Les algorithmes de filtrage collaboratif sont largement utilisés dans le domaine des algorithmes de recommandation, principalement basés sur l'utilisateur (UserCF) et sur les éléments (ItemCF) deux types différents:
- Algorithme de recommandation basé sur l'utilisateur: c'est un algorithme pour trouver des utilisateurs ayant des intérêts similaires. Si vous construisez une plate-forme de partage de ressources d'apprentissage, votre groupe d'utilisateurs a un passe-temps professionnel et relativement stable en lecture et apprentissage. Lorsque l'utilisateur A (c'est-à-dire l'utilisateur connecté) a besoin de recommandations personnalisées, il peut d'abord trouver un groupe d'utilisateurs G qui est similaire à ses intérêts, puis prédire et évaluer ce qui est inclus dans G mais pas dans A, et enfin en fonction de la valeur d'évaluation prédite. L'utilisateur A fait une recommandation.
- Algorithme de recommandation basé sur les éléments: lorsqu'un utilisateur a besoin d'une recommandation personnalisée, par exemple, parce qu'il a déjà acheté des fleurs, il lui recommandera des pots de fleurs, car de nombreux autres utilisateurs achètent des fleurs et des pots de fleurs en même temps. Les algorithmes de recommandation basés sur les éléments doivent d'abord calculer la similitude entre les éléments, puis générer une liste de recommandations pour l'utilisateur en fonction de la similitude de l'élément et du comportement historique de l'utilisateur.
L'auteur de cet article présentera la mise en œuvre du premier algorithme, l'algorithme de filtrage collaboratif basé sur l'utilisateur (UserCF). Comme mentionné ci-dessus, nous divisons les étapes en trois étapes:
1. Recherchez un groupe d'utilisateurs ayant des intérêts similaires à ceux de l'utilisateur A
- Tout d'abord, nous devons calculer la similitude entre les utilisateurs. Dans cet article, nous utilisons la similitude cosinus pour calculer, la formule est

(Où N (u) représente l'ensemble des articles achetés par l'utilisateur u, | N (u) | est le nombre d'articles achetés par lui, et N (v) est le même et fait l'objet de l'utilisateur v)
Calculer la partie dénominateur: nous construisons une matrice de similitude sparseMatrix, sparseMatrix [u] [v] représente le nombre d'articles identiques achetés par l'utilisateur u et l'utilisateur v
- Ensuite, nous trions la similitude des utilisateurs dans l'ordre décroissant et prenons uniquement les groupes d'utilisateurs les plus similaires dans le seuil
2. Prédisez et analysez ceux inclus dans G que A n'a pas entendus ou vus.
Dans le groupe d'utilisateurs similaires, les articles achetés par des utilisateurs similaires que je (utilisateurs connectés) ne possède pas sont obtenus en tant qu'articles avec prédictions. Parce que les utilisateurs qui partagent mes intérêts les ont achetés, je pourrais aussi les aimer. C'est le principe de UserCF. Pour que ces éléments soient prédits, nous devons effectuer une analyse de prédiction, la formule est:
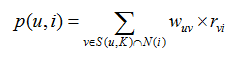
Où u est l'utilisateur, i est l'élément, (u, k) est le groupe similaire de l'utilisateur u, p (u, i) est la préférence de l'utilisateur pour l'élément i, r est la note, dans cet exemple, 1 Dans un système de notation, il joue un rôle dans l'ajustement des poids, ce qui rend les résultats plus précis.
3. Recommander A en fonction de la valeur d'analyse prévue
Selon l'analyse de l'utilisateur de la favorabilité des éléments prédits, une liste triée peut être générée après tri. Dans cet exemple, elle est plus concise et ne recommande que la plus appropriée.
