Table des matières
- avant-propos
- Pré-connaissance
- Le contenu des cours
-
- 1. [Cache niveau 3] raisonnement évolutif
- Deuxièmement, l'analyse du code source sous-jacente (extension)
- résumer
avant-propos
préparation à la lecture
Examen passé :
- Analyse des principes fondamentaux sous-jacents de Spring [difficulté d'apprentissage : ★★☆☆☆ ]
- Analyse manuscrite du processus du conteneur Spring simple【Difficulté d'apprentissage : ★★☆☆☆】
- Analyse des concepts fondamentaux de l'architecture sous-jacente de Spring [difficulté d'apprentissage : ★★★☆☆ , degré d'importance : ★★★★★ ]
- Organigramme du cycle de vie de Bean [difficulté d'apprentissage : ☆☆☆☆☆ , degré d'importance : ★★★★★ ]
- Analyse du code source du cycle de vie du haricot au printemps ——Phase 1 (Scan pour générer la définition du haricot) [Difficulté d'apprentissage : ★★☆☆☆ , Importance : ★★★☆☆ ]
- Analyse du code source du cycle de vie des haricots au printemps — Phase 2 (1) (Instanciation de l'IOC) [Difficulté d'apprentissage : ★★★★★ , Importance : ★★★☆☆ ]
- Analyse du code source du cycle de vie des haricots au printemps — Phase 2 (2) (remplissage d'attributs IOC/injection de dépendances) [Difficulté d'apprentissage : ★★★★★ , Importance : ★★★★★ ]
conseils de lecture
- Regardez le code source, n'oubliez pas de vous emmêler dans les détails, sinon il est facile de rester bloqué. Normalement, il suffit de regarder le processus principal
- Si vous ne comprenez pas, regardez les annotations de classe ou les annotations de méthode. Spring est un excellent code source, les annotations sont vraiment en place
- Si vous êtes un utilisateur d'idées, utilisez davantage la fonction de signet de F11.
- Ctrl + F11 Sélectionnez les fichiers/dossiers, utilisez des mnémoniques pour définir/annuler les signets (obligatoire)
- Maj + F11 Couche d'affichage des favoris contextuels (obligatoire)
- Ctrl +1,2,3...9 Localiser la position du signet de la valeur correspondante (obligatoire)
Pré-connaissance
Cycle de vie du haricot
Le cycle de vie d'un bean fait référence à : comment un bean est-il généré au printemps ? Les étapes de génération du Bean sont les suivantes : (PS : nous ne décrirons pas ici le cycle de vie du Bean en détail, nous décrirons uniquement le processus général)
- Instancier les beans selon beanDefinition
- Remplir les propriétés dans l'objet d'origine (injection de dépendances)
- avant l'initialisation
- initialisation
- après initialisation
- Mettez le bean généré dans le pool singleton
Placez l'objet proxy final généré dans le pool singleton (appelé singletonObjects dans le code source) et récupérez-le directement du pool singleton la prochaine fois que vous obtiendrezBean
Génération de dépendances circulaires
En ce qui concerne les dépendances circulaires, tout le monde les connaît. Le code des dépendances circulaires est le suivant :
@Component
public class CircularA {
@Autowired
CircularB b;
}
@Component
public class CircularB {
@Autowired
CircularA a;
}
Mais avez-vous déjà réfléchi à la manière dont les dépendances circulaires sont générées et à la manière de les résoudre ? Ici, je veux vous faire une déduction, tout comme nous sommes des auteurs Spring, réfléchissant à la façon de résoudre les dépendances circulaires.
Trois cartes au printemps
Ici, je veux quand même vous donner une introduction générale à l'avance, lors de l'obtention d'un bean singleton, quelles sont les trois Maps qui apparaissent dans le code source de Spring et ce qui est utilisé pour les stocker. Ils sont les suivants :
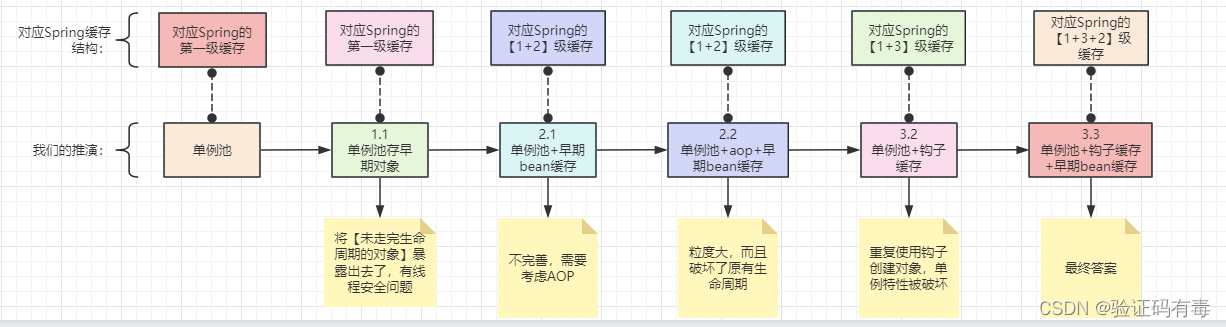
Map<String, Object> singletonObjects: Cache niveau 1. C'est ce que nous appelons souvent le pool singleton, les haricots stockés ici,Il a parcouru le cycle de vie complet de Spring, [terminé le cycle de vie conçu par Spring](Faire l'expérience du cycle de vie complet ici ne signifie pas que vous devez passer par avant et après l'instanciation, avant et après l'initialisation. En termes simples, c'est : Bean mature approuvé par Spring)Map<String, Object> earlySingletonObjects: Cache de deuxième niveau. Directement traduit, ce qui est stocké ici est [Early Singleton Bean]. Qu'est-ce qui est tôt ? C'est par rapport au précédent [Mature Bean],[Bean qui n'a pas encore terminé son cycle de vie]。Map<String, ObjectFactory<?>> singletonFactories:Cache L3. La traduction littérale est [usine de haricots singleton]. En fait, j'aime toujours utiliser un nom propre mentionné précédemment pour expliquer :Mise en cache par méthode Hook des beans de production。
Le contenu des cours
Remarque : L'organigramme du cycle de vie du bean dans la figure ci-dessous ne représente pas le cycle réel. Pour plus de commodité, j'ai juste effectué quelques traitements.
