Du point de vue de l'optimisation elle - même , BatchSize et le taux d'apprentissage (et l'impact de la stratégie de réduction du taux d'apprentissage) dans la formation en apprentissage profond sont les
paramètres les plus importants qui affectent la convergence des performances du modèle.
Le taux d'apprentissage affecte directement l'état de convergence du modèle et la taille par lots affecte les performances de généralisation du modèle. Les deux sont directement liés au numérateur et au dénominateur et peuvent également s'influencer mutuellement.
Annuaire d'articles
- 1 L'effet de Batchsize sur les résultats d'entraînement (même nombre de tours d'époque)
- Comparaison des résultats
- 1. Alexnet 2080s train_batchsize = 32, val_batchsize = 64。lr = 0,01 GHIMyousan
- 2. Alexnet 2080 train_batchsize = 64 , val_batchsize = 64 , lr = 0,01 GHIM-me 14k itera
- 3. Alexnet 2080s train_batchsize = 64 , val_batchsize = 64 , lr = 0,02 GHIM-yousan
- 4 Squeezenet 2080s train_bs = 64 val-bs = 64 lr 0,01 GHIMyousan
- 4- Expérience de répétabilité Squeezenet 2080s train_bs = 64 val-bs = 64 lr 0,01 GHIM-me, le résultat est toujours surajusté 87% acc
- 5 == mobilenetv1 2080s t-bs: 64, v-bs: 64 lr: 0,01, GHIM-me == sur-ajustement
- 5 == mobilenetv2 2080s t-bs: 64, v-bs: 64 lr: 0,01, GHIM-me == sur-ajustement
- 6 mobilenetv1 2080 t-bs: 64 v-bs: 64 lr: 0,01 GHIM-me équipée
- 6 mobilenetv2 2080 t-bs: 64 v-bs: 64 lr: 0,01 GHIM-me équipée
- 10 prédécesseurs parlent de batchsize
- 1 ** Dans une certaine plage, d'une manière générale, plus le Batch_Size est grand, plus la direction vers le bas qu'il détermine est précise et plus l'oscillation d'entraînement sera petite. **
- 2 == Les performances des lots de grande taille sont réduites car le temps de formation n'est pas assez long, ce qui n'est pas essentiellement un problème avec la taille de lot. Les mises à jour des paramètres sous les mêmes époques sont réduites, donc un nombre d'itérations plus long est nécessaire. ==
- 3 == La grande taille de lot converge vers le minimum net, tandis que la petite taille de lot converge vers le minimum plat, qui a une meilleure capacité de généralisation. ==
- 4 La taille des lots augmente, le taux d'apprentissage devrait augmenter avec les autres
- 5 Augmenter la taille de Batchsize équivaut à ajouter une atténuation du taux d'apprentissage
- Conclusion
- 1 Si le taux d'apprentissage est augmenté, la taille du lot doit également augmenter, afin que la convergence soit plus stable.
- 2 Essayez d'utiliser un taux d'apprentissage élevé, car de nombreuses études ont montré qu'un taux d'apprentissage plus élevé est propice à l'amélioration de la capacité de généralisation. Si vous voulez vraiment vous désintégrer, vous pouvez essayer d'autres méthodes, comme augmenter la taille du lot, le taux d'apprentissage a un grand impact sur la convergence du modèle et l'ajuster soigneusement.
- 3 L'inconvénient de l'utilisation de bn est que vous ne pouvez pas utiliser une taille de lot trop petite, sinon la moyenne et la variance seront biaisées. Alors maintenant, c'est généralement autant que la mémoire vidéo peut en contenir. De plus, lorsque le modèle est réellement utilisé, il est vraiment plus important de distribuer et de prétraiter les données. Si les données ne sont pas bonnes, il est inutile de jouer d'autres tours.
1 L'effet de Batchsize sur les résultats d'entraînement (même nombre de tours d'époque)
Ici, nous utilisons GHIM-20, 20 images de chaque type dans 20 catégories, un total de 10000 (train9000) (val1000) et
un total de 100 époques (équivalent à parcourir 10000 images 100 fois, dont acc (la traversée est imprimée 10 fois par itération) Un total de 1000 val_list)

Alexnet utilisé ici (train_batchsize = 32 et train_batchsize = 64 respectivement)
Comparaison des résultats
1. Alexnet 2080s train_batchsize = 32, val_batchsize = 64。lr = 0,01 GHIMyousan
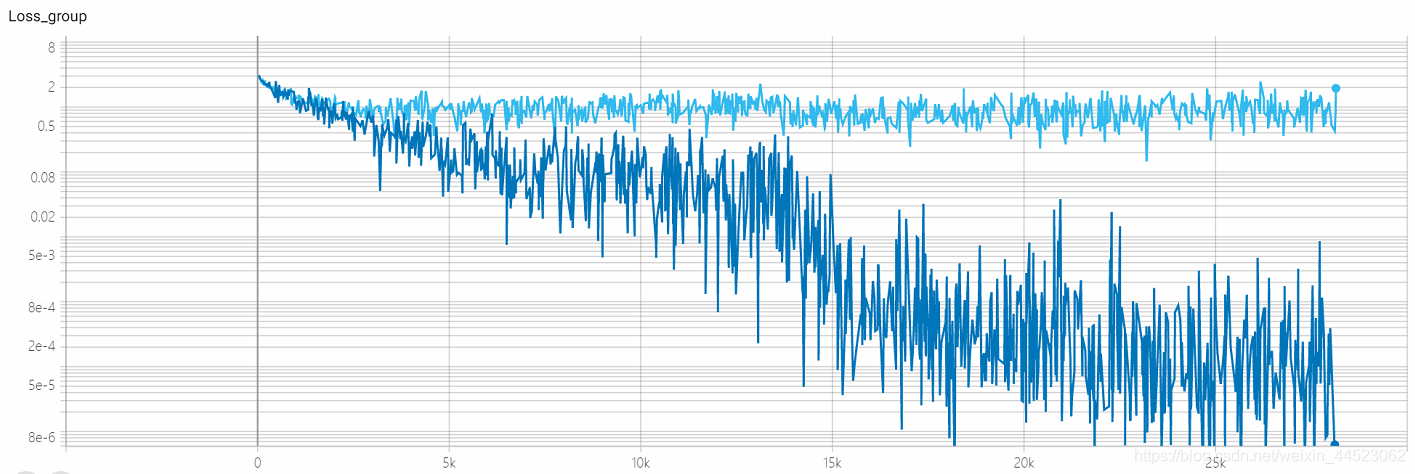
- Formation des années 2080 s 4.68h, près de 28k itérations == 100époque x 9000/32, chaque train-lot enregistre une perte bleu foncé
- val-batch enregistre un val-loss bleu clair
Question: la perte est-elle convergente?
la perte d'acc est toujours plus grande que la perte de train pour voir qu'il s'agit d'un problème de surajustement
Vérifié quelques réponses
1. Théoriquement, il ne converge pas , c'est-à-dire qu'il y a un problème avec le réseau que vous avez conçu, qui est aussi le premier facteur à considérer: si le gradient existe, c'est-à-dire si la propagation arrière s'est rompue;
2. Théoriquement, il est convergent :-
Le paramètre de taux d'apprentissage est déraisonnable (dans la plupart des cas) .Si le paramètre de taux d'apprentissage est trop élevé, il provoquera une non-convergence.Si il est trop petit, il entraînera un taux de convergence très lent;
-
La taille de lot est trop grande, elle tombe dans l'optimum local et ne peut pas atteindre l'optimum global, elle ne peut donc pas continuer à converger;
-
La capacité du réseau, il est certain que la perte du réseau peu profond pour effectuer des tâches complexes ne diminue pas. La conception du réseau est trop simple. En général, plus le nombre de couches et le nombre de nœuds dans le réseau sont grands, plus la capacité d'ajustement est forte. Si le nombre de couches et de nœuds n'est pas suffisant , Impossible de s'adapter à des situations complexes, provoquera également la non-convergence.
