Sicherheit ist immer eine Frage von größter Bedeutung. Wenn Sicherheitsvorfälle frühzeitig erkannt und gestoppt werden können, kann das Ergebnis völlig anders ausfallen. Der Hauptzweck dieses Artikels ist sehr einfach. Er besteht darin, zu versuchen, ein Erkennungsmodell für gefährliche Objekte wie z B. Waffen und Messer, basierend auf dem Zielerkennungsmodell. Das Identifizierungssystem soll Verbrechen auf Basis künstlicher Intelligenz bekämpfen, schauen Sie sich einfach die Darstellungen an:
Diese Art von Szene ist relativ empfindlich, daher ist es grundsätzlich schwierig, den Datensatz tatsächlich selbst zu sammeln, um das Modell zu entwickeln. Daher stammen die meisten Daten hier von Huchao.com, hauptsächlich für die praktische Analyse und Verwendung. Ein kurzer Blick auf die Der Datensatz lautet wie folgt:

Die Anmerkungsdatei im VOC-Format lautet wie folgt:
Der Inhalt der Beispielanmerkung lautet wie folgt:
<annotation>
<folder>DATASET</folder>
<filename>images/0a53eb41-a382-4463-ad29-3e63bef6420d.jpg</filename>
<source>
<database>The DATASET Database</database>
<annotation>DATASET</annotation>
<image>DATASET</image>
</source>
<owner>
<name>YMGZS</name>
</owner>
<size>
<width>416</width>
<height>416</height>
<depth>3</depth>
</size>
<segmented>0</segmented>
<object>
<name>pistol</name>
<pose>Unspecified</pose>
<truncated>0</truncated>
<difficult>0</difficult>
<bndbox>
<xmin>3</xmin>
<ymin>7</ymin>
<xmax>403</xmax>
<ymax>395</ymax>
</bndbox>
</object>
</annotation>Die Anmerkungsdatei im YOLO-Format lautet wie folgt:

Der Inhalt der Beispielanmerkung lautet wie folgt:
1 0.546875 0.492788 0.122596 0.466346
Die Kerntrainingskonfiguration sieht folgendermaßen aus:
def parse_opt(known=False):
parser = argparse.ArgumentParser()
parser.add_argument('--weights', type=str, default='weights/yolov5n.pt', help='initial weights path')
parser.add_argument('--cfg', type=str, default='models/yolov5n.yaml', help='model.yaml path')
parser.add_argument('--data', type=str, default='data/self.yaml', help='dataset.yaml path')
parser.add_argument('--hyp', type=str, default='data/hyps/hyp.scratch-low.yaml', help='hyperparameters path')
parser.add_argument('--epochs', type=int, default=100, help='total training epochs')
parser.add_argument('--batch-size', type=int, default=8, help='total batch size for all GPUs, -1 for autobatch')
parser.add_argument('--imgsz', '--img', '--img-size', type=int, default=416, help='train, val image size (pixels)')
parser.add_argument('--rect', action='store_true', help='rectangular training')
parser.add_argument('--resume', nargs='?', const=True, default=False, help='resume most recent training')
parser.add_argument('--nosave', action='store_true', help='only save final checkpoint')
parser.add_argument('--noval', action='store_true', help='only validate final epoch')
parser.add_argument('--noautoanchor', action='store_true', help='disable AutoAnchor')
parser.add_argument('--noplots', action='store_true', help='save no plot files')
parser.add_argument('--evolve', type=int, nargs='?', const=300, help='evolve hyperparameters for x generations')
parser.add_argument('--bucket', type=str, default='', help='gsutil bucket')
parser.add_argument('--cache', type=str, nargs='?', const='ram', help='--cache images in "ram" (default) or "disk"')
parser.add_argument('--image-weights', action='store_true', help='use weighted image selection for training')
parser.add_argument('--device', default='0', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')
parser.add_argument('--multi-scale', action='store_true', help='vary img-size +/- 50%%')
parser.add_argument('--single-cls', action='store_true', help='train multi-class data as single-class')
parser.add_argument('--optimizer', type=str, choices=['SGD', 'Adam', 'AdamW'], default='SGD', help='optimizer')
parser.add_argument('--sync-bn', action='store_true', help='use SyncBatchNorm, only available in DDP mode')
parser.add_argument('--workers', type=int, default=0, help='max dataloader workers (per RANK in DDP mode)')
parser.add_argument('--project', default='runs/train', help='save to project/name')
parser.add_argument('--name', default='yolov5n', help='save to project/name')
parser.add_argument('--exist-ok', action='store_true', help='existing project/name ok, do not increment')
parser.add_argument('--quad', action='store_true', help='quad dataloader')
parser.add_argument('--cos-lr', action='store_true', help='cosine LR scheduler')
parser.add_argument('--label-smoothing', type=float, default=0.0, help='Label smoothing epsilon')
parser.add_argument('--patience', type=int, default=100, help='EarlyStopping patience (epochs without improvement)')
parser.add_argument('--freeze', nargs='+', type=int, default=[0], help='Freeze layers: backbone=10, first3=0 1 2')
parser.add_argument('--save-period', type=int, default=-1, help='Save checkpoint every x epochs (disabled if < 1)')
parser.add_argument('--seed', type=int, default=0, help='Global training seed')
parser.add_argument('--local_rank', type=int, default=-1, help='Automatic DDP Multi-GPU argument, do not modify')
Sie können sehen: Ich verwende hier das Modell der n-Serie, die Bildgröße beträgt 416 x 416 und die iterative Berechnung von 100 Epochen wird standardmäßig durchgeführt.
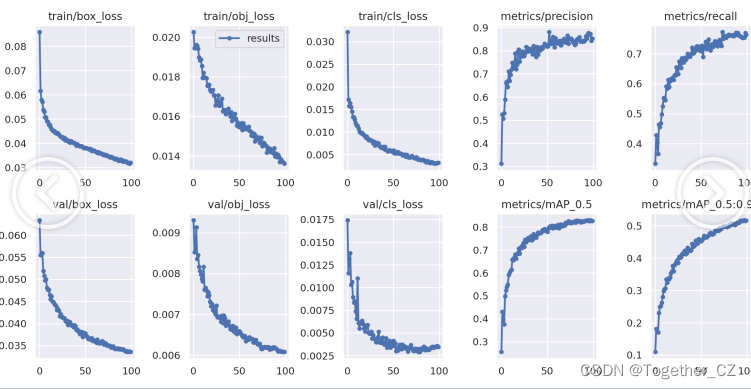
Die Ergebnisdetails lauten wie folgt:
Der F1-Wert und die PR-Kurve lauten wie folgt:
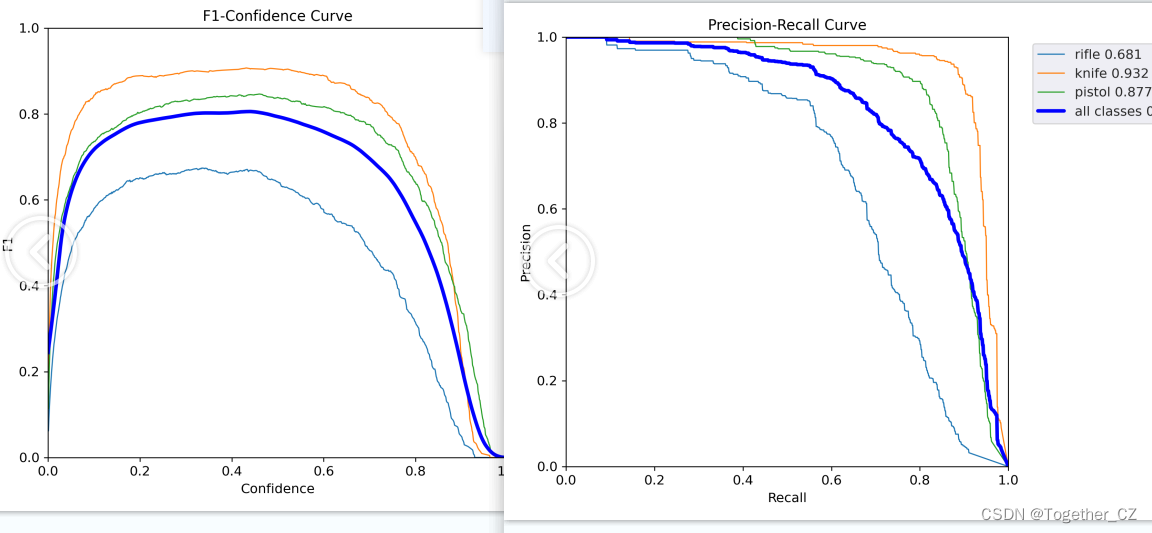
Die Präzisions- und Rückrufkurven lauten wie folgt:
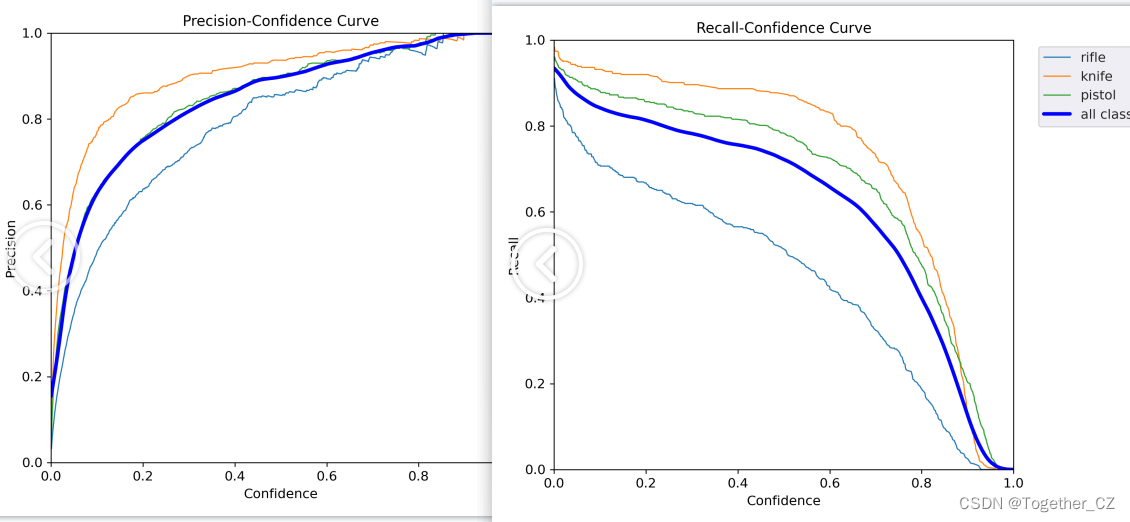
Die allgemeine Trainingsvisualisierung sieht wie folgt aus:
Das Beispiel für die Stapelberechnung lautet wie folgt:

Bei Interesse können Sie es ausprobieren.
Die Verwirrungsmatrix lautet wie folgt:

Die Datenvisualisierung sieht wie folgt aus:
