Adresse papier
https://openreview.net/pdf?id=_VjQlMeSB_J
Résumé
Nous explorons comment la génération d'une chaîne de pensée - une série d'étapes de raisonnement intermédiaires - peut améliorer considérablement la capacité des grands modèles de langage à effectuer un raisonnement complexe. En particulier, nous montrons comment cette capacité de raisonnement émerge naturellement dans des modèles de langage suffisamment grands grâce à une méthode simple appelée incitation à la chaîne de pensée, où certaines démonstrations de la chaîne de pensée sont fournies à titre d'exemple dans les invites.
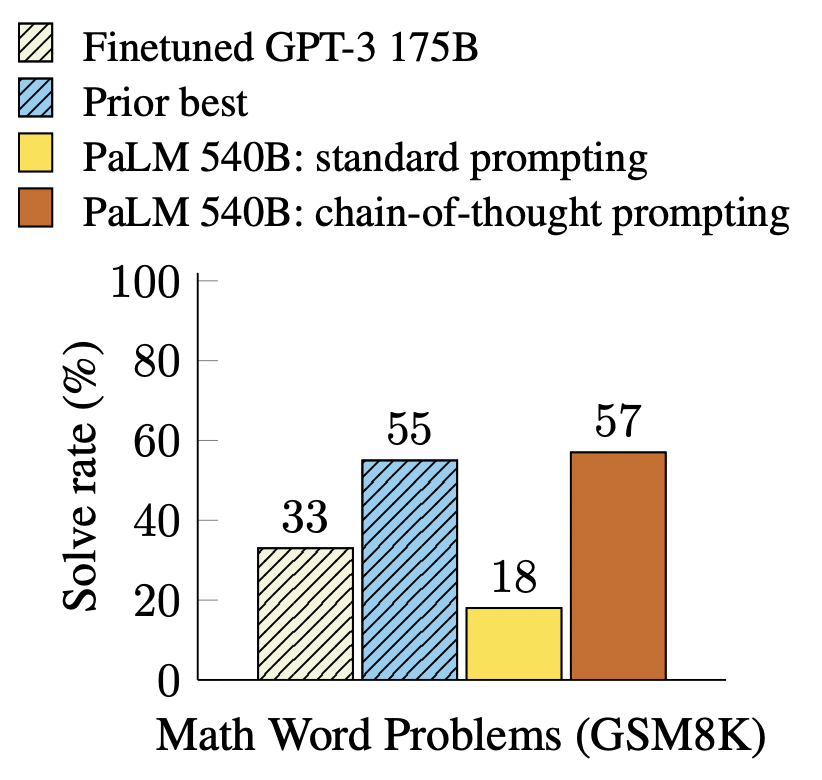
Des expériences sur trois modèles de langage à grande échelle montrent que les signaux de la chaîne de pensée améliorent les performances sur une gamme de tâches de raisonnement arithmétique, de bon sens et symbolique. Les gains empiriques peuvent être stupéfiants. Par exemple, l'utilisation de seulement huit paradigmes de chaîne de pensée incite le PaLM 540B à atteindre une précision de pointe sur la référence GSM8K pour les problèmes de mots mathématiques, dépassant même le GPT-3 affiné avec un validateur.
1. Introduction
Les modèles de langage ont récemment révolutionné le domaine de la PNL. Il a été démontré que la mise à l'échelle des modèles de langage apporte une gamme d'avantages, tels que l'amélioration des performances et l'efficacité des échantillons. Cependant, l'augmentation de la taille du modèle ne suffit pas à elle seule pour atteindre des performances élevées sur des tâches difficiles telles que l'arithmétique, le bon sens et le raisonnement symbolique.