La base de la diminution du pas du taux d'apprentissage n'est pas trop grande, et la taille de lot = 32 n'est pas grande, donc elle est convergée? ? (Après tout, la perte = 0,0008 n'est pas trop grande.) La
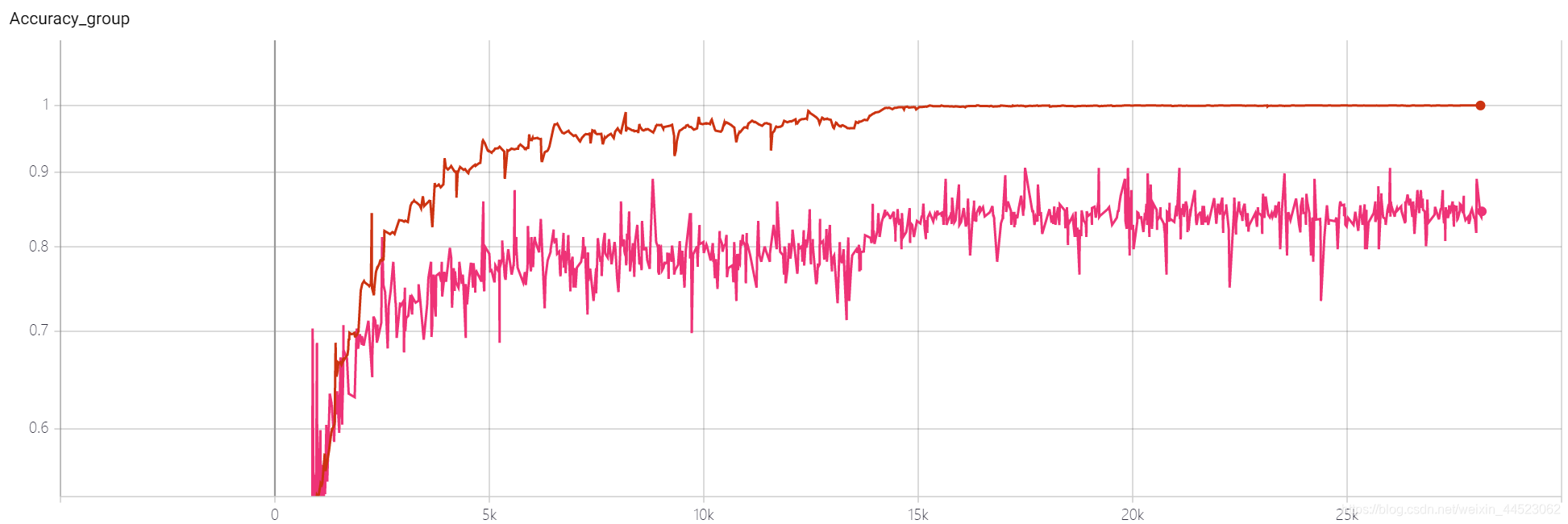
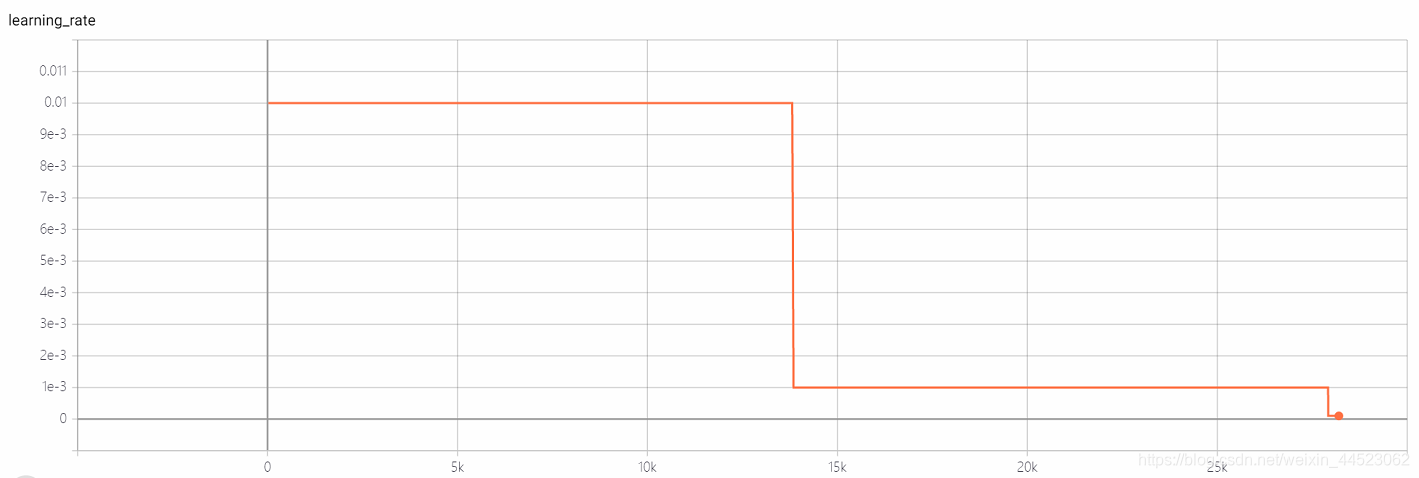
courbe acc est la suivante: elle est essentiellement ajustée après avoir regardé l'image après 15k itérations (c'est-à-dire, epoch = 15000 * 32/9000 = 53 tours). Ce qui est intéressant, c'est que cela correspond à l'apprentissage à ce moment. Le taux est passé de 0,01 à 0,001
Question: Pourquoi l'acc84% de val ne monte-t-il pas
L'ensemble d'apprentissage fonctionne bien et la différence entre les ensembles de tests est trop élevée, ce qui indique que les fonctionnalités apprises ne sont pas encore suffisamment généralisées.
Quelle couche de fonctionnalités d'apprentissage n'est pas assez bonne?
Solution de sur-ajustement
1. Raison:- La raison du surajustement est que l’ampleur de l’ensemble d’entraînement ne correspond pas à la complexité du modèle,
- L'amplitude de l'ensemble d'apprentissage est inférieure à la complexité du modèle;
- La distribution des fonctionnalités de l'ensemble de formation et de l'ensemble de test est incohérente;
- Les données de bruit dans l'échantillon ...
2. Solution
(structure du modèle plus simple, augmentation des données, régularisation, abandon, arrêt précoce, ensemble, données de nettoyage)
-
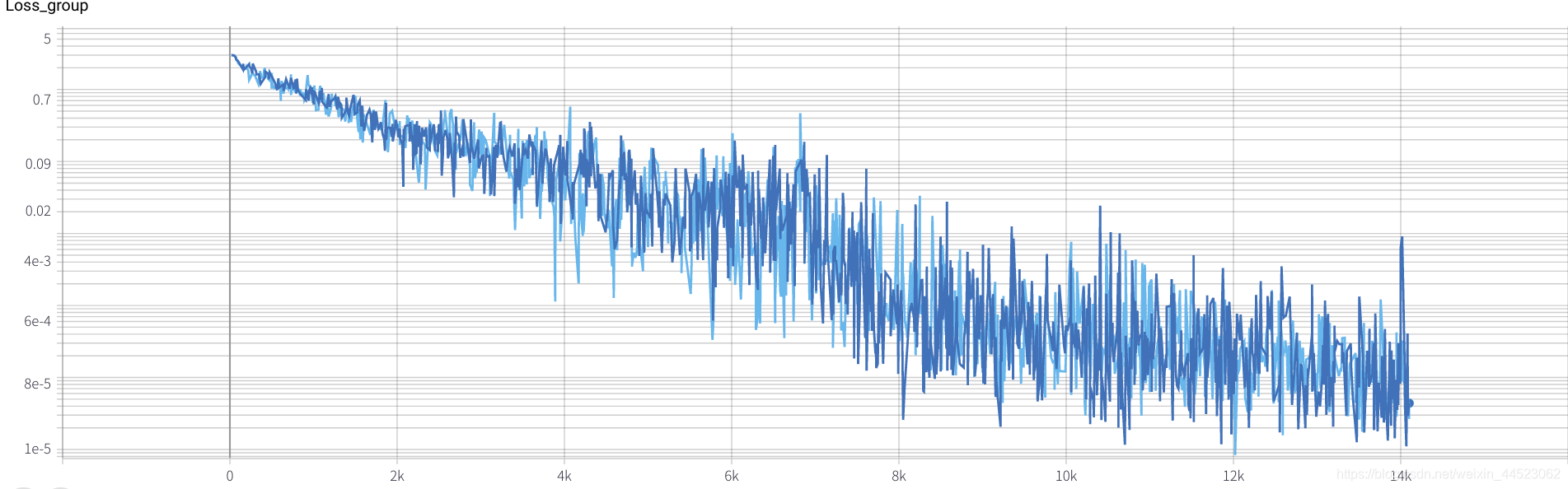
2. Alexnet 2080 train_batchsize = 64 , val_batchsize = 64 , lr = 0,01 GHIM-me 14k itera
2080 train_batchsize = 64, l'itération de 4,5 km est essentiellement adaptée (4500 * 64/9000 = 32 tours), et train et val sont meilleurs. Et le montage est bon
