En voyant mes amis copier et coller à plusieurs reprises le répertoire de la page Web au mot tous les jours, je me sens très imprudent. J'ai donc pensé à utiliser la fonction bureautique automatisée de Python pour le sauver! Par exemple, l'image suivante est le contenu en HTML. Je veux l'extraire et l'écrire en mot. Je dois également apporter le titre du livre et nommer le mot. Une fois écrit, vous pouvez traiter par lots! ! ! N’est-ce pas merveilleux? O ( ̄︶ ̄) o Heureusement, mon 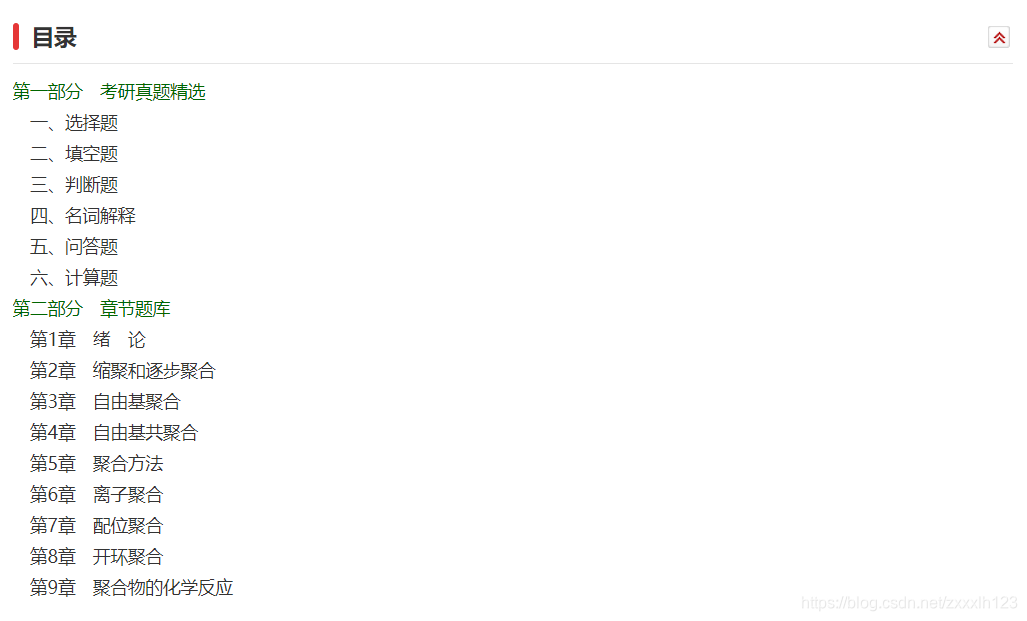
ami utilisera un outil sitemapX pour écrire le chemin cible de la page Web dans un fichier txt. 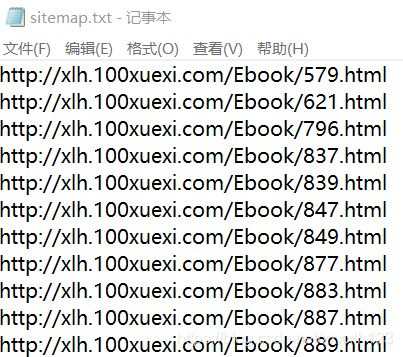
Bibliothèques appelées:
import time
import re
import urllib.request
import os
import pypandoc
from docx.oxml.ns import qn
from docx import Document
Il y a encore quelques points importants à prendre en compte dans ce petit projet:
(1) Analyser 30 fichiers HTML à chaque fois, puis mettre à jour le fichier txt d'origine, sinon les 30 premiers fichiers HTML seront traités à chaque fois.
#Obtenir une liste de pages Web def input_html (txtname):
avec open (txtname, 'r') as f:
content = f.read ()
s1 = content.split ('\ n') # La chaîne parlante est convertie en list
html_num = len (s1)
#Nombre total de liens print ('Le fichier contient {} links'.format (html_num))
s2 = s1 [30:] # Les liens restants
new_html =' \ n'.join (s2) #Update
new_html_num = len (s2) #Total number of links
print ('Terminez cette tâche, il reste {} liens à gauche' '.format (new_html_num))
return new_html #Créez
un nouveau document, distingué par le temps
import time
nowtime = time. strftime ("% Y% m% d% H% M% S", time.localtime ()) # L'heure actuelle est représentée comme un nouveau fichier
avec open ("sitemap" + nowtime + ".txt", "w" , encoding = 'utf-8') comme f:
f.write (input_html ("sitemap.txt"))
f.close ()
1234567891011121314151617181920

(2) Pour lire le fichier HTML et extraire le contenu requis, vous devez utiliser des expressions régulières pour extraire deux parties, l'une est le titre et l'autre est le contenu avec la table des matières.
