iSCSI est une technologie importante dans les systèmes de stockage modernes au niveau de l'entreprise. Le serveur iSCSI open source tgt a un problème de performances à un seul thread, et les correctifs d'optimisation associés ont des effets inégaux et n'ont pas vraiment résolu le problème. Cet article présente comment le NetEase Shufan L'équipe de stockage a adopté une série de L'innovation unique permet une amélioration significative des performances tgt et l'utilise pour la courbe de stockage défini par logiciel natif cloud open source, permettant au système de périphérique de bloc Curve de maintenir des performances élevées dans différents environnements de système d'exploitation.
Contexte
1. Courbe BS
Curve (github.com/opencurve/curve) est un système de stockage distribué cloud natif open source de NetEase Shufan, comprenant le système de périphérique bloc CurveBS et le système de fichiers CurveFS. Parmi eux, CurveBS entreprend un grand nombre de tâches, telles que servir de disque cloud pour les machines virtuelles KVM et K8s PV, qui est l'infrastructure de la plate-forme cloud. CurveBS peut également être utilisé par les utilisateurs dans d'autres scénarios commerciaux, tels que les systèmes de stockage SAN dans les entreprises peuvent être remplacés par CurveBS - car CurveBS utilise la cohérence des répliques Raft et les concepts CopySet pour réparer automatiquement les répliques endommagées, à la fois en termes de fiabilité et de stabilité , ces fonctionnalités sont suffisants pour remplacer le SAN traditionnel, et même surpasser le SAN traditionnel en termes d'évolutivité et de performances en termes de coût.
2. iSCSI
En ce qui concerne les périphériques de stockage traditionnels tels que SAN, nous devons mentionner SCSI. En tant que protocole de connexion et de transmission pour les périphériques de bloc externes, SCSI est le protocole de périphérique de bloc le plus étendu. Il a été proposé pour la première fois en 1979 et est une technologie d'interface développée pour Il est maintenant totalement omniprésent sur les mini-ordinateurs, les serveurs et les PC ordinaires. Afin de pouvoir transmettre des blocs de données via TCP/IP, Cisco et IBM ont lancé le protocole iSCSI, qui a été fortement soutenu par les principaux fabricants de stockage. iSCSI peut réaliser la transmission du protocole SCSI sur un réseau IP, permettant un accès rapide aux données et des opérations de sauvegarde telles que l'Ethernet haut débit. La norme iSCSI a été certifiée par l'IETF (Internet Engineering Task Force) le 11 février 2003. iSCSI hérite des deux technologies les plus traditionnelles : SCSI et protocole TCP/IP. Cela a jeté des bases solides pour le développement d'iSCSI. Les systèmes de stockage basés sur iSCSI peuvent implémenter des fonctions de stockage SAN avec peu d'investissement, et même utiliser directement les réseaux TCP/IP existants. Surtout pour les systèmes non Linux tels que les systèmes Windows, si vous souhaitez utiliser CurveBS comme disque dur Windows, laissez simplement CurveBS prendre en charge le protocole iSCSI.
3. Quel est l'objectif
Pour prendre en charge iSCSI, vous devez disposer d'un logiciel de serveur iSCSI. tgt (cadre cible Linux) est un serveur iSCSI open source. Pour plus de détails, veuillez consulter : https://github.com/opencurve/curve-tgt/blob/master/ LISEZMOI .
Par rapport à d'autres logiciels de serveur iSCSI open source dans l'industrie, nous avons constaté que tgt est la solution la plus appropriée, car il s'agit d'un mode utilisateur pur, ne dépend pas du noyau du système d'exploitation, n'a pas besoin d'écrire différents codes pour différentes versions du noyau, et permet le travail de développement devient beaucoup plus simple.