Le code est le suivant:
#include<cstdio>
#include<cstring>
#include<cmath>
#include<iostream>
#include<algorithm>
#include<set>
using namespace std;
const int maxn = 100;
struct similarty{
double weight;
int user;
}similartys[maxn];
void myprint(int userItem[][maxn],int n){
for(int i=0;i<n;i++){
cout<<"用户"<<userItem[i][0]<<"买了:";
int j=1;
while(userItem[i][j]!='\0'){
cout<<userItem[i][j]<<" ";
j++;
}
cout<<endl;
}
cout<<"-----------"<<endl;
}
int length(int *array){
int num=0;
int p=1;
while(array[p]!='\0'){
num++;
p++;
}
return num;
}
bool myfind(int userItem[][maxn],int user,int n){
for(int i=1;i<=length(userItem[user-1]);i++){
if(userItem[user-1][i]==n) return true;
}
return false;
}
bool cmp(similarty a,similarty b){
return a.weight>b.weight;
}
int main(){
int n=5; //用户人数
int userId=3; //推荐给userId
int num=2; //匹配用户个数
cout<<"用户人数:"<<n<<" "<<"登录id:"<<userId<<endl<<"具体情况:"<<endl;
//数据集
int userItem[n][maxn]={
{1,1,2,3,6,7},
{2,2,3},
{3,1,2,4,5,7},
{4,1,2,4,6},
{5,3,4}
};
myprint(userItem,n);
int sparseMatrix[n+1][n+1]; //记录两个用户之间的相似度的稀疏矩阵
memset(sparseMatrix,0,sizeof(sparseMatrix));
//计算用户之间的相似相似度矩阵
for(int i=0;i<n;i++){
for(int j=i+1;j<n;j++){
int p=1;
while(userItem[i][p]!='\0'){
int q=1;
while(userItem[j][q]!='\0'){
if(userItem[i][p] == userItem[j][q]){
sparseMatrix[userItem[j][0]][userItem[i][0]]++;
sparseMatrix[userItem[i][0]][userItem[j][0]]++;
break;
}
q++;
}
p++;
}
}
}
//计算用户之间的相似度 (余弦相似性)
int userIdLength = length(userItem[userId-1]);
int cnt=0;
for(int i=1;i<=n;i++){
if(i!=userId){
int iLength = length(userItem[i-1]);
similartys[cnt].weight = sparseMatrix[userId][i]/sqrt(userIdLength*iLength);
similartys[cnt].user = i;
cout<<"用户"<<userId<<"和"<<i<<"相似度:"<<similartys[cnt].weight<<endl;
cnt++;
}else{
similartys[cnt++].weight=-1;
}
}
sort(similartys,similartys+n,cmp);
cout<<"-----------"<<endl<<"用户匹配度最高的[2]位用户为:";
for(int i=0;i<2;i++){
cout<<similartys[i].user<<" ";
}
set<int> items; //记录考虑的商品:相似用户有的,而登录用户没有的
for(int i=0;i<2;i++){
for(int j=1;j<=length(userItem[similartys[i].user-1]);j++){
if(!myfind(userItem,userId,userItem[similartys[i].user-1][j])){
items.insert(userItem[similartys[i].user-1][j]);
}
}
}
cout<<endl<<"-----------"<<endl<<"考虑商品:"<<endl;
set<int>::iterator it = items.begin();
for(it;it!=items.end();it++){
cout<<*it<<" ";
}
cout<<endl<<"它们的匹配度为:"<<endl;
//计算商品匹配度
double maxpick = 0;
int recommendation;
for(it=items.begin();it!=items.end();it++){
double pick = 0;
for(int i=0;i<2;i++){
if(myfind(userItem,similartys[i].user,*it)){
pick+=similartys[i].weight;
}
}
if(pick>maxpick){
maxpick = pick;
recommendation = *it;
}
cout<<"商品"<<*it<<":"<<pick<<endl;
}
cout<<"-----------"<<endl<<"推荐商品:"<<recommendation<<endl;
}Effet d'opération:

Résumé: Le principe de l'algorithme CF est en fait relativement simple, et nous devons maîtriser les formules de calcul en plusieurs étapes pour obtenir des fonctions de base.
