(Cet article est une petite note et une perception de l'apprentissage des reptiles par moi-même)
Après l'apprentissage initial de python, vous devriez déjà avoir une impression générale de concepts tels que les chaînes, les listes, les dictionnaires, les tuples, les instructions conditionnelles, les instructions de boucle, etc., et enfin vous pouvez commencer à faire quelques petits exercices pour consolider vos points de connaissance. L'écriture d'exercices sur chenilles est parfaite.
1. Les bases du Web
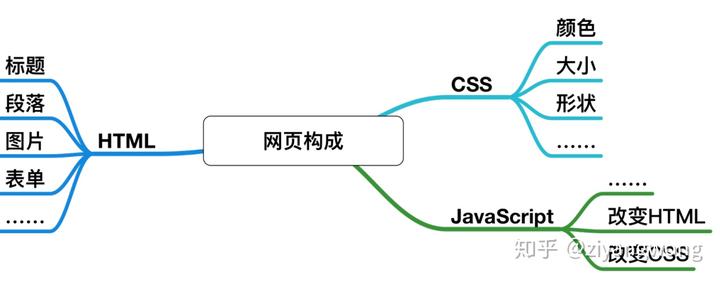
L'essence d'un crawler est d'obtenir les informations requises à partir d'une page Web, et il est encore nécessaire d'avoir un peu de compréhension de la connaissance de la page Web. La définition de Baidu Encyclopedia de HTML : HTML, Hypertext Markup Language, est un langage de marquage. Il comprend une série de balises. Grâce à ces balises, le format du document sur le réseau peut être unifié et les ressources Internet dispersées peuvent être connectées en un tout logique. Le texte HTML est un texte descriptif composé de commandes HTML, qui peuvent expliquer du texte, des graphiques, des animations, des sons, des tableaux, des liens, etc.
Bien sûr, les pages Web ne sont pas seulement HTML, elles ne peuvent obtenir que des effets statiques, et les pages Web que nous voyons souvent ont également du CSS avec des styles d'embellissement et du JavaScript pour des effets dynamiques. Les robots d'exploration n'ont pas d'exigences élevées pour le langage frontal, et il suffit de trouver les informations dont ils ont besoin pour explorer.Bien sûr, les robots d'exploration de chaussures pour enfants avec une base frontale seront plus pratiques.