Lorsque nous avons développé le serveur de périphériques de bloc Curve, nous voulions que plus de systèmes utilisent des périphériques de bloc CurveBS, pas seulement des systèmes Linux, nous avons donc modifié tgt pour permettre à CurveBS de fournir des services iSCSI, pour lesquels nous avons ajouté des pilotes CurveBS natifs pour tgt, lire et écrire CurveBS directement via l'interface curvebs partie 1, en contournant la couche de périphérique de bloc du noyau, en économisant les ressources système et en appelant la couche de périphérique de bloc du noyau.
4. Problèmes rencontrés lors de l'utilisation de tgt
Nous avons observé que le tgt vanilla utilisait un seul thread principal, la boucle d'événements epoll, pour traiter les commandes iSCSI, et incluait également le socket domian unix du plan de gestion dans ce thread principal. Sur un réseau 10 Gbit/s ou même un réseau plus rapide, la vitesse de traitement des commandes iSCSI avec un seul thread (c'est-à-dire un seul processeur) ne peut plus suivre le besoin. Lorsqu'un thread traite plusieurs cibles, la vitesse de la requête de plusieurs initiateurs ISCSI Légèrement plus élevé et cette utilisation iSCSI à thread unique est occupée à 100 %. Par conséquent, l'optimisation de tgt a été mise à l'ordre du jour, et les pairs de l'industrie nationale ont longtemps déclaré que l'implémentation à un seul thread de tgt présentait des problèmes de performances, et les développeurs de sheepdog ont également mentionné comment l'optimiser. Après une recherche minutieuse et une détermination à réussir, nous avons soigneusement analysé l'architecture de tgt et trouvé un moyen de l'optimiser. Cette méthode est unique à l'équipe Curve et ne fait référence à aucun correctif externe, car nous estimons que ces correctifs ne résolvent pas vraiment le problème.
Stratégie d'optimisation NetEase Shufan
1. Utilisez plusieurs threads pour epoll
Les performances des processeurs modernes obéissent toujours à la loi de Moore, mais la voie d'implémentation de la loi de Moore a changé. La fréquence d'horloge d'un seul processeur n'est plus augmentée, mais remplacée par des cœurs de processeur plus physiques. À cette fin, nous devons implémenter plusieurs threads de boucle d'événement epoll, chacun étant responsable du traitement des commandes iscsi sur un certain nombre de connexions socket, afin que la capacité de traitement de plusieurs processeurs puisse être exercée.
2. Créez un fil epoll pour chaque cible
Plus précisément dans le processus de mise en œuvre, afin d'éviter le problème de dépassement de la capacité de traitement d'un seul processeur lorsque plusieurs cibles partagent un thread epoll, nous définissons un thread epoll pour chaque cible. L'utilisation du processeur du thread epoll cible est planifiée par le planificateur du système d'exploitation, de sorte qu'une utilisation équitable du processeur puisse être obtenue sur chaque cible. S'il y a suffisamment de processeurs, chaque cible peut avoir un processeur à servir, ce qui améliorera considérablement les performances. Bien sûr, si la vitesse du réseau est plus rapide et que les performances d'E/S du SSD sont meilleures, il y aura toujours un seul thread epoll qui ne pourra pas gérer une requête sur une cible iscsi, mais à l'heure actuelle, cette solution reste la meilleure solution que nous pouvons faire, car nous n'avons pas besoin d'introduire d'autres mécanismes supplémentaires de multithreading et de verrouillage.
3. Plan de gestion
Le plan de gestion maintient la compatibilité avec l'objectif d'origine. En termes d'utilisation de la ligne de commande, il n'y a aucune différence ni aucune modification, de sorte que la charge de travail du support humain est réduite et que les manuels et documents originaux sont des matériaux complets. Le plan de gestion fournit des services sur le thread principal du programme. Le thread principal est également un thread de boucle epoll, qui n'est pas différent du cible d'origine. Il est responsable de la gestion de cible, lun, connexion/déconnexion, découverte, session , connexion, etc... Lorsque l'initiateur se connecte au serveur ISCSI, il est toujours servi par le thread du plan de gestion en premier. Si la connexion doit finalement créer une session pour accéder à une cible, la connexion sera migrée vers le thread epoll de la cible correspondante.