Ce travail explore comment libérer le pouvoir de raisonnement des grands modèles de langage à travers une approche simple guidée par deux idées. Premièrement, les techniques de raisonnement arithmétique peuvent bénéficier de la génération d'un raisonnement en langage naturel qui mène à la réponse finale. En plus des approches neuronales-symboliques utilisant des langages formels, des travaux antérieurs ont permis aux modèles de générer des étapes intermédiaires en langage naturel au lieu du langage naturel en entraînant à partir de zéro ou en affinant des modèles pré-entraînés. Deuxièmement, les grands modèles de langage offrent la perspective passionnante d'un apprentissage en quelques prises de vue en contexte avec des indices. C'est-à-dire qu'au lieu d'affiner un point de contrôle de modèle de langage distinct pour chaque nouvelle tâche, on peut simplement "indiquer" le modèle avec des paradigmes d'entrée-sortie pour les tâches de démonstration. Notamment, cela réussit sur une gamme de tâches de réponse à des questions simples.
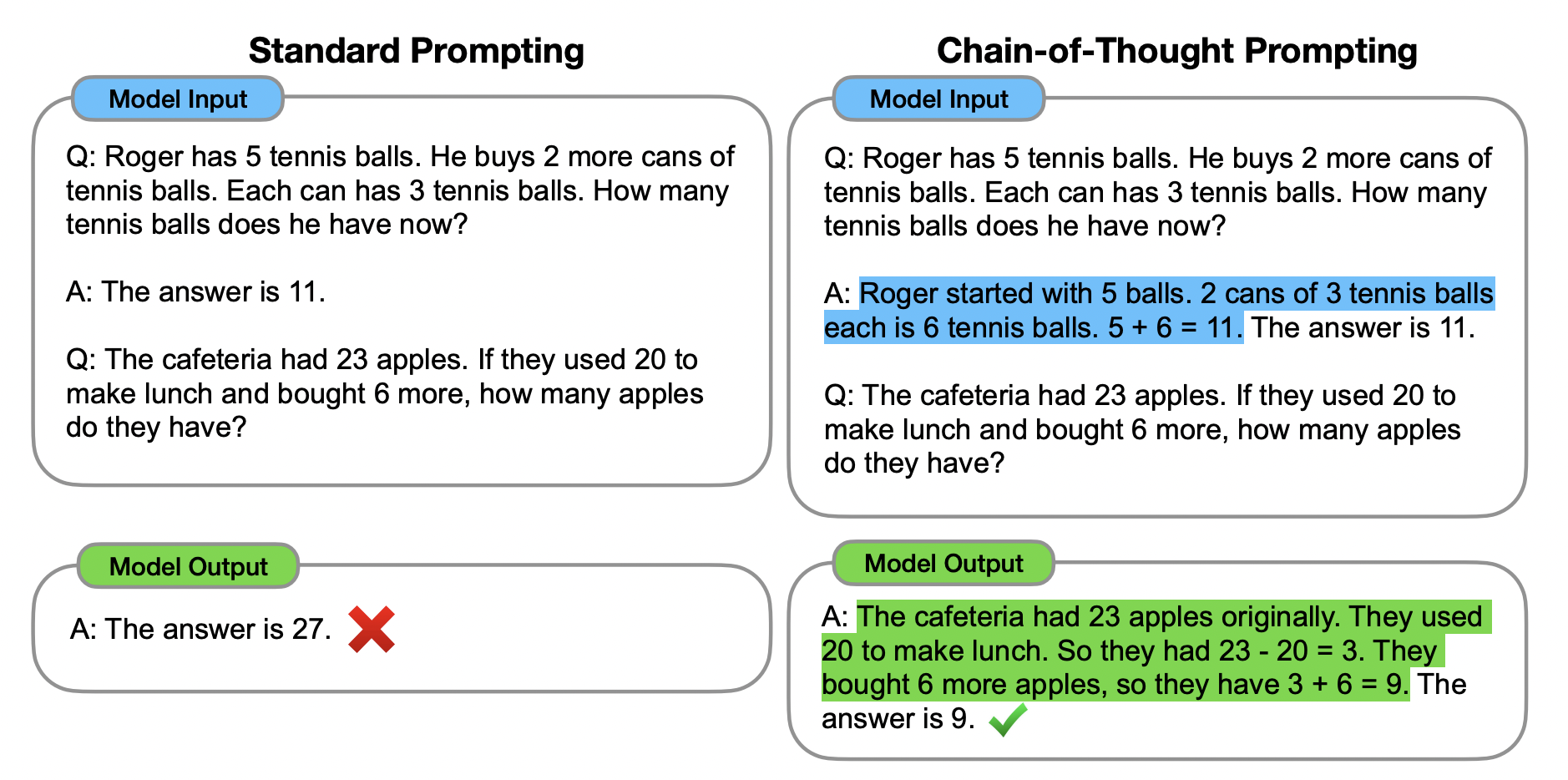
Cependant, les deux idées ci-dessus ont des limites importantes. Pour la formation à l'augmentation des principes de terrain et les méthodes de réglage fin, il est coûteux de créer un grand nombre de vérités de terrain de haute qualité, qui sont beaucoup plus complexes que les simples paires entrée-sortie utilisées dans l'apprentissage automatique général. Pour la méthode traditionnelle d'indication de petits échantillons utilisée par Brown et al. (2020), qui fonctionnent mal sur les tâches nécessitant des capacités de raisonnement et ne s'améliorent généralement pas de manière substantielle avec la taille du modèle de langage (Rae et al., 2021). Dans cet article, nous combinons les forces des deux idées d'une manière qui évite leurs limites. Plus précisément, nous explorons la capacité des modèles de langage à exécuter des signaux à quelques coups pour les tâches d'inférence, étant donné un signal composé de triplets : 〈entrée, chaîne de pensée, sortie〉. Une chaîne de pensée est une série d'étapes intermédiaires d'inférence en langage naturel menant à un résultat final, nous appelons cette approche un indice de chaîne de pensée. La figure 1 montre un exemple d'invite.
