Cloud Computing et Big Data - Déployer le cluster Kubernetes + Déploiement nginx complet (super détaillé !)
L'idée de base du déploiement d'un cluster Kubernetes est la suivante :
-
Préparez l’environnement :
- Sélectionnez un système d'exploitation approprié : sélectionnez une distribution Linux appropriée comme système d'exploitation en fonction de vos besoins et assurez-vous de faire la même sélection sur tous les nœuds.
- Installer Docker : installez Docker sur tous les nœuds, qui seront utilisés pour conteneuriser les applications et les composants.
- Installez les outils Kubernetes : installez
kubectlet outils, qui seront utilisés pour la gestion et la configuration du clusterkubeadm.kubelet
-
Configurez le nœud maître (Master Node) :
- Sélectionnez un nœud comme nœud maître : généralement l'un des nœuds esclaves est sélectionné comme nœud maître, qui peut être n'importe quelle machine disposant de ressources suffisantes.
- Initialiser le nœud maître : utilisez
kubeadm initla commande pour initialiser le nœud maître et obtenir le jeton de jointure généré. - Configurer un plugin réseau : sélectionnez et installez un plugin réseau approprié, tel que Flannel, Calico ou Weave, pour activer la communication réseau entre les nœuds.
-
Ajoutez des nœuds esclaves (nœuds de travail) :
- Exécutez la commande join sur chaque nœud esclave : à l'aide du jeton de jointure généré précédemment, exécutez la commande sur chaque nœud esclave
kubeadm joinpour le joindre au cluster. - Confirmer la jonction du nœud : exécutez la commande sur le nœud maître
kubectl get nodespour vous assurer que tous les nœuds ont réussi à rejoindre le cluster.
- Exécutez la commande join sur chaque nœud esclave : à l'aide du jeton de jointure généré précédemment, exécutez la commande sur chaque nœud esclave
-
Déployez le plugin Web :
- En fonction du plug-in réseau sélectionné, suivez son déploiement et sa configuration spécifiques. Cela garantira la communication réseau entre les nœuds et fournira les capacités de mise en réseau du cluster Kubernetes.
-
Déployez d'autres composants et applications :
- Déployez d'autres composants de base requis tels que kube-proxy et kube-dns/coredns.
- Déployez vos applications ou services, qui peuvent être gérés à l'aide du déploiement, du service ou d'autres types de ressources de Kubernetes.
-
Vérifiez l'état du cluster :
- Exécutez
kubectl get nodeset d'autreskubectlcommandes pour garantir que les nœuds et les composants du cluster fonctionnent correctement. - Tester les applications : exécutez des tests sur les applications déployées dans le cluster pour vous assurer qu'elles fonctionnent correctement et interagissent avec d'autres composants.
- Exécutez
Ce qui précède est l'idée de base du déploiement d'un cluster Kubernetes. Les étapes et détails exacts peuvent varier en fonction de l'environnement et des besoins, mais cette brève description peut vous aider à comprendre le déroulement général du processus de déploiement.
Ensuite, nous déploierons le cluster kubernetes et compléterons le service nginx en pratique.
Commencez à déployer le cluster Kubernetes
Exécutez les commandes suivantes en tant que root :
1. Installez et configurez Docker sur tous les nœuds
1. Installez les outils requis pour Docker
yum install -y yum-utils device-mapper-persistent-data lvm2

2. Configurez la source docker d'Alibaba Cloud
yum-config-manager --add-repo http://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo

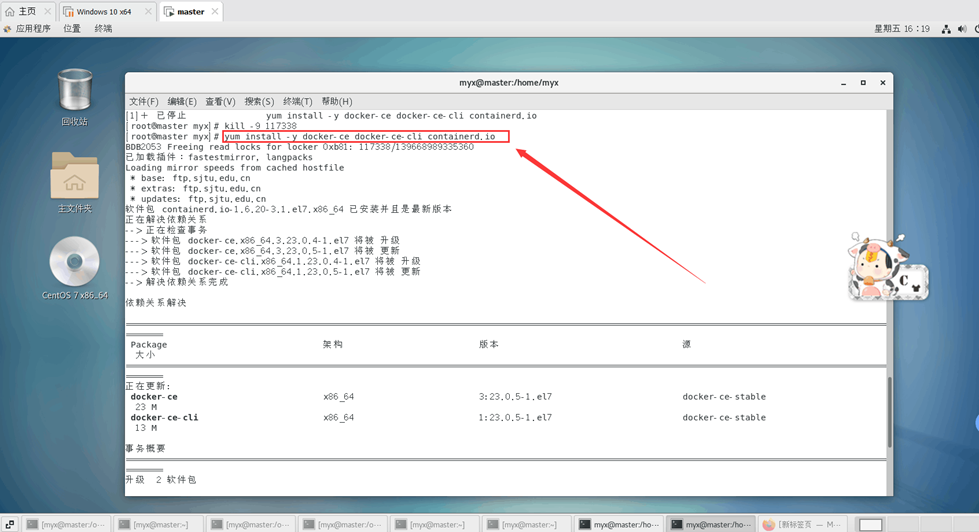
3. Installez docker-ce, docker-ce-cli, containersd.io
yum install -y docker-ce docker-ce-cli containerd.io
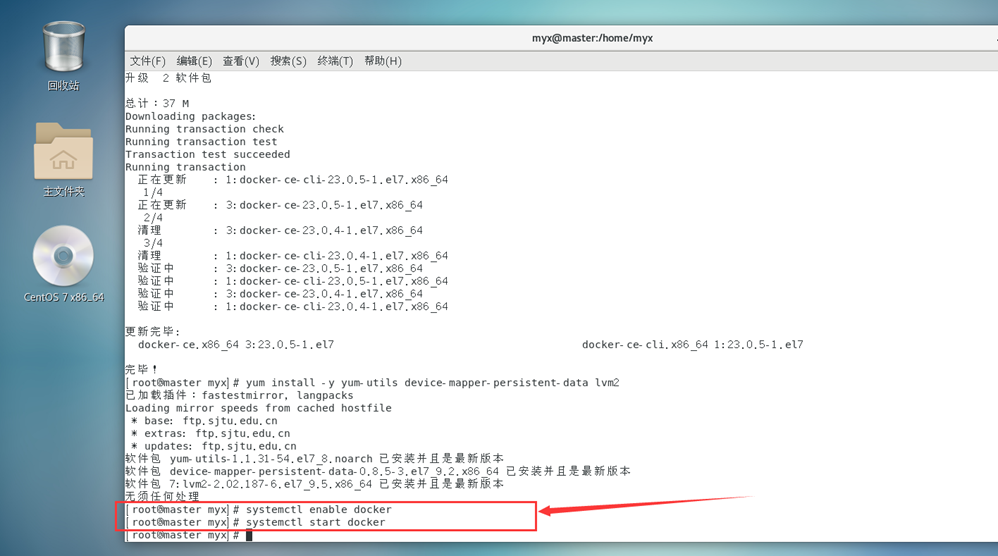
4. Démarrez Docker
systemctl enable docker #设置开机自启
systemctl start docker #启动docker
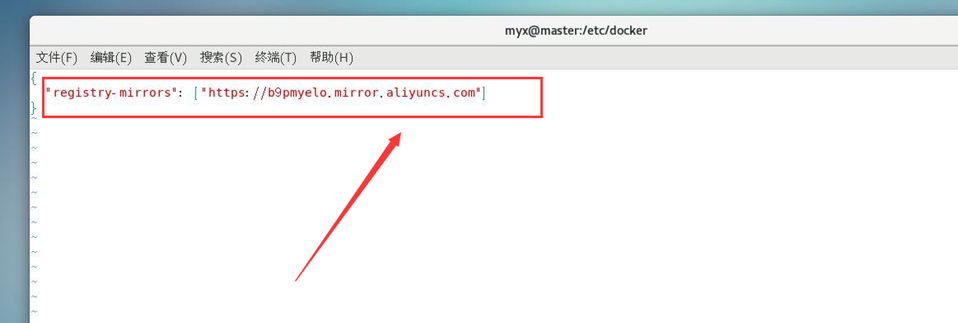
5. Définir l'accélérateur de miroir
#Définir l'accélérateur de miroir, créer un nouveau fichier daemon.json (référence 1)
cat <<EOF > /etc/docker/daemon.json
{
"registry-mirrors": ["https://b9pmyelo.mirror.aliyuncs.com"]
}
6. Générez et modifiez le fichier de configuration par défaut /etc/containerd/config.toml de containersd (référence 2)
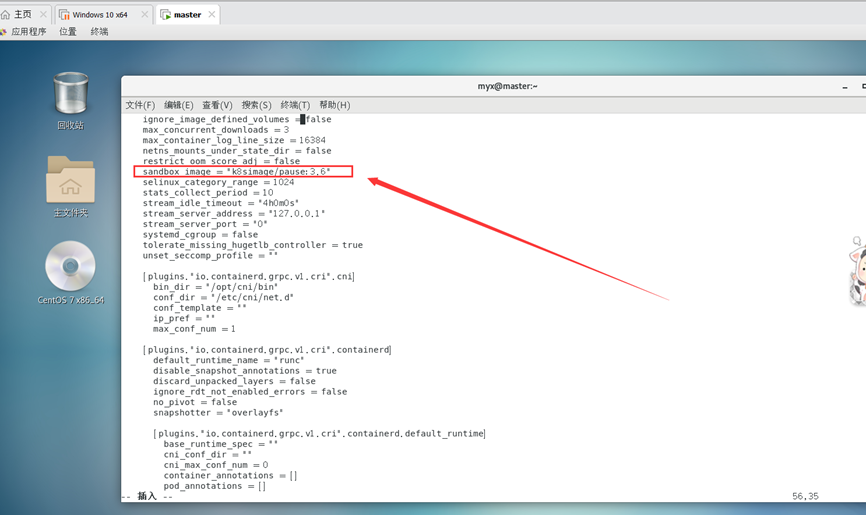
containerd config default > /etc/containerd/config.toml


