1 Vue d'ensemble du pool de connexions
- Problème lié à l'utilisation des objets de connexion :
nous nous connections une fois à la base de données pour créer une connexion une seule fois. Sinon, nous la fermions directement, puis la créerions en cours d'utilisation. Cela entraînait une utilisation excessive des ressources et augmentait la charge du serveur et prendrait beaucoup de temps. - Solution : pour
résoudre ces problèmes, nous devons considérer comment augmenter la vitesse de connexion et comment augmenter le taux d'utilisation.
Ce qui suit présentera une introduction détaillée et l'utilisation du pool de connexion de base de données le plus pratique ------ Druid (druid)
Après l'introduction ci-dessus, nous devons créer un pool de connexions pour nous connecter à l'opération de base de données. Avant que le pool de connexions ne soit utilisé, les utilisateurs créent eux-mêmes des objets de connexion lorsqu'ils accèdent à la base de données.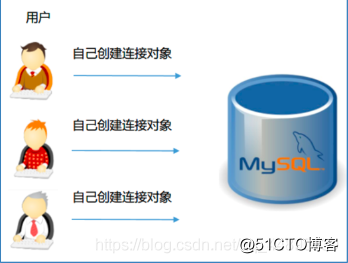
Après avoir utilisé le pool de connexions: au démarrage du système, un objet fabrique sera créé, qui contient un certain nombre d'objets de connexion à la base de données. Lorsque l'utilisateur l'utilise, l'objet de connexion sera directement extrait du pool et il n'est pas nécessaire de le créer vous-même.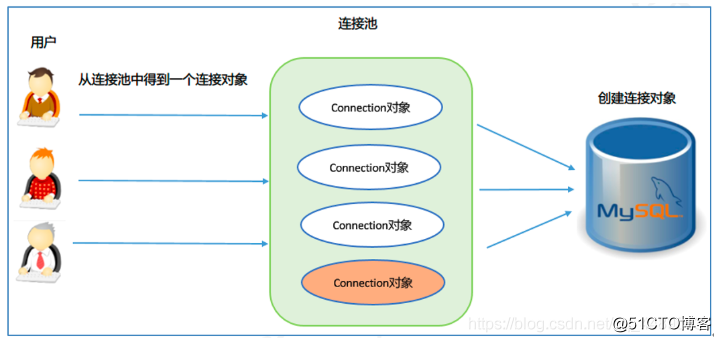
Le principe du pool de connexions pour résoudre le problème du statu quo
| Objet de connexion de connexion | Les caractéristiques de fonctionnement |
|---|---|
| Une fois créé | L'objet de connexion n'est plus créé par lui-même, mais un certain nombre de connexions ont été créées au démarrage du système et placé dans le pool de connexions |
| lors de son utilisation | Obtenir un objet de connexion créé directement à partir du pool de connexions |
| Lorsqu'il est fermé | Ne fermez pas vraiment l'objet de connexion, mais remettez l'objet de connexion dans le pool de connexions pour que l'utilisateur suivant l'utilise |
- Interface de source de données: interface javax.sql.DataSource
Méthodes dans l'interface de la source de données:
| Méthodes dans l'interface DataSource | la description |
|---|---|
| Connexion getConnection () | Obtenez l'objet de connexion à partir du pool de connexions |
Chaque pool de connexions aura un grand nombre de paramètres, et chaque paramètre a une signification différente. Presque tous les paramètres ont des valeurs par défaut. La signification des noms de paramètres dans différents pools de connexions est également différente!
| Paramètres communs | la description |
|---|---|
| Connexions initiales | Le nombre d'objets de connexion créés au démarrage du serveur |
| Nombre maximum de connexions | Combien d'objets de connexion peuvent être placés au maximum dans le pool de connexions |
| Temps d'attente le plus long | S'il n'y a pas d'objet de connexion dans le pool de connexions, définissez la durée maximale d'attente de l'utilisateur, en millisecondes. Lancer une exception si elle dépasse ce temps |
| Temps de récupération d'inactivité maximal | Si un objet de connexion n'est pas utilisé pendant une longue période, définissez la durée de recyclage de cet objet. La valeur par défaut est de ne pas recycler. |
2 Pool de connexion couramment utilisé (nous préférons druid)
Introduction aux pools de connexions communs
DataSource lui-même est une interface fournie par Oracle, et il n'y a pas d'implémentation spécifique. Son implémentation est implémentée par les fournisseurs de bases de données des principaux pools de connexions. Il suffit d'apprendre à l'utiliser.
Composants de pool de connexions couramment utilisés:
- Ali Baba - Druid druid connection pool: Druid est un projet sur la plateforme open source Alibaba (main).
- Le pool de connexions à la base de données DBCP (DataBase Connection Pool) est un projet de pool de connexions Java sur Apache et un composant de pool de connexions utilisé par Tomcat.
- C3P0 est un pool de connexions JDBC open source, actuellement les projets open source qui l'utilisent incluent Hibernate, Spring, etc. C3P0 a pour fonction de récupérer automatiquement les connexions inactives.