Nous évaluons empiriquement sur des repères d'arithmétique, de bon sens et de raisonnement symbolique, montrant que les indices de la chaîne de pensée surpassent les indices standard, parfois à un degré surprenant. La figure 2 illustre un tel résultat - sur le benchmark de problèmes de mots mathématiques GSM8K (Cobbe et al., 2021), les invites de chaîne de pensée utilisant le PaLM 540B surpassent considérablement les invites standard et atteignent de nouvelles performances de pointe. L'approche d'indication uniquement est importante car elle ne nécessite pas un grand ensemble de données d'apprentissage et un seul point de contrôle de modèle peut effectuer de nombreuses tâches sans perte de généralité. Ce travail met en évidence la façon dont de grands modèles de langage peuvent être appris à partir d'exemples de données en langage naturel sur quelques tâches (voir Apprentissage automatique des modèles d'entrée et de sortie à partir de grands ensembles de données d'apprentissage).
2 conseils pour penser en chaîne
Tenez compte de votre propre processus de pensée lorsque vous résolvez des tâches de raisonnement complexes telles que des problèmes de mots mathématiques à plusieurs étapes. Il est courant de décomposer le problème en étapes intermédiaires et de résoudre chaque étape avant de donner la réponse finale : "Après que Jane ait donné 2 fleurs à sa maman, elle en a 10... Puis après qu'elle en ait donné 3 à son papa, elle aura 7 . . . donc la réponse est 7." Le but de cet article est de donner aux modèles de langage la capacité de générer quelque chose comme une chaîne de pensée - une série cohérente d'étapes de raisonnement intermédiaires qui mènent à une réponse finale à une question. Si une démonstration du raisonnement en chaîne de pensée est fournie pour les petits indices du paradigme, nous démontrons que des modèles de langage suffisamment grands peuvent générer des chaînes de pensée.
La figure 1 montre un exemple de modèle qui génère une idée pour résoudre un problème de mots mathématiques qui serait autrement incorrect. Dans ce cas, une chaîne de pensée ressemble à une solution et peut être interprétée comme une solution, mais nous choisissons toujours de l'appeler une chaîne de pensée pour mieux saisir l'idée qu'elle imite un processus de pensée étape par étape pour arriver à une réponse ( et De plus, les solutions/explications suivent souvent la réponse finale (Narang et al., 2020 ; Wiegreffe et al., 2022 ; Lampinen et al., 2022, etc.).
ont plusieurs propriétés attrayantes.