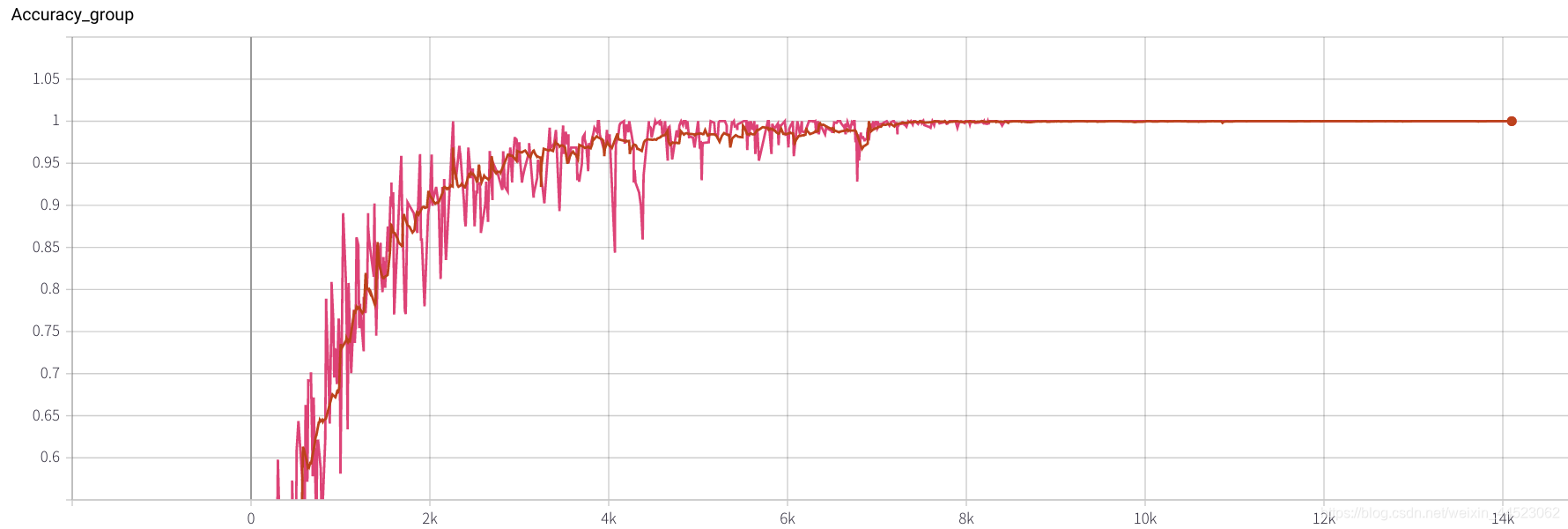
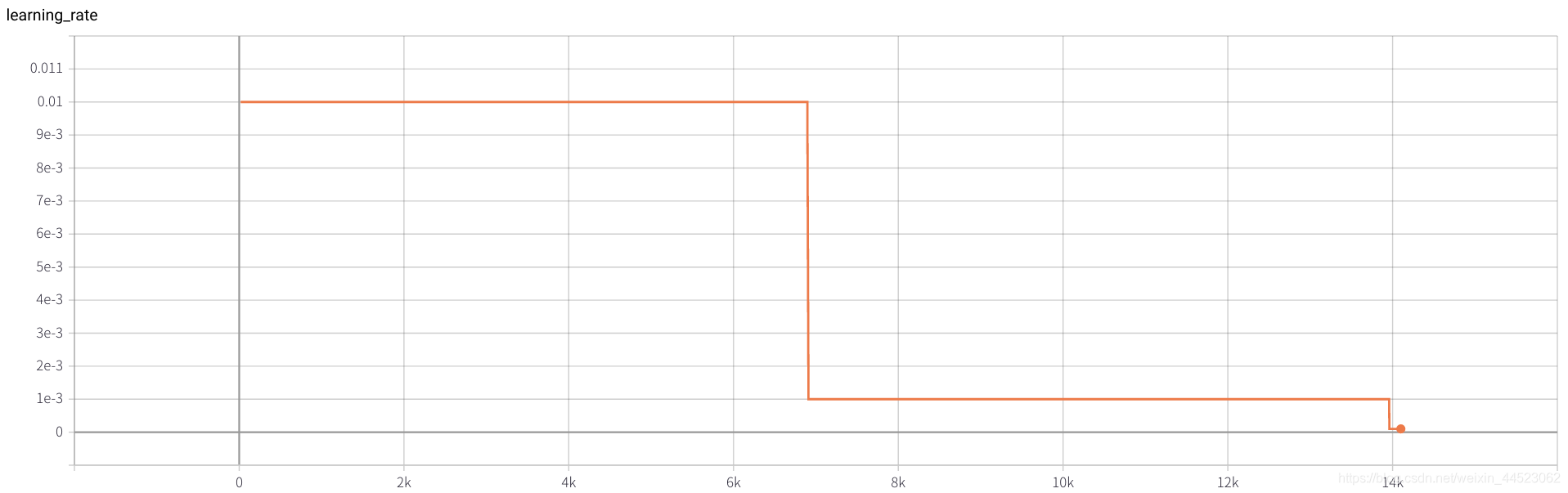
3. Alexnet 2080s train_batchsize = 64 , val_batchsize = 64 , lr = 0,02 GHIM-yousan
Années 2080, pas de convergence ou de surajustement? ? ?
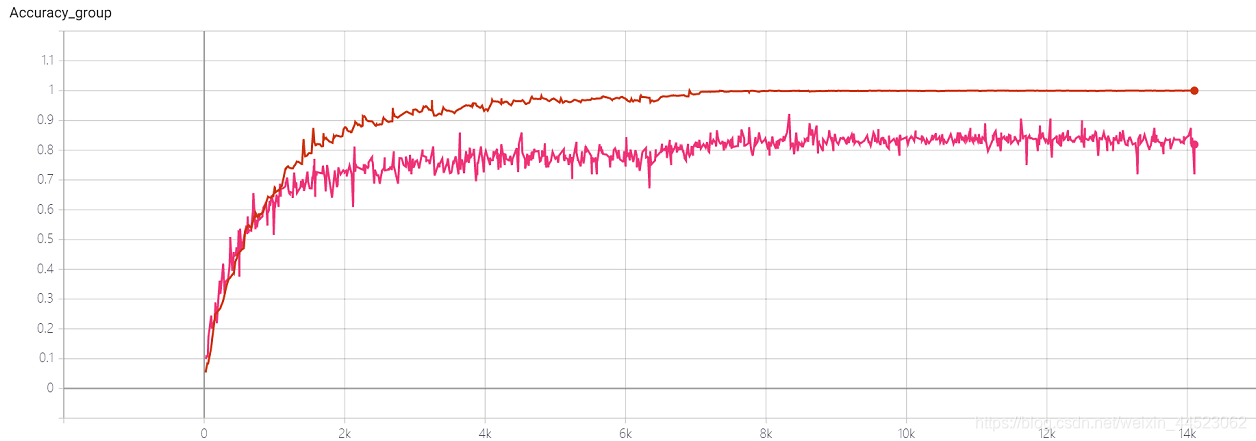
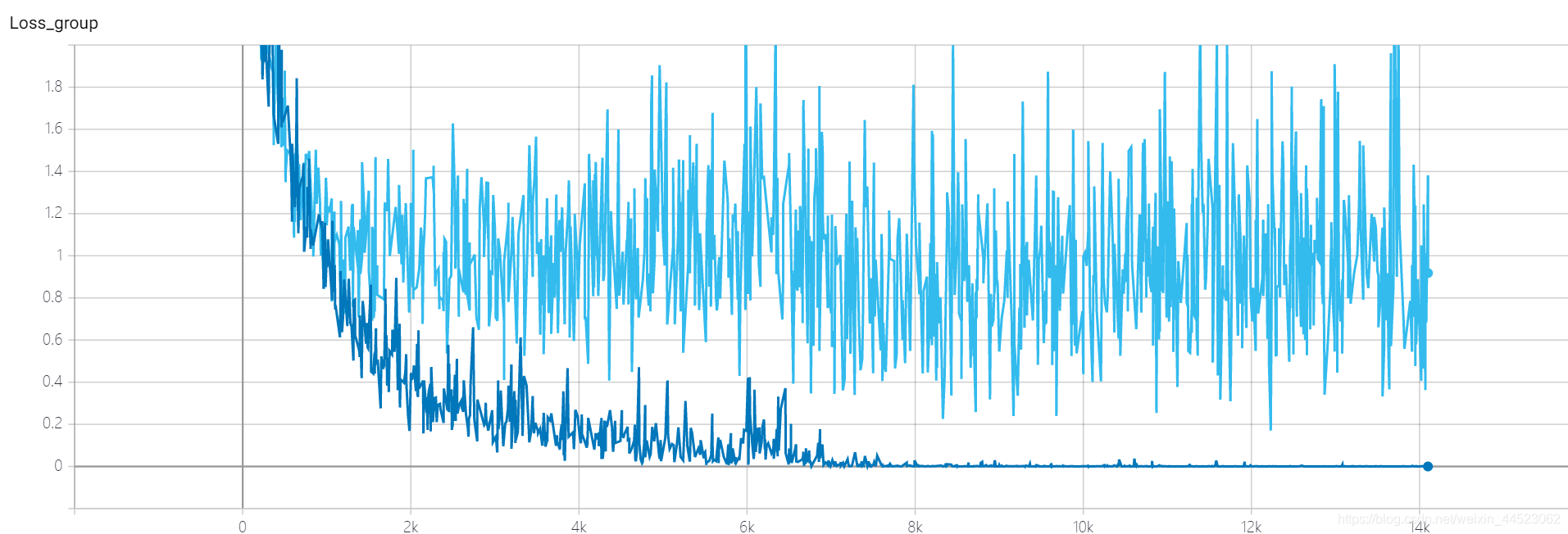
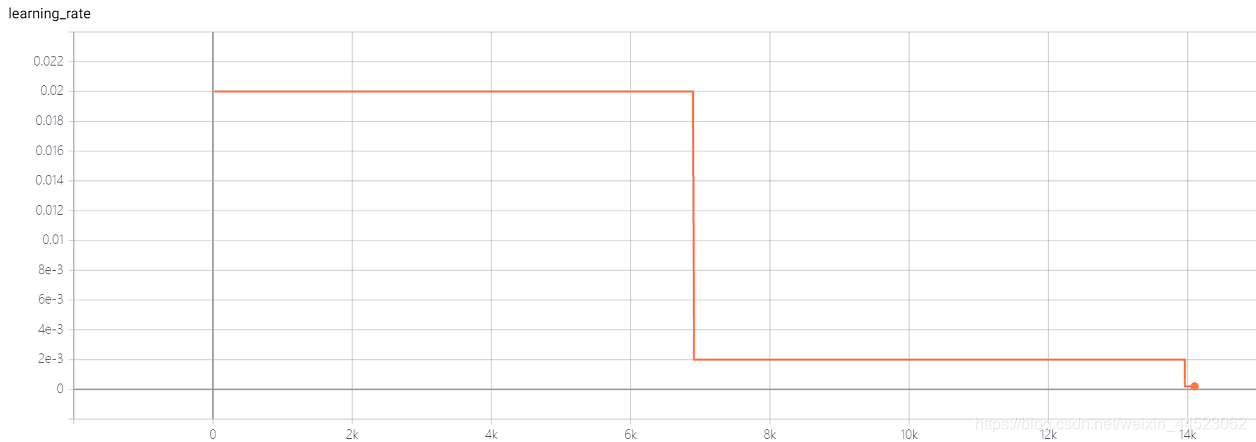
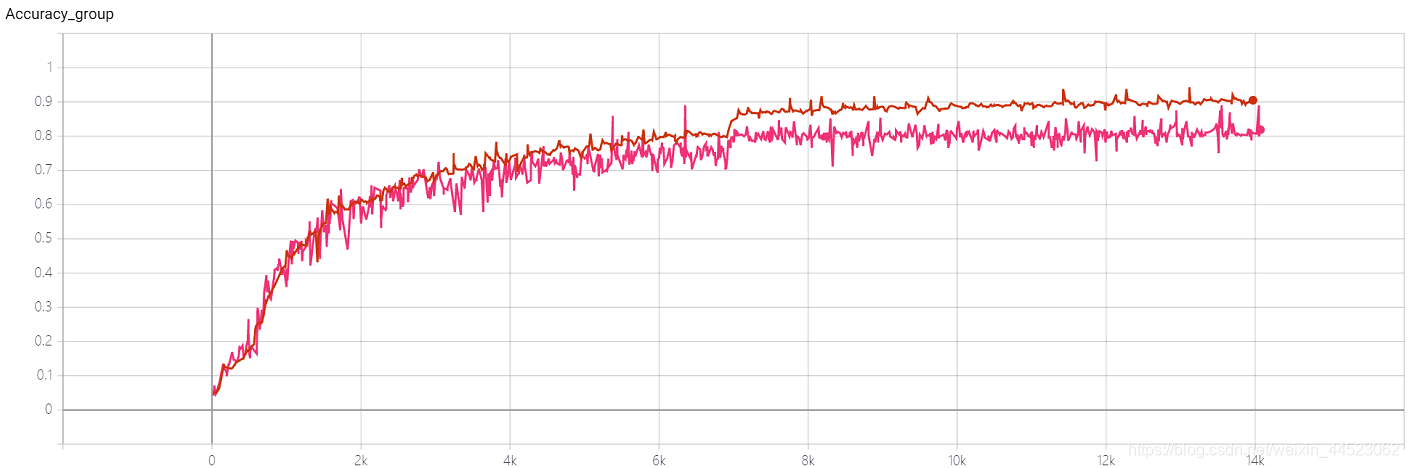
4 Squeezenet 2080s train_bs = 64 val-bs = 64 lr 0,01 GHIMyousan

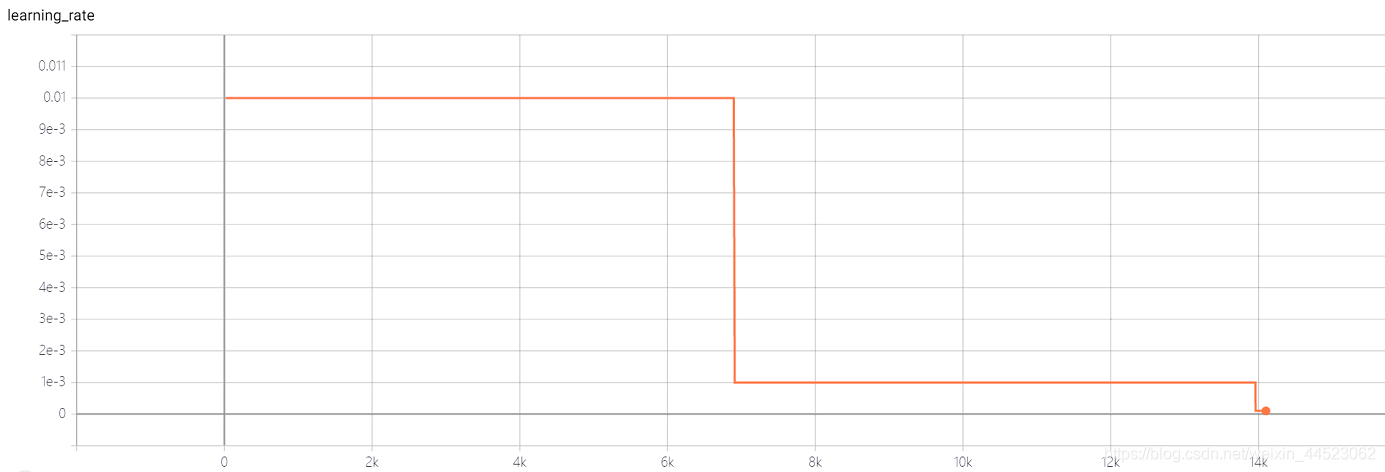
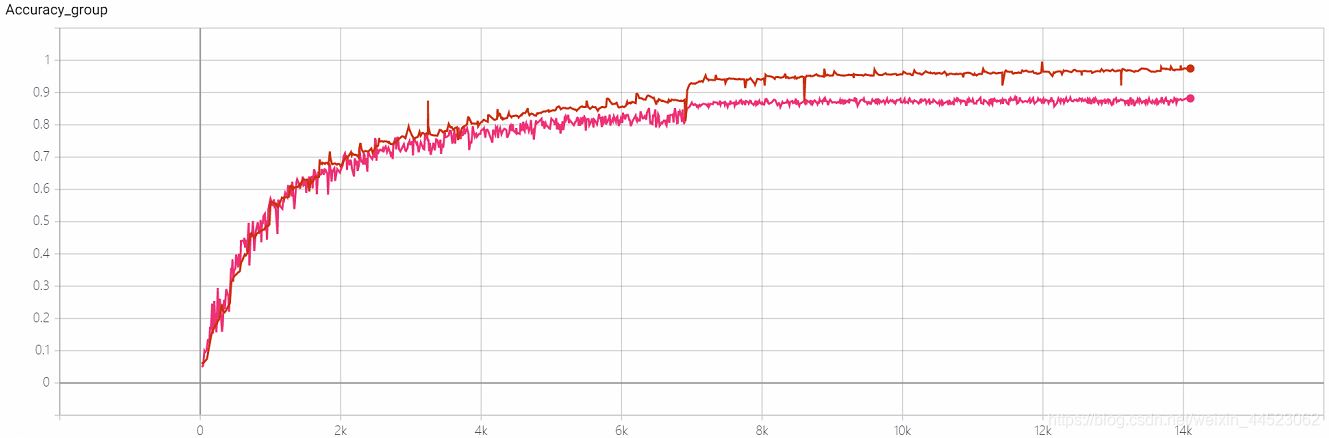
