Types de données de base Redis
- Préface
- Pourquoi avez-vous besoin d'une base de données NoSQL
- Qu'est-ce que Redis
- Introduction aux connaissances de base de Redis
- Type de données Redis
- Pour résumer
Préface
Dans le développement quotidien, nous choisissons généralement des bases de données relationnelles pour stocker des données, telles que MySQL, Oracle, etc., mais dans les scénarios commerciaux avec une grande concurrence, les bases de données relationnelles deviennent souvent des goulots d'étranglement du système et ne peuvent pas répondre pleinement à nos besoins, donc La base de données non relationnelle, la base de données NoSQL, est née.
L'interprétation la plus courante de la base de données NoSQL est "non relationnelle", et certaines personnes l'expliquent comme "Pas seulement SQL". Les bases de données non relationnelles ne garantissent pas les transactions, c'est-à-dire qu'elles ne disposent pas des fonctionnalités ACID. C'est également la plus grande différence entre les bases de données non relationnelles et les bases de données relationnelles. Le Redis que nous sommes sur le point d'introduire est un type de base de données NoSQL.
PS: Cette série d'articles est basée sur la version Redis5.0.5 .
Pourquoi avez-vous besoin d'une base de données NoSQL
Par rapport aux bases de données relationnelles traditionnelles, les bases de données NoSQL présentent les avantages suivants:
- 1. Il n'y a pas de relation entre les données, ce qui est très facile à développer
- 2. Prise en charge de la lecture et de l'écriture de données massives, de meilleures performances avec une concurrence élevée
- 3. Prise en charge du stockage distribué, et facile à étendre et à réduire
En même temps, il existe de nombreux types de bases de données NoSQL. Selon les différents types de stockage de données, il existe principalement les bases de données NoSQL courantes suivantes:
- 1. Stockage clé-valeur. Tels que: Redis et MemcaheDB
- 2. Stockage de documents. Tels que: MongoDB
- 3. Stockage de la colonne. Tels que: HBase
- 4. Stockage de graphiques. Tels que: Neo4j
- 5. Stockage d'objets
- 6. Les autres types ne sont plus répertoriés
Qu'est-ce que Redis
Nom complet Redis: REmote DIctionary Service, c'est-à-dire service de dictionnaire distant. Redis est une base de données open source (en conformité avec le protocole BSD), prise en charge par le réseau, basée sur la mémoire et basée sur des journaux persistants.
Redis présente les caractéristiques suivantes:
- 1. Prise en charge des types de données riches. Tels que les chaînes (chaînes), les hachages (hachages), les listes (listes), les ensembles (ensembles), les ensembles triés (ensembles triés) et les requêtes de plage, les bitmaps, etc.
- 2. Fonctions riches. Fournit un mécanisme de persistance, une stratégie d'expiration, un abonnement / une version et d'autres fonctions
- 3. Hautes performances, haute disponibilité et prise en charge des clusters
- 4. Fournit des API en plusieurs langues
Introduction aux connaissances de base de Redis
Redis utilise le stockage de clés et de valeurs, et la longueur maximale de la clé et de la valeur est limitée à 512 Mo.
Redis dispose de 16 bases de données par défaut. Cela peut être modifié dans le fichier de configuration redis.conf:
databases 16
Ces 16 bases de données sont nommées avec les numéros 0-15 et ne prennent pas en charge la modification des noms, et les données entre les bases de données ne sont pas isolées . Par exemple, si nous basculons vers une base de données, exécutez la commande flushhall pour effacer les données de toutes les bases de données, donc Il n'est pas recommandé d'isoler différentes données du système d'entreprise via une base de données, mais nous pouvons la définir sur différentes bases de données pour différents modules du même système d'entreprise.
Commandes d'opération de base de données couramment utilisées
- Changer de base de données. Après avoir changé de base de données, le numéro de la base de données actuelle sera affiché. La base de données numéro par défaut 0 n'affiche pas le numéro.
select 数据库编号

Comme vous pouvez le voir sur la figure ci-dessous, nous définissons la valeur dans la base de données 0, nous ne pouvons donc pas obtenir la valeur dans d'autres bases de données:

- Effacer la base de données actuelle
flushdb
- Effacer toutes les bases de données
flushall
Type de données Redis
Il existe 9 types de données pris en charge dans Redis jusqu'à la version 5.0.5. Elles sont:
- 1, chaînes de sécurité binaire (chaînes de sécurité binaires)
- 2, listes (liste)
- 3 ensembles
- 4. Ensembles triés (ensemble ordonné)
- 5. Hashs
- 6, tableaux de bits (ou simplement des bitmaps) (位 位)
- 7 、 HyperLogLogs
- 8 、 géospatial
- 9 、 Flux
Bien que 9 types soient répertoriés ici, les 5 premiers sont les plus couramment utilisés.
Dans Redis, différents types de commandes sont fournis pour chaque type de données, présentons-les tour à tour.
1. chaînes de sécurité binaire (chaînes de sécurité binaires)
Le type de chaîne est le type le plus largement utilisé et la valeur de clé dans Redis ne peut être stockée que sous forme de chaîne, tandis que la valeur peut prendre en charge 9 types de données.
Les chaînes dans Redis peuvent stocker trois types de données:
- Chaîne
- Entier
- Point flottant
Ainsi, nos commandes d'opération de type chaîne incluent également des commandes d'incrémentation automatique, examinons les commandes d'opération courantes de type chaîne
Commandes courantes
Voici plusieurs commandes de fonctionnement couramment utilisées:
- Définir la valeur (une seule clé et une seule valeur peuvent être définies)
set key value
- Définir la valeur (clé et valeur multiples)
mset key1 value1 key2 value2
- Prenez une valeur unique
get key
- Prenez plusieurs valeurs
get key1 key2

- Afficher toutes les clés de la base de données actuelle (utilisez cette opération avec précaution, s'il y a trop de valeurs de clé, elle peut directement planter)
keys *
- Afficher le nombre total de clés de base de données actuelles (renvoyer un entier)
dbsize
- Vérifiez si la clé existe dans la base de données actuelle (renvoyée est un entier: 0-no1-yes)
exists key
- Renommer la clé
rename oldKey newKey

- Supprimer la clé (plusieurs séparés par des espaces, le retour est le nombre de clés supprimées avec succès)
del key

- Afficher le type de clé
type key

- Incrément de 1 (si la valeur n'est pas un entier, une erreur sera signalée)
incr key
- Incrémenter la taille spécifiée (si la valeur n'est pas un entier, une erreur sera signalée)
incrby key 需要自增的数字

- Définissez la valeur, si la clé existe déjà, le paramètre échoue
setnx key value # 设置单个key
mset key1 value1 key2 value2 # 设置多个key

PS: setnx et mset sont des opérations atomiques. Elles doivent toutes être correctement définies pour renvoyer true. Il existe également des paramètres pour définir le délai d'expiration. En général, les verrous distribués sont implémentés en fonction de cette commande avec un délai d'expiration.
- Définir la clé avec l'heure d'expiration
set key value EX|PX 18 # EX表示秒,PX表示毫秒
L'exemple suivant est configuré pour expirer automatiquement après 5 secondes

- Réglez l'heure d'expiration individuellement. Cependant, afin de garantir l'atomicité, nous utilisons toujours la commande set ci-dessus avec le temps directement.
expire key
Scénario d'application
Les scénarios d'application du type chaîne sont très riches. Les données chaudes normales peuvent être mises en cache à l'aide du type chaîne. Les scénarios suivants peuvent être principalement appliqués:
- 1. Données du hotspot et son cache d'objets
- 2. Partage de session distribué
- 3. Verrou distribué (à l'aide de la commande setnx)
- 4. Redis est déployé indépendamment et peut être utilisé comme identifiant unique au monde
- 5. En utilisant sa commande d'incrémentation atomique, il peut être utilisé comme compteur ou limite de courant, etc.
2. listes
Les éléments à l'intérieur de la liste dans Redis sont également des chaînes, et nous pouvons ajouter l'élément spécifié à la position spécifiée dans la liste. Les commandes de fonctionnement du type de données liste commencent généralement par une lettre minuscule l.
Commandes courantes
Regardez quelques commandes de fonctionnement couramment utilisées:
- Insérez une ou plusieurs valeurs dans la tête de la clé de liste, créez une clé si la clé n'existe pas
lpush key value1 value2
- Insérez une valeur dans la tête de la clé de liste et ne faites rien si la clé n'existe pas
lpushx key value1 value2
- Supprimer et renvoyer l'élément head de la valeur clé
lpop key
- Insérez une ou plusieurs valeurs à la fin de la clé de liste, créez une clé si la clé n'existe pas
rpush key value1 value2
- Insérez une ou plusieurs valeurs à la fin de la clé de liste et ne faites rien si la clé n'existe pas
rpushx key value
- Supprimer et renvoyer le dernier élément de la valeur de clé
rpop key
- Renvoie la longueur de la liste de clés
llen key
- Renvoie l'élément dont l'index est index dans la liste de clés. La tête commence à 0 et la queue commence à -1
lindex key index
- Renvoie les éléments entre les indices start (inclus) et stop (inclus) dans la liste des clés
lrange key start stop
- Définissez la valeur sur la position d'index spécifiée dans la liste de clés. Si la clé n'existe pas ou si l'index est hors limites, une erreur sera signalée
lset key index value
- Intercepter les éléments entre [début, fin] dans la liste et remplacer la liste d'origine pour enregistrer
ltrim key start end

3 ensembles
La collection dans Redis est une collection non ordonnée de type String, et les éléments de la collection sont uniques et ne peuvent pas être répétés.
Commandes courantes
Les commandes set set operation commencent généralement par s. Voici quelques commandes couramment utilisées:
- Ajoutez un ou plusieurs membres d'élément à la clé d'ensemble et renvoyez le nombre d'ajouts réussis, si l'élément existe déjà, il sera ignoré
sadd key member1 member2
- Déterminer si l'élément membre existe dans la clé d'ensemble
sismember key member
- Supprimez les éléments de la clé d'ensemble, les éléments inexistants seront ignorés
srem key member1 member2
- Déplacer l'élément membre de la source de l'ensemble vers dest, si le membre n'existe pas, ne rien faire
smove source dest member
- Renvoie tous les éléments de la clé de collection
smembers key

4. ensembles triés (ensemble commandé)
La différence entre un ensemble ordonné et un ensemble dans Redis est que chaque élément d'un ensemble ordonné est associé à un score de type double, puis les scores sont classés dans l'ordre croissant.
Commandes courantes
Les commandes de fonctionnement des ensembles triés commencent généralement par z. Voici quelques commandes couramment utilisées:
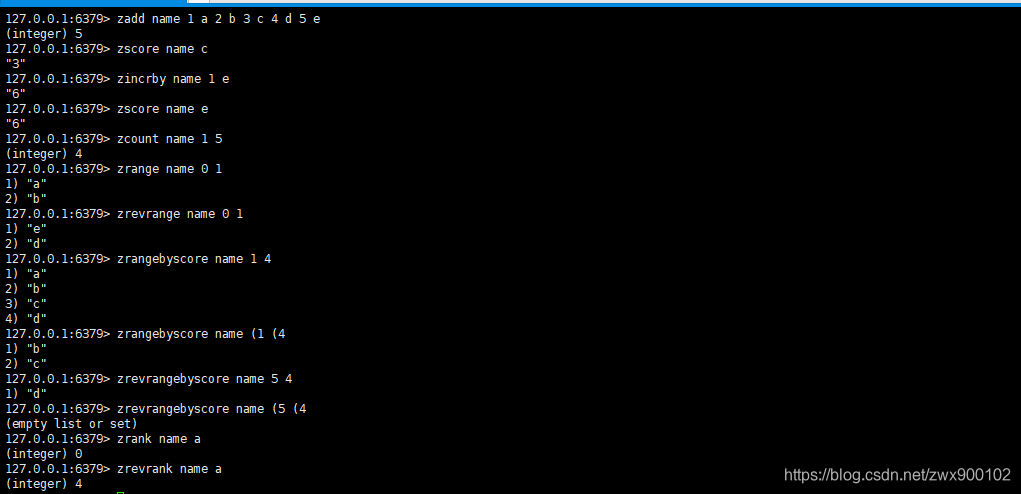
- Ajouter un ou plusieurs éléments membre et son score à la clé d'ensemble ordonnée
zadd key score1 member1 score2 member2
- Renvoie le score du membre membre dans la clé d'ensemble ordonnée
zscore key member
- Ajouter num au membre dans la clé d'ensemble ordonnée, num peut être négatif
zincrby key num member
- Renvoie le nombre de membres dont la valeur de score est comprise entre min (inclus) et max (inclus) dans la clé d'ensemble ordonnée
zcount key min max
- Renvoie tous les membres entre le début (inclus) et la fin (inclus) une fois que le score dans la clé d'ensemble ordonnée est arrangé de petit à grand
zrange key start stop
- Renvoie tous les membres entre le début (inclus) et la fin (inclus) une fois que le score dans la clé d'ensemble ordonnée est agencé de grand à petit
zrevrange key start stop
- Renvoie tous les éléments du score de min à max dans l'ensemble ordonné, triés par score de petit à grand. Notez que la valeur par défaut est l'intervalle fermé, mais vous pouvez ajouter (ou [pour contrôler l'intervalle d'ouverture et de fermeture devant max et min
zrangebyscore key min max
- Renvoie tous les éléments du score du maximum au minimum dans l'ensemble ordonné, triés par score du plus grand au plus petit. Notez que la valeur par défaut est un intervalle fermé, mais vous pouvez ajouter (ou [pour contrôler l'intervalle d'ouverture et de fermeture
zrevrangebyscore key max min
- Renvoie le classement des éléments du membre dans l'ensemble ordonné (de petit à grand) et le résultat renvoyé est calculé à partir de 0
zrank key member
- Renvoie le classement des éléments du membre dans l'ensemble ordonné (de grand à petit) et le résultat renvoyé est calculé à partir de 0
zrevrank key member
- Renvoie le nombre de membres entre min et max dans l'ensemble ordonné. Notez que les valeurs min et max de cette commande doivent être précédées de (ou [pour contrôler l'intervalle d'ouverture et de fermeture , les valeurs spéciales-et + représentent respectivement l'infini négatif et l'infini positif
zlexcount key min max
5. hachures
Ce qui est stocké dans la table de hachage est une table de mappage de clés et de valeurs. Les commandes d'exploitation des types de données de hachage commencent généralement par h.
Commandes courantes
Voici quelques exemples de commandes couramment utilisées:
- Définissez la valeur du champ de champ dans la clé de table de hachage sur value
hset key field value #设置单个field
hmset key field1 value1 field2 value2 #设置多个field
- Définissez la valeur du champ de champ dans la clé de table de hachage sur value, si le champ existe déjà, ne faites rien
hsetnx key field value
- Récupère la valeur correspondant au champ de champ dans la clé de table de hachage
hget key field
- Obtenez la valeur correspondant à plusieurs champs dans la clé de table de hachage
hmget key field1 field2
- Supprimer un ou plusieurs champs dans la clé de table de hachage
hdel key field1 field2
- Renvoie le nombre de champs dans la clé de table de hachage
hlen key
- Ajoutez l'incrémentation à la valeur du champ de champ dans la clé de table de hachage. L'incrément peut être un nombre négatif. Si le champ n'est pas un nombre, une erreur sera signalée.
hincrby key field increment
- Ajoutez un incrément incrémentiel à la valeur du champ de champ dans la clé de table de hachage. L'incrément peut être un nombre négatif. Si le champ n'est pas de type flottant, une erreur sera signalée
hincrbyfloat key field increment
- Ajoutez l'incrémentation à la valeur du champ de champ dans la clé de table de hachage. L'incrément peut être un nombre négatif. Si le champ n'est pas un nombre, une erreur sera signalée.
hincrby key field increment
- Obtenir tous les champs de la clé de table de hachage
hkeys key
- Obtenez les valeurs de tous les champs de la table de hachage
hvals key

Scénario d'application
Le type de hachage est en fait très similaire au type de chaîne, donc fondamentalement, tout ce qu'une chaîne peut faire, le hachage peut faire, et dans certains scénarios, il sera plus efficace d'utiliser le stockage de classification de hachage.
6. tableaux de bits (ou simplement des bitmaps) 位 图
Bitmap bitmap consiste à définir 0 ou 1 via le plus petit bit d'unité, qui indique la valeur ou l'état correspondant à un élément, et sa valeur ne peut être que 0 ou 1, indiquant oui ou non. Par conséquent, cela est généralement utilisé pour compter s'il faut se connecter, s'il faut collecter, etc. des données tout ou rien.
Par exemple, le format des données de stockage est généralement: 100110000111, où 0 et 1 sont la valeur de bit, et la valeur de bit de la position spécifiée (décalage) peut être définie lors du réglage.
PS: la structure de données de stockage sous-jacente du bitmap est également un objet chaîne.
Commandes courantes
Le type de données bitmap fournit principalement les commandes suivantes:
- Pour la valeur de chaîne stockée dans la clé, définissez ou effacez la valeur de bit sur le décalage de décalage spécifié. Le paramètre de décalage doit être supérieur ou égal à 0 et inférieur à 2 ^ 32 (le mappage de bits est limité à 512 Mo).
setbit key offset value
- Obtenir la valeur de bit au décalage de décalage spécifié
getbit key offset
- Calculez le nombre de bits mis à 1 dans une chaîne donnée, le début et la fin peuvent être omis pour tout compter, 0 signifie le premier chiffre, -1 signifie le dernier chiffre
bitcount key [start] [end]
- Renvoie la position du premier bit binaire dans le bitmap, le début et la fin peuvent être omis, 0 signifie le premier bit, -1 signifie le dernier bit
bitpos key bit [start] [end]

Scénario d'application
Ceci est généralement utilisé dans les scénarios tout ou rien, comme s'il faut se connecter, s'il faut garder l'utilisateur, s'il faut récupérer des marchandises, s'il faut aimer, etc.
7.HyperLogLogs
HyperLogLog est une structure de données nouvellement ajoutée utilisée pour les algorithmes de statistiques cardinales dans Redis 2.8.9. L'avantage est que lorsque le nombre ou le volume d'éléments d'entrée est très grand, l'espace nécessaire pour calculer la base est toujours fixe et petit. Cette structure de données est généralement utilisée pour compter des informations telles que les UV.
HyperLogLog lui-même est un algorithme, qui provient de l'article "HyperLogLog l'analyse d'un algorithme d'estimation de cardinalité quasi optimale", si vous êtes intéressé par cet algorithme, vous pouvez aller le savoir.
Dans Redis, chaque clé HyperLogLog n'a besoin que de 12 Ko de mémoire pour calculer la base de près de 2 ^ 64 éléments différents, mais elle peut également avoir un taux d'erreur de 0,81%.
PS: La structure de données de stockage sous-jacente d'HyperLogLogs est également un objet chaîne.
Commandes courantes
Ce type de données fournit principalement les trois commandes suivantes:
- Ajouter n'importe quel nombre d'éléments à la clé dans l'HyperLogLog spécifié
pfadd key element1 element2
- Obtenez la cardinalité d'une ou plusieurs clés
pfcount key1 key2
- Combinez plusieurs clés source en une seule clé de destination, la cardinalité de la clé de destination combinée est proche de l'union de toutes les clés de source avant la fusion
pfmerge destkey sourcekey1 sourcekey2

De ce qui précède, nous pouvons voir qu'il n'y a pas de commande à retirer après l'avoir sauvegardée, donc cela est généralement utilisé pour les statistiques, et il doit pouvoir accepter les erreurs.
Par exemple, dans l'exemple ci-dessus, si u1 u2 u3 u4 est l'identifiant de l'utilisateur, je n'ai pas besoin de juger, tant que l'utilisateur visite la page Web une fois, je l'enregistrerai une fois, et la dernière valeur récupérée via pfcount est la valeur après la déduplication (c'est-à-dire ce qui précède Dit base) , bien qu'il y ait une certaine erreur, mais des données statistiques telles que UV sont acceptables.
Scénario d'application
Ceci est généralement utilisé dans les statistiques de données qui peuvent accepter des scénarios d'erreur, tels que les statistiques UV et d'autres scénarios
8. géospatial (emplacement géographique)
Geospatial est un nouveau type de données d'index géospatial avec une requête de rayon ajoutée dans Redis version 3.2. Généralement utilisé pour stocker et calculer la distance entre deux endroits.
PS: La structure de données de stockage sous-jacente d'HyperLogLogs est également une collection ordonnée d'objets.
Commandes courantes
Voici quelques commandes couramment utilisées:
- Ajoutez l'élément d'espace donné (latitude, longitude, nom) à la clé spécifiée. La longitude effective est comprise entre -180 degrés et 180 degrés et la latitude effective est comprise entre -85,05112878 degrés et 85,05112878 degrés.
geoadd key longitude latitude member
- Renvoie la position (longitude et latitude) de tous les éléments à la position donnée à partir de la touche.
geopos key member1 member2
- Renvoie la distance entre deux emplacements donnés. L'unité par défaut est le mètre (m), qui peut être spécifié par unité. L'unité prend en charge les types suivants: mètres (m), kilomètres (km), miles (mi), pieds (ft).
geodist key member1 member2 [unit]
- Avec la longitude et la latitude données comme centre, renvoie tous les éléments de localisation dont la distance du centre ne dépasse pas la distance maximale donnée parmi les éléments de localisation contenus dans la clé.
georadius key longitude latitude radius m|km|ft|mi [WITHCOORD] [WITHDIST] [WITHHASH] [ASC|DESC] [COUNT count]
- Avec l'élément donné comme centre, retourne tous les éléments de position dont la distance du centre ne dépasse pas la distance maximale donnée parmi les éléments de position contenus dans la clé.
georadiusbymember key member radius m|km|ft|mi [WITHCOORD] [WITHDIST] [WITHHASH] [ASC|DESC] [COUNT count]
Les deux dernières commandes sont fondamentalement les mêmes, l'une est de spécifier la latitude et la longitude, et l'autre est de lire automatiquement la latitude et la longitude d'un élément. Les principaux paramètres sont les suivants (l'unité ne sera pas répétée):
- WITHDIST: Lors du retour de l'élément de position, la distance entre l'élément de position et le centre est également renvoyée. L'unité de distance est cohérente avec l'unité de distance donnée par l'utilisateur.
- WITHCOORD: renvoie ensemble la longitude et la latitude de l'élément d'emplacement.
- WITHHASH: sous la forme d'un entier signé de 52 bits, renvoie le score d'ensemble ordonné de l'élément de position après le code geohash d'origine. Cette option est principalement utilisée pour les applications de bas niveau ou le débogage, et a peu d'effet dans la pratique.
- ASC: Selon la position du centre, l'élément de position est renvoyé de proche à loin.
- DESC: Selon la position du centre, l'élément de position est renvoyé de loin vers près.
- COUNT: spécifiez le nombre de retours. Cela a peu d'effet sur les performances de calcul, mais s'il y a beaucoup de zones renvoyées, l'utilisation de count peut économiser de la bande passante
Scénario d'application
Ce scénario d'application est évident, et il n'est nécessaire que pour les scénarios qui doivent calculer l'emplacement géographique.
9. flux
Streams est un type de données introduit par Redis5.0. La file d'attente de messages durable qui prend en charge la multidiffusion est utilisée pour implémenter la fonction de publication et d'abonnement. La conception de Streams s'appuie sur Kafka. Stream est le type de données le plus complexe de Redis. Nous ne l'introduirons pas ici. Lorsque nous présenterons la fonction de distribution / abonnement plus tard, nous présenterons séparément ce type de données et son API d'opération puissante et complexe.
Pour résumer
Cet article présente principalement 9 types de données de base dans Redis et leurs commandes d'opération et scénarios d'application couramment utilisés pour l'analyse. Les types de données dans Redis sont très riches. Bien que le type chaîne soit suffisant dans la plupart des cas, mais dans certains scénarios spécifiques L'utilisation de types spécifiques sera plus efficace et plus élégante.
Dans le prochain article, nous présenterons la structure de données sous-jacente des types de données dans Redis.
S'il vous plaît faites attention à moi et apprenez et progressez avec le loup solitaire .