1. [Cache niveau 3] raisonnement évolutif
1. Uniquement le raisonnement évolutif du cache de premier niveau
Regardons d'abord une image. Avant qu'il n'y ait pas de cache de troisième niveau, lorsqu'il n'y a qu'un seul cache de premier niveau, si A dépend de B et B dépend de A, alors le phénomène suivant se produira :
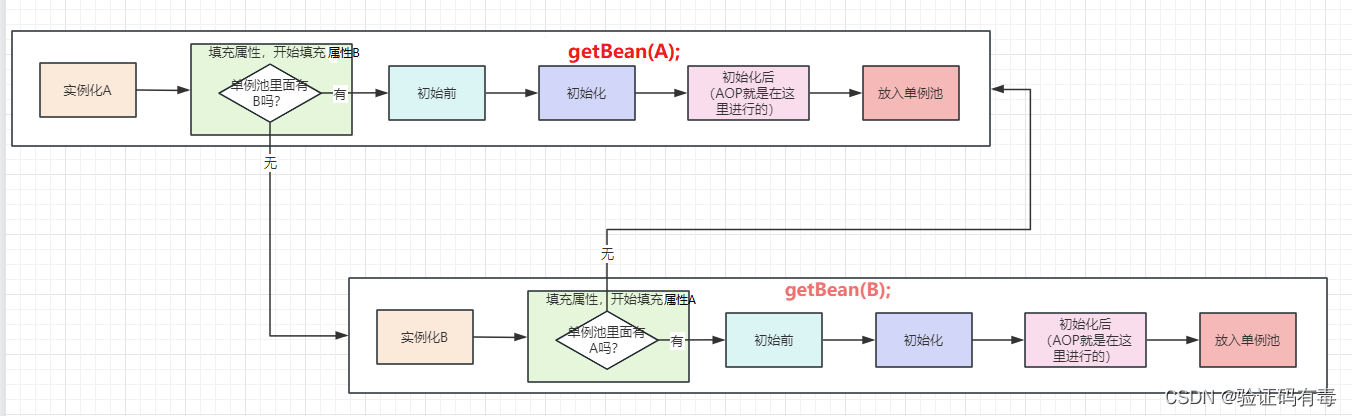
Évidemment, dans le processus de notre création initiale, il n'y aura ni objet B ni objet A dans le pool singleton. Après tout, ils n'ont atteint que la deuxième étape [injection d'attributs], et c'est dans la dernière étape qu'ils mettent les objets générés dans le pool singleton. Par conséquent, dans la situation de l’image ci-dessus, s’il n’y a pas d’intervention externe, une boucle fermée se forme entre les deux beans, qui ne peut pas être déliée. Ce n’est évidemment pas le résultat que nous souhaitons, n’est-ce pas ? Alors comment résoudre ce problème ?
1.1 Placer directement l'objet généré après l'instanciation dans le pool singleton
À l’heure actuelle, une pensée tout à fait normale est la suivante : ne serait-il pas bien si je le mettais à l’avance dans le pool singleton, comme indiqué ci-dessous :
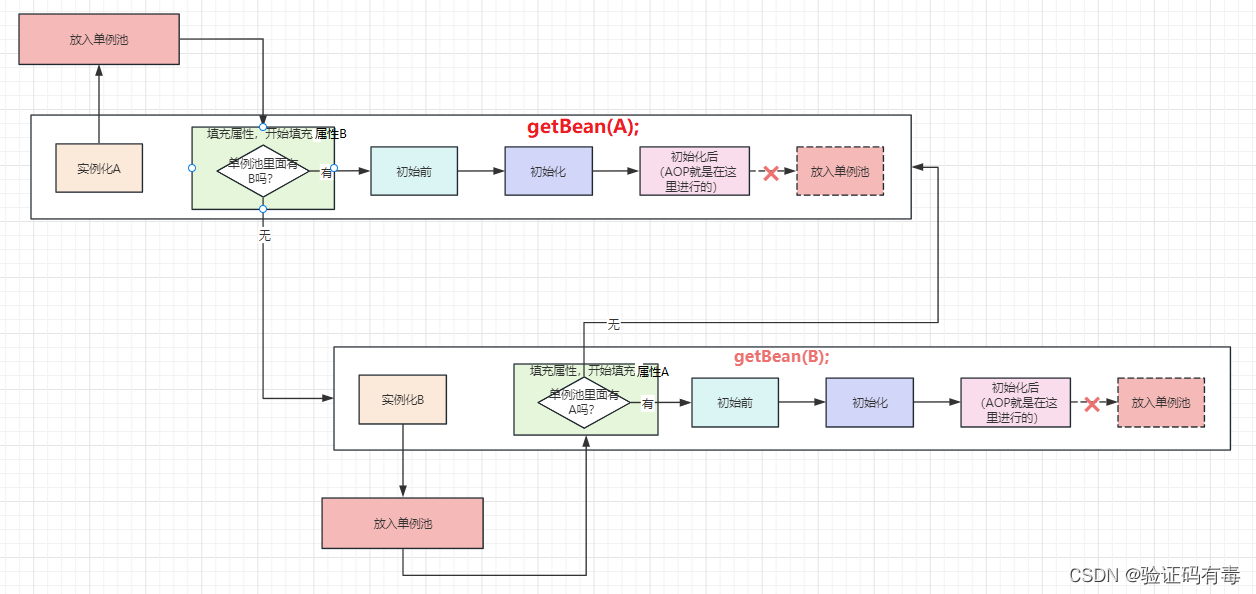
n’est-il pas cassé ? Hehehe,
je peux seulement dire que cela a du sens, mais pas grand-chose. Étant donné que Spring prend en fait des objets du pool singleton, cela équivaut à exposer à l'avance [ les objets semi -finis qui n'ont pas terminé leur cycle de vie ] . De cette façon, dans un environnement multithread, si quelqu'un vient accéder au pool singleton, obtient directement ce BeanA, puis y appelle la méthode, s'il n'y a pas d'[injection de propriété], ne serait-ce pas G ? Oui, c'est un problème de sécurité de concurrence ! Ici, nous ne pouvons transmettre ce schéma que directement.
PS : Bien sûr, je sais que certaines personnes diront que verrouiller le cache de premier niveau peut le résoudre, ah, oui, c'est possible. Mais vous êtes-vous déjà demandé ce qu'il en était de la performance...
1.2 Résumé
- Après l'instanciation, [ les objets semi-finis qui n'ont pas terminé leur cycle de vie ] sont placés dans le pool singleton, ce qui entraînera des problèmes de sécurité des threads
(PS : Faites attention à la conclusion ici, elle sera testée plus tard !!! /狗头/狗头)
2. Présentation du raisonnement évolutif du cache de deuxième niveau
2.1 Introduire un premier objet après l'instanciation d'un stockage de carte intermédiaire (cache de deuxième niveau suspecté)
Une réflexion tout à fait normale, j'ajoute une nouvelle carte et la sauvegarde immédiatement après l'instanciation. Quoi qu'il en soit, il a déjà été instancié et l'adresse a été corrigée. Peu importe la façon dont vous opérerez plus tard, vous opérerez sur l'objet à cette adresse. Exposer cet objet à l'avance n'affectera pas du tout le résultat.
