniques sont abordées dans l'article, à savoir
- apprentissage profond (DL, apprentissage profond)
- géométrie épipolaire (EG, géométrie épipolaire, géométrie épipolaire)
- apprentissage ponctuel (OSL, apprentissage ponctuel, apprentissage ponctuel)
- Modèle 3D morphable (3DMM, modèle 3D déformable)
- forme à partir de méthodes d'ombrage (SFS, reconstruction basée sur la forme de l'ombre, restauration de la profondeur à partir des niveaux de gris)
Cet article fournit une analyse approfondie de la reconstruction du visage en 3D à l’aide de techniques d’apprentissage profond. L'analyse des performances de différentes techniques de reconstruction du visage est discutée du point de vue du logiciel, du matériel, des avantages et des inconvénients. Les défis et les orientations futures du développement de la technologie de reconstruction du visage en 3D sont également abordés.
1. Introduction
La reconstruction faciale 3D est un problème d’identification biométrique dont la vitesse de développement a été accélérée par l’avènement des modèles d’apprentissage profond. De nombreux contributeurs à la recherche sur la reconnaissance faciale 3D ont réalisé des progrès au cours des cinq dernières années (voir Figure 1). Diverses applications telles que la reconstitution et l'animation vocale , la manipulation faciale , le doublage vidéo , le maquillage virtuel , le mapping par projection , le vieillissement du visage et le remplacement du visage ont été développées [1].
Figure 1 : Nombre d'articles de recherche publiés sur la reconstruction du visage en 3D, 2016-2021

La reconstruction du visage en 3D est confrontée à de nombreux défis, tels que le retrait des obturateurs , le démaquillage , le transfert d'expression et la prédiction de l'âge .
Les obstructions peuvent être internes ou externes . Certains occulteurs internes bien connus incluent les cheveux, les barbes, les moustaches et les profils. Les occlusions externes se produisent lorsque d'autres objets/personnes masquent une partie du visage, comme des lunettes, des mains, des bouteilles, du papier et des masques [2].
Les principales raisons à l'origine de la croissance de la recherche sur la reconstruction faciale 3D sont les unités centrales de traitement (CPU) multicœurs, les smartphones, les unités de traitement graphique (GPU) et les applications cloud telles que Google Cloud Platform (GCP), Amazon Web Services (AWS), et disponibilité de Microsoft Azure [3-5].
Données 3D pour
- voxels (voxels, voxels, pixel+volume+élément)
- nuage de points
- un maillage 3D que les GPU peuvent traiter (maillage 3D pouvant être traité par GPU)
Indique (voir Figure 2). Récemment, des chercheurs ont lancé des recherches sur la reconnaissance faciale 4D [6, 7]. La figure 3 montre la classification de la reconstruction du visage 3D.
Figure 2 : Image de visage 3D : a image RVB, b image de profondeur, c image de grille, d image de nuage de points, e image de voxel
Figure 3 : Classification de la reconstruction faciale 3D


1.1 Cadre général pour la reconstruction du visage en 3D
Le cadre de reconnaissance faciale basé sur la reconstruction 3D implique un prétraitement , un apprentissage profond et une prédiction . La figure 4 montre les étapes impliquées dans les techniques d'inpainting de visage 3D, qui peuvent acquérir diverses formes d'images 3D, qui comportent toutes différentes étapes de prétraitement en fonction des besoins.
Figure 4 : Un cadre général pour le problème de reconstruction de visage 3D [9]
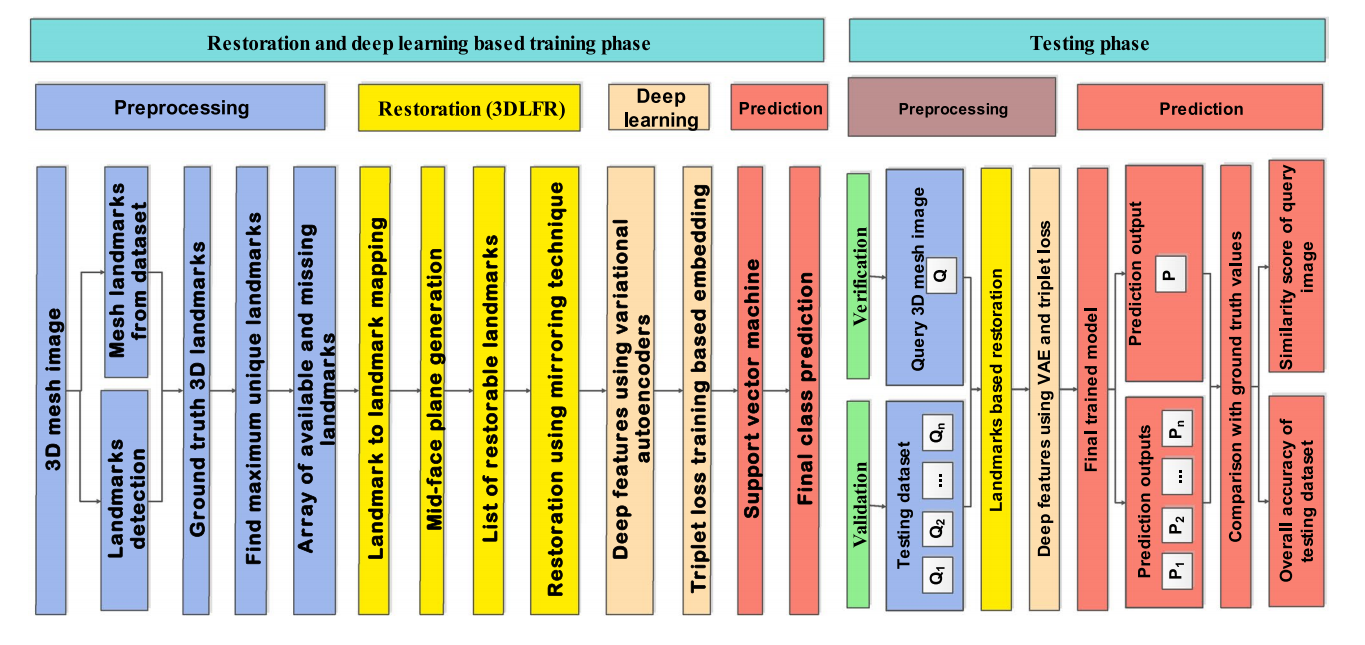
L'alignement du visage peut être effectué ou non avant l'envoi à l'étape de reconstruction. Sharma et Kumar [2, 8, 9] n'utilisent pas l'alignement du visage dans leurs techniques de reconstruction.
La reconstruction faciale peut être réalisée à l'aide de diverses techniques, telles que la reconstruction basée sur 3DMM, la reconstruction basée sur EG, la reconstruction basée sur OSL, la reconstruction basée sur DL et la reconstruction basée sur SFS. De plus, une étape de prédiction est nécessaire suite à la reconstruction du visage. Les prédictions peuvent être utilisées dans les applications de reconnaissance faciale, de reconnaissance des émotions, de reconnaissance du genre ou d’estimation de l’âge.
1.2 Nuage de mots
Le nuage de mots montre les 100 principaux mots-clés pour la reconstruction du visage en 3D (voir Figure 5).
Figure 5 : Nuage de mots de la littérature sur la reconstruction du visage en 3D

À partir de ce nuage de mots, des mots-clés liés aux algorithmes de reconstruction faciale tels que « visage 3D », « pixel », « image » et « reconstruction » ont été largement utilisés. Le mot-clé « reconstruction faciale en 3D » attire les chercheurs en tant que domaine problématique pour la technologie de reconnaissance faciale.
La reconstruction faciale consiste à compléter des images de visages occlus . La plupart des techniques de reconstruction de visage 3D utilisent des images 2D dans le processus de reconstruction [10-12]. Récemment, les chercheurs ont commencé à étudier les images de grille et de voxel [2, 8]. Les réseaux contradictoires génératifs (GAN) sont utilisés pour l'échange de visages et la modification des caractéristiques du visage pour les visages 2D [13]. Ceux-ci doivent encore être explorés à l’aide de techniques d’apprentissage profond.
Cet article est motivé par une étude de recherche détaillée sur l'apprentissage profond des nuages de points 3D [14] et la réidentification des personnes [15]. Comme le montre la figure 1, la recherche sur les visages 3D s'est développée au fil du temps au cours des cinq dernières années. La plupart des études de reconstruction préfèrent utiliser des techniques d'apprentissage profond basées sur le GAN. Cet article vise à étudier l'utilisation de techniques d'apprentissage profond pour la reconstruction de visages en 3D et son application dans des scénarios du monde réel.
Les contributions de cet article comprennent :
- Les avantages et les inconvénients des différentes techniques de reconstruction faciale 3D sont discutés.
- Les exigences matérielles et logicielles requises pour les techniques de reconstruction faciale 3D sont proposées.
- Les ensembles de données, les mesures d'évaluation des performances et l'applicabilité à la reconstruction du visage en 3D sont étudiés.
- Les défis des techniques actuelles et futures de reconstruction faciale 3D sont explorés.
Le reste de l'article est organisé comme suit : La section 2 présente des variantes de la technique de reconstruction de visage 3D. La section 3 traite des mesures d'évaluation des performances et la section 4 présente les ensembles de données utilisés pour les techniques de reconstruction. La section 5 traite des outils et des techniques pour le processus de reconstruction. La section 6 explore les applications potentielles de la reconstruction du visage en 3D. La section 7 résume les défis de recherche actuels et les orientations futures de la recherche. La section 8 fournit des commentaires concluants.
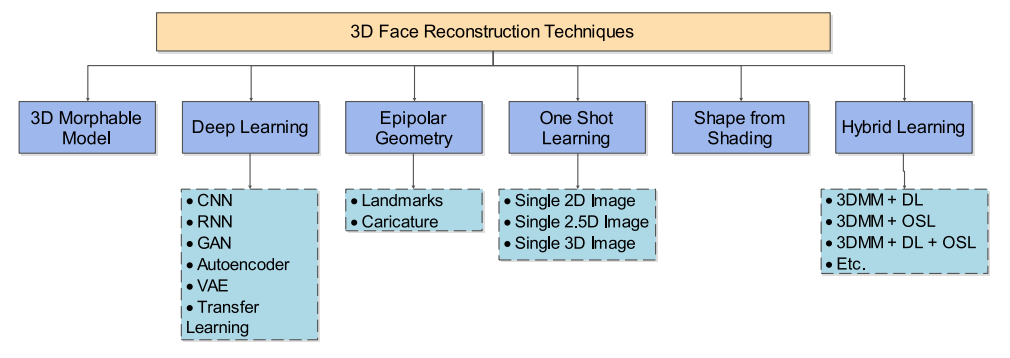
2 Technologie de reconstruction du visage en 3D
Les techniques de reconstruction de visage 3D sont généralement classées en cinq catégories principales, notamment la reconstruction basée sur un modèle déformable 3D (3DMM), la reconstruction basée sur l'apprentissage en profondeur (DL), la reconstruction basée sur la géométrie épipolaire (EG), la reconstruction basée sur l'apprentissage en un seul coup (OSL). reconstruction basée sur la reconstruction et la forme de l'ombre (SFS). La figure 6 montre la technique de reconstruction faciale 3D. La plupart des chercheurs travaillent sur des techniques hybrides de reconstruction faciale et sont considérées comme la sixième catégorie.
Figure 6 : Technologie de reconstruction de visage 3D
2.1 Reconstruction basée sur 3DMM
Les modèles déformables 3D (3DMM) sont des modèles génératifs pour l'apparence et la forme du visage [16]. Tous les visages à générer se trouvent dans une correspondance point à point dense, ce qui peut être réalisé grâce à un processus d'enregistrement des visages. Les morphes sont générés par des correspondances denses. La technique se concentre sur la séparation de la couleur et de la forme du visage d'autres facteurs tels que l'éclairage, la luminosité, le contraste, etc. [17].
Le 3DMM a été introduit par Blanz et Vetter [18]. Des variantes du 3DMM sont disponibles dans la littérature [19-23]. Ces modèles utilisent des représentations de faible dimension pour les expressions faciales, les textures et les identités. Basel Face Model (BFM) est l'un des modèles 3DMM accessibles au public. Le modèle est construit en enregistrant des maillages de modèles correspondant aux visages numérisés obtenus à partir du point le plus proche itératif (ICP) et de l'analyse en composantes principales (ACP) [24].
La figure 7 montre l'amélioration progressive du 3DMM au cours des 20 dernières années [18, 25-28]. La figure présente les résultats de l'article original de Blanz et Vetter de 1999 [18], du premier modèle déformable accessible au public en 2009 [25], des résultats de rendu facial de pointe [28] et des modèles GAN [27].
Figure 7 : Améliorations progressives du 3DMM au cours des deux dernières décennies [17]

