base de código de caracteres
unicode
es un conjunto de caracteres Unicode, de una idea muy simple: todos los caracteres incluidos en una colección del mundo, el ordenador se limitan a apoyar este conjunto de caracteres será capaz de visualizar todos estos personajes, no va a ser confusos.
Y proporciona solamente los puntos de código Unicode para cada carácter, en el punto final de este código indica qué tipo de secuencia de bytes, implica el método de codificación.
UTF-32 y UTF-8
El método más sencillo de codificación se utiliza para cada punto de código representa una de cuatro bytes, cada punto de correspondencia de código de bytes. Este método de codificación se llama UTF-32. UTF-32 es la ventaja de que la regla de conversión es sencilla e intuitiva, alta eficiencia de búsqueda. La desventaja es que un desperdicio de espacio, la versión en Inglés del mismo contenido, será cuatro veces más grande que la codificación ASCII. El inconveniente fatal, de hecho, nadie utiliza este método de codificación, HTML 5 estándar establece expresamente que la página no puede ser codificado en UTF-32.
Así nació la UTF-8, UTF-8 es una codificación de longitud variable métodos, la longitud de caracteres que van desde 1 byte a 4 bytes. Los caracteres más comúnmente utilizados, los bytes más delantera más corta de 128 caracteres, sólo un byte, exactamente el mismo código ASCII.
Nota Unicode UTF-8 es sólo una aplicación. Como el código "estricta" Unicode 4E25, y codificación UTF-8 de E4B8A5, los dos son diferentes.
UCS-2
UCS-2 (2-byte juego de caracteres común) formato de codificación es una codificación de longitud fija es de sólo 16 bytes para representar el código de bits de unidad de codificación. Este resultado representa el resultado de los más (BMP) en el intervalo de 0 a UTF-16 como 0xFFFF.
UTF-16 (16-bit Unicode Transformation Format) es una extensión del UCS-2, que representa la relación de gama BMP permite más caracteres. Es un formato de longitud variable, que cada bit de código se puede usar una o dos unidades de 16 bytes de codificación representado. En este código de manera capaz de codificar bits entre 0 a 0x10ffff.
Brevemente, UTF-16 es una extensión del UCS-2.
UTF-16
UTF-16 codificados entre UTF-32 y UTF-8, combinada con las características de los dos tipos de longitud fija y los métodos de codificación de longitud variable.
Se reglas de codificación son simples: un carácter sustancialmente plana ocupa 2 bytes, caracteres plano auxiliar ocupa 4 bytes. Esto es, la longitud de código UTF-16 es o bien 2 bytes (U + 0000 a U + FFFF), o 4 bytes (U + 010000 a U + 10FFFF).
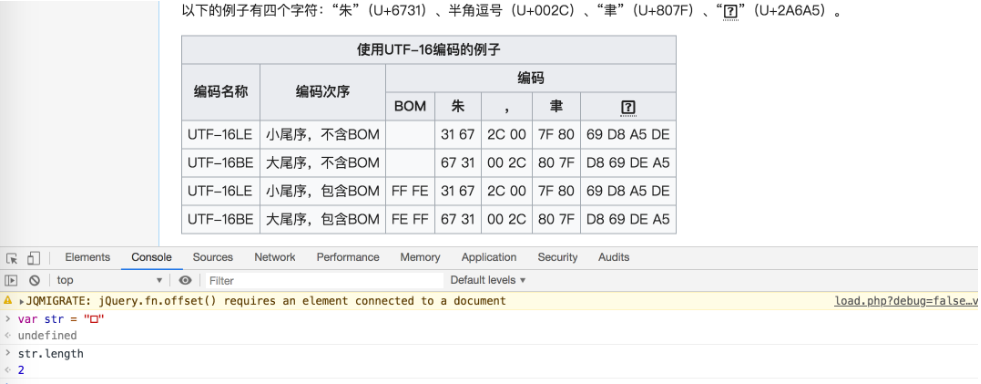
¿Qué conjunto de caracteres que codifica el uso de JS?
ES 5.1 tiene un pasaje
Una implantación conforme de esta norma internacional interpretará caracteres en conformidad con el estándar Unicode, versión 3.0 o posterior e ISO / IEC 10646-1, ya sea con UCS-2 o UTF-16 como la adoptada codificación de nivel de formulario, aplicación 3. Si el adoptado ISO / IEC 10646-1 subconjunto no se especifica lo contrario, se presume que es el subconjunto BMP, colección 300. Si no se especifica de otro modo la forma codificación adoptada, se presume que es el UTF-16 forma de codificación.
Por lo tanto motor JS puede optar por utilizar UCS-2 o UTF-16.
¿Por qué no elegir UTF-8 es? Debido a razones históricas, apareció por primera vez en el UCS-2, a continuación, en 1996 UTF-16 2.0 estándar Unicode con el nacimiento, puede migrar a UTF-16. Pero no pueden moverse a UTF-8, porque destruiría la compatibilidad binaria de interfaz API (y otras características).
Además, incluso en Java, funciona de la misma manera: en un principio apoyó la UCS-2, UTF-16, pero se trasladó en J2SE 5.0.
Usted puede obtener los códigos de caracteres Unicode graves por los códigos de la figura.
var str = '严'
str.charCodeAt(0).toString(16) // "4e25"Calcular el número de bytes ocupado por la cadena
/**
* 计算字符串所占的内存字节数,默认使用UTF-8的编码方式计算,使用一至四个字节为每个字符编码
* 参考来源: http://www.jb51.net/article/73675.htm
*
* 000000 - 00007F(128个代码) 0zzzzzzz(00-7F) 一个字节
* 000080 - 0007FF(1920个代码) 110yyyyy(C0-DF) 10zzzzzz(80-BF) 两个字节
* 000800 - 00D7FF & 00E000 - 00FFFF(61440个代码) 1110xxxx(E0-EF) 10yyyyyy 10zzzzzz 三个字节
* 010000 - 10FFFF(1048576个代码) 11110www(F0-F7) 10xxxxxx 10yyyyyy 10zzzzzz 四个字节
*
* 注: Unicode在范围 D800-DFFF 中不存在任何字符
* {@link http://zh.wikipedia.org/wiki/UTF-8}
*
* UTF-16 大部分使用两个字节编码,编码超出 65535 的使用四个字节
* 000000 - 00FFFF 两个字节
* 010000 - 10FFFF 四个字节
*
* {@link http://zh.wikipedia.org/wiki/UTF-16}
* @param {String} str
* @param {String} charset utf-8
* @return {Number}
*/
var sizeof = function(str, charset) {
var total = 0,
charCode,
i,
len;
charset = charset ? charset.toLowerCase() : '';
if (charset === 'utf-16' || charset === 'utf16') {
for (i = 0, len = str.length; i < len; i++) {
charCode = str.charCodeAt(i);
if (charCode <= 0xffff) {
total += 2;
} else {
total += 4;
}
}
} else {
for (i = 0, len = str.length; i < len; i++) {
charCode = str.charCodeAt(i);
if (charCode <= 0x007f) {
total += 1;
} else if (charCode <= 0x07ff) {
total += 2;
} else if (charCode <= 0xffff) {
total += 3;
} else {
total += 4;
}
}
}
return total;
}