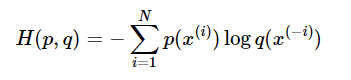Répertoire de colonnes : pytorch (segmentation d'image UNet) introduction rapide et combat réel - zéro, préface
introduction rapide de pytorch et combat réel - 1, préparation des connaissances (introduction aux éléments)
introduction rapide de pytorch et combat réel - 2, apprentissage en profondeur développement de réseau classique
pytorch rapide introduction Et combat réel - trois, Unet réalise
une introduction rapide de pytorch et un combat réel - quatre, formation et test du réseau
Apprentissage en profondeur de certains concepts
Entropie croisée, régularisation, cartographie d'identité et dégradation. Je suis aussi fan, n'ayez pas peur, c'est bien si ça marche quand même.
Qu'est-ce que la descente de gradient, qu'est-ce que l'algorithme BP, qu'est-ce que le graphe de calcul, qu'est-ce que le réseau continu complet, le réseau convolutif ... emmm d'accord, je comprends toujours le réseau convolutif, donc je vais pour l'apprentissage en profondeur.
Si vous ne comprenez pas la convolution, regardez ceci : La route vers l'apprentissage automatique 3 : Réseau de neurones convolutifs
Efforcez-vous d'obtenir la vitesse la plus rapide pour commencer à travailler sur le code, donc, les concepts suivants que je serai très à l'aise après avoir compris, un pendant environ cinq minutes, pour comprendre : Faites
référence à une certaine station @莫追python et 某达@晓强DL et ce site Attendez le patron,
si vous aimez les plus détaillés, vous pouvez trouver @刘二大人 sur une certaine station
0 Apprentissage automatique et apprentissage en profondeur
Développement de l'apprentissage automatique : classification linéaire -> perceptron -> descente de gradient -> réseau de neurones -> algorithme BP -> réseau entièrement connecté à trois couches -> CNN comme SVM prend en charge le perceptron vectoriel, arbre de décision, algorithme EM, carte de probabilité, baie
naïve sont tous des apprentissages automatiques spéciaux.
Bien sûr, le deep learning appartient aussi au machine learning. Où est la différence ?
Réseaux de neurones convolutifs !
En 2012, AlexNet a intégré l'ingénierie et la classification des fonctionnalités, et a utilisé des réseaux de neurones convolutifs pour écraser les méthodes traditionnelles d'apprentissage automatique dans le domaine du CV. En tant que jalon, il a ouvert le prélude à la domination de la vision par ordinateur par les réseaux de neurones convolutifs et accéléré l'application de l'informatique. vision.
1 Concepts de prétraitement des données
1.1 Caractéristiques des données
L'exemple classique du livre de pastèque, la pastèque a diverses caractéristiques qui peuvent être entrées dans le réseau (ou le cerveau humain) pour le jugement.
Je ne connais pas grand-chose à la pastèque, alors je l'ai changé.
Si un groupe de chiens et un groupe de chats sont des chiens jaunes et des chats blancs, la sélection de la fonction de couleur peut très bien résoudre cette tâche de classification, mais il est difficile de résoudre ce problème si vous choisissez le nombre d'yeux et le nombre de queues.
Par conséquent, de bonnes fonctionnalités peuvent bien expliquer le problème.
Nous devons sélectionner les bonnes fonctionnalités et filtrer les mauvaises.
L'exemple concret est beaucoup plus complexe.
Référence : Comment distinguer les fonctionnalités utiles
1.2 Standardisation des fonctionnalités
Il existe un certain nombre de fonctionnalités qui ne sont pas standard dans les instances concrètes :
Les prix des maisons varient selon de nombreux paramètres (par exemple au centre-ville, étage, quartier, ville, etc.).
Prenons deux paramètres comme exemple, la distance en km et la surface en m2
sont d'environ 10 km, et la surface est de 0 ~ 200, la portée est différente, l'influence est différente, c'est-à-dire que le poids est différent (mais il ne fait pas reflètent l'importance), mais après normalisation, le poids peut mieux refléter l'importance.
Deux façons :

et ! Certaines caractéristiques sont quantifiées, telles que la distance et la surface.
Mais il y a encore certaines caractéristiques telles que "la ville où vous vous trouvez" qui ne sont pas quantifiées, vous pouvez donc trouver un moyen de quantifier les caractéristiques pour résoudre le problème : comme le classement des villes.
