article Annuaire
- Tout d'abord, le déploiement manuel
- En second lieu, la deploy automatisation pseudo-distribué Hadoop
- En troisième lieu, erreur de détermination
Environnement: une seule machine virtuelle vmware, ip est 172.16.193.200.
Tout d'abord, le déploiement manuel
1, désactiver le pare-feu, SELinux
systemctl stop firewalld
sed -i '/SELINUX/s/enforcing/disabled/g' /etc/selinux/config
2, définir le nom d'hôte
hostnamectl set-hostname huatec01
3, installez jdk1.8
https://blog.csdn.net/weixin_44571270/article/details/102939666
4, télécharger Hadoop
wget http://mirrors.hust.edu.cn/apache/hadoop/core/hadoop-2.8.5/hadoop-2.8.5.tar.gz
mv hadoop-2.8.5.tar.gz /usr/local
cd /usr/local
tar xvf hadoop-2.8.5.tar.gz
mv hadoop-2.8.5 hadoop
5, de modifier le fichier de configuration hadoop
cd /usr/local/hadoop/etc/hadoop/
- hadoop.env.sh
- core-site.xml
- hdfs-site.xml
- mapred-site.xml
- fil-site.xml
(1) hadoop.env.sh
Ce fichier est le fichier de configuration de l'environnement d'exploitation Hadoop, le besoin de compter fonctionnement Hadoop JDK, dont la valeur nous modifions le chemin d'exportation JAVA_HOME JDK nous avons installé comme suit:
export JAVA_HOME=/usr/local/jdk1.8.0_141
(2) à noyau-site.xml
Le fichier de base de profil Hadoop, le contenu du fichier de configuration comme suit:
<configuration>
<property>
<name>fs.defaultFS </name>
<value>hdfs://huatec01:9000</value>
</property>
<property>
<name>Hadoop.tmp.dir</name>
<value>/huatec/hadoop-2.8.5/tmp</value>
</property>
</configuration>
Dans le code ci-dessus, nous avons principalement Configuré avec deux attributs, un premier attribut pour spécifier une adresse de communication NameNode HDFS, ici nous attribuons à huatec01; générer un second attribut pour l'opération de stockage de fichiers lors de la spécification Hadoop le catalogue, on n'a pas besoin de créer ce répertoire, car le format est automatiquement créé lorsque le Hadoop.
(3) hdfs-site.xml
Le fichier est des fichiers de configuration de base HDFS, les fichiers de configuration comme suit:
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
Le nombre de copies par défaut grappe Hadoop est de trois, mais maintenant que nous venons de l'installation pseudo-distribué sur un seul noeud, sans avoir à enregistrer trois copies, nous modifier la valeur de la propriété à 1 peut être. Trois nœuds sont entièrement distribués.
(4) mapred-site.xml
Ce fichier n'existe pas, mais il y a un fichier modèle mapred-site.xml.template, nous renommer le fichier modèle mapred-site.xml, puis de le modifier. Le profil de fichier MapReduce à la base, le contenu du fichier de configuration résulte que:
mv mapred-site.xml.template mapred-site.xml
vim mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
La raison pour laquelle la configuration des propriétés ci-dessus, car après Hadoop2.0, MapReduce est en cours d'exécution sur l'architecture de fil, nous avons besoin de faire une déclaration spéciale.
(5) fil-site.xml
Fil est le fichier de profil de cadre, nous spécifier le nom de noeud et les principales propriétés de notre NodeManager ResourceManager, le contenu du fichier de configuration comme suit:
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>huatec01</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
Dans le code ci-dessus, nous avons configuré les deux propriétés. Le premier attribut est utilisé pour indiquer l'adresse du ResourceManager, parce que nous sommes déploiement sur un seul nœud, nous pouvons spécifier huatec01, un second attribut pour spécifier le réducteur de mode d'acquisition de données.