Remplacez sandbox_image="registry.k8s.io/pause:3.6"
par sandbox_image="k8simage/pause:3.6"

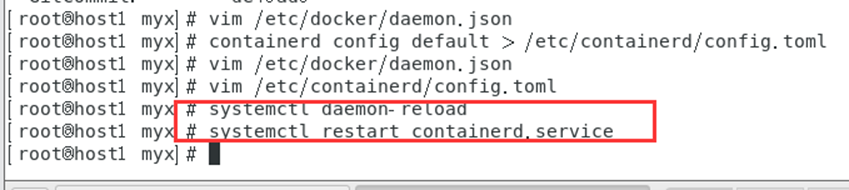
Redémarrez le service conteneur
systemctl daemon-reload
systemctl restart containerd.service

Remarque : Cette étape peut résoudre l'échec de l'extraction de l'image \"registry.k8s.io/pause:3.6\" ; Échec de la création du bac à sable pour le pod : extraction de l'imageregistry.k8s.io/pause:3.6 et d'autres problèmes (des problèmes d'erreur spécifiques peuvent be Consultez les journaux en exécutant la commande suivante : journalctl -xeu kubelet)
7. Désactivez le pare-feu
systemctl disable firewalld
systemctl stop firewalld


8. Fermez Selinux
# Désactivez temporairement Selinux
setenforce 0
#Ou fermez définitivement, modifiez les paramètres du fichier /etc/sysconfig/selinux
sed -i 's/SELINUX=permissive/SELINUX=disabled/' /etc/sysconfig/selinux

sed -i 's/SELINUX=enforcing/SELINUX=disabled/g' /etc/selinux/config

9. Désactiver la partition d'échange
swapoff -a
#Ou désactiver définitivement, commentez la ligne de swap dans le fichier /etc/fstab
sed -i ‘s/.*swap.*/#&/’ /etc/fstab


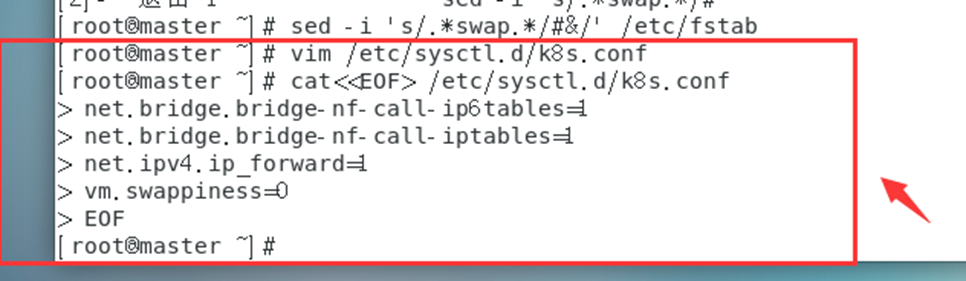
10. Modifiez les paramètres du noyau
pour transmettre le trafic IPv4 ponté à la chaîne iptables (certains trafics ipv4 ne peuvent pas passer par la chaîne iptables, car un filtre dans le noyau Linux passera par lui, puis déterminera s'il peut entrer dans le noyau Linux. processus de candidature actuel Pour traiter, cela entraînera donc une perte de trafic), configurez le fichier k8s.conf (le fichier k8s.conf n'existe pas, vous devez le créer vous-même)
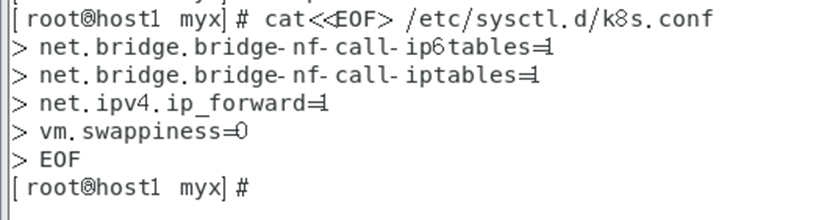
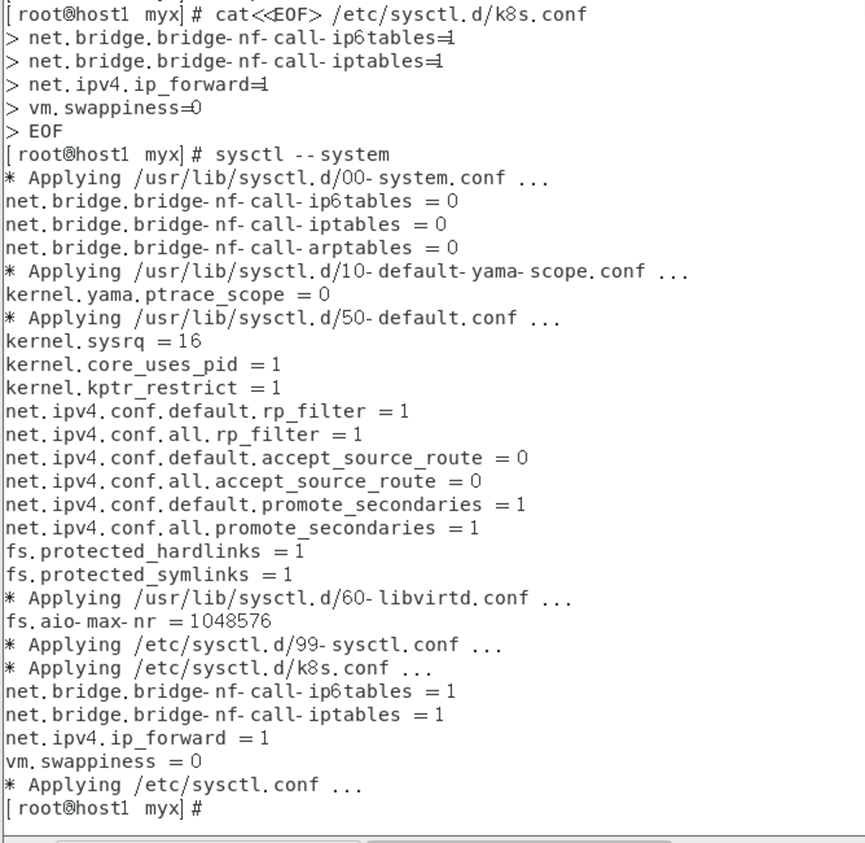
cat<<EOF> /etc/sysctl.d/k8s.conf
net.bridge.bridge-nf-call-ip6tables=1
net.bridge.bridge-nf-call-iptables=1
net.ipv4.ip_forward=1
vm.swappiness=0
EOF
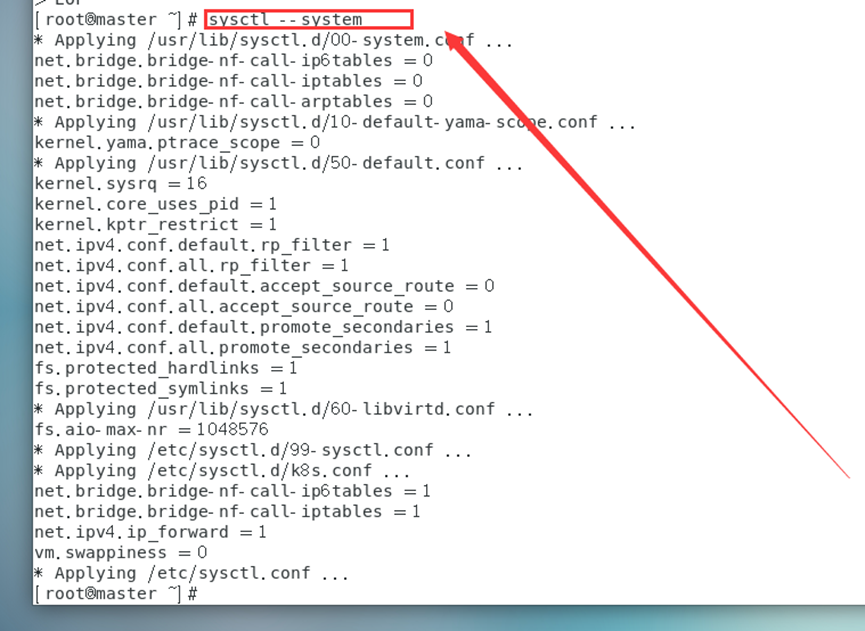
sysctl --system
#Rechargez tous les paramètres système, ou utilisez sysctl -p
Document 1 : https://yebd1h.smartapps.cn/pages/blog/index?blogId=123605246&_swebfr=1&_swebFromHost=bdlite
2. Installez et configurez Kubernetes sur tous les nœuds (sauf ceux spécifiés séparément)
1. Configurer la source Kubernetes Alibaba Cloud
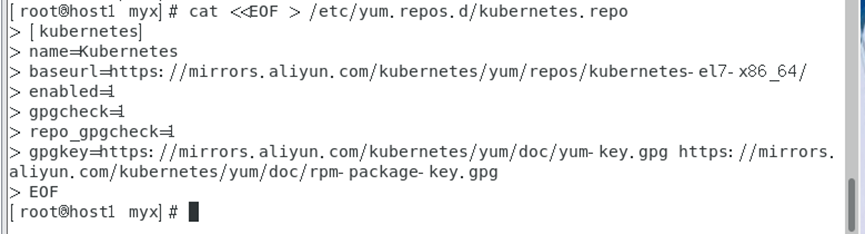
cat <<EOF > /etc/yum.repos.d/kubernetes.repo
[kubernetes]
name=Kubernetes
baseurl=https://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64/
enabled=1
gpgcheck=1
repo_gpgcheck=1
gpgkey=https://mirrors.aliyun.com/kubernetes/yum/doc/yum-key.gpg https://mirrors.aliyun.com/kubernetes/yum/doc/rpm-package-key.gpg
EOF

