J'ai seulement commencé à apprendre ml et dl cette année. Je n'ai pas beaucoup appris sur dl, principalement ml. J'ai commencé à apprendre des connaissances théoriques pendant les vacances d'été. Au cours du processus d'apprentissage, j'ai appris que DataWhale, une organisation open source relativement importante en Chine, pouvait apprendre d'eux. J'ai appris beaucoup de choses et j'ai appris à connaître beaucoup de bigwigs. J'ai lentement commencé à comprendre la compétition. De l'introduction à Kaggle basée sur 0, à Tianchi et au concours CCF plus tard, en quelques mois seulement, j'ai une certaine compréhension des compétitions de science des données. J'espère Vous pouvez obtenir les récompenses de première ligne dans les compétitions suivantes et les compétitions CCF de l'année prochaine. Cette compétition CCF a participé à un total de 6 compétitions, cinq compétitions officielles et une compétition d'entraînement.

Il y a quatre compétitions structurées et deux compétitions de PNL. Il n'y a que 3 compétitions auxquelles vous avez vraiment participé dans tout le processus. Il y en a aussi une qui a pris du temps. S'il y a deux compétitions, j'ai cliqué pour participer, mais il n'y avait aucune mention. Et le résultat.
Présentons à tour de rôle quelques-unes des compétitions auxquelles j'ai participé à l'ensemble du processus, et résumons également certaines des connaissances acquises lors de la compétition.
Répertoire d'articles
- 1. Classification des données de séries chronologiques sur les mouvements des utilisateurs en intérieur
- 2. Prévision des risques de collecte illégale de fonds par les entreprises
- 3. Découverte et classification intelligentes du contenu des données pour la gouvernance de la sécurité des données
- Quatre, résumé
1. Classification des données de séries chronologiques sur les mouvements des utilisateurs en intérieur
Adresse de la question: Classification des données des séries chronologiques des sports en salle.
Cette question et les coéquipiers ont travaillé ensemble et ont obtenu la première place. J'ai rédigé une ligne de base avant cette compétition.
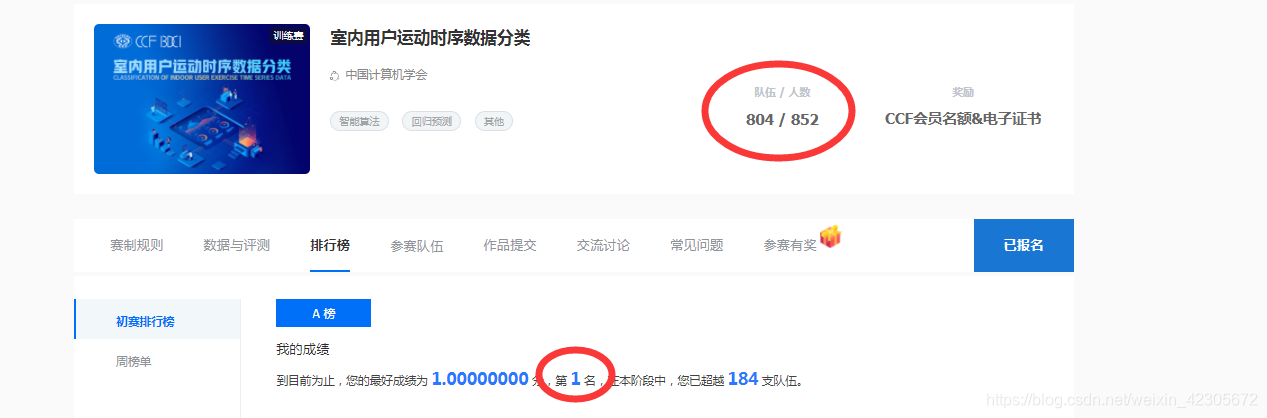
1. Présentation des données
Sur la base des besoins réels ci-dessus et des progrès de l'apprentissage profond, ce concours de formation vise à construire un algorithme général de classification de séries chronologiques. Établissez un modèle de classification des séries chronologiques précis à travers cette question et espérez que tout le monde explorera des méthodes d'expression de caractéristiques de séries chronologiques plus robustes.
