Nebula Graph est une base de données graphique distribuée avec des performances élevées, une haute disponibilité et une forte cohérence. Étant donné que Nebula Graph adopte une architecture de séparation de stockage et de calcul, la couche de stockage expose en fait une interface kv simple, utilise RocksDB comme machine d'état et utilise le protocole de cohérence Raft pour garantir la cohérence de plusieurs copies de données. Bien que le protocole Raft soit plus facile à comprendre que Paxos, de nombreux domaines nécessitent encore une attention et une optimisation dans la mise en œuvre de l'ingénierie.
En outre, la façon de tester le système distribué basé sur Raft est également un problème qui tourmente l'industrie.À l'heure actuelle, Nebula utilise principalement Jepsen comme outil de vérification de la cohérence. Mon petit ami a déjà donné une introduction détaillée dans " La pratique du cadre de test Jepsen dans la base de données graphique Graph Nébuleuse ". Les étudiants qui ne connaissent pas grand-chose à Jepsen peuvent d'abord passer à cet article.
Dans cet article, nous nous concentrerons sur la façon d'utiliser Jepsen pour vérifier la cohérence du kv distribué de Nebula Graph.
Définition fortement cohérente
Tout d'abord, ce que nous devons comprendre s'appelle la cohérence forte, qui est en fait la linéarisation, également connue sous le nom de cohérence linéaire. Pour citer la définition dans le livre "Designing Data-Intensive Applications":
Dans un système linéarisable, dès qu'un client termine avec succès une écriture, tous les clients lisant dans la base de données doivent pouvoir voir la valeur qui vient d'être écrite.
C'est-à-dire, bien qu'un système distribué fortement cohérent puisse avoir plusieurs copies à l'intérieur, il est exposé comme s'il n'y en avait qu'une seule, et toute demande de lecture du client obtient les dernières données écrites.
Comment Jepsen vérifie-t-il si le système répond à une forte cohérence
En prenant un exemple de chronologie de test Jepsen, le modèle utilisé est à registre unique , c'est -à- dire que le système entier n'a qu'un seul registre (la valeur initiale est vide), et le client ne peut lire ou écrire que sur ce registre (toutes les opérations sont atomiques Sexe, il n'y a pas d'état intermédiaire). En même temps, quatre clients envoient des demandes au système. Les bords supérieur et inférieur de chaque case de la figure représentent l'heure à laquelle la demande est envoyée et l'heure à laquelle la réponse est reçue.

Du point de vue du client, pour toute demande, le serveur traitant la demande peut survenir à tout moment à partir du moment où le client envoie la demande pour recevoir le résultat correspondant. On peut voir qu'avec le temps, les trois opérations 1/3/4 du client écrivent 1 / écrivent 4 / lisent 1 se chevauchent réellement dans le temps, mais nous pouvons déterminer à travers les réponses reçues par différents clients Le véritable état du système.
Puisque la valeur initiale est vide, la demande de lecture du client 4 obtient 1, indiquant que l'opération de lecture du client 4 doit être après l'écriture 1 du client 1, et l'écriture 4 se produit avant l'écriture 1 (sinon elle lira 4), Vous pouvez confirmer que l'ordre dans lequel les trois opérations se sont réellement produites est d'écriture 4-> d'écriture 1-> de lecture 1. Bien que d'un point de vue global, la demande de lecture 1 soit émise en premier, elle est en fait traitée en dernier. Les opérations suivantes n'ont pas de chevauchement dans le temps et se produisent dans l'ordre. Enfin, le client 2 lit enfin 4 de la dernière écriture. L'ensemble du processus n'a pas violé la définition cohérente forte et a réussi la vérification.
Si la valeur obtenue par la lecture du client 3 est 4, alors le système entier n'est pas fortement cohérent, car selon l'analyse précédente, la valeur de la dernière écriture réussie est 1, tandis que le client 3 lit 4, Il s'agit d'une valeur expirée, qui viole la cohérence linéaire. En fait, Jepsen utilise également un algorithme similaire pour vérifier si le système distribué répond à une forte cohérence.
Trouvez le problème correspondant grâce à la vérification de cohérence de Jepsen
Présentons d'abord brièvement le processus de traitement d'une demande dans Nebula Raft (en prenant trois exemplaires comme exemple) afin de mieux comprendre les problèmes ultérieurs. La demande de lecture est relativement simple. Comme le client n'enverra la demande qu'au leader, le nœud leader n'a besoin que d'obtenir le résultat correspondant directement à partir de la machine d'état et de le renvoyer au client sous l'hypothèse qu'il est le leader.
Le processus de demande d'écriture est plus compliqué, comme le montre le diagramme du groupe de radeaux:
Le leader (cercle vert sur la figure) reçoit la demande envoyée par le client et l'écrit dans son propre wal (écrire le journal d'avance).