Maninchedda et al [29] ont proposé une méthode de reconstruction automatique basée sur la géométrie épipolaire 3D pour résoudre la situation où le visage est obstrué par des lunettes. Ils proposent un modèle de segmentation variationnel pouvant représenter une grande variété de lunettes.
Zhang et ses collègues [30] ont proposé une méthode pour reconstruire des nuages de points de visage 3D denses à partir d'une seule trame de données capturée par un capteur RVB-D. Un nuage de points initial de la région faciale a été capturé à l’aide de l’algorithme de clustering K-Means. Le voisinage du nuage de points est ensuite estimé à l'aide d'un réseau de neurones artificiels (ANN).
De plus, l'interpolation Radial Basis Function (RBF) est utilisée pour obtenir l'approximation finale de la face 3D centrée sur le nuage de points.
Jiang et al [31] ont proposé un algorithme de restauration de visage 3D (PIFR) basé sur le 3DMM. Les images d'entrée sont normalisées pour obtenir plus d'informations sur la visibilité des repères faciaux. L’avantage de cette méthode est la capacité de reconstruction faciale invariante de pose. Cependant, la reconstruction doit être améliorée dans ses grandes dimensions.
Dans le domaine de la vision par ordinateur, une grande pose (grande pose) fait généralement référence à la situation dans laquelle l'orientation, l'angle ou l'angle de rotation d'un visage ou d'un objet dans une image change considérablement, comme la rotation, la mise à l'échelle et la translation. Dans la reconstruction du visage, une grande pose fait généralement référence à la situation dans laquelle le visage est placé dans une orientation non frontale ou où le visage est partiellement obstrué. Ces situations augmentent la difficulté de reconnaissance et de reconstruction faciale.
Wu et al.[32] ont proposé une technique de reconstruction 3D des expressions faciales à partir d'une seule image. Les paramètres du 3DMM ont été calculés à l'aide du cadre de régression en cascade. Lors de l'étape d'extraction des caractéristiques, l'histogramme des dégradés orientés (HOG) et les décalages de points clés sont utilisés.
Kollias et ses collègues [33] ont proposé une nouvelle technique pour synthétiser les expressions faciales et les niveaux d'émotions positives/négatives. Sur la base de la technique d'éveil des valeurs (VA), 600 000 images sont annotées à partir de l'ensemble de données 4DFAB [34]. La technique fonctionne sur des ensembles de données extérieurs sauvages. Cependant, l'ensemble de données 4DFAB n'est pas accessible au public.
Lyu et ses collègues [35] ont proposé un ensemble de données Pixel-Face qui génère des images haute résolution à partir d'images 2D. Pour la reconstruction de visage en 3D, Pixel-3DM est proposé. Cependant, cette étude n’a pas pris en compte les situations d’occlusion externe.
2.2 Reconstruction basée sur DL
Le réseau contradictoire génératif 3D (3DGAN) et le réseau neuronal convolutif 3D (3DCNN) sont des techniques d'apprentissage en profondeur pour la reconstruction du visage en 3D [27]. Les principaux avantages de ces méthodes sont une haute fidélité, une plus grande précision et des performances en matière d’erreur absolue moyenne (MAE). Cependant, la formation d’un GAN prend beaucoup de temps. La reconstruction du visage à partir de vues canoniques peut être réalisée par la méthode Facial Identity Preserving (FIP) [36].
Tang et ses collègues [37] ont introduit un modèle d'apprentissage profond génératif multicouche pour générer des images dans de nouvelles situations d'éclairage. En reconnaissance faciale, le corpus de formation est chargé de fournir des étiquettes pour les perceptrons multi-vues. Augmentez les données synthétiques à partir d’une seule image en utilisant la géométrie du visage [38].
Richardson et al.[39] ont proposé une version non supervisée de la reconstruction ci-dessus. La tâche d'animation faciale [40] est mise en œuvre à l'aide d'un CNN supervisé. Utilisez des réseaux de neurones convolutifs profonds (DCNN) pour récupérer la texture et la forme 3D. Dans [41], la restauration de la texture du visage fournit de meilleurs détails que le 3DMM [42].
La figure 8 illustre les différentes étapes de la reconnaissance faciale 3D utilisant la récupération des régions occluses.
Figure 8 : Différentes étapes de reconnaissance faciale 3D utilisant des techniques de restauration [9]

Kim et ses collègues [26] ont proposé un algorithme de reconnaissance faciale 3D basé sur un réseau neuronal convolutif profond. Grâce à la technologie d’amélioration du visage 3D, diverses expressions faciales peuvent être synthétisées à l’aide d’un seul scan du visage 3D. La formation de modèles basée sur l'apprentissage par transfert est plus rapide. Cependant, lorsque les images de nuages de points 3D sont converties en images 2,5D, les données 3D sont perdues.
2.5D signifie généralement que les informations de profondeur sont limitées à un seul plan (comme une image 2D), et chaque pixel de ce plan est associé à une valeur de profondeur. Dans la reconnaissance faciale 3D, le processus de conversion des données faciales 3D en une image 2,5D consiste à mapper la valeur de profondeur de chaque point 3D au pixel correspondant sur l'image 2D, obtenant ainsi les informations de profondeur de chaque pixel. Cette méthode peut réduire la dimensionnalité des données, simplifier les calculs et réduire les besoins en espace de stockage, mais une partie des informations 3D sera perdue, ce qui peut affecter la précision de la reconnaissance faciale.
Gilani et al.[43] ont proposé une technique permettant de développer un large corpus de visages 3D annotés. Ils ont formé un réseau neuronal convolutionnel 3D de reconnaissance faciale (FR3DNet) pour reconnaître 3,1 millions de visages 3D de 100 000 personnes. Le test est basé sur 31 860 images de 1 853 personnes.
Thies et ses collègues [44] ont proposé une technique de marionnettes vocales neuronales pour générer une sortie vidéo réaliste à partir d'une source audio d'entrée. Ceci est basé sur un réseau neuronal récurrent DeepSpeech utilisant l’espace modèle 3D latent. Audio2ExpressionNet est responsable de la conversion de l'audio d'entrée en expressions faciales spécifiques.
Li et ses collègues [45] ont proposé SymmFCNet, un réseau neuronal convolutionnel cohérent et symétrique pour reconstruire les pixels manquants en utilisant l'autre moitié du visage. SymmFCNet comprend des sous-réseaux de repondération de l'éclairage, de déformation et de reconstruction générative. Le recours à plusieurs réseaux constitue un inconvénient majeur.
Han et ses collègues [46] ont proposé un système de dessin pour créer des photos caricaturales 3D en modifiant les traits du visage. Une approche non conventionnelle d'apprentissage en profondeur est conçue pour obtenir des cartes de saillance des sommets. Ils utilisent l'ensemble de données FaceWarehouse [20] pour la formation et les tests. L'avantage est de convertir des images 2D en modèles de caricatures faciales 3D. Cependant, avec les lunettes, la qualité du manga en souffre. De plus, la reconstruction est affectée par différentes conditions d'éclairage.
[47] ont implémenté un auto-encodeur tel que 3DFaceGAN pour modéliser la distribution de la surface du visage en 3D. La perte de reconstruction et la perte contradictoire sont utilisées pour le générateur et le discriminateur. L’inconvénient est que le GAN est difficile à entraîner et ne peut pas être appliqué aux solutions de visage 3D en temps réel.
2.3 Reconstruction basée sur EG
Les méthodes de reconstruction de visage basées sur la géométrie épipolaire utilisent plusieurs images en perspective non synthétiques du même sujet pour générer une seule image 3D [48]. Le principal avantage de ces techniques est une bonne fidélité géométrique. L’étalonnage des caméras et des images orthographiques sont deux défis majeurs rencontrés par ces techniques. La figure 9 montre les images de plan épipolaire horizontal et vertical (EPI) obtenues à partir des images de vue centrale et de sous-ouverture.
Figure 9 : a Image plan épipolaire correspondant à la courbe faciale 3D, b EPI horizontal, c EPI vertical [48]
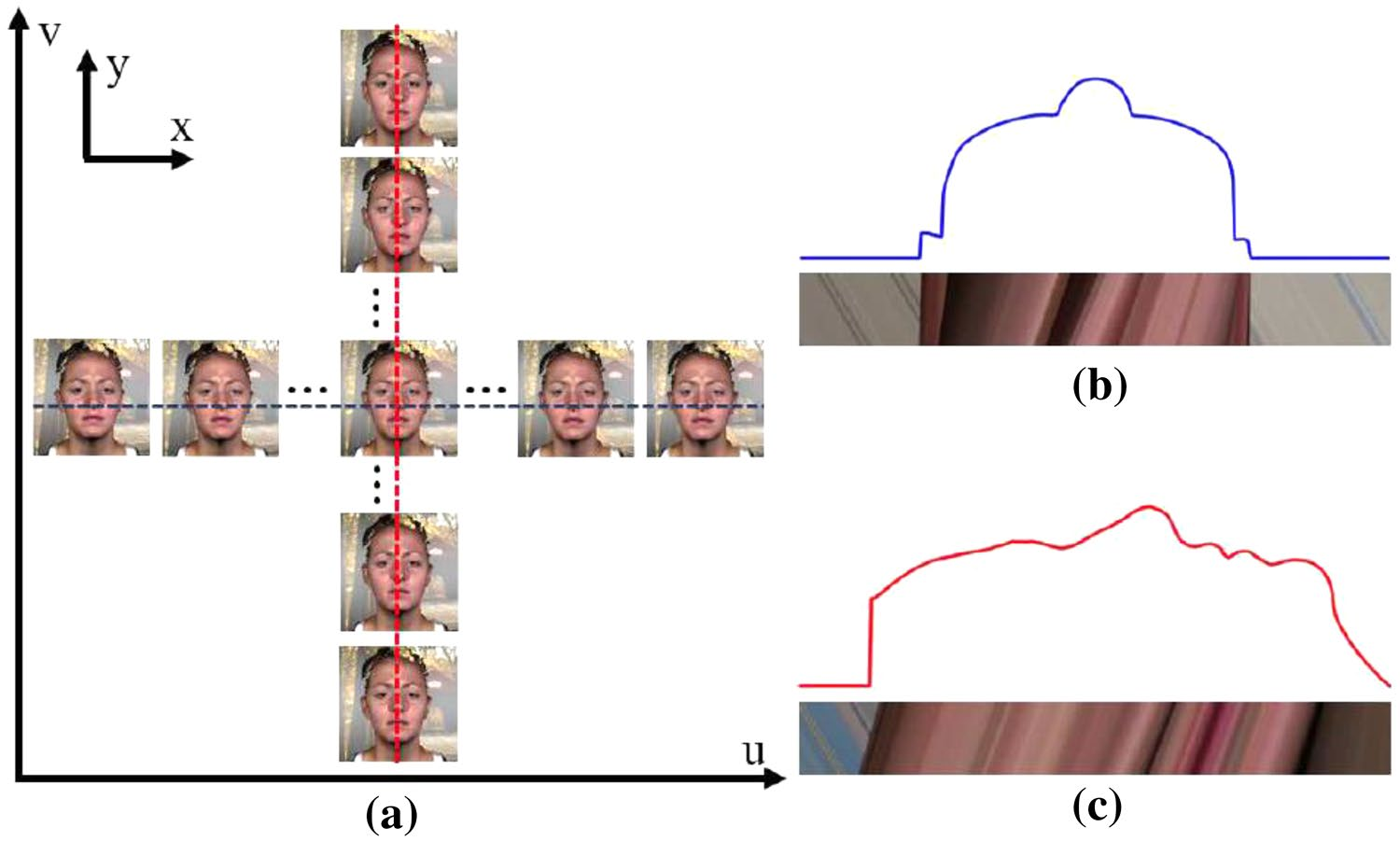
Anbarjafari et ses collègues [49] ont proposé une nouvelle technique pour générer des visages 3D capturés par les caméras des téléphones portables. Au total, 68 repères de visage sont utilisés pour diviser le visage en quatre régions. Différentes étapes sont utilisées lors de la création de textures, de la création de zones pondérées, du morphing de modèle et de la composition. Le principal avantage de cette technique est la bonne capacité de généralisation obtenue à partir des points caractéristiques. Cependant, il repose sur des ensembles de données présentant de bonnes formes de tête, ce qui affecte la qualité globale.
2.4 Reconstruction basée sur OSL
Les méthodes de reconstruction basées sur l'apprentissage ponctuel utilisent une seule image d'un individu pour recréer un modèle de reconnaissance 3D [50]. La technique utilise une seule image de chaque sujet pour entraîner le modèle. Par conséquent, ces techniques s’entraînent plus rapidement tout en donnant des résultats prometteurs [51]. Cependant, cette approche ne peut être généralisée aux vidéos. Aujourd’hui, la reconstruction 3D basée sur l’apprentissage ponctuel est un domaine de recherche actif.
Afin de former un modèle cartographique d'images 2D à 3D, des modèles 3D réalistes sont nécessaires. Certains chercheurs utilisent la prédiction de profondeur pour reconstruire des structures 3D [52, 53]. Alors que d'autres techniques prédisent directement la forme 3D [54, 55]. Peu d'études ont réalisé une reconstruction de visage 3D en utilisant une seule image 2D [38, 39].
Les valeurs optimales des paramètres pour les visages 3D peuvent être obtenues en utilisant des réseaux de neurones profonds et des vecteurs de paramètres de modèle. Des améliorations majeures ont été obtenues sur [56, 57]. Cependant, cette approche ne peut pas gérer correctement les variations de pose. Le principal inconvénient de cette technique est la création de visages 3D multi-vues et la dégradation de la reconstruction. La figure 10 montre le cadre général des techniques de reconstruction faciale basées sur une seule prise.
Figure 10 : Cadre général de la reconstruction du visage 3D basée sur OSL
Xing et al. [58] ont proposé une technique de reconstruction de visage en 3D utilisant une seule image sans considérer la forme 3D réelle. Le rendu du modèle facial est utilisé dans le processus de reconstruction. Utilisez la méthode guidée de réglage fin pour envoyer des commentaires afin d’améliorer encore la qualité du rendu. Cette technique fournit des méthodes pour reconstruire des formes 3D à partir d'images 2D. Cependant, l'inconvénient est l'utilisation de transformations de corps rigides pour le prétraitement.
2.5 Reconstruction basée sur SFS
Les méthodes de restauration de forme (SFS) sont basées sur la récupération de forme 3D à partir d'ombres et d'éclairages [59, 60]. Il utilise des images qui produisent des modèles en bon état. Cependant, l'occlusion ne peut pas être gérée lorsque l'estimation de la forme interfère avec l'ombre de l'objet. Cela fonctionne bien avec l'éclairage dans les vues de face non frontales (voir Figure 11).
Figure 11 : Récupération de forme faciale 3D a image 2D, b image de profondeur 3D, c projection de texture, d histogramme d'albédo [59]