6, le système de fichier formaté
démarrage initial que vous devez exécuter le système de fichiers de format hdfs NameNode -format, puis commencer à HDFS et fils, départ après hdfs de démarrage direct et le fil peuvent être.
/usr/local/hadoop/bin/hdfs namenode -format
7, et commencer à HDFS fil
cd /usr/local/hadoop/sbin/
sh start-dfs.sh
sh start-yarn.sh
#关闭hadoop
sh stop-dfs.sh
sh stop-yarn.sh
8, voir processus hadoop
jps
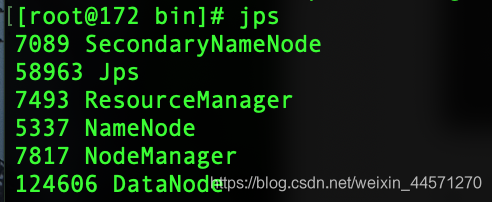 Accès 172.16.193.200:50070 ce que l'
Accès 172.16.193.200:50070 ce que l'
 accès 172.16.193.200:8088, entrer dans l' interface de gestion MapReduce:
accès 172.16.193.200:8088, entrer dans l' interface de gestion MapReduce:
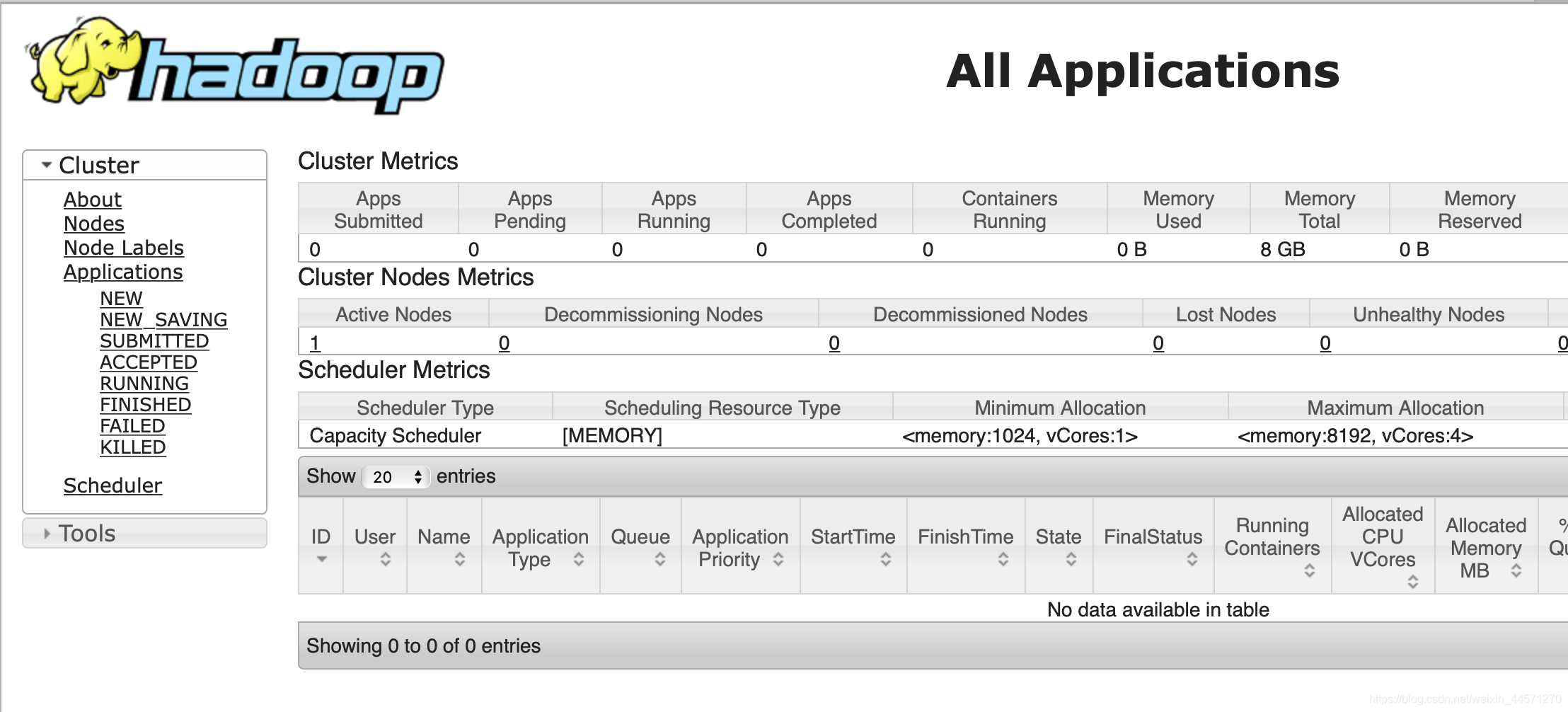 un déploiement réussi!