En fait, cette question du concours est assez vague, et aucune explication spécifique n'est donnée: pour les données, tout le monde jette directement les données dans le modèle au début, puis soumet directement le résultat pour obtenir un bon score.
2. Description des données
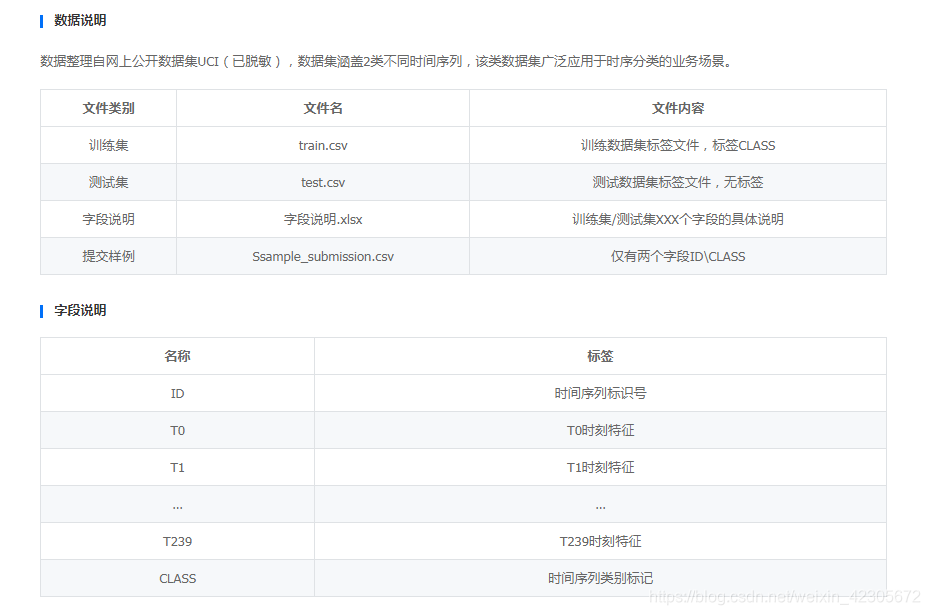
3. Récolte de gibier
C’est aussi la première fois que j’entre en contact avec ce type de problème de série chronologique. Je ne savais pas par où commencer au début. Avec la marchandise sèche partagée par nos coéquipiers, nous avons commencé à créer des fonctionnalités, ajouté les fonctionnalités créées aux données originales, puis nous nous sommes entraînés ensemble. Il a joué un bon rôle et l'augmentation du score est également assez importante.
Par conséquent, s'il y a moins de fonctionnalités pour vous lors d'un jeu, vous devez apprendre à extraire de nouvelles fonctionnalités à partir des données données, telles que
#统计特征
max_X=data.x.max()
min_X=data.x.min()
range_X=max_X-min_X
var_X=data.x.var()
std_X=data.x.std()
mean_X=data.x.mean()
median_X=data.x.median()
kurtosis_X=data.x.kurtosis()
skewness_X =data.x.skew()
Q25_X=data.x.quantile(q=0.25)
Q75_X=data.x.quantile(q=0.75)
#聚合特征
#差分值
max_diff1_x=data.x.diff(1).max()
min_diff1_x=data.x.diff(1).min()
range_diff1_x=max_diff1_x-min_diff1_x
var_diff1_x=data.x.diff(1).var()
std_diff1_x=data.x.diff(1).std()
mean_diff1_x=data.x.diff(1).mean()
median_diff1_x=data.x.diff(1).median()
kurtosis_diff1_x=data.x.diff(1).kurtosis()
skewness_diff1_x =data.x.diff(1).skew()
Q25_diff1_X=data.x.diff(1).quantile(q=0.25)
Q75_diff1_X=data.x.diff(1).quantile(q=0.75)
Attendez, plus de 30 nouvelles fonctionnalités ont été créées.
