L'utilisation de la pagination comme mécanisme principal pour implémenter la mémoire virtuelle peut entraîner une surcharge de performances plus élevée. Étant donné que la pagination doit être utilisée, l'espace d'adressage de la mémoire doit être divisé en un grand nombre d'unités de taille fixe (pages), et les informations de mappage d'adresses de ces unités doivent être enregistrées. Étant donné que ces informations de mappage sont généralement stockées dans la mémoire physique, lors de la conversion d'adresses virtuelles, la logique de pagination nécessite un accès mémoire supplémentaire. Chaque fois qu'une instruction est extraite, chargée ou sauvegardée explicitement, une lecture supplémentaire de la mémoire est nécessaire pour obtenir les informations de conversion, ce qui est trop lent. Par conséquent, nous sommes confrontés aux problèmes suivants:
Question clé: comment accélérer la traduction d'adresses
Comment accélérer la traduction d'adresses virtuelles et éviter autant que possible l'accès à la mémoire supplémentaire? Quel type de support matériel est nécessaire? Comment le système d'exploitation doit-il le prendre en charge?
Pour accélérer quelque chose, le système d'exploitation a généralement besoin d'aide. L'aide vient souvent de vieux amis des systèmes d'exploitation: le matériel. Nous devons augmenter la mémoire tampon de contournement de traduction d'adresse (pour des raisons historiques [CP78]) (translation-lookaside buffer, TLB [CG68, C95]), qui est le cache matériel pour la traduction fréquente d'adresses virtuelles vers physiques. Par conséquent, un meilleur nom serait le cache de traduction d'adresses. Pour chaque accès mémoire, le matériel vérifie d'abord le TLB pour voir s'il y a le mappage de conversion attendu, et s'il y en a, la conversion est terminée (bientôt) sans accéder à la table de pages (qui contient tous les mappages de conversion). TLB apporte une énorme amélioration des performances, en fait, il rend possible la mémoire virtuelle [C95].
19.1 Algorithme de base de TLB
La figure 19.1 présente un cadre général illustrant la manière dont le matériel gère la traduction d'adresses virtuelles. On suppose qu'une table de pages linéaire simple (table de pages linéaire, c'est-à-dire que la table de pages est un tableau) et un TLB géré par matériel (TLB géré par matériel, c'est-à-dire que le matériel est responsable de nombreux Responsabilité de l'accès à la table des pages, il y aura plus d'explications ci-dessous).
1 VPN = (VirtualAddress & VPN_MASK) >> SHIFT
2 (Success, TlbEntry) = TLB_Lookup(VPN)
3 if (Success == True) // TLB Hit
4 if (CanAccess(TlbEntry.ProtectBits) == True)
5 Offset = VirtualAddress & OFFSET_MASK
6 PhysAddr = (TlbEntry.PFN << SHIFT) | Offset
7 AccessMemory(PhysAddr)
8 else
9 RaiseException(PROTECTION_FAULT)
10 else // TLB Miss
11 PTEAddr = PTBR + (VPN * sizeof(PTE))
12 PTE = AccessMemory(PTEAddr)
13 if (PTE.Valid == False)
14 RaiseException(SEGMENTATION_FAULT)
15 else if (CanAccess(PTE.ProtectBits) == False)
16 RaiseException(PROTECTION_FAULT)
17 else
18 TLB_Insert(VPN, PTE.PFN, PTE.ProtectBits)
19 RetryInstruction()Figure 19.1 Algorithme de flux de contrôle TLB
Le flux général de l'algorithme matériel est le suivant: commencez par extraire le numéro de page (VPN) de l'adresse virtuelle (voir Figure 19.1, ligne 1), puis vérifiez si le TLB a un mappage de conversion pour le VPN (ligne 2). Si tel est le cas, nous avons un hit TLB, ce qui signifie que le TLB a une carte de conversion pour cette page. Succès! Ensuite, nous pouvons prendre le numéro de cadre de page (PFN) de l'entrée TLB associée, le combiner avec le décalage de l'adresse virtuelle d'origine pour former l'adresse physique souhaitée (PA) et accéder à la mémoire (lignes 5 à 7), en supposant Le contrôle de protection n'a pas échoué (ligne 4).
Si le CPU ne trouve pas la carte de conversion dans le TLB (TLB miss), nous avons du travail à faire. Dans cet exemple, le matériel accède à la table de pages pour trouver la carte de traduction (lignes 11-12), et utilise la carte de traduction pour mettre à jour le TLB (ligne 18), en supposant que l'adresse virtuelle est valide et que nous avons les droits d'accès appropriés (ligne 13, 15 lignes). La série d'opérations ci-dessus est coûteuse, principalement parce que des références mémoire supplémentaires sont nécessaires pour accéder à la table des pages (ligne 12). Enfin, lorsque la mise à jour du TLB est réussie, le système essaie à nouveau l'instruction.A ce moment, il y a ce mappage de conversion dans le TLB, et la référence mémoire est rapidement traitée.