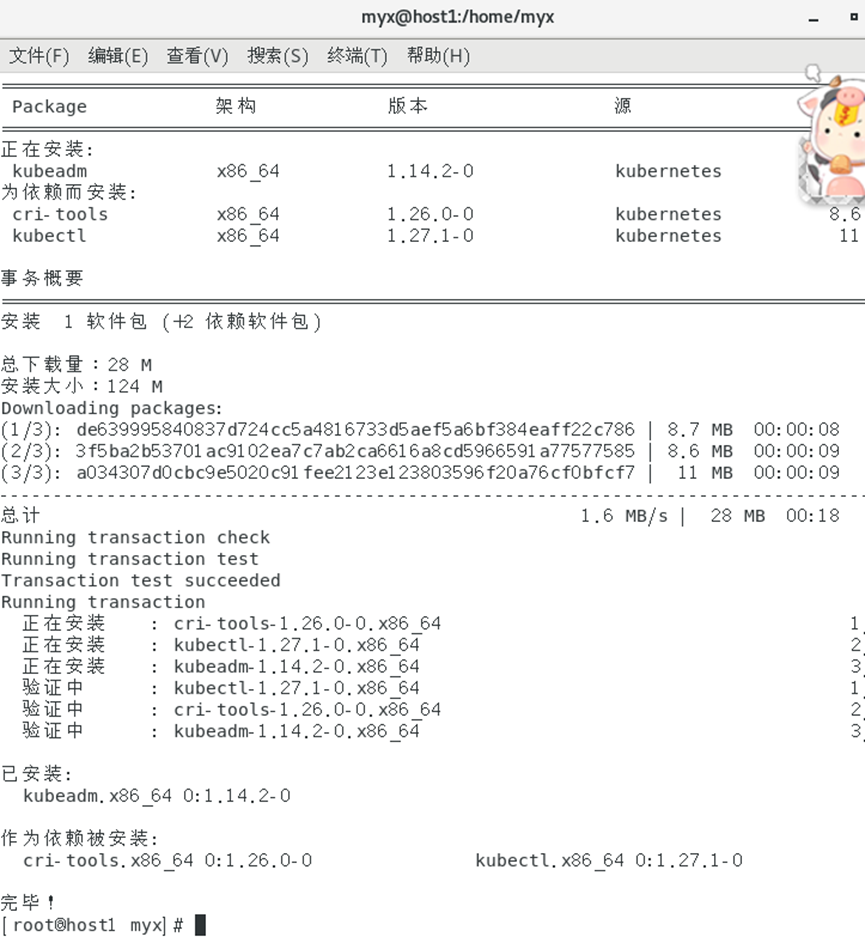
2. Installez kubeadm, kubectl et kubelet (kubeadm et kubectl sont tous deux des outils et kubelet est un service système, référence 1)
yum install -y kubelet-1.14.2
yum install -y kubeadm-1.14.2
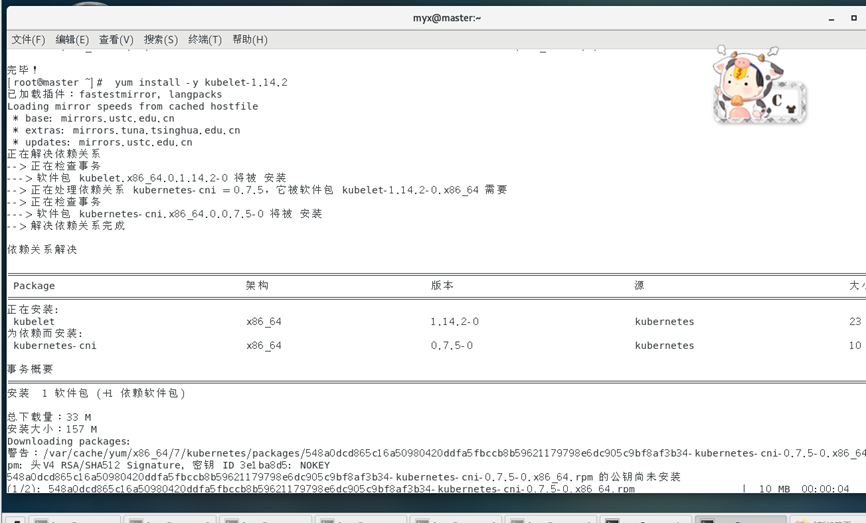
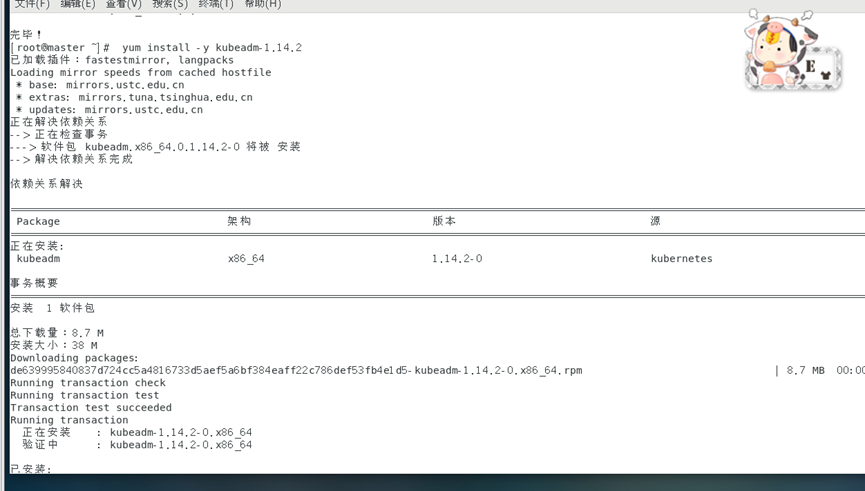
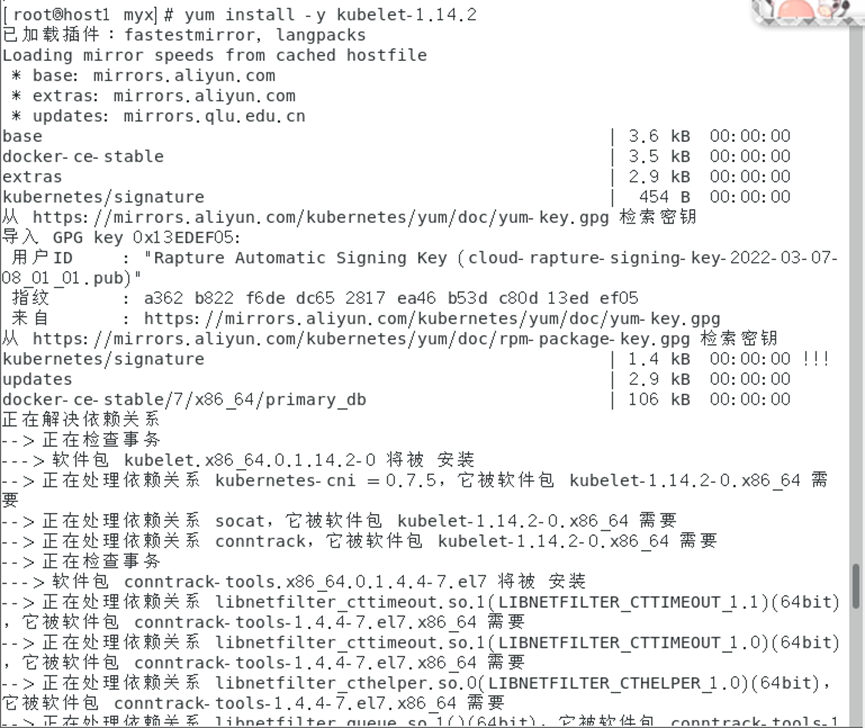
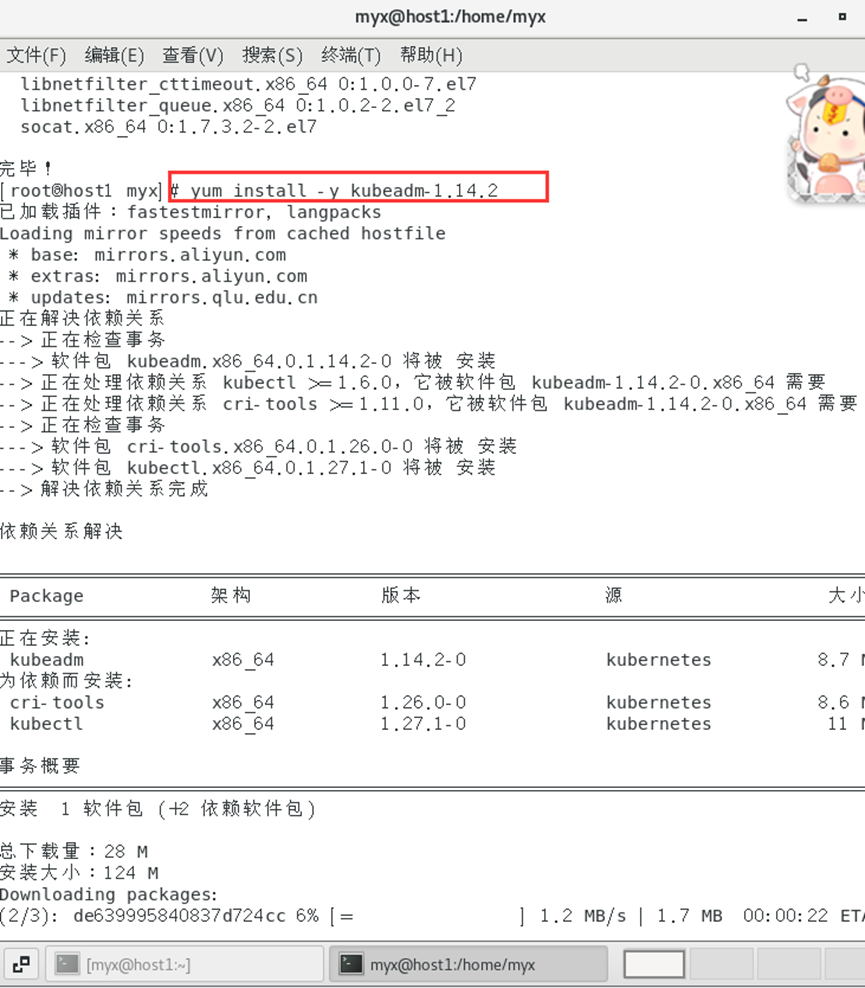
3. Démarrez le service Kubelet
systemctl enable kubelet && systemctl start kubelet