un déploiement réussi!
En second lieu, la deploy automatisation pseudo-distribué Hadoop
#!/bin/bash
#authored by WuJinCheng
#This shell script is written in 2020.3.17
JDK=jdk1.8.tar.gz
HADOOP_HOME=/usr/local/hadoop
#------初始化安装环境----
installWget(){
echo -e '\033[31m ---------------初始化安装环境...------------ \033[0m'
sed -i '/SELINUX/s/enforcing/disabled/g' /etc/selinux/config
systemctl stop firewalld
wget -V
if [ $? -ne 0 ];then
echo -e '\033[31m 开始下载wget工具... \033[0m'
yum install wget -y
fi
}
#------JDK install----
installJDK(){
ls /usr/local/|grep 'jdk*'
if [ $? -ne 0 ];then
echo -e '\033[31m ---------------开始下载JDK安装包...------------ \033[0m'
wget http://www.wujincheng.xyz/$JDK
if [ $? -ne 0 ]
then
exit 1
fi
mv $JDK /usr/local/
cd /usr/local/
tar xvf $JDK
mv jdk1.8.0_141/ jdk1.8
ls /usr/local/|grep 'jdk1.8'
if [ $? -ne 0 ];then
echo -e '\033[31m jdk安装失败! \033[0m'
fi
echo -e '\033[31m jdk安装成功! \033[0m'
fi
}
JDKPATH(){
echo -e '\033[31m ---------------开始配置环境变量...------------ \033[0m'
grep -q "export JAVA_HOME=" /etc/profile
if [ $? -ne 0 ];then
echo 'export JAVA_HOME=/usr/local/jdk1.8'>>/etc/profile
echo 'export CLASSPATH=$CLASSPATH:$JAVAHOME/lib:$JAVAHOME/jre/lib'>>/etc/profile
echo 'export PATH=$PATH:$JAVA_HOME/bin:$JAVA_HOME/jre/bin'>>/etc/profile
source /etc/profile
fi
}
#------hadoop install----
installHadoop(){
hostnamectl set-hostname huatec01
ls /usr/local/|grep "hadoop*"
if [ $? -ne 0 ];then
echo -e '\033[31m ---------------开始下载hadoop安装包...------------ \033[0m'
wget http://mirrors.hust.edu.cn/apache/hadoop/core/hadoop-2.8.5/hadoop-2.8.5.tar.gz
if [ $? -ne 0 ]
then
exit 2
fi
mv hadoop-2.8.5.tar.gz /usr/local
cd /usr/local
tar xvf hadoop-2.8.5.tar.gz
mv hadoop-2.8.5 hadoop
fi
}
#------hadoop conf----
hadoopenv(){
sed -i '/export JAVA_HOME=/s#${JAVA_HOME}#/usr/local/jdk1.8#g' /usr/local/hadoop/etc/hadoop/hadoop-env.sh
}
coresite(){
echo '<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!--
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
-->
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>fs.defaultFS </name>
<value>hdfs://huatec01:9000</value>
</property>
<property>
<name>Hadoop.tmp.dir</name>
<value>/huatec/hadoop-2.8.5/tmp</value>
</property>
</configuration>'>$HADOOP_HOME/etc/hadoop/core-site.xml
}
hdfssite(){
echo '<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!--
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