4. Verrous sur les structures de données
Fournissez un mutex pour chaque cible. La structure de données dans la cible est protégée par ce verrou. Lorsque le thread epoll cible est en cours d'exécution, le verrou est verrouillé par le thread, de sorte que le thread peut mettre fin arbitrairement à une session ou à une connexion. Lorsque le thread entre dans epoll_wait, le verrou est libéré et le verrou est à nouveau verrouillé lorsque epoll_wait revient. Nous avons modifié le code pertinent afin que le thread epoll cible n'ait pas besoin de traverser la liste cible, mais accède uniquement à la structure liée à la cible qu'il dessert, de sorte que nous n'avons pas besoin du verrou de liste cible. Le plan de gestion modifiera également la structure des données dans la cible, déplacera une connexion de connexion, supprimera une session ou une connexion, qui doivent toutes verrouiller le verrou cible. Ainsi, le plan de gestion et le thread epoll cible utilisent ce mutex pour l'exclusion mutuelle, afin que la cible correspondante puisse être accessible en toute sécurité. Étant donné que le plan de gestion est monothread et que de nombreux threads epoll cibles ne traversent pas la liste cible, nous n'avons pas besoin de verrous de liste cible dans l'ensemble du système, et la seule chose que nous ajoutons est les verrous cibles.
5. la connexion établit une session
Lorsque login_finish réussit, login_finish crée parfois une session (si aucune session n'existe). login_finish définit la cible iscsi vers laquelle migrer dans le champ migrate_to de la structure de connexion.
6. La connexion est ajoutée à la session
Habituellement, une nouvelle connexion génère une nouvelle session, tout comme le login_finish mentionné ci-dessus. Mais il y a une situation, iSCSI autorise plusieurs connexions dans une session, donc la connexion est directement ajoutée à la session, ce qui est fait par login_security_done.
7. Quand effectuer la migration de connexion
Lorsque l'appel revient à iscsi_tcp_event_handler, étant donné que login_finish définit la cible migrate_to target, iscsi_tcp_event_handler verrouille la structure cible iscsi cible et insère le fd de la connexion dans la boucle d'événements de la cible cible pour terminer la migration.
8. Définir le nom du pthread
Définissez le nom du thread de chaque boucle d'événement cible en haut sur tgt/n, et n est l'identifiant cible, de sorte qu'il soit facile d'utiliser des outils tels que top pour observer quelle cible occupe le CPU.