La méthode de Jiang et al.[61] s'inspire de l'utilisation du RVB-D et de la vidéo monoculaire pour l'animation faciale. Le calcul pour faire une estimation approximative du visage 3D cible est effectué en ajustant un modèle paramétrique à l'image d'entrée. Le principal inconvénient de cette technique est la reconstruction d’une image 3D à partir d’une seule image 2D. En revanche, les techniques SFS reposent sur des connaissances prédéfinies sur la géométrie faciale, telles que la symétrie faciale.
2.6 Reconstruction basée sur l'apprentissage hybride
Reconstruction basée sur l’apprentissage hybride
Richardson et al.[38] ont proposé une technique pour générer une base de données avec des images faciales réalistes utilisant des formes géométriques. Le réseau proposé est construit en utilisant le modèle ResNet [62]. Cette technique ne peut pas récupérer des images avec des attributs faciaux différents. Il ne parvient pas à généraliser le processus de formation à la nouvelle génération de visages.
Liu et al [63] ont proposé une technique de reconstruction de visage en 3D utilisant une méthode hybride 3DMM et de restauration de forme. L'erreur absolue moyenne (MAE) a été tracée pour la convergence de l'erreur de reconstruction.
Richardson et ses collègues [39] ont proposé un modèle d'apprentissage ponctuel pour extraire des formes faciales grossières à fines. Récupération grossière des traits du visage à l’aide de CoarseNet et FineNet. Reconstruction faciale très détaillée, y compris les rides en une seule image. Cependant, cela ne peut pas être généralisé aux traits du visage disponibles dans les données d’entraînement. Le recours aux données synthétiques constitue un autre inconvénient.
Jackson et ses collègues [51] ont proposé un modèle basé sur CNN pour reconstruire la géométrie faciale 3D à l'aide d'une seule image faciale 2D. Cette méthode ne nécessite aucun type d’alignement du visage. Cela fonctionne bien avec tous les types d’expressions et de poses.
Tewari et al.[64] ont proposé un modèle génératif basé sur un réseau d'auto-encodeurs convolutifs pour la reconstruction du visage. Ils ont utilisé les modèles AlexNet [65] et VGGFace [66]. Cependant, la méthode échoue dans les occlusions telles que les barbes ou les objets externes.
Dou et ses collègues [67] ont proposé une technique basée sur un réseau neuronal profond (DNN) pour la reconstruction de visage 3D de bout en bout à l'aide d'une seule image 2D. La fonction de perte multitâche et le CNN fusionné sont mélangés pour la reconnaissance faciale. Le principal avantage de cette approche est un cadre simplifié avec un modèle de bout en bout. Cette méthode présente cependant l’inconvénient de s’appuyer sur des données synthétiques.
Han et ses collègues [68] ont proposé un système de dessin basé sur l'apprentissage profond de CNN pour la modélisation 3D de visages et de dessins animés. Habituellement, des expressions faciales riches sont générées par MAYA et ZBrush. Cependant, il inclut une interaction utilisateur basée sur les gestes. L'entrée au niveau de la forme est combinée avec la sortie de la couche entièrement connectée pour générer une sortie bilinéaire.
Hsu et ses collègues [69] ont proposé deux méthodes différentes de reconnaissance faciale à pose croisée. Une technique est basée sur la reconstruction 3D et l’autre est construite à l’aide de CNN profonds. Les composants du visage sont construits à partir de la bibliothèque de visages 2D. Les surfaces 3D sont reconstruites à l'aide de composants faciaux 2D. Les modèles basés sur CNN peuvent facilement gérer les fonctionnalités sauvages. Les méthodes basées sur les composants 3D ne se généralisent pas bien.
Feng et ses collègues [48] ont développé FaceLFnet pour récupérer des visages 3D à l'aide d'images plan épipolaires (EPI). Ils récupèrent les courbes faciales 3D verticales et horizontales à l’aide de CNN. Des images réalistes de champs lumineux ont été synthétisées à l’aide de visages 3D. 14 000 scans du visage de 80 personnes différentes ont été utilisés pendant la formation, totalisant 11 millions de courbes faciales/EPI. Ce modèle est un choix privilégié pour les applications médicales. Cependant, cette technique nécessite un grand nombre de courbes images planes épipolaires.
Zhang et al.[70] ont proposé une technique de reconstruction de visage 3D utilisant une combinaison de visages plastiques et de stéréophotométrie clairsemée. Des techniques d'optimisation sont utilisées pour la direction d'éclairage de chaque pixel ainsi que pour un éclairage de haute précision. La segmentation sémantique est effectuée sur les images d'entrée et les proxys géométriques pour reconstruire des détails tels que les rides, les sourcils, les grains de beauté et les pores. L'erreur géométrique moyenne a été utilisée pour vérifier la qualité de la reconstruction. Cette technique repose sur l’éclairage du visage.
Tran et al.[71] ont proposé une technique de reconstruction de visage 3D basée sur la cartographie de convexité. Estimez les cartes convexes à l’aide d’une approche codeur-décodeur convolutif. Le pooling maximum et les unités linéaires rectifiées (ReLU) sont utilisés avec des couches convolutives. Le principal inconvénient de cette technique est que la symétrie douce non optimisée est plus lente à mettre en œuvre.
Feng et ses collègues [72] ont proposé un ensemble de données de référence composé d'images faciales 2K de 135 individus. Cinq méthodes différentes de reconstruction de visage 3D sont évaluées sur l'ensemble de données proposé.
Feng et al [73] ont proposé une technique de reconstruction de visage 3D basée sur des cartes de position UV de coordonnées de texture, appelée Position Map Regression Network (PRN). CNN régresse la forme 3D à partir d'une seule image 2D. Les fonctions de perte pondérée utilisent différentes formes de poids lors de la convolution, à savoir des masques de poids. Les cartes de position UV peuvent également être généralisées. Cependant, il est difficile de l’appliquer dans des scénarios pratiques.
[74] ont proposé un réseau basé sur un codeur-décodeur pour régresser la forme du visage 3D à partir d'images 2D. La perte articulaire est calculée sur la base d’erreurs de reconstruction du visage 3D et de reconnaissance. Cependant, la fonction de perte articulaire affecte la qualité de la forme du visage.
Chinaev et al.[75] ont développé un modèle basé sur CNN pour la reconstruction du visage en 3D à l'aide d'appareils mobiles. MobileFace CNN a été utilisé pendant la phase de test. Cette approche est rapide à former sur les appareils mobiles et peut être appliquée en temps réel. Cependant, l’annotation de visages 3D avec des modèles plastiques au cours de la phase de prétraitement coûte cher.
Gecer et al [27] ont proposé une technique de reconstruction de visage 3D basée sur DCNN et GAN. Dans l’espace UV, GAN est utilisé pour entraîner le générateur à générer des textures faciales. Une stratégie d'ajustement 3DMM non traditionnelle est formulée sur un moteur de rendu différenciable et un GAN.
Deng et ses collègues [76] ont proposé une méthode de reconstruction de visage en un seul coup basée sur CNN pour l'apprentissage faiblement supervisé. Pertes combinées au niveau de la perception et au niveau de l’image. Les avantages de cette technique sont la grande pose et l'invariance de l'occlusion. Cependant, au stade de la prédiction, la confiance du modèle est faible en termes d’occlusion.
Yuan et al [77] ont proposé une technique de restauration de visage 3D utilisant 3DMM et GAN pour les faces occluses. Validez la qualité des visages 3D à l’aide d’un discriminateur local et d’un discriminateur global. La cartographie sémantique des repères faciaux conduit à la génération de visages synthétiques sous occlusion. En revanche, plusieurs discriminateurs augmentent la complexité temporelle.
Luo et al [78] ont mis en œuvre une approche siamoise CNN pour la restauration faciale en 3D. Ils valident la qualité de la méthode de reconstruction à l’aide de fonctions de coût paramétrique pondéré de distance (WPDC) et de fonctions de coût contrastives. Cependant, la reconnaissance faciale n’a pas été testée dans la nature et le nombre d’images d’entraînement est faible.
[79] ont proposé une méthode basée sur le GAN pour synthétiser des visages 3D de haute qualité. Amélioration de l'expression à l'aide du GAN conditionnel. 10 000 nouvelles identités individuelles ont été synthétisées de manière aléatoire à partir de l’ensemble de données 300W-LP. Cette technologie produit des visages 3D de haute qualité avec des détails fins. Cependant, les GAN sont difficiles à former et ne peuvent pas être appliqués à des solutions en temps réel.
Chen et ses collègues [80] ont proposé une technique de reconstruction de visage 3D utilisant un encodeur VGG 3DMM auto-supervisé. Régression des paramètres 3DMM à l'aide d'un cadre en deux étapes pour reconstruire les détails du visage. Génère des visages de bonne qualité sous occlusion normale. Utilisez l'espace UV pour capturer les détails du visage. Cependant, le modèle échoue sur les occlusions extrêmes, les expressions et les poses larges. L'ensemble de données CelebA [81] est utilisé pour la formation, et CelebA est utilisé avec l'ensemble de données LFW [82] pour le processus de test.
Ren et ses collègues [83] ont développé un cadre d'encodeur-décodeur pour le défloutage vidéo 3D des points de visage. Prédire la connaissance de l'identité et la structure du visage via la branche de rendu et la reconstruction faciale 3D. La suppression du flou des visages est un défi lorsqu'il s'agit de vidéos à pose variable. Le principal inconvénient de cette technique est son coût de calcul élevé.
Tu et ses collègues [10] ont développé une technique d'apprentissage auto-supervisé assistée en 2D (2DASL) pour les images faciales en 2D. Utilisez les informations sur le bruit des points clés pour améliorer la qualité des modèles faciaux 3D. L'apprentissage autocritique est développé pour améliorer les modèles faciaux 3D. Deux ensembles de données, à savoir AFLW-LFPA [84] et AFLW2000-3D [85], sont utilisés pour la restauration du visage 3D et l'alignement du visage. Cette approche fonctionne bien pour les visages 2D dans la nature ainsi que pour les points clés bruyants. Cependant, il repose sur des annotations de points clés 2D à 3D.
Liu et ses collègues [86] ont proposé une méthode automatique pour générer des visages 3D avec pose et normalisation d'expression (PEN). L’avantage de cette technique est que la reconstruction à partir d’une seule image 2D et la reconnaissance faciale 3D sont invariantes en matière de pose et d’expression. Cependant, ce n’est pas invariant par l’occlusion.
Lin et ses collègues [24] ont mis en œuvre une technique de reconstruction de visage en 3D basée sur des images uniques prises dans la nature. Génération de textures faciales haute densité à l'aide de réseaux convolutifs graphiques. Les bases de données FaceWarehouse [20] et CelebA [81] sont utilisées pour la formation.
Ye et ses collègues [87] ont proposé un ensemble de données de dessins animés 3D à grande échelle. Ils ont généré un modèle plastique 3D linéaire basé sur PCA pour les formes de bandes dessinées. 6,1 000 images de caricatures de portraits sont collectées à partir de pinterest.com et de l'ensemble de données WebCaricature [88]. Des bandes dessinées 3D de haute qualité ont été synthétisées. Cependant, pour les images de visages d’entrée masquées, la qualité de la caricature n’est pas bonne.
Lattas et al [89] ont proposé une technique permettant de générer des reconstructions faciales 3D de haute qualité à partir d'images arbitraires. Une base de données à grande échelle de 200 sujets différents a été collectée sur la base de la géométrie et de la réflectivité. Former un réseau de transformation d’images pour estimer l’albédo spéculaire et diffus. La technique utilise les GAN pour générer des avatars haute résolution. Cependant, il ne peut pas générer d’avatars pour les thèmes de peau foncée.
Zhang et ses collègues [90] ont proposé une technique de détection automatique des points clés et de restauration de visages 3D pour les mangas. Utilisez l'image 2D du manga pour régresser la direction et la forme du manga 3D. Le modèle ResNet est utilisé pour coder l'image d'entrée dans un espace latent. Le décodeur est utilisé avec des couches entièrement connectées pour générer des points clés 3D sur la caricature.
Deng et ses collègues [91] ont proposé une intégration latente DISentangled, précisément contrôlable (DiscoFaceGAN), pour représenter de fausses personnes avec diverses poses, expressions et éclairages. L'apprentissage contrastif est utilisé pour faciliter le démêlage en comparant les visages rendus avec les visages réels. La génération du visage est précise dans l'expression, la pose et l'éclairage. La qualité des modèles générés est moindre dans des conditions de faible luminosité et dans des poses extrêmes.
Li et al.[92] ont proposé une technique de reconstruction de visage 3D pour estimer la pose d'un visage 3D, en utilisant une estimation grossière à fine. Ils génèrent des modèles 3D à l'aide d'une méthode de pondération adaptative. L'avantage de cette technique est sa robustesse aux occlusions partielles et aux poses extrêmes. Cependant, le modèle échoue lorsque les points clés 2D et 3D sont mal estimés lorsqu'ils sont masqués.
Chaudhuri et ses collègues [93] ont proposé une méthode d'apprentissage profond pour former des cartes d'albédo dynamiques personnalisées et des formes de mélange expressives. Générez des restaurations faciales 3D de manière photoréaliste. La perte d'analyse du visage et la perte de dégradé de forme de mélange capturent la signification sémantique des formes de mélange reconstruites. Cette technique a été entraînée sur des vidéos en pleine nature et a généré des visages 3D de haute qualité et le transfert des mouvements du visage d'une personne à une autre. Il ne fonctionne pas bien sous occlusion externe.
Shang et al.[94] ont proposé une technique d'apprentissage auto-supervisé pour la synthèse de vues prenant en compte l'occlusion. La cohérence multidimensionnelle est réalisée à l'aide de trois fonctions de perte différentes, à savoir la perte de cohérence en profondeur, la perte de cohérence en pixels et la perte épipolaire basée sur des points clés. La reconstruction est effectuée par une méthode tenant compte de l'occlusion. Il ne fonctionne pas bien avec les occlusions externes (mains, lunettes, etc.).
Cai et al. [95] ont proposé un GAN guidé par l'attention (AGGAN), capable de reconstruire un visage en 3D à l'aide d'images 2,5D. AGGAN utilise une technique d'encodeur automatique pour générer des images voxels 3D à partir d'images de profondeur. Cartographie des visages 2,5D à 3D à l'aide de GAN basés sur l'attention. La technique gère un large éventail de poses et d’expressions de tête. Cependant, dans le cas d’une bouche large, les expressions faciales ne peuvent pas être entièrement reconstruites.
Xu et al.[96] ont proposé une méthode pour entraîner des modèles géométriques de tête sans utiliser de données de référence 3D. Utiliser des CNN pour former des images synthétiques profondes avec une géométrie de tête sans optimisation. Manipulation de la pose de la tête à l'aide de GAN et de déformation 3D.
Le tableau 1 présente une analyse comparative des techniques de reconstruction faciale 3D.
Tableau 1 : Analyse comparative des technologies de reconstruction faciale 3D

