


Medien für Innovationsdienste der Data-Intelligence-Branche
——Fokus auf digitale Intelligenz und Change Business
Eines Morgens an einem Arbeitstag erhielt Xiao Li, der Leiter des Datenentwicklungsteams eines E-Commerce-Unternehmens, einen Anruf von einem Kollegen aus der Geschäftsabteilung: „Herr Li, wir brauchen ein Datenblatt über die Verkäufe eines.“ Bestimmtes Produkt, aber wir haben lange danach gesucht und konnten es nicht bekommen. Sobald wir genaue Daten erhalten, wird die Aktion in den nächsten Tagen gestartet, und wir wagen es nicht, ohne Daten zufällige Entscheidungen zu treffen. .."
Xiao Li rief sofort die Mitglieder des Datenentwicklungsteams zu einer Notfallbesprechung an, um zu besprechen, wie der Geschäftsabteilung schnell genaue Daten bereitgestellt werden können. Am Ende stellte Xiao Li fest, dass die Mitglieder des Datenentwicklungsteams unterschiedliche Datenmodelle und -spezifikationen verwendeten und es an einem einheitlichen Standard mangelte, was sich stark auf die Datenqualität und die Ausgabeeffizienz auswirkte. Gleichzeitig kann die Datenqualität aufgrund des Fehlens wirksamer Data-Governance-Maßnahmen nicht effektiv gewährleistet werden, was zu unbefriedigten Datenbedürfnissen der Geschäftsabteilungen führt ...
Dieses Szenario ist ein Problem, mit dem die Datenteams vieler Unternehmen häufig konfrontiert sind. Mit der kontinuierlichen Weiterentwicklung der Digitalisierung haben viele Unternehmen tatsächlich begonnen, ihre eigenen „Datenbestände“ anzusammeln und anzuhäufen, und verschiedene Systeme haben auch ihre Datenanalysefähigkeiten und -fähigkeiten verbessert So viel wie möglich. Effizienz Es gibt jedoch immer noch eine unüberbrückbare „Lücke“ zwischen Datenentwicklung und Datenverbrauch, da es dem Datenentwicklungsprozess aus geschäftlicher Sicht an Qualitätssicherung mangelt, was sich stark auf die Effizienz des Geschäftsbetriebs, das Management und die Entscheidungsfindung auswirkt. Gründung von Unternehmen.
Wenn sich viele Unternehmen mit diesem Problem befassen, besteht die häufigste Methode darin, ein separates Datenverwaltungssystem aufzubauen und durch abteilungsübergreifende Zusammenarbeit und Kommunikation einen Mechanismus und Prozess für die Zusammenarbeit einzurichten, wodurch die Verbindung zwischen Datenentwicklung und Datenverwaltung gestärkt wird. Oberflächlich betrachtet löst diese Methode das Problem, tatsächlich erhöht sie jedoch die Kommunikationskosten und verlangsamt die Effizienz des Teams.
Massive Daten konnten nicht nur die Effizienz der Teamarbeit verbessern, sondern verursachten auch das Problem der „Datenarmut“. Laut dem Bericht von Gartner werden Unternehmen aufgrund von Datenqualitätsproblemen jedes Jahr 1 Milliarde US-Dollar verlieren. Wie kann dieses Problem gelöst werden? Als Reaktion auf dieses Problem interviewte Data Ape Yu Lihua, General Manager der Big-Data-Produktlinie von Netease Shufan, um die innovative Praxis von Netease Shufan bei der Integration von Datenentwicklung und Governance vorzustellen.
Massendaten sind nicht gleichbedeutend mit Datenbeständen
Mit der rasanten Entwicklung der Big-Data-Technologie und der kontinuierlichen Weiterentwicklung der Unternehmensdigitalisierung nimmt auch die Datenmenge zu. Im Zuge der Digitalisierung sollten Unternehmen ihr Datenpotenzial nutzen, um sich an externe Veränderungen anzupassen. Gartner ist der Ansicht, dass die Assetisierung von Daten in Betracht gezogen werden sollte. Digitale Assets sollten lieferbare und wiederverwendbare Produkte mit hohem gemeinsamem Wert sein. Riesige Datenmengen führen jedoch oft dazu, dass Unternehmen in die missliche Lage der „Datenarmut“ geraten, was die gemeinsame Nutzung und Wiederverwendung erschwert. Yu Lihua glaubt, dass sich Datenarmut auf vier Aspekte konzentriert: Sie können sie nicht finden, Sie können sie nicht verstehen, Sie können ihnen nicht vertrauen und Sie können sie nicht kontrollieren.