Référence : Pourquoi la normalisation des fonctionnalités
1.3 Traitement des données déséquilibrées
Exemple typique : 99 " images " "exemples" de chats ("images" peuvent entraîner des problèmes de reconnaissance, remplacés par "exemples" ici), et un exemple d'image d'un chien comme ensemble d'entraînement. (Ces exemples sont des descriptions de fonctionnalités, qui peuvent être le poids de la hauteur des couleurs ou la distribution des valeurs de pixels dans l'image)
Tant que la machine devine tous les chats, le taux de précision peut atteindre 99 %
. problème de classification des chats et des chiens, la classification de cette machine Le taux de précision de la classification de la méthode est de 100 % pour les chats, mais de 0 % pour les chiens. Donc,
en fait, cette machine ne peut pas résoudre le problème de la classification des chats et des chiens
[simplement la classification, pas reconnaissance]
• 也就是说这个数据集不能解决这个问题,那么就要对数据集进行处理。
1. Trouver un meilleur ensemble de données
2. Dupliquer l'exemple du chien, le rendre égal
3. Réduire l'exemple du chat, le rendre égal
Pour les autres méthodes, reportez-vous à l'article suivant : Traiter les données déséquilibrées
2 Concepts de conception de réseau
2.1 Fonction d'excitation
Je n'y connais pas grand-chose, alors parlons brièvement de mon opinion :
tout d'abord, toutes les fonctionnalités pincées ne peuvent pas durer éternellement. Dans le processus de travail sur les réseaux de neurones, de nombreuses combinaisons de fonctionnalités doivent être éliminées. L'élimination mécanisme est la fonction d'activation. Par conséquent, la fonction d'activation retransforme le résultat pour déterminer s'il répond à la norme d'activation.
En termes simples, si cette route peut aller, si c'est 0, elle ne peut pas aller (tuer les neurones), si ce n'est pas 0, elle peut aller (activer les neurones).
Remarques précédentes :
将线性函数变成非线性来解决非线性问题。也就是对y再进行一次变换。
但这些激励函数必须可微分。因为多层网络的梯度传导中,需要对微分计算梯度下降方向。
对于浅层网络,激励函数选择没有那么大要求。
但是当网络层数比较深的时候,激励函数选择不甚会导致梯度消失以及梯度下降问题。
也和梯度传导过程中的微分有关。
浅层的CNN可以用relu,浅层循环网络可以用relu或者tanh
Emmm n'est que mon sentiment, référence spécifique :
Pourquoi avez-vous besoin d'une fonction d'incitation
Fonctions d'incitation couramment utilisées
2.2 Optimizer optimiseur accélère la formation des réseaux de neurones (comme SGD)
Référence : les optimiseurs accélèrent la formation des réseaux de neurones
Couche 2.3 BN
Cette section présente brièvement, suivie d'une introduction détaillée dans GoogleNet-V2
Normalisation par lots (BN : Batch Normalization : résoudre le problème que la distribution des données de la couche intermédiaire change pendant le processus de formation, afin d'empêcher le gradient de disparaître ou d'exploser, et d'accélérer la vitesse de formation). Prenant la fonction d'activation tanh comme exemple , seules les données de formation dans la
partie médiane Temps sont des données relativement plus efficaces, et lorsqu'elles sont distribuées des deux côtés, l'influence sur le processus de formation sera comparée. . . "Fixe" (ne change pas beaucoup avec les changements)
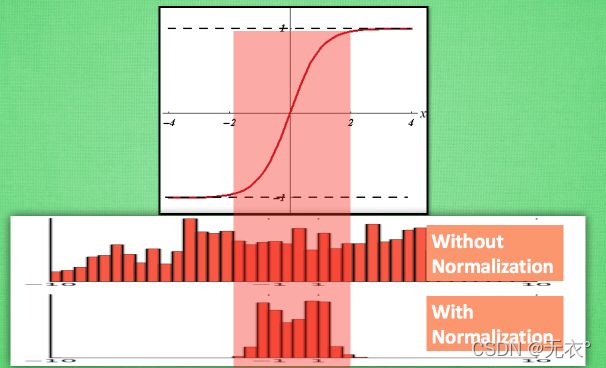
, nous pouvons donc le migrer sans affecter la distribution globale des données, c'est-à-dire normaliser et transformer les données dans un bon intervalle tout en conservant relativement la distribution , de manière à mieux " influencer la formation.
Référence :
Pourquoi la normalisation par lots de
la couche BN Explication détaillée
2.4 Développement et sélection de réseaux classiques
Parce que si le réseau est divisé en modules, la structure à quatre niveaux est trop grande et la longueur elle-même est trop longue, il n'est donc pas pratique d'écrire et de lire. Ici, je choisis directement le réseau Unet pour le traitement des images médicales.
Ouvrez un seul article pour présenter : introduction rapide à pytorch et combat réel - 2. Développement de réseau classique d'apprentissage en profondeur
3. Concepts de la fonction Perte
Ne vous y attardez pas trop, regardez-le avec désinvolture ou ne le regardez pas. A ce stade, il est bon de le comprendre simplement, de toute façon, c'est une erreur.
Fonctions de perte courantes
3.1 Régularisation L1 L2
Qu'est-ce que la régularisation L1 L2
3.2 Erreur quadratique moyenne
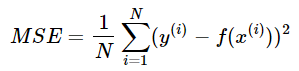
3.3 Fonction de coût d'entropie croisée (entrée croisée)