4- Expérience de répétabilité Squeezenet 2080s train_bs = 64 val-bs = 64 lr 0,01 GHIM-me, le résultat est toujours surajusté 87% acc
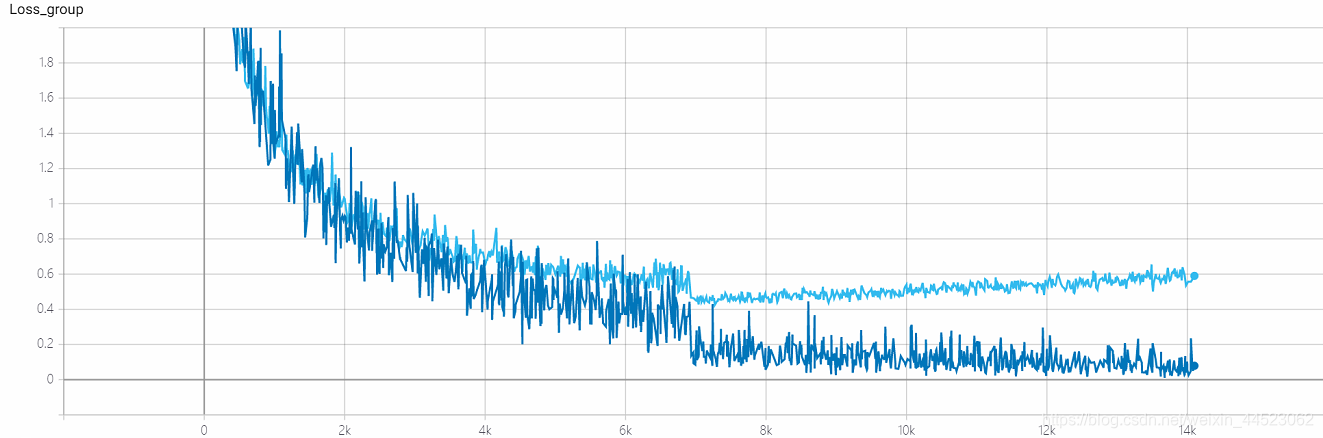
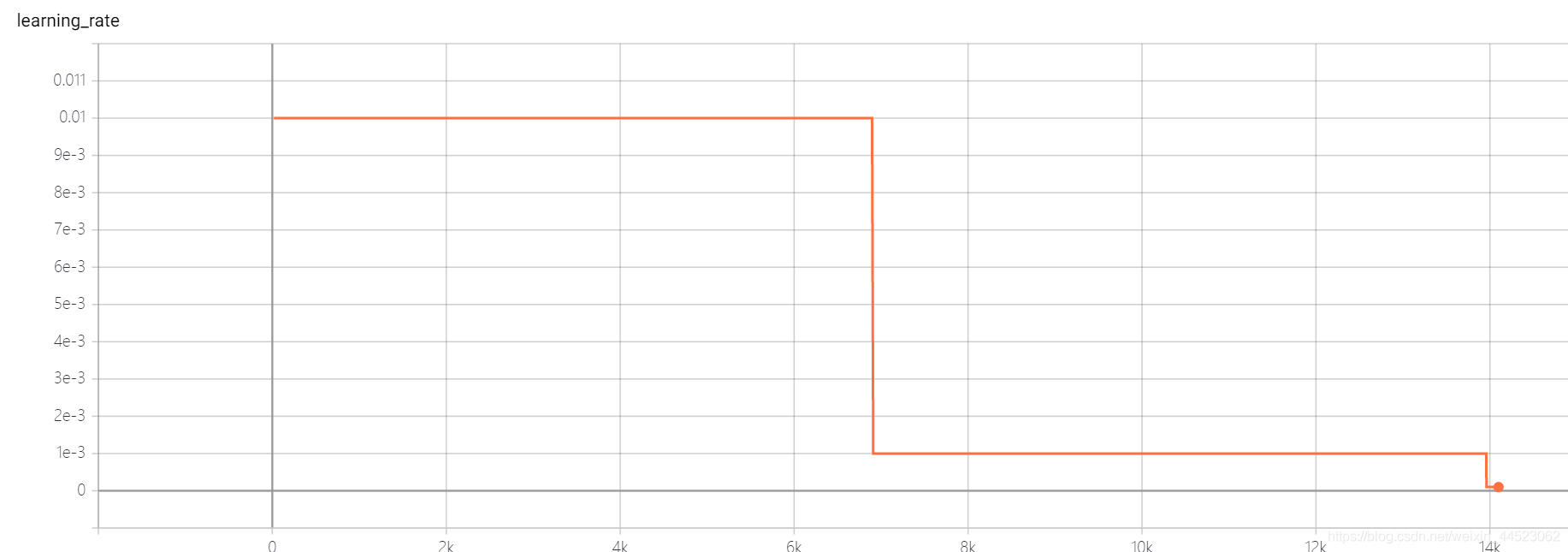
5 mobilenetv1 2080s t-bs: 64, v-bs: 64 lr: 0,01, GHIM-meSur-ajustement
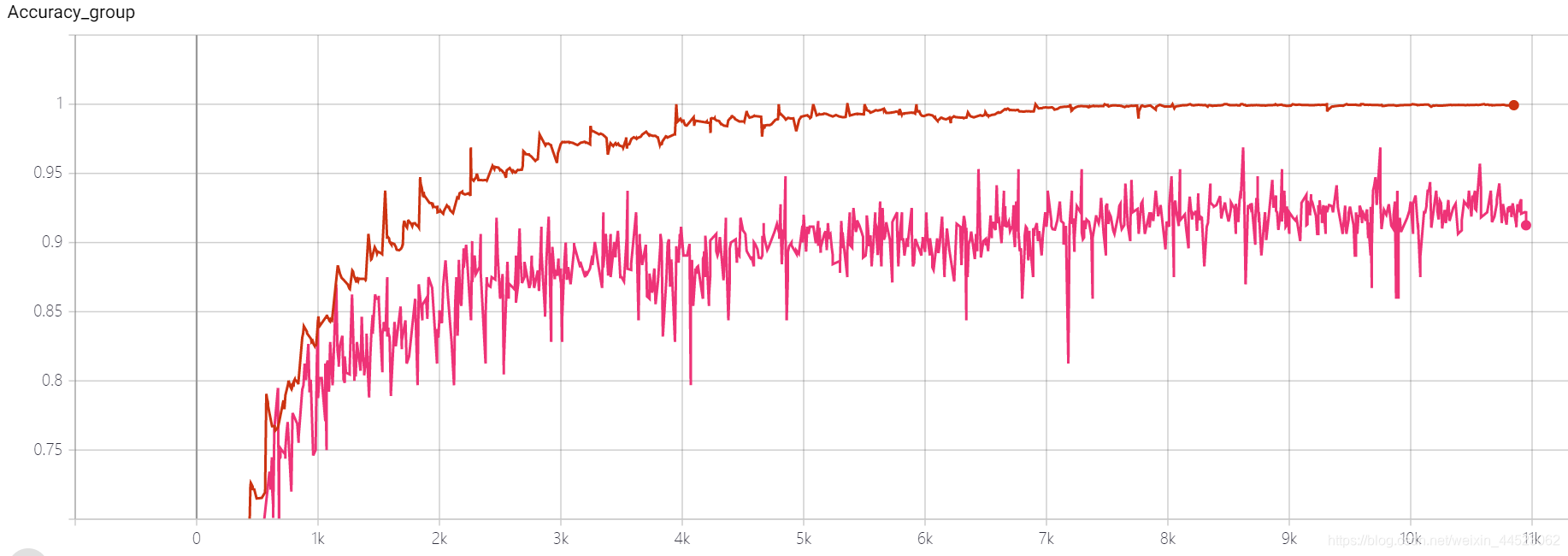
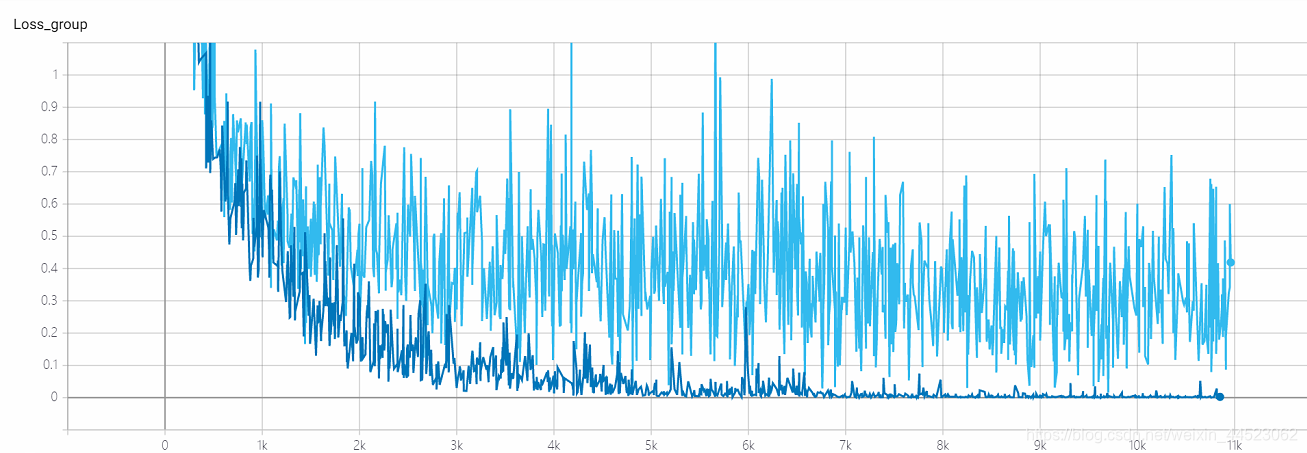
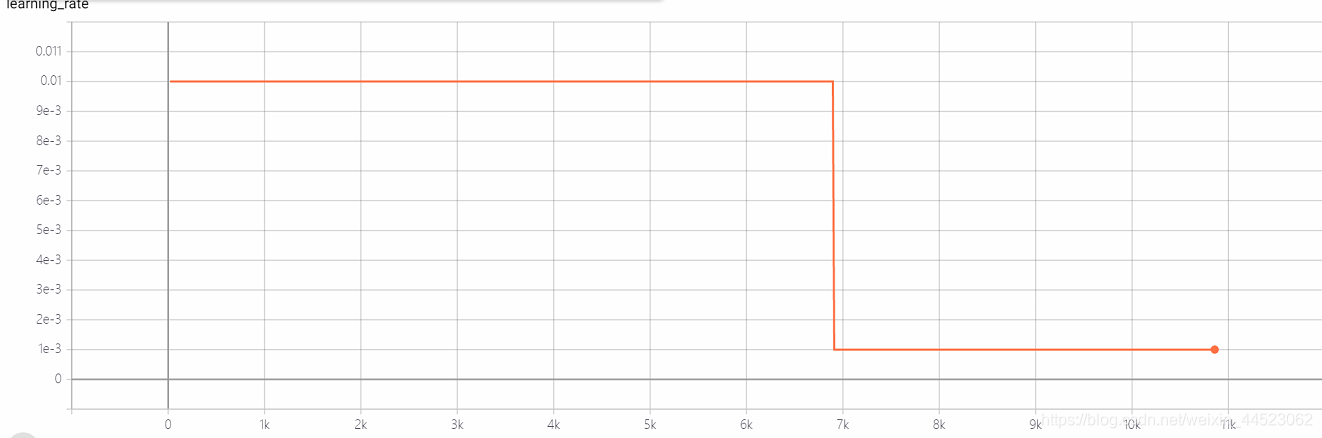
5 mobilenetv2 2080s t-bs: 64, v-bs: 64 lr: 0.01, GHIM-meSur-ajustement
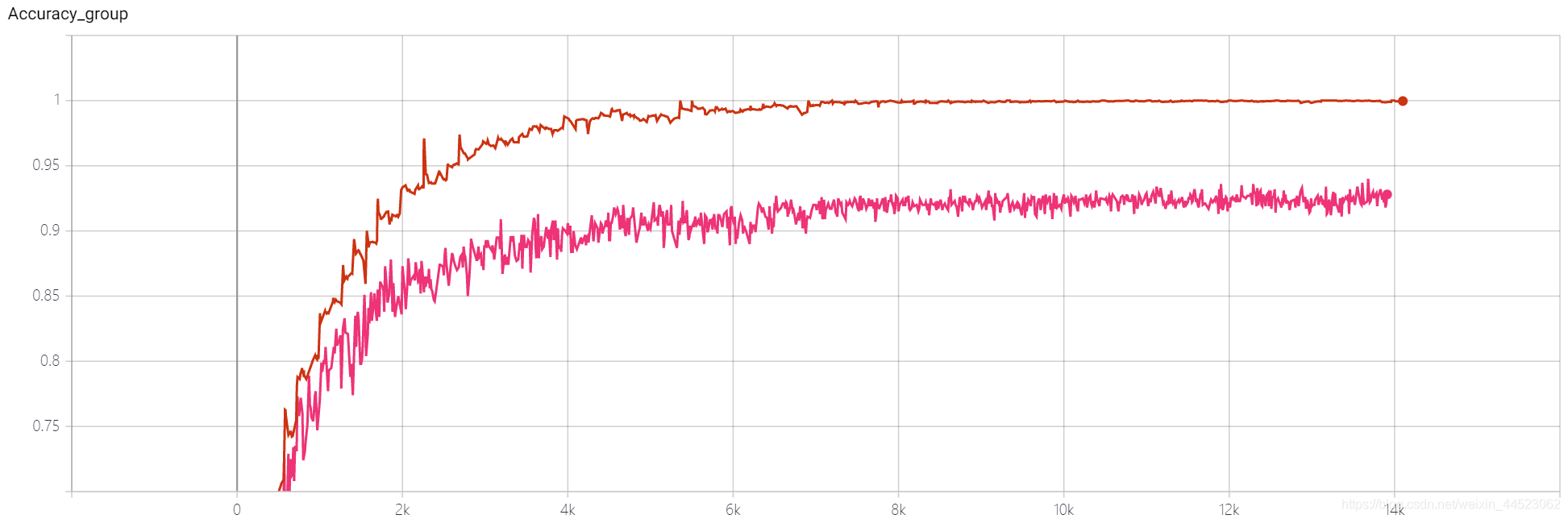
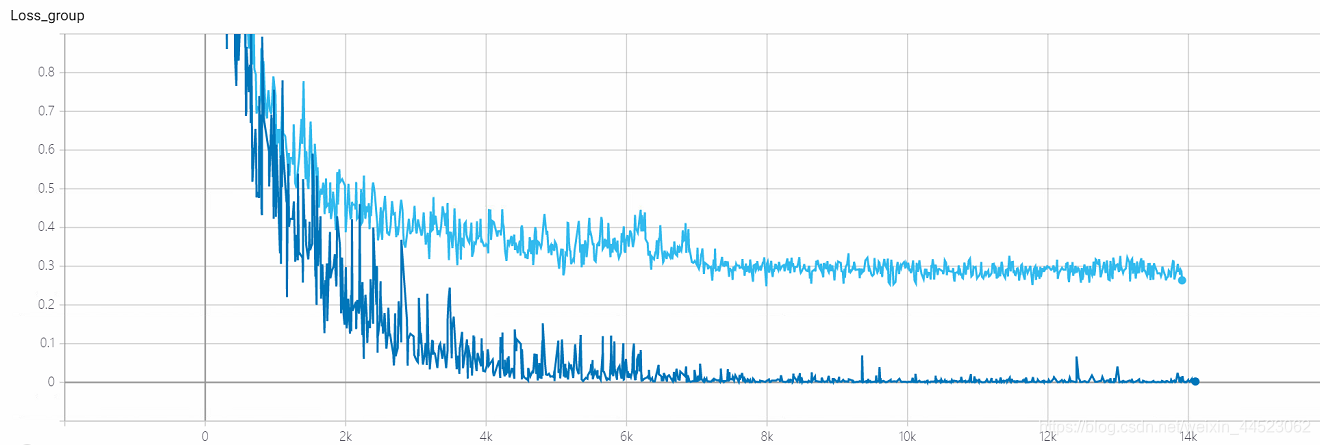