TLB est similaire aux autres caches, à condition que, dans des circonstances normales, le mappage de conversion soit dans le cache (c'est-à-dire, hit). Si tel est le cas, seule une petite quantité de surcharge est ajoutée, car la vitesse d'accès de la conception est très rapide près du cœur du processeur TLB. Si le TLB échoue, cela entraînera beaucoup de surcharge de pagination. Il faut accéder à la table des pages pour trouver la mappe de traduction, ce qui entraîne une référence mémoire supplémentaire (ou plus, si la table des pages est plus complexe). Si cela se produit fréquemment, le programme ralentira considérablement. Par rapport à la plupart des instructions du processeur, l'accès à la mémoire est coûteux et les erreurs TLB entraînent plus d'accès à la mémoire. Par conséquent, nous espérons éviter autant que possible les ratés TLB.
19.2 Exemple: accès à un tableau
Afin de clarifier le fonctionnement de TLB, examinons un simple traçage d'adresse virtuelle et voyons comment TLB peut améliorer ses performances. Dans cet exemple, supposons qu'il existe un tableau de 10 entiers de 4 octets et que l'adresse virtuelle de départ est 100. Supposons en outre qu'il existe un petit espace d'adressage virtuel de 8 bits avec une taille de page de 16B. Nous pouvons diviser l'adresse virtuelle en un VPN 4 bits (avec 16 pages de mémoire virtuelle) et un offset de 4 bits (avec 16 octets dans chaque page).
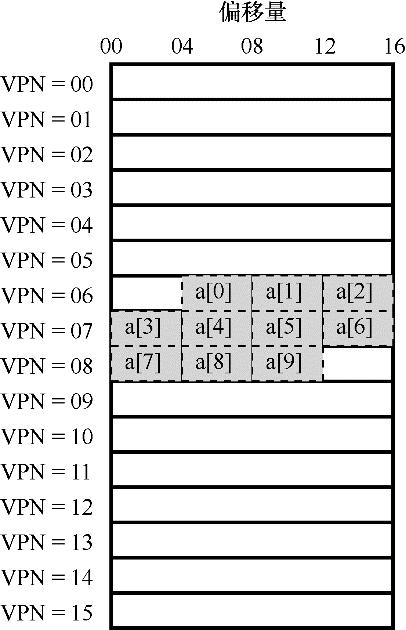
Figure 19.2 Exemple: un tableau dans un petit espace d'adressage
La figure 19.2 montre la disposition de ce tableau sur 16 pages de 16 octets dans le système. Comme vous pouvez le voir, le premier élément (a [0]) du tableau commence à (VPN = 06, offset = 04), et seuls trois entiers de 4 octets sont stockés sur cette page. Le tableau continue sur la page suivante (VPN = 07), qui contient les 4 éléments suivants (a [3]… a [6]). Les 3 derniers éléments (a [7]… a [9]) du tableau de 10 éléments sont situés sur la page suivante de l'espace d'adressage (VPN = 08).
Considérons maintenant une simple boucle, accédant à chaque élément du tableau, similaire au programme C suivant:
int sum = 0;
for (i = 0; i < 10; i++) {
sum += a[i];
}Pour simplifier, nous prétendons que l'accès mémoire généré par la boucle est uniquement pour le tableau (en ignorant les variables i et sum , et l'instruction elle-même). Lors de l'accès au premier élément du tableau (a [0]), le CPU verra l'adresse de mémoire virtuelle 100 chargée. Le matériel en extrait le VPN (VPN = 06), puis l'utilise pour vérifier le TLB afin de trouver un mappage de conversion valide. Supposons que ce soit la première fois que le programme accède au tableau et que le résultat soit un échec TLB.
Prochaine visite a [1], voici la bonne nouvelle: TLB hit! Étant donné que le deuxième élément du tableau est après le premier élément, ils sont sur la même page. Comme nous avons déjà visité cette page lorsque nous avons visité le premier élément du tableau, la carte de conversion de cette page est mise en cache dans le TLB. Donc ça réussit. L'accès à un [2] est également réussi (appuyez à nouveau) car il est sur la même page qu'un [0] et un [1].
Malheureusement, lorsque le programme accède à un [3], il provoquera un manque TLB. Mais encore une fois, les quelques éléments suivants (a [4]… a [6]) atteindront tous le TLB car ils sont sur la même page en mémoire.
Enfin, l'accès à un [7] entraînera le dernier échec du TLB. Le système recherchera à nouveau la table des pages, déterminera l'emplacement de cette page virtuelle dans la mémoire physique et mettra à jour le TLB en conséquence. Les deux dernières visites (a [8], a [9]) ont bénéficié de cette mise à jour du TLB. Lorsque le matériel a recherché leur mappage de conversion dans le TLB, ils ont frappé les deux fois.
