Table des matières
(5) Étapes de base de l'analyse d'association
4. Algorithme d'analyse de corrélation a priori
(1) Trouver des ensembles d'éléments fréquents
(2) Générer une relation d'association
5. Algorithme de croissance PF
(1) Encoder les transactions dans les arbres FP
(2) Trouver des ensembles d'éléments fréquents
6. implémentation de code python
1. Introduction
Prenons par exemple l'histoire la plus classique des "couches et de la bière". Cette histoire concerne un supermarché qui a analysé les listes de courses des clients dans le passé et a découvert que de nombreux clients achetaient de la bière en achetant des couches. Le supermarché mettait de la bière et des couches sur des étagères adjacentes. étagères, une décision bizarre qui a vu les ventes de couches et de bière monter en flèche.
Il est difficile de trouver intuitivement la relation entre les couches et la bière, mais après ce type d'exploration et d'analyse de données, cette relation peut être découverte à partir des données chaotiques Le processus de recherche de la relation est une analyse de corrélation.
L'analyse de corrélation a été largement utilisée dans les plates-formes de commerce électronique et de vidéos courtes d'aujourd'hui, et ses principaux scénarios d'application sont les suivants :
(1) Ventes de matières premières , analysez la possibilité pour les clients d'acheter différentes matières premières en même temps, afin de concevoir des stratégies de commercialisation des matières premières de manière ciblée.
(2) Analyse du comportement , basée sur le comportement des utilisateurs sur Internet, analyse leurs habitudes et préférences de comportement potentielles
(3) Diagnostic des pannes Pour les grands systèmes complexes, il est possible d'analyser les pannes corrélées en examinant les données historiques passées.
2. Concepts de base
(1) Ensemble d'éléments
Soit I={i1,i2,...,id} l'ensemble de tous les éléments des données et T={t1,t2,...,tn} l'ensemble de toutes les transactions. Les itemsets contenus dans chaque transaction ti sont un sous-ensemble de I.
Dans l'analyse d'association, une collection contenant zéro ou plusieurs éléments est appelée un ensemble d'éléments. Si un itemset contient k éléments, il est appelé k-itemset. Un ensemble d'éléments qui ne contient que 0 éléments est appelé un ensemble vide.
(2) Règles d'association
Les règles d'association sont de la forme X -> Y , où X et Y sont des ensembles d'éléments disjoints.
La signification de cette règle d'association est la suivante : sur la base des données historiques, X apparaît et la possibilité que Y apparaisse en même temps est très élevée.
(3) Assistance
Le degré de prise en charge reflète la fréquence de tous les éléments de la relation d'association apparaissant dans l'ensemble de données Si le degré de prise en charge d'une relation d'association est élevé, la règle d'association peut être universelle .
Le soutien de l'élément X est défini comme
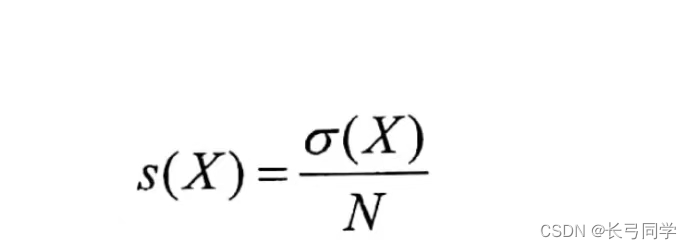
(Dans cette formule : N est le nombre de transactions dans la transaction et O(X) est le nombre de fois que X apparaît dans la transaction.)
Pour une règle d'association de la forme X -> Y, son support est défini comme

(Dans cette formule : O(XUY) signifie le nombre de fois où X et Y apparaissent en même temps)
(4) Confiance
La règle d'association X->Y avec une confiance plus élevée indique que Y est plus susceptible d'apparaître lorsque X apparaît, et la fiabilité de cette règle d'association est plus élevée.
Le niveau de confiance de X->Y est défini comme :

(5) Étapes de base de l'analyse d'association
1. Trouver des ensembles d'éléments fréquents
2. Générer des règles d'association
4. Algorithme d'analyse de corrélation a priori
(1) Trouver des ensembles d'éléments fréquents
Donner d'abord un principe préalable :
Théorème 1. Si un itemset est fréquent, alors son sous-ensemble doit aussi être fréquent
Théorème 2. Si un itemset est un itemset peu fréquent, alors son sur-ensemble (ensemble parent) doit aussi être un itemset peu fréquent
L'algorithme d'analyse d'association Apriori utilise le théorème 2 pour trouver rapidement les itemsets non fréquents, exclut les itemsets non fréquents et le reste correspond aux itemsets fréquents à trouver.
(2) Générer une relation d'association
Le nombre de règles d'association dans les itemsets fréquents est encore très important, il est donc nécessaire d'utiliser certaines propriétés de confiance pour supprimer autant que possible les relations d'association invalides, réduisant ainsi la difficulté de générer des règles d'association.
Théorème 3. Pour le k-itemset fréquent Y, si la confiance de la règle X->YX est inférieure au seuil de confiance, alors la confiance de la règle X'->YX' est également inférieure au seuil de confiance. Autrement dit, c(X->Y) < c0, alors c(X'->Y) < c0 .
Le théorème 3 peut être utilisé pour exclure rapidement les règles d'association invalides et se concentrer uniquement sur les règles d'association qui respectent le seuil de confiance.
5. Algorithme de croissance PF
L'algorithme de croissance FP (frequent pattern growth) encode les ensembles de transactions dans une structure de données d'arbres FP et obtient des ensembles d'éléments fréquents basés sur les arbres FP.
(1) Encoder les transactions dans les arbres FP
Le tableau suivant est supposé collecter les informations des grandes catégories V qui préoccupent plusieurs utilisateurs ordinaires :
(ensemble de transactions triées par le nombre d'occurrences de l'élément)
| identifiant de transaction | article |
| 1 | Actualités, Finances, Sports |
| 2 | nouvelles, santé |
| 3 | finances, célébrité |
| 4 | l'éducation physique |
| 5 | Actualités, Finance, Santé |
| 6 | Actualités, Finances, Stars |
| 7 | star de l'actualité |
| 8 | Actualités, Finances, Sports |
1. Programmez la transaction 1 dans l'arborescence FP, et le nombre à côté du nom du nœud indique le nombre de transactions passant par le nœud :
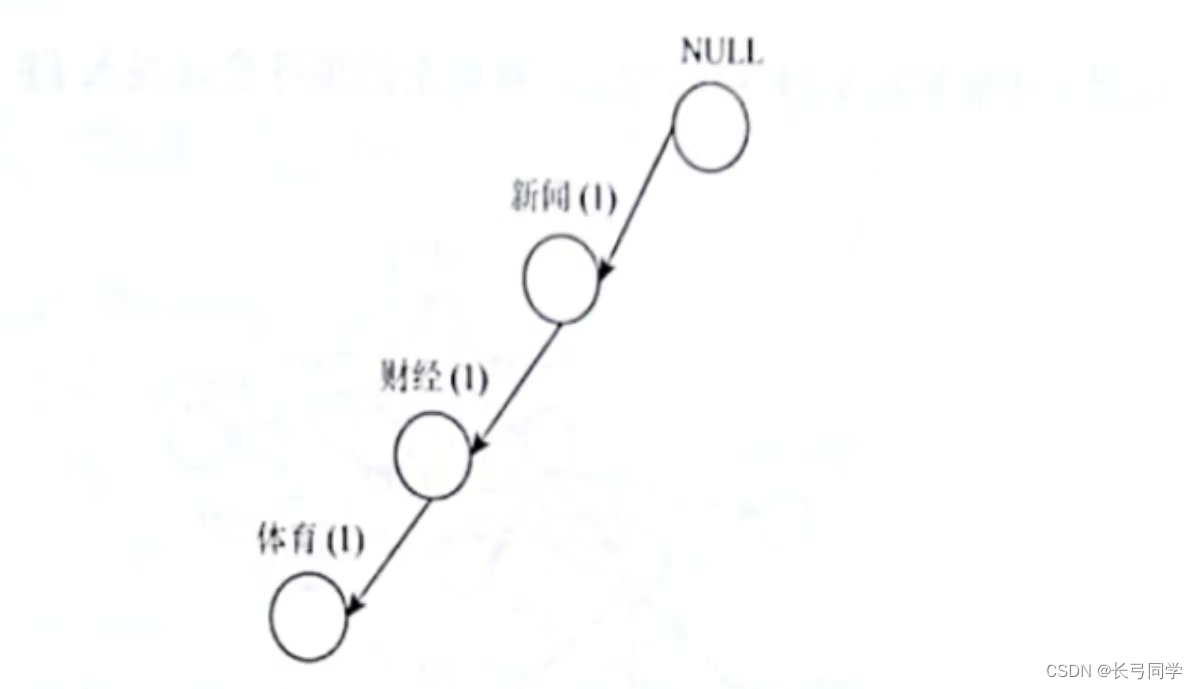
2. Programmer la transaction 2 dans l'arborescence FP
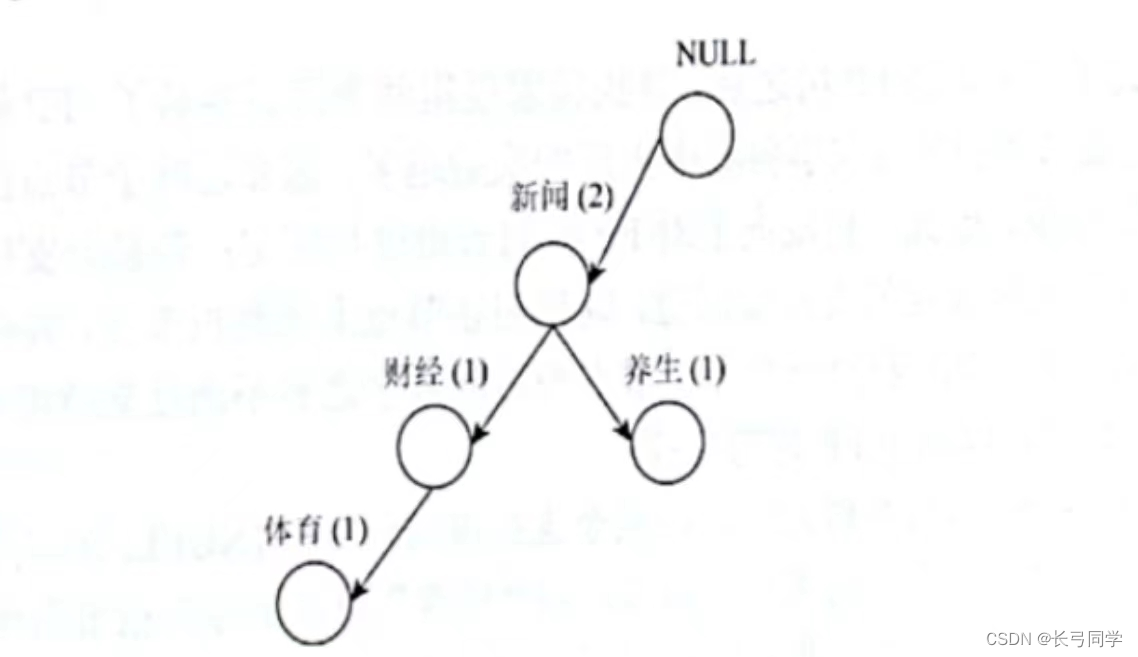
3. Mettez la transaction 3 dans l'arborescence FP, car la transaction 3 a une relation financière avec la transaction 1, alors connectez-les avec une ligne pointillée

4. Compilez les transactions restantes dans l'arborescence FP conformément aux règles ci-dessus, comme indiqué dans la figure suivante :

L'arbre FP du jeu de transactions est compilé
(2) Trouver des ensembles d'éléments fréquents
Pour tout chemin dans l'arbre FP, plus il est proche du nœud racine, plus il apparaît dans l'ensemble de transactions, et plus il est proche du nœud feuille, moins il apparaît dans l'ensemble de transactions.
Par conséquent, les nœuds de l'arbre FP sont jugés de bas en haut : si le nombre à côté d'un nœud dans une branche atteint le seuil défini, cela signifie que le nœud remonte au nœud racine, et les ensembles d'éléments composés de n'importe quel nœud dans ce sont des éléments fréquents.
Dans l'arbre FP formé ci-dessus, sous un certain seuil de support, on peut trouver des itemsets fréquents : {news, finance}, {sports, finance}, {news, sports}, {news, finance, sports}.
6. implémentation de code python
(code d'analyse d'association a priori)
from pandas as pd
from mlxtend.preprocessing import TranscactionEncoder
from mlxtend.frequent_patterns import apriori
from mlxtend.frequent_patterns import association_rules
# 对数据集X进行编码,X为一个列表,表示整个事务合集:X列表中每个元素也是一个列表,表示每一个项集。
# 这里将数据集编码为二元形式
Encode_X=TranscactionEncoder.fit_transform(X)
X_df=pd.DataFrame(Encode_X)
# 对编码后的事务集X_df使用apriori算法生成频繁项集,support参数设置支持度阈值
frequent_itemsets=apriori(X_df,min_support=0.6)
# 从生成的频繁项集中寻找关联规则,min_threshold为置信度阈值
ass_rule=association_rules(frequent_itemsets,min_threshold=0.7)