De plus, j'ai appris la méthode de fusion d'empilement de ce jeu, plus les nouvelles fonctionnalités de la structure, puis j'utilise cette méthode de fusion, l'augmentation du score est particulièrement importante, je ne connais pas les autres jeux, au moins ce jeu est comme ça!
2. Prévision des risques de collecte illégale de fonds par les entreprises
Les données officielles de ce jeu sont assez nombreuses. Comment extraire des fonctionnalités utiles de plusieurs tables est la clé de ce jeu! J'ai également écrit un partage de base avant , qui a été amélioré sur la base de la ligne de base de Shui Ge A榜排名36,B榜79. Dans l'ensemble, c'est bon.
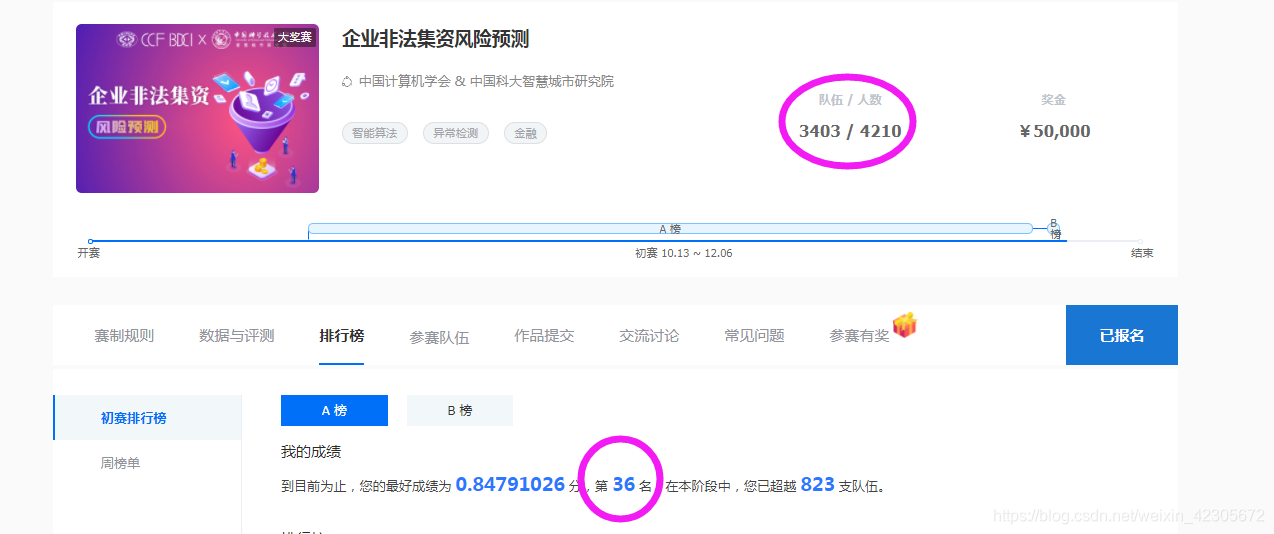

1. Présentation des données
L'ensemble de données contient des données d'environ 25 000 entreprises, dont environ 15 000 entreprises ont étiqueté les données comme ensemble de formation et les données restantes comme ensemble de test. Les données se composent d'informations de base sur la société, de rapports annuels sur les sociétés, de statut fiscal, etc. Les données comprennent de nombreux types de données (non sensibilisées) tels que les chiffres, les caractères et la date. Certains champs sont manquants dans certaines sociétés. La première colonne est id. C'est l'identification unique de l'entreprise.
2. Description des données
Ici, prenez la première table base_info.csv comme exemple, qui
contient les informations de base de toutes les entreprises impliquées dans les ensembles de données 7 et 8. Chaque ligne représente les données de base d'une entreprise, et chaque ligne comporte 33 colonnes. La colonne id est l'identification unique de l'entreprise. Les colonnes sont séparées par des séparateurs ",".