Utiliser le pool de connexions Druid
Introduction à DRUID
Druid est un pool de connexion de base de données développé par Alibaba appelé Monitoring, qui surpasse les autres pools de connexion de base de données en termes de fonction, de performances et d'évolutivité. Druid a déployé plus de 600 applications à Alibaba et a été rigoureusement testé dans des environnements de production à grande échelle pendant plus d'un an. Tels que: l'événement annuel double onze, le ticket de train annuel de la Fête du Printemps.
Adresse de téléchargement de Druid: https://github.com/alibaba/druid
Le package jar utilisé par le pool de connexions DRUID: druid-1.0.9.jar
Paramètres de configuration communs
| paramètre | La description |
|---|---|
| URL | Chaîne de connexion |
| Nom d'utilisateur | Nom d'utilisateur |
| mot de passe | mot de passe |
| driverClassName | Le nom de la classe du pilote sera automatiquement identifié en fonction de l'URL, cet élément peut être laissé non configuré |
| dimension initiale | Connexions initiales |
| maxActive | Nombre maximum de connexions |
| maxWait | Temps d'attente le plus long |
Présentation de l'API du pool de connexions Druid
- Obtenez le flux d'entrée du fichier de configuration
| Méthodes en classe | La description |
|---|---|
| InputStream getResourceAsStream (chemin de chaîne) | Chargez le fichier de configuration sous le classpath et transformez-le en objet de flux d'entrée |
- Méthodes de la classe Properties, lire les clés et les valeurs dans le fichier de propriétés et les charger dans la collection

- Créez un pool de connexions via la méthode statique de la fabrique Druid et fournissez une collection d'attributs en tant que paramètres
| Méthodes de DruidDataSourceFactory | méthode |
|---|---|
| public static DataSource createDataSource (Propriétés propriétés) | Créer un pool de connexions via les attributs de la collection d'attributs |
3 Utiliser le pool de connexions Druid
Démonstration de cas: obtenir l'objet de connexion
Paquet de guide: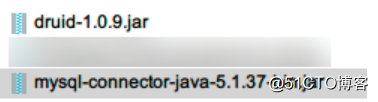
étape
- Créez un fichier de propriétés dans le répertoire src, avec n'importe quel nom de fichier, et définissez les paramètres ci-dessus
- Code Java
- Chargez le contenu du fichier de propriétés dans l'objet Properties
- Utilisez la classe de fabrique, créez un pool de connexions DRUID, utilisez les paramètres du fichier de configuration
- Retirez 10 sorties de connexion du pool de connexions DRUID

Fichier de configuration .properties:
url=jdbc:mysql://localhost:3306/test
username=root
password=root
driverClassName=com.mysql.jdbc.Driver
initialSize=5
maxActive=10
maxWait=2000code java:
public class Demo2Druid {
public static void main(String[] args) throws Exception {
//1.从类路径下加载配置文件,获取一个输入流。如果不指定路径,默认是读取同一个包下资源文件
InputStream inputStream = Demo2Druid.class.getResourceAsStream("/druid.properties");
//2.使用Properties对象的方法将配置文件中属性加载到Properties对象中
Properties properties = new Properties();
//加载了配置文件中所有的属性
properties.load(inputStream);
//3.通过druid的工厂类创建连接池
DataSource dataSource = DruidDataSourceFactory.createDataSource(properties);
//获取10个连接对象
for (int i = 1; i <= 11; i++) {
Connection connection = dataSource.getConnection();
System.out.println("第" + i + "个连接对象:" + connection);
//第3个连接关闭
if (i==3) {
connection.close();
}
}
}
}
Mais si le nombre maximum de connexions à la base de données est dépassé: 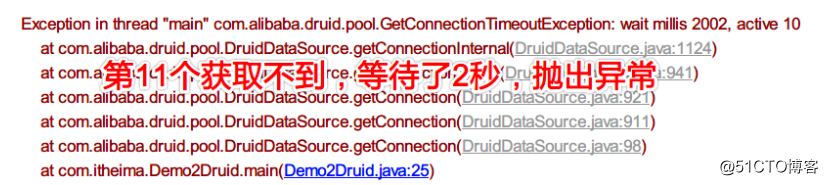
mais nous laissons la troisième fermer la connexion, ce qui équivaut à renvoyer un objet de connexion au pool de connexions, donc le résultat sera affiché: (il y a deux valeurs d'adresse qui sont identiques!)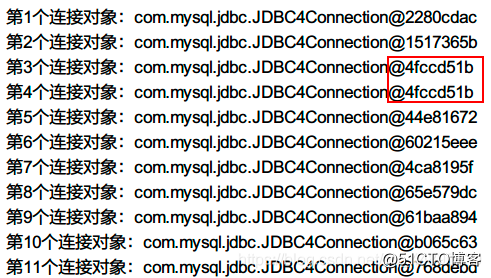
4 Les outils de données sont encore améliorés
une analyse
Utilisez le pool de connexions Druid pour obtenir l'objet de connexion afin d'améliorer la vitesse d'accès à la base de données
- Supprimer le code lié à la connexion à la base de données dans la classe