- Premièrement, les chaînes de pensée permettent en principe au modèle de décomposer les problèmes à plusieurs étapes en étapes intermédiaires, ce qui signifie que des calculs supplémentaires peuvent être alloués à des problèmes nécessitant plus d'étapes d'inférence.
- Deuxièmement, la chaîne de pensée fournit une fenêtre interprétable sur le comportement du modèle, montrant comment il aurait pu arriver à une réponse particulière, et une opportunité de déboguer où le chemin de raisonnement s'est mal passé (malgré la caractérisation complète des calculs qui prennent en charge le modèle) . La réponse reste une question ouverte).
- Troisièmement, le raisonnement en chaîne peut être utilisé pour des tâches telles que les problèmes de mots mathématiques, le raisonnement de bon sens et la manipulation de symboles, et pourrait potentiellement (du moins en principe) être applicable à toute tâche que les humains peuvent résoudre par le langage.
- Enfin, l'inférence de la chaîne de pensée peut être facilement obtenue dans des modèles de langage standard suffisamment grands en incluant simplement des exemples de chaînes de séquence de pensée dans le paradigme des invites à quelques coups.
Dans des expériences empiriques, nous observerons l'utilité des indices de la chaîne de pensée dans le raisonnement arithmétique (Section 3), le raisonnement de bon sens (Section 4) et le raisonnement symbolique (Section 5).
3 Raisonnement arithmétique
Nous considérons d'abord les problèmes de mots mathématiques de la forme de la figure 1, qui mesurent la capacité de raisonnement arithmétique des modèles de langage. Bien que simple pour les humains, le raisonnement arithmétique est une tâche avec laquelle les modèles de langage ont souvent du mal (Hendrycks et al., 2021 ; Patel et al., 2021, etc.). De manière frappante, lorsqu'elles sont utilisées avec un modèle de langage paramétrique 540B, les indications de chaîne de pensée fonctionnent sur plusieurs tâches au même titre que les modèles affinés spécifiques à une tâche, atteignant même l'état de l'art au niveau de référence GSM8K difficile (Cobbe et al. , 2021).
3.1 Dispositif expérimental