4. Générez la version actuelle du fichier de configuration d'initialisation dans le répertoire /etc/kubernetes
kubeadm config print init-defaults > /etc/kubernetes/init-default.yaml

1) Spécifiez l'adresse IP que le kube-apiserver diffuse aux autres composants.
Ce paramètre doit être défini sur l'adresse IP du nœud maître pour garantir que les autres nœuds peuvent accéder au kube-apiserver
: [host ip( Intranet)]
Cet élément est défini en fonction de l'adresse IP de son nœud maître. Le paramètre de cette machine est :
advertiseAddress:192.168.95.20
2) Spécifiez la source de l'entrepôt pour installer l'image.
Il est recommandé d'utiliser une image domestique telle qu'Alibaba Cloud :
imageRepository : Registry.aliyuncs.com/google_containers
Remarque : Nous rencontrerons les problèmes d'initialisation suivants au début :
failed to pull image registry.k8s.io/kube-apiserver:v1.26.3
Ce paramètre combiné aux paramètres suivants de la commande kubeadm init peut résoudre le problème :
--image-repository=registry.aliyuncs.com/google_containers
Autrement dit, lors de l'initialisation : kubeadm init --image-repository=registry.aliyuncs.com/google_containers
est initialisé plus tard
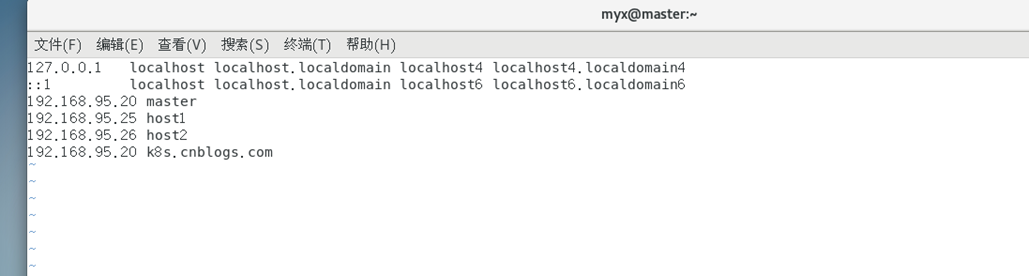
3) Modifiez /etc/hosts et ajoutez une ligne :
192.168.95.20 k8s.cnblogs.com #需根据自己主机的IP地址进行修改
En général, l'étape 4 peut résoudre le problème compliqué de [kubelet-check] Délai d'expiration initial de 40 secondes écoulé.
Référence 2 :
https://blog.csdn.net/weixin_52156647/article/details/129765134
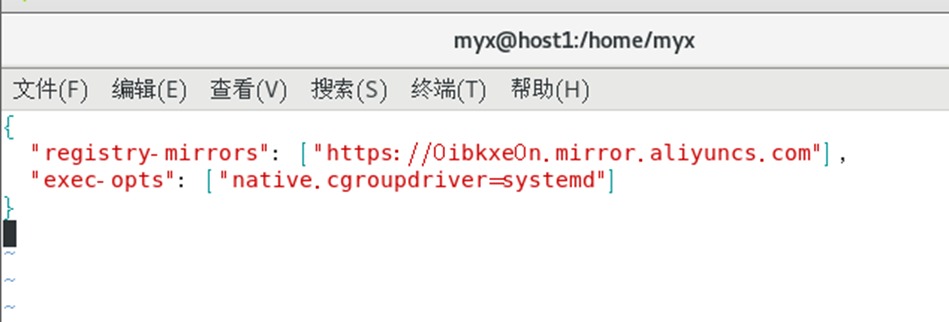
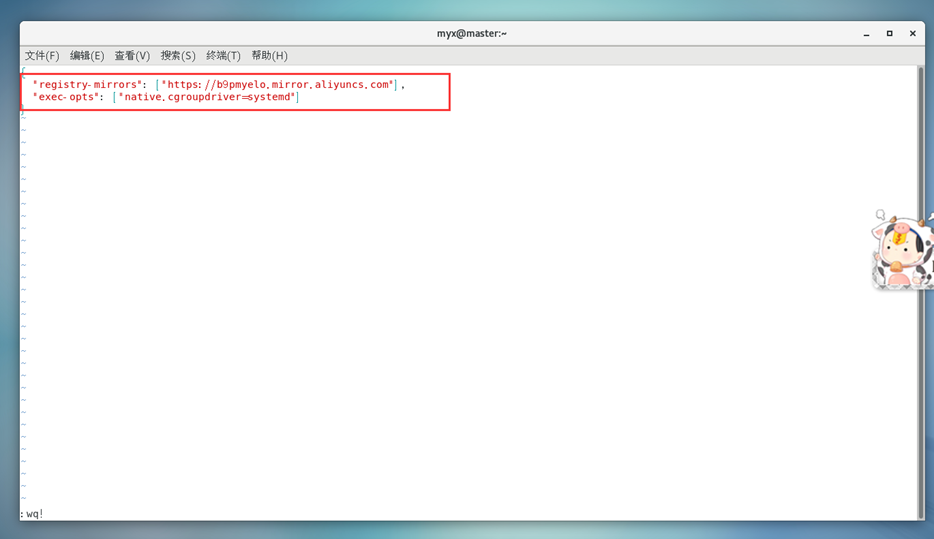
4) Unifiez le pilote Cgroup de Kubernetes et docker en tant que systemd,
modifiez le fichier /etc/docker/daemon.json et ajoutez les paramètres suivants :
vim /etc/docker/daemon.json
#Afin de maintenir la cohérence de la configuration du docker de tous les nœuds, les dockers des autres nœuds ont également été modifiés
{
"registry-mirrors": ["https://b9pmyelo.mirror.aliyuncs.com"],
"exec-opts": ["native.cgroupdriver=systemd"]
}
recharger le menu fixe
systemctl daemon-reload
systemctl restart docker
5. Avant d'initialiser Kubernetes sur le nœud maître, exécutez :
systemctl restart docker

achèvement de la commande kubelet
echo "source <(kubectl completion bash)" >> ~/.bash_profile
source .bash_profile


Extraire l'image Répertoriez
la liste des images requises pour le démarrage du cluster Kubernetes. Ces images incluent des composants du plan de contrôle (tels que kube-apiserver, kube-controller-manager et kube-scheduler) et d'autres composants nécessaires (tels que etcd, CoreDNS, etc.), et modifient la balise pour qu'elle soit cohérente avec la version requise.
.
kubeadm config images list