Le tableau 2 résume les avantages et les inconvénients des techniques de reconstruction faciale 3D.
Tableau 2 : Comparaison des avantages et inconvénients des technologies de reconstruction faciale 3D

3 Normes d'évaluation des performances
Les mesures d'évaluation des performances sont importantes pour comprendre la qualité d'un modèle formé. Il existe une variété d'indicateurs d'évaluation, notamment l'erreur absolue moyenne (MAE), l'erreur quadratique moyenne (MSE), l'erreur moyenne normalisée (NME), l'erreur quadratique moyenne (RMSE), la perte d'entropie croisée (CE), l'aire sous la courbe ( AUC), intersection sur rapport d'union (IoU), rapport signal/bruit de pointe (PSNR), courbe caractéristique de fonctionnement du récepteur (ROC) et indice de similarité structurelle (SSIM).
Le tableau 3 résume les mesures d’évaluation des performances des techniques de reconstruction de visage 3D.
Tableau 3 : Évaluation des techniques de reconstruction de visage 3D à partir de mesures de performance

Lors de la reconstruction du visage, les mesures d'évaluation des performances les plus importantes sont le MAE, le MSE, le NME, le RMSE et la perte contradictoire. Il s’agit de cinq mesures d’évaluation des performances largement utilisées. Les pertes contradictoires sont utilisées depuis 2019 avec l’avènement des GAN sur les images 3D.
4 ensembles de données pour la reconnaissance faciale
Le tableau 4 présente une description détaillée des ensembles de données utilisés pour les techniques de reconstruction de visage 3D.
Tableau 4 : Description détaillée des jeux de données utilisés

L’analyse de différents ensembles de données met en évidence le fait que la plupart des ensembles de données faciales 3D sont des ensembles de données accessibles au public. Par rapport aux ensembles de données publics de visages 2D, ils ne disposent pas d’un nombre suffisant d’images pour entraîner les modèles. Cela rend l’étude des visages 3D plus intéressante car le facteur d’évolutivité n’a pas encore été testé et est devenu un domaine de recherche actif. Il convient de mentionner que seuls trois ensembles de données, Bosphorus, Kinect-FaceDB et UMBDB, contiennent des images occluses pour la suppression de l'occlusion.
5 Outils et techniques pour la reconstruction du visage en 3D
Le tableau 5 présente les technologies utilisées en termes de matériel d'unité de traitement graphique (GPU), de taille de mémoire vive (RAM), d'unité centrale de traitement (CPU) et de brèves applications. La comparaison met en évidence l’importance de l’apprentissage profond dans la reconstruction faciale 3D. Les GPU jouent un rôle essentiel dans les modèles basés sur le deep learning. Avec l’avènement de Google Collaboratory, les GPU sont désormais disponibles gratuitement.
Tableau 5 : Analyse comparative des technologies, du matériel et des applications de reconstruction de visage 3D

6 candidatures
Basé sur la technologie AI+X [128], où X est une expertise dans le domaine de la reconnaissance faciale, un grand nombre d’applications sont concernées par la reconstruction faciale 3D. La manipulation faciale, l'animation et la reproduction vocales, le doublage vidéo, le maquillage virtuel, le mapping par projection, le remplacement du visage, le vieillissement du visage et l'impression 3D en médecine sont quelques-unes des applications bien connues. Ces applications sont abordées dans les sous-sections suivantes.
6.1 Manipulation du visage
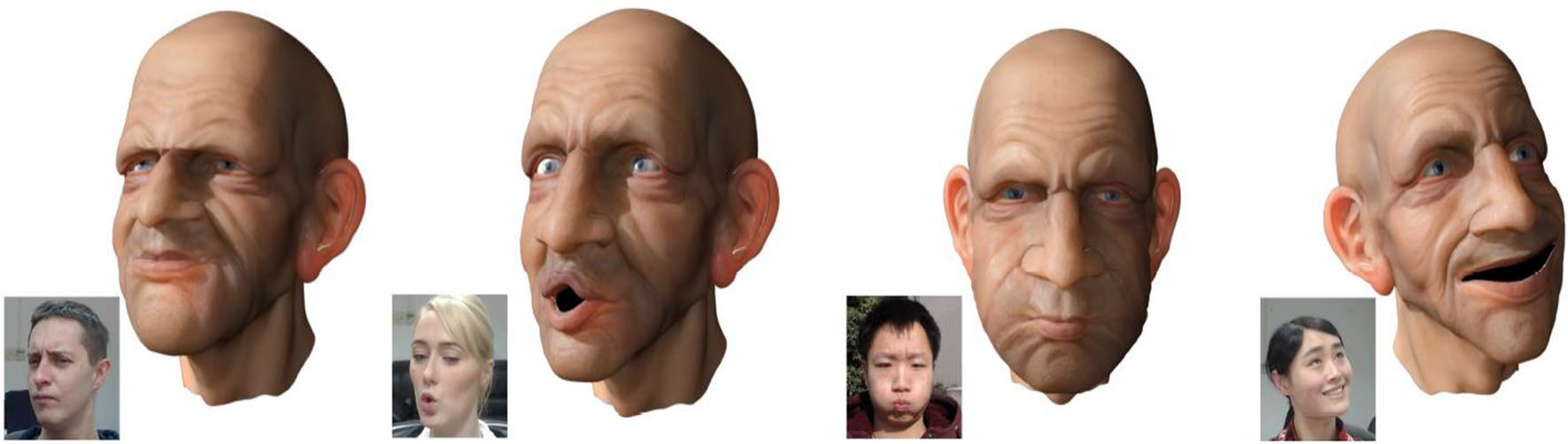
Les industries du jeu vidéo et du cinéma utilisent le clonage ou la manipulation faciale dans l’animation faciale vidéo. Les expressions et les émotions sont transmises de l'utilisateur au personnage cible via des flux vidéo. Lorsqu'un artiste interprète un personnage animé dans un film, la reconstruction faciale 3D peut aider à transférer les expressions de l'artiste au personnage. La figure 12 montre un exemple de manipulation dans une démonstration en temps réel d'un avatar numérisé [129, 130].
Figure 12 : Spectacle de marionnettes faciales en temps réel [129]
6.2 Animation et reproduction vocales
Zollhofer et ses collègues [1] discutent de divers travaux de rendu de visages basés sur la vidéo. La plupart des méthodes reposent sur la reconstruction des visages source et cible à l’aide de modèles faciaux paramétriques. La figure 13 montre l'architecture pipeline pour la manipulation neuronale de la parole [44]. L'entrée audio est soumise à une extraction de fonctionnalités via Deep Speech basée sur des réseaux de neurones récurrents. De plus, les fonctionnalités d'expression basées sur l'auto-encodeur sont transférées avec le modèle 3D vers un moteur de rendu neuronal pour recevoir des animations vocales.
Figure 13 : Marionnettes vocales neuronales

6.3 Doublage vidéo
Le doublage est une partie importante de la réalisation cinématographique dans laquelle des pistes audio sont ajoutées ou remplacées dans la scène originale. La voix de l'acteur original doit être remplacée par la voix du doubleur. Ce processus nécessite une formation suffisante des doubleurs pour synchroniser leur audio avec l'acteur original [131]. Pour minimiser les divergences dans le doublage visuel, une reconstruction dynamique de la synthèse labiale est nécessaire pour compléter le dialogue prononcé par les acteurs vocaux. Cela implique de mapper les mouvements de la bouche du doubleur sur les mouvements de la bouche de l'acteur [132]. Par conséquent, des techniques d’échange d’images ou de passage de paramètres sont utilisées.
La figure 14 montre le doublage visuel de VDub [131] et Face2Face avec le doublage en direct activé. La figure 14 montre un exemple de DeepFake dans 6.S191 [133], montrant un exemple d'instructeur de cours utilisant l'apprentissage profond pour doubler sa propre voix avec celle d'une personne célèbre.
Figure 14 : Exemple DeepFake dans 6.S191 [133]

6.4 Maquillage virtuel
L'utilisation du maquillage virtuel est très courante sur les plateformes en ligne, pour les réunions et les chats vidéo, où la présentation d'un bon look fait partie intégrante. Cela inclut les modifications de l’image numérique telles que l’application du bon rouge à lèvres, du bon masque facial, etc. C'est idéal pour les entreprises de produits de beauté, car elles peuvent diffuser des publicités numériques où les consommateurs peuvent découvrir les effets du produit en temps réel sur leurs images. Ceci est réalisé en utilisant différents algorithmes de reconstruction.
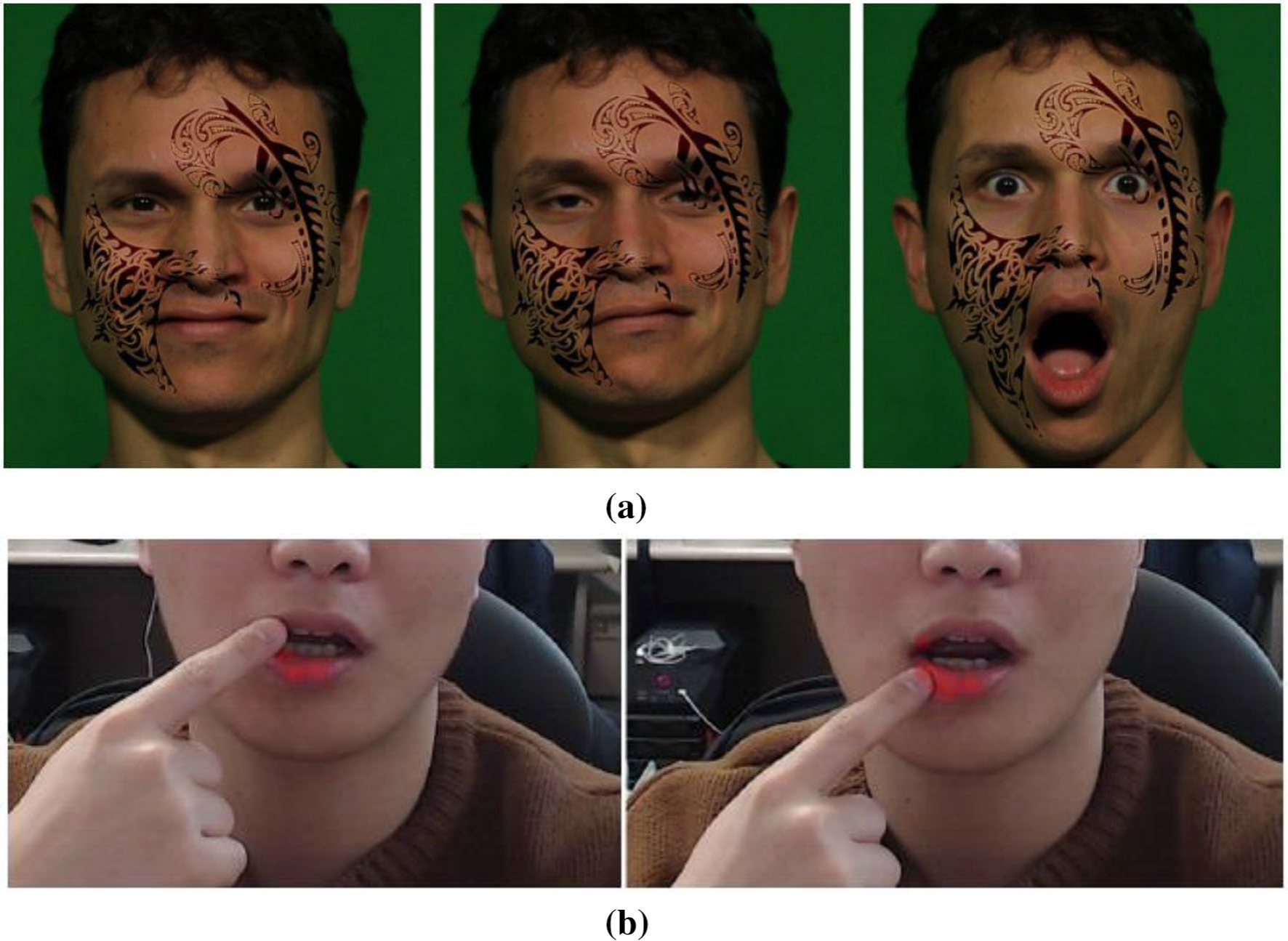
Il a été démontré que les tatouages virtuels synthétiques s'adaptent aux expressions faciales [134] (voir Figure 15a).
Viswanathan et ses collègues [135] ont proposé un système dans lequel deux images faciales étaient prises en entrée, l'une avec les yeux ouverts et l'autre avec les yeux fermés. Un visage en réalité augmentée est proposé pour ajouter une ou plusieurs formes, couches, couleurs et textures de maquillage au visage.
Nam et ses collègues [136] ont proposé une méthode de maquillage des lèvres basée sur la réalité augmentée qui utilise un maquillage pixel par pixel par rapport au maquillage polygone par polygone, comme le montre la figure 15b.
Figure 15 : un tatouage virtuel synthétique [134] et, b un maquillage de rouge à lèvres pixel par pixel basé sur la réalité augmentée [136]
6.5 Cartographie de projection
Le mapping de projection utilise un projecteur pour modifier le caractère ou l'expression d'une image du monde réel. Cette technique est utilisée pour donner vie aux images fixes et leur donner une présentation visuelle. Cartographie par projection utilisant différentes méthodes dans des images 2D et 3D pour modifier l'apparence des personnes. La figure 16 montre un système de cartographie par projection en temps réel nommé Face-Forge [137].
Figure 16 : Cartographie de projection en temps réel basée sur FaceForge [137]

Lin et ses collègues [24] ont proposé une technique de projection de visage 3D en faisant passer l'image d'entrée via CNN et en combinant les informations avec 3DMM pour obtenir la texture fine du visage (voir Figure 17).
Figure 17 : Cartographie par projection de surface 2D combinée avec un modèle 3DMM [24]