- Obtenez la connexion à la base de données, récupérez-la dans le pool de connexions
- Ajouter une nouvelle méthode pour obtenir l'objet du pool de connexions
- L'objet pool de connexions (source de données) peut être obtenu dès que la classe est chargée, et le pool de connexions est créé dans le bloc de code statique
Code
package com.aoshen.Test;
import com.alibaba.druid.pool.DruidDataSourceFactory;
import javax.sql.DataSource;
import java.io.IOException;
import java.io.InputStream;
import java.lang.reflect.Field;
import java.sql.*;
import java.util.ArrayList;
import java.util.List;
import java.util.Properties;
public class JDBCUtils {
//声明连接池对象
private static DataSource dataSource;
//使用静态,是类加载的时候就创建连接池
static{
try {
//读取配置文件
InputStream inputStream = JDBCUtils.class.getClassLoader().getResourceAsStream("druid");
//获取Properties对象,加载到该对象中
Properties properties = new Properties();
//获取配置文件
properties.load(inputStream);
//创建druid工厂
dataSource = DruidDataSourceFactory.createDataSource(properties);
} catch (Exception e) {
e.printStackTrace();
}
}
//获取数据库连接
public static Connection getConn() throws SQLException {
return dataSource.getConnection();
}
/**
* 关闭连接
* 查询调用这个方法
*/
public static void close(Connection connection, Statement statement, ResultSet resultSet) {
try {
if (resultSet != null) {
resultSet.close();
}
} catch (SQLException e) {
e.printStackTrace();
}
try {
if (statement != null) {
statement.close();
}
} catch (SQLException e) {
e.printStackTrace();
}
try {
if (connection != null) {
connection.close();
}
} catch (SQLException e) {
e.printStackTrace();
}
}
/**
* 关闭连接
* 增删改没有结果集
*/
public static void close(Connection connection, Statement statement) {
//直接调用上面的方法
close(connection, statement, null);
}
/**
* 通用的增删改方法
*/
public static int update(String sql,Object...args){
Connection conn = null;
PreparedStatement ps = null;
//返回影响的行数
int row = 0;
try{
//获取连接
conn = getConn();
//获取预编译对象
ps = conn.prepareStatement(sql);
//获取元数据,得到有多少占位符
ParameterMetaData metaData = ps.getParameterMetaData();
int count = metaData.getParameterCount();
//循环获取赋值
for (int i = 0; i < count; i++) {
ps.setObject(i+1,args[i]);
}
//执行SQL语句
row = ps.executeUpdate();
}catch (Exception e){
e.printStackTrace();
}finally {
close(conn,ps);
}
return row;
}
/**
* 通用的查询方法
*/
public static <T> List<T> equery(String sql,Class<T>c,Object...args){
Connection conn = null;
PreparedStatement ps = null;
ResultSet rs = null;
//创建集合用于接收数据库中查的值
List<T>list = new ArrayList<>();
try{
//获取连接
conn = getConn();
//获取预编译对象
ps = conn.prepareStatement(sql);
//通过获取元数据给占位符赋值
ParameterMetaData metaData = ps.getParameterMetaData();
int count = metaData.getParameterCount();
for (int i = 0; i < count; i++) {
ps.setObject(i+1,args[i]);
}
//执行sql
rs = ps.executeQuery();
//遍历集合,封装到集合中吗,一行数据封装一个对象
while (rs.next()){
//每条记录封装成一个对象
T t = c.newInstance();
//得到实体类中有哪些列名
Field[] fields = c.getDeclaredFields();
//遍历赋值
for (Field field : fields) {
//获取列名
String name = field.getName();
//获取内容
Object value = rs.getObject(name);
//因为是私有的,要暴力反射
field.setAccessible(true);
//把最后得到的值赋值给创建的对象中
field.set(t,value);
}
//把最后含每一行值的对象添加到集合中
list.add(t);
}
}catch (Exception e){
e.printStackTrace();
}finally {
close(conn,ps,rs);
}
return list;
}
}Utiliser des outils
/**
* 使用工具类
*/
public class Demo3UseUtils {
public static void main(String[] args) {
//使用工具类添加1条记录
int row = JdbcUtils.update("insert into student values(null,?,?,?)", "嫦娥", 0, "1997-07-07");
System.out.println("添加了" + row + "条");
//使用工具类查询所有的数据
List<Student> students = JdbcUtils.query("select * from student", Student.class);
//打印
students.forEach(System.out::println);
}
}
sommaire
Modification de la manière d'obtenir la connexion
- Créer un objet de pool de connexions dans un bloc de code statique
- Ajout d'une méthode pour obtenir la source de données
- Modification de la méthode d'obtention de la connexion, obtention de l'objet de connexion à partir du pool de connexions