import re
import urllib.request #import module de requête
def Parse_html (url):
res = urllib.request.urlopen (url)
#call urlopen () pour obtenir l'interface de réponse du serveur html = res.read (). decode (' utf-8 ')
#Décodez les données de réponse renvoyées et affectez-les à html
return html html = Parse_html (url) # Extraire une
partie du fichier source comme partie de contenu
str1 = re.findall (' <div class = "DetailInfo" > ([\ s \ S] *?) <div class = "Column ElectronicIntro" ', html)
#Take the part between str1 [0] = str1 [0] .replace (' <div class = "Column ColumnCatalog" id = "columnCatalog" style = "display: none"> ',' <div class = "Column ColumnCatalog" id = "columnCatalog" style = ""> ')
str1_1 = re.sub (' </span> [\ s] *? <li> ',' </span> \ n </li><li> ', str1 [0]) #
Terminer la partie manquante en partie </li> str1_2 = re.sub (' </span> [\ s] *? </ul> ',' </span> \ n </ li> </ul> ', str1_1) #Terminer la partie manquante en partie </li><li> ', str1 [0]) # fill missing in part </li>
# Extraire une str2 = re.findall ("<h1 [\ s \ S] *? </ h1> ", html) #Matches with line breaks [\ s \ S] * ?, correspond à n'importe quel caractère intermédiaire, y compris les sauts de ligne
# Extraire une
partie du fichier source comme partie titre 123456789101112131415
Comment afficher le lien de l'image cible correspondant à la page Web? Utilisez le navigateur Chrome pour ouvrir la page Web ci-dessus, puis appuyez sur F12, vous verrez le code source de cette page Web sur la droite, suivez les trois étapes dans l'image ci-dessous, cliquez sur la petite flèche, déplacez la souris sur l'image cible, survolez , this Le code source de la page Web correspondant à cette partie cible sera mis en évidence à droite. Vous pouvez voir la partie que j'ai encadrée en rouge, et la partie entre guillemets après src est la connexion de cette image.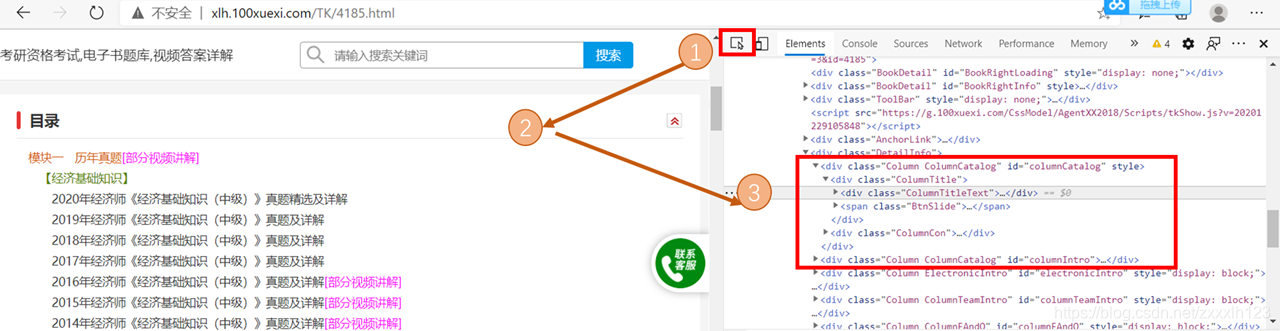
Il y a encore deux problèmes au milieu , l'un est manquant, ce qui rendra une partie du contenu non affichable; l'autre problème style = "display: none" cette partie masquera le répertoire, vous devez donc le remplacer par style = "". Cette partie concerne la structure du HTML et des expressions régulières .
(3) Combinez le contenu extrait pour former un fichier HTML.
import os
def write_html (title, content):
html1 = open ("n.html", "w") # write into html
html1.write (title) #
titlehtml1.write (content) #
contenthtml1.close ()
# 把 Le le contenu traité est écrit dans le fichier HTML
write_html (str2 [0], str1_2)
123456789
(4) Écrire des fichiers HTML dans Word
import pypandoc
def html_docx (html_path, docx_path):
f = open (html_path, "r", encoding = 'gbk')
html1 = f.read ()
output = pypandoc.convert_text (html1, 'docx', 'html', fichier de sortie = docx_path) # Convertir le code html en docx # Ecrire un
nouveau fichier HTML dans Word, au format
html_docx ("n.html", "file1.docx")
1234567
Il y a une difficulté à ce stade, c'est-à-dire l'importation de pypandoc.Le serveur utilisé par l'entreprise peut être débogué sans problème, mais l'ordinateur à la maison a signalé une erreur AUCUN pandoc n'a été trouvé. Voir la figure ci-dessous pour plus de détails:

J'ai trouvé de nombreuses façons d'essayer sur Internet, principalement en suivant les directives de signalement des erreurs, mais aucune ne s'est améliorée. Enfin trouvé un post https://blog.csdn.net/qq_43741748/article/details/105454719, "Téléchargez et installez Pandoc (version Windows et Mac)" téléchargé depuis le site officiel de Pandoc https://www.pandoc.org/ installation .html , exécutez simplement le problème d'installation directement. 