Résumons le comportement du TLB dans ces 10 opérations d'accès: manquer, frapper, frapper, manquer, frapper, frapper, frapper, manquer, frapper, frapper. Diviser le nombre de visites par le nombre total de visites donne un taux de réussite TLB de 70%. Bien que ce ne soit pas très élevé (en fait, nous voulons que le taux de réussite soit proche de 100%), mais ce n'est pas nul, et nous serions surpris qu'il soit nul. Même si c'est la première fois que le programme accède au tableau, le TLB améliore toujours les performances grâce à la localisation spatiale. Les éléments du tableau sont stockés étroitement dans plusieurs pages (c'est-à-dire qu'ils sont étroitement adjacents dans l'espace), de sorte que seul l'accès au premier élément de la page entraînera un échec TLB.
Faites également attention à l'effet de la taille de la page sur les résultats de cet exemple. Si la taille de la page double (32 octets au lieu de 16), l'accès au tableau rencontrera moins d'erreurs. La taille d'une page typique est généralement de 4 Ko. Dans ce cas, un accès intensif basé sur une baie permettra d'obtenir d'excellentes performances TLB, et chaque accès à une page ne rencontrera qu'un seul échec.
Il y a un dernier point concernant les performances du TLB: si le programme accède à nouveau au tableau peu de temps après ce cycle, nous verrons de meilleurs résultats, en supposant que le TLB est suffisamment grand pour mettre en cache le mappage de transformation requis: hit, hit, hit , Frappez, frappez, frappez, frappez, frappez, frappez, frappez. Dans ce cas, en raison de la localité temporelle, qui se réfère à nouveau à l'élément de mémoire dans un court laps de temps, le taux de succès TLB sera élevé. Comme d'autres caches, le succès de TLB repose sur la localité spatiale et temporelle. Si un programme présente une telle localité (comme le font de nombreux programmes), le taux de succès TLB peut être élevé.
Conseil: utilisez le cache autant que possible
Le cache est l’une des techniques d’amélioration des performances les plus élémentaires des systèmes informatiques et est utilisé maintes et maintes fois pour accélérer les «situations courantes» [HP06]. L'idée derrière la mise en cache matérielle est de tirer parti de la localité des références d'instructions et de données. Il existe généralement deux types de localités: la localité temporelle et la localité spatiale. La localité temporelle signifie que l'instruction ou l'élément de données accédé le plus récemment peut être consulté à nouveau prochainement. Pensez aux variables de boucle ou aux instructions dans une boucle, elles sont consultées plusieurs fois à plusieurs reprises. La localité spatiale signifie que lorsqu'un programme accède à l'adresse mémoire x, il peut accéder rapidement à la mémoire adjacente à x. Pensez à parcourir une sorte de tableau, en accédant à un élément après l'autre. Bien entendu, ces propriétés dépendent des caractéristiques du programme, pas d'une loi absolue, mais plutôt d'une règle empirique.
Le cache matériel, qu'il s'agisse d'instructions, de données ou de traduction d'adresses (comme TLB), tire parti de la localité pour stocker une copie de la mémoire dans une petite et rapide mémoire sur puce. Le processeur peut d'abord vérifier s'il existe une copie à proximité dans le cache, plutôt que d'avoir à accéder à la mémoire (lente) pour satisfaire la demande. S'il existe, le processeur peut y accéder très rapidement (par exemple, en quelques horloges du processeur) et éviter de passer beaucoup de temps à accéder à la mémoire (plusieurs nanosecondes).
Vous vous demandez peut-être: puisqu'un cache comme TLB est si bon, pourquoi ne pas créer un cache plus grand et contenir toutes les données? Il est dommage que nous ayons rencontré ici des lois plus fondamentales, tout comme les lois de la physique. Si vous souhaitez mettre en cache rapidement, il doit être petit car la vitesse de la lumière et d'autres limitations physiques joueront un rôle. Les grands caches sont destinés à être lents, ils ne peuvent donc pas atteindre leurs objectifs. Par conséquent, nous ne pouvons utiliser que des caches petits et rapides. La question qui reste est de savoir comment utiliser à bon escient le cache pour améliorer les performances.