Le chef envoie l'entrée de journal correspondante en wal au suiveur et entre dans l'attente.
Une fois que le suiveur a reçu l'entrée de journal, il l'écrit dans son propre wal (n'attend pas qu'elle soit appliquée à la machine d'état) et renvoie le succès.
Une fois que le leader a reçu au moins un abonné et qu'il a réussi, il s'applique à la machine d'état et envoie une réponse au client.
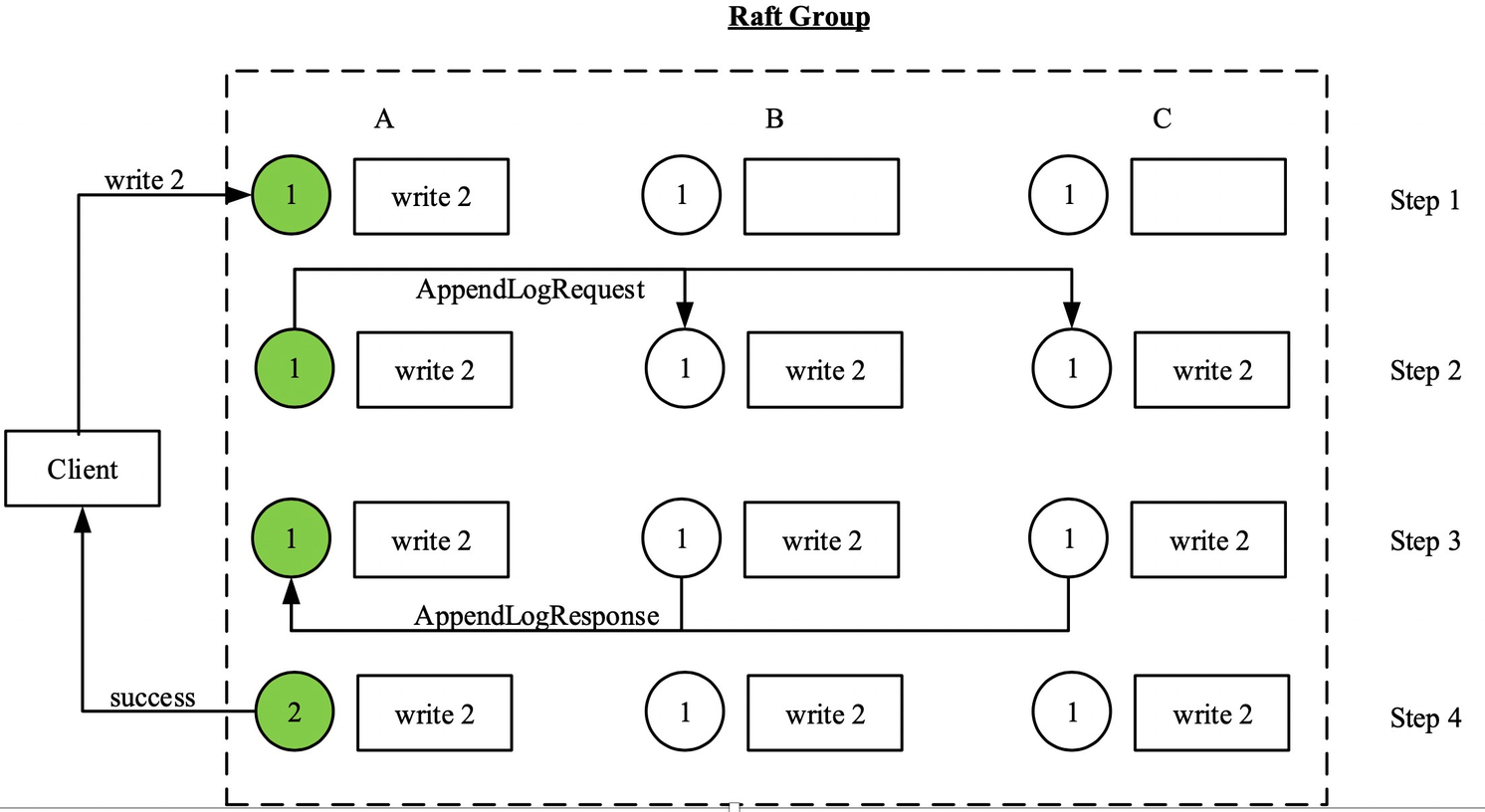
Ci-dessous, j'utiliserai des exemples pour illustrer les problèmes de cohérence trouvés dans la précédente mise en œuvre de Raft via les tests Jepsen:
Comme le montre la figure ci-dessus, ABC forme un groupe de radeaux à trois copies, le cercle est la machine d'état (pour simplifier, il est supposé être un registre unique) et l'entrée de journal correspondante est enregistrée dans la boîte.
