Dans le domaine des entreprises, Jinli est une solution unique pour les scénarios d'approvisionnement des employés tels que les avantages, le marketing et les incitations, y compris une plate-forme SAAS d'incitation flexible pour les employés et les membres. Puisqu'il s'adresse directement à tous les employés de l'entreprise, la haute disponibilité de ses services est particulièrement importante.Cet article présentera comment réduire le MTTR de l'application grâce à des exercices d'ingénierie du chaos à la veille de la promotion Jinli Mall.
Le MTTR (temps moyen de récupération) est le temps moyen nécessaire pour récupérer d'une panne de produit ou de système . Cela inclut toute la durée de la panne - à partir du moment où le système ou le produit tombe en panne jusqu'à ce qu'il soit restauré à plein fonctionnement.
Comment réduire le MTTR de l'application dans le scénario du chaos drill, doit-il se baser sur la surveillance et le positionnement, puis sur un retour manuel pour le traitement ? Peut-il être automatisé et existe-t-il une solution pour réduire l'impact lors de l'exercice de chaos ? De cette manière, une hémostase rapide peut être obtenue et la stabilité du système peut être encore améliorée.
Cet article répondra aux questions ci-dessus en se basant sur la réflexion et la pratique.
Les échecs sont omniprésents et inévitables.
Nous commencerons par l'enquête et les mesures du problème de redémarrage de la machine hôte et de l'exercice de chaos du service sous-jacent.
arrière-plan
[Perspective du client] : Il existe un grand nombre d'interfaces (y compris les connaissements), des rapports d'erreurs sur les heures supplémentaires, des sauts de taux de disponibilité, certains clients sont touchés, ce qui entraîne des plaintes des clients.
Grâce au positionnement, nous avons découvert les raisons du redémarrage de la machine hôte et de l'exercice chaotique des services sous-jacents au début de la préparation de la grande promotion, qui a longtemps affecté la disponibilité et les performances de notre système secondaire. En particulier, le déploiement et l'application de l'interface centrale affecteront la disponibilité de plusieurs interfaces à grande échelle et affecteront davantage l'expérience des acheteurs finaux.
Surtout dans le domaine TOB, il y a un effet de bouche à oreille des gros clients, si un gros client rencontre ce problème, il sera facilement amplifié et intensifié.
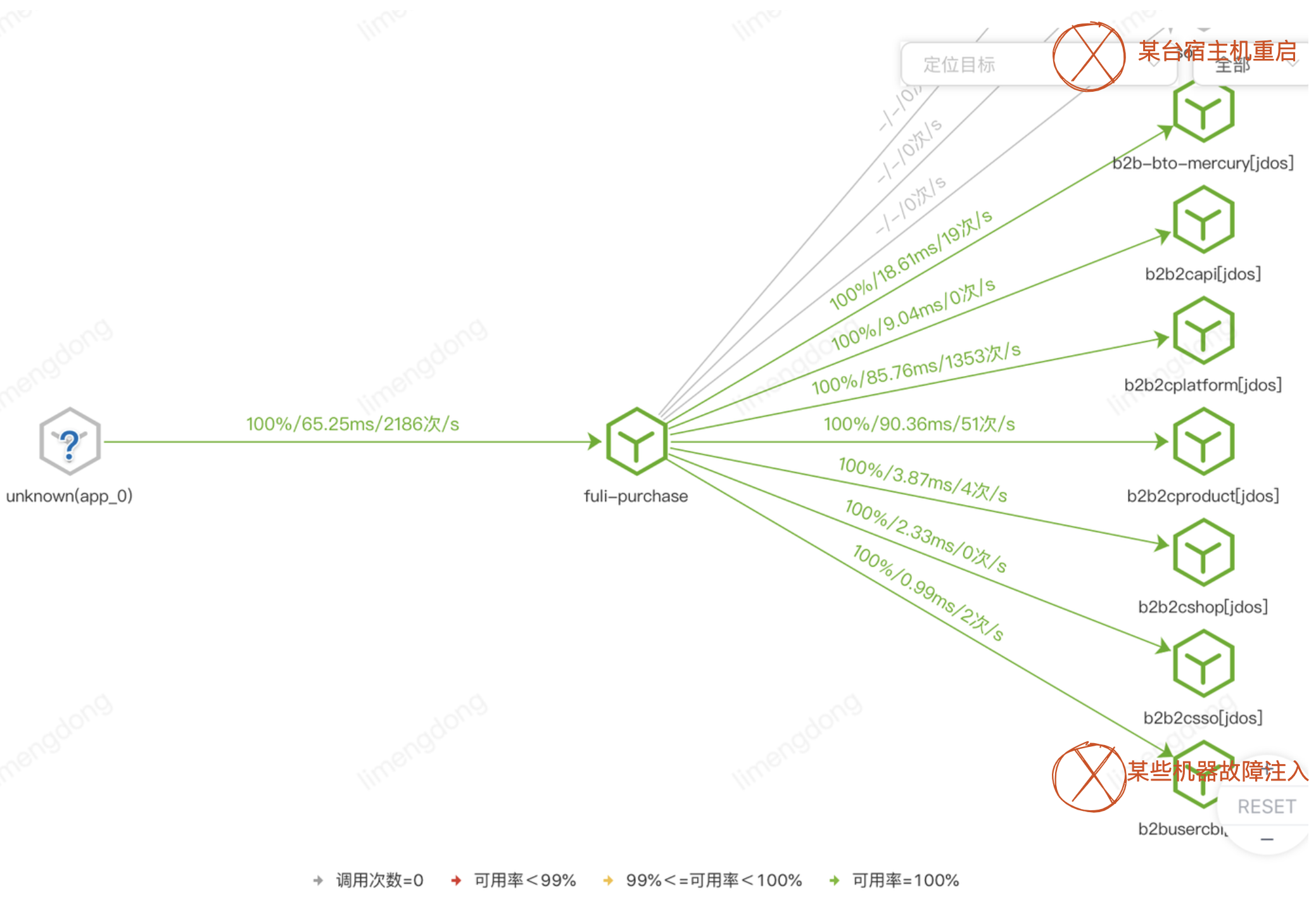
Mesures temporaires
D'une part, coopérez avec l'équipe d'exploitation et de maintenance pour confirmer que la machine hôte redémarre sans notification en temps opportun, et d'autre part, synchronisez l'impact de l'exercice avec le fournisseur de services sous-jacent. Il est recommandé qu'ils respectent le principe de l'exercice pour minimiser le rayon d'explosion, contrôler la portée de l'impact et s'assurer que la perceuse est contrôlable.
En plus de la coordination ci-dessus avec la situation externe, nous avons également une réflexion interne. Tout d'abord, l'échec de la situation elle-même est incontrôlable. Indépendamment de la machine hôte ou de l'exercice de chaos, la scène réelle a une probabilité de se produire (et s'est produite ). Ensuite, nous ne pouvons que surveiller et localiser, puis supprimer manuellement la machine ou avertir le fournisseur de services de s'en occuper ? Peut-il être automatisé et existe-t-il des options pour réduire l'impact ? De cette manière, une hémostase rapide peut être obtenue et la stabilité du système peut être encore améliorée.
Plan à long terme - Pratique de capacité de middleware JSF
Étant donné que les pannes ne peuvent être évitées, adoptez les pannes et développez la capacité d'obtenir des pannes d'application par certains moyens techniques pour assurer une haute disponibilité des applications.
Étant donné que plus de 90 % des appels internes sont des appels RPC (JSF), nous nous concentrons toujours sur la tolérance aux pannes du middleware JSF. Ce qui suit présente principalement le délai d'expiration et la nouvelle tentative, l'équilibrage de charge adaptatif et la fusion de services du middleware JSF. Théorie et pratique du basculement .
La pratique est le seul critère pour tester la vérité.
À propos des délais d'expiration et des tentatives
Dans le processus de développement proprement dit, je pense que vous avez vu trop d'échecs causés par des délais d'attente non définis et des paramètres incorrects. Lorsque le délai d'expiration n'est pas défini ou que le paramètre est déraisonnable, la réponse à la demande sera ralentie et l'accumulation continue de demandes lentes provoquera une réaction en chaîne et même provoquera une avalanche d'applications.
Non seulement nos propres services, mais également les services dépendants externes, non seulement les services HTTP, mais également les services middleware, doivent définir une stratégie de nouvelle tentative de délai d'attente raisonnable et y prêter attention.
Tout d'abord, la stratégie de nouvelle tentative des services de lecture et d'écriture est également très différente. Les services de lecture sont naturellement adaptés à une nouvelle tentative (par exemple, réessayez deux fois après avoir défini un délai raisonnable), mais la plupart des services d'écriture ne peuvent pas être réessayés, mais s'ils le sont toute conception idempotente est également possible.
De plus, avant de définir le délai d'attente de l'appelant, il est nécessaire de comprendre le temps de réponse TP99 du service dépendant (si les performances du service dépendant fluctuent fortement, vous pouvez également vous référer au TP95). peut être ajouté 50% sur cette base. Bien sûr, le temps de réponse du service n'est pas constant, et plus de temps de calcul peut être nécessaire dans certaines conditions de longue traîne, donc afin d'avoir suffisamment de temps pour attendre de telles réponses de requêtes de longue traîne, nous devons définir le délai d'attente assez raisonnablement.
Enfin, le nombre de tentatives ne doit pas être trop élevé (une forte simultanéité peut entraîner une série de problèmes (généralement 2 fois, jusqu'à 3 fois), bien que plus le nombre de tentatives est élevé, plus la disponibilité du service est élevée, mais une forte simultanéité conduira au trafic de requêtes multiples, similaire à la simulation d'une attaque DDOS, dans les cas graves, cela peut même accélérer la cascade de défauts. Par conséquent, il est préférable d'utiliser une nouvelle tentative de délai d'attente en conjonction avec des fusibles, des échecs rapides et d'autres mécanismes pour de meilleurs résultats, ce qui permettra être mentionné plus tard.
En plus d'introduire des moyens, il est important de vérifier l'efficacité des moyens.
Scène de simulation (les deux autres méthodes suivantes utilisent également cette scène)
Solution : utiliser l'injection de fautes (50 % de retard du réseau machine 3000-5000 ms) pour simuler des scénarios similaires et vérifier.
Le déploiement de la machine est le suivant :
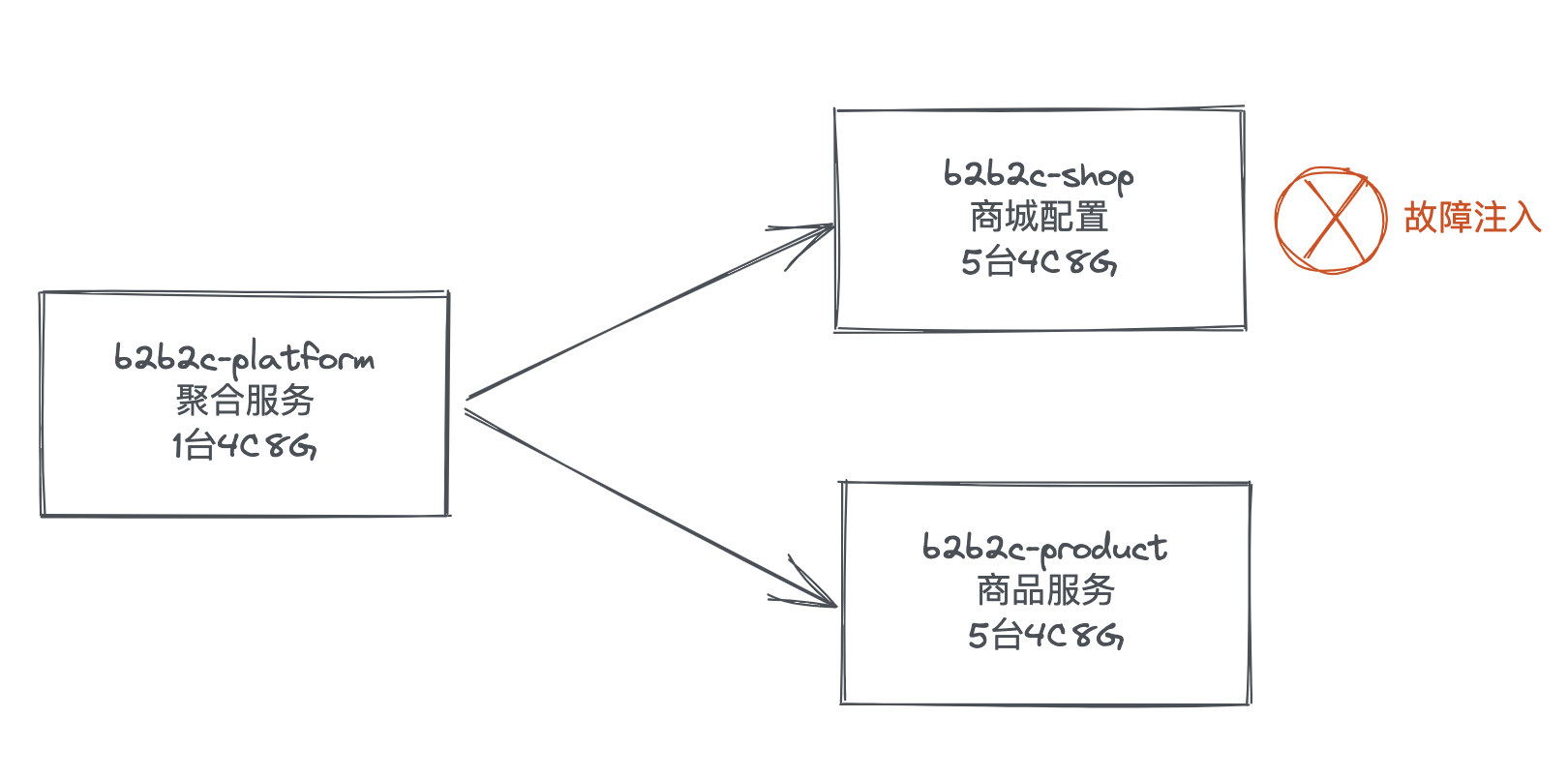
Surveillance de la valeur clé de l'interface de test de pression (QPS-300) et de l'interface de défaut :
1. Interface de mesure de pression : jdos_b2b2cplatform.B2b2cProductProviderImpl.queryProductBpMap
2. Consommation de services : jdos_b2b2cplatform.ActivityConfigServiceRPCImpl.queryActivityConfig
3. Prestation de service : jdos_b2b2cshop.com.jd.ka.b2b2c.shop.service.impl.sdk.ActivityConfigServiceImpl.queryActivityConfig
【Avis】
Les scénarios réseau ne prennent pas en charge les situations suivantes :
1. La salle informatique où se trouve le conteneur applicatif : lf04, lf05, lf07, ht01, ht02, ht05, ht07, htmysql, lfmysql02, yn02, hk02, hk03
2. La version du noyau de la machine physique : 2.6x, 3.8x, 3.10x
Cas normal (pas de défaut injecté)
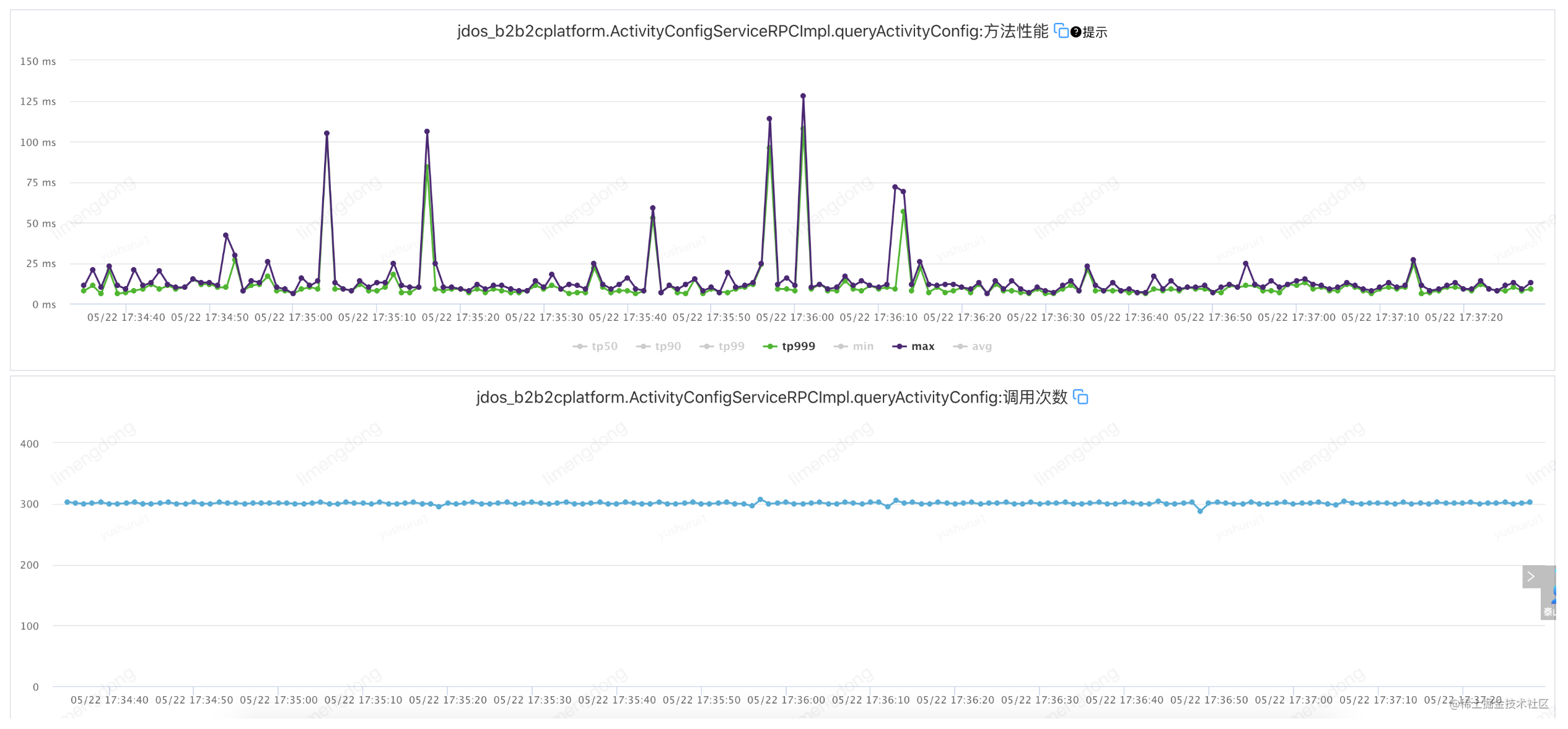
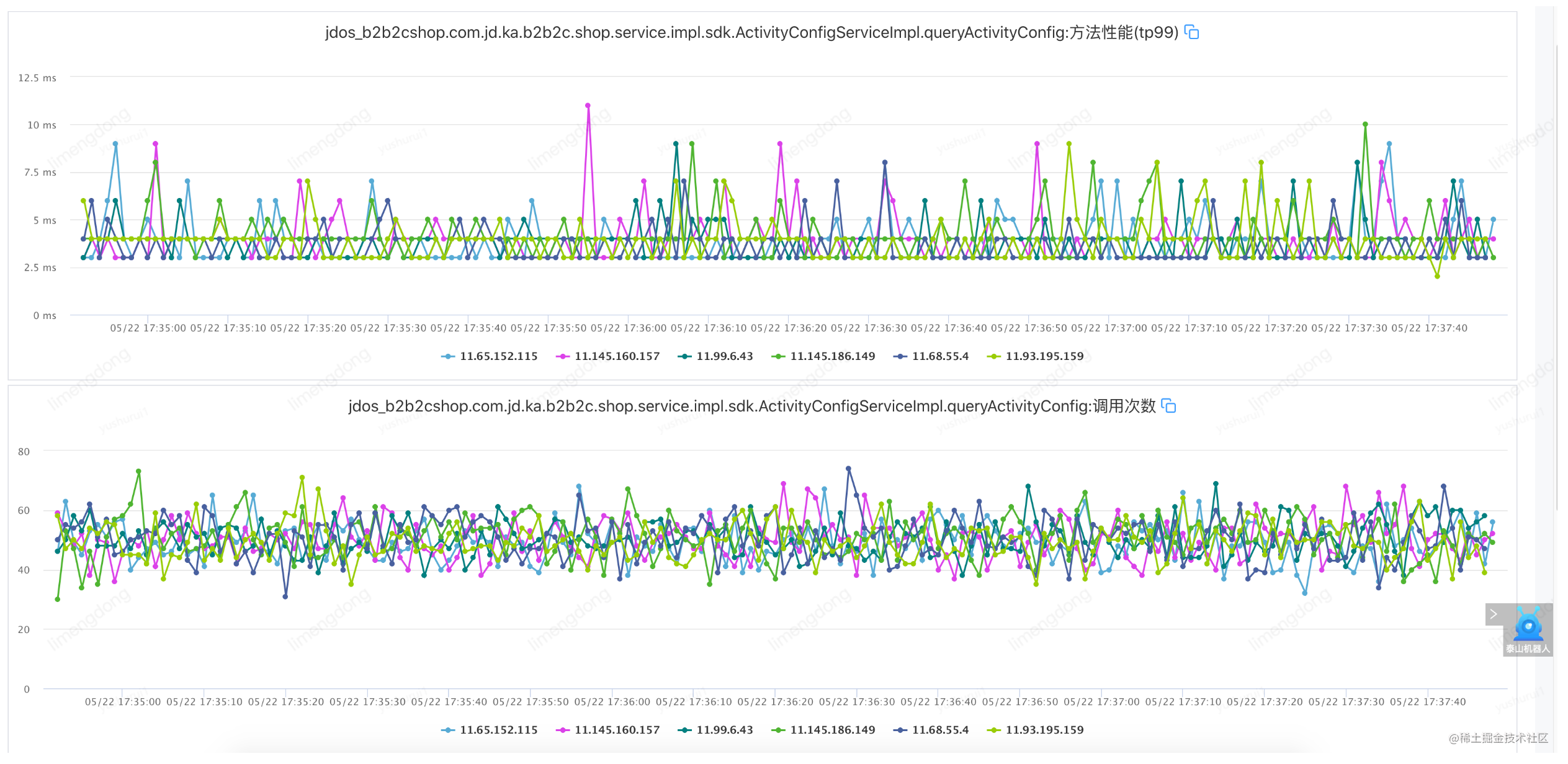
Échec de l'injection - lorsque le paramètre de temporisation est déraisonnable (timeout 2000 ms, réessayez 2)
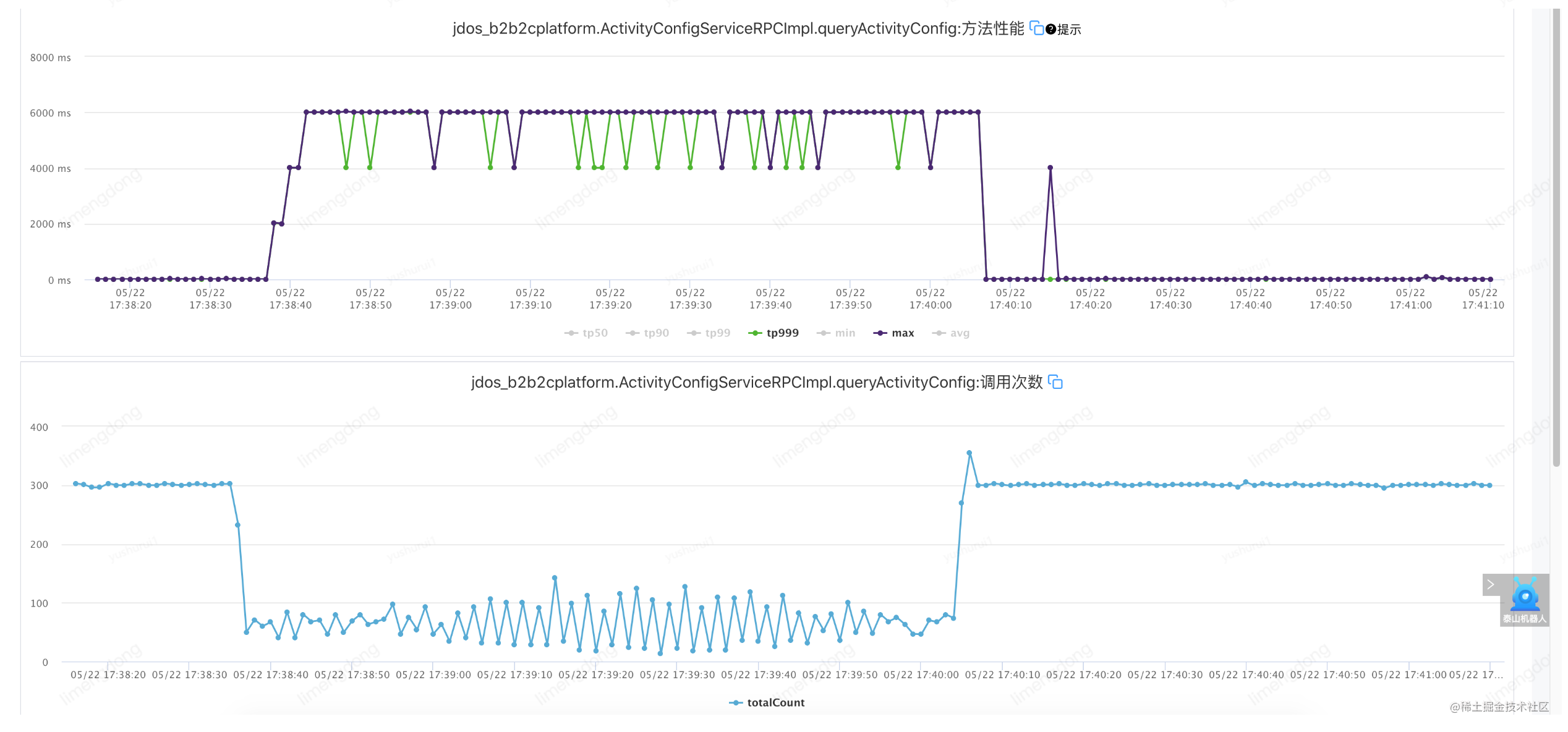
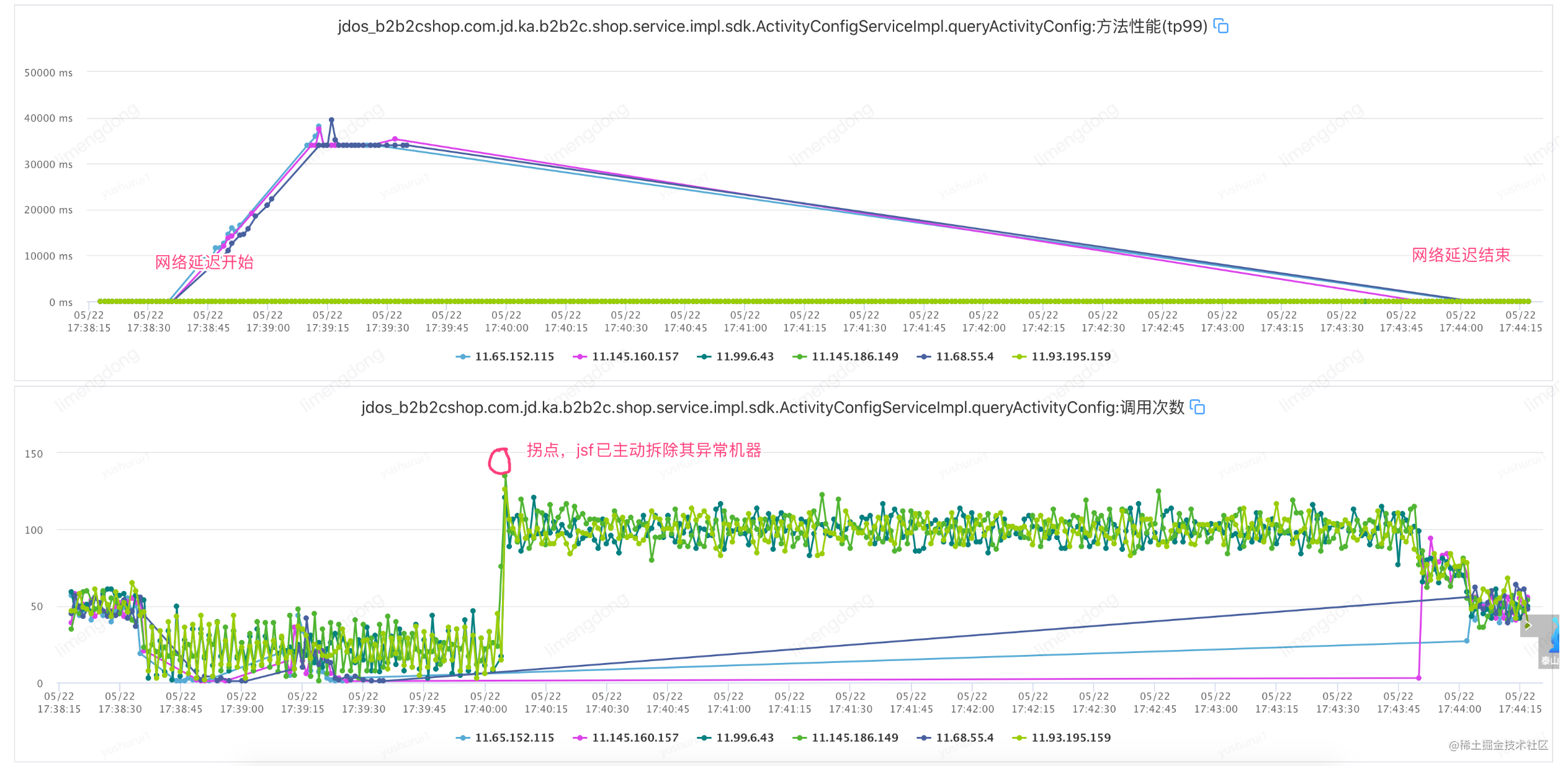
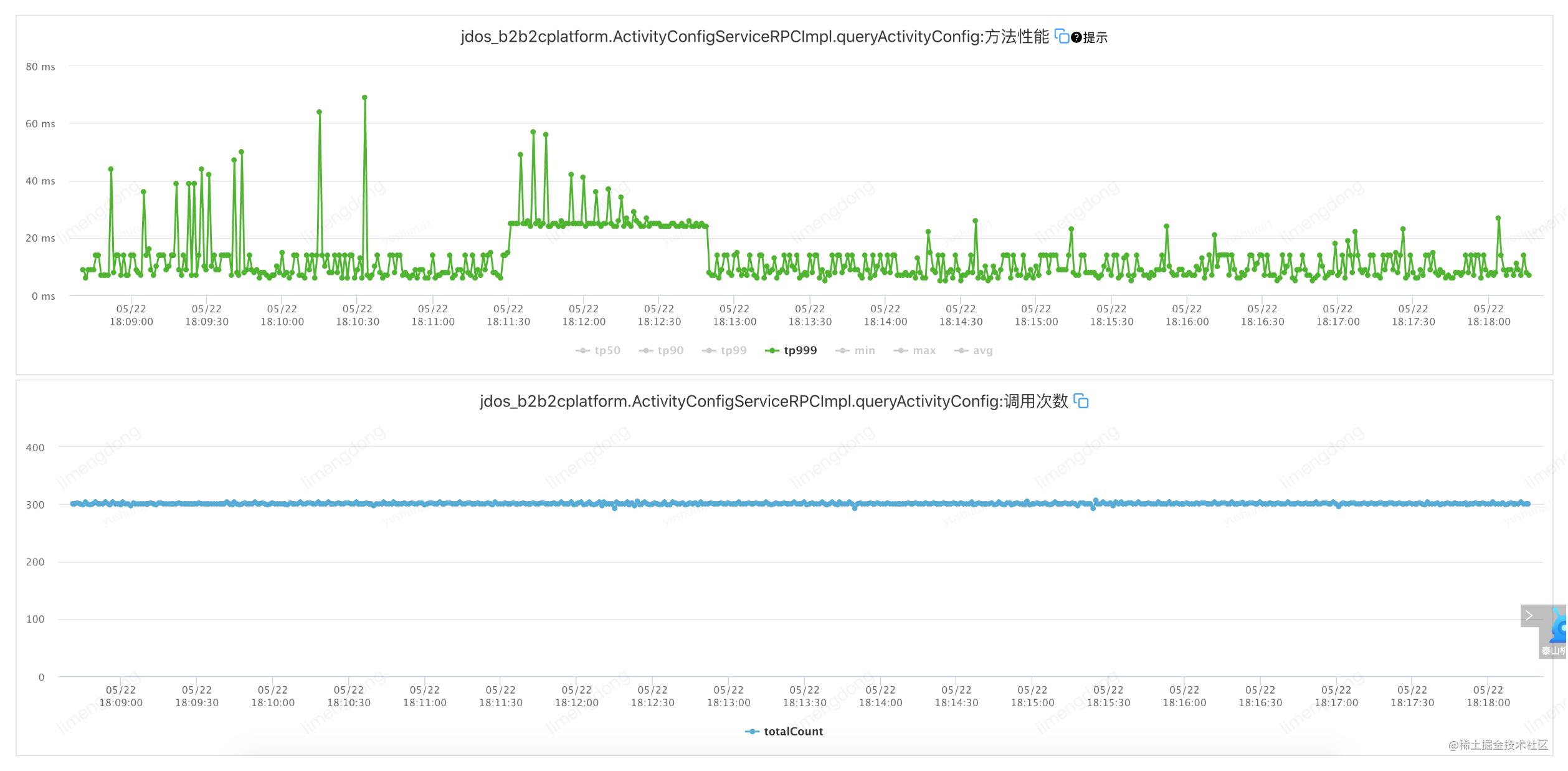
Défaut d'injection - lorsque le paramètre de temporisation est raisonnable (timeout 10 ms, réessayez 2)
L'interface TP99 est à 6ms, réglez le timeout à 10ms, réessayez 2. A savoir : jsf:methodname="queryActivityConfig"timeout="10"retries="2"/
Résumé des tentatives d'expiration du délai
Grâce à des tentatives d'expiration raisonnables, la demande globale est stable et le basculement après les tentatives améliore considérablement la disponibilité de l'interface.
Supplément de nouvelle tentative de délai d'attente
Dans le cas d'un fractionnement déraisonnable de la dimension d'interface, nous pouvons utiliser la configuration de nouvelle tentative de délai d'expiration de la dimension de méthode d'une manière plus précise. Cependant, il y a une note ici. La méthode d'annotation actuelle de JSF ne prend pas en charge la nouvelle tentative de délai d'expiration. paramètre de la dimension de méthode, ne prend en charge que la dimension d'interface. , si la classe d'annotation a été utilisée, elle peut être configurée et utilisée en migrant XML.
À propos de l'équilibrage de charge adaptatif
Le but de la conception d'équilibrage de charge adaptatif à réponse la plus courte est de résoudre le problème des capacités inégales des nœuds de fournisseur, de sorte que les fournisseurs avec des capacités de traitement plus faibles puissent accepter moins de trafic, de sorte que les fournisseurs individuels avec de moins bonnes performances n'affectent pas la demande chronophage des consommateurs comme dans son ensemble et sa disponibilité.
Ceux qui sont capables travaillent plus que ceux qui sont maladroits, et ceux qui sont sages s'inquiètent plus que ceux qui sont insensés.
Cependant, il y a quelques problèmes avec cette stratégie :
- Une concentration excessive du trafic sur des instances hautes performances et la limite de trafic sur une seule machine du fournisseur de services peuvent devenir un goulot d'étranglement.
- La longueur de la réponse ne représente parfois pas le débit de la machine.
- Dans la plupart des scénarios, lorsqu'il n'y a pas de différence évidente dans la durée de réponse des différents fournisseurs, la réponse la plus courte équivaut à aléatoire (aléatoire).
Le mécanisme de mise en œuvre de la réponse la plus courte existant est similaire à l'algorithme P2C (Power of Two Choice), mais la méthode de calcul n'utilise pas le nombre de connexions en cours de traitement, mais sélectionne au hasard deux fournisseurs de services pour participer au calcul de comparaison de réponse la plus rapide par défaut, à savoir : statistiques Demander du temps, des visites, des exceptions et des demandes simultanées pour chaque fournisseur, comparer le temps de réponse moyen * le nombre actuel de demandes et l'utiliser pour calculer la charge de réponse la plus rapide. Choisissez les gagnants pour éviter l'élevage. De cette manière, la capacité de débit de la machine côté fournisseur est mesurée de manière adaptative, puis le trafic est alloué autant que possible à la machine avec une capacité de débit élevée pour améliorer les performances de service globales du système.
<jsf:consumer id="activityConfigService"
interface="com.jd.ka.b2b2c.shop.sdk.service.ActivityConfigService"
alias="${jsf.activityConfigService.alias}" timeout = "3000" filter="jsfLogFilter,jsfSwitchFilter"
loadbalance="shortestresponse">
<jsf:method name="queryActivityConfig" timeout="10" retries="2"/>
</jsf:consumer>
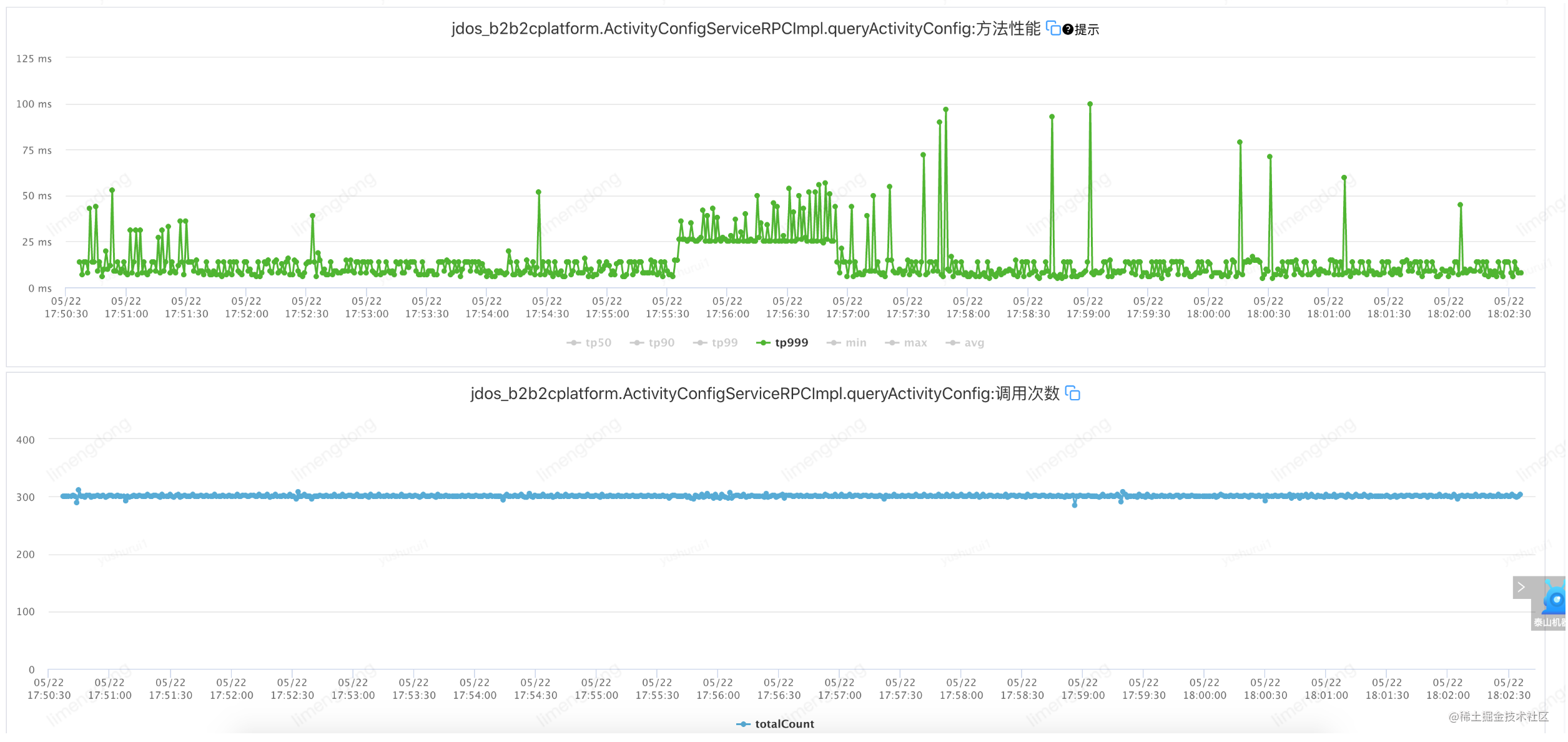
Injecter des défauts (configurer un équilibrage de charge adaptatif)
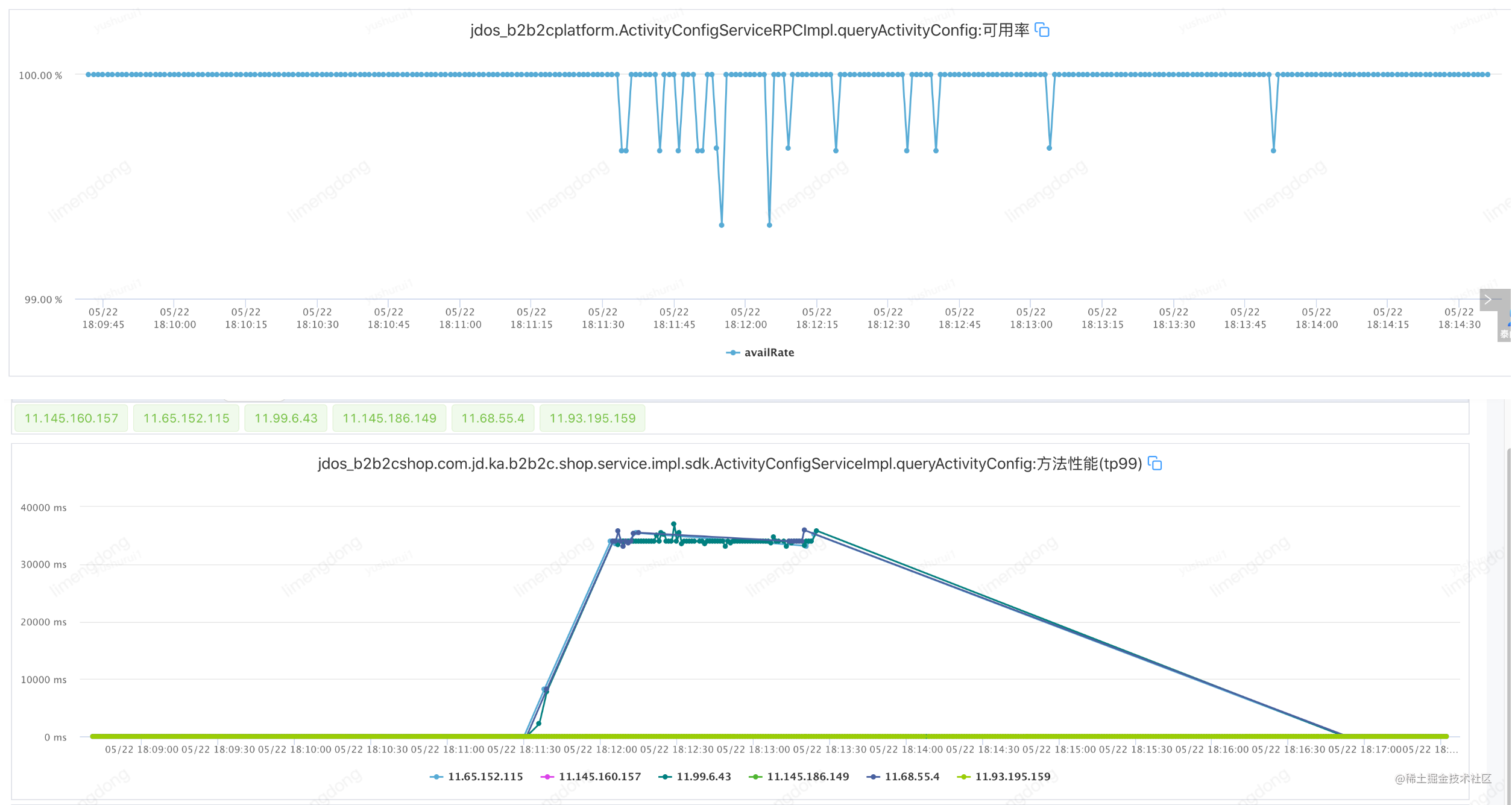
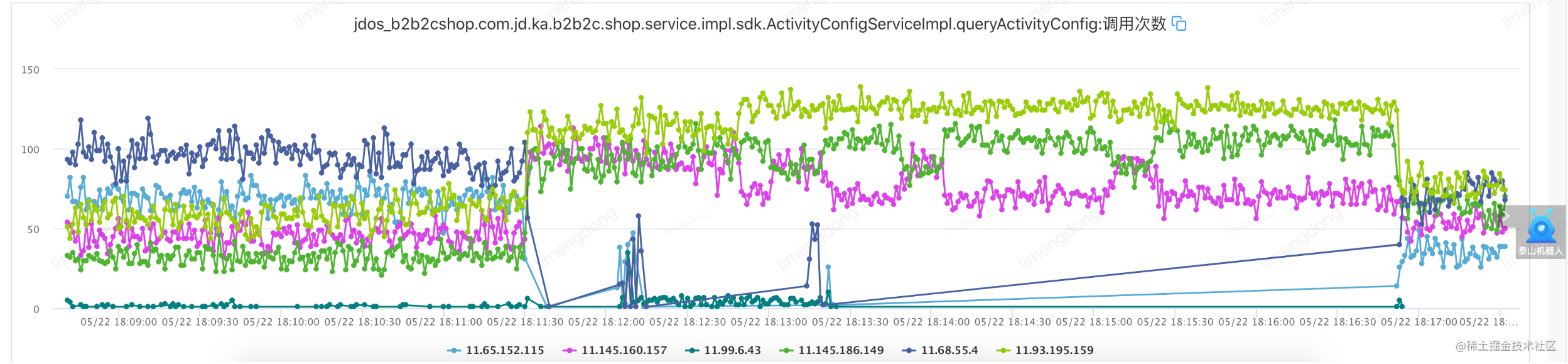
Résumé de l'équilibrage de charge adaptatif
En introduisant l'équilibrage de charge adaptatif, le mode "homme capable travaille plus" démarre dès l'appel initial de l'interface, et la machine élue transporte un trafic plus élevé. Après l'injection de la faute, la fenêtre à court terme de disponibilité de l'interface disparaît et la disponibilité rate jumps.point, ce qui garantit en outre la haute disponibilité et la performance du service.
À propos du disjoncteur de service
Lorsque le circuit est court-circuité ou sérieusement surchargé, le fusible dans le fusible fusionnera automatiquement pour protéger le circuit. Éviter les impacts majeurs sur les équipements, même les incendies.
La fusion de service est un mécanisme de protection de liaison pour les scénarios de service instables.
L'idée de base derrière cela est très simple, encapsulez un appel de fonction protégé dans un objet disjoncteur, qui surveille les pannes. Lorsqu'un service du lien d'appel est indisponible ou que le temps de réponse est trop long, ce qui fait que le défaut atteint le seuil défini, le service sera interrompu et il n'y aura plus d'appels au service du nœud dans la fenêtre soufflée, de sorte que pour éviter au maximum l'instabilité des services aval Impact sur les services amont.
<!-- 服务熔断策略配置 -->
<jsf:reduceCircuitBreakerStrategy id="demoReduceCircuitBreakerStrategy"
enable="true" <!-- 熔断策略是否开启 -->
rollingStatsTime="1000" <!-- 熔断器指标采样滚动窗口时长,单位 ms,默认 5000ms -->
triggerOpenMinRequestCount="10" <!-- 单位时间内触发熔断的最小访问量,默认 20 -->
triggerOpenErrorCount="0" <!-- 单位时间内的请求异常数达到阀值,默认 0,小于等于0 代表不通过异常数判断是否开启熔断 -->
triggerOpenErrorPercentage="50" <!-- 单位时间内的请求异常比例达到阀值,默认 50,即 默认 50% 错误率 -->
<!-- triggerOpenSlowRT="0" 判定请求为慢调用的请求耗时,单位 ms,请求耗时超过 triggerOpenSlowRT 则认为是慢调用 (默认为 0,即默认不判定)-->
<!-- triggerOpenSlowRequestPercentage="0" 采样滚动周期内触发熔断的慢调用率(默认为 0,即默认不触发慢调用熔断 -->
openedDuration="10000" <!-- 熔断开启状态持续时间,单位 ms,默认 5000ms -->
halfOpenPassRequestPercentage="30" <!-- 半闭合状态,单位时间内放行流量百分比,默认 40-->
halfOpenedDuration="3000" <!-- 半闭合状态持续时间设置,需要大于等于 rollingStatsTime ,默认为 rollingStatsTime -->
<!-- failBackType="FAIL_BACK_EXCEPTION" failBack策略, 取值:FAIL_BACK_EXCEPTION抛出异常、FAIL_BACK_NULL返回null、FAIL_BACK_CUSTOM配置自定义策略,配合 failBackRef 属性 -->
<!-- failBackRef="ref" 如果 failBackStrategy 配置为 FAIL_BACK_CUSTOM 则必填,用户自定义的failback策略com.jd.jsf.gd.circuitbreaker.failback.FailBack<Invocation> 接口实现类 -->
/>
<jsf:consumerid="activityConfigService"interface="com.jd.ka.b2b2c.shop.sdk.service.ActivityConfigService"
alias="${consumer.alias.com.jd.ka.b2b2c.shop.sdk.service.ActivityConfigService}" timeout="2000"check="false"
serialization="hessian"loadbalance="shortestresponse"
connCircuitBreakerStrategy="demoCircuitBreakerStrategy">
<jsf:methodname="queryActivityConfig"timeout="10"retries="2"/>
</jsf:consumer>
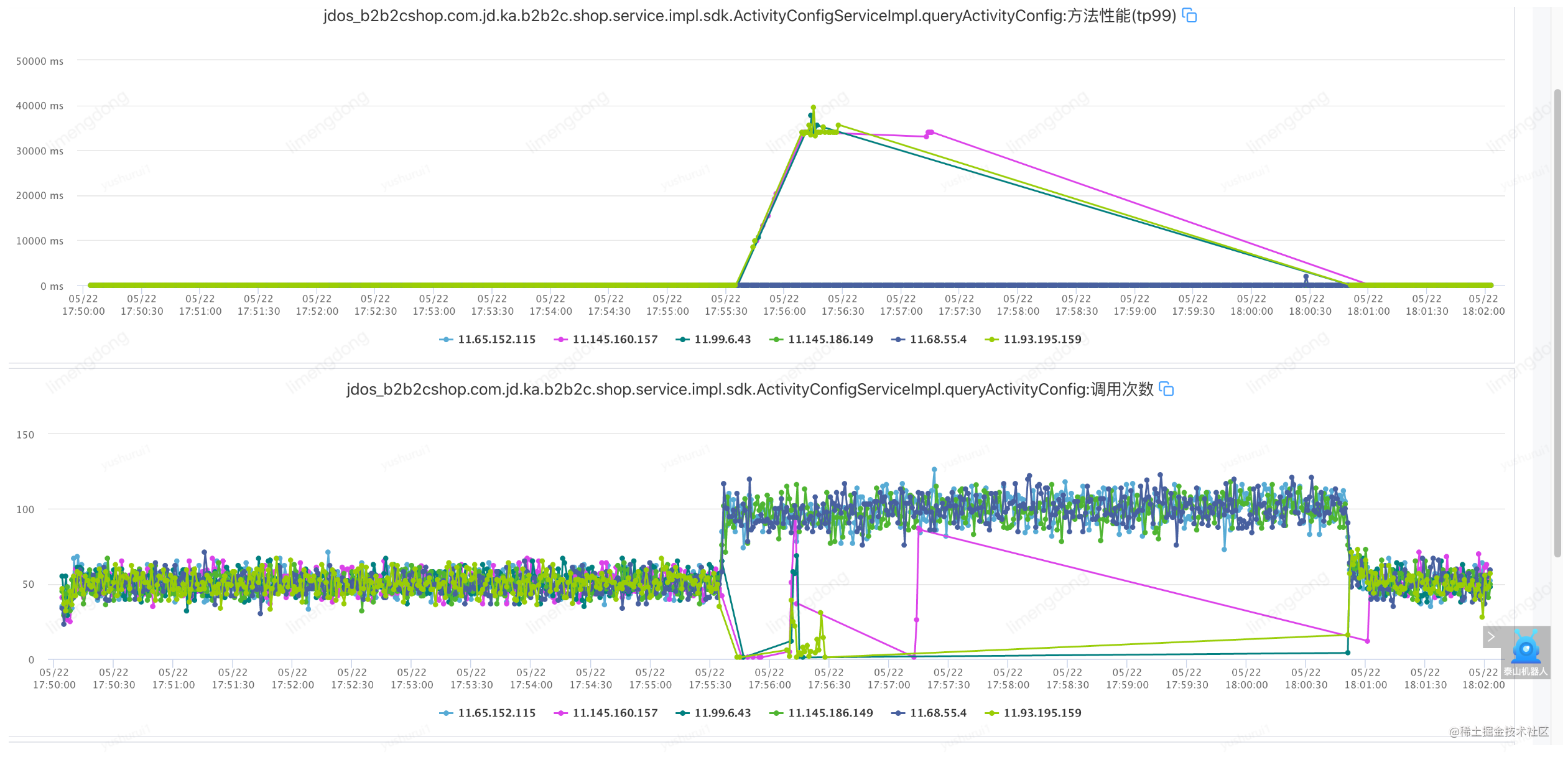
Voici un petit épisode. En raison du mécanisme de battement de cœur de JSF lui-même, après avoir détecté un défaut, la machine correspondante est automatiquement supprimée (détectée une fois toutes les 30 secondes et supprimée si les trois temps sont anormaux). Le mécanisme de fusible que nous avons défini nous-mêmes n'est pas évident, nous réinitialisons donc le défaut.(Délai réseau 800-1500ms) pour re-percer.