(5) Ajustez davantage le contenu Word en fonction des besoins, principalement en ajustant la police à Microsoft Yahei , en ajoutant un pied de page , en nommant le fichier avec le titre du contenu et en le stockant.
#Modifier le style du mot, nommer le fichier, ajouter un pied
de page depuis l'importation docx Document document = Document ('file1.docx')
document . Paragraphs [0] .text = document. Paragraphs [0] .text.replace ("[题库]" , "")
document. Paragraphs [0] .text = document. Paragraphs [0] .text.replace ("[eBook]", "")
f = document. Paragraphs [0] .text
filename = f # prendre le nom du fichier
sec = document.sections # Objet de section dans le document
Word sec0 = sec [0] # Récupère l'objet de chapitre
font0 = sec0.footer # Renvoie l'objet de pied de page
#print (font0)
# Définit le pied de page #
print (font0.
Paragraphs ) font0_par = font0. Paragraphs [0]
font0_par.add_run ('Examen d'entrée au réseau d'apprentissage Xinglanhai-troisième cycle, banque de questions e-book, réponse vidéo détaillée')
de docx.oxml.ns import qn
document.styles ['Normal']. font. nom = u'Microsoft Yahei '
document.styles ['Normal'] ._ element.rPr.rFonts.set (qn ('w: eastAsia'), u'Microsoft Yahei ') # Enregistrez toutes les polices dans le paragraphe
document.save (' {}. docx '. format (nom de fichier))
1234567891011121314151617181920
La liste de la première étape doit être parcourue en boucle. Ce sont les bases, donc je n'entrerai pas dans les détails. Il y a aussi une partie de gestion des exceptions qui doit être ajoutée lors de la boucle. Affichez les résultats du traitement pour que tout le monde puisse les voir,
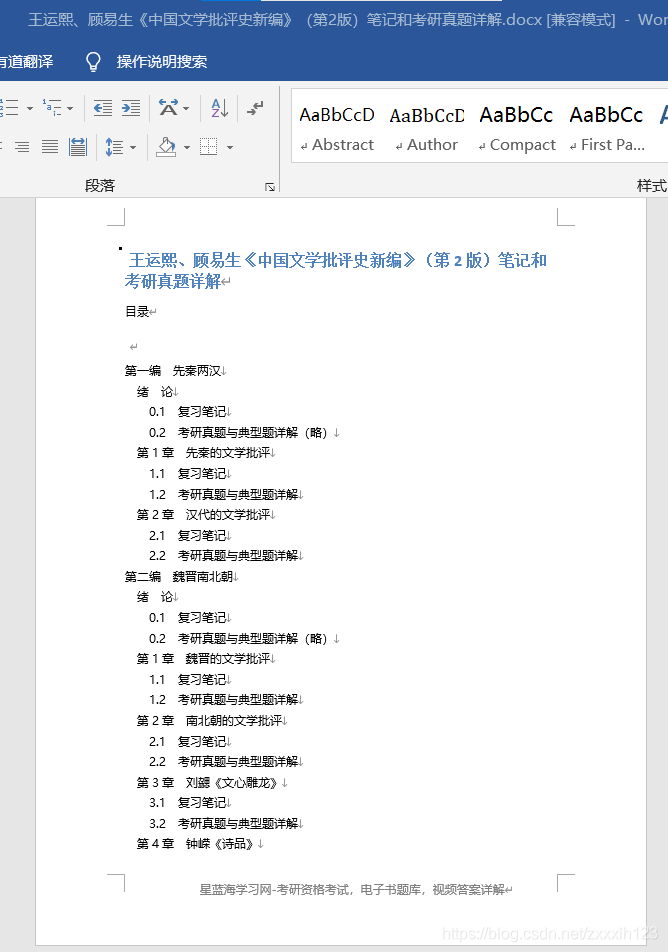
Dans le cadre du traitement des documents docx, le titre ne peut pas être changé, et il doit encore être amélioré à l'avenir!