Nous explorons les indices de la chaîne de pensée pour divers modèles de langage à travers plusieurs repères.
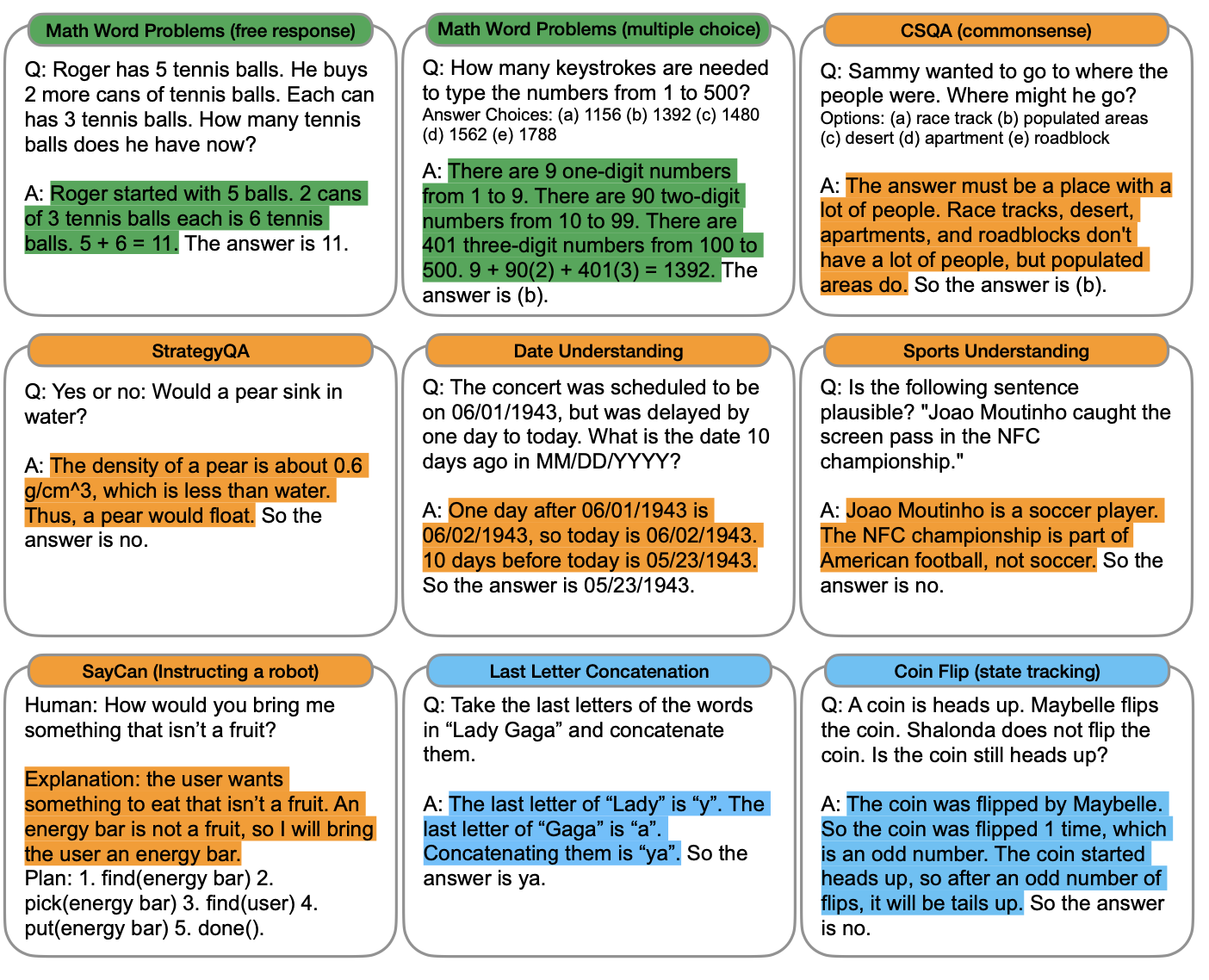
référence . Nous considérons les cinq critères de référence suivants pour les questions de mots mathématiques : (1) le repère de questions de mots mathématiques GSM8K (Cobbe et al., 2021), (2) l'ensemble de données SVAMP de questions de mots mathématiques avec différentes structures (Patel et al., 2021), (3) l'ensemble de données ASDiv de divers problèmes de mots mathématiques (Miao et al., 2020), (4) l'ensemble de données AQuA de problèmes de mots algébriques et (5) le benchmark MAWPS (Koncel-Kedziorski et al., 2016). Des exemples de questions sont donnés dans le tableau 12 en annexe.
Conseils standards . Pour la ligne de base, nous considérons les indices standard de quelques coups, popularisés par Brown et al. (2020), où les modèles de langage reçoivent des exemples contextuels de paires entrée-sortie avant de produire des prédictions pour des exemples de temps de test. Les exemples sont présentés sous forme de questions et de réponses. Le modèle donne directement la réponse, comme le montre la figure 1 (à gauche).
Incite à penser en chaîne . Notre méthode proposée augmente chaque exemplaire dans une invite de quelques coups avec une chaîne de pensée de réponses connexes, comme le montre la figure 1 (à droite). Étant donné que la plupart des ensembles de données n'ont qu'une seule division d'évaluation, nous avons composé manuellement un ensemble de huit petits exemples avec des chaînes de pensée pour l'incitation - La figure 1 (à droite) montre un exemple de chaînes de pensée, l'ensemble complet d'exemples se trouve dans le tableau 20 en annexe. (Ces paradigmes spécifiques n'ont pas été conçus par incitation ; la robustesse est étudiée dans la section 3.4 et l'annexe A.2.) huit paradigmes de chaîne de pensée sont utilisés par tous les benchmarks sauf AQuA, qui est à choix multiples plutôt qu'à réponse libre. Pour AQuA, nous avons utilisé les quatre échantillons et solutions de l'ensemble d'apprentissage, comme indiqué dans le tableau 21 en annexe.