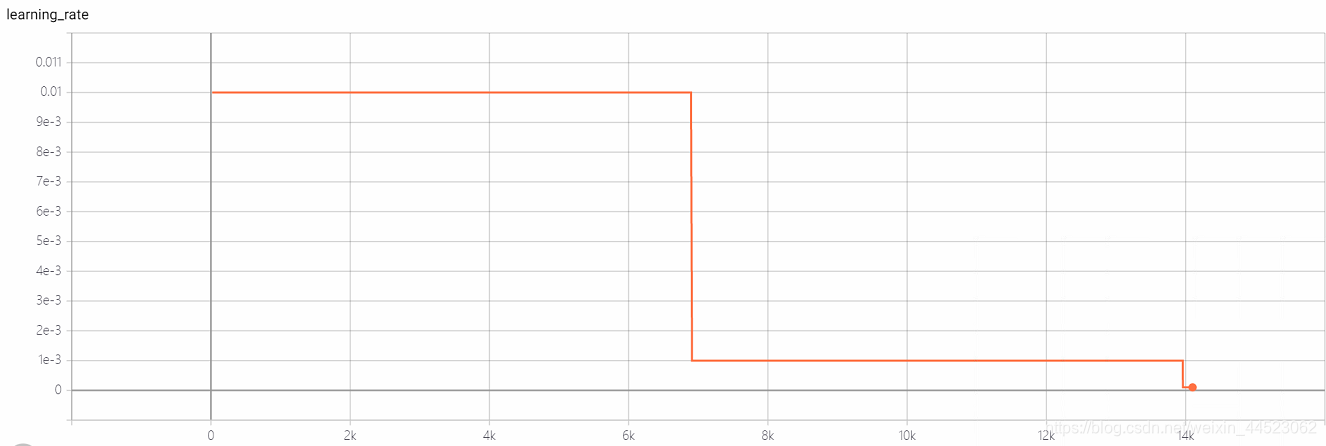
6 mobilenetv1 2080 t-bs: 64 v-bs: 64 lr: 0,01 GHIM-me équipée
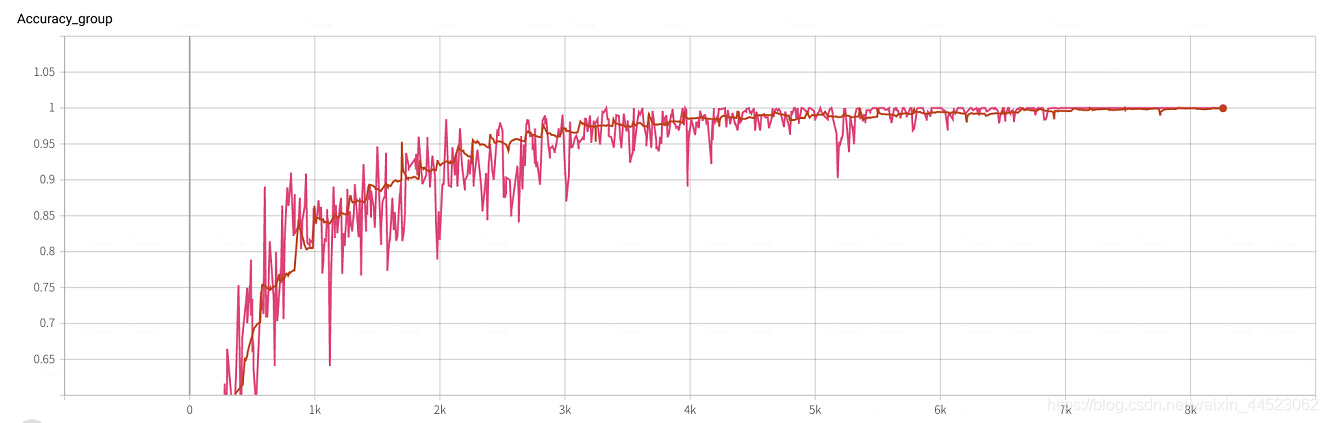

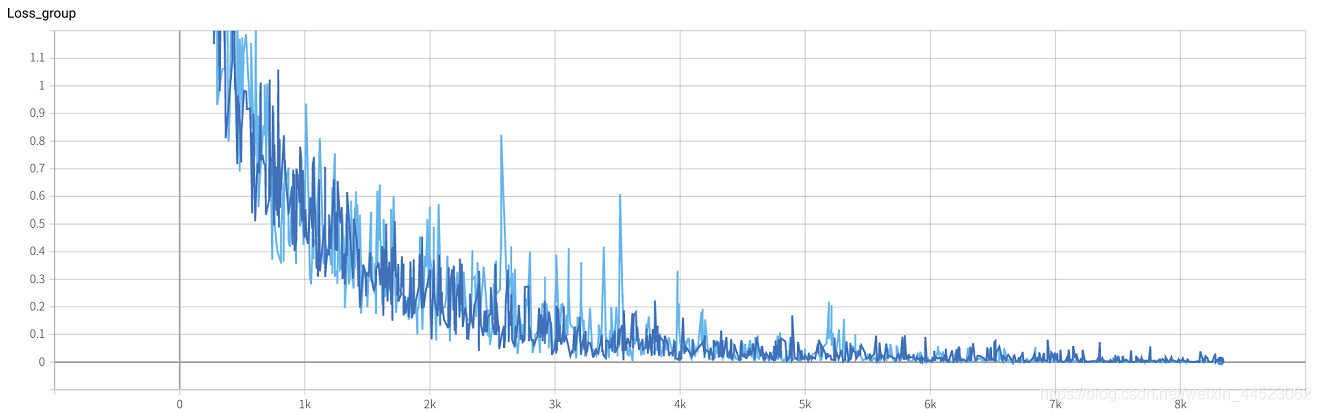
6 mobilenetv2 2080 t-bs: 64 v-bs: 64 lr: 0,01 GHIM-me équipée
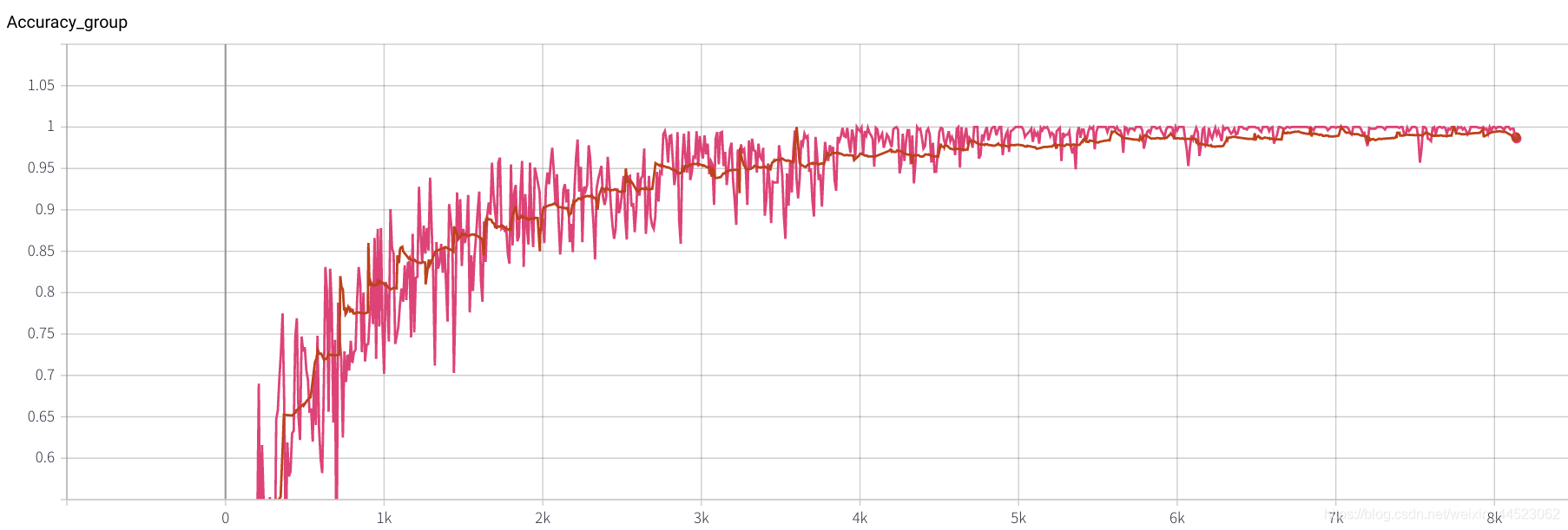
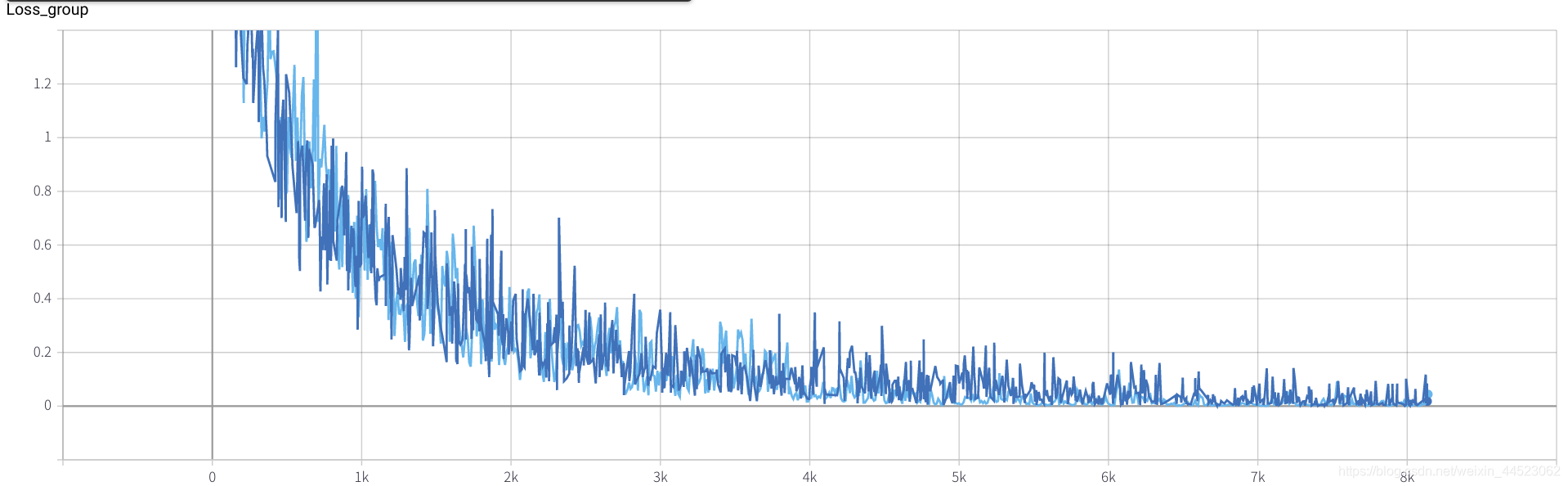
lr = 0,01
10 prédécesseurs parlent de batchsize
1 Dans une certaine plage, d'une manière générale, plus le Batch_Size est grand, plus la direction vers le bas qu'il détermine est précise, ce qui entraîne moins de choc d'entraînement.