„Nicht gefunden“ bedeutet, dass in modernen Unternehmen Daten oft in dezentralen Datenbanken gespeichert werden, die von verschiedenen Abteilungen oder Teams gepflegt werden können. Dies hat dazu geführt, dass einige Daten nicht im Verzeichnis gemountet werden und die Standardisierung schlecht ist. Das Auffinden der gewünschten Daten für Geschäftsmitarbeiter ist für das Geschäftspersonal gleichbedeutend mit der Suche nach der Nadel im Heuhaufen. Genau wie das E-Commerce-Unternehmen am Anfang des Artikels hat es große Datenmengen angesammelt und verfügt über ein professionelles Datenteam, aber das Geschäftspersonal kann die benötigten Daten immer noch nicht finden. Natürlich gibt es solche Probleme nicht nur bei E-Commerce-Unternehmen, auch große Internetunternehmen wie NetEase hatten zuvor ähnliche Probleme. Innerhalb von NetEase verfügt NetEase Yanxuan beispielsweise über mehr als 100.000 Tabellen für ein Unternehmen und Cloud Music über mehr als 80.000 Tabellen. Für Geschäftspersonal ist es sehr schwierig, die erforderlichen Daten zu finden. Dies verschwendet nicht nur Zeit und Energie des Geschäftspersonals, sondern schränkt auch die Genauigkeit und Effizienz der Unternehmensentscheidungen ein.
„Unverständlich“ ist ein Problem, das durch fehlende Metadaten und schlechte Verwaltung verursacht wird. In einem bestimmten Unternehmen innerhalb von NetEase fehlten beispielsweise 78 % der Metadaten, selbst wenn das Geschäftspersonal die Daten fand, konnte es sie nicht verstehen. Dies liegt daran, dass Daten oft in einem Fachbegriff gespeichert werden, der für Laien schwer verständlich sein kann. Darüber hinaus können die Daten selbst komplex sein und erfordern Spezialwissen, um sie zu verstehen. Wenn Geschäftsleute Daten nicht verstehen, können sie sie nicht für gute Entscheidungen nutzen.
„Unzuverlässig“ ist vor allem auf Probleme mit der Datenqualität und Glaubwürdigkeit zurückzuführen. Beispielsweise wurden in einem bestimmten Unternehmen innerhalb von NetEase jede Woche mehr als 10 Probleme mit der Datenqualität beanstandet, und es gab sogar ein Problem mit Datenlecks bei Lieferanten … Dies zeigt, dass es Probleme mit der Qualität und Glaubwürdigkeit der Daten gibt. Zu den Datenqualitätsproblemen können fehlende Daten, Datenfehler, Datenduplizierung usw. gehören. Diese Probleme führen dazu, dass das Geschäftspersonal an der Richtigkeit der Daten zweifelt und ihr Vertrauen in die Daten beeinträchtigt . Datenlecks werden zur Offenlegung von Geschäftsgeheimnissen und der Privatsphäre der Kunden von Unternehmen führen und den Ruf und die Glaubwürdigkeit von Unternehmen ernsthaft beeinträchtigen.
„Unkontrollierbar“ bedeutet vor allem, dass Daten nicht effektiv verwaltet und kontrolliert werden können. Im Rechenzentrum einer Geschäftseinheit belegen beispielsweise 78,39 % der Tabellen 21,63 % des Speicherplatzes. Auf diese Daten, die viel Entwicklungsarbeitskraft, Speicherressourcen und Rechenressourcen verbrauchen, wurde jedoch kein einziges Mal zugegriffen 30 Tage, was zu einer großen Menge an Ressourcen führt. Verschwendung. Wenn die Daten nicht effektiv verwaltet und kontrolliert werden, führt dies zu unnötiger Duplizierung, Redundanz und Nutzlosigkeit der Daten, wodurch Ressourcen und Kosten des Unternehmens verschwendet werden.