Le format des données est le suivant:
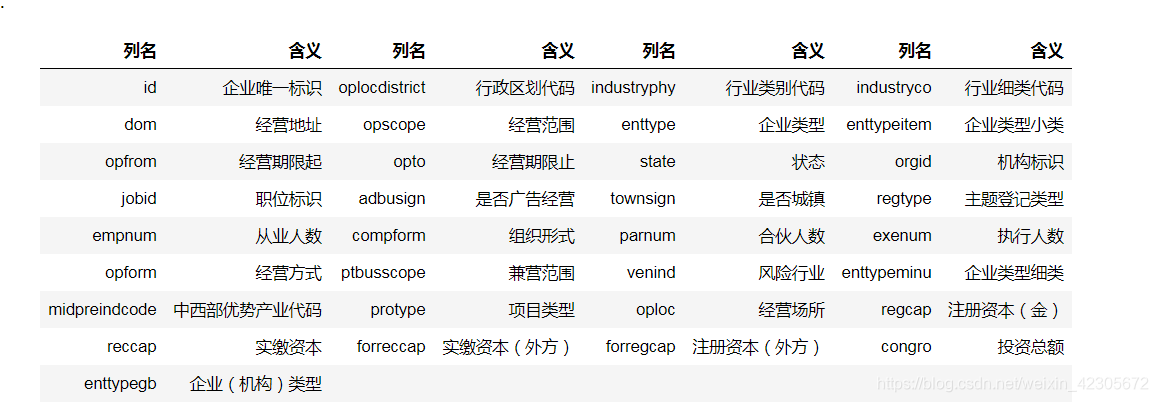
#读取数据
base_info = pd.read_csv(PATH + 'base_info.csv')
#输出数据shape和不重复企业id数
print(base_info.shape, base_info['id'].nunique())
#读取数据
base_info.head(1)
#查看缺失值,这里借助了missingno这个包,import missingno as msno。
msno.bar(base_info)#查看缺失值
Graphique de résultat:
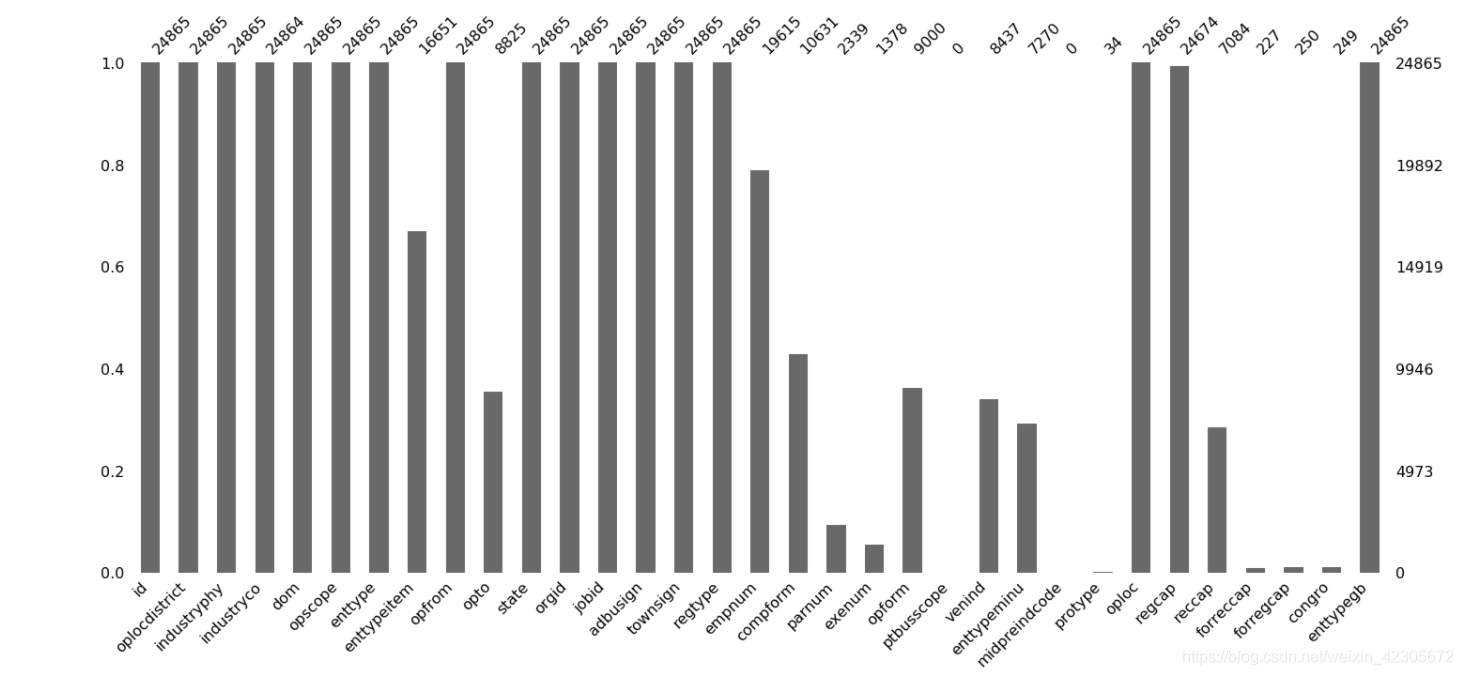
Ce graphique montre clairement quelles données ont des valeurs manquantes. L'axe horizontal est la fonction et l'axe vertical est le nombre de valeurs non manquantes. Les zones blanches de chaque colonne représentent les valeurs manquantes!
3. Récolte de gibier
3.1 Sélection et construction des caractéristiques
Dans les données fournies par ce concours, de nombreuses tables ont des valeurs manquantes. Pour le traitement des valeurs manquantes, la sélection et la construction d'entités, le croisement d'entités, le regroupement, etc., vous devez avoir une certaine compréhension, car les bonnes caractéristiques sont l'étape suivante. La base de la formation des modèles. Pour le traitement des fonctionnalités, veuillez vous référer à un article que j'ai écrit auparavant.
#orgid 机构标识 oplocdistrict 行政区划代码 jobid 职位标识
base_info['district_FLAG1'] = (base_info['orgid'].fillna('').apply(lambda x: str(x)[:6]) == \
base_info['oplocdistrict'].fillna('').apply(lambda x: str(x)[:6])).astype(int)
base_info['district_FLAG2'] = (base_info['orgid'].fillna('').apply(lambda x: str(x)[:6]) == \
base_info['jobid'].fillna('').apply(lambda x: str(x)[:6])).astype(int)
base_info['district_FLAG3'] = (base_info['oplocdistrict'].fillna('').apply(lambda x: str(x)[:6]) == \
base_info['jobid'].fillna('').apply(lambda x: str(x)[:6])).astype(int)
#parnum 合伙人数 exenum 执行人数 empnum 从业人数
base_info['person_SUM'] = base_info[['empnum', 'parnum', 'exenum']].sum(1)