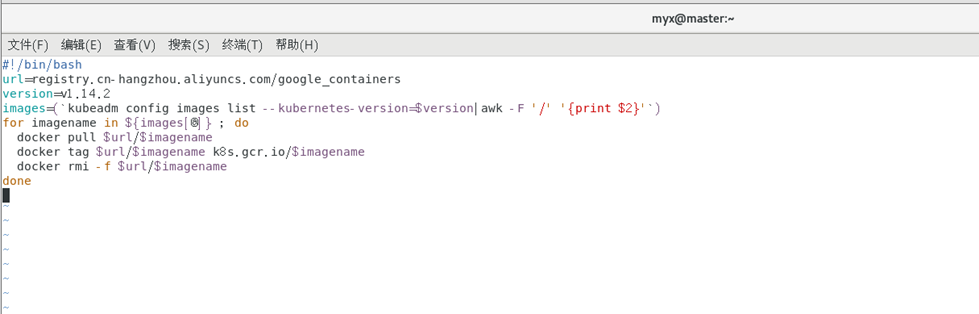
Définir la source miroir et le programme de script
vim image.sh
#!/bin/bash
url=registry.cn-hangzhou.aliyuncs.com/google_containers
version=v1.14.2
images=(`kubeadm config images list --kubernetes-version=$version|awk -F '/' '{print $2}'`)
for imagename in ${images[@]} ; do
docker pull $url/$imagename
docker tag $url/$imagename k8s.gcr.io/$imagename
docker rmi -f $url/$imagename
done
script de lancement
chmod u+x image.sh
./image.sh
docker images
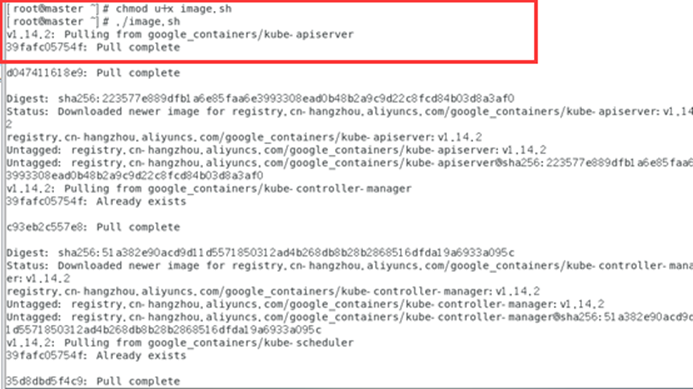
images docker Vérifiez les images dans l'entrepôt Docker et constatez que toutes les images commencent par Registry.aliyuncs.com/google_containers/, et que certaines d'entre elles sont différentes des noms d'image requis dans la liste des images de configuration kubeadm. Nous voulons modifier le nom de l'image, c'est-à-dire re-étiqueter l'image
docker images
Montrer les résultats:
docker tag registry.cn-hangzhou.aliyuncs.com/google_containers/kube-apiserver:v1.14.10 k8s.gcr.io/kube-apiserver:v1.14.10
docker tag registry.cn-hangzhou.aliyuncs.com/google_containers/kube-controller-manager:v1.14.10 k8s.gcr.io/kube-controller-manager:v1.14.10
docker tag registry.cn-hangzhou.aliyuncs.com/google_containers/kube-scheduler:v1.14.10 k8s.gcr.io/kube-scheduler:v1.14.10
docker tag registry.cn-hangzhou.aliyuncs.com/google_containers/kube-proxy:v1.14.10 k8s.gcr.io/kube-proxy:v1.14.10
docker tag registry.cn-hangzhou.aliyuncs.com/google_containers/pause:3.1 k8s.gcr.io/pause:3.1
docker tag registry.cn-hangzhou.aliyuncs.com/google_containers/etcd:3.3.10 k8s.gcr.io/etcd:3.3.10
docker tag registry.cn-hangzhou.aliyuncs.com/google_containers/coredns:1.3.1 k8s.gcr.io/coredns:1.3.1
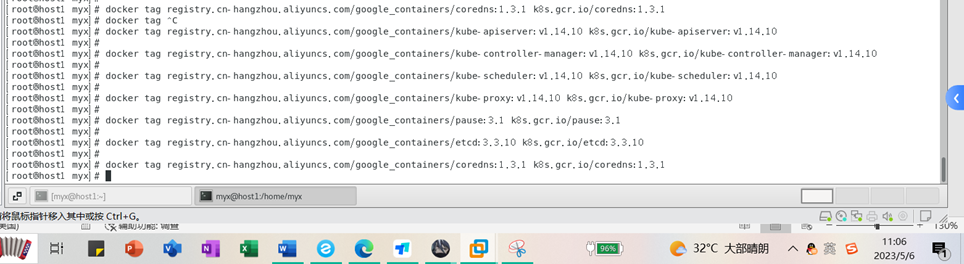
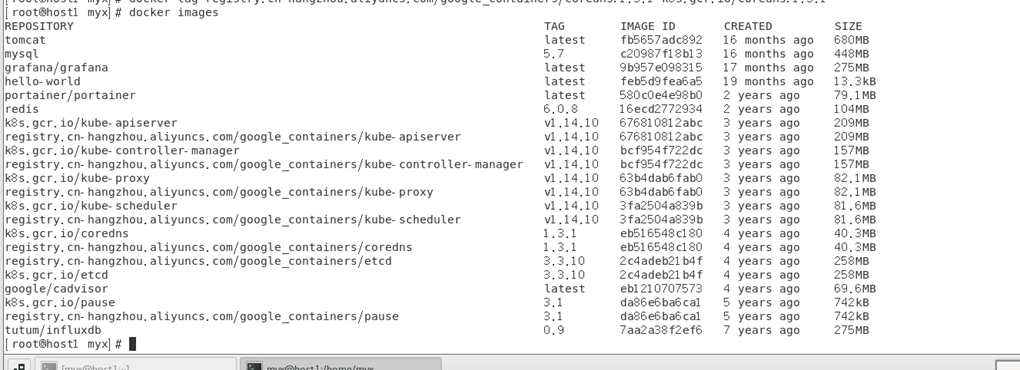
Après avoir modifié la balise, vérifiez à nouveau et constatez que le nom de l'image et le numéro de version sont cohérents avec la liste des images requises pour le démarrage du cluster Kubernetes répertoriées dans la commande « kubeadm config images list ».
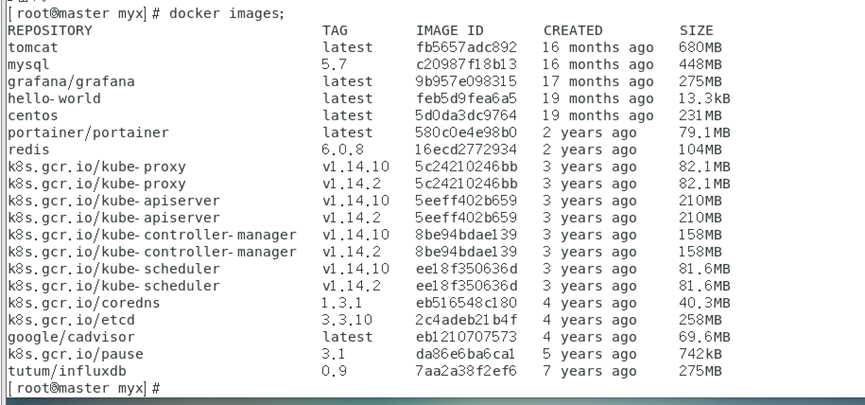
Une autre façon de récupérer les images une par une
kubeadm config images list

docker pull registry.cn-hangzhou.aliyuncs.com/google_containers/kube-apiserver:v1.40.10
docker pull registry.cn-hangzhou.aliyuncs.com/google_containers/kube-controller-manager:v1.40.10
docker pull registry.cn-hangzhou.aliyuncs.com/google_containers/kube-scheduler:v1.40.10
docker pull registry.cn-hangzhou.aliyuncs.com/google_containers/kube-proxy:v1.40.10
docker pull registry.cn-hangzhou.aliyuncs.com/google_containers/pause:3.1
docker pull registry.cn-hangzhou.aliyuncs.com/google_containers/etcd:3.3.10
docker pull registry.cn-hangzhou.aliyuncs.com/google_containers/coredns:1.3.1

Affichez à nouveau l'image du menu fixe :
docker images
Réinitialiser le cluster k8s
kubeadm reset
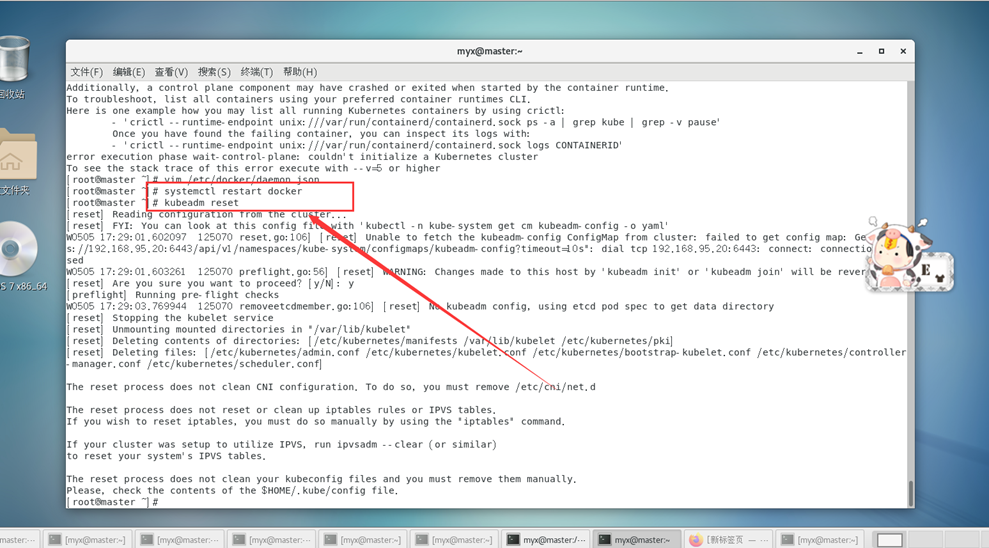
Pour libérer l'occupation du port, supprimez le fichier de configuration généré lors de l'initialisation précédente, etc.
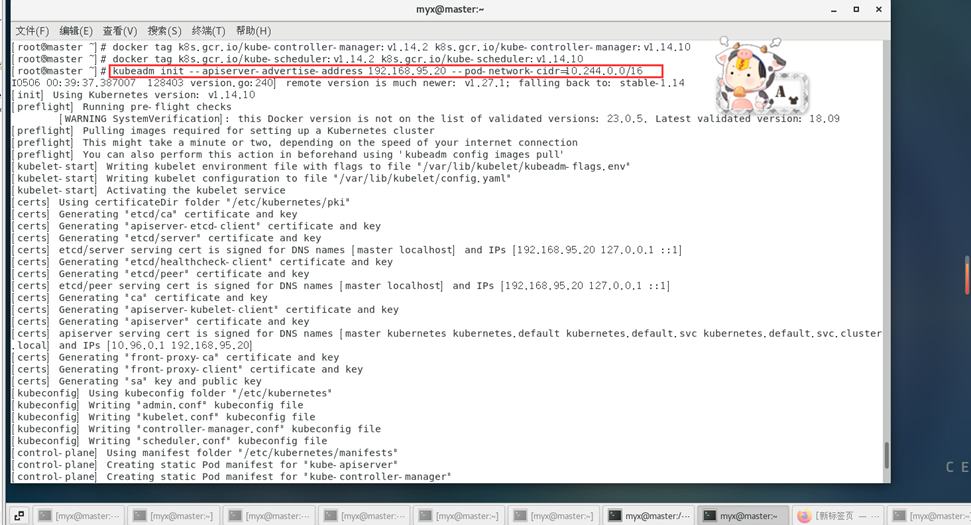
Commencez ensuite à exécuter formellement l'initialisation du cluster :
kubeadm init --apiserver-advertise-address 192.168.95.20 --pod-network-cidr=10.244.0.0/16
Un message d'exécution s'affiche : Your Kubernetes control-plane has initialized successfully!L'initialisation du cluster s'est terminée avec succès.
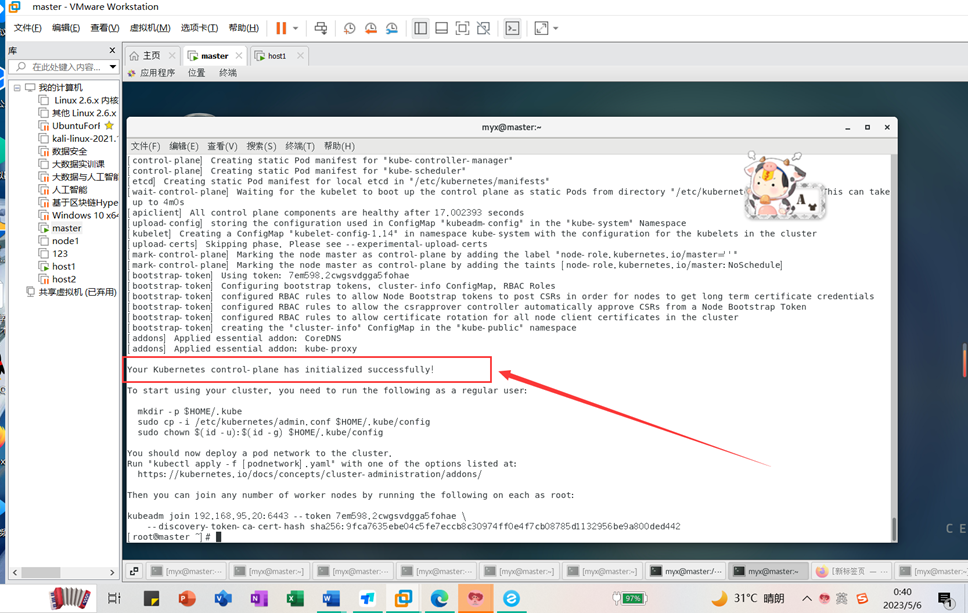