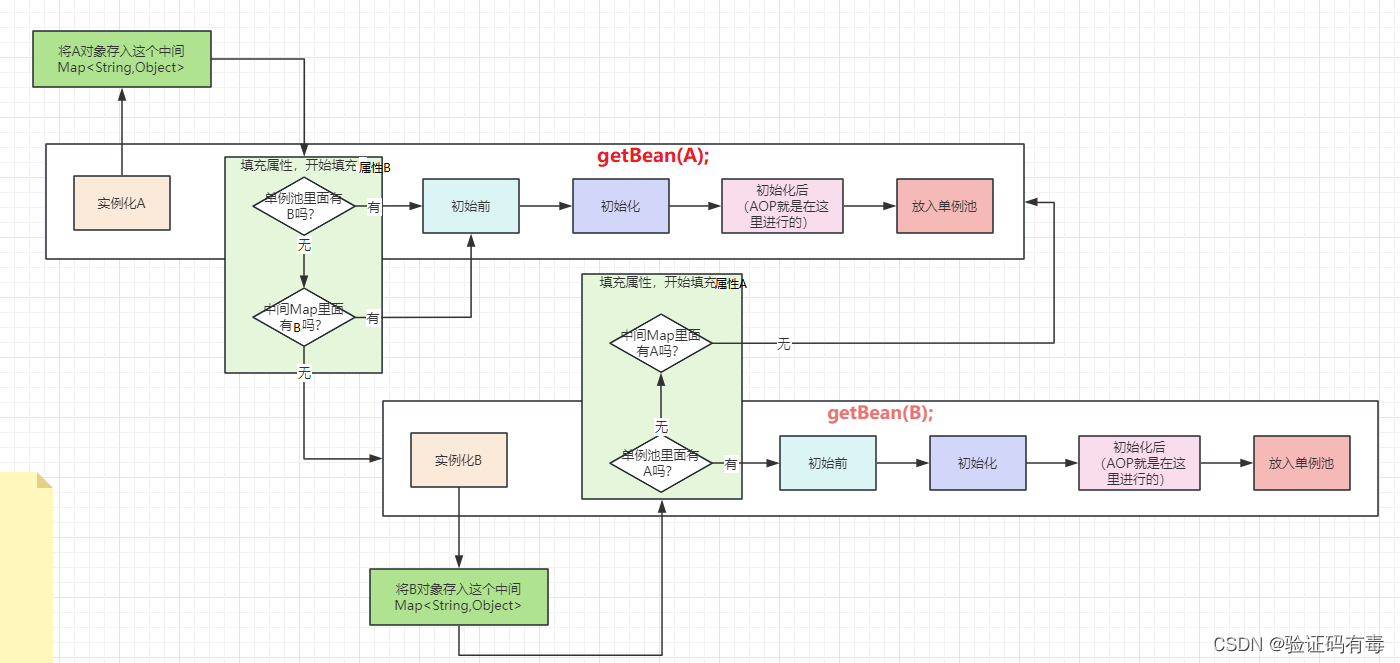
Comme le montre la figure ci-dessus, j'ajoute alors un cache intermédiaire Map pour stocker les objets précédemment instanciés, est-ce possible ? Eh bien, à en juger par l’organigramme, cela semble vraiment être la réponse finale.
Cependant, si je vous demande [que faire avec AOP] ou pour être précis, ce dont vous avez besoin c'est [que faire avec l'objet proxy], comment répondrez-vous ?? Évidemment, cette table intermédiaire stocke l'objet d'origine, mais parfois j'ai besoin d'un objet proxy. Vous voyez, après un petit examen, il y a un autre problème. Eh bien, continuons à améliorer ce plan.
(PS : cette question signifie que nous devons considérer le proxy AOP à l'avance à cette étape. Tout le monde devrait se souvenir de cette conclusion)
(Remarque : je donne juste un exemple de la nécessité d'AOP. En fait, il fait référence à tout processus qui nécessite un proxy. Pensez-vous qu'il existe une situation de proxy à plusieurs niveaux)
(Remarque : je donne juste un exemple de la nécessité d'AOP. En fait, il fait référence à tout processus qui nécessite un proxy. Pensez-vous qu'il existe une situation de proxy à plusieurs niveaux)
(Remarque : je donne juste un exemple de la nécessité d'AOP. En fait, il fait référence à tout processus qui nécessite un proxy. Pensez-vous qu'il existe une situation de proxy à plusieurs niveaux)
2.2 Résoudre le problème de la nécessité d'être proxy dans la version 2.1 (cache de deuxième niveau suspecté)
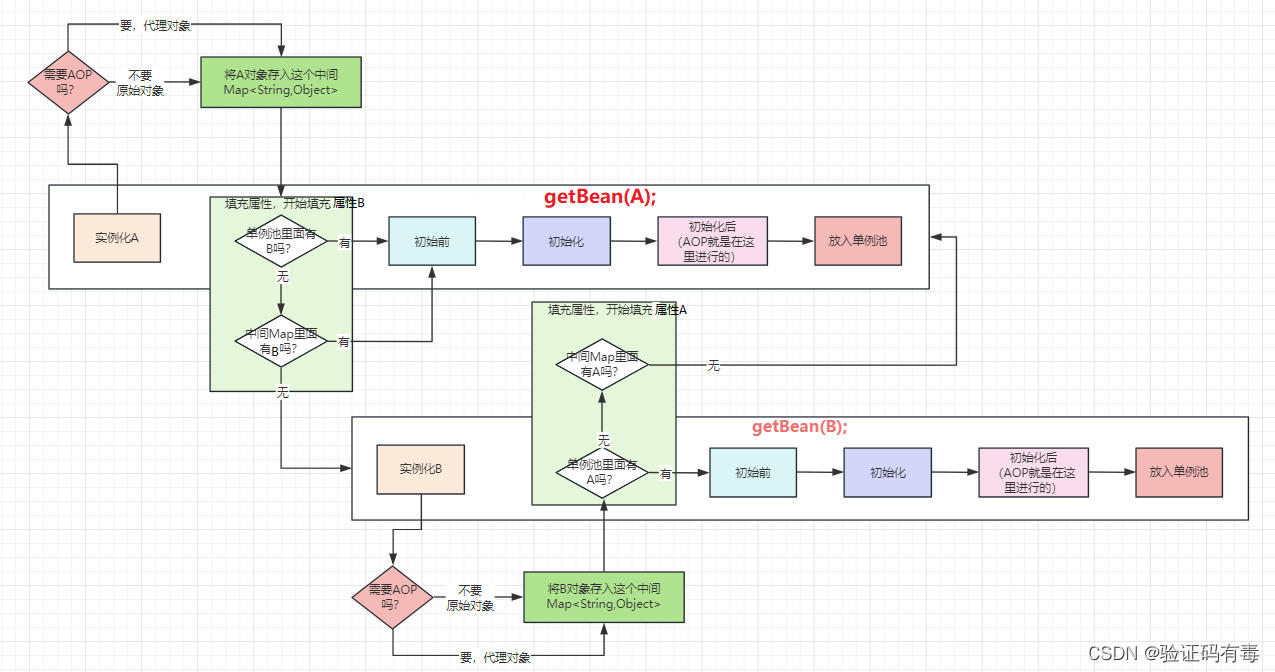
Voilà, ajoutez simplement une étape supplémentaire au processus AOP, hehehe. Mais selon la pratique habituelle, je l'ai déjà fait [hehehe], donc je dois demander : est-ce que ça va vraiment ? Ha, vraiment ! Tout va vraiment bien. Alors pourquoi avons-nous besoin d’un cache de troisième niveau ?