base_info['person_NULL_SUM'] = base_info[['empnum', 'parnum', 'exenum']].isnull().astype(int).sum(1)
#regcap 注册资本(金) congro 投资总额
# base_info['regcap_DIVDE_empnum'] = base_info['regcap'] / base_info['empnum']
# base_info['regcap_DIVDE_exenum'] = base_info['regcap'] / base_info['exenum']
# base_info['reccap_DIVDE_empnum'] = base_info['reccap'] / base_info['empnum']
# base_info['regcap_DIVDE_exenum'] = base_info['regcap'] / base_info['exenum']
#base_info['congro_DIVDE_empnum'] = base_info['congro'] / base_info['empnum']
#base_info['regcap_DIVDE_exenum'] = base_info['regcap'] / base_info['exenum']
base_info['opfrom'] = pd.to_datetime(base_info['opfrom'])#opfrom 经营期限起
base_info['opto'] = pd.to_datetime(base_info['opto'])#opto 经营期限止
base_info['opfrom_TONOW'] = (datetime.now() - base_info['opfrom']).dt.days
base_info['opfrom_TIME'] = (base_info['opto'] - base_info['opfrom']).dt.days
#opscope 经营范围
base_info['opscope_COUNT'] = base_info['opscope'].apply(lambda x: len(x.replace("\t", ",").replace("\n", ",").split('、')))
#对类别特征做处理
cat_col = ['oplocdistrict', 'industryphy', 'industryco', 'enttype',
'enttypeitem', 'enttypeminu', 'enttypegb',
'dom', 'oploc', 'opform','townsign']
#如果类别特征出现的次数小于10转为-1
for col in cat_col:
base_info[col + '_COUNT'] = base_info[col].map(base_info[col].value_counts())
col_idx = base_info[col].value_counts()
for idx in col_idx[col_idx < 10].index:
base_info[col] = base_info[col].replace(idx, -1)
# base_info['opscope'] = base_info['opscope'].apply(lambda x: x.replace("\t", " ").replace("\n", " ").replace(",", " "))
# clf_tfidf = TfidfVectorizer(max_features=200)
# tfidf=clf_tfidf.fit_transform(base_info['opscope'])
# tfidf = pd.DataFrame(tfidf.toarray())
# tfidf.columns = ['opscope_' + str(x) for x in range(200)]
# base_info = pd.concat([base_info, tfidf], axis=1)
base_info = base_info.drop(['opfrom', 'opto'], axis=1)#删除时间