6. Configurez le nœud
Les 3 commandes suivantes sont utilisées par des utilisateurs ordinaires :
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
7. Faites attention à la commande et à la clé secrète lorsque vous rejoignez depuis le nœud
kubeadm join 192.168.95.20:6443 --token 7em598.2cwgsvdgga5fohae \
--discovery-token-ca-cert-hash sha256:9fca7635ebe04c5fe7eccb8c30974ff0e4f7cb08785d1132956be9a800ded442
Gardez cette clé en sécurité.
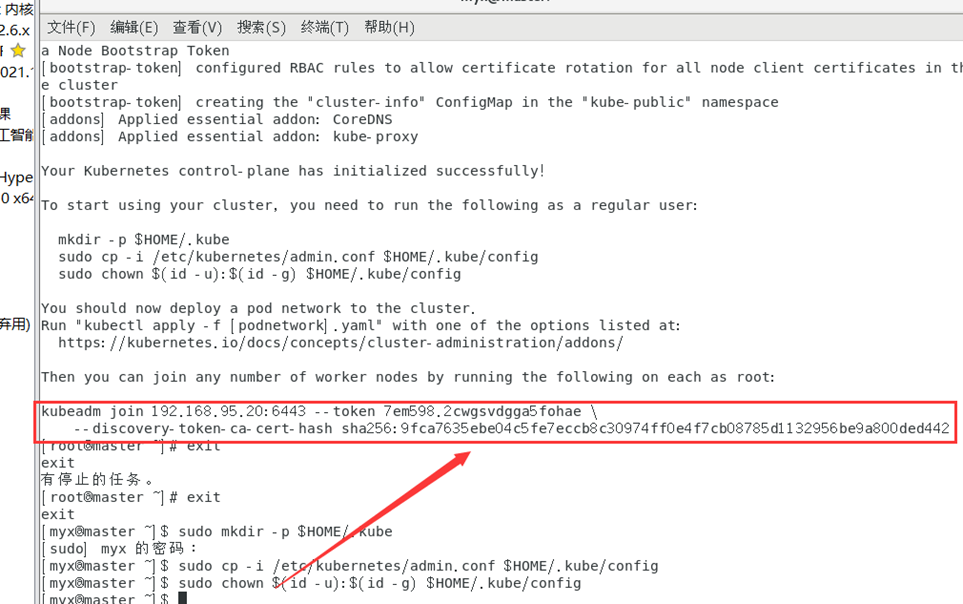
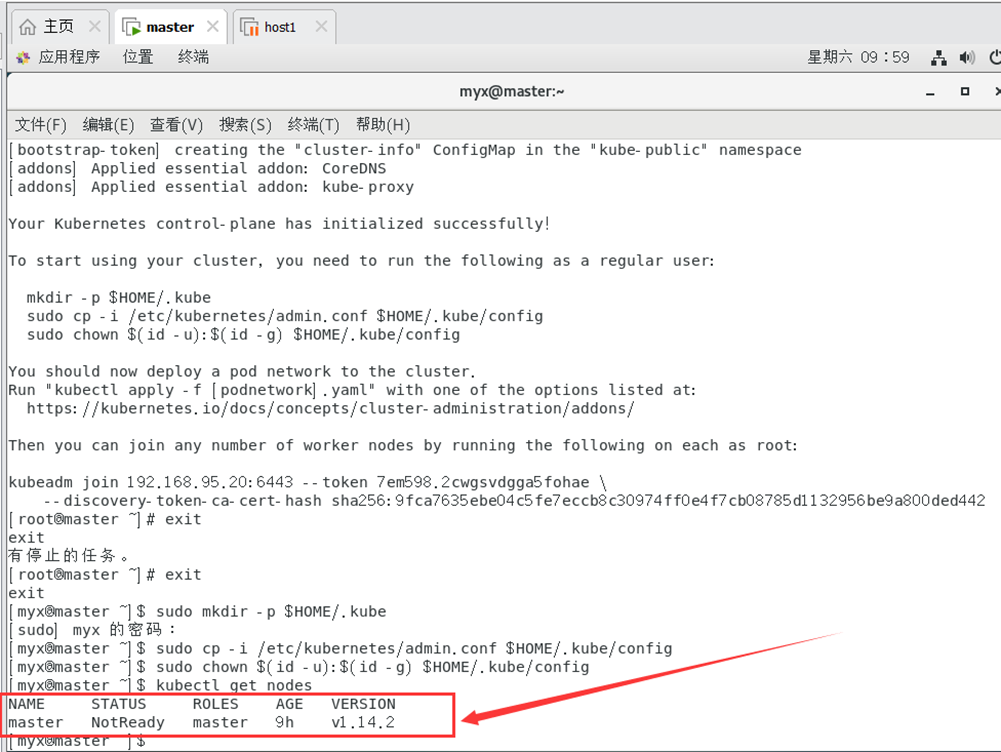
8. Vérifiez l'état d'exécution du nœud (état NotReady)
kubectl get nodes
3. Installez et configurez le nœud esclave Kubernetes
1. Installez le logiciel du nœud esclave et configurez-le selon les première et deuxième étapes ci-dessus.
Configuration de base de host1 :
version docker
Kubectl version
kubeadm version
kubelet version
2. Rejoignez le cluster à partir du nœud (utilisez l'utilisateur root)
kubeadm join 192.168.95.20:6443 --token 7em598.2cwgsvdgga5fohae \
--discovery-token-ca-cert-hash sha256:9fca7635ebe04c5fe7eccb8c30974ff0e4f7cb08785d1132956be9a800ded442
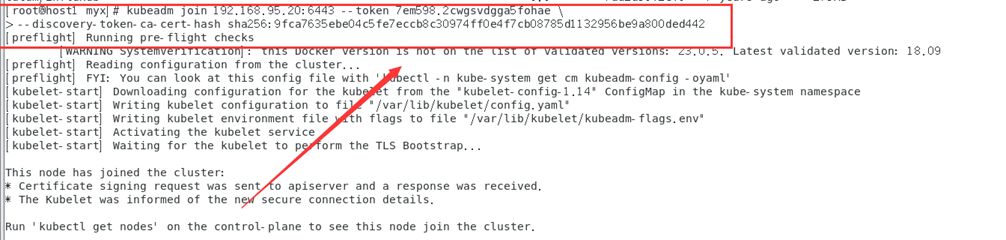
Remarque : Cette étape rencontre généralement les problèmes suivants :
[ERROR CRI]: container runtime is not running:
En effet, le conteneur installé avec un sous-paquet le désactivera par défaut en tant que moteur d'exécution du conteneur :
Solution :
1) Utilisez systemctl status containerdView Status
Active : actif (en cours d'exécution) pour indiquer que le conteneur fonctionne normalement
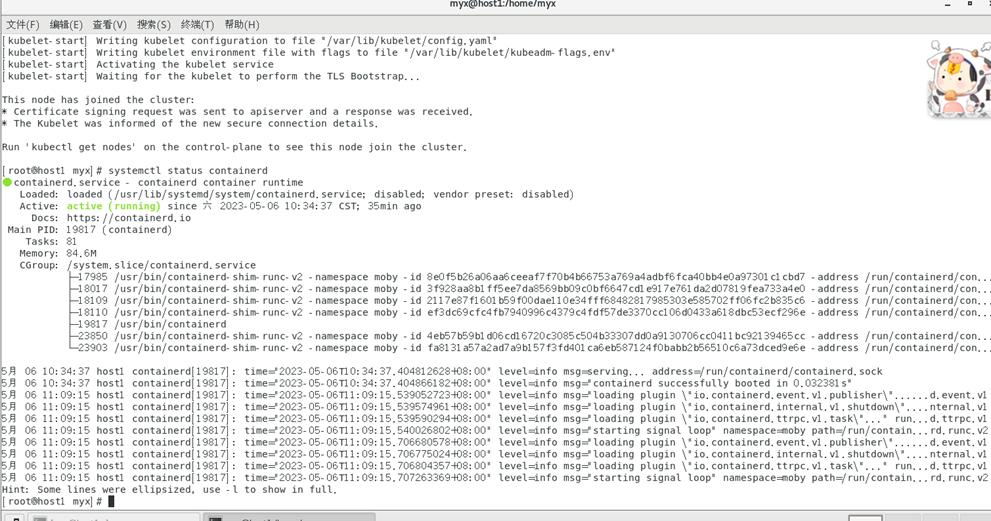
2) Vérifiez /etc/containerd/config. fichier toml, c'est le fichier de configuration lorsque le conteneur est en cours d'exécution
3)
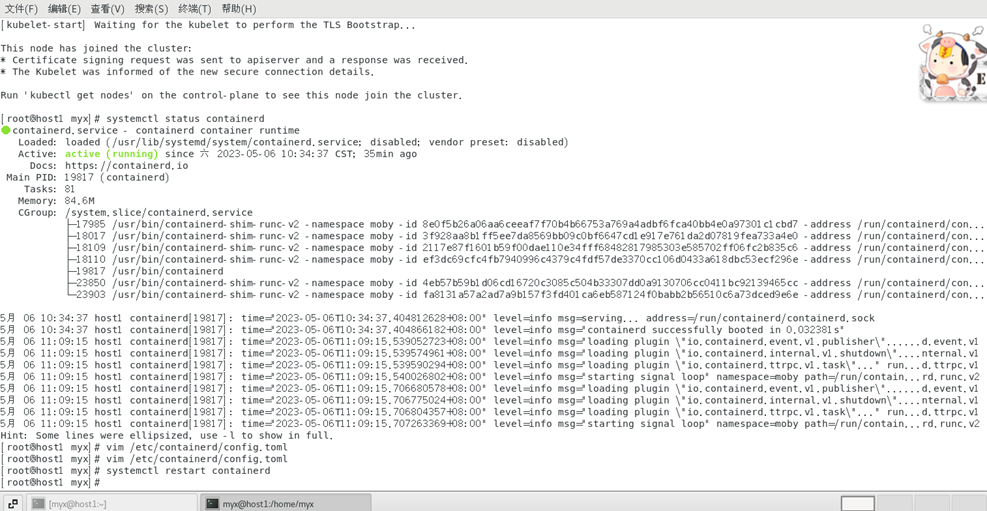
vim /etc/containerd/config.toml
Si vous voyez cette ligne :disabled_plugins : ["cri"],
commentez cette ligne avec # ou supprimez "cri":
#disabled_plugins : [“cri”] ou
désactivé_plugins : []
4) Redémarrez le runtime du conteneur
systemctl restart containerd
Référence 3 : https://blog.csdn.net/weixin_52156647/article/details/129758753
4. Affichez les nœuds esclaves joints sur le nœud maître et résolvez les problèmes ultérieurs
kubectl get nodes