modèle de langage. Nous évaluons cinq modèles de langage à grande échelle. Le premier est GPT-3 (Brown et al., 2020), pour lequel nous utilisons text-ada-001, text-babbage-001, text-curie-001 et text-davinci-002, qui correspondent à peu près au modèle InstructGPT Modèles paramétriques 350M, 1.3B, 6.7B, 175B (Ouyang et al., 2022). Vient ensuite le LaMDA (Thoppilan et al., 2022), qui a des modèles de paramètres 422M, 2B, 8B, 68B et 137B. Le troisième est PaLM, qui a des modèles de paramètres 8B, 62B et 540B. Le quatrième est UL2 20B (Tay et al., 2022) et le cinquième est Codex (Chen et al., 2021, code-davinci-002 dans OpenAI API). Nous échantillonnons à partir du modèle via un décodage gourmand (bien que des travaux de suivi aient montré que les indices de la chaîne de pensée peuvent être améliorés en prenant la réponse finale majoritaire sur de nombreuses générations d'échantillonnage (Wang et al., 2022a)). Pour LaMDA, nous rapportons les résultats moyens pour cinq graines aléatoires, chacune avec un échantillon différent mélangé au hasard. Étant donné que les expériences LaMDA n'ont pas montré de grandes différences entre les différentes graines, pour économiser le calcul, nous rapportons les résultats pour un seul exemple de commande pour tous les autres modèles.
3.2 Résultats
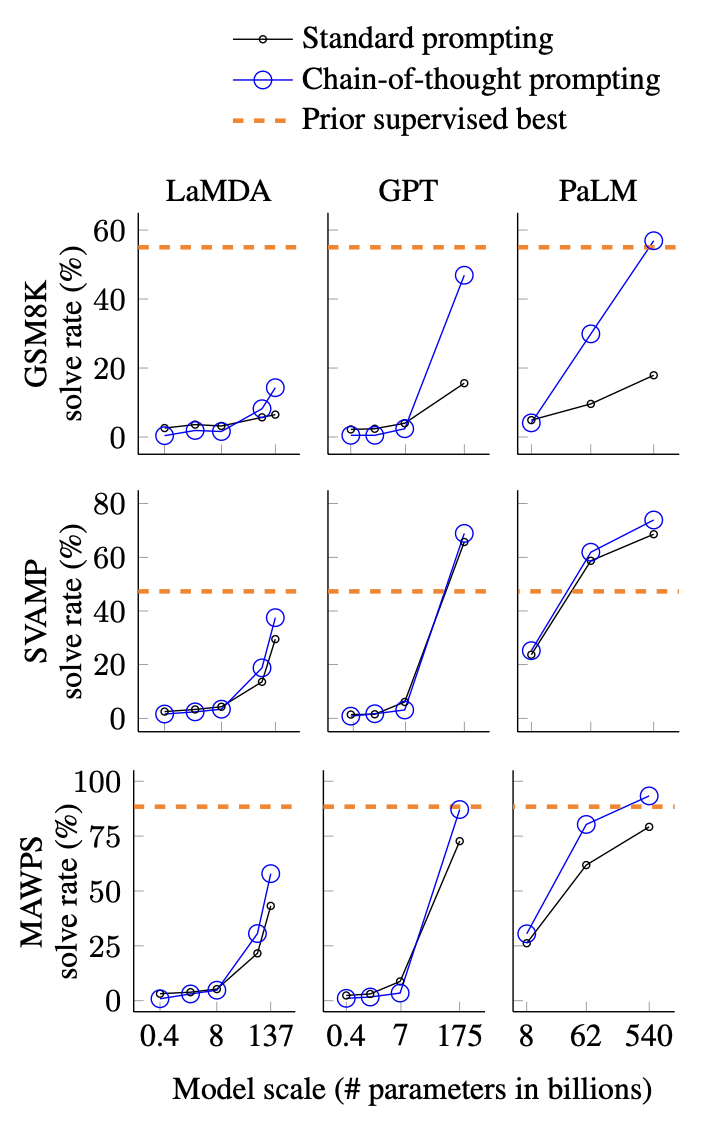
La figure 4 résume les résultats les plus solides suscités par la chaîne de pensée, et le tableau 2 en annexe montre toutes les sorties expérimentales pour chaque ensemble de modèles, taille de modèle et référence. Il y a trois plats à emporter.