3. Présentation du raisonnement évolutif du cache de troisième niveau
3.1 Pourquoi le cache L3
À ce stade, je suis sur le point de commencer à faire semblant. (Je soupçonne même que Spring fait semblant d'écrire comme ça, haha, je plaisante) En fait, il y a

beaucoup d'arguments sur Internet, j'ai aussi résumé les points forts de centaines d'écoles, combinés avec ce que mon professeur a dit en classe , et a conclu les conclusions suivantes :
- le cycle de vie est rompu!Je pense que c'est la raison la plus importante, mais c'est aussi difficile à comprendre. Comment le comprenez-vous ? Vous souvenez-vous de la façon dont j'ai décrit le printemps pour la première fois ? Quel est le cœur du Printemps ? Savez-vous à quelle partie du cycle de vie du bean se situe la mise en œuvre de l'AOP ?
- La première question : Spring est un conteneur IOC qui implémente la technologie AOP
- La deuxième question : le noyau de Spring est IOC et AOP, mais toutes les fondations viennent d'IOC
- La troisième question : AOP est implémenté dans la phase [post-initialisation] du cycle de vie du bean. parce que,L'implémentation actuelle de la technologie AOP repose également sur certains des nombreux points d'extension fournis par Spring.. Par exemple, l'implémentation d'AOP utilise : BeanPostProcessor. Quel est le sens révélé ici ? Je pense que cela signifie :Dans Spring, AOP est simplement utilisé comme extension supplémentaire.. C'est comme si nous implémentions Mybatis basé sur le point d'extension de Spring et SpringMVC.
PS : Alors, quand vous arrivez ici, savez-vous comment comprendre cela [ le cycle de vie est rompu ] ? Si nous jugeons si nous devons faire AOP après l'instanciation, cela signifie que nous n'avons pas fait [injection de propriété], [avant initialisation], [initialisation], [après initialisation] et d'autres cycles de vie, nous devons commencer à le faire AOP, déplacer directement le processus AOP de [après initialisation] vers [avant l'injection d'attributs]. Et, lors du processus d’implémentation de cet AOP, vous devez appeler une méthode similaire à la suivante :
for(BeanPostProcessor bp : this.beanPostProcessorsCache) { bp.postProcessAfterInitialization(bean); }Mais ce code sera en réalité appelé plus tard [après initialisation]. Je suppose que certains amis diront ceci : puis-je parcourir les BeanPostProcessors spécifiés qui implémentent AOP ? Eh bien, ça marche vraiment. Cependant, comme mentionné ci-dessus, si nous le regardons du point de vue de Spring : AOP n'est qu'une extension de mon IOC. De ce point de vue, cette implémentation est un peu intrusive, et la sémantique a également légèrement changé.
- Les dépendances cycliques se produisent fréquemment. Je pense que j'aimerais demander à tout le monde : avez-vous beaucoup de dépendances circulaires dans vos scénarios d'utilisation réels ? Frère, j'écris du code Java depuis plus de 4 ans et je ne me souviens que de quelques fois. alors, que diriez-vous de revenir sur la solution ci-dessus ?Il porte un jugement à chaque fois qu'il instancie et génère un bean! Est-ce un peu redondant ?
- style de code. C’est très abstrait de dire cela, ce n’est pas une déclaration très courante, mais cela a du sens. Comment comprendre cette phrase ?
En fait, 2 et 3 devraient être combinés et construits sur la dernière lutte de [1], c'est-à-dire que je dois encore commencer à juger [si l'AOP est nécessaire] une fois que [l'instanciation] est terminée. Tout d’abord, vous souvenez-vous encore de la raison pour laquelle l’AOP devrait être jugée à l’avance ? En raison de la nécessité de dépendances circulaires. autrement dit,Nous devons en fait [juger s'il s'agit d'AOP] quand [il y a une dépendance circulaire], n'est-ce pas ? Autrement dit, quand [il n'y a pas de dépendance circulaire], il n'est pas du tout nécessaire. Donc, si vous jugez directement l’AOP ici, la granularité est-elle trop grande ?