1. À ce stade, STATUS affiche
la solution NotReady :
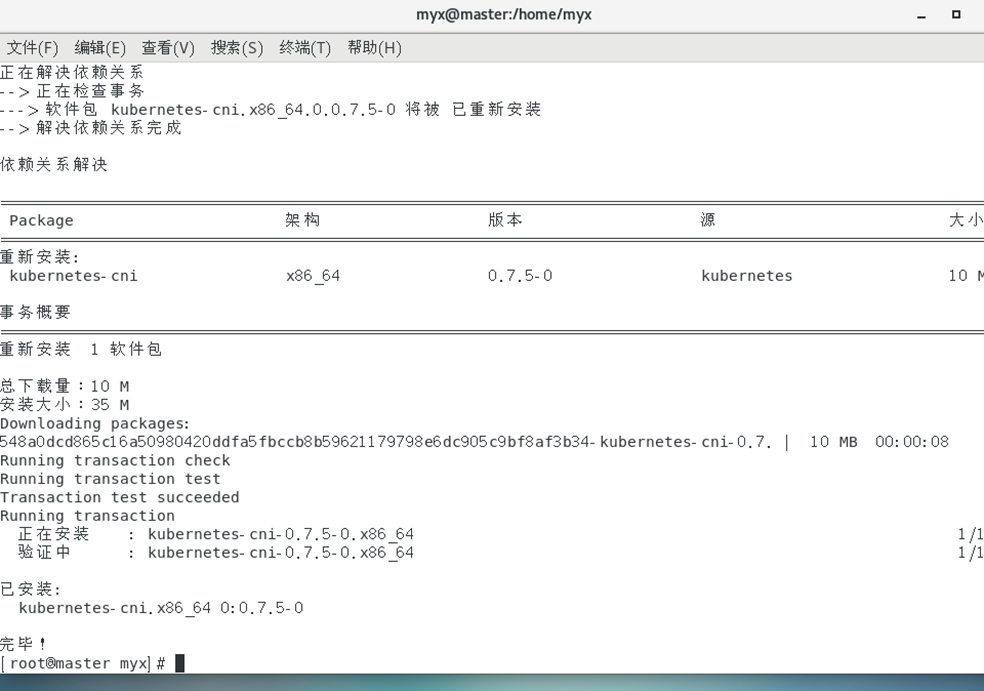
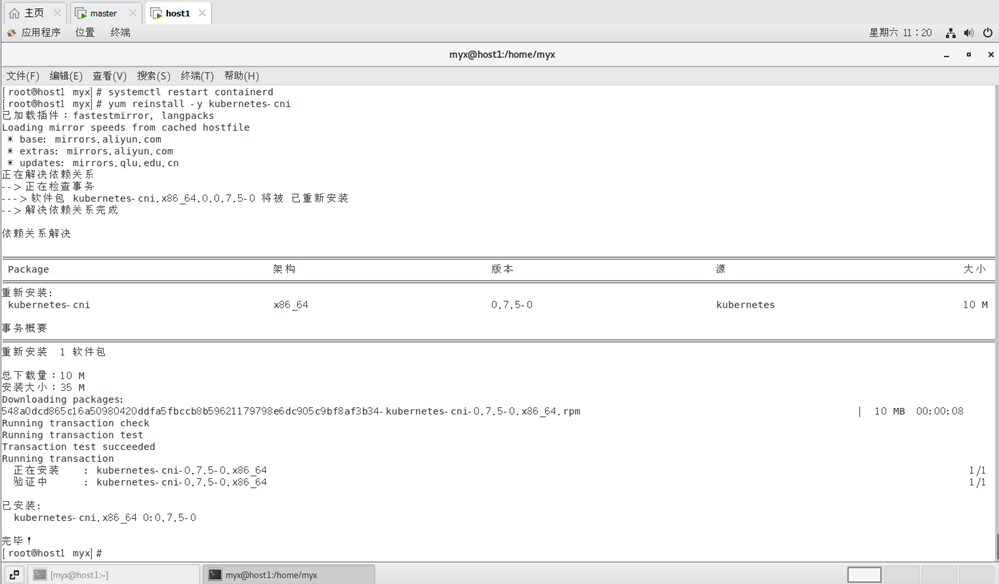
1) Réinstallez kubernetes-cni sur tous les nœuds du cluster :
yum reinstall -y kubernetes-cni
2) Installez le réseau sur le nœud maître :
kubectl apply -f https://raw.githubusercontent.com/flannel-io/flannel/master/Documentation/kube-flannel.yml, où 185.199.108.133 raw.githubusercontent.com Add etc/hosts
(Référence 5 : https://www.cnblogs.com/sinferwu/p/12726833.html )
3. Problèmes lors de l'exécution de kubectl get nodes
1) n'a pas pu obtenir la liste actuelle des groupes d'API du serveur :
résolu :
la commande ne peut pas être exécuté en tant que root.
2) Problème kubernetes-admin
L'entrée K8S kubectl get nodes affiche La connexion au serveur localhost:8080 a été refusée - avez-vous spécifié le bon hôte ou le bon port ? La raison
de ce problème est que la commande kubectl doit être exécutée avec kubernetes-admin . Cela peut être dû à un environnement système impur, comme le fait de ne pas effacer complètement la configuration avant de réinstaller k8s.
Solution :
(1) Copiez le fichier /etc/kubernetes/admin.conf généré après l'initialisation du nœud maître dans le répertoire correspondant du nœud esclave.
scp /etc/kubernetes/admin.conf host1:/etc/kubernetes/

(2) Définir les variables d'environnement sur tous les nœuds et mettre à jour
echo "export KUBECONFIG=/etc/kubernetes/admin.conf" >> ~/.bash_profile
source ~/.bash_profile


Vérifiez la véritable adresse IP de raw.githubusercontent.com sur https://www.ipaddress.com/.
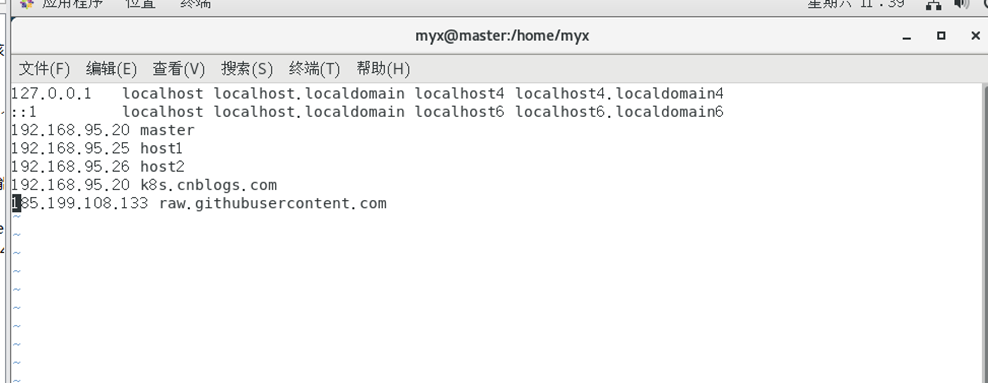
courir à nouveau
kubectl apply -f https://raw.githubusercontent.com/flannel-io/flannel/master/Documentation/kube-flannel.yml
Installez la flanelle avec succès !