19.3 Qui traitera les échecs TLB
Il y a une question à laquelle nous devons répondre: qui s'occupera des échecs du TLB? Il peut y avoir deux réponses: matériel ou logiciel (système d'exploitation). Le matériel précédent avait un jeu d'instructions complexe (parfois appelé Complex-Instruction Set Computer, CISC), et les personnes qui construisaient le matériel ne faisaient pas confiance à ceux qui travaillaient sur le système d'exploitation. Par conséquent, le matériel est entièrement responsable de la gestion des échecs TLB. Pour ce faire, le matériel doit connaître l'emplacement exact de la table de pages en mémoire (via le registre de base de table de pages, utilisé à la ligne 11 de la figure 19.1), et le format exact de la table de pages. Lorsqu'un échec se produit, le matériel "traversera" la table de pages, trouvera l'entrée de table de pages correcte, récupérera la mappe de conversion souhaitée, mettra à jour le TLB avec elle et réessayera l'instruction. Cette "ancienne" architecture a TLB pour la gestion du matériel. Un exemple est l'architecture x86, qui utilise une table de pages fixe à plusieurs niveaux (voir le chapitre 20 pour plus de détails). La table de pages actuelle est indiquée par le registre CR3 [I09 ].
Les architectures plus modernes (par exemple, MIPS R10k [H93], SPARC v9 [WG00] de Sun, sont des ordinateurs à jeu d’instructions réduit, un ordinateur à jeu d’instructions réduit, RISC), il existe ce que l’on appelle le TLB géré par logiciel (TLB géré par logiciel) ). Lorsqu'un échec TLB se produit, le système matériel lèvera une exception (voir Figure 19.3, ligne 11), qui suspendra le flux d'instructions en cours, élever le niveau de privilège en mode noyau et passer au gestionnaire d'interruptions. Ensuite, comme vous l'avez peut-être deviné, ce gestionnaire d'interruptions est un morceau de code du système d'exploitation pour gérer les échecs TLB. Lorsque ce code est en cours d'exécution, il recherchera la mappe de conversion dans la table des pages, puis mettra à jour le TLB avec une instruction spéciale "privilégiée" et reviendra du piège. A ce moment, le matériel réessayera l'instruction (provoquant un hit TLB).
1 VPN = (VirtualAddress & VPN_MASK) >> SHIFT
2 (Success, TlbEntry) = TLB_Lookup(VPN)
3 if (Success == True) // TLB Hit
4 if (CanAccess(TlbEntry.ProtectBits) == True)
5 Offset = VirtualAddress & OFFSET_MASK
6 PhysAddr = (TlbEntry.PFN << SHIFT) | Offset
7 Register = AccessMemory(PhysAddr)
8 else
9 RaiseException(PROTECTION_FAULT)
10 else // TLB Miss
11 RaiseException(TLB_MISS)Figure 19.3 Algorithme de flux de contrôle TLB (traitement du système d'exploitation)
Quelques détails importants sont discutés ensuite. Tout d'abord, le retour de l'instruction de trap est ici légèrement différent du retour de trap mentionné précédemment qui sert les appels système. Dans ce dernier cas, le retour de l'interruption devrait continuer d'exécuter l'instruction après que le système d'exploitation est intercepté, tout comme le retour d'un appel de fonction, il continuera d'exécuter l'instruction après l'appel. Dans le premier cas, après être revenu de l'interruption manquée TLB, le matériel doit continuer l'exécution à partir de l'instruction qui a provoqué l'interruption. Cette nouvelle tentative provoquera donc à nouveau l'exécution de l'instruction, mais cette fois elle atteindra le TLB. Par conséquent, selon la cause de l'interruption ou de l'exception, le système doit enregistrer un compteur de programme différent lorsqu'il entre dans le noyau afin qu'il puisse continuer à s'exécuter correctement à l'avenir.
Deuxièmement, lors de l'exécution du code de gestion des erreurs TLB, le système d'exploitation doit faire très attention pour éviter une récursivité infinie qui provoque des erreurs TLB. Il existe de nombreuses solutions, par exemple, vous pouvez placer les gestionnaires d'interruptions manquées TLB directement dans la mémoire physique [ils ne sont pas mappés (non mappés), sans traduction d'adresse]. Ou conservez certains éléments dans le TLB, enregistrez la traduction d'adresse permanente et valide, et laissez certains des blocs d'emplacement de traduction d'adresse permanente au code de traitement lui-même. Ces traductions d'adresses câblées atteindront toujours le TLB.
Le principal avantage de la méthode de gestion logicielle est la flexibilité: le système d'exploitation peut utiliser n'importe quelle structure de données pour implémenter la table de pages sans changer le matériel. Un autre avantage est la simplicité. On peut voir à partir du flux de contrôle TLB (voir la ligne 11 de la figure 19.3, par rapport aux lignes 11 à 19 de la figure 19.1) que le matériel n'a pas besoin de faire beaucoup de travail sur les échecs, il lance des exceptions et la gestion des erreurs du système d'exploitation Le programme s'occupera du reste.