3.2 Résoudre le problème de 3.1 [grande granularité]
Je pense qu'en réponse au problème de la "grande granularité", ces étudiants très intelligents ont déjà pensé à la conception du "cache de troisième niveau" dont je vous ai parlé plus tôt. Hé, je l'ai conçu comme un cache à fonction hook. , Même le cache de deuxième niveau composé de Spring [Niveau 1 + Niveau 3] peut-il également résoudre le problème de la grande granularité ? (C'est un peu difficile à comprendre, veuillez lire attentivement l'expression lambda), comme suit :
(PS : La carte correspond au cache de troisième niveau de Spring)
Map<String, ObjectFactory<?>> singletonFactories = new HashMap<>(16)
singletonFactories.put(beanName, ()->{
determinedAop(bean);});
void determinedAop(Object bean) {
Object exposedObject = object;
if (object 是否需要被代理) {
exposedObject = 代理对象obejct;
}
return exposedObject;
}
Oui, ça ressemble un peu à ça. Cependant, il manque encore un jugement, celui de juger [s'il existe une dépendance circulaire]. C'est également facile à gérer, il suffit de juger si la carte mentionnée ci-dessus a une valeur ou non. (PS : je pense que oui. Mais un nouvel ensemble a été ajouté au printemps pour stocker le nom du bean en cours de création. Pour les amis intéressés, veuillez lire mon dernier contenu.) Mais est-ce suffisant
? pas assez. Pourquoi, que se passe-t-il si j'ai une troisième classe qui nécessite une dépendance circulaire ? Comme suit:
@Component
public class CircularA {
@Autowired
CircularB b;
@Autowired
CircularC c;
}
@Component
public class CircularB {
@Autowired
CircularA a;
}
@Component
public class CircularC {
@Autowired
CircularA a;
}
L'effet est le suivant :
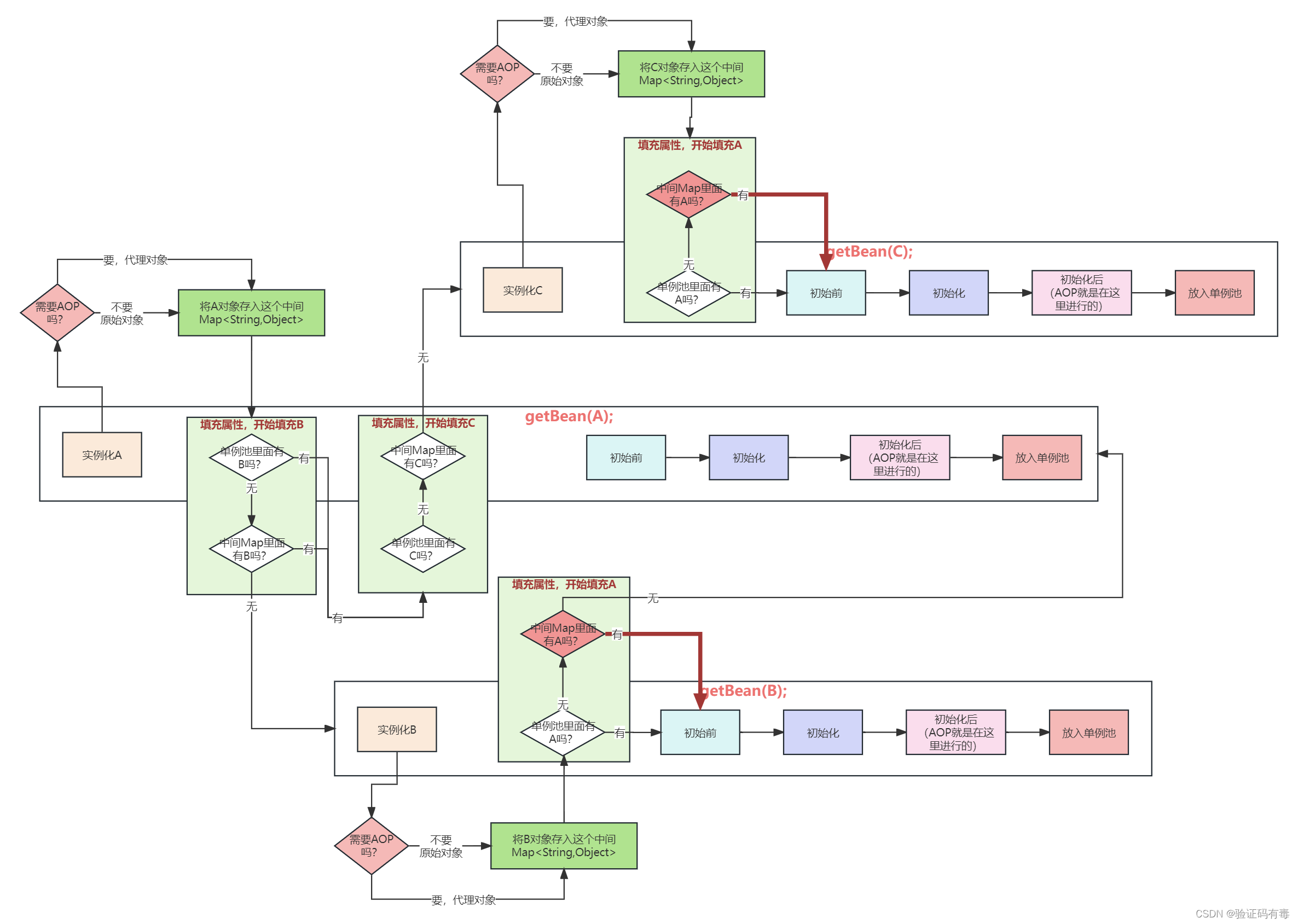
vous ne pourrez peut-être pas le voir à travers l'image, je vous le rappellerai donc directement. Ce qui suit :
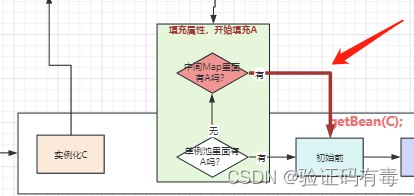
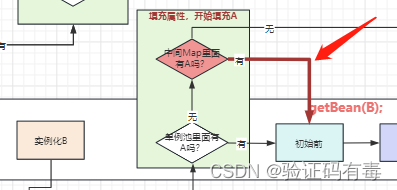
étant donné que la carte intermédiaire au-dessus de vous stocke une fonction de rappel, s'il existe un proxy pour cette fonction, renvoyez-vous un nouvel objet à chaque fois ? ? ? Ce n'est évidemment pas conforme à nos attentes, cas unique, le A injecté dans B et C devrait être le même ! ce qu'il faut faire? Enregistrez-le simplement. Mais peut-il être mis directement dans le pool singleton ? Non, tu sais pourquoi ? Ha, la raison est la même que pour la version 1.1.
3.3 Résoudre le problème généré en appelant plusieurs fois la fonction hook dans 3.2
Par conséquent, une autre carte de cache est introduite ici pour mettre en cache les beans mentionnés ci-dessus. Appelez-le ici : haricots précoces.(PS : La carte correspond au cache de deuxième niveau de Spring)
Jusqu'à présent, le cache de troisième niveau a été introduit. Les étudiants sont-ils inutiles ?