9. Un exemple de mise en œuvre
Si le plan de gestion souhaite supprimer une cible, le code suivant illustre le processus :
/* called by mgmt */
tgtadm_err tgt_target_destroy(int lld_no, int tid, int force)
{
struct target *target;
struct acl_entry *acl, *tmp;
struct iqn_acl_entry *iqn_acl, *tmp1;
struct scsi_lu *lu;
tgtadm_err adm_err;
eprintf("target destroy\n");
/*
* 这里因为控制面是单线程的,而且SCSI IO线程不会删除target,
* 所以我们找target的时候并不需要锁
*/
target = target_lookup(tid);
if (!target)
return TGTADM_NO_TARGET;
/*
* 这里要锁住target,因为我们要删除数据结构,所以不能和iscsi io
* 线程一起共享,必须在target event loop线程释放了锁时进行
*/
target_lock(target);
if (!force && !list_empty(&target->it_nexus_list)) {
eprintf("target %d still has it nexus\n", tid);
target_unlock(target);
return TGTADM_TARGET_ACTIVE;
}
…
/* 以上步骤删除了所有资源 ,可以释放锁了 */
target_unlock(target);
if (target->evloop != main_evloop) {
/* 通知target上的evloop停止,并等待evloop 线程退出 */
tgt_event_stop(target->evloop);
if (target->ev_td != 0)
pthread_join(target->ev_td, NULL);
/* 下面把evloop的资源删除干净 */
work_timer_stop(target->evloop);
lld_fini_evloop(target->evloop);
tgt_destroy_evloop(target->evloop);
}
Effet d'optimisation
1. Comparaison des performances
Nous avons configuré 3 disques pour tgt, dont 1 volume CurveBS et 2 disques locaux
<target iqn.2019-04.com.example:curve.img01>
backing-store cbd:pool//iscsi_test_
bs-type curve
</target>
<target iqn.2019-04.com.example:local.img01>
backing-store /dev/sde
</target>
<target iqn.2019-04.com.example:local.img02>
backing-store /dev/sdc
</target>
Utilisez cette machine pour vous connecter iscsi iscsiadm --mode node --portal 127.0.0.1:3260 --login
Pour configurer un périphérique de bloc pour que fio accède à ces iscsi, utilisez
[global]
rw=randread
direct=1
iodepth=128
ioengine=aio
bsrange=16k-16k
runtime=60
group_reporting
[disk01]
filename=/dev/sdx
[disk02]
filename=/dev/sdy
size=10G
[disk03]
filename=/dev/sdz
size=10G
Les résultats des tests sont les suivants :
Le premier est le score de test fio non optimisé avec 38,8K IOPS.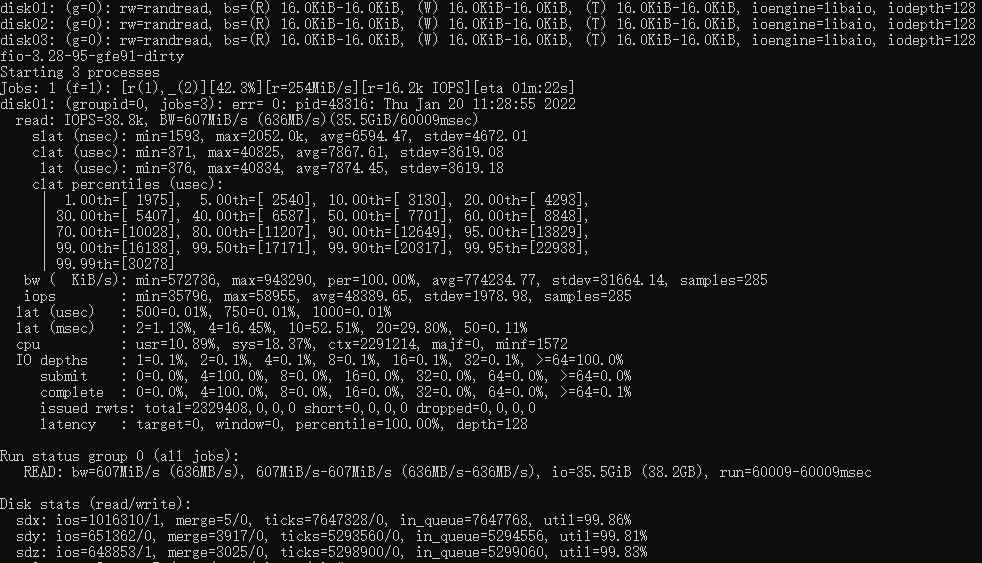
Suivi par le score de test fio optimisé multithread, l'IOPS a atteint 60,9K.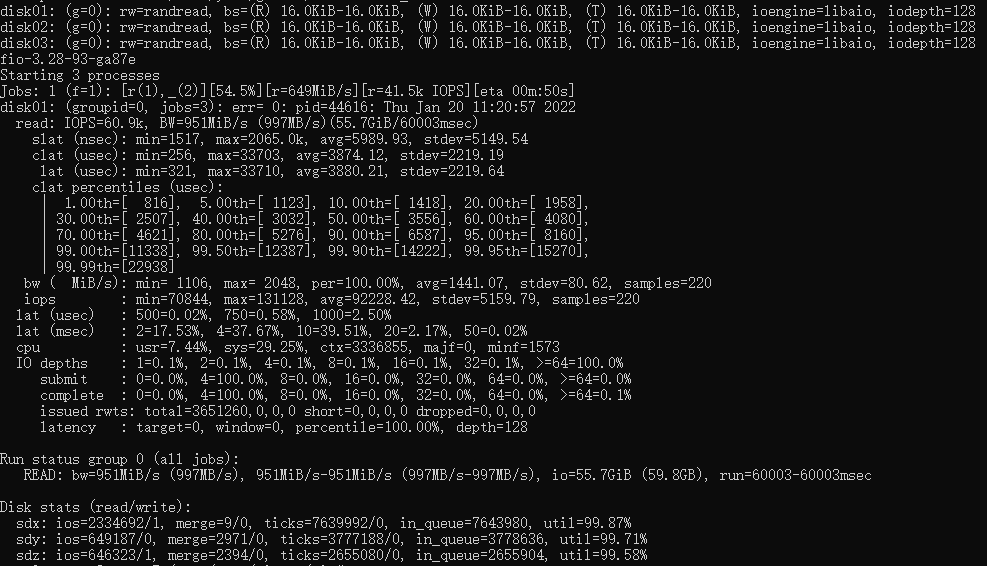
On peut voir que les performances de tgt ont été grandement améliorées.Avec l'augmentation de cible, nous n'avons plus à nous soucier du gaspillage du processeur dans le système.