-->
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>'>$HADOOP_HOME/etc/hadoop/hdfs-site.xml
}
mapredsite(){
mv $HADOOP_HOME/etc/hadoop/mapred-site.xml.template $HADOOP_HOME/etc/hadoop/mapred-site.xml
echo '<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!--
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
-->
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>'>$HADOOP_HOME/etc/hadoop/mapred-site.xml
}
yarnsite(){
echo '<?xml version="1.0"?>
<!--
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
-->
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>huatec01</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- Site specific YARN configuration properties -->
</configuration>'>$HADOOP_HOME/etc/hadoop/yarn-site.xml
}
#------hdfs 格式化----
hdfsFormat(){
echo -e '\033[31m -----------------开始hdfs格式化...------------ \033[0m'
$HADOOP_HOME/bin/hdfs namenode -format
if [ $? -ne 0 ];then
echo -e '\033[31m Hadoop-hdfs格式化失败! \033[0m'
exit 1
fi
echo -e '\033[31m Hadoop-hdfs格式化成功! \033[0m'
}
install(){
installWget
installJDK
JDKPATH
installHadoop
hadoopenv
coresite
hdfssite
mapredsite
yarnsite
hdfsFormat
}
case $1 in
install)
install
echo -e '\033[31m Hadoop自动化部署完成! \033[0m'
;;
JDK)
installWget
installJDK
JDKPATH
;;
Hadoop)
installWget
installHadoop
echo -e '\033[31m Hadoop安装完成! \033[0m'
;;
confHadoop)
hadoopenv
coresite
hdfssite
mapredsite
yarnsite
echo -e '\033[31m Hadoop配置完成! \033[0m'
;;
format)
hdfsFormat
;;
*)
echo "Usage:$0 {install|JDK|Hadoop|confHadoop|format}";;
esac
En troisième lieu, erreur de détermination
1, il peut y avoir pas pu se connecter à la septième Hadoop de début de l' étape! Refuser l' ouverture de session
 apparaît cette phrase.
apparaît cette phrase.
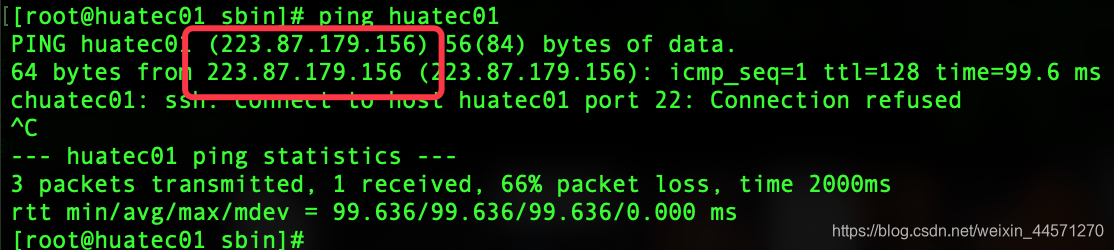 ping sur notre hôte! Il a été constaté que le huatec01 lorsqu'une résolution de nom de domaine. si
ping sur notre hôte! Il a été constaté que le huatec01 lorsqu'une résolution de nom de domaine. si
vim /etc/resolv.conf
 C'est tout!
C'est tout!
2, DataNode a commencé, mais pas d' interface Hadoop DataNode
sixième étape à plusieurs reprises clusterid mise en forme des incohérences causées lors de la prise en compte!
cd /tmp/hadoop-root/dfs/
VERSION sous le nom de clusterid en cours
et
VERSION clusterid sous les incohérences actuelles dans les données
à modifier dans un service cohérent, redémarrage Hadoop!