Supplément: RISC et CISC
Dans les années 80, une discussion animée a eu lieu dans le domaine de l'architecture informatique. L'un est le camp CISC, c'est-à-dire le calcul des jeux d'instructions complexes (calcul des jeux d'instructions complexes), et l'autre est RISC, c'est-à-dire le calcul des jeux d'instructions réduits (calcul des jeux d'instructions réduits) [PS81]. Le camp RISC est représenté par David Patterson de Berkeley et John Hennessy de Stanford (ils ont écrit des livres très célèbres [HP06]), bien que John Cocke ait plus tard remporté le Turing Award pour ses premiers travaux sur RISC [CM00].
Le jeu d'instructions CISC a tendance à avoir de nombreuses instructions, et chaque instruction est plus puissante. Par exemple, vous pouvez voir une copie de chaîne qui accepte deux pointeurs et une longueur, et copie certains octets de la source vers la cible. L'idée derrière CISC est que les instructions doivent être des primitives de haut niveau, ce qui rend le langage d'assemblage lui-même plus facile à utiliser et un code plus compact.
Le jeu d'instructions RISC est exactement le contraire. Le point clé derrière RISC est que le jeu d'instructions est en fait le but ultime du compilateur, et tous les compilateurs nécessitent en fait un petit nombre de primitives simples qui peuvent être utilisées pour générer du code haute performance. Par conséquent, les défenseurs du RISC préconisent que les éléments inutiles (en particulier le microcode) soient supprimés du matériel autant que possible, et que les éléments restants doivent être simples, unifiés et rapides.
Les premières puces RISC ont eu un impact énorme car elles étaient nettement plus rapides [BC91]. Les gens ont rédigé de nombreux articles et certaines sociétés apparentées ont été créées l'une après l'autre (comme MIPS et Sun). Mais au fil du temps, les fabricants de puces CISC comme Intel ont adopté de nombreux avantages des puces RISC, comme l'ajout d'étapes précoces du pipeline pour convertir des instructions complexes en certaines micro-instructions, afin qu'elles puissent fonctionner comme RISC. Ces innovations, couplées à l'augmentation du nombre de transistors dans chaque puce, ont permis au CISC de rester compétitif. La controverse s'est finalement calmée et les deux types de processeurs peuvent désormais fonctionner très rapidement.
19.4 Contenu TLB
Examinons de plus près le contenu du TLB matériel. Un TLB typique a 32, 64 ou 128 éléments et est entièrement associatif. Fondamentalement, cela signifie qu'une carte d'adresses peut exister n'importe où dans le TLB, et le matériel recherchera le TLB en parallèle pour trouver la carte de conversion souhaitée. Le contenu d'une entrée TLB peut ressembler à ceci:
VPN | PFN | Autres bits
Notez que VPN et PFN existent dans le TLB en même temps, car un mappage d'adresse peut apparaître n'importe où (en termes de matériel, TLB est appelé un cache entièrement associatif). Le matériel recherche ces éléments en parallèle pour voir s'il existe une correspondance.
Supplément: le bit effectif de TLB! = Le bit effectif de la table de pages
Une erreur courante est de confondre le bit effectif du TLB et le bit effectif de la table de pages. Dans la table de pages, si une entrée de table de pages (PTE) est marquée comme invalide, cela signifie que la page n'a pas été demandée pour être utilisée par le processus et que le programme normalement en cours d'exécution ne doit pas accéder à l'adresse. Lorsqu'un programme tente d'accéder à une telle page, il tombera dans le système d'exploitation et le système d'exploitation arrêtera le processus.
Le bit effectif de TLB est différent, il indique simplement si l'élément TLB est un mappage d'adresse valide. Par exemple, lorsque le système est démarré, toutes les entrées TLB sont généralement initialisées à un état non valide car il n'y a pas de mappe de traduction d'adresses en cache ici. Une fois la mémoire virtuelle activée, lorsque le programme commence à s'exécuter et accède à sa propre adresse virtuelle, le TLB se remplit lentement, de sorte que les éléments valides remplissent rapidement le TLB.
Le bit valide TLB joue un rôle important dans la commutation de contexte système, que nous discuterons plus loin plus tard. En définissant tous les éléments TLB comme non valides, le système peut garantir que le processus à exécuter n'utilisera pas par erreur le mappage de traduction d'adresses virtuelle-physique du processus précédent.
Les «autres bits» sont plus intéressants. Par exemple, TLB a généralement un bit valide, qui est utilisé pour identifier si l'élément est une mappe de conversion valide. Il existe généralement des bits de protection pour identifier si la page a des droits d'accès. Par exemple, les pages de codes sont identifiées comme lisibles et exécutables, tandis que les pages du tas sont identifiées comme lisibles et inscriptibles. Il existe d'autres bits, y compris l'identifiant d'espace d'adressage (identifiant d'espace d'adressage), le bit sale, etc. Plus d'informations seront présentées ci-dessous.