2. Test Windows
Le système est préalablement testé sur Windows et fonctionne bien. Pour plus de détails sur la configuration d'un client iSCSI sous Windows, veuillez consulter : https://jingyan.baidu.com/article/e4511cf37feade2b845eaff8.html
Il convient de noter que lors de la configuration de l'authentification CHAP sous Windows, le mot de passe doit être défini sur 12 à 16 caractères, et il doit être le même que celui sur tgt. Si le chiffrement n'est pas défini dans cette longueur, d'étranges erreurs Windows iSCSI apparaîtront.
cible et courbe
Nous fournissons un pilote pour que tgt accède à CurveBS, voir doc/README.curve pour plus de détails, afin que les utilisateurs puissent utiliser le stockage de blocs CurveBS sur n'importe quel système d'exploitation prenant en charge iSCSI (par exemple Windows, Mac).
Ajout de la fonction de sensibilisation à l'extension de capacité à tgt, car le périphérique de bloc de CurveBS peut être étendu et le tgt d'origine ne peut déterminer la taille du périphérique de bloc que lors de la création d'un lun, et il ne peut pas être modifié par la suite. que la commande tgtadm peut informer le cible des informations d'extension de capacité. Le client iSCSI peut relire la taille du LUN pour terminer l'expansion. Pour plus de détails sur la façon de relire la taille du lun, voir doc/README.curve.
résumé
Cet article présente les problèmes rencontrés par l'équipe NetEase Shufan Curve dans l'utilisation de tgt, les méthodes d'optimisation uniques pour tgt et les résultats obtenus, et l'application de tgt dans CurveBS. Le service cible iser actuel appartient toujours au service thread principal. Compte tenu de la popularité de RDMA, cette partie du code n'a pas été modifiée. On s'attend à ce qu'avec la popularité de l'environnement RDMA, nous procédions à d'autres optimisations.
apprendre encore plus
- Page d'accueil du projet Curve : http://www.opencurve.io/
- documentation d'utilisation de tgt : https://github.com/opencurve/curveadm/wiki/others#deploy-tgt
- Les experts de NetEase Shufan interpréteront l'optimisation tgt et d'autres technologies liées à Curve lors de la réunion bihebdomadaire en ligne de la communauté Curve.Bienvenue pour scanner le code QR suivant sur WeChat pour rejoindre le groupe d'utilisateurs Curve pour voir l'heure/les sujets de la réunion bihebdomadaire Curve et plus de nouvelles.

L'auteur de cet article : Équipe NetEase Shufan Curve