Dans l'état initial, les machines d'état dans les trois copies sont toutes 1, le leader est A et le terme est 1
Le client envoie une demande d'écriture 2, et le responsable la traite selon le processus ci-dessus et est tué après avoir informé le client que l'écriture a réussi. (Une fois l'étape 4 terminée)
Après cela, C a été sélectionné comme leader du terme 2, mais parce que C n'a peut-être pas appliqué l'entrée de journal de l'écriture précédente 2 à la machine d'état à ce moment (la machine d'état est toujours 1). Si C reçoit une demande de lecture du client à ce moment, alors C renverra directement 1. Cela viole la définition de cohérence forte et a réussi à écrire 2 auparavant, mais a lu le résultat expiré.
Le problème est qu'après que C est sélectionné comme leader du terme 2, le battement de cœur doit être envoyé pour garantir que l'entrée de journal du terme précédent est acceptée par la plupart des nœuds. Avant que ce battement de cœur réussisse, il ne peut pas fournir de lecture externe (sinon il peut lire des données expirées) . Les étudiants intéressés peuvent se référer à la figure 8 et à la section 5.4.2 dans le raft parer.
En partant de la question précédente, nous avons trouvé une autre question connexe via Jepsen: comment le leader s'assure-t-il qu'il est toujours le leader? Ce problème se produit souvent dans les partitions réseau. Lorsque le leader n'est pas en mesure de communiquer avec d'autres nœuds en raison de problèmes de réseau et est isolé, à ce stade, si la demande de lecture est toujours autorisée à être traitée, il est possible de lire la valeur expirée. Pour cela, nous avons introduit le concept de bail leader.
Une fois qu'un nœud est sélectionné en tant que leader, le nœud doit envoyer régulièrement des battements de cœur à d'autres nœuds. Si le battement de cœur confirme que la plupart des nœuds l'ont reçu, il obtiendra un bail pour une période de temps et s'assurera qu'aucun nouveau leader n'apparaîtra pendant ce temps. , Ce qui garantit que les données du nœud doivent être à jour, afin que les requêtes de lecture puissent être traitées normalement pendant cette période.
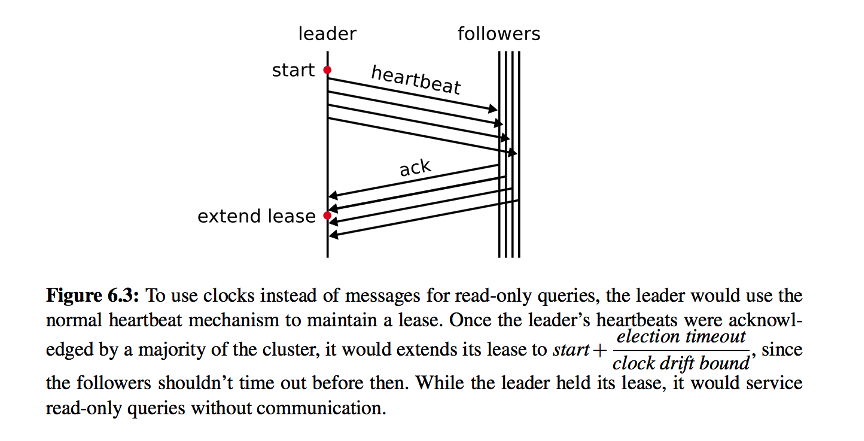
Différent de la méthode de traitement de TiKV, nous n'avons pas pris l'intervalle de battement de cœur multiplié par le coefficient comme le temps de location, compte tenu principalement du problème de la dérive d'horloge différente de différentes machines. Au lieu de cela, il enregistre le coût en temps du dernier battement de cœur ou appendLog réussi, et soustrait le coût de l'intervalle de battement de cœur pour être la durée du bail. Hôpital d'insémination artificielle de Zhengzhou: http://jbk.39.net/yiyuanfengcai/tsyl_zztjyy/3102/
Lorsque la partition réseau se produit, le leader est toujours isolé, mais il peut toujours gérer les demandes de lecture pendant cette période de bail (pour les demandes d'écriture, le client sera informé de l'échec d'écriture en raison de l'isolement), et il retournera l'échec après la durée du bail. Lorsque le suiveur ne reçoit pas de message du leader pendant au moins un intervalle de pulsation, il lance une élection et sélectionne un nouveau leader pour traiter les demandes des clients ultérieurs.
Conclusion
Pour un système distribué, de nombreux problèmes nécessitent une longue période de tests de stress et de simulation de pannes. Grâce à Jepsen, le système distribué peut être vérifié sous différents défauts d'injection. Plus tard, nous envisagerons également d'utiliser d'autres outils d'ingénierie du chaos pour vérifier le graphique de la nébuleuse et améliorer continuellement les performances en supposant une fiabilité élevée des données.
Hôpital de Zhengzhou pour l'infertilité: http://mobile.03913882333.com/