Zusammenfassend lässt sich sagen, dass die schlechte Qualität von Datenbeständen ein ernstes Problem darstellt und DataOps als neues Tool zur effizienten Datennutzung und verbesserten datengesteuerten Entscheidungsfindung große Aufmerksamkeit erhalten hat. Derzeit ist die gängige DataOps-Praxis auf dem Markt die Einrichtung einer Datenentwicklungspipeline, die CI/CD-Funktionen integriert. Obwohl diese Methode den gesamten Datenentwicklungsprozess standardisiert, fehlt ihr immer noch die notwendige Infrastruktur, um den Datenverbrauchsanforderungen gerecht zu werden. Einschränkungen, und das tat sie auch Da die oben genannten vier häufigen Probleme nicht vollständig gelöst werden können, ist es notwendig, Lösungen aus einer höheren Dimension zu finden.
Netease war Vorreiter bei der Integration von Datenentwicklung und Governance
Um das Problem der „Datenarmut“ grundlegend zu lösen, schlug NetEase Shufan das Konzept der Datenentwicklung und Governance-Integration basierend auf der Datenentwicklungspipeline vor, bei der es sich um die End-to-End-DataOps-Praxis handelt. Aus der wörtlichen Bedeutung geht hervor, dass der Unterschied zwischen der Methode von Netease Shufan und der herkömmlichen Methode darin besteht, dass sie Datenentwicklung und Datenverwaltung vollständig miteinander verbindet. Yu Lihua sagte gegenüber Data Ape, dass, wenn viele Unternehmen Data-Middle-End betreiben oder Datenplattformen aufbauen, der Datenentwicklungsprozess und der Data-Governance-Prozess getrennt sind und möglicherweise sogar Dienste von verschiedenen Anbietern bereitgestellt werden. Die Trennung der beiden kann leicht dazu führen Datenstandards und Metadaten. Es gibt Unterschiede in den Daten usw., was wiederum dazu führt, dass das Geschäftspersonal beim Datenkonsum Daten nicht finden oder verstehen kann, was zu „Datenarmut“ führt. Der Kern des von Netease Shufan vorgeschlagenen End-to-End-DataOps besteht aus 12 Worten: Zuerst entwerfen, dann entwickeln, zuerst standardisieren und dann modellieren. Das heißt, vor der Datenentwicklung müssen Unternehmen klar darüber nachdenken, welche Daten benötigt werden und wie sie gestaltet werden sollen ... und dann mit der Datenentwicklung gemäß dem Gesamtdesign fortfahren. Dieser Prozess ist dem Entwicklungsprozess eines Softwareprojekts sehr ähnlich. Beginnen Sie am Ende und bestimmen Sie zunächst die Ziele und Anforderungen des Produkts, um die Korrektheit und Effizienz des Entwicklungsprozesses sicherzustellen. Gleichzeitig kann es Unternehmen dabei helfen, Einsparungen zu erzielen die Kosten für den Aufbau von Datenplattformen.