Lorsque la liste des nœuds du cluster est à nouveau obtenue via la commande kubectl get nodes, il s'avère que l'état du cluster host1 est toujours à l'état NotReady et une erreur est signalée en vérifiant le journal :
journalctl -f -u kubelet
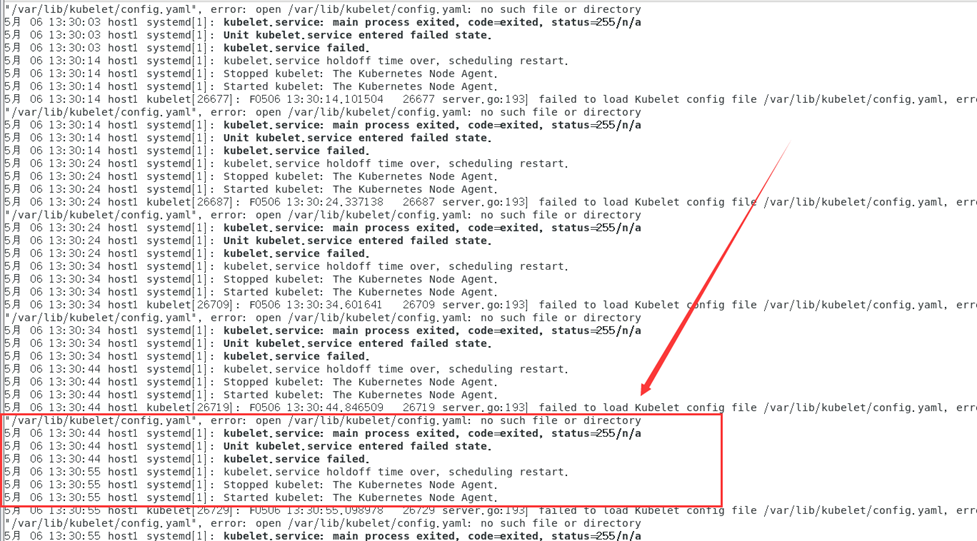
Selon les informations du journal, la raison de l'erreur est que la configuration de kubelet ne peut pas être téléchargée depuis /var/llib/kubelet/config.yaml.
La raison de l'erreur est probablement que je l'ai exécuté sans faire kubeadm init auparavant systemctl start kubelet.
On peut essayer de mettre à jour le token et régénérer le token, le code est le suivant :
kubeadm token create --print-join-command
Mettez à jour le contenu de la sortie de copie de jeton sur le nœud maître g

et exécutez-le dans hsot1
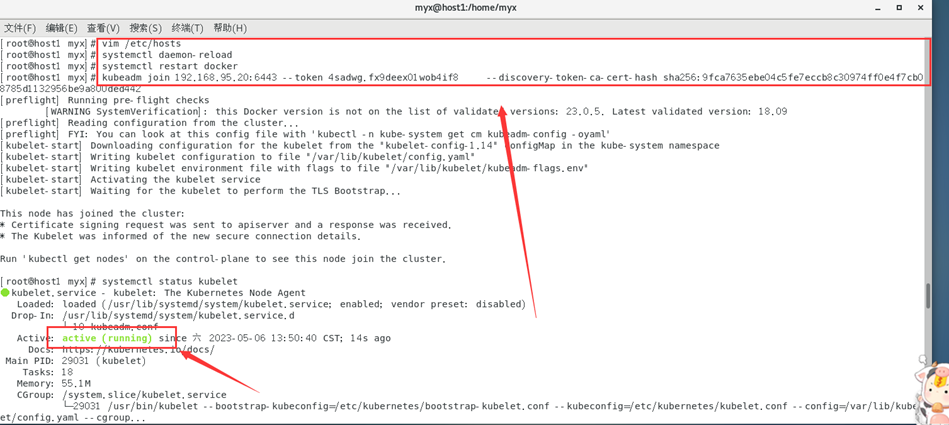
pour résoudre le problème avec succès !
Les clusters sont tous à l'état Prêt !

Référence six : https://www.cnblogs.com/eastwood001/p/16318644.html
5. Testez Kubernetes
1. Exécutez sur le nœud maître :
kubectl create deployment nginx --image=nginx #创建一个httpd服务测试

kubectl expose deployment nginx --port=80 --type=NodePort #端口就写80,如果你写其他的可能防火墙拦截了

kubectl get svc,pod #对外暴露端口

2. Accédez à la page d'accueil de Nginx en utilisant l'adresse IP du nœud maître et le port réservé :
par exemple :
192.168.95.20:21729
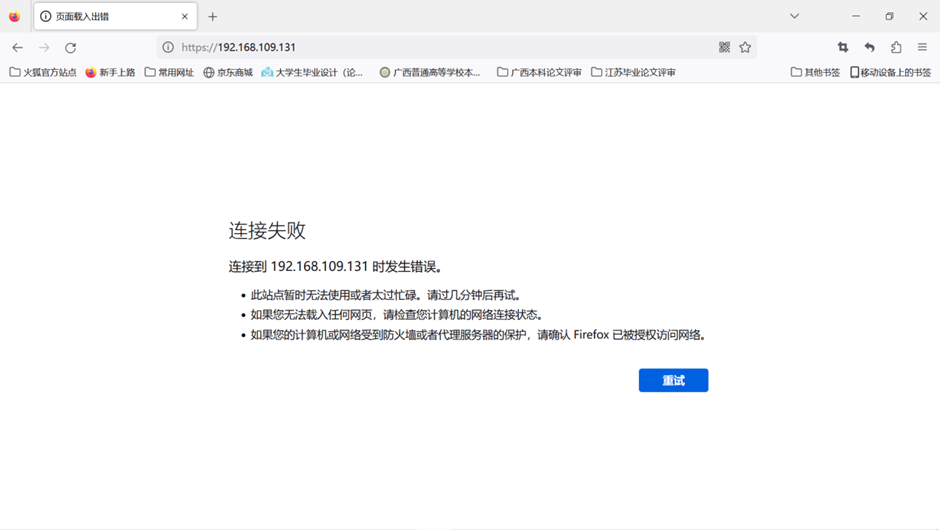
afficher la connexion a échoué
à l'aide de la commande
kubectl describe pod nginx-77b4fdf86c-krqtk
Montrer les résultats:
open /run/flannel/subnet.env: no such file or directory
J'ai constaté qu'il me manquait les fichiers de configuration réseau CNI pertinents.
Nous devons vérifier soigneusement chaque nœud, y compris si le nœud principal existe /run/flannel/subnet.env. Le contenu doit être similaire à ce qui suit :
FLANNEL_NETWORK=10.244.0.0/16
FLANNEL_SUBNET=10.244.0.1/24
FLANNEL_MTU=1450
FLANNEL_IPMASQ=true
En vérifiant le journal des erreurs, j'ai constaté qu'il me manquait le fichier de configuration réseau cni correspondant.
Créez les fichiers de configuration liés au réseau cni :
mkdir -p /etc/cni/net.d/
cat <<EOF> /etc/cni/net.d/10-flannel.conf
{
"name":"cbr0","type":"flannel","delegate": {
"isDefaultGateway": true}}
EOF
Ici, nous utilisons la commande cat et l'opérateur de redirection (<<) pour écrire {"name": "cbr0", "type": "flannel", "delegate": {"isDefaultGateway": true}} dans /etc/cni /net.d/10-flannel.conf.
mkdir /usr/share/oci-umount/oci-umount.d -p
mkdir /run/flannel/
cat <<EOF> /run/flannel/subnet.env
FLANNEL_NETWORK=10.199.0.0/16
FLANNEL_SUBNET=10.199.1.0/24
FLANNEL_MTU=1450
FLANNEL_IPMASQ=true
EOF
Ici, entre <<EOF et EOF, il y a plusieurs lignes de texte, et chaque ligne contient la définition d'une variable d'environnement. Plus précisément :
FLANNEL_NETWORK=10.199.0.0/16 définit une variable d'environnement nommée FLANNEL_NETWORK et la définit sur 10.199.0.0/16.
FLANNEL_SUBNET=10.199.1.0/24 définit une variable d'environnement nommée FLANNEL_SUBNET et la définit sur 10.199.1.0/24.
FLANNEL_MTU=1450 définit une variable d'environnement appelée FLANNEL_MTU et la définit sur 1450.
FLANNEL_IPMASQ=true définit une variable d'environnement appelée FLANNEL_IPMASQ et la définit sur true.
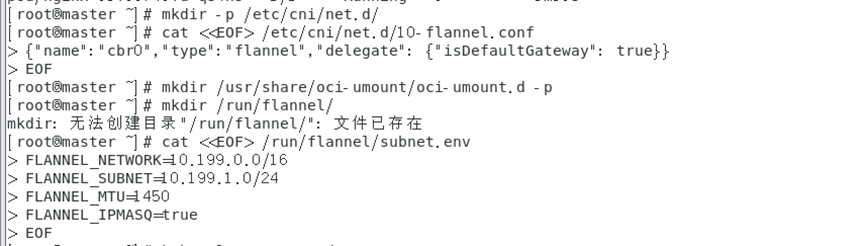
Si un nœud ne possède pas le fichier, copiez-le et déployez-le à nouveau. Cette erreur ne doit pas être signalée.
Vérifions-le sur le nœud host1 :
cat /run/flannel/subnet.env
cat /etc/cni/net.d/10-flannel.conf

Grâce à la commande, vous pouvez voir que le nœud esclave possède déjà des fichiers de configuration associés liés au réseau cni.
Si ces fichiers de configuration importants sont manquants, des erreurs seront également signalées dans le journal du cluster :
cni config uninitialized
5月 06 12:44:06 master kubelet[48391]: W0506 12:44:06.599700 48391 cni.go:213] Unable to update cni config: No networks found in /etc/cni/net.d
5月 06 12:44:07 master kubelet[48391]: E0506 12:44:07.068343 48391 kubelet.go:2170] Container runtime network not ready: NetworkReady=false reason:NetworkPluginNotReady message:docker: network plugin is not ready

S'il n'y a aucun problème avec la configuration ci-dessus,
nginx s'affiche avec succès à la fin.
Kubectl get nodes
La commande kubectl get nodes renverra ici un tableau contenant des informations sur tous les nœuds du cluster, telles que le nom du nœud, l'état, le rôle (maître/travailleur), etc.

saisie de l'URL du navigateur
192.168.95.25:30722

Ou saisissez CLUSTER-IP :
10.100.184.180

De cette façon, nous avons déployé avec succès le cluster Kubernetes et terminé le déploiement de nginx !
Ceux-ci sont tous testés personnellement et peuvent être déployés avec succès selon les opérations normales ci-dessus. Je vous souhaite tout le meilleur.
Enfin, je vous souhaite tout le meilleur pour les vacances d'été, étudiez solidement et à fond et amusez-vous.