algorithme de rétropropagation
La rétropropagation est un algorithme d'apprentissage supervisé utilisé pour former des perceptrons multicouches (réseaux de neurones artificiels).
OK, pourquoi avons-nous besoin de rétropropagation?
Lors de la conception d'un réseau de neurones, nous initialisons d'abord les poids avec des valeurs aléatoires ou n'importe quelle variable. De toute évidence, nous ne sommes pas des surhumains et nous ne pouvons garantir que les poids que nous choisissons seront corrects ou s'adapteront le mieux à notre modèle. D'accord, d'accord ! Nous avons choisi certaines valeurs de poids au début, mais nous avons constaté que : la sortie du modèle est très différente de la sortie réelle, c'est-à-dire que la valeur d'erreur est grande.
Maintenant, comment pouvons-nous réduire cette valeur d'erreur ?
Fondamentalement, tout ce que nous devons faire est de continuer à modifier les paramètres du modèle de manière à minimiser l'erreur. En d'autres termes, nous devons former notre modèle, et pour être plus précis, c'est-à-dire rétropropager notre modèle !
Consultez ces graphiques ci-dessous :
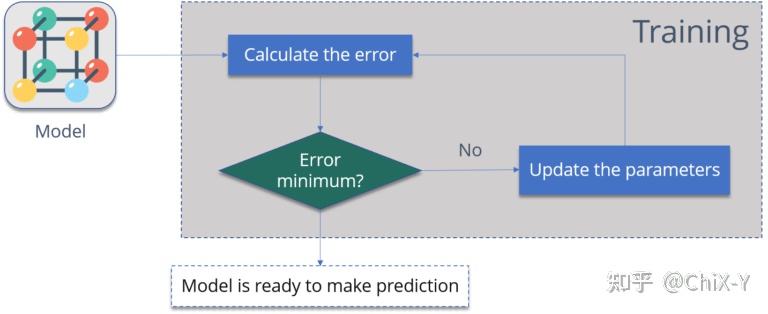
La figure ci-dessus résume les étapes de rétropropagation, qui sont :
1. Erreur de calcul – la différence entre la sortie du modèle et la sortie réelle.
2. Minimiser l'erreur – vérifie que l'erreur est minimisée.
3. Mettre à jour les paramètres (poids du modèle).
Ensuite, calculez à nouveau l'erreur jusqu'à ce que l'erreur soit réduite au minimum.
Lorsque l'erreur de modèle devient minime, c'est que le modèle est prêt !
Je suis à peu près sûr, maintenant que vous savez pourquoi nous avons besoin de la rétropropagation, ou pourquoi et quel est l'intérêt de former un modèle, voyons ce qu'est vraiment la rétropropagation.
Qu'est-ce que la rétropropagation ?
L'algorithme de rétropropagation utilise une technique appelée règle incrémentielle ou descente de gradient pour trouver le minimum de la fonction d'erreur dans l'espace des poids, puis considère les poids qui minimisent la fonction d'erreur comme la solution finale au problème d'apprentissage automatique.
Par exemple:
Supposons que vous ayez maintenant un ensemble de données avec des étiquettes :

Ensuite, votre modèle actuel, si la valeur de poids est 3, la sortie est la suivante :

La valeur d'erreur entre la sortie réelle et la sortie idéale peut être calculée :
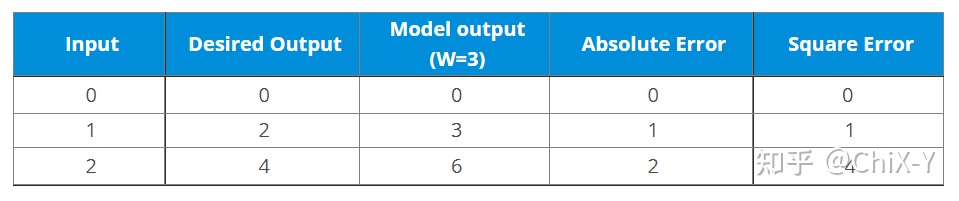
Et si vous changez W en 4 ?

On peut voir que si nous augmentons W, l'erreur augmentera également, donc il n'y a pas de sens positif pour nous d'augmenter W, alors que se passe-t-il si nous diminuons W ?