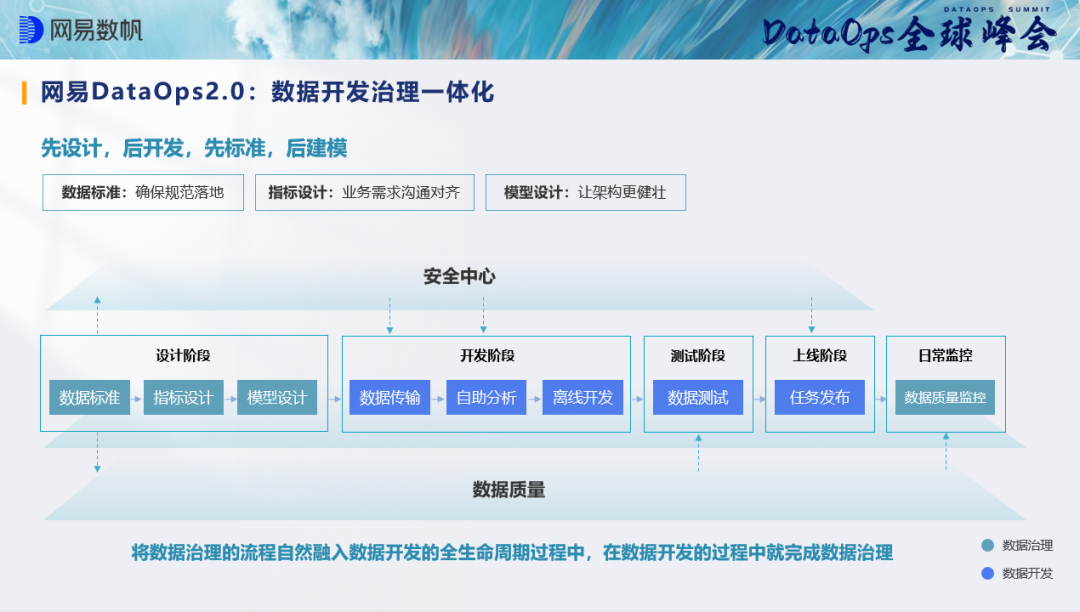
Tatsächlich lässt sich anhand des Kerns dieser 12 Charaktere leicht erkennen, dass Netease Shufan eine globalere Perspektive bei der Lösung von Problemen hat. Die traditionelle Lösung ist eine „Block-für-Block“-Lösung oder eine lokale Perspektive, während End-to-End-DataOps eine umfassende Überlegung darstellt. In der frühen Phase des Plattformaufbaus müssen Geschäftsparteien, Datenarchitekten und Datenproduktentwickler dies tun Führen Sie das Gesamtdesign durch. Erstellen Sie geschäftsbezogene Spezifikationen für Datenstandards und verwenden Sie dann Datenstandards als Kern, um automatisch Regeln für die Datenqualitätsprüfung zu generieren, automatisch Tabellenklassifizierungs- und -bewertungsstrategien, Datendesensibilisierungsstrategien, Datensicherheitsmanagementstrategien usw. zu generieren. - Dies alles stellt sicher, dass Unternehmensdaten Kernressourcen besser teilen und wiederverwenden können. Zurück zum E-Commerce-Unternehmen am Anfang des Artikels: Wenn vor der Datenentwicklung ein vollständiger Entwurf vorliegt und die Standards und Spezifikationen zuerst geklärt werden, weist die nachfolgende Datenplattform keine Daten auf, die nicht gefunden werden können.
Aus dieser Logik ist es nicht schwer zu erkennen, dass bei der Integration von Datenentwicklung und Governance der nachfolgende Entwicklungs- und Modellierungsprozess sehr reibungslos abläuft und die Modelle gemäß dem Design erstellt werden, solange ein Design und ein Standard vorhanden sind und die Standardspezifikationen entsprechen den Spezifikationen. Es muss überprüft, umgestaltet und umgestaltet werden.
Für Unternehmen besteht aufgrund des Gesamtdesigns und der Standards der Datenplattform kein Grund zur Sorge über die Codierungsprobleme im nachfolgenden Entwicklungs- und Modellierungsprozess, und sie können die Codierung aufgrund der Einschränkungen sogar getrost an Drittunternehmen auslagern vor dem Standard Unter der aktuellen Situation gibt es im Grunde keinen „seltsamen Kreis“ endloser Revisionsprobleme nach dem Online-Gehen, und es gibt im Grunde kein Problem mit gelieferten Produkten, die nicht den Spezifikationen und Standards entsprechen. Schließlich sind die Spezifikationen und Standards wurden bereits festgelegt. Auf diese Weise müssen sich Unternehmen nicht mehr um das Problem der „Datenarmut“ kümmern, die Effizienz der Datennutzung und des Geschäftsbetriebs kann erheblich verbessert werden und auch die Entwicklungskosten werden erheblich gesenkt.
Mit Blick auf das Endergebnis hat sich die Effizienz des F&E-Teams um das Zehnfache gesteigert
Yu Lihua glaubt, dass der Wert von End-to-End-DataOps für Datenbestände in gewisser Weise mit dem „iPhone-Moment“ im Mobiltelefonbereich verglichen werden kann, der die Regeln der Datenverwaltung grundlegend neu definieren wird. Im Vergleich zu herkömmlichen Lösungen kann das Kernkonzept der Datenentwicklung und Governance-Integration grundsätzlich als „Dimensionsreduzierungsschlag“ beschrieben werden, da es aus einer umfassenderen Perspektive betrachtet wird und am Ende über den Aufbau eines Rechenzentrums oder einer Datenplattform nachdenkt , nicht nur in einen bestimmten Link verwickelt. Die Integration von Entwicklung und Governance kann viele Vorteile bringen: Sie löst die Probleme beim Auffinden, Verstehen, Vertrauenswürdigkeit und Verwaltbarkeit von Daten, verbessert die Qualität und Effizienz des Aufbaus von Datenbeständen erheblich und reduziert die durch Datenfehler verursachte Nacharbeit, wodurch die Schwierigkeit verringert wird Entwicklung und Verwaltung der Zusammenarbeit zwischen mehreren Teams, sodass die Effizienz bei der Bereitstellung von Anwendungen höher wird. Gartner prognostiziert, dass die Effizienz von Forschungs- und Entwicklungsteams, die DataOps-Methoden anwenden, bis 2025 im Vergleich zu herkömmlichen Methoden um das Zehnfache gesteigert werden kann.
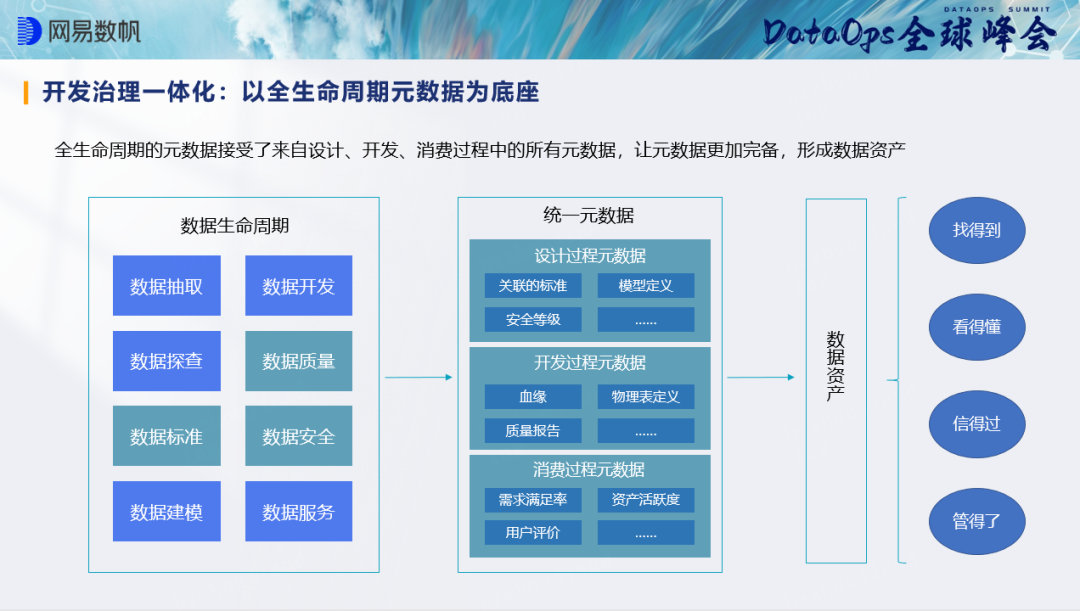
Am Beispiel von Netease Cloud Music kann die Einführung des DataOps-Entwicklungs- und Governance-Integrationsmodells die Effizienz der Modellwiederverwendung, der Spezifikationskonstruktion und der Regelabdeckung verbessern. Durch logisches Senken kann die Anzahl der Indikatoren erheblich reduziert werden, und die Wiederverwendung von Cloud-Musikmodellen wurde bereits durchgeführt um das Vierfache erhöht, und 34.000 Modelle waren offline; in Bezug auf die Spezifikationskonstruktion gab es zuvor keine Sicherheitsspezifikation, und das aktuelle Sicherheitsniveau von Feldern und Indikatoren wurde zu 100 % eingestellt; in Bezug auf die Qualität die Regelabdeckung Die Datenrate wurde erheblich verbessert, die Geschäftsmetadaten wurden ebenfalls ergänzt und die Daten wurden besser genutzt.
Aus Sicht der Datenanwendung glaubt Yu Lihua, dass die Integration von Entwicklung und Governance auch die Self-Service-Datendienstfunktionen von Managern und Geschäftsteams verbessert hat . Ein Kunde von Netease Shufan hat durch den Aufbau einer integrierten Datenentwicklungs- und Governance-Plattform von 0 auf 1 einen nützlichen Datenbestand geschaffen. Derzeit gibt es 200 Datenanalyseteams, die Self-Service-Analysen durchführen können, darunter 32 Führungskräfte. Darüber hinaus kann es die Wahrscheinlichkeit von Datenunfällen verringern und die Compliance-Fähigkeiten des Unternehmens verbessern . Derzeit hat NetEase Shufan 180 Standards für einen Finanzkunden implementiert und hilft Kunden dabei, das Risiko regulatorischer Strafen effektiv zu reduzieren.
Yu Lihua stellte Data Ape auch den Fall eines bestimmten Telekommunikationsbetreibers vor, um die Vorteile, die die Integration von Datenentwicklung und Governance mit sich bringen kann, weiter zu analysieren.
Ein Telekommunikationsbetreiber ist ein staatliches Unternehmen mit einer großen Menge an Benutzerdaten und Betriebsdaten. Um diese Daten besser verwalten zu können, richtete der Betreiber mehrere Datensysteme ein und implementierte ein Data-Governance-Projekt. Allerdings stehen sie immer noch vor dem Dilemma, dass der Standard nicht umgesetzt werden kann. Tatsächlich besteht das Hauptproblem für den Betreiber darin, dass Datenstandards, Datenqualität und Datenentwicklungsspezifikationen nur auf der Wörterbuchebene bleiben und nicht in den Datenproduktionsprozess integriert werden können. Zweitens können die Datenqualitätsprüfungsregeln nicht mit den Wertebereichsbeschränkungen der Datenelemente in den Datenstandards in Verbindung gebracht werden, die Datenelemente in den Datenstandards können nicht mit den Datenmodellierungstools verknüpft werden und das Datensicherheitsniveau in der Metadatenverwaltung und Die Datendesensibilisierung des Sicherheitscenters kann nicht verknüpft werden. .
Um diese Probleme zu lösen, führte der Betreiber die Netease Shufan EasyData-Plattform ein, um End-to-End-DataOps zu realisieren. Die erfolgreiche Anwendung der EasyData-Plattform bietet eine gute Lösung für die Datenverwaltung des Betreibers und beweist auch, dass die Integration der Datenentwicklung die Datenqualität und Entwicklungseffizienz effektiv verbessern kann. Mit Hilfe der EasyData-Plattform hat der Telekommunikationsbetreiber mehr als 100 Datenqualitätsaudits erstellt, die mehr als 8.000 Online-Vorgänge abdecken, und insgesamt mehr als 60.000 Self-Service-Analysezeiten unterstützt. Für den Verbraucher ist die Datenbeschaffung kein Problem mehr qualitativ hochwertige Daten zeitnah bereitzustellen. Man kann sagen, dass die Implementierung von EasyData nicht nur die Datenverwaltung und -verwaltung stärkt, sondern auch die manuelle Beteiligung an der Datenverwaltung wirksam reduziert und die Effizienz der Datenausgabe verbessert.
Natürlich spiegeln sich die Vorteile der Datenentwicklung und Governance-Integration nicht nur in der „Kostenreduzierung und Effizienzsteigerung“ auf der Benutzerseite und den Datensicherheitsspezifikationen wider, sondern haben auch ihre eigenen einzigartigen Vorteile in Bezug auf Forschungs- und Entwicklungseffizienz, Datenqualität und Selbst -Service und Reduzierung von Datenunfällen.
