Escrito por el principio: Anoche un amigo de repente me hizo una pregunta, si no al final como un largo tiempo, mucho tiempo después quería pensar en una solución, pero supongo que debe haber una mejor manera de resolver.
distribuciones estadísticas acumulativas y multidimensionales
El nombre es un requisitos de la misión temporales de acuerdo con el pensamiento autor, aquí lo primero que describen el contenido de la tarea,
los objetivos de la misión :
el cálculo de una matriz, tiempos de vuelta seleccionados al azar N, N veces la producción de todas las posibles extracción y ha sido propiedad y estