avant-propos
Dans Redis, il existe un type de données. Lors du stockage, deux structures de données sont utilisées pour les stocker séparément. Alors, pourquoi Redis fait-il cela ? Cela fera-t-il que les mêmes données occuperont deux fois plus d'espace ?
Cinq types de base d'objets de collection
Un objet de collection dans Redis est une collection non ordonnée contenant des éléments de type chaîne, et les éléments de la collection sont uniques et non répétables.
Il existe deux structures de données sous-jacentes pour les objets de collection : intset et hashtable. En interne, le codage est utilisé pour distinguer :

encodage intset
intset (ensemble d'entiers) peut contenir des valeurs entières de type int16_t, int32_t, int64_t, et il est garanti qu'il n'y a pas d'éléments en double dans l'ensemble.
La structure de données intset est définie comme suit (dans le code source inset.h) :
typedef struct intset {
uint32_t encoding;//编码方式
uint32_t length;//当前集合中的元素数量
int8_t contents[];//集合中具体的元素
} intset;
复制代码La figure suivante est un schéma simplifié du stockage de l'objet collection d'un intset :

codage
L'encodage à l'intérieur d'intset enregistre le type de stockage de données de l'ensemble d'entiers actuel, il existe trois types principaux :
- INTSET_ENC_INT16
À l'heure actuelle, chaque élément de contents[] est une valeur entière de type int16_t, la plage est : -32768 ~ 32767 (-2 à la puissance 15 ~ 2 à la puissance 15 - 1).
- INTSET_ENC_INT32
À l'heure actuelle, chaque élément de contents[] est une valeur entière de type int32_t, la plage est : -2147483648 ~ 2147483647 (-2 à la puissance 31 ~ 2 à la puissance 31 - 1).
- INTSET_ENC_INT64
À ce stade, chaque élément de contents[] est une valeur entière de type int64_t, et la plage est : -9223372036854775808 ~ 9223372036854775807 (-2 à la puissance 63 ~ 2 à la puissance 63 - 1).
Contenu[]
contents[] Bien que la définition de la structure soit écrite en tant que type int8_t, le type de stockage réel est déterminé par l'encodage ci-dessus.
Mise à niveau de la collection d'entiers
Si les éléments de l'ensemble d'entiers sont tous de 16 bits au début et sont stockés dans le type int16_t, alors un autre entier de 32 bits doit être stocké, puis l'ensemble d'entiers d'origine doit être mis à jour et l'entier de 32 bits peut être stocké après la mise à niveau Stocké dans une collection d'entiers. Cela implique la mise à niveau du type de l'ensemble d'entiers. Le processus de mise à niveau comporte principalement 4 étapes :
- Développez la taille de l'espace de tableau sous-jacent en fonction du type de l'élément nouvellement ajouté et allouez le nouvel espace en fonction du nombre de bits des éléments existants après la mise à niveau.
- Convertissez les éléments existants et remettez les éléments convertis dans le tableau un par un de l'arrière vers l'avant.
- Placez le nouvel élément en tête ou en queue du tableau (car la condition pour déclencher la mise à niveau est que le type entier du tableau actuel ne peut pas stocker le nouvel élément, donc le nouvel élément est soit plus grand soit plus petit que l'élément existant).
- Modifiez la propriété d'encodage au dernier encodage et modifiez la propriété de longueur de manière synchrone.
PS : Comme pour l'encodage des objets de chaîne, une fois le type de la collection d'entiers mis à niveau, l'encodage restera et ne pourra pas être rétrogradé.
Exemple de mise à niveau
1. Supposons que nous ayons un stockage de collection dont l'encodage est int16_t, et stocke en interne 3 éléments :

2. A ce moment, un entier 50000 doit être inséré, et on constate qu'il ne peut pas être stocké, et 50000 est un entier de type int32_t, il est donc nécessaire de demander un nouvel espace, et la taille de l'application l'espace est 4 * 32 - 48=80.

3. Maintenant, il y a 4 éléments à placer dans le nouveau tableau, et le tableau d'origine est classé 3e, il est donc nécessaire de déplacer les 3 mis à niveau vers les bits 64-95.

4. Allez-y et déplacez le 2 mis à niveau vers 32-63 bits.

5. Continuez à déplacer le 1 mis à niveau vers les bits 0-31.

6. Le 50000 sera alors placé dans les bits 96-127.

7. Enfin, les attributs d'encodage et de longueur seront modifiés et la mise à niveau sera terminée après modification.
encodage de table de hachage
La structure de la table de hachage a été analysée en détail dans la description précédente de l'objet de hachage, si vous voulez en savoir plus, vous pouvez cliquer ici.
conversion d'encodage intset et table de hachage
Redis choisira d'utiliser l'encodage intset lorsqu'une collection remplit les deux conditions suivantes :
- Tous les éléments détenus par un objet de collection sont des valeurs entières.
- Le nombre d'éléments stockés dans l'objet collection est inférieur ou égal à 512 (ce seuil peut être contrôlé par le fichier de configuration set-max-intset-entries).
Une fois que les éléments de la collection ne remplissent pas les deux conditions ci-dessus, l'encodage de la table de hachage sera sélectionné.
Commandes courantes pour les objets de collection
- sadd key member1 member2 : ajoute un ou plusieurs éléments member à la clé set, et renvoie le nombre d'ajouts réussis. Si l'élément existe déjà, il sera ignoré.
- membre de clé sismember : détermine si le membre d'élément existe dans la clé d'ensemble.
- clé srem membre1 membre2 : supprimez les éléments de la clé définie et les éléments inexistants seront ignorés.
- smove source dest member : déplacez le membre de l'élément de la source de la collection vers dest, ou ne faites rien si le membre n'existe pas.
- clé smembers : renvoie tous les éléments de la clé définie.
Connaissant les commandes courantes pour manipuler les objets de collection, nous pouvons vérifier le type et l'encodage de l'objet de hachage mentionné ci-dessus. Avant de tester, afin d'éviter l'interférence d'autres valeurs de clé, nous exécutons d'abord la commande flushall pour effacer la base de données Redis.
Exécutez les commandes suivantes dans l'ordre :
sadd num 1 2 3 //设置 3 个整数的集合,会使用 intset 编码
type num //查看类型
object encoding num //查看编码
sadd name 1 2 3 test //设置 3 个整数和 1 个字符串的集合,会使用 hashtable 编码
type name //查看类型
object encoding name //查看编码
复制代码Obtenez l'effet suivant :

On peut voir que lorsqu'il n'y a que des entiers dans les éléments de l'ensemble, l'ensemble utilise l'encodage intset, et lorsque les éléments de l'ensemble contiennent des non-entiers, l'encodage de la table de hachage est utilisé.
Cinq types de base d'objets de collection ordonnés
La différence entre un ensemble ordonné et un ensemble dans Redis est que chaque élément de l'ensemble ordonné est associé à un score de type double, puis trié par ordre croissant du score. En d'autres termes, l'ordre de l'ensemble trié est déterminé par la fraction lorsque nous définissons nous-mêmes la valeur.
Il existe deux structures de données sous-jacentes pour les objets d'ensemble triés : skiplist et ziplist. En interne, il se distingue également par l'encodage :

encodage de la liste de sauts
skiplist est la liste de sauts, parfois appelée simplement liste de sauts. L'objet d'ensemble ordonné codé avec skiplist utilise la structure zset comme implémentation sous-jacente, et le zset contient à la fois un dictionnaire et une liste de sauts.
table de saut
La table de saut est une structure de données ordonnée, et sa principale caractéristique est d'atteindre l'objectif d'accéder rapidement aux nœuds en maintenant plusieurs pointeurs vers d'autres nœuds dans chaque nœud.
Dans la plupart des cas, l'efficacité de la table de saut peut être égale à celle de l'arbre équilibré, mais l'implémentation de la table de saut est beaucoup plus simple que l'implémentation de l'arbre équilibré, donc Redis choisit d'utiliser la table de saut pour implémenter l'ordre Positionner.
La figure suivante est une liste chaînée ordonnée ordinaire. Si nous voulons trouver l'élément 35, nous ne pouvons parcourir que du début à la fin (les éléments de la liste chaînée ne prennent pas en charge l'accès aléatoire, la recherche binaire ne peut donc pas être utilisée, et le tableau est accessible de manière aléatoire via des indices), donc la recherche binaire est généralement applicable aux tableaux triés), et la complexité temporelle est O(n).

Ensuite, si nous pouvons sauter directement au milieu de la liste chaînée, nous pouvons économiser beaucoup de ressources. C'est le principe de la liste de sauts. Comme le montre la figure suivante, il s'agit d'un exemple de la structure de données de la liste de sauts. :
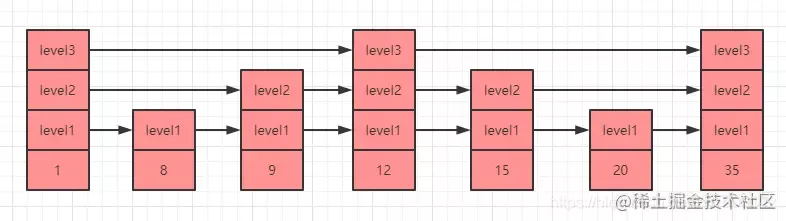
Dans la figure ci-dessus, niveau1, niveau2 et niveau3 sont les niveaux de la liste de sauts. Chaque niveau a un pointeur vers l'élément suivant du même niveau. Par exemple, lorsque nous parcourons pour trouver l'élément 35 dans la figure ci-dessus, il y a trois choix :
- La première consiste à exécuter le pointeur du niveau level1, qu'il faut parcourir 7 fois (1->8->9->12->15->20->35) pour trouver l'élément 35.
- La seconde consiste à exécuter le pointeur de niveau level2 et à parcourir 5 fois (1-> 9-> 12-> 15-> 35) pour trouver l'élément 35.
- Le troisième type consiste à exécuter les éléments du niveau niveau 3. A ce moment, il suffit de parcourir 3 fois (1->12->35) pour trouver l'élément 35, ce qui améliore grandement l'efficacité.
Structure de stockage de la liste de sauts
Chaque nœud de la liste de sauts est un nœud zskiplistNode (dans le code source server.h) :
typedef struct zskiplistNode {
sds ele;//元素
double score;//分值
struct zskiplistNode *backward;//后退指针
struct zskiplistLevel {//层
struct zskiplistNode *forward;//前进指针
unsigned long span;//当前节点到下一个节点的跨度(跨越的节点数)
} level[];
} zskiplistNode;
复制代码- niveau
level est le niveau dans la table de saut, qui est un tableau, ce qui signifie qu'un élément d'un nœud peut avoir plusieurs niveaux, c'est-à-dire plusieurs pointeurs vers d'autres nœuds, et le programme peut choisir le chemin le plus rapide pour améliorer l'accès via des pointeurs à différents niveaux de vitesse.
level est un nombre compris entre 1 et 32 qui est généré aléatoirement selon la loi de puissance à chaque fois qu'un nouveau nœud est créé.
- vers l'avant (pointeur vers l'avant)
Chaque couche aura un pointeur vers l'élément à la fin de la liste liée, et le pointeur vers l'avant doit être utilisé lors de la traversée de l'élément.
- portée
Le span enregistre la distance entre deux nœuds. Il convient de noter que s'il pointe vers NULL, le span vaut 0.
- vers l'arrière (pointeur vers l'arrière)
Contrairement au pointeur vers l'avant, il n'y a qu'un seul pointeur vers l'arrière, vous ne pouvez donc revenir qu'au nœud précédent à chaque fois (le pointeur vers l'arrière n'est pas dessiné dans la figure ci-dessus).
- élé (élément)
L'élément dans la table de saut est un objet sds (la version précédente utilisait l'objet redisObject), et l'élément doit être unique et ne peut pas être répété.
- score
Le score du nœud est un nombre à virgule flottante de type double. Dans la table de saut, les nœuds sont classés par ordre croissant en fonction de leurs scores. Les scores des différents nœuds peuvent être répétés.
La description ci-dessus n'est qu'un nœud dans la liste de sauts, et plusieurs nœuds zskiplistNode forment un objet zskiplist :
typedef struct zskiplist {
struct zskiplistNode *header, *tail;//跳跃表的头节点和尾结点指针
unsigned long length;//跳跃表的节点数
int level;//所有节点中最大的层数
} zskiplist;
复制代码À ce stade, vous pouvez penser que l'ensemble ordonné est implémenté avec cette zskiplist, mais en fait, Redis n'utilise pas directement la zskiplist pour l'implémenter, mais utilise l'objet zset pour l'encapsuler à nouveau.
typedef struct zset {
dict *dict;//字典对象
zskiplist *zsl;//跳跃表对象
} zset;
复制代码Ainsi, au final, si un ensemble ordonné utilise un encodage de liste de sauts, sa structure de données est illustrée dans la figure suivante :
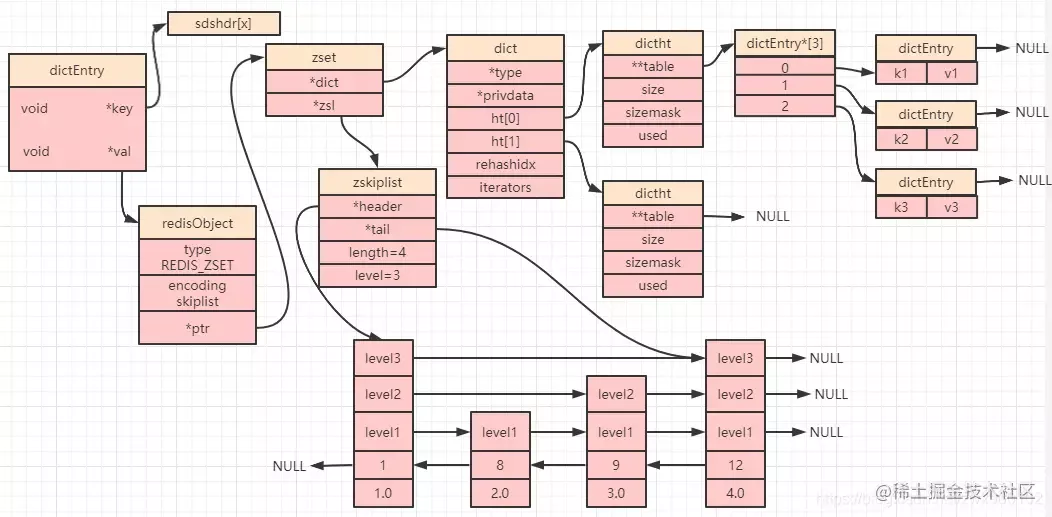
La clé du dictionnaire dans la partie supérieure de la figure ci-dessus correspond à l'élément de l'ensemble ordonné (membre) et la valeur correspond au score (score). Dans la partie inférieure de la figure ci-dessus, les entiers de la table de saut 1, 8, 9 et 12 correspondent également à l'élément (membre), et le nombre de type double dans la dernière ligne est le score (score).
C'est-à-dire que les données du dictionnaire et de la table de sauts pointent toutes deux vers les éléments que nous stockons (les deux structures de données pointent finalement vers la même adresse, donc les données ne seront pas stockées de manière redondante).Pourquoi Redis fait-il cela ?
Pourquoi choisir d'utiliser à la fois un dictionnaire et une table de saut
Les ensembles triés peuvent être implémentés en utilisant directement le tableau de saut ou en utilisant le dictionnaire seul, mais réfléchissons-y, si nous utilisons le tableau de saut seul, alors bien que nous puissions utiliser un pointeur avec une grande étendue pour parcourir les éléments pour trouver les données dont nous avons besoin, c'est compliqué. Le degré atteint toujours O(logN), et la complexité d'obtention d'un élément dans un dictionnaire est O(1). Si vous utilisez un dictionnaire seul pour obtenir des éléments, c'est très rapide, mais le dictionnaire n'est pas ordonné, donc si vous voulez trouver une plage, vous devez trier est une opération qui prend du temps, donc Redis combine deux structures de données pour maximiser les performances, ce qui est aussi la subtilité de la conception Redis.
encodage de la liste zip
Les listes compressées sont utilisées à la fois dans les objets de liste et les objets de hachage. Pour plus de détails, cliquez ici.
blog.csdn.net/zwx900102/a…
conversion d'encodage ziplist et skiplist
Lorsqu'un objet d'ensemble ordonné remplit les deux conditions suivantes, il utilise l'encodage ziplist pour le stockage :
- Le nombre d'éléments stockés dans l'objet ensemble trié est inférieur à 128 (peut être modifié en configurant zset-max-ziplist-entries).
- La longueur totale de tous les éléments stockés dans l'objet ensemble trié est inférieure à 64 octets (peut être modifiée en configurant zset-max-ziplist-value).
Commandes courantes de l'objet collection ordonnée
- zadd clé score1 membre1 score2 membre2 : ajoutez un ou plusieurs éléments (membres) et leurs scores à la clé de l'ensemble trié.
- zscore key member : renvoie le score du membre membre dans la clé de l'ensemble trié.
- zincrby key num membre : ajoutez num au membre dans la clé de l'ensemble trié, et num peut être un nombre négatif.
- zcount key min max : renvoie le nombre de membres dont la valeur de score se situe dans l'intervalle [min,max] dans la clé de l'ensemble trié.
- zrange key start stop : renvoie tous les membres dans l'intervalle [start, stop] après que le score dans la clé d'ensemble trié est organisé de petit à grand.
- zrevrange key start stop : renvoie tous les membres dans l'intervalle [start, stop] une fois que les scores de la clé d'ensemble triée sont classés de grand à petit.
- clé zrangebyscore min max : renvoie tous les éléments dans l'intervalle [min,max] dans l'ensemble trié trié par score de petit à grand. Notez que la valeur par défaut est un intervalle fermé, mais vous pouvez ajouter ( ou [ avant les valeurs de max et min pour contrôler l'intervalle ouvert et fermé.
- zrevrangebyscore clé max min : Renvoie tous les éléments dans l'intervalle [min,max] dans l'ensemble trié trié par score de grand à petit. Notez que la valeur par défaut est un intervalle fermé, mais vous pouvez ajouter ( ou [ avant les valeurs de max et min pour contrôler l'intervalle ouvert et fermé.
- zrank key member : renvoie le rang (de petit à grand) des éléments dans member dans l'ensemble trié, et le résultat renvoyé commence à 0.
- Membre clé zrevrank : renvoie le classement des éléments du membre dans l'ensemble trié (de grand à petit) et le résultat renvoyé commence à 0.
- Clé zlexcount min max : renvoie le nombre de membres entre min et max dans l'ensemble trié. Notez que min et max dans cette commande doivent être précédés de ( ou [ pour contrôler l'intervalle ouvert et fermé, et les valeurs spéciales - et + représentent respectivement l'infini négatif et l'infini positif.
Connaissant les commandes courantes pour faire fonctionner les objets d'ensemble ordonnés, nous pouvons vérifier le type et l'encodage de l'objet de hachage mentionné ci-dessus. Avant de tester, afin d'éviter l'interférence d'autres valeurs de clé, nous exécutons d'abord la commande flushall pour effacer la base de données Redis.
Avant d'exécuter la commande, nous modifions d'abord le paramètre zset-max-ziplist-entries dans le fichier de configuration à 2, puis redémarrons le service Redis.
Une fois le redémarrage terminé, exécutez les commandes suivantes dans l'ordre :
zadd name 1 zs 2 lisi //设置 2 个元素会使用 ziplist
type name //查看类型
object encoding name //查看编码
zadd address 1 beijing 2 shanghai 3 guangzhou 4 shenzhen //设置4个元素则会使用 skiplist编码
type address //查看类型
object encoding address //查看编码
复制代码Obtenez l'effet suivant :

Résumer
Cet article analyse principalement les principes d'implémentation des structures de stockage sous-jacentes intset et skiplist d'objets d'ensemble et d'objets d'ensemble ordonnés, et se concentre sur la façon dont les ensembles triés implémentent le tri et pourquoi deux structures de données (dictionnaire et liste de sauts) sont utilisées pour le stockage simultané. les données.
Auteur :
Compte officiel_IT Brother Lien : https://juejin.cn/post/7075575482669858824