Cliquez sur la carte ci-dessous pour suivre le compte officiel " CVer "
Marchandises sèches lourdes AI/CV, livrées dans un premier temps
Cliquez pour entrer —> [Video Understanding and Transformer] Groupe d'échange
Auteur : Sakura.D | Réimpression autorisée (Source : Zhihu) Éditeur : CVer
https://zhuanlan.zhihu.com/p/584669411
TL; DR
UniFormerV2 : Apprentissage spatio-temporel en armant Image ViTs avec Video UniFormer
Code (opensource):
https://github.com/OpenGVLab/UniFormerV2
Lien de téléchargement papier : https://arxiv.org/abs/2211.09552
Présentez brièvement notre travail récemment publié UniFormerV2. La méthode est inspirée par UniFormer et un module de modélisation de synchronisation général et efficace est conçu, qui peut être inséré de manière transparente dans diverses images de pré-formation open source ViT, ce qui améliore considérablement la capacité du modèle à traiter la synchronisation. informations. . Afin d'améliorer encore les performances sur les benchmarks traditionnels, nous nettoyons les données de K400/K600/K700 pour obtenir un ensemble de données K710 plus rationalisé (vidéo de formation de 0,66 Mo). L'entraînement sur cet ensemble de données peut améliorer les performances de plus de 1 %. Sur la base de l'encodeur visuel fourni par CLIP, notre UniFormerV2 a finalement obtenu des résultats SOTA dans 8 benchmarks grand public, y compris des ensembles de données liés à la scène (K400/K600/K700 à court terme et Moments in Time, et ActivityNet et HACS à long terme), et le temps ensembles de données liés à la série (Something-SomethingV1&V2). Avec un seul modèle (354 millions de paramètres), nous avons finalement atteint une précision de 90,0 % pour la première fois sur le K400.

Le code, le modèle et les configurations de formation correspondantes ont été open source, ce qui devrait être la meilleure performance sur ces 8 benchmarks populaires parmi les modèles open source actuels. Les amis sont invités à l'essayer, si cela est utile, vous pouvez commander une étoile avec vous ~
Motivation

Lorsque nous travaillions sur UniFormer [1] l'année dernière , nous avions souvent l'impression que le cycle d'expérimentation était trop long. Étant donné qu'UniFormer est un tout nouveau cadre, chaque fois que nous ajustons la structure, nous devons d'abord passer par une série de pré-formation d'image ImageNet, puis étendre le modèle et effectuer un réglage secondaire sur des ensembles de données vidéo tels que Kinetics. Selon le retour des résultats, la structure est améliorée.
Une méthode de formation plus concise consiste à pré-former directement sur des données vidéo (telles que SlowFast [2] et MViT [3] ), mais cette méthode ne convient qu'aux grandes institutions de recherche telles que Google/Meta, et à pré-former directement sur données vidéo, mais le coût de la formation est également plus élevé.
Bien que cela puisse concevoir plus soigneusement un cadre efficace et convivial pour les tâches vidéo, le même FLOP est en effet bien supérieur à certains travaux basés sur ViT dans la même période (tels que TimeSformer [4], ViViT [5] et Mformer [ 6 ] ) , mais la deuxième formation Le coût élevé nous limite également à explorer des modèles à plus grande échelle. Notre plus grand modèle à l'époque était UniFormer-B (paramètres 50M), introduisait 32 images et devait utiliser 32 V100 pour s'entraîner sur Kinetics pendant environ 2 semaines. Existe-t-il donc une meilleure solution de conception structurelle et de formation, qui peut garantir que les performances du modèle sont suffisamment bonnes et peut réduire les coûts de formation, de sorte que la puissance de calcul générale du laboratoire puisse également effectuer l'exploration des images vidéo en 2022 ?
Rappelant 2019-2021, alors que ViT n'avait pas encore été proposé, la communauté académique a conçu une série de modèles vidéo légers basés sur ResNet, tels que TSM [7] et STM [8] . Ces méthodes conçoivent des modules de temporisation plug-and-play, et une série de vérifications suffisantes sont effectuées sur ResNet50 et ResNet101. En raison de la petite taille du réseau ResNet, ces méthodes n'ont pas été en mesure d'améliorer considérablement les performances de l'ensemble de données vidéo. À l'heure actuelle, la meilleure méthode sur la série Kinetics reste le grand modèle CSN [9] et Meta pre -formé avec un grand jeu de données. SlowFast etc.
En 2021, la montée en puissance de ViT a également provoqué l'émergence de travaux tels que TimeSformer et ViViT.Ces travaux ont encore élargi l'attention temporelle réelle, ont pleinement utilisé le ViT pré-formé ImageNet-21K open source, et une fois actualisé la limite de performance de la série Cinétique. Cependant, les frais généraux du mécanisme d'attention ne sont toujours pas abordables pour les laboratoires généraux.À l'heure actuelle, la quantité de calcul du modèle a été mesurée en TFLOP. Et sur la base de la méthode de pré-formation d'image ViT, il est difficile d'améliorer vraiment la capacité de modélisation temporelle, et l'effet est médiocre sur des ensembles de données liés au temps forts tels que Something-Something (encore pire que le modèle léger basé sur ResNet ). Cela nous a également incités à explorer les caractéristiques de la convolution et de l'attention, et à concevoir un cadre vidéo efficace UniFormer.
Lorsque vient le temps de 2022, davantage de modèles ViT pré-entraînés sont open source, tels que Deit III supervisé [10] , CLIP [11] et DINO [12] pour l'apprentissage contrastif , et MAE [13] et BeiT pour l'apprentissage par masque [ 14] , et l'échelle augmente également de jour en jour. Nous pouvons tirer pleinement parti de ces grands modèles d'image open source pré-formés, concevoir des modules de modélisation de synchronisation légers et migrer vers des tâches vidéo avec un faible coût de formation !
UniFormerV2 a également été produit sous cette idée.Nous avons suivi l'idée de conception structurelle dans UniFormerV1 et conçu un module d'apprentissage spatio-temporel local et global efficace, qui peut être inséré de manière transparente dans l'image pré-formée forte ViT pour obtenir une construction vidéo puissante. Nous avons mené des expériences d'adaptation sur une série de pré-formations et de modèles à différentes échelles, et pouvons atteindre des performances exceptionnelles sur des ensembles de données populaires. Comme le montre le coin inférieur droit de la figure ci-dessus, notre modèle a obtenu le meilleur compromis entre précision et calcul sur le K400, et a atteint pour la première fois une précision de 90,0 % dans le top 1.
Méthode
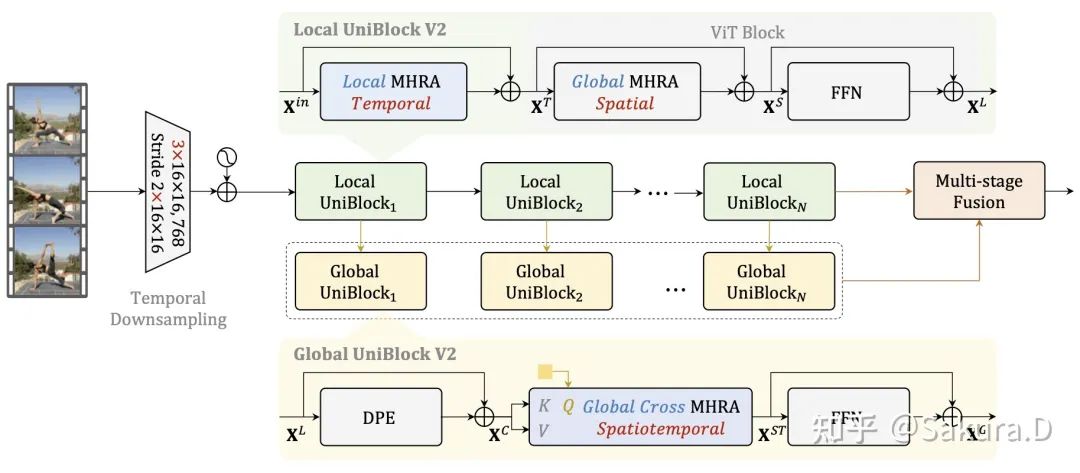
cadre général
Le cadre général du modèle est illustré dans la figure ci-dessus, qui comprend principalement quatre améliorations principales, et l'expérience d'ablation sera également présentée en détail plus tard :
Sous-échantillonnage temporel : Effectuez un sous-échantillonnage temporel au niveau de la couche d'intégration de patch. Cette opération étend l'intégration de patch à la convolution 3D et suréchantillonne dans l'ordre temporel. Sous le principe de la même quantité de calcul, il peut entrer deux fois le nombre d'images déguisées, ce qui peut améliore considérablement la précision du modèle Capacité de discrimination pour un comportement fortement dépendant du temps.
UniBlock local : sur le principe de conserver la modélisation globale de l'espace de ViT d'origine, nous introduisons en outre la modélisation du temps local. Ce module suit la conception du module local UniFormer, mais la convolution en profondeur ne fonctionne que dans la dimension temporelle. Améliorez la capacité de modélisation temporelle du réseau squelette sous la prémisse d'une petite quantité de calcul.
UniBlock global : pour les tâches vidéo, il est particulièrement important d'apprendre les dépendances à long terme pour les jetons spatio-temporels globaux. Afin de compresser le calcul des modules globaux, nous introduisons l'attention croisée, utilisons un seul jeton apprenable comme requête et produisons des jetons de différentes couches comme clés et valeurs, conception. Et nous introduisons le DPE dans UniFormer pour améliorer les informations de localisation spatio-temporelle du jeton. De cette façon, chaque module global comprime les informations spatio-temporelles de la couche correspondante en un seul jeton informatif.