19.5 Gestion du TLB lors du changement de contexte
Avec TLB, lors de la commutation entre processus (et donc de commutation d'espace d'adressage), vous serez confronté à de nouveaux problèmes. Plus précisément, le mappage d'adresse virtuelle-physique contenu dans le TLB n'est valable que pour le processus en cours et n'a aucune signification pour les autres processus. Par conséquent, lorsqu'un changement de processus se produit, le matériel ou le système d'exploitation (ou les deux) doit veiller à ce que le processus sur le point de s'exécuter n'interprète pas la mappe d'adresses du processus précédent.
Afin de mieux comprendre cette situation, regardons un exemple. Lorsqu'un processus (P1) est en cours d'exécution, supposez que le TLB met en cache le mappage d'adresse valide pour lui, c'est-à-dire la table de pages de P1. Pour cet exemple, supposons que le numéro de page virtuelle 10 de P1 soit mappé au numéro de trame physique 100.
Dans cet exemple, supposons qu'il existe un autre processus (P2) et que le système d'exploitation décide rapidement d'effectuer un changement de contexte et d'exécuter P2. On suppose ici que le numéro de page virtuelle 10 de P2 est mappé sur le numéro de trame physique 170. Si les mappages d'adresses de ces deux processus se trouvent dans le TLB, le contenu du TLB est indiqué dans le Tableau 19.1.
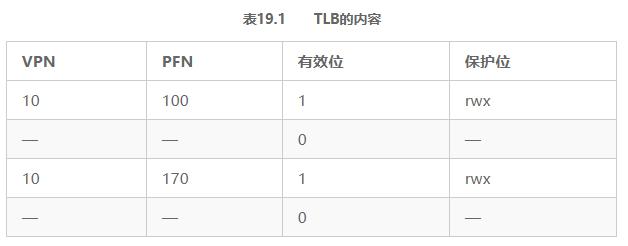
Dans le TLB ci-dessus, il y a évidemment un problème: VPN 10 est converti en PFN 100 (P1) et PFN 170 (P2), mais le matériel ne peut pas dire quel élément appartient à quel processus. Il nous reste donc encore du travail à faire pour que TLB prenne en charge correctement et efficacement la virtualisation sur plusieurs processus. Par conséquent, les questions clés sont:
La question clé: comment gérer le contenu de TLB pendant la commutation de processus
Si un changement de contexte inter-processus se produit, le mappage d'adresse du processus précédent dans le TLB n'a pas de sens pour le processus à exécuter. Que doit faire le matériel ou le système d'exploitation pour résoudre ce problème?
Il existe des solutions possibles à ce problème. Une méthode consiste simplement à vider le TLB pendant le changement de contexte, de sorte que le TLB devienne vide avant l'exécution du nouveau processus. S'il s'agit d'un système TLB de gestion de logiciel, cela peut être fait via une instruction explicite (privilégiée) lorsqu'un changement de contexte se produit. S'il s'agit d'un TLB de gestion matérielle, vous pouvez effacer le TLB lorsque le contenu du registre de base de table de page change (notez que le système d'exploitation doit changer la valeur du registre de base de table de page (PTBR) pendant le changement de contexte). Dans les deux cas, l'opération d'effacement met tous les bits valides (valides) à 0, effaçant essentiellement le TLB.
L'effacement du TLB pendant le changement de contexte est une solution réalisable, et le processus ne lira plus le mauvais mappage d'adresse. Cependant, il y a une certaine surcharge: à chaque fois qu'un processus s'exécute, lorsqu'il accède aux données et aux pages de codes, il déclenche un échec TLB. Si le système d'exploitation change fréquemment de processus, cette surcharge sera élevée.
Afin de réduire cette surcharge, certains systèmes ont ajouté une prise en charge matérielle pour réaliser le partage de TLB de commutation entre contextes. Par exemple, certains systèmes ajoutent un identificateur d'espace d'adressage (ASID) au TLB. Vous pouvez considérer l'ASID comme un identificateur de processus (PID), mais il a généralement moins de bits que le PID (le PID est généralement de 32 bits et l'ASID est généralement de 8 bits).
Si nous prenons toujours le TLB ci-dessus comme exemple et ajoutons l'ASID, il est clair que différents processus peuvent partager le TLB: tant que le champ ASID est utilisé pour distinguer le mappage d'adresses indiscernables. Le tableau 19.2 montre le TLB après avoir ajouté le champ ASID.
Tableau 19.2 TLB après l'ajout du champ ASID
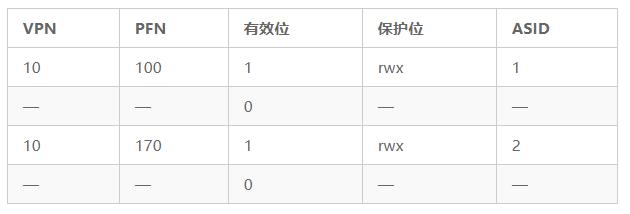
Par conséquent, avec l'identificateur d'espace d'adressage, le TLB peut mettre en cache les mappages d'espace d'adressage de différents processus en même temps sans aucun conflit. Bien entendu, le matériel a également besoin de savoir quel processus est en cours d'exécution pour effectuer la traduction d'adresse.Par conséquent, le système d'exploitation doit définir un certain registre privilégié comme ASID du processus en cours pendant le changement de contexte.