3.4 Comment juger s'il existe une dépendance circulaire (pas si important)
Comme mentionné ci-dessus, pour juger s'il existe une dépendance circulaire, même si je pense que la carte de troisième niveau peut être utilisée pour juger, après tout, cette existence représente également [la création]. Mais Spring a ajouté un nouvel ensemble pour stocker le nom du bean en cours de création. Pourquoi il en est ainsi, je pense qu'il y a plusieurs raisons :
- Cette carte de cache de troisième niveau sera théoriquement supprimée immédiatement après utilisation. Quels sont les avantages de faire cela ? Dans une certaine mesure, le risque d'appels multiples est réduit ;
- Maintenant, il est
singletonsCurrentlyInCreationjugé par un ensemble appelé Set. Ensuite, les grands peuvent cliquer pour voir où ce jugement est référencé, et vous constaterez qu'il existe de nombreuses références et que le cycle de vie couvert est plus large. Ou disons-le autrement, de nombreux endroits doivent juger si le bean est en train de [créer], donc un nouvel ensemble est ajouté pour le sauvegarder. L'utilisation de la carte de troisième niveau pour juger n'est applicable qu'à la scène de [dépendance circulaire]. Donc, comme il existe déjà un ensemble, utilisez-le directement et la sémantique est plus claire.
3.5 Mention spéciale
Attention, ce que j'ai fait dans la 3.1, 3.2 et 3.3 c'est juste pour améliorer le plan 2.2. Vous souvenez-vous encore de la conclusion de la 2.2 ? [Nous devons considérer l'AOP à l'avance à cette étape], c'est-à-dire que c'est inévitable, et le plan d'amélioration ultérieur consiste simplement à réduire la granularité autant que possible.
4. Résumé
Ah, j'ai bien peur de ne pas avoir été clair. J'ai aussi peur que tout le monde n'ait pas compris. Donnez un autre diagramme d’évolution du raisonnement.
Deuxièmement, l'analyse du code source sous-jacente (extension)
L'entrée du code source de la dépendance circulaire se trouve ici. AbstractAutowireCapableBeanFactory#doCreateBean()En regardant le nom, vous devriez être quelque peu impressionné, n'est-ce pas ? Ne transmettez pas également cette méthode lors de l'instanciation. En fait, à proprement parler, le code source ici n’a rien à dire, l’essentiel est de comprendre ses principes sous-jacents. Laissez-moi le publier pour vous avec désinvolture, veuillez faire attention aux commentaires à l'intérieur, je le marquerai pour vous dans le code lié à [dépendance circulaire] :
protected Object doCreateBean(String beanName, RootBeanDefinition mbd, @Nullable Object[] args)
throws BeanCreationException {
// 实例化bean
BeanWrapper instanceWrapper = null;
if (mbd.isSingleton()) {
instanceWrapper = this.factoryBeanInstanceCache.remove(beanName);
}
if (instanceWrapper == null) {
instanceWrapper = createBeanInstance(beanName, mbd, args);
}
Object bean = instanceWrapper.getWrappedInstance();
Class<?> beanType = instanceWrapper.getWrappedClass();
if (beanType != NullBean.class) {
mbd.resolvedTargetType = beanType;
}
// 合并beanDefinition Bean后置处理器
synchronized (mbd.postProcessingLock) {
if (!mbd.postProcessed) {
try {
applyMergedBeanDefinitionPostProcessors(mbd, beanType, beanName);
}
catch (Throwable ex) {
throw new BeanCreationException(mbd.getResourceDescription(), beanName,
"Post-processing of merged bean definition failed", ex);
}
mbd.postProcessed = true;
}
}
// 【循环依赖】关键源码一
// 这里就是我们在分析中说的注册钩子方法,判断是否需要【循环依赖】
boolean earlySingletonExposure = (mbd.isSingleton() && this.allowCircularReferences &&
isSingletonCurrentlyInCreation(beanName));
if (earlySingletonExposure) {
if (logger.isTraceEnabled()) {
logger.trace("Eagerly caching bean '" + beanName +
"' to allow for resolving potential circular references");
}
addSingletonFactory(beanName, () -> getEarlyBeanReference(beanName, mbd, bean));
}
// 【循环依赖】关键源码二
// 但是这里看不出来,因为AOP就是在下面的initializeBean里面的,需要挖掘一下才能找到
Object exposedObject = bean;
try {
populateBean(beanName, mbd, instanceWrapper);
exposedObject = initializeBean(beanName, exposedObject, mbd);
}
catch (Throwable ex) {
if (ex instanceof BeanCreationException && beanName.equals(((BeanCreationException) ex).getBeanName())) {
throw (BeanCreationException) ex;
}
else {
throw new BeanCreationException(
mbd.getResourceDescription(), beanName, "Initialization of bean failed", ex);
}
}
// 【循环依赖】关键源码三
if (earlySingletonExposure) {
Object earlySingletonReference = getSingleton(beanName, false);
if (earlySingletonReference != null) {
if (exposedObject == bean) {
exposedObject = earlySingletonReference;
}
else if (!this.allowRawInjectionDespiteWrapping && hasDependentBean(beanName)) {
String[] dependentBeans = getDependentBeans(beanName);
Set<String> actualDependentBeans = new LinkedHashSet<>(dependentBeans.length);
for (String dependentBean : dependentBeans) {
if (!removeSingletonIfCreatedForTypeCheckOnly(dependentBean)) {
actualDependentBeans.add(dependentBean);
}
}
if (!actualDependentBeans.isEmpty()) {
throw new BeanCurrentlyInCreationException(beanName,
"Bean with name '" + beanName + "' has been injected into other beans [" +
StringUtils.collectionToCommaDelimitedString(actualDependentBeans) +
"] in its raw version as part of a circular reference, but has eventually been " +
"wrapped. This means that said other beans do not use the final version of the " +
"bean. This is often the result of over-eager type matching - consider using " +
"'getBeanNamesForType' with the 'allowEagerInit' flag turned off, for example.");
}
}
}
}
// Register bean as disposable.
try {
registerDisposableBeanIfNecessary(beanName, bean, mbd);
}
catch (BeanDefinitionValidationException ex) {
throw new BeanCreationException(
mbd.getResourceDescription(), beanName, "Invalid destruction signature", ex);
}
return exposedObject;
}
Comme indiqué ci-dessus, il existe 3 codes sources critiques ci-dessus.