for col in ['industryphy', 'dom', 'opform', 'oploc']:
base_info[col] = pd.factorize(base_info[col])[0]
J'ai ajouté la signification de ces champs dans le code, afin que je puisse comprendre ces significations et effectuer quelques traitements. Vous pouvez également ajouter ces significations.
3.2 Sélection du modèle
En ce qui concerne le choix des modèles, chacun choisit essentiellement plusieurs modèles populaires pour l'apprentissage intégré, tels que XGboost, Lightgbm et Catboost.
Ces modèles uniques donnent de bons résultats dans de nombreuses compétitions. Si les résultats de ces modèles sont combinés, l'effet peut être meilleur. Bien sûr, il peut y avoir des différences dans les effets de plusieurs modèles dans certaines compétitions, et ces modèles d'apprentissage intégrés peuvent automatiquement corriger les Les caractéristiques de valeur sont gérées par elles-mêmes!
Mais il est recommandé que vous appreniez les connaissances théoriques de ces apprentissages intégrés, qui vous seront d'une grande aide pour vos études ou concours ultérieurs.
3. Découverte et classification intelligentes du contenu des données pour la gouvernance de la sécurité des données
Il s'agit d'un concours lié à la PNL. Pour être honnête, je ne lis pas grand-chose sur les théories liées à la PNL, ce concours peut donc être considéré comme un concours d'introduction à l'apprentissage personnel. Je n'ai pas utilisé de méthodes d'apprentissage en profondeur, mais des machines traditionnelles. Pour apprendre à faire, le laboratoire n'a pas les conditions pour faire du deep learning, mais seulement une simple compréhension de ce modèle de deep learning.