Fusion en plusieurs étapes : afin de fusionner des jetons informatifs de différentes couches pour obtenir des représentations plus complexes, nous avons exploré plusieurs méthodes de fusion, notamment en série, parallèle et hiérarchique, et avons finalement adopté la conception en série la plus simple. Autrement dit, le jeton informatif de la couche précédente sera utilisé comme jeton de requête de la couche suivante et intègre de manière itérative plusieurs couches d'informations. Enfin, ces représentations spatio-temporelles issues de la fusion multicouche sont pondérées et fusionnées avec les représentations d'entrée du réseau squelette pour obtenir des représentations discriminantes qui sont finalement envoyées à la couche de classification.
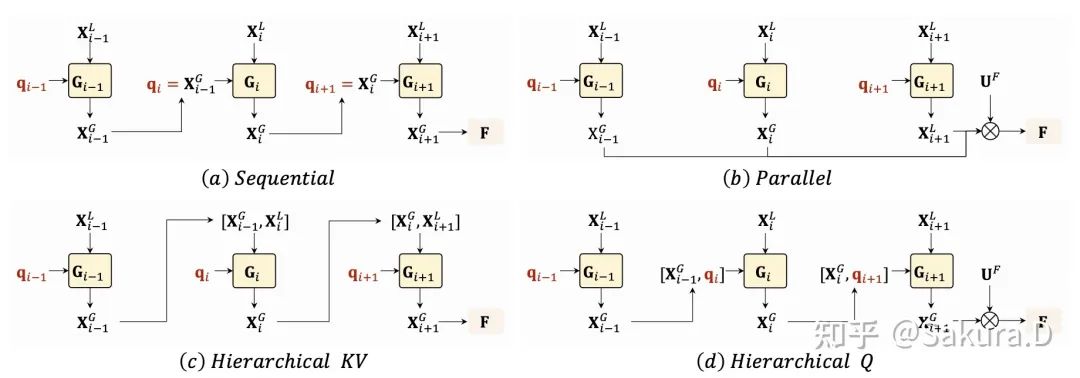
Détails d'implémentation
Pour la structure, après des expériences d'ablation nous avons trouvé que :
Pour les vidéos liées à la scène telles que la série Kinetics, c'est-à-dire en partant du principe qu'une seule image peut mieux juger du comportement, le modèle n'a qu'à insérer Global UniBlock dans la couche profonde pour répondre aux besoins de ce grand type de données.
Pour les vidéos liées à quelque chose avec une synchronisation forte, la capacité de modélisation temporelle du modèle est extrêmement élevée. En plus d'introduire un sous-échantillonnage temporel dans Patch Embedding, nous insérons également Local UniBlock dans chaque couche et insérons Global UniBlock au milieu et en profondeur. couches du réseau. , afin d'obtenir une forte discrimination temporelle.
Mais avec une structure aussi simple, une conception d'hyperparamètres est nécessaire pour assurer la convergence normale du modèle pendant l'entraînement. Nous avons expliqué dans les détails d'implémentation du texte principal de l'article et de l'annexe :
Initialisation du modèle : afin de garantir que la formation initiale du modèle est cohérente avec la sortie du modèle d'image d'origine, nous avons initialisé à zéro certains modules insérés, y compris la sortie de la couche linéaire par Local UniBlock, la requête apprenable, la sortie de la couche linéaire par FFN dans Global UniBlock, et attention pondérée Un poids apprenable pour la force.
Hyperparamètres de formation : pour un modèle pré-formé solide, un taux d'apprentissage plus faible doit être utilisé pour la migration complète des tâches vidéo, et lorsque la taille des données est petite, une régularisation supplémentaire telle que droppath doit être introduite. Les hyperparamètres spécifiques peuvent se trouvent dans Voir le tableau 11 en annexe du texte original.