Data Ape Observation: Die Integration von Datenentwicklung und Governance ist zu einem neuen Trend geworden
Da die Vorteile der Datenentwicklung und Governance-Integration so offensichtlich sind, stellt sich die Frage, ob dies zum zukünftigen Trend der Branche werden wird? Data Ape glaubt, dass es unter den folgenden vier Gesichtspunkten betrachtet werden kann.
Erstens kann die Integration der Datenentwicklungs-Governance die Datenqualität und -zuverlässigkeit verbessern. Laut dem Bericht von Gartner kann die integrierte Lösung aus Datenentwicklung und Governance den durch Datenqualitätsprobleme verursachten Verlust minimieren und so die Entscheidungseffizienz und den Geschäftsvorteil von Unternehmen verbessern.
Zweitens entspricht die Integration von Datenentwicklung und Governance den Gesetzen, Vorschriften und Marktanforderungen. Laut dem Marktforschungsunternehmen IDC wird der globale Markt für Data Governance- und Datenschutzlösungen bis 2025 ein Volumen von 15,2 Milliarden US-Dollar erreichen. Die Integration von Datenentwicklung und Governance kann Unternehmen dabei helfen, die Anforderungen von Gesetzen und Vorschriften zu erfüllen, z. B. den Schutz personenbezogener Daten, die gesetzeskonforme Erfassung und Nutzung von Daten sowie die Verbesserung der Wettbewerbsfähigkeit und Innovationsfähigkeit von Unternehmen.
Drittens kann die Integration von Datenentwicklung und Governance die Effizienz und Innovationsfähigkeit der Datenproduktion verbessern. Laut dem Umfragebericht von Forrester glauben mehr als 50 % der Unternehmen, dass die Effizienz der Datenentwicklung und die Innovationsfähigkeit ihre größten Sorgen bereiten . Die Integration von Datenentwicklung und Governance kann das einheitliche Management von Dateneffizienz und Innovationsfähigkeiten verbessern und dadurch die Wettbewerbsfähigkeit und Innovationsfähigkeit von Unternehmen verbessern.
Viertens ist die Integration von Datenentwicklung und Governance förderlicher für die Integration verschiedener neuer Technologien. Seit Anfang dieses Jahres hat die künstliche Intelligenz mit der Popularität von ChatGPT viel Aufmerksamkeit erregt. Data Ape ist der Ansicht, dass seine Entwicklung nicht von der Unterstützung getrennt werden kann, unabhängig davon, ob es sich um ein Allzweck-Großmodell oder ein groß angelegtes vertikales Modell handelt von Enterprise Big Data und wie man die von Unternehmen angesammelten Datenbestände sinnvoll nutzt und wie man groß angelegte Modellprodukte trainiert, die das eigene Unternehmen unterstützen, stehen in direktem Zusammenhang mit der Datenentwicklung und Datenverwaltung. Öffnen der Datenbestände von Unternehmen ist genau der Vorteil der Datenentwicklung und Governance-Integration.
Basierend auf den oben genannten vier Punkten können wir es in einem Satz zusammenfassen: Das integrierte Modell der Datenentwicklung und -verwaltung entspricht eher dem zukünftigen Entwicklungstrend der Datenindustrie und ist auch ein „Stärkeinstrument“. „Um die Wettbewerbsfähigkeit von Unternehmen zu steigern. Tatsächlich wurde die Integration von Datenentwicklung und Governance in den „DataOps Practice Guide (1.0)“ geschrieben, der vom Institut für Cloud Computing und Big Data der China Academy of Information and Communications Technology geleitet wird. Integrierte DataOps, durch den Aufbau globaler Daten Beobachtungsansicht und Front-End-Datenqualitätskontrolle können die früheren Probleme von zwei Skins in Entwicklung und Governance, ungleichmäßigen Datenanforderungen, geringer Produktbereitstellungseffizienz, Schwierigkeiten bei der Förderung der domänenübergreifenden Zusammenarbeit und Schwierigkeiten bei der Kontrolle der Entwicklungskosten effektiv lösen.