Premièrement, la figure 4 montre que l'indication de la chaîne de pensée est une capacité émergente à l'échelle du modèle (Wei et al., 2022b). Autrement dit, les indices de chaîne de pensée n'affectent pas positivement les performances des petits modèles et ne génèrent des gains de performances que lorsqu'ils sont utilisés avec des modèles avec des paramètres d'environ 100 B. Sur le plan qualitatif, nous constatons que les modèles à plus petite échelle produisent des chaînes de pensée fluides mais illogiques, ce qui entraîne des performances inférieures à la normale pour les signaux.
Deuxièmement, les indices de chaîne de pensée ont des gains de performances plus importants pour des problèmes plus complexes. Par exemple, pour GSM8K (l'ensemble de données avec les performances de base les plus faibles), les performances des plus grands modèles GPT et PaLM font plus que doubler. D'autre part, pour SingleOp, le sous-ensemble le plus simple de MAWPS qui ne nécessite qu'une seule étape pour être résolu, les améliorations de performances sont soit négatives, soit très faibles (voir le tableau 3 en annexe).
Troisièmement, l'incitation à la chaîne de pensée via GPT-3 175B et PaLM 540B surpasse l'état de l'art, qui affine généralement les modèles spécifiques aux tâches sur des ensembles de données d'apprentissage étiquetés. La figure 4 montre comment le PaLM 540B atteint l'état de l'art sur GSM8K, SVAMP et MAWPS en utilisant des conseils de chaîne de pensée (mais notez que les conseils standard dépassent déjà le meilleur état de l'art précédent pour SVAMP). Sur deux autres ensembles de données, AQuA et ASDiv, PaLM avec des invites de chaîne de pensée atteint moins de 2 % de l'état de l'art (tableau 2 en annexe).
Pour mieux comprendre pourquoi les chaînes de pensée sont utilisées pour faciliter le travail, nous avons examiné manuellement les chaînes de pensée générées par LaMDA 137B pour les modèles générés par GSM8K. Sur les 50 exemples aléatoires pour lesquels le modèle a renvoyé la réponse finale correcte, toutes les chaînes de pensée générées étaient également logiquement et mathématiquement correctes, à l'exception de deux qui ont abouti à la réponse correcte par coïncidence (voir l'annexe D.1 et le tableau 8 pour l'exemple de chaîne de pensée pour la génération correcte du modèle). Nous avons également vérifié au hasard 50 échantillons aléatoires où le modèle a donné la mauvaise réponse. La conclusion de cette analyse était que 46 % des chaînes de pensée étaient presque correctes à l'exception d'erreurs mineures (erreur de calculatrice, mauvais mappage de symboles ou manque d'une étape de raisonnement), et 54 % supplémentaires présentaient des erreurs majeures de compréhension sémantique ou des erreurs de cohérence (voir Annexe D.2). Pour mieux comprendre pourquoi la mise à l'échelle améliore le raisonnement de la chaîne de pensée, nous avons effectué une analyse similaire des erreurs produites par le PaLM 62B et si ces erreurs ont été corrigées par la mise à l'échelle du PaLM 540B. En résumé, l'extension de PaLM à 540B corrige la plupart des étapes manquantes et des erreurs de compréhension sémantique dans le modèle 62B (voir l'annexe A.1).
3.3 Etude d'ablation
. . à suivre