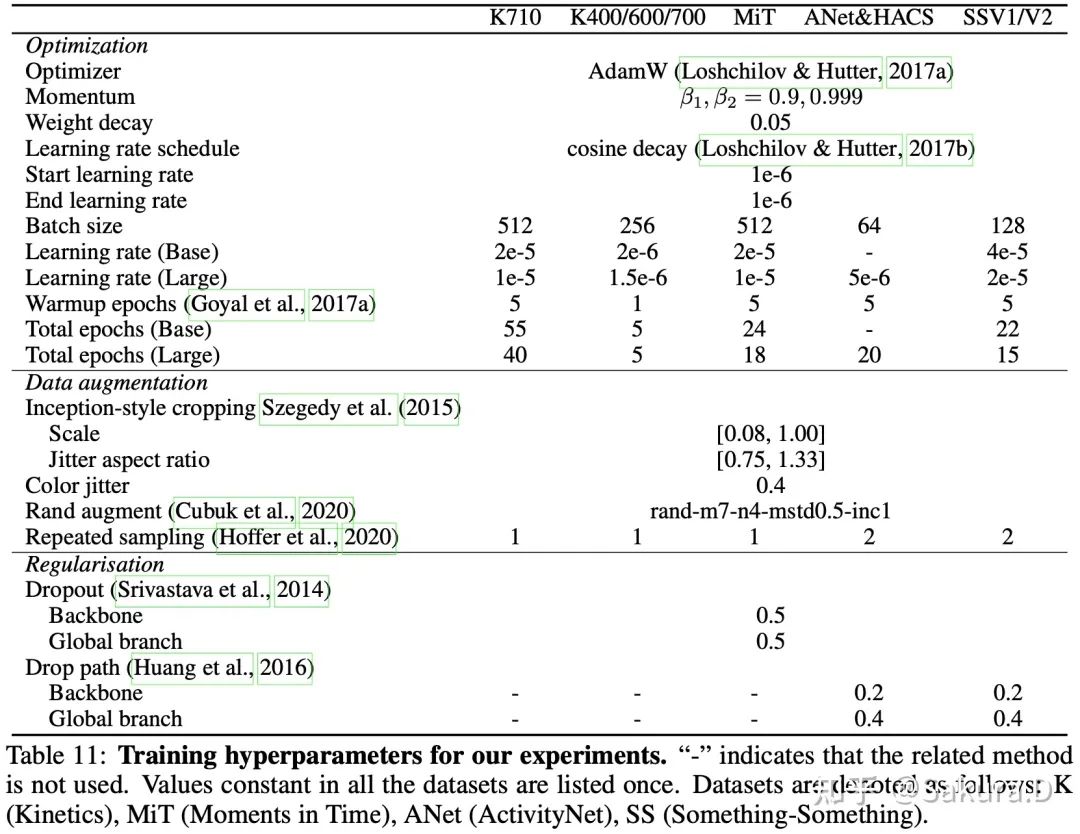
Cinétique-710
Afin d'améliorer encore les performances de transfert du modèle de pré-formation d'image, le travail SOTA actuel MTV [15] introduit des données de texte vidéo à grande échelle WTS-60M pour la pré-formation multimodale secondaire. Compte tenu du coût de formation de cette méthode (et la collecte de données est trop coûteuse), nous n'utilisons que des données open source pour la pré-formation supervisée. Nous avons essayé une variété de méthodes de formation conjointes d'ensembles de données, telles que la formation conjointe d'ensembles de données multi-sources dans COVER [16] , mais le réglage de K400 + SSV2 + MiT était difficile à travailler dans nos expériences. Nous avons donc simplement combiné des données homologues, c'est-à-dire K400, K600 et K700, ce qui impliquait principalement deux étapes importantes :
Nettoyage des données : en raison du chevauchement entre différents ensembles de données, ensemble d'entraînement et ensemble d'entraînement, ensemble d'entraînement et ensemble de test, et ensemble de test et ensemble de test, y compris la fuite d'informations, nous supprimons d'abord les vidéos qui se chevauchent en fonction de l'ID YouTube et obtenons 0,66 M vidéo.
Nettoyage des étiquettes : nous avons effectué un nettoyage des étiquettes en fonction de l'ID YouTube et des noms de catégorie des trois ensembles de données, et avons finalement retenu les catégories d'étiquettes 710. Le tableau 20 en annexe de l'article fournit la carte des étiquettes.
Nous appelons cet ensemble de données réduit Kinetics-710 (K710).Pour la pré-formation supervisée secondaire, nous utilisons directement un seul ensemble de données pour former les hyperparamètres, et le modèle n'entre que 8 images. Une fois la pré-formation terminée, quel que soit le nombre de trames (8/16/32/64) entrées, le modèle n'a besoin de former que 5 époques sur un seul ensemble de données K400/K600/K700 pour obtenir une amélioration des performances de plus supérieur à 1 %. Réduit considérablement les frais généraux d'entraînement. Il convient de noter que lors du réglage fin du modèle de pré-formation K710, nous cartographierons les poids de la couche de classification, c'est-à-dire que nous conserverons les poids correspondants des classes 400/600/700 selon la carte des étiquettes.