De plus, vous avez peut-être pensé à une autre situation, deux des TLB sont très similaires. Dans le tableau 19.3, deux éléments appartenant à deux processus différents pointent deux VPN différents vers la même page physique.
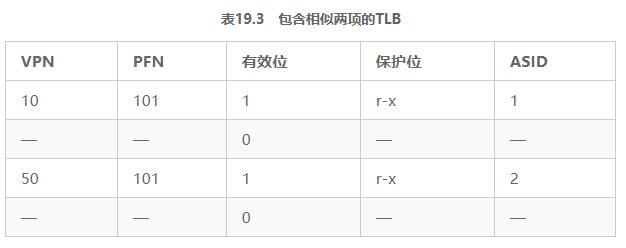
Cela peut se produire si deux processus partagent la même page physique (par exemple, une page d'un segment de code). Dans l'exemple ci-dessus, le processus P1 et le processus P2 partagent la page physique 101, mais P1 mappe sa page virtuelle 10 à cette page physique et P2 mappe sa page virtuelle 50 à la page physique. Les pages de code partagées (dans des bibliothèques binaires ou partagées) sont utiles car elles réduisent l'utilisation de pages physiques, réduisant ainsi la surcharge de mémoire.
19.6 Stratégie de remplacement du TLB
TLB, comme les autres caches, a un autre problème à prendre en compte, à savoir le remplacement du cache. Plus précisément, lorsqu'un nouvel élément est inséré dans le TLB, un ancien élément est remplacé (remplacer), donc la question est: lequel doit être remplacé?
Question clé: comment concevoir une stratégie de remplacement de TLB
Lors de l'ajout d'un nouvel élément à la TLB, quel ancien élément doit être remplacé? Le but est bien entendu de réduire le taux de ratés TLB (ou d'augmenter le taux de réussite), améliorant ainsi les performances.
Nous étudierons cette stratégie en détail lors de l'examen de la question de l'échange de pages sur disque. Ici, nous soulignons brièvement quelques stratégies typiques. Une stratégie courante consiste à remplacer les éléments les moins récemment utilisés (LRU). LRU tente de tirer parti de la localité dans le flux de référence de la mémoire, en supposant que les éléments qui n'ont pas été utilisés récemment peuvent être de bons candidats à l'échange. Une autre stratégie typique est la stratégie aléatoire (aléatoire), c'est-à-dire sélectionner au hasard un objet à échanger. Cette stratégie est simple et peut éviter une situation extrême. Par exemple, un programme accède à n +1 pages dans une boucle , mais la taille TLB ne peut stocker que n pages. A ce moment, la stratégie LRU apparemment "raisonnable" se comportera de manière déraisonnable, car chaque accès à la mémoire déclenchera un échec TLB, et la stratégie aléatoire est bien meilleure dans ce cas.
19.7 Entrées TLB du système actuel
Enfin, nous examinons brièvement le vrai TLB. Cet exemple provient de MIPS R4000 [H93], qui est un système moderne qui utilise un logiciel pour gérer TLB. La figure 19.4 montre un terme MIPS TLB légèrement simplifié.

Figure 19.4 Eléments TLB de MIPS
MIPS R4000 prend en charge un espace d'adressage 32 bits avec une taille de page de 4 Ko. Donc, dans une adresse virtuelle typique, attendez-vous à voir un VPN 20 bits et un décalage 12 bits. Cependant, comme vous pouvez le voir dans le TLB, il n'y a que des VPN 19 bits. En fait, l'adresse utilisateur n'occupe que la moitié de l'espace d'adressage (le reste est réservé au noyau), donc seul un VPN 19 bits est nécessaire. Le VPN est converti en un numéro de trame physique (PFN) de 24 bits maximum, ce qui lui permet de prendre en charge des systèmes avec jusqu'à 64 Go de mémoire physique (224 pages de mémoire 4KB).