6.6 Remplacement du visage
Le remplacement de visage est couramment utilisé dans l'industrie du divertissement, où un visage source est remplacé par un visage cible. Cette technique s'appuie sur des paramètres tels que l'identité, les traits du visage et les expressions des deux visages (source et cible). La face source doit être rendue de manière à correspondre aux conditions de la face cible. Adobe After Effects, un outil largement utilisé dans l'industrie du cinéma et de l'animation, peut faciliter le remplacement des visages [138] (voir Figure 18).
Figure 18 : Système de remplacement de visage avec expression inchangée [138]

6.7 Vieillissement du visage
Le vieillissement du visage est une technique efficace pour convertir des images faciales 3D en 4D. Si les GAN vieillissants pouvaient être utilisés pour synthétiser une seule image 3D, cela aiderait à créer des ensembles de données 4D. Le vieillissement du visage est également appelé progression de l'âge ou synthèse de l'âge car il « ressuscite » le visage en modifiant ses traits. Améliorez les traits du visage à l'aide de diverses techniques afin que l'image originale soit préservée. La figure 19 montre le processus de traduction de visage à l'aide du GAN conditionnel à l'âge (ACGAN) [139].
Figure 19 : Transformation de visage à l'aide d'ACGAN [139]

Shi et ses collègues [140] ont utilisé le GAN pour le vieillissement du visage, car différentes parties du visage ont des vitesses de vieillissement différentes dans le temps. Par conséquent, ils utilisent un GAN conditionnel basé sur l’attention avec normalisation pour gérer le vieillissement segmentaire du visage.
Fang et al [141] ont proposé une méthode de vieillissement progressif du visage utilisant une fonction de perte triplet au niveau du générateur GAN. Une perte de conversion complexe les aide à faire face efficacement au vieillissement du visage.
Huang et ses collègues [142] ont utilisé le GAN progressif pour traiter trois aspects du vieillissement du visage, tels que la préservation de l'identité, la haute fidélité et la précision du vieillissement. [143] ont proposé un GAN contrôlable pour manipuler l’espace latent des images faciales d’entrée afin de contrôler le vieillissement du visage.
Yadav et ses collègues [144] ont proposé une méthode de reconnaissance faciale pour différentes tranches d'âge en utilisant deux images différentes de la même personne.
Sharma et ses collègues [145] ont utilisé le pipeline CycleGAN pour la progression de l'âge et le GAN à super-résolution amélioré pour le GAN de fusion haute fidélité.
[146] ont proposé une méthode de vieillissement du visage pour modéliser les visages jeunes, modéliser l'apparence du visage et les transformations géométriques.
Comme le montre le tableau 6, la reconstruction du visage peut être utilisée dans trois types de contextes différents. La manipulation faciale, l'animation vocale et la reproduction faciale sont tous des exemples de reconstruction faciale basée sur l'animation. Le remplacement de visage et le doublage vidéo sont deux exemples d'applications vidéo. Le vieillissement du visage, le maquillage virtuel et le mapping par projection font partie des applications faciales 3D les plus courantes.
Tableau 6 : Application de la technologie de reconstruction du visage 3D

7 défis et orientations futures de la recherche
Cette section traite des principaux défis rencontrés lors de la reconstruction du visage en 3D, suivie des orientations pour les recherches futures.
7.1 Défis actuels
Les défis actuels de la reconstruction du visage en 3D comprennent l’élimination des occlusions, le démaquillage, le transfert d’expression et la prédiction de l’âge. Ceux-ci seront abordés dans les prochaines sous-sections.
7.1.1 Suppression des occlusions
La suppression des occlusions est une tâche difficile pour la reconstruction du visage en 3D. Les chercheurs utilisent des voxels et des repères 3D pour gérer les occlusions faciales 3D [2, 8, 9].
Sharma et Kumar [2] ont développé une technique de reconstruction du visage basée sur les voxels. Après le processus de reconstruction, ils utilisent un pipeline entraîné avec des auto-encodeurs variationnels, des LSTM bidirectionnels et une perte de triplet pour obtenir une reconnaissance faciale 3D.
Sharma et Kumar [20] ont proposé une méthode de reconstruction et de reconnaissance de visage basée sur les voxels. Ils utilisent un générateur et un discriminateur basés sur la théorie des jeux pour générer des triplets. Une fois les informations manquantes reconstruites, les occlusions sont supprimées. Sharma et Kumar [22] ont construit une technique de reconstruction de visage 3D à apprentissage unique en utilisant des repères faciaux 3D (voir Figure 20).
Figure 20 : Reconstruction 3D du visage à partir de repères faciaux [9]

7.1.2 Appliquer des produits cosmétiques et les enlever
Effectuer le maquillage et le démaquillage lors de réunions virtuelles pendant la pandémie de COVID-19 est un défi [154-156].
MakeupBag [154] propose une technique de transfert automatique de style de maquillage en résolvant les problèmes de séparation du maquillage et de maquillage du visage. Le principal avantage du MakeupBag est qu’il prend en compte le teint et la couleur de la peau lors du transfert du maquillage (comme le montre la figure 21).
Figure 21 : MakeupBag basé sur le résultat du maquillage appliqué d’un visage de référence à un visage cible [154].

Li et ses collègues [155] ont proposé un système de vérification du visage invariant par le maquillage. Ils utilisent un Semantic-Aware Makeup Cleaner (SAMC) pour démaquiller le visage dans une variété d'expressions et de poses. La technique fonctionne sans surveillance tout en localisant les zones de maquillage du visage et utilise une carte d'attention comprise entre 0 et 1, représentant le degré de maquillage.
Horita et Aizawa [156] ont proposé un réseau contradictoire génératif (SLGAN) guidé par des styles et des vecteurs latents. Ils utilisent un GAN contrôlable pour permettre aux utilisateurs d'ajuster l'effet d'ombrage des produits cosmétiques (voir Figure 22).
Figure 22 : Transfert et suppression de produits cosmétiques basés sur le GAN [156]

7.1.3 Transfert d'expressions
Le transfert d'expression est un problème actif, en particulier avec l'avènement des GAN.
Wu et ses collègues [157] ont proposé ReenactGAN, une méthode capable de transférer des expressions humaines d'une vidéo source vers une vidéo cible. Ils utilisent un modèle basé sur un codeur-décodeur pour la traduction du visage de la source à la cible. Le transformateur est évalué à l'aide de trois fonctions de perte, à savoir la perte récurrente, la perte contradictoire et la perte liée à la forme. La figure 23 montre des images de Donald Trump recréant des expressions.
Figure 23 : Transfert d'expression à l'aide de ReenactGAN [157]

Les deepfakes sont une préoccupation, car les expressions faciales et le contexte sont différents.
Nirkin et ses collègues [158] ont proposé une méthode de détection des deepfakes pour détecter les manipulations d'identité et le remplacement de visages. Dans une image deepfake, la région du visage est manipulée en changeant contextuellement le visage à modifier.
[159] ont étudié quatre méthodes de deepfake, notamment la synthèse complète, l'échange d'identité, la manipulation d'attributs faciaux et l'échange d'expression.
7.1.4 Prédiction de l'âge
Grâce aux deepfakes et aux réseaux contradictoires génératifs [140, 142], les visages peuvent être déformés à d’autres âges, comme le montre la figure 24. Par conséquent, le défi de prédire l'âge d'une personne dépasse l'imagination, en particulier sur les cartes d'identité ou les faux visages sur les plateformes de réseaux sociaux.
Figure 24 : Résultats du GAN pour le vieillissement progressif du visage [142]

Fang et ses collègues [141] ont proposé une technique de simulation de l'âge du visage basée sur le GAN. Le modèle Triple-GAN proposé utilise une perte de traduction triplet pour modéliser les relations entre les modèles d'âge. Ils utilisent un générateur et un discriminateur basés sur un codeur-décodeur pour la classification par âge.
Kumar et al.[160] emploient l'apprentissage par renforcement sur l'espace latent basé sur le modèle GAN [161]. Ils utilisent un processus de décision markovien (MDP) pour la manipulation sémantique.
[162] ont proposé une technique GAN semi-supervisée pour générer des images faciales réalistes. Ils ont synthétisé des images de visages à l’aide de données réelles et d’âges cibles lors de la formation du réseau.
Zhu et ses collègues [163] ont utilisé une technique GAN conditionnelle basée sur l'attention pour synthétiser des images faciales avec une haute fidélité ciblée.
7.2 Défis futurs
L’apprentissage non supervisé reste un problème ouvert dans la reconstruction de visages en 3D. Récemment, [164] a proposé une solution pour les objets déformables symétriques 3D. Dans cet article, certaines possibilités futures de reconstruction faciale en 3D sont discutées en détail, telles que la reconstruction des lèvres, la capture des dents et de la langue, la capture des yeux et des paupières, la reconstruction de la coiffure et la reconstruction de la tête complète. Ces défis représentent des tâches pour les chercheurs travaillant dans le domaine de la reconstruction faciale 3D.
7.2.1 Reconstruction des lèvres
Les lèvres sont l’un des éléments les plus critiques de la région buccale. Diverses célébrités subissent une chirurgie des lèvres, notamment un lifting, une réduction et une augmentation des lèvres [165, 166].
Heidekrueger et al.[165] ont étudié les proportions de lèvres préférées des femmes. Il a été conclu que le sexe, l’âge, la profession et le pays peuvent influencer la préférence pour des proportions de lèvres inférieures.
L'esthétique de la lèvre supérieure a été revue par Baudoin et al. [166]. Différentes options de traitement allant des produits de comblement à la dermabrasion et à l'excision chirurgicale sont étudiées.
Zollhofer et al. [1] montrent la reconstruction des lèvres comme une application de la reconstruction du visage en 3D sur la figure 25. Dans [167], une vidéo des lèvres reconstitue le roulement, l'étirement et la flexion des lèvres.
Figure 25 : Reconstruction des lèvres de haute qualité [1]

7.2.2 Capture des dents et de la langue
Dans la littérature, peu de travaux de recherche s’intéressent à la capture de l’intérieur de la cavité buccale. Reconstruire les dents et la langue dans le cadre de la reconstruction du visage 2D basée sur GAN est une tâche difficile. La barbe ou la moustache peuvent rendre difficile l’accrochage des dents et de la langue. Dans [163], un modèle statistique est discuté. Il existe différentes applications pour reconstruire des régions dentaires, par exemple en créant le contenu d'avatars numériques et en restauration dentaire sur la base de la géométrie faciale (voir Figure 26).
Figure 26 : Reconstruction dentaire et son application [168]

7.2.3 Capture des yeux et des paupières
[170] ont démontré une estimation du regard en 3D et une reconstruction du visage à partir de vidéos RVB.
Wen et al [169] ont proposé une technique de suivi et de reconstruction en temps réel des paupières 3D (voir Fig. 27). Cette approche est combinée à des systèmes de suivi du visage et des yeux pour obtenir des visages complets avec des régions oculaires détaillées. Dans [171], un LSTM bidirectionnel a été utilisé pour le suivi des paupières.
Figure 27 : Suivi des paupières basé sur les bords sémantiques [169]

7.2.4 Reconstruction de coiffure
La reconstruction de coiffures est une tâche difficile sur les visages 3D. La synthèse capillaire 3D basée sur des auto-encodeurs variationnels volumétriques [172] est illustrée à la figure 28.
Figure 28 : Synthèse de cheveux 3D à l’aide d’auto-encodeurs variationnels volumétriques [172]

Ye et al.[173] ont proposé un modèle de reconstruction capillaire basé sur une technique codeur-décodeur. Il génère un champ vectoriel volumétrique à l'aide d'une carte d'orientation basée sur les coiffures. Ils ont utilisé un mélange de couches CNN, de connexions sautées, de couches entièrement connectées et de couches déconvolutives lors de la génération de l'architecture de format codeur-décodeur. Pendant la formation, les pertes structurelles et de contenu sont utilisées comme mesures d'évaluation.
7.2.5 Reconstruction complète de la tête
La reconstruction de la tête en 3D est un domaine de recherche actif.
He et ses collègues [174] ont proposé une reconstruction faciale 3D entièrement pilotée par la tête. L'image d'entrée et les résultats de reconstruction ont été générés avec des textures de vue latérale (voir Figure 29). Ils ont utilisé un modèle paramétrique d'albédo pour compléter la carte de texture de la tête. Les réseaux convolutifs sont utilisés pour la segmentation des régions du visage et des cheveux. La reconstruction de tête humaine a diverses applications dans la réalité virtuelle et la génération d'avatars.
Figure 29 : Reconstruction complète de la tête [174]

Le tableau 7 présente les défis et les orientations futures, ainsi que leurs problèmes cibles.
Tableau 7 : Défis et orientations futures de la recherche pour la reconstruction du visage en 3D