Maintenant, voici ce que nous avons fait :
1. Nous initialisons d'abord une valeur aléatoire à "W", puis nous propageons vers l'avant.
2. Ensuite, nous avons remarqué quelques erreurs. Pour réduire cette erreur, nous rétropropagions et augmentons la valeur de "W".
3. Après cela, nous avons également remarqué que l'erreur augmentait. Nous savons que nous ne pouvons pas augmenter la valeur "W". Donc, nous rétropropagions à nouveau, en réduisant la valeur "W", et cette fois l'erreur diminue.
Par conséquent, nous essayons d'obtenir les valeurs des poids telles que l'erreur soit minimisée. Fondamentalement, nous devons déterminer si nous devons augmenter ou diminuer la valeur du poids. Une fois que nous savons cela, nous continuons à mettre à jour les valeurs de poids dans cette direction jusqu'à ce que l'erreur devienne minimale. Il se peut que si les poids sont mis à jour davantage, l'erreur augmentera. À ce stade, nous devons nous arrêter, ce qui est notre valeur de poids finale.
Jetez un oeil à l'image ci-dessous:

Ce que nous devons atteindre, c'est le "Global Loss Minimum", qui est l'algorithme de rétropropagation. Examinons les principes mathématiques qui le sous-tendent.
Comment fonctionne l'algorithme de rétropropagation ?
Jetez un œil au réseau de neurones ci-dessous :

Le réseau de neurones ci-dessus contient les points suivants :
Deux unités d'entrée, deux unités cachées, deux unités de sortie et deux unités de polarisation.
Voici les étapes impliquées dans la rétropropagation :
Étape 1 : Propagation vers l'avant.
Étape 2 : Rétropropagation.
Étape 3 : Rassemblez toutes les valeurs et calculez les valeurs de poids mises à jour.
Étape 1 propagation vers l'avant
Commençons d'abord la passe avant :

Nous répétons ce processus avec les neurones de la couche de sortie, en utilisant la sortie des neurones de la couche cachée comme entrée.

Examinons maintenant le cas d'erreur :

Étape 2 Rétropropagation
Maintenant, nous allons rétropropager. De cette manière, nous essaierons de réduire l'erreur en faisant varier les valeurs de poids et de biais.
En considérant W5, nous allons calculer le taux de variation de la variation d'erreur de poids W5.

Puisque nous effectuons une rétropropagation, la première chose que nous devons faire est de calculer le taux de variation (dérivée partielle) de l'erreur totale Etotal pour out o1 et out o2, comme suit :

Maintenant, nous allons propager plus en arrière et calculer le taux de variation de la sortie out o1 (ou out o2) pour net o1 (ou net o2) :
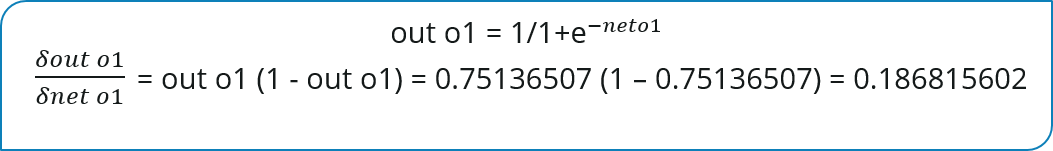
De la même manière, calculez le taux de variation de net o1 pour W5 :

Étape 3 Calculez la nouvelle valeur de poids
Maintenant, mettons toutes les valeurs ensemble :
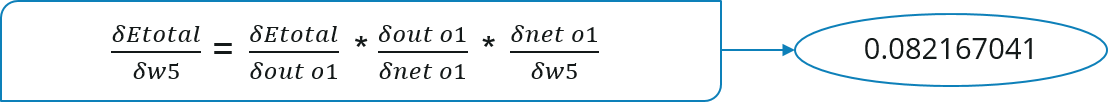
Mettons maintenant à jour W5 avec la formule de calcul dans l'algorithme de descente de gradient que nous avons appris auparavant :

De même, nous pouvons utiliser exactement la même méthode pour mettre à jour d'autres valeurs de poids. Après cela, nous transmettrons à nouveau et calculerons la sortie, puis calculerons l'erreur. Si l'erreur atteint le minimum, nous nous arrêtons, sinon nous continuons à rétropropager pour mettre à jour les poids.
Enfin, écrivez un pseudocode pour décrire plus clairement l'algorithme de rétropropagation :
initialize network weights (often small random values)
do
forEach training example named ex
prediction = neural-net-output(network, ex) // forward pass
actual = teacher-output(ex)
compute error (prediction - actual) at the output units
compute {displaystyle Delta w_{h}} for all weights from hidden layer to output layer // backward pass
compute {displaystyle Delta w_{i}} for all weights from input layer to hidden layer // backward pass continued
update network weights // input layer not modified by error estimate
until all examples classified correctly or another stopping criterion satisfied
return the network