2.1 Le premier code source de la clé
Le premier code source clé ici est le suivant :
// 【循环依赖】关键源码一
// 这里就是我们在分析中说的注册钩子方法,判断是否需要【循环依赖】
boolean earlySingletonExposure = (mbd.isSingleton() && this.allowCircularReferences &&
isSingletonCurrentlyInCreation(beanName));
if (earlySingletonExposure) {
if (logger.isTraceEnabled()) {
logger.trace("Eagerly caching bean '" + beanName +
"' to allow for resolving potential circular references");
}
addSingletonFactory(beanName, () -> getEarlyBeanReference(beanName, mbd, bean));
}
allowCircularReferences Déterminez si [autorise la dépendance circulaire] et isSingletonCurrentlyInCreation(beanName)déterminez si [la dépendance circulaire existe]. Ensuite, appelez addSingletonFactoryl'enregistrement d'une méthode hook getEarlyBeanReference(beanName, mbd, bean). La méthode hook est implémentée comme suit :
protected Object getEarlyBeanReference(String beanName, RootBeanDefinition mbd, Object bean) {
Object exposedObject = bean;
if (!mbd.isSynthetic() && hasInstantiationAwareBeanPostProcessors()) {
for (SmartInstantiationAwareBeanPostProcessor bp : getBeanPostProcessorCache().smartInstantiationAware) {
exposedObject = bp.getEarlyBeanReference(exposedObject, beanName);
}
}
return exposedObject;
}
Écoutez, il existe un [post-processeur Bean intelligent prenant en charge l'instanciation SmartInstantiationAwareBeanPostProcessor ]. Et nous appelons sa getEarlyBeanReferenceméthode pour obtenir une référence à un objet [early bean]. Hé, ce [early bean] est très familier dès sa sortie, le cache de deuxième niveau, n'y a-t-il rien de mal à cela ?
Il n'est pas difficile de voir à partir de là que ce post-processeur Bean a une excellente relation avec l'implémentation AOP de Spring. Mais je tiens à vous dire à l'avance que la classe principale d'AOP est en fait une classe d'implémentation de cette interface. AnnotationAwareAspectJAutoProxyCreatorQuant à savoir comment la creuser, je présenterai le cours AOP plus tard. Mais au final, nous nous sommes penchés sur getEarlyBeanReferencecette méthode, et finalement son code source est le suivant : (PS : Quand on appelle la méthode suivante, cela signifie que le jugement AOP est fait à l'avance)
public Object getEarlyBeanReference(Object bean, String beanName) {
Object cacheKey = getCacheKey(bean.getClass(), beanName);
this.earlyProxyReferences.put(cacheKey, bean);
return wrapIfNecessary(bean, beanName, cacheKey);
}
Ce code source est très simple, vous pouvez savoir ce qu'il signifie en regardant le nom. En fin de compte, return wrapIfNecessaryce n'est rien de plus que l'objet d'origine ou l'objet proxy, selon [si AOP est requis].
Le grand gars peut se demander, this.earlyProxyReferences.put(cacheKey, bean);à quoi sert la deuxième ligne de cache ? Hé, l'AOP normal est [après initialisation], vous êtes en avance sur le calendrier maintenant, pourquoi ne l'enregistrez-vous pas ? Si vous ne l'enregistrez pas, souhaitez-vous réexécuter l'AOP lorsque vous accédez à [après l'initialisation] ? Hé, c'est tout.
2.2 Le code source de la deuxième clé
Le code source de la deuxième clé dit ceci :
// 【循环依赖】关键源码二
// 但是这里看不出来,因为AOP就是在下面的initializeBean里面的,需要挖掘一下才能找到
Object exposedObject = bean;
try {
populateBean(beanName, mbd, instanceWrapper);
exposedObject = initializeBean(beanName, exposedObject, mbd);
}
Mais en fait, je veux parler initializeBeandu traitement [post-initialisation] à l'intérieur. Je suppose que les étudiants expérimentés, ou les étudiants qui ont déjà vu mon introduction à Spring, devraient savoir de quelle méthode il s'agit [après initialisation]. Je ne l'indexerai pas et afficherai simplement le code source appelant :
@Override
public Object applyBeanPostProcessorsAfterInitialization(Object existingBean, String beanName)
throws BeansException {
Object result = existingBean;
for (BeanPostProcessor processor : getBeanPostProcessors()) {
Object current = processor.postProcessAfterInitialization(result, beanName);
if (current == null) {
return result;
}
result = current;
}
return result;
}
Le lieu d'appel est comme ceci, mais le code source du post-processeur Bean qui gère l'AOP est le suivant, je n'indexerai pas au milieu, voici juste une impression que tout le monde puisse voir :
@Override
public Object postProcessAfterInitialization(@Nullable Object bean, String beanName) {
if (bean != null) {
Object cacheKey = getCacheKey(bean.getClass(), beanName);
if (this.earlyProxyReferences.remove(cacheKey) != bean) {
return wrapIfNecessary(bean, beanName, cacheKey);
}
}
return bean;
}
Écoutez, voici l'utilité de earlyProxyReferencesjuger si l'AOP a été effectuée à l'avance. Mais voici un détail très important, qui sera utilisé en parlant du code source de la troisième clé ci-dessous !
Tout de suite:Quand this.earlyProxyReferences.remove(cacheKey) == beanc'est le cas, cela signifie que j'ai effectué AOP à l'avance, et à ce moment l'objet d'origine est renvoyé directement, pas l'objet proxy ! (Logique normale, lorsqu'il n'y a pas d'AOP à l'avance, l'objet proxy est renvoyé ici). En gardant cette conclusion à l’esprit, nous examinerons
2.3 Le code source de la troisième clé
comme suit:(Remarque : Il existe une condition préalable clé pour saisir ce code, à savoir : earlySingletonExposure==true, ce qui signifie qu'il y avait une dépendance circulaire auparavant !)
// 【循环依赖】关键源码三
if (earlySingletonExposure) {
Object earlySingletonReference = getSingleton(beanName, false);
if (earlySingletonReference != null) {
if (exposedObject == bean) {
exposedObject = earlySingletonReference;
}
else if (!this.allowRawInjectionDespiteWrapping && hasDependentBean(beanName)) {
String[] dependentBeans = getDependentBeans(beanName);
Set<String> actualDependentBeans = new LinkedHashSet<>(dependentBeans.length);
for (String dependentBean : dependentBeans) {
if (!removeSingletonIfCreatedForTypeCheckOnly(dependentBean)) {
actualDependentBeans.add(dependentBean);
}
}
if (!actualDependentBeans.isEmpty()) {
throw new BeanCurrentlyInCreationException(beanName,
"Bean with name '" + beanName + "' has been injected into other beans [" +
StringUtils.collectionToCommaDelimitedString(actualDependentBeans) +
"] in its raw version as part of a circular reference, but has eventually been " +
"wrapped. This means that said other beans do not use the final version of the " +
"bean. This is often the result of over-eager type matching - consider using " +
"'getBeanNamesForType' with the 'allowEagerInit' flag turned off, for example.");
}
}
}
}
Pour être honnête, c'est assez gênant d'en parler, et cette connaissance est un peu impopulaire, et difficile à décrire. On estime que vous ne la rencontrez pas souvent. Cependant, nous pouvons savoir approximativement quelle est la logique à traiter ici grâce aux informations d'exception renvoyées à la fin. La traduction est la suivante :
Traduction littérale d'exception : le Bean portant le nom "beanName" a été injecté dans d'autres Beans [xxxx] dans sa version antérieure dans le cadre d'une référence circulaire, mais a finalement été encapsulé (encapsulé signifie : proxy). Cela signifie que les autres beans mentionnés ci-dessus utilisent une version non finale du bean.