8Conclusion
Cet article fournit une étude détaillée et approfondie des techniques de reconstruction faciale en 3D.
Six techniques de reconstruction sont initialement discutées. L’observation est que l’évolutivité est le plus grand défi pour le problème des visages 3D, car il n’existe pas d’ensembles de données suffisamment volumineux et accessibles au public pour les visages 3D. La plupart des chercheurs ont travaillé sur des images RVB-D.
Avec le développement du deep learning, il existe des contraintes matérielles pour travailler avec des images de grille ou des images de voxel.
Les défis actuels et futurs liés à la reconstruction de visages en 3D dans le monde réel sont discutés. Ce domaine est un domaine de recherche ouvert avec de nombreux défis, notamment ceux liés aux capacités des réseaux contradictoires génératifs (GAN) et des deepfakes. exister
- reconstruction des lèvres
- Reconstruction orale interne
- reconstruction des paupières
- Divers styles de cheveux
- reconstruction complète de la tête
D’une part, cette recherche n’a pas été pleinement explorée.
Déclaration Conflit d'intérêts : Au nom de tous les auteurs, l'auteur correspondant ne déclare aucun conflit d'intérêts.
les références
- Zollhöfer M, Thies J, Garrido P et al (2018) Progrès récents dans la reconstruction, le suivi et les applications du visage 3D monoculaire. Computational Graphics Forum 37(2):523–550. https://doi.org/10.1111/cgf.13382
- Sharma S, Kumar V (2020) Reconstruction de visage 3D basée sur Voxel à l'aide de l'apprentissage profond séquentiel et son application à la reconnaissance faciale. Applications d'outils multimédias 79 : 17303–17330. https://doi.org/10.1007/s11042- 020-08688- X
- API Cloud Vision | Google Cloud. https://cloud.google.com/vision/docs/face-tutorial. Consulté : 12 janvier 2021
- AWS Marketplace : API Deep Vision. https://aws.amazon.com/marketplace/pp/Deep-Vision-AI-Inc-Deep-Vision-API/B07JHXVZ4M. Consulté le 12 janvier 2021.
- Vision par ordinateur | Microsoft Azure. https://azure.microsoft.com/en-in/services/cognitive-services/computer-vision/. Consulté le 12 janvier 2021
- Koujan MR, Dochev N, Roussos A (2020) Reconstruction de visage monoculaire 4D en temps réel à l'aide de modèles LSFM. Préimpression arXiv : 2006.10499.
- Behzad M, Vo N, Li X, Zhao G (2021) Vers une reconnaissance des émotions 4D clairsemée au-delà de la lecture du visage. Neural Computing 458 : 297-307
- Sharma S, Kumar V (2020) Reconnaissance faciale 3D invariante d'occlusion basée sur Voxel utilisant la théorie des jeux et le recuit simulé. Outils et applications multimédias 79(35):26517–26547.
- Sharma S, Kumar V (2021) Récupération de visage basée sur un repère 3D pour la reconnaissance à l'aide d'encodeurs automatiques variationnels et de perte ternaire. IET Biometrics 10(1):87–98. https://doi.org/ 10.1049/bme2.12005
- Tu X, Zhao J, Xie M et autres (2020) Reconstruction de visage 3D à image unique assistée par des images de visage 2D dans la nature. IEEE Trans Multimed 23 : 1160-1172. https://doi.org/10.1109/TMM. 2020.2993962
- Bulat A, Tzimiropoulos G À quel point sommes-nous proches de résoudre le problème de l'alignement des visages 2D et 3D ? (et un ensemble de données de 230 000 repères faciaux 3D). Dans : Actes de la Conférence internationale de l'IEEE sur la vision par ordinateur (ICCV), pp.
- Zhu X, Lei Z, Liu X et al. (2016) Alignement du visage dans de grandes poses : une solution 3D. Vision par ordinateur et reconnaissance de formes (CVPR), pp. 146-155.
- Gu S, Bao J, Yang H et al. (2019) Édition de portraits guidée par masque facial à l'aide de GAN conditionnels. Dans : Actes de la conférence 2019 de la communauté informatique de l'IEEE sur la reconnaissance de formes en vision par ordinateur, 2019-juin : 3431–3440. doi : https://doi.org/10.1109/CVPR.2019.00355
- Guo Y, Wang H, Hu Q et autres (2020) Deep Learning for 3D Point Clouds: A Survey. IEEE Trans Pattern Anal Mach Intell 43(12):4338–4364. https://doi.org/10.1109/tpami .2020.3005434
- Ye M, Shen J, Lin G et autres (2021) Deep Learning for Person Re-ID : Survey and Prospects. IEEE Trans Pattern Anal Mach Intell 8828 : 1–1. https://doi.org/10.1109/tpami .2021.3054775
- Tran L, Liu X Modèles de morphologie faciale 3D non linéaires. Dans : Actes de la conférence IEEE sur la vision par ordinateur et la reconnaissance de formes, Pages : 7346–7355.
- Egger B, Smith WAP, Tewari A et al. (2020) Modèles faciaux morphologiques 3D : passé, présent et futur. ACM Trans Graph 39(5):1–38. https://doi.org/10.1145/3395208
- Blanz V, Vetter T (1999) Reconnaissance faciale basée sur l'ajustement d'un modèle morphologique 3D. IEEE Trans Pattern Anal Mach Intell 25(9):1063–1074
- Booth J, Roussos A, Ponniah A et al. (2018) Modèles morphologiques 3D à grande échelle. Int J Comput Vis 126 : 233–254. https://doi.org/10.1007/s11263-017-1009-7
- Cao C, Weng Y, Zhou S et al. (2014) FaceWarehouse : Une base de données d'expressions faciales 3D pour l'informatique visuelle. IEEE Trans Vis Comput Graph 20 : 413–425. https://doi.org/10.1109/TVCG.2013.249
- Gerig T, Morel-Forster A, Blumer C et al. (2018) Modèles morphologiques du visage - un cadre ouvert. Dans : Actes de la 13e Conférence internationale de l'IEEE sur la reconnaissance automatique des gestes faciaux, FG. Pages : 75–82. https:/ /doi.org/10.1109/FG.2018.00021
- Huber P, Hu G, Tena R et al (2016) Un modèle de visage morphologique 3D multi-résolution et un cadre d'ajustement. Dans : Actes de la 11e conférence conjointe sur la théorie et les applications de la vision par ordinateur, de l'imagerie et de l'infographie, p. 79. –86.SciTePress.
- Li T, Bolkart T et al (2017) Modèles d'apprentissage de la forme et des expressions du visage à partir de scans 4D. ACM Trans Graphics 36(6):1–17. https://doi.org/10.1145/3130800.3130813.
- Lin J, Yuan Y, Shao T, Zhou K (2020) Reconstruction de visages 3D haute fidélité à l'aide de réseaux convolutifs graphiques. Reconnaissance de modèles de vision par ordinateur (CVPR). https://doi.org/10.1109/cvpr42600.2020.00593
- Paysan P, Knothe R, Amberg B et al (2009) Un modèle de visage 3D pour la reconnaissance faciale invariante de pose et d'éclairage. Dans : 6e Conférence internationale de l'IEEE sur la surveillance vidéo et basée sur les signaux avancés, AVSS 2009. Pages : 296– 301.
- Kim D, Hernandez M, Choi J, Medioni G (2018) Deep 3D Facial Recognition. IEEE International Joint Conference on Biometrics (IJCB), IJCB 2017 2018-janvier : 133-142. https://doi.org/10.1109/BTAS .2017.8272691
- Gecer B, Ploumpis S, Kotsia I, Zafeiriou S (2019) Ganfit : Reconstruction de visages 3D haute fidélité à l'aide de réseaux contradictoires génératifs. Dans : Actes de la conférence IEEE/CVF sur la vision par ordinateur et la reconnaissance de formes : 1155-1164. https:/ /doi.org/10.1109/CVPR.2019.00125
- Kim H, Garrido P, Tewari A et autres (2018) Portraits vidéo en profondeur. ACM Trans Graphics 37:1–14. https://doi.org/10.1145/3197517.3201283
- Maninchedda F, Oswald MR, Pollefeys M (2017) Reconstruction rapide de modèles 3D de visages avec des lunettes. Dans : Conférence IEEE/CVF sur la vision par ordinateur et la reconnaissance de formes (CVPR). https://doi.org/10.1109/CVPR.2017.490
- Zhang S, Yu H, Wang T et al. (2018) Reconstruction de visage 3D dense à partir d'une image à profondeur unique dans un environnement sans contrainte. Réalité virtuelle 22(1):37-46. https://doi.org/10.1007/ s10055-017-0311-6
- Jiang L, Wu X, Kittler J (2018) Reconstruction faciale 3D invariante de pose, 1 à 8. Préimpression arXiv arXiv : 1811.05295.
- Wu F, Li S, Zhao T et autres (2019) Reconstruction de visage 3D à l'aide d'une régression en cascade avec déplacement de points de repère. Pattern Recognition Letters 125 : 766–772. https://doi.org/10.1016/j.patrec.2019.07. 017
- Kollias D, Cheng S, Ververas E et autres (2020) Deep Neural Network Augmentation: Generating Faces for Sentiment Analysis. International Journal of Computer Vision 128:1455-1484. https://doi.org/10.1007/s11263-020- 01304-3
- 4DFAB : Une base de données d'expressions faciales 4D à grande échelle pour les applications biométriques | DeepAI. https://deepai.org/publication/4dfab-a-large-scale-4d-facial-expression-database-for-biometric-applications. Consulté en octobre 2020 14
- Lyu J, Li X, Zhu X, Cheng C (2020) Pixel-Face : une référence à grande échelle et haute résolution pour la reconstruction de visages 3D. arXiv par arXiv:2008.12444
- Zhu Z, Luo P, Wang X, Tang X (2013) Deep Learning for Identity Preserving Face Space, dans : Actes de la conférence internationale de l'IEEE sur la vision par ordinateur, Institute of Electrical and Electronics Engineers, pp. 113-120.
- Tang Y, Salakhutdinov R, Hinton G (2012) Deep Lambertian Networks. préimpression arXiv arXiv:1206.6445
- Richardson E, Sela M, Kimmel R (2016) Reconstruction de visages 3D en apprenant à partir de données synthétiques. Dans : Actes de la 4e Conférence internationale sur la vision 3D 2016, 3DV 2016. Institute of Electrical and Electronics Engineers, pp. 460-467.
- Richardson E, Sela M, Or-El R, Kimmel R (2017) Apprendre la reconstruction détaillée du visage à partir d'une seule image. Dans : Actes de la conférence IEEE sur la vision par ordinateur et la reconnaissance de formes, pp. 1259-1268.
- Laine S, Karras T, Aila T et al (2016) Capture de représentation faciale à l'aide de réseaux de neurones profonds. Préimpression arXiv arXiv : 1609.06536, 3
- Nair V, Susskind J, Hinton GE (2008) Analyse synthétique par apprentissage d'une boîte noire générative inverse. Dans : Conférence internationale sur les réseaux de neurones artificiels, pp. 971-981.
- Peng X, Feris RS, Wang X, Metaxas DN (2016) Un réseau d'encodeurs-décodeurs récurrents pour l'alignement continu des faces. Dans : Conférence européenne sur la vision par ordinateur, pp. 38–56.
- Zulqarnain Gilani S, Mian A (2018) Apprendre de millions de scans 3D pour la reconnaissance faciale 3D à grande échelle. Dans : Actes de la conférence de l'IEEE Computer Society sur la vision par ordinateur et la reconnaissance de formes, pp. 1896-1905. https:// doi .org/10.1109/CVPR.2018.00203
- Thies J, Elgharib M, Tewari A et al (2019) Neural voice manipulation: Audio-driven facial reproduction, dans : Conférence européenne sur la vision par ordinateur, pp.
- Li X, Hu G, Zhu J et al. (2020) Apprentissage de CNN profonds symétriquement cohérents pour la complétion des visages. Transactions IEEE sur le traitement d'images 29 : 7641–7655. https://doi.org/10.1109/TIP.2020.3005241
- Han X, Hou K, Du D et autres (2020) CaricatureShop : croquis de caricature personnalisés et au niveau photo. Transactions IEEE sur la vision et l'infographie 26 : 2349-2361. https://doi.org/10.1109/TVCG.2018.2886007
- Moschoglou S, Ploumpis S, Nicolaou MA, et al (2020) 3DFaceGAN : Réseaux contradictoires pour la représentation, la génération et la transformation des visages 3D. Journal international de vision par ordinateur 128(10):2534-2551. https://doi.org/10.1007/s11263-020-01329-8
- Feng M, Zulqarnain Gilani S, Wang Y et autres (2018) « Reconstruction de visages 3D à partir d'images en champ lumineux : une approche sans modèle ». Notes de cours en informatique (y compris la sous-série Notes de cours sur l'intelligence artificielle et la sous-série Notes de cours sur la bioinformatique) 11214 LNCS : 508-526. https://doi.org/10.1007/978-3-030-01249-6_31
- Anbarjafari G, Haamer RE, LÜSi I et al (2019) « Reconstruction faciale 3D avec fusion la mieux adaptée basée sur la région à l'aide de téléphones mobiles pour les médias sociaux basés sur la réalité virtuelle ». Bulletin scientifique de l’Académie polonaise des sciences. 67 : 125-132. https://doi.org/10.24425/bpas.2019.127341
- Kim H, Zollhöfer M, Tewari A et autres (2018) « InverseFaceNet : rendu inverse monoculaire profond ». Dans Actes de la conférence IEEE sur la vision par ordinateur et la reconnaissance de formes, pp. 4625-4634.
- Jackson AS, Bulat A, Argyriou V, Tzimiropoulos G (2017) "Reconstruction de grands visages 3D à partir d'une seule image via la régression volumétrique directe CNN". Dans Actes de la Conférence internationale de l'IEEE sur la vision par ordinateur 2017-octobre : 1031-1039. https://doi.org/10.1109/ICCV.2017.117
- Eigen D, Puhrsch C, Fergus R (2014) "Prédiction de cartes de profondeur à partir d'images uniques à l'aide de réseaux profonds multi-échelles". Préimpression arXiv : 1406.2283.
- Saxena A, Chung SH, Ng AY (2008) "Reconstruction en profondeur 3D à partir d'une seule image fixe". Journal international de vision par ordinateur 76 : 53-69. https://doi.org/10.1007/s11263-007-0071-y