expérience
Cinétique
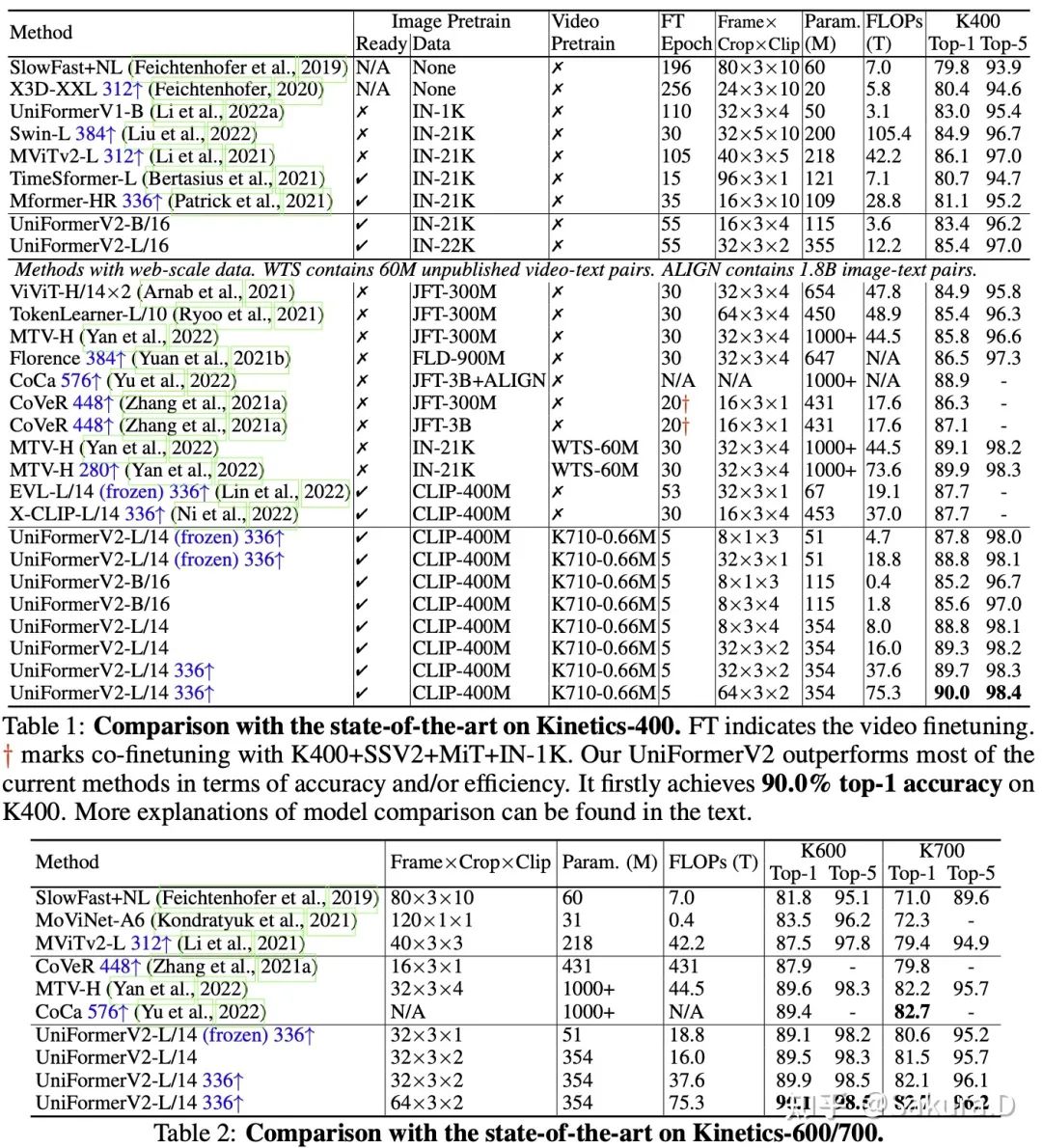
En plus de la quantité de calcul et de précision, nous fournissons plusieurs indicateurs supplémentaires, notamment si le modèle de pré-formation d'image est prêt (c'est-à-dire qu'aucune pré-formation supplémentaire n'est requise), s'il comprend une pré-formation secondaire et combien les époques doivent être formées sur un seul ensemble de données. Sous examen approfondi, notre UniFormerV2 est non seulement efficace dans la formation, mais surpasse également le modèle SOTA précédent dans les performances de test.
Moments dans le temps
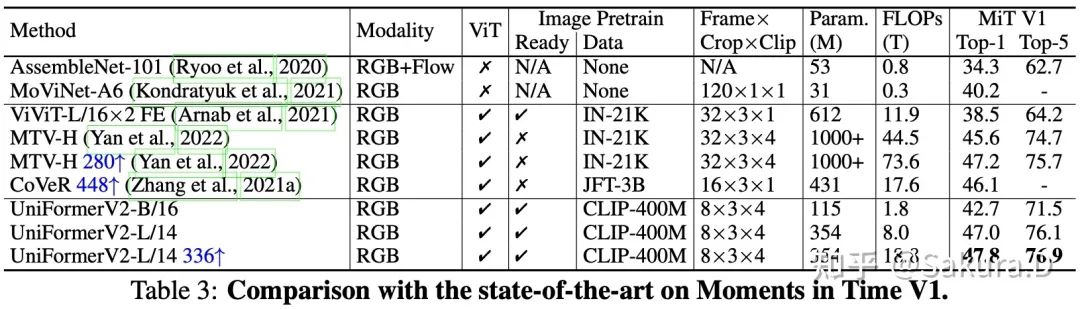
UniFormerV2 réalise également les meilleures performances pour le comportement de MiT, qui présente de plus grandes différences entre les classes au sein d'une classe, ce qui vérifie pleinement la robustesse de notre schéma.