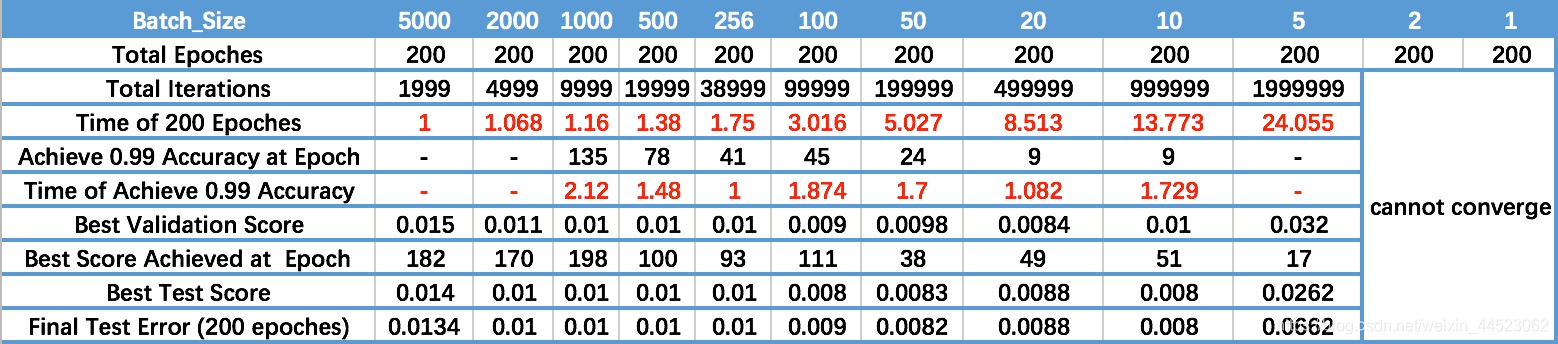
- À mesure que Batch_Size augmente, le nombre d'époques nécessaires pour obtenir la même précision augmente. Avant-dernière ligne
- À mesure que Batch_Size augmente, plus le traitement de la même quantité de données est rapide.
- En raison de la contradiction entre les deux facteurs ci-dessus, Batch_Size augmente jusqu'à un certain point, atteignant le moment optimal.
- Étant donné que la précision de convergence finale tombera dans différents extremums locaux, Batch_Size augmente à certains moments pour atteindre la précision de convergence finale optimale.
2 La baisse importante des performances de la taille de lot est due au fait que le temps de formation n'est pas assez long, ce qui n'est pas essentiellement un problème avec la taille de lot. La mise à jour des paramètres sous les mêmes époques devient moins, donc un nombre d'itérations plus long est nécessaire.
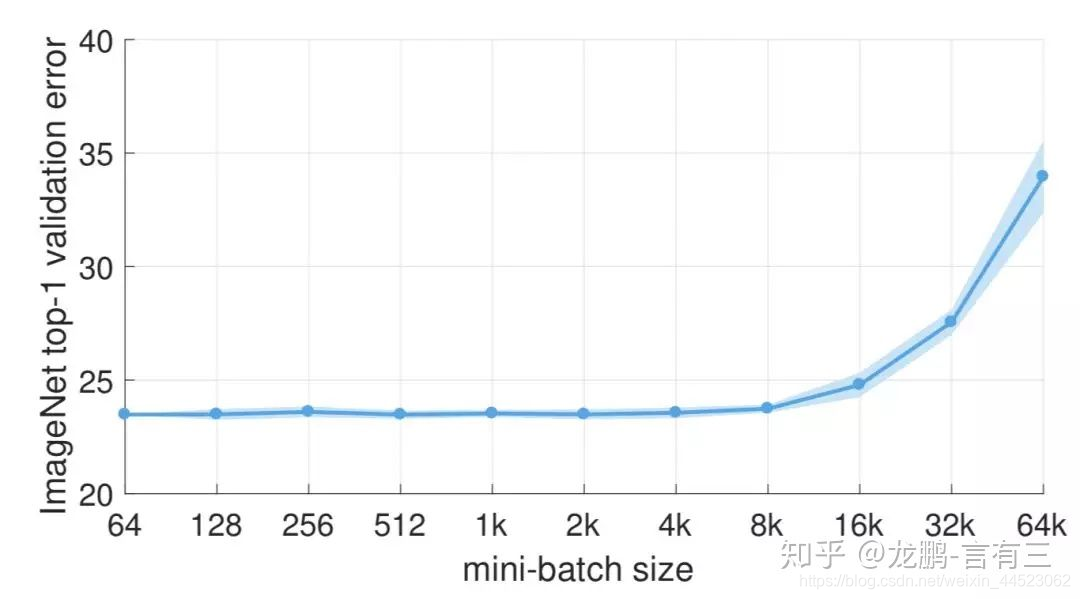
Le taux d'erreur augmente après batchsize = 8k
3 La grande taille de lot converge vers le minimum net, tandis que la petite taille de lot converge vers le minimum plat, qui a une meilleure capacité de généralisation.
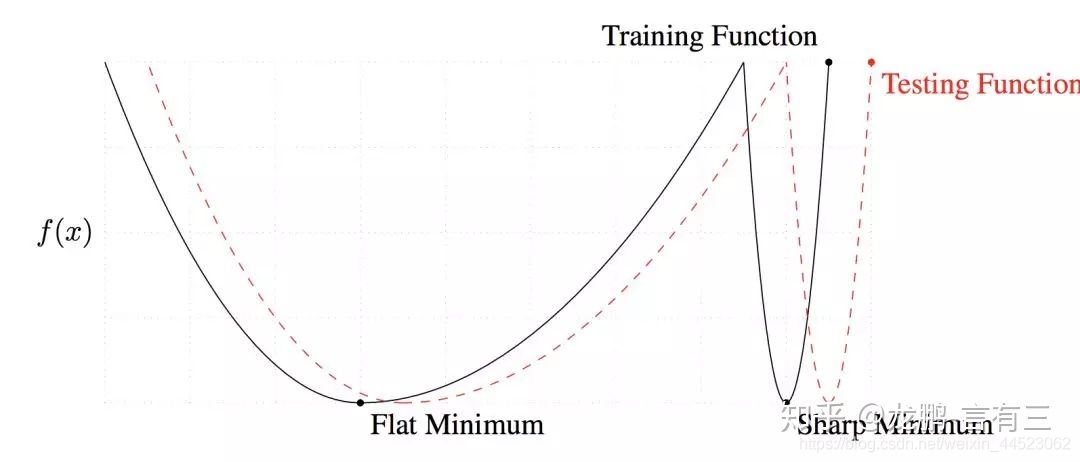
La différence entre les deux réside dans la tendance changeante, l'une rapide et l'autre lente, comme indiqué ci-dessus, la principale raison de ce phénomène est que le bruit causé par la petite taille de lot permet d'échapper au strict minimum.
4 La taille des lots augmente, le taux d'apprentissage devrait augmenter avec les autres
Habituellement, lorsque nous augmentons la taille du lot à N fois l'original, pour garantir que les poids mis à jour après le même échantillon sont égaux, selon la règle de mise à l'échelle linéaire, le taux d'apprentissage doit être augmenté aux N fois d'origine [5]. Cependant, si la variance des poids doit être maintenue, le taux d'apprentissage doit être augmenté aux temps sqrt (N) d'origine [7]. À l'heure actuelle, les deux stratégies ont été étudiées et la première est principalement utilisée.
5 Augmenter la taille de Batchsize équivaut à ajouter une atténuation du taux d'apprentissage
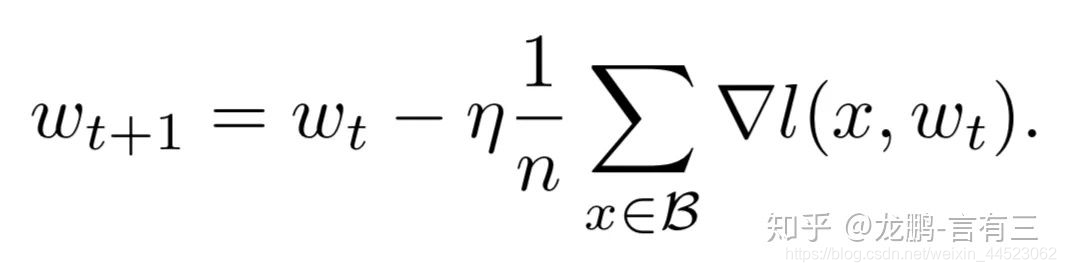
En fait, on peut voir à partir de la formule de mise à jour du poids de SGD que les deux sont en effet équivalents, et cela est vérifié par des expériences suffisantes dans l'article
Conclusion
1 Si le taux d'apprentissage est augmenté, la taille du lot doit également augmenter, afin que la convergence soit plus stable.
2 Essayez d'utiliser un taux d'apprentissage élevé, car de nombreuses études ont montré qu'un taux d'apprentissage plus élevé est propice à l'amélioration de la capacité de généralisation. Si vous voulez vraiment vous désintégrer, vous pouvez essayer d'autres méthodes, comme augmenter la taille du lot, le taux d'apprentissage a un grand impact sur la convergence du modèle et l'ajuster soigneusement.
3 L'inconvénient de l'utilisation de bn est que vous ne pouvez pas utiliser une taille de lot trop petite, sinon la moyenne et la variance seront biaisées. Alors maintenant, c'est généralement autant que la mémoire vidéo peut en contenir. De plus, lorsque le modèle est réellement utilisé, il est vraiment plus important de distribuer et de prétraiter les données. Si les données ne sont pas bonnes, il est inutile de jouer d'autres tours.
Lecture de référence
https://zhuanlan.zhihu.com/p/29247151
https://zhuanlan.zhihu.com/p/64864995