MIPS TLB a également quelques marqueurs intéressants. Par exemple, le bit global (Global, G) est utilisé pour indiquer si cette page est globalement partagée par tous les processus. Par conséquent, si la position globale est 1, l'ASID est ignoré. Nous avons également vu l'ASID 8 bits, qui est utilisé par le système d'exploitation pour distinguer l'espace de processus (comme décrit ci-dessus). Voici une question: et si le nombre de processus en cours dépasse 256 (28)? Enfin, nous voyons 3 bits de cohérence (Coherence, C), qui déterminent comment le matériel met en cache la page (dont l'un dépasse le cadre de ce livre); le bit sale (dirty) indique si la page est écrite avec de nouvelles données ( L'utilisation sera présentée plus tard); le bit valide (valide) indique au matériel si le mappage d'adresse de l'élément est valide. Il existe également un champ de masque de page, non illustré dans la figure 19.4, pour prendre en charge différentes tailles de page. Plus tard, j'expliquerai pourquoi une page plus grande pourrait être utile. Enfin, certains des 64 bits sont inutilisés (la partie grise de la figure 19.4).
MIPS TLB a généralement 32 éléments ou 64 éléments, dont la plupart sont fournis pour les processus utilisateur, et une petite partie est réservée aux systèmes d'exploitation. Le système d'exploitation peut définir un registre surveillé pour indiquer au matériel le nombre d'emplacements TLB qu'il doit se réserver. Ces mappages de conversion réservés sont utilisés par le système d'exploitation pour le code et les données qu'il utilise à des moments critiques. À ces moments-là, les erreurs TLB peuvent causer des problèmes (par exemple, dans les gestionnaires d'erreurs TLB).
Puisque le TLB de MIPS est géré par logiciel, le système doit fournir des instructions pour mettre à jour le TLB. MIPS fournit quatre de ces instructions: TLBP, utilisé pour déterminer si le mappage de conversion spécifié est dans le TLB; TLBR, utilisé pour lire le contenu du TLB dans le registre spécifié; TLBWI, utilisé pour remplacer l'élément TLB spécifié; TLBWR , Utilisé pour remplacer aléatoirement un élément TLB. Le système d'exploitation peut utiliser ces instructions pour gérer le contenu du TLB. Bien entendu, ces instructions sont des instructions privilégiées, ce qui est essentiel. Si le programme utilisateur peut modifier arbitrairement le contenu du TLB, vous pouvez imaginer les choses terribles qui vont se passer.
Astuce: la RAM n'est pas toujours RAM (loi de Culler)
La mémoire RAM (Random-Access Memory) implique que vous pouvez accéder à n'importe quelle partie de la RAM aussi rapidement. Bien qu'il soit généralement correct de penser à la RAM de cette façon, en raison des fonctions matérielles / du système d'exploitation telles que TLB, l'accès à certaines pages de mémoire est coûteux, en particulier les pages qui ne sont pas mises en cache par TLB. Par conséquent, il est préférable de se souvenir de cette astuce d'implémentation: la RAM n'est pas toujours de la RAM. Parfois, l'accès aléatoire à l'espace d'adressage, en particulier aux pages qui ne sont pas mises en cache par le TLB, peut entraîner de graves pertes de performances. Parce que l'un de mes mentors, David Culler, avait l'habitude de souligner que TLB est la source de nombreux problèmes de performance, nous avons nommé cette loi d'après lui: la loi de Culler.
Cet article est tiré de «Introduction aux systèmes d'exploitation»

Ce livre se concentre sur les trois principaux concepts de virtualisation, de concurrence et de persistance, et présente les principaux composants de tous les systèmes modernes (y compris la planification, la gestion de la mémoire virtuelle, les sous-systèmes de disque et d'E / S et les systèmes de fichiers). Le livre se compose de 50 chapitres, divisés en 3 parties, qui traitent de la virtualisation, de la concurrence et de la persistance. L'auteur présente les concepts thématiques introduits sous forme de dialogue, et l'écriture spirituelle et humoristique est également incluse, essayant d'aider les lecteurs à comprendre les principes de la virtualisation, de la concurrence et de la persistance dans les systèmes d'exploitation.
Le contenu de ce livre est complet, et il fournit un code réel et exécutable (pas un pseudo-code), ainsi que des exercices correspondants, ce qui est très approprié pour les enseignants des majeures connexes dans les collèges et les universités pour mener à bien l'enseignement et les étudiants pour mener une auto-étude.
Ce livre présente les caractéristiques suivantes:
● Le thème est prédominant et il entoure étroitement les trois principaux éléments thématiques de la virtualisation du système d'exploitation, de la concurrence et de la persistance.
● Présentez le contexte du dialogue, posez des questions, expliquez les principes et inspirez la pratique.
● Contient de nombreux «suppléments» et «astuces» pour élargir les connaissances des lecteurs et accroître leur intérêt.
● Utilisez du vrai code au lieu d'un pseudo-code pour permettre aux lecteurs d'avoir une compréhension plus approfondie et approfondie du système d'exploitation.
● Proposez de nombreuses méthodes d'apprentissage telles que des devoirs, des simulations et des projets pour encourager les lecteurs à s'exercer.
● Fournir aux enseignants des ressources pédagogiques auxiliaires.