Panne d'injection (disjoncteur de service)
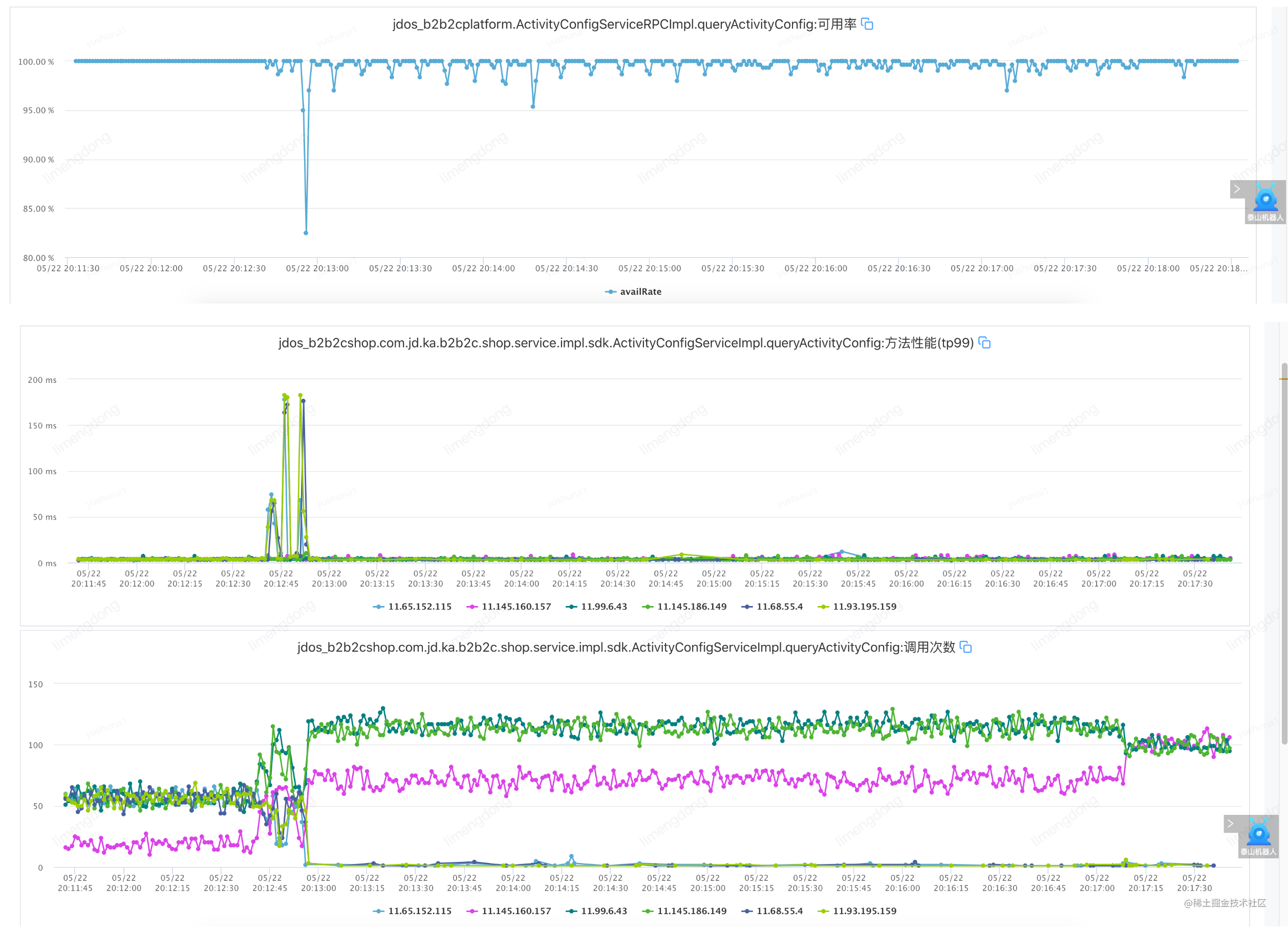
Résumé du disjoncteur de service
Du point de vue de la disponibilité, il est vrai que l'accès aux nœuds de machine anormaux sera fermé dans la fenêtre. Cependant, étant donné que la stratégie de restauration automatique n'est pas implémentée et que la fenêtre d'ouverture pour la fusion est courte, la disponibilité renverra toujours directement le message d'échec d'appel. après l'ouverture de la fenêtre, affectant ainsi la disponibilité. Par conséquent, par rapport à l'échec après la fusion, le meilleur moyen est de coopérer avec la capacité de dégradation du service, en appelant la logique de dégradation du service prédéfinie, et d'utiliser le résultat de la logique de dégradation comme résultat d'appel final pour le renvoyer à l'appelant du service. plus élégamment.
Supplément de disjoncteur de service
- Le groupe a construit un composant de fusible unifié et établi des capacités de plate-forme correspondantes sur le mont Tai. Si l'équipe a besoin d'introduire une capacité de disjoncteur, elle peut être directement accessible et utilisée pour éviter la duplication de la construction . Pour plus de détails, voir : http://taishan.jd.com/flowControl/limitIndex
> 一种机制可能会击败另一种机制。
En effet, afin d'améliorer la flexibilité et la robustesse du système pour faire face à diverses pannes et situations imprévisibles, dans les systèmes distribués, il est généralement conçu pour pouvoir échouer partiellement.Même s'il ne peut pas satisfaire tous les clients, il peut toujours envoyer Certains clients fournissent des services. Mais la fusion est conçue pour transformer une défaillance partielle en une défaillance complète, empêchant ainsi la propagation de la défaillance. Par conséquent, il existe une relation restrictive mutuelle entre la coupure de circuit de service et les principes de conception des systèmes distribués. Par conséquent, une analyse et une réflexion approfondies, ainsi qu'un réglage ultérieur, sont nécessaires avant utilisation.
en conclusion
La capacité n'est qu'un moyen, la stabilité est le but.
Quelle que soit la méthode utilisée pour créer la stabilité, nous devons toujours réfléchir à la manière de trouver un équilibre entre les besoins de l'entreprise et la construction de la stabilité, afin de créer une architecture à haute disponibilité qui prend en charge la croissance à long terme de l'entreprise.
Cette fois, j'ai écrit ceci, si vous avez des questions, n'hésitez pas à communiquer. J'espère qu'une partie de l'expérience de l'article vous apportera des gains, ou en d'autres termes, vous souhaiterez peut-être réfléchir aux solutions techniques et aux moyens que vous utiliserez pour résoudre des problèmes similaires. Bienvenue à laisser un message et à échanger, et espérons communiquer avec d'autres partenaires partageant les mêmes idées.
documents de référence
document externe
Le pouvoir de deux choix aléatoires : https://brooker.co.za/blog/2012/01/17/two-random.html
Équilibrage de charge : https://cn.dubbo.apache.org/zh-cn/overview/core-features/load-balance/#shortestresponse
Auteur : JD Retail Li Mengdong
Source de contenu : communauté de développeurs JD Cloud