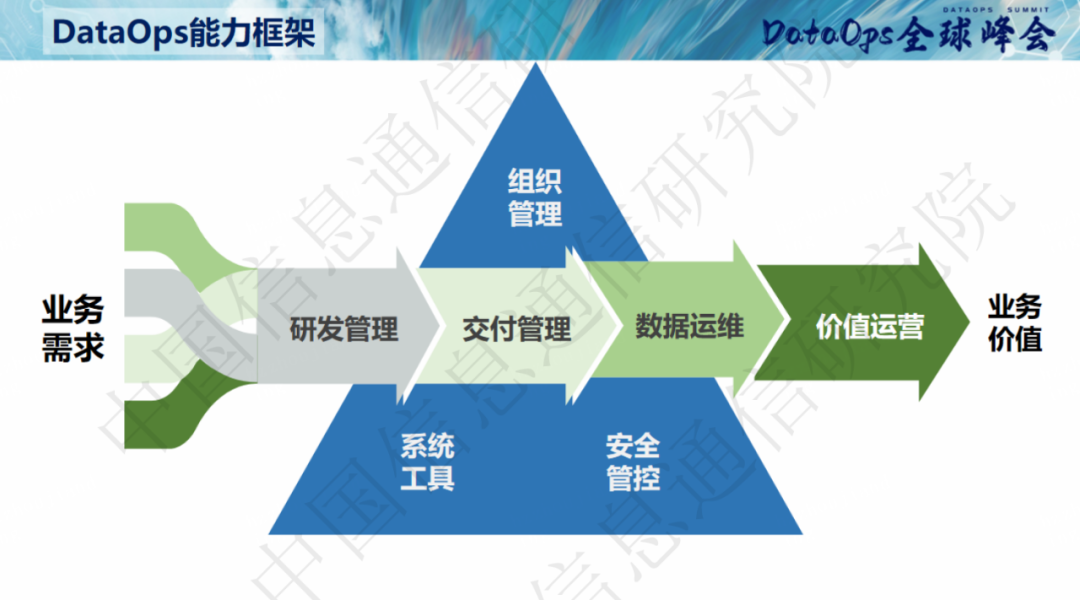
Yu Lihua erwähnte zwei Punkte, als er über die zukünftige Planung von DataOps sprach: Der eine besteht darin, weiterhin gute Arbeit in der grundlegenden Arbeit zu leisten, hauptsächlich um die Benutzererfahrung kontinuierlich zu verbessern und mehr Datenbanken zu verbinden, um Echtzeit-DataOps zu erstellen usw.; der Die andere besteht darin, die Datenentwicklung und Governance-Integration sowie die Integration neuer Technologien wie Low-Code, AIGC usw. durch kontinuierliche Integration neuer Technologien, intelligente Governance-Funktionen wie Empfehlungen für Sicherheitsstufen, standardmäßige automatische Zuordnung, automatische Generierung von Rechenaufgaben usw. zu untersuchen Fehlerkorrektur und automatische Fehlerdiagnose können realisiert werden, wodurch die Benutzernutzungsschwelle reduziert wird. Data Ape glaubt, dass diese beiden Richtungen die strategische Ausrichtung von NetEase Shufan sind, „hohe Mauern zu bauen und Lebensmittel in großem Umfang anzusammeln“.
Im digitalen Zeitalter, in dem die digitale Transformation ständig voranschreitet und sich die technologische Innovation beschleunigt, kämpfen Unternehmen bis zum Ende nicht um die Anhäufung von Daten und die Geschwindigkeit der Technologieiteration, sondern um die Effizienz der Daten.
Um neue Ideen und neue Richtungen für die digitale Intelligenz von Unternehmen zu liefern, veranstaltete Netease Shufan am 10. August gemeinsam mit der China Academy of Information and Communications Technology, ökologischen Partnern, Finanz-, Fertigungs- und anderen Unternehmen eine Veranstaltung zum Thema „Intensive Landwirtschaft für die Digitalisierung“. Intelligence“ im JW Marriott Hotel in Peking . Innovationsbeschleunigung – NetEase Shufan City Tour (Peking) „Branchengipfel, um die neuesten Fortschritte der digitalen Intelligenztechnologie und praktische Branchenerfahrungen auszutauschen.
Text: Gewinner / Datenaffe