Quelque chose quelque chose
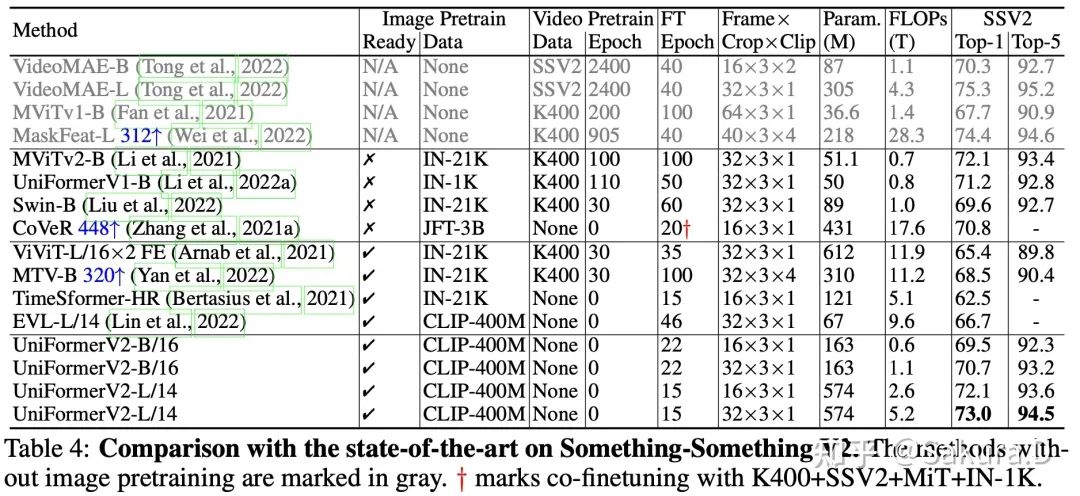
Sur quelque chose-quelquechoseV2, un ensemble de données liées au temps aussi solide, UniFormerV2 est bien meilleur qu'une série de méthodes conçues sur la base de ViT dans le passé. Il convient de noter que ces méthodes fonctionnent souvent bien sur Kinetics, ce qui montre également qu'elles ne le sont pas. vraiment réel par essence pour modéliser le temps. Par rapport aux méthodes SOTA précédentes, grâce aux avantages d'un puissant pré-entraînement d'image, UniFormerV2 n'a besoin de former qu'un petit nombre d'époques sur une seule donnée vidéo, tandis que les méthodes précédentes doivent souvent pré-entraîner sur le K400 en premier, ou effectuer des milliers d'époques Entraînement supervisé pour obtenir les meilleures performances.
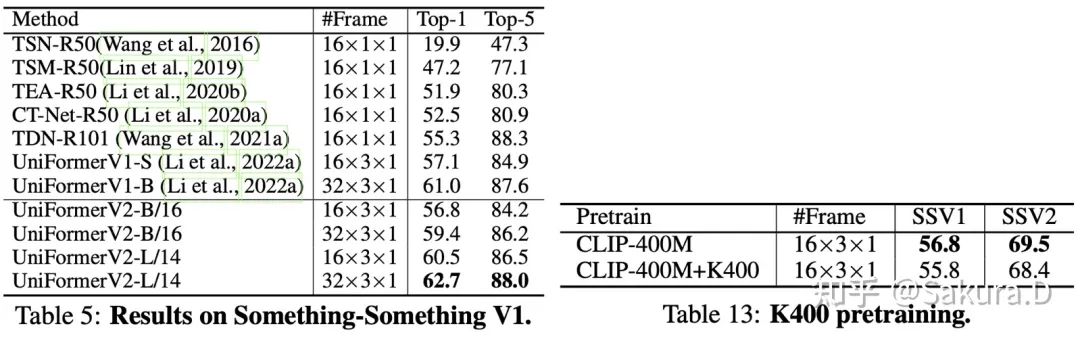
Sur le jeu de données Something-SomethingV1, UniFormerV2 actualise les performances de pointe. Comme le montre le tableau de droite, nous avons également essayé d'introduire une pré-formation K400 supplémentaire, mais l'effet de réglage fin est encore pire. La raison possible est que le modèle que nous utilisons a été pré-formé avec des données graphiques de 400 M, tandis que le K400 ne contient qu'une vidéo de formation de 0,24 M, et que la vidéo est liée à la scène (c'est-à-dire que l'effet est similaire à une seule image), et il y a un domaine entre K400 et la différence Sth-Sth, une formation K400 supplémentaire peut détruire la distribution des fonctionnalités de la pré-formation CLIP.