. . . . . . . . . . . . . . . . . . . .
En termes humains : le Bean nommé beanName a déjà été empaqueté par [proxy AOP] une fois dans la dépendance circulaire, mais il a été à nouveau empaqueté par [proxy package] plus tard dans un autre traitement. Par conséquent, le bean proxy précédemment injecté dans [Circular Dependency] n'est pas le dernier bean proxy. Si vous rencontrez cette situation, vous pouvez uniquement signaler une erreur
Regardez, à travers la traduction ci-dessus, ce qui se passe est très clair. C'est ça le problème.
Mais en fait, il y a toujours un problème avec le code source de Spring. En raison de l'existence de la conclusion en 2.2, cela peut conduire à la situation mentionnée dans la case de jugement noire dans la figure suivante, et alors une erreur est signalée : le processus est dû au fait que, 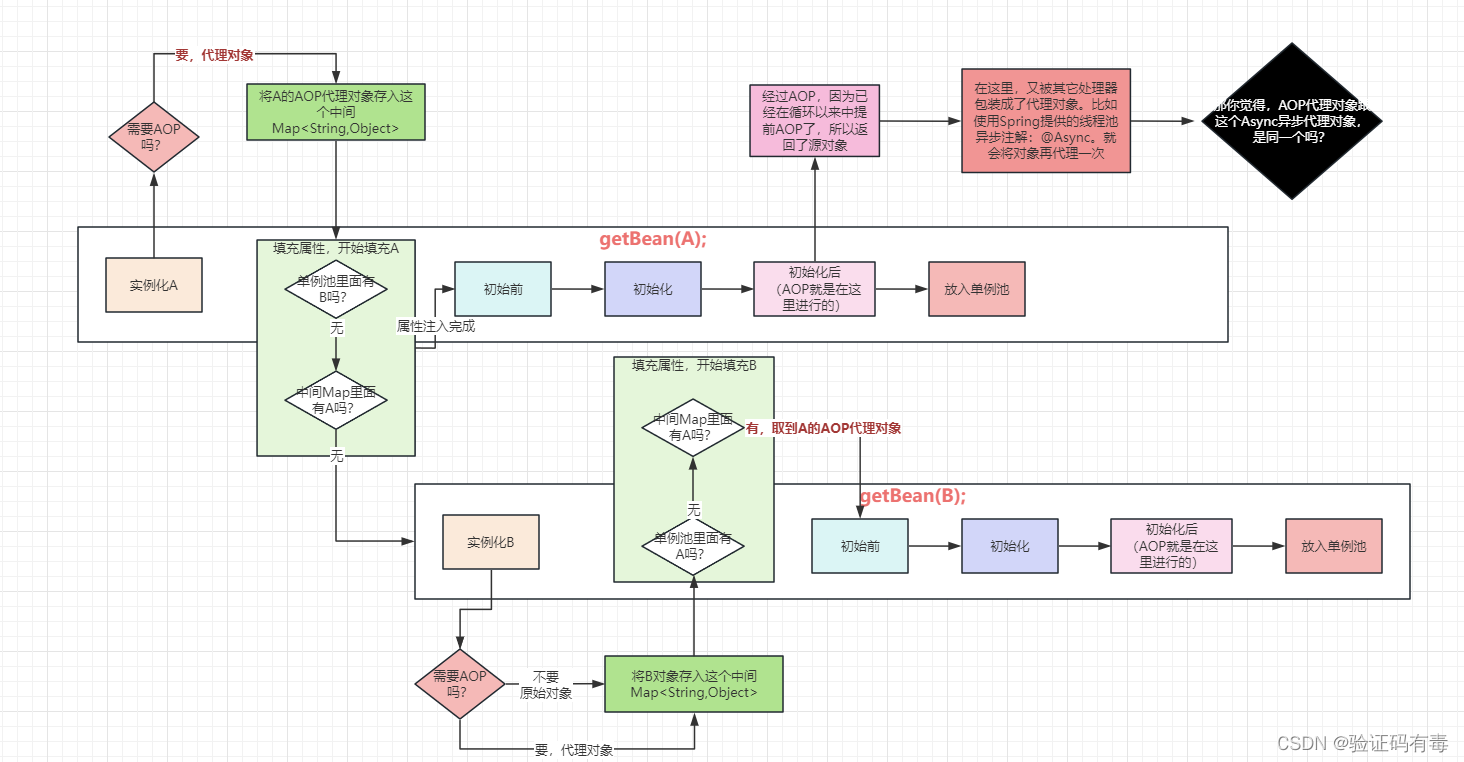
dans le processus d'instanciation de A, il y a une circulaire dépendance entre A et B et l'agent AOP de A L'objet est généré en utilisant l'objet de méthode hook dans le processus de B, donc, dans le processus de création de A, A ne peut pas percevoir qu'il a été généré en tant que proxy AOP ! Ainsi, plus tard, lorsque nous avons atteint le processus de [après initialisation], en raison de la conclusion de la version 2.2, l'objet d'origine a été utilisé et a été mandaté par Async ! horrible! Ce n’est évidemment pas ce que nous souhaitons !
2.3.1 Comment résoudre les problèmes ci-dessus
En fait, l'idée est très simple : puisque ce problème est causé par une dépendance circulaire, brisons la dépendance circulaire ! attends, tu ne crois pas que je t'ai dit de changer la structure des cours ? Non. Alors réfléchissez-y, existe-t-il un moyen de rompre la dépendance circulaire sans changer la structure des classes ?
En parlant de ça, rappelons-nous, vous souvenez-vous encore de la cause de la dépendance circulaire ? N'est-ce pas à cause des attributs que [l'injection en série] est nécessaire ? L'explication populaire est que je dois injecter des propriétés dans le processus de création de beans. Existe-t-il un moyen de ne pas injecter de propriétés lors de la création de beans ? Il y a, @Lazycommentez.
résumer
- Découvrez les causes des dépendances circulaires et les principes de conception de la structure de cache à trois niveaux