En tant que cadre important pour les entrepôts de données dans le Big Data, Hive s'est amélioré en vitesse du moteur MR lent à Tez, en passant par Spark d'aujourd'hui. Bien qu'un SQL Hive soit converti en plusieurs travaux de Spark et combien d'étapes seront générées, nous ne sommes pas encore en mesure de juger : "Mais combien de tâches y aura-t-il après que Spark aura lu la table Hive ?"
On sait que "le nombre de tâches dans Spark est déterminé par les partitions" , alors comment décider ?
-
Lorsque Hive lit des fichiers non découpables, toutes les données ne peuvent être lues que par un seul nœud, même si vous définissez vous-même manuellement les partitions
-
Si les fichiers de chaque partition de la table Hive sont de petits fichiers de plusieurs mégaoctets qui peuvent être découpés en tranches, alors lors de la lecture d'étincelle, chaque tâche ne traite que ces petits fichiers, ce qui non seulement gaspille des ressources mais aussi une perte de temps.
Puis on lance l'analyse à partir du code source du fichier lu par spark :
//简单写个读取文件的语句
val words: RDD[String] = sc.textFile("xxxx",3)
Nous entrons à partir de la méthode textfile(),
def textFile(
path: String,
//注意看这里的最小分区,如果textfile()方法中传了分区参数的话就会以传入的为准,否则就会使用默认值
//def defaultMinPartitions: Int = math.min(defaultParallelism, 2)
//我们通过源码发现,defaultMinPartitions 是默认并行度和2的最小值,而默认并行度=自己的cpu核数,所以分区最小值一般等于2
minPartitions: Int = defaultMinPartitions): RDD[String] = withScope {
assertNotStopped()
hadoopFile(path, classOf[TextInputFormat], classOf[LongWritable], classOf[Text],
//把上面的minPartitions传到这个hadoopFile()方法中。
minPartitions).map(pair => pair._2.toString).setName(path)
}
Nous entrons donc à partir de hadoopFile()

On constate que le HadoopRDD sera appelé pour lire le fichier, et celui ici inputFormatClassest spécifié lors de la création de Hive. Il n'est pas spécifié par défaut org.apache.hadoop.mapred.TextInputFormat. En même temps, faites attention au paramètre ici minPartitions, qui est la valeur passée par la méthode que nous venons de décrire. Cette fois, allez-y et entrez depuis HadoopRDD et récupérez minPartitions pour voir quelle méthode utilise ce paramètre. Après recherche, j'ai trouvé la méthode suivante
//getSplits()获取切片数
val allInputSplits = getInputFormat(jobConf).getSplits(jobConf, minPartitions)
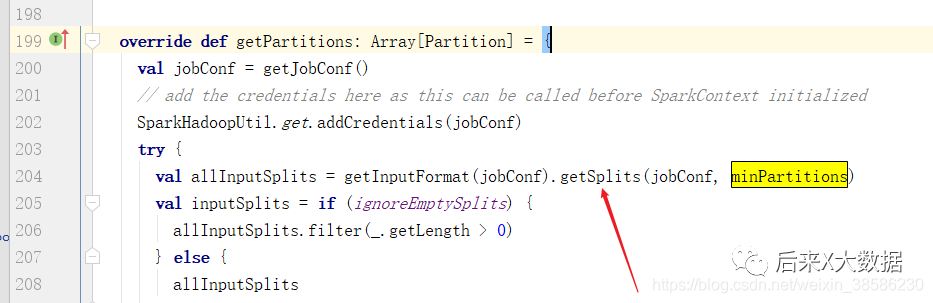
Continuez ensuite à entrer à partir de la méthode getSplits, puis recherchez la classe d'implémentation via Ctrl + h, ici nous sélectionnons FileInputFormat et continuons à récupérer getSplits, puis trouvons la méthode suivante, examinons son code source :
public InputSplit[] getSplits(JobConf job, int numSplits)
throws IOException {
Stopwatch sw = new Stopwatch().start();
FileStatus[] files = listStatus(job);
// Save the number of input files for metrics/loadgen
job.setLong(NUM_INPUT_FILES, files.length);
long totalSize = 0; // compute total size
for (FileStatus file: files) { // check we have valid files
if (file.isDirectory()) {
throw new IOException("Not a file: "+ file.getPath());
}
totalSize += file.getLen();
}
//注意看这里,文件的总大小,直接除以之前获取到切片数,为2
long goalSize = totalSize / (numSplits == 0 ? 1 : numSplits);
long minSize = Math.max(job.getLong(org.apache.hadoop.mapreduce.lib.input.
FileInputFormat.SPLIT_MINSIZE, 1), minSplitSize);
//而上面的minSplitSize通过看源码发现private long minSplitSize = 1;
//从这里得到的minSize 也等于1
// generate splits
ArrayList<FileSplit> splits = new ArrayList<FileSplit>(numSplits);
NetworkTopology clusterMap = new NetworkTopology();
files是上面扫描的分区目录下的part-*****文件
for (FileStatus file: files) {
Path path = file.getPath();
long length = file.getLen();
if (length != 0) {
FileSystem fs = path.getFileSystem(job);
BlockLocation[] blkLocations;
if (file instanceof LocatedFileStatus) {
blkLocations = ((LocatedFileStatus) file).getBlockLocations();
} else {
blkLocations = fs.getFileBlockLocations(file, 0, length);
}
//判断文件是否可切割
if (isSplitable(fs, path)) {
// 这里获取的不是文件本身的大小,它的大小从上面的length就可以知道,这里获取的是HDFS文件块(跟文件本身没有关系)的大小
// HDFS文件块的大小由两个参数决定,分别是 dfs.block.size 和 fs.local.block.size
// 在HDFS集群模式下,由 dfs.block.size 决定,对于Hadoop2.0来说,默认值是128MB
// 在HDFS的local模式下,由 fs.local.block.size 决定,默认值是32MB
long blockSize = file.getBlockSize();// 128MB
// 这里计算splitSize,goalSize是textfile()方法中指定路径下的文件总大小,minSize为1
long splitSize = computeSplitSize(goalSize, minSize, blockSize);
//而这里computeSplitSize = Math.max(minSize, Math.min(goalSize, blockSize))
//所以如果文件大小>128M,那么splitSize 就等于128M,否则就等于文件大小
long bytesRemaining = length;
// 如果文件大小大于splitSize,就按照splitSize对它进行分块
// 由此可以看出,这里是为了并行化更好,所以按照splitSize会对文件分的更细,因而split会更多
//SPLIT_SLOP 为1.1,也就是说,如果文件大小是切片大小的1.1倍以下时,也会分到一个切片,而不会分为2个
while (((double) bytesRemaining)/splitSize > SPLIT_SLOP) {
String[][] splitHosts = getSplitHostsAndCachedHosts(blkLocations,
length-bytesRemaining, splitSize, clusterMap);
splits.add(makeSplit(path, length-bytesRemaining, splitSize,
splitHosts[0], splitHosts[1]));
bytesRemaining -= splitSize;
}
//而当切到最后一个切片<1.1倍时,就会再追加一个切片。
//举个例子,假如文件大小为160M,因为160/128>1.1,所以切了一个之后,还剩32M
//32M/128<1.1,但是32M != 0 ,所以就会为这32M生成一个切片。
if (bytesRemaining != 0) {
String[][] splitHosts = getSplitHostsAndCachedHosts(blkLocations, length
- bytesRemaining, bytesRemaining, clusterMap);
splits.add(makeSplit(path, length - bytesRemaining, bytesRemaining,
splitHosts[0], splitHosts[1]));
}
} else {
//这里指的是文件不可分割
String[][] splitHosts = getSplitHostsAndCachedHosts(blkLocations,0,length,clusterMap);
//在这里就makeSplit = new FileSplit(file, start, length, hosts);
//所以就是1个分区直接读取,所以假如这个文件的大小是500G不可分割的文件,
//那么只能是一个节点去读,只能用Spark的一个Task,容易数据倾斜。
splits.add(makeSplit(path, 0, length, splitHosts[0], splitHosts[1]));
}
} else {
//Create empty hosts array for zero length files
splits.add(makeSplit(path, 0, length, new String[0]));
}
}
sw.stop();
if (LOG.isDebugEnabled()) {
LOG.debug("Total # of splits generated by getSplits: " + splits.size()
+ ", TimeTaken: " + sw.elapsedMillis());
}
return splits.toArray(new FileSplit[splits.size()]);
}
Donc, s'il y a 200 petits fichiers sous la partition de table Hive et que la taille est de 5 Mo, alors chaque petit fichier est une division, ce qui correspond à une partition Spark, donc quand il y a plusieurs petites partitions de fichiers, le nombre de tâches Spark Il sera également augmenter en ligne droite, et le nombre de partitions auto-spécifié ne résout pas le problème pour les petits fichiers, il est donc impossible de changer la situation de lecture d'un grand nombre de tâches dans la table Hive.
S'il s'agit d'un fichier indivisible d'une taille de 500 Go (un fichier indivisible bien supérieur à la taille de bloc de 128 Mo), il ne peut être lu que par un seul nœud et une seule tâche de Spark peut être utilisée, ce qui permet de fausser facilement les données.
Alors revenons à la question du début ? Comment optimiser ces deux scénarios :
-
Selon le scénario commercial réel, le volume de données de l'entreprise est relativement important et il y aura plusieurs gigaoctets de données chaque jour. N'utilisez donc pas de méthodes de compression indivisibles lors du stockage à nouveau, vous pouvez utiliser Lzo ou bzip2.
-
Lorsque plusieurs petits fichiers sont générés, il est nécessaire de penser à la source des petits fichiers, c'est-à-dire si la méthode de partitionnement de la table Hive actuelle est raisonnable. La configuration progressive des fichiers journaux vers Hive est-elle raisonnable ? La dernière chose est de fusionner de petits fichiers.
Enfin, j'ai mis le processus de traçabilité du code source sur une image pour que tout le monde puisse le voir.