ActivityNet et HACS

Sur les ensembles de données comportementales à long terme ActivityNet et HACS, UniFormerV2 présente un avantage significatif par rapport aux méthodes SOTA précédentes.
Différents ViT préformés
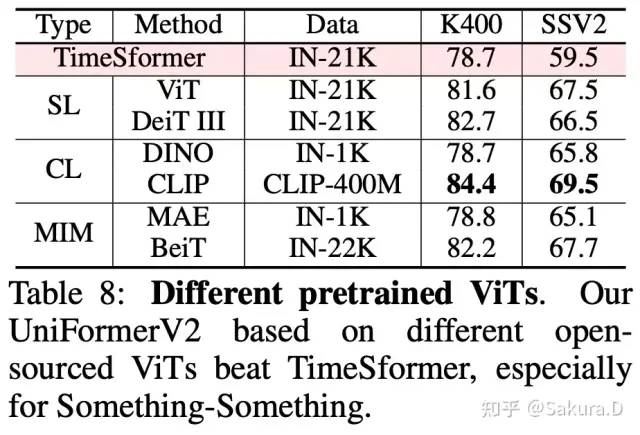
Nous avons effectué une vérification d'adaptation sur le ViT pré-formé avec une pré-formation supervisée, un apprentissage contrastif et un apprentissage par masque. On peut voir que même avec le ViT pré-formé sur ImageNet-1K, notre méthode peut surpasser TimeSformer, en particulier dans Sth -Sth sur de solides ensembles de données liées à des séries chronologiques. Une autre observation intéressante est que différentes méthodes de pré-formation ne peuvent pas faire une grande différence, mais plus la taille des données de pré-formation est grande, plus l'amélioration des tâches vidéo est évidente.
Expérience d'ablation
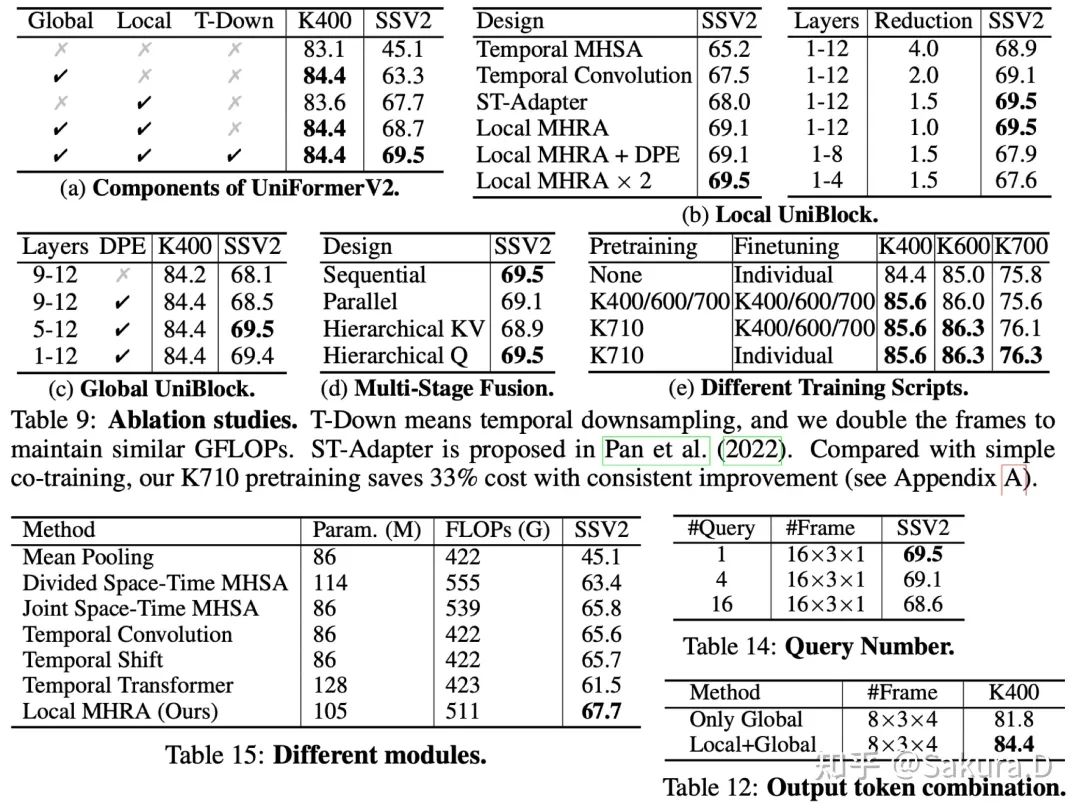
Nous avons mené des expériences d'ablation approfondies sur K400 et Sth-SthV2, en vérifiant pleinement l'efficacité de chaque module proposé dans notre méthode, ainsi que l'efficacité de la pré-formation secondaire de K710. Les partenaires intéressés peuvent consulter le texte pour voir une analyse plus approfondie.
visualisation
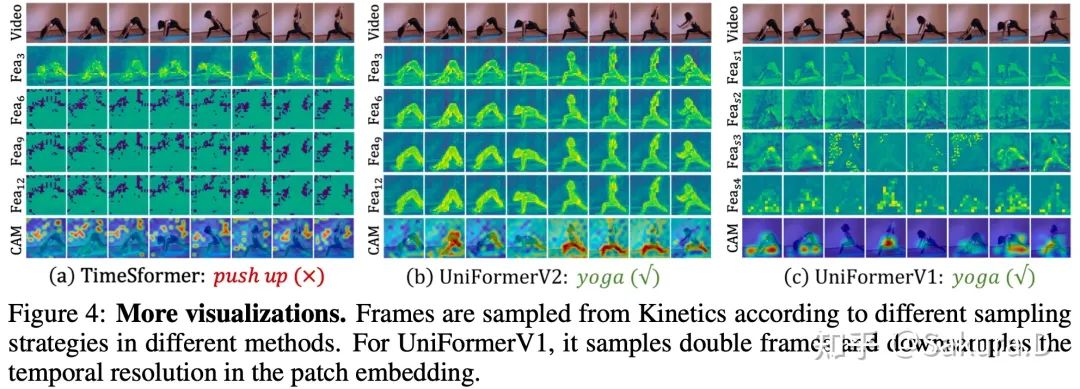
Les caractéristiques visuelles peuvent être trouvées qu'UniFormerV2 peut mieux conserver les détails des caractéristiques dans les couches peu profondes et profondes, et se concentrer sur la zone de premier plan.
conclusion
Dans UniFormerV2, nous avons exploré et conçu un module de modélisation spatio-temporelle plus efficace et polyvalent, qui peut s'adapter de manière transparente à l'image pré-formation ViT et améliorer considérablement l'effet de traitement des tâches vidéo. Le modèle open source et la bénédiction de K710 rendent la formation de l'ensemble du spectre de formation du modèle très efficace. En utilisant uniquement une pré-formation CLIP open source et des données supervisées open source, UniFormerV2 peut surpasser le précédent SOTA sur 8 benchmarks populaires.
À l'heure actuelle, les codes, modèles et configurations pertinents d'UniFormerV2 sont open source, et il s'agit également du modèle open source le plus puissant de ces huit ensembles de données. J'espère pouvoir apporter une petite contribution à la communauté. Bienvenue pour l'essayer et aider à trouver des bugs !
référence
^ Uniforme https://arxiv.org/abs/2201.04676
^ SlowFast https://arxiv.org/abs/1812.03982
^ MViT https://arxiv.org/abs/2104.11227
^ TimeSformer https://arxiv.org/abs/2102.05095
^ViViT https://arxiv.org/abs/2103.15691
^Mancien https://arxiv.org/abs/2106.05392
^TSM https://arxiv.org/abs/1811.08383
^ STM https://arxiv.org/abs/1908.02486
^ CSN https://arxiv.org/abs/1904.02811
^ Jour III https://arxiv.org/abs/2204.07118
^CLIP https://openai.com/blog/clip/
^DINO https://arxiv.org/abs/2104.14294
^MAE https://arxiv.org/abs/2111.06377
^Beit https://arxiv.org/abs/2106.08254
^ MTV https://arxiv.org/abs/2201.04288
^COUVERTURE https://arxiv.org/abs/2112.07175
Cliquez pour entrer —> [Video Understanding and Transformer] Groupe d'échange
Téléchargement du papier et du code ICCV/CVPR 2023
Réponse de fond : CVPR2023, vous pouvez télécharger la collection d'articles CVPR 2023 et coder des articles open source
后台回复:ICCV2023,即可下载ICCV 2023论文和代码开源的论文合集视频理解和Transformer交流群成立
扫描下方二维码,或者添加微信:CVer333,即可添加CVer小助手微信,便可申请加入CVer-视频理解或者Transformer 微信交流群。另外其他垂直方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch、TensorFlow和Transformer等。
一定要备注:研究方向+地点+学校/公司+昵称(如视频理解或者Transformer+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群
▲扫码或加微信号: CVer333,进交流群
CVer计算机视觉(知识星球)来了!想要了解最新最快最好的CV/DL/AI论文速递、优质实战项目、AI行业前沿、从入门到精通学习教程等资料,欢迎扫描下方二维码,加入CVer计算机视觉,已汇集数千人!
▲扫码进星球
▲点击上方卡片,关注CVer公众号Ce n'est pas facile à organiser, veuillez aimer et regarder![]()