1. Présentation des données
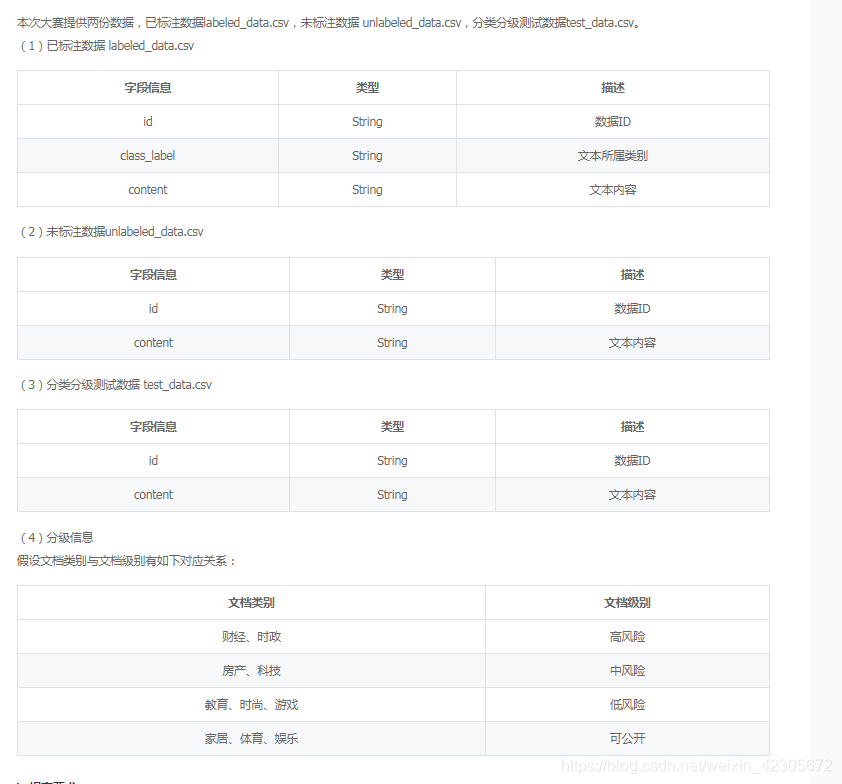
(1) Données annotées: Un total de 7 000 documents, les catégories comprennent 7 catégories, à savoir: finance, immobilier, ameublement, éducation, technologie, mode et actualité. Chaque catégorie contient 1 000 documents.
(2) Données non étiquetées: 33 000 documents au total.
(3) Données des tests de classification et de classement: un total de 20 000 documents, dont 10 catégories: finance, immobilier, ameublement, éducation, technologie, mode, actualité, jeux, divertissements et sports.
2. Description des données
Cette compétition est généralement une tâche de classification, mais il y a une difficulté qui est que l'officiel n'a donné que 7 catégories d'ensembles d'entraînement, mais vous devez prédire dix catégories, vous devez donc donner les trois autres catégories vous-même. Ils taguent et s'entraînent ensemble!
3. Récolte de gibier
La première fois que je suis entré en contact avec la connaissance de la PNL, j'étais vraiment un peu blanc, et je ne connaissais pas grand chose aux théories, donc ce jeu est aussi une voie d'opportunisme, et j'ai également appris de nouveaux concepts pour les données de type texte.
Idée 1: le classificateur d'apprentissage automatique TF-IDF +
utilise directement TF-IDF pour extraire des caractéristiques du texte, utiliser des classificateurs pour la classification et sélectionner les classificateurs peuvent utiliser SVM, LR, XGboost, etc.
Idée 2: FastText
FastText est un vecteur de mots d'entrée de gamme. À l'aide de l'outil FastText fourni par Facebook, vous pouvez rapidement créer un classificateur
Idée 3: Classificateur d'apprentissage en profondeur WordVec +
WordVec est un vecteur de mots avancé, et la classification est complétée par la construction d'une classification d'apprentissage en profondeur. La structure du réseau de classification d'apprentissage en profondeur peut choisir TextCNN, TextRnn ou BiLSTM.
Idée 4: Vecteur de mots
Bert Bert est un vecteur de mots parfaitement assorti doté de puissantes capacités de modélisation et d'apprentissage.
Quatre, résumé
En participant à ce type de concours de science des données pour la première fois, j'ai beaucoup gagné. Je peux grandir rapidement dans le concours, communiquer avec d'autres étudiants et apprendre beaucoup de nouvelles connaissances. Certains contenus n'ont peut-être été vus qu'en théorie, mais pas Je ne l'ai pas fait dans la pratique. Grâce à la compétition, je peux apprendre plus de compétences et de méthodes qui ne peuvent pas être vues en théorie. La première compétition CCF s'est terminée avec succès. Passez à d'autres compétitions. Je reviendrai à la compétition CCF l'année prochaine!
Heure d'enregistrement: 7 décembre 2020