- Tulsiani S, Zhou T, Efros AA, Malik J (2017) "Supervision multi-vues pour la reconstruction à vue unique via la cohérence des rayons différenciables". Dans Actes de la conférence IEEE sur la vision par ordinateur et la reconnaissance de formes, pp. 2626-2634.
- Tatarchenko M, Dosovitskiy A, Brox T (2017) « Réseaux génératifs Octtree : une architecture convolutionnelle efficace pour une sortie 3D haute résolution ». Dans Actes de la Conférence internationale de l'IEEE sur la vision par ordinateur, pp. 2088-2096.
- Roth J, Tong Y, Liu X (2016) "Reconstruction adaptative de visages 3D à partir d'une collection de photos sans contrainte". Dans Actes de la conférence IEEE sur la vision par ordinateur et la reconnaissance de formes, pp. 4197-4206.
- Kemelmacher-Shlizerman I, Seitz SM (2011) "Reconstruction faciale à l'état sauvage". Dans Actes de la Conférence internationale de l'IEEE sur la vision par ordinateur, pp. 1746-1753.
- Xing Y, Tewari R, Mendonça PRS (2019) « Une méthode guidée auto-supervisée pour la reconstruction de visage 3D à image unique ». Dans Actes de la conférence d'hiver 2019 de l'IEEE sur la vision informatique appliquée, WACV 2019 : 1014-1023. https://doi.org/10.1109/WACV.2019.00113
- Kemelmacher-Shlizerman I, Basri R (2011) "Reconstruction de visage 3D à partir d'une seule image en utilisant une seule forme de plan de référence". Transactions IEEE sur l'analyse de modèles et l'intelligence artificielle 33 : 394-405. https://doi.org/10.1109/TPAMI.2010.63
- Sengupta S, Lichy D, Kanazawa A et autres (2020) « SfSNet : apprentissage de la forme du visage, de l'albédo et de l'éclairage dans la nature ». Analyse de modèles IEEE et trading d'intelligence artificielle. https://doi.org/10.1109/TPAMI.2020.3046915
- Jiang L, Zhang J, Deng B et autres (2018) « Reconstruction de visages 3D avec des détails géométriques à partir d'une seule image ». Transactions IEEE sur le traitement d'images 27 : 4756-4770. https://doi.org/10.1109/TIP.2018.2845697
- He K, Zhang X, Ren S, Sun J (2016) "Apprentissage résiduel profond pour la reconnaissance d'images". Dans Actes de la conférence IEEE sur la vision par ordinateur et la reconnaissance de formes, pp. 770-778.
- Liu F, Zeng D, Li J, Zhao Q, juin (2017) "Reconstruction de visage 3D via régression en cascade dans l'espace des formes". Frontières des technologies de l'information et de l'ingénierie électronique 18 : 1978-1990. https://doi.org/10.1631/FITEE.1700253
- Tewari A, Zollhöfer M, Kim H et al (2017) MoFA : un auto-encodeur facial à convolution profonde basé sur un modèle pour la reconstruction monoculaire non supervisée. Dans : Actes de travail de la Conférence internationale IEEE 2017 sur la vision par ordinateur, ICCVW 2017 2018-Janua : 1274-1283. https://doi.org/10.1109/ICCVW.2017.153
- Krizhevsky A, Sutskever I, Hinton GE (2012) Réseaux de neurones à convolution profonde pour la classification ImageNet. Progrès dans les systèmes de traitement de l'information neuronale 25 : 1097-1105
- Groupe de géométrie visuelle d'Oxford. http://www.robots.ox.ac.uk/~vgg/data/vgg_face/. Consulté le 13 octobre 2020
- Dou P, Shah SK, Kakadiaris IA (2017) Reconstruction de visage 3D de bout en bout avec des réseaux de neurones profonds. Dans : 30e conférence IEEE sur la reconnaissance de formes en vision par ordinateur, CVPR, 1503-1512. https://doi.org/10.1109/CVPR.2017.164
- Han X, Gao C, Yu Y (2017) DeepSketch2Face : un système de dessin basé sur l'apprentissage profond pour les modèles de visages et de caricatures 3D. Transactions ACM dans les graphiques 36 : 1-12. https://doi.org/10.1145/3072959.3073629
- Hsu GS, Shie HC, Hsieh CH, Chan JS (2018) Reconstruction de composants 3D à localisation rapide et CNN pour la reconnaissance de poses croisées. Transactions IEEE sur la technologie vidéo dans les circuits et les systèmes 28 : 3194-3207. https://doi.org/10.1109/TCSVT.2017.2748379
- Cao X, Chen Z, Chen A et al. (2018) Reconstruction de visage 3D photométrique clairsemée guidée par un modèle morphologique. Actes de la conférence de l'IEEE Computer Society sur la reconnaissance de formes en vision par ordinateur. https://doi.org/10.1109/CVPR.2018.00487
- Tran AT, Hassner T, Masi I et autres (2018) Reconstruction faciale 3D extrême : voir à travers les occlusions. Actes de la conférence de l'IEEE Computer Society sur la reconnaissance de formes en vision par ordinateur. https://doi.org/10.1109/CVPR.2018.00414
- Feng ZH, Huber P, Kittler J et al. (2018) Évaluation de la reconstruction 3D dense à partir d'images de visage 2D dans la nature. Dans : 13e Conférence internationale de l'IEEE sur la reconnaissance automatique des gestes faciaux, FG 2018 780-786. https://doi.org/10.1109/FG.2018.00123
- Feng Y, Wu F, Shao X et autres (2018) Reconstruction conjointe de visages 3D et alignement dense avec des réseaux de régression de graphiques de localisation. Notes de cours en informatique (y compris une sous-série de notes de cours en intelligence artificielle Notes de cours en bioinformatique) 11218 LNCS : 557-574. https://doi.org/10.1007/978-3-030-01264-9_33
- Liu F, Zhu R, Zeng D et autres (2018) Caractéristiques de démêlage dans les formes de visage 3D pour la reconstruction et la reconnaissance des visages articulaires. Actes de la conférence de l'IEEE Computer Society sur la reconnaissance de formes en vision par ordinateur. https://doi.org/10.1109/CVPR.2018.00547
- Chinaev N, Chigorin A, Laptev I (2019) MobileFace : Reconstruction de visage 3D via une régression CNN efficace. Dans : Leal-Taixé Laura, Roth Stefan (eds) Computer Vision - ECCV 2018 Symposium : Munich, Allemagne, 8-14 septembre 2018, Actes, Partie IV. Springer International Publishing, Cham, pages 15-30. https://doi.org/10.1007/978-3-030-11018-5_3
- Deng Y, Yang J, Xu S et autres (2019) Reconstruction précise de visages 3D à l'aide d'un apprentissage faiblement supervisé : d'une image unique à une collection d'images. Symposium de l'IEEE Computer Society sur la reconnaissance de formes en vision par ordinateur 2019-juin : 285-295. https://doi.org/10.1109/CVPRW.2019.00038
- Yuan X, Park IK (2019) Désocclusion faciale à l'aide de modèles morphologiques 3D et de réseaux antagonistes génératifs. Dans : Actes de la conférence internationale de l'IEEE sur la vision par ordinateur 2019-octobre : 10061-10070. https://doi.org/10.1109/ICCV.2019.01016
- Luo Y, Tu X, Xie M (2019) Apprentissage d'une reconstruction de visage 3D robuste et de représentations identitaires discriminantes. 2019 2e Conférence internationale de l'IEEE sur le traitement des signaux d'information et de communication, ICICSP 2019 317-321. https://doi.org/10.1109/ICICSP48821.2019.8958506
- Gecer B, Lattas A, Ploumpis S et autres (2019) Synthétisation des réseaux contradictoires génératifs tronc-éperon pour des modèles faciaux 3D couplés. Conférence européenne sur la vision par ordinateur. Springer, Cham, pp 415-433.
- Chen Y, Wu F, Wang Z et autres (2019) Reconstruction faciale 3D détaillée avec apprentissage auto-supervisé. Transactions IEEE sur le traitement d'images 29 : 8696-8705
- Ensemble de données sur les caractéristiques faciales des célébrités à grande échelle (CelebA). http://mmlab.ie.cuhk.edu.hk/projects/CelebA.html. Consulté le 13 octobre 2020.
- Ensemble de données sur les visages étiquetés dans la nature (LFW) | Kaggle. https://www.kaggle.com/jessicali9530/lfw-dataset. Consulté le 13 octobre 2020
- Ren W, Yang J, Deng S et autres (2019) Utilisation des priors de visage 3D pour le défloutage vidéo du visage. Dans les actes de la conférence internationale IEEE sur la vision par ordinateur. 2019-octobre : 9387-9396. https://doi.org/10.1109/ICCV.2019.00948
- Jourabloo A, Liu X (2015) Alignement de visages 3D invariants de pose. Dans les actes de la conférence internationale IEEE sur la vision par ordinateur. pages 3694 à 3702
- Cheng S, Kotsia I, Pantic M et autres (2018) 4DFAB : une base de données d'expressions faciales 4D à grande échelle pour les applications biométriques. https://arxiv.org/pdf/1712.01443v2.pdf, consulté le 14 octobre 2020
- Liu F, Zhao Q, Liu X, Zeng D (2020) Alignement du visage articulaire et reconstruction du visage 3D pour la reconnaissance faciale. Analyse de modèles graphiques IEEE et transactions d'intelligence artificielle. 42 : 664-678. https://doi.org/10.1109/TPAMI.2018.2885995
- Ye Z, Yi R, Yu M et autres (2020) 3D-CariGAN : une solution de bout en bout allant des photos faciales à la génération de caricatures 3D. 1-17.Préimpression arXiv arXiv:2003.06841
- Huo J, Li W, Shi Y et autres (2017) Web comics : une référence pour la reconnaissance des bandes dessinées. préimpression arXiv arXiv:1703.03230
- Lattas A, Moschoglou S, Gecer B et al (2020) AvatarMe : Reconstruction de visage 3D « dans le monde » réaliste. 757 à 766. https://doi.org/10.1109/cvpr42600.2020.00084
- Cai H, Guo Y, Peng Z, Zhang J (2021) Détection de points clés et reconstruction de visages 3D pour les mangas à l'aide de modèles paramétriques non linéaires. Modèles graphiques 115 : 101103. https://doi.org/10.1016/j.gmod.2021.101103
- Deng Y, Yang J, Chen D et autres (2020) Génération d'images faciales démêlées et contrôlables via un apprentissage par imitation-contraste 3D. https://doi.org/10.1109/cvpr42600.2020.00520
- Li K, Yang J, Jiao N et autres (2020) Reconstruction adaptative du visage 3D à partir d'une seule image. 1 à 11. Préimpression arXiv arXiv:2007.03979
- Chaudhuri B, Vesdapunt N, Shapiro L, Wang B (2020) Modélisation personnalisée du visage pour une reconstruction améliorée du visage et une redirection de l'action. Dans Vedaldi A, Bischof H, Brox T, Frahm JM (eds) Computer Vision - ECCV 2020 : 16e Conférence européenne, Glasgow, Royaume-Uni, 23-28 août 2020, Actes, Partie V. Springer International Publishing, Cham, pages 142 à 160. https://doi.org/10.1007/978-3-030-58558-7_9
- Shang J, Shen T, Li S et autres (2020) Reconstruction de visage 3D monoculaire auto-supervisée en considérant la cohérence géométrique multi-vues des occlusions. Dans Computer Vision - ECCV 2020 : 16e Conférence européenne, Glasgow, Royaume-Uni, 23-28 août 2020, Actes, XV Partie 16 (pp. 53-70). Springer International Publishing
- Cai X, Yu H, Lou J et autres (2020) Récupérez la géométrie faciale 3D à partir de vues en profondeur à l'aide de réseaux contradictoires génératifs guidés par l'attention. Préimpression arXiv arXiv:2009.00938
- Xu S, Yang J, Chen D et autres (2020) Portraits 3D en profondeur à partir d'une seule image. 7707-7717.https://doi.org/10.1109/cvpr42600.2020.00773
- Zhang J, Lin L, Zhu J, Hoi SCH (2021) Reconstruction 3D de facettes faiblement supervisées. 1 à 9. Préimpression arXiv arXiv:2101.02000
- Köstinger M, Wohlhart P, Roth PM, Bischof H (2011) Marqueurs faciaux annotés dans la nature : une base de données réelle à grande échelle pour la localisation des marqueurs faciaux. Actes de la conférence internationale de l'IEEE sur la vision par ordinateur. https://doi.org/10.1109/ICCVW.2011.6130513
- ICG-AFLW. https://www.tugraz.at/institute/icg/research/teambischof/lrs/downloads/afw/. Consulté le 14 octobre 2020
- Tu X, Zhao J, Jiang Z et autres (2019) Reconstruction de visage 3D à image unique assistée par des images de visage 2D dans la nature. IEEE Trans Multimed. https://doi.org/10.1109/TMM.2020.2993962
- Moschoglou S, Papaioannou A, Sagonas C et al (2017) AgeDB : la première base de données d'âge sauvage collectée manuellement. Dans Actes de la conférence IEEE sur la vision par ordinateur et la reconnaissance de formes, pp. 51-59
- Morphace. https://faces.dmi.unibas.ch/bfm/main.php?nav=1-1-0&id=details. Consulté le 14 octobre 2020.
- Savran A, Alyüz N, Dibeklioğlu H et al (2008) Base de données Bosphorus pour l'analyse faciale 3D. Symposium européen sur la biométrie et la gestion de l'identité, Springer, Berlin, Heidelberg, pp. 47-56.
- Base de données d'expressions faciales 3D - Université de Binghamton. http://www.cs.binghamton.edu/~lijun/Research/3DFE/3DFE_Analysis.html. Consulté le 13 octobre 2020.
- Centre de recherche sur la biométrie et la sécurité. http://www.cbsr.ia.ac.cn/english/3DFace Databases.asp. Consulté le 14 octobre 2020.
- Yi D, Lei Z, Liao S, Li SZ (2014) Learning Face Representation from Scratch. Préimpression arXiv arXiv:1411.7923
- Front Side Celebrities in the Wild, http://www.cfpw.io/, consulté le 14 octobre 2020.
- Yang H, Zhu H, Wang Y et autres (2020) FaceScape : ensemble de données de visage 3D de haute qualité à grande échelle et prédiction détaillée de visage 3D orientable. 598-607
- FaceWarehouse. http://kunzhou.net/zjugaps/facewarehouse/. Consulté le 13 octobre 2020.
- Phillips PJ, Flynn PJ, Scruggs T et al (2005) An Overview of the Face Recognition Grand Challenge. En 2005, conférence de l'IEEE Computer Society sur la vision par ordinateur et la reconnaissance de formes (CVPR'05), Vol. 1 : pp. 947-954.
- MORENO, A. (2004) GavabDB : A 3D Face Database. Dans Actes du 2e travail de biométrie Internet COST275, 2004, pp. 75-80
- Le V, Brandt J, Lin Z et al. (2012) Localisation interactive des traits du visage. Notes de cours en informatique (y compris les notes de cours en intelligence artificielle, notes de cours en bioinformatique) 7574 LNCS:679-692. https://doi.org/10.1007 /978-3-642-33712-3_49
- Formulaire de demande d'ensemble de données IJB-A | NIST. https://www.nist.gov/itl/iad/image-group/ijb-dataset-request-form. Consulté le 14 octobre 2020
- Min R, Kose N, Dugelay JL (2014) KinectfaceDB : A Kinect Database for Facial Recognition. IEEE Trans Syst Man, Cybern Syst 44:1534-1548. https://doi.org/10.1109/TSMC.2014.2331215
- Belhumeur PN, Jacobs DW, Kriegman DJ, Kumar N (2011) Localisation des parties du visage à l'aide d'exemples cohérents. Actes de la conférence de l'IEEE Computer Society sur la reconnaissance de formes en vision par ordinateur. https://doi.org/10.1109/CVPR.2011.5995602
- Bagdanov AD, Del Bimbo A, Masi I (2011) Forence 2D/3D Hybrid Face Dataset. En 2011, ACM Joint Studio Workshop on Human Gesture and Behavior Understanding - Actes de J-HGBU '11. ACM Press, New York, États-Unis, p. .79
- Notre Dame CVRL. https://cvrl.nd.edu/projects/data/#nd-2006-data-set. Consulté le 13 octobre 2020.
- Laboratoire d'ingénierie de l'image et de la vidéo, Université du Texas à Austin. http://live.ece.utexas.edu/research/texas3dfr/. Consulté le 14 octobre 2020.
- Le HA, Kakadiaris IA (2017) UHDB31 : A Dataset for Better Understanding of Face Recognition Under Pose and Illumination Changes. Dans les actes du Symposium international IEEE 2017 sur la vision par ordinateur (ICCVW). IEEE, pp. 2555-2563.
- Colombo A, Cusano C, Schettini R (2011) UMB-DB : Une base de données de visages 3D partiellement occultés. Dans les actes de la conférence internationale de l'IEEE sur la vision par ordinateur, pp. 2113-2119.
- Parkhi OM, Vedaldi A, Zisserman A, (2015) Reconnaissance faciale profonde. Pages 1-12
- Sanderson C (2002) Base de données VidTIMIT (n° REP_WORK).IDIAP
- Son Chung J, Nagrani A, Zisserman A, (2018) VoxCeleb2 : Reconnaissance approfondie des empreintes vocales. préimpression arXiv arXiv:1806.05622
- Base de données des visages YouTube : page d'accueil. https://www.cs.tau.ac.il/~wolf/ytfaces/. Consulté le 14 octobre 2020
- 300-VW | Vision par ordinateur en ligne. https://computervisiononline/.com/dataset/1105138793. Consulté le 13 octobre 2020
- i·bug - Ressources - Défi 300 visages dans la nature (300- W), ICCV 2013. https://ibug.doc.ic.ac.uk/resources/300-W/. Consulté le 14 octobre 2020
- Vijayan V, Bowyer K, Flynn P (2011) Jumeaux 3D et défi d'expression. Dans : Actes de la conférence internationale de l'IEEE sur la vision par ordinateur. pages 2100 à 2105
- AI + X : Ne changez pas de carrière, rejoignez AI - YouTube. http://www.youtube.com/watch?v=4Ai7wmUGFNA. Consulté le 5 février 2021
- Cao C, Hou Q, Zhou K (2014) Régression des expressions dynamiques de déplacement pour le suivi et l'animation des visages en temps réel. Dans : Transactions ACM sur les graphiques. Association pour les machines informatiques, pp 1-10
- Bouaziz S, Wang Y, Pauly M (2013) Modélisation en ligne pour l'animation faciale en temps réel. Graphique trans ACM 32 : 1–10. https://doi.org/10.1145/2461912.2461976
- Garrido P, Valgaerts L, Sarmadi H et al (2015) VDub : Modification des vidéos du visage d'un acteur pour un alignement visuel convaincant avec des pistes audio doublées. Forum d'infographie 34 : 193-204. https://doi.org/10.1111/cgf.12552
- Thies J, Zollhöfer M, Stamminger M et al. Face2Face : capture et relecture de visages en temps réel à partir d'une vidéo RVB
- Introduction au Deep Learning du MIT | 6.S191 - YouTube. https://www.youtube.com/watch?v=5tvmMX8r_OM. Consulté le 8 février 2021
- Garrido P, Valgaerts L, Wu C, Theobalt C (2013) Reconstruction de la géométrie faciale dynamique détaillée à partir de vidéos monoculaires. Graphique trans ACM 32 : 1–10. https://doi.org/10.1145/2508363.2508380
- Viswanathan S, Heisters IES, Evangelista BP et al. (2021) Systèmes et procédés pour générer des effets de maquillage en réalité augmentée. Brevet américain 10 885 697
- Nam H, Lee J, Park JI (2020) Système interactif de maquillage des lèvres AR pixel par pixel utilisant une caméra RVB. Journal d'ingénierie de radiodiffusion 25(7):1042-51
- Siegl C, Lange V, Stamminger M et al. FaceForge : Cartographie multi-projection de visages non rigides sans marqueur
- Remplacer les visages dans une vidéo à l'aide des outils d'image fixe et de visage - Tutoriels After Effects - YouTube. https://www.youtube.com/watch?v=x7T5jiUpUiE. Consulté le 6 février 2021
- Antipov G, Baccouche M et Dugelay JL, (2017), Face Aging with Conditional Generative Adversarial Networks. Dans : Conférence internationale de l'IEEE sur le traitement d'images (ICIP), pp. 2089-2093
- Shi C, Zhang J, Yao Y et autres (2020) CAN-GAN : Réseaux contradictoires génératifs normalisés à attention conditionnelle pour la synthèse de l'âge du visage. Lettres de reconnaissance de formes 138 : 520-526. https://doi.org/10.1016/j.patrec.2020.08.021
- Fang H, Deng W, Zhong Y, Hu J (2020) Triple-GAN : vieillissement progressif du visage grâce à la triple perte de transformation. Dans : Symposium de la réunion de l'IEEE Computing Society sur la reconnaissance de formes en vision par ordinateur, juin 2020 : 3500-3509. https://doi.org/10.1109/CVPRW50498.2020.00410
- Huang Z, Chen S, Zhang J, Shan H (2020) PFA-GAN : Progressive Face Aging with Generative Adversarial Networks. Transactions IEEE sur l'investigation et la sécurité de l'information. https://doi.org/10.1109/TIFS.2020.3047753
- Liu S, Li D, Cao T et autres (2020) Édition des attributs de visage basée sur le GAN. Subvention IEEE 8 : 34854-34867. https://doi.org/10.1109/ACCESS.2020.2974043
- Yadav D, Kohli N, Vatsa M et autres (2020) Réducteur d'écart d'âge-GAN pour reconnaître les visages espacés selon l'âge. Dans : 25e Conférence internationale sur la reconnaissance de formes (ICPR), pp 10090-10097
- Sharma N, Sharma R, Jindal N (2020) Techniques améliorées pour la progression de l'âge du visage et super-résolution améliorée à l'aide de réseaux contradictoires génératifs. Wireless Personal Communications 114:2215-2233. https://doi.org/10.1007/s11277-020 - 07473-1
- Liu L, Yu H, Wang S et autres (2021) Apprentissage des processus de forme et de texture pour le vieillissement du visage chez les enfants. Signal Processing Image Communications 93:116127. https://doi.org/10.1016/j.image.2020.116127
- Nirkin Y, Keller Y, Hassner T (2019) FSGAN : Remplacement et reconstitution de visages indépendants du sujet. Dans : Actes de la conférence internationale IEEE/CVF sur la vision par ordinateur, pp. 7184-7193.
- Tripathy S, Kannala J, Rahtu E (2020) ICface : Reconstitution de visages interprétables et contrôlables à l'aide de GAN. Dans : Actes de la conférence d'hiver IEEE/CVF sur les applications de vision par ordinateur, pp. 3385-3394
- Ha S, Kersner M, Kim B et autres (2019) MarioNETte : reconstitution de visages à quelques coups de feu qui préserve l'identité des cibles invisibles. arXiv 34 : 10893-10900
- Zhang J, Zeng † Xianfang, Wang M et autres (2020) FreeNet : Reconstitution de visages multi-identités. Dans : Actes de la conférence IEEE/CVF sur la vision par ordinateur et la reconnaissance de formes, pp. 5326-5335.
- Zeng X, Pan Y, Wang M et al. (2020) Découplage auto-supervisé de l'identité et de la pose pour une reconstitution réaliste du visage. arXiv 34:12757-12764
- Ding X, Raziei Z, Larson EC et al (2020) Détection d'échange de visages à l'aide de l'apprentissage profond et de l'évaluation subjective. EURASIP Journal of Information Security, pp.
- Zukerman J, Paglia M, Sager C et al. (2019) Manipulation vidéo et remplacement du visage. Brevet américain 10 446 189
- Hoshen D (2020) MakeupBag : séparation de l'extraction et de l'application du maquillage. Préimpression arXiv rXiv : 2012.02157.
- Li Y, Huang H, Yu J et al (2020) Nettoyants de maquillage soucieux de la beauté. Préimpression arXiv arXiv:2004.09147
- Horita D, Aizawa K (2020) SLGAN : Réseaux contradictoires génératifs guidés par le style et la latente pour un transfert et un retrait de maquillage idéaux. Préimpression arXiv arXiv : 2009.07557
- Wu W, Zhang Y, Li C et al (2018) ReenactGAN : Apprendre à reproduire des visages via un transfert de frontière. Dans : Actes de la Conférence européenne sur la vision par ordinateur (ECCV), pp. 603-619.
- Nirkin Y, Wolf L, Keller Y, Hassner T (2020) Détection DeepFake basée sur les différences entre les visages et leur contexte.Préimpression arXiv arXiv :2008.12262.
- Tolosana R, Vera-Rodriguez R, Fierrez J et al (2020) Deepfakes et leurs conséquences : une enquête sur la manipulation faciale et la détection d'hypothèses. Information Fusion 64 : 131-148
- Shubham K, Venkatesh G, Sachdev R et al (2020) Apprendre une politique d'apprentissage par renforcement profond pour les opérations d'âge sémantique sur l'espace latent des GAN pré-entraînés. Dans : Conférence internationale conjointe 2021 sur les réseaux de neurones (IJCNN), pp. 1-8. .IEEE
- Karras T, Aila T, Laine S, Lehtinen J (2017) Croissance progressive des GAN pour améliorer la qualité, la stabilité et la variation.Préimpression arXiv arXiv:1710.10196
- Pham QTM, Yang J, Shin J (2020) FaceGAN semi-supervisé pour la progression et la régression de l'âge du visage avec des images synthétiques appariées. Électronique 9 : 1-16. https://doi.org/10.3390/electronics9040603
- Zhu H, Huang Z, Shan H, Zhang J (2020) Observation globale, vieillissement local : vieillissement du visage avec mécanisme d'attention Haiping Zhu Zhizhong Huang Hongming Shan Laboratoire clé de traitement intelligent de l'information de Shanghai, École d'informatique, Université de Fudan, Chine, 200433 ICASSP 2020-2020 Actes de la Conférence internationale de l'IEEE sur le traitement de l'audio, de la parole et du signal 1963-1967
- Wu S, Rupprecht C, Vedaldi A (2021) Apprentissage non supervisé d'objets 3D éventuellement symétriques déformables dans des images dans la nature. IEEE Trans Pattern Anal Mach Intell. https://doi.org/10.1109/TPAMI.2021.3076536
- Heidekrueger PI, Juran S, Szpalski C et al (2017) Proportions actuelles des lèvres préférées chez les femmes. J Cranio-Maxillofacial Surg 45:655-660. https://doi.org/10.1016/j.jcms.2017.01.038
- Baudoin J, Meuli JN, di Summa PG et al (2019) Un guide complet sur la restauration cosmétique de la lèvre supérieure. J Cosmet Dermatol 18:444-450
- Garrido P, Zollhöfer M, Wu C et al. (2016) Reconstruction 3D corrigée des lèvres à partir d'une vidéo monoculaire. ACM Trans Graph 35:1-11. https://doi.org/10.1145/2980179.2982419
- Wu C, Bradley D, Garrido P et al. (2016) Reconstruction dentaire basée sur un modèle. ACM Trans Graph 35(6):220-221. https://doi.org/10.1145/2980179.2980233
- Wen Q, Xu F, Lu M, Yong JH (2017) Suivi des paupières 3D en temps réel à partir des bords sémantiques. ACM Trans Graph 36:1-11. https://doi.org/10.1145/3130800.3130837.
- Wang C, Shi F, Xia S, Chai J (2016) Animation du regard 3D en temps réel à l'aide d'une seule caméra RVB. ACM Trans Graph 35:1-14. https://doi.org/10.1145/2897824.2925947.
- Zhou X, Lin J, Jiang J, Chen S (2019) Apprendre un itracker amélioré combiné avec un LSTM bidirectionnel pour l'estimateur de regard 3D. Dans : Actes de l'IEEE International Multimedia and Exposition. IEEE Computer Society, pp 850-855.
- Li H, Hu L, Saito S (2020) Synthèse capillaire 3D à l’aide d’auto-encodeurs variationnels volumétriques. ACM Transactions on Graphics (TOG) 37(6):1-12
- Ye Z, Li G, Yao B, Xian C (2020) HAO-CNN : Reconstruction consciente des cheveux basée sur le champ vectoriel volumétrique. Comput Animat Virtual Worlds 31:e1945. https://doi.org/10.1002/cav.1945
- He H, Li G, Ye Z et autres (2019) Reconstruction de la tête humaine 3D basée sur les données. Comput Graph 80:85-96. https://doi.org/10.1016/j.cag.2019.03.008
Déclaration de l'éditeur : Springer Nature maintient sa neutralité en ce qui concerne les réclamations juridiques dans la publication de cartes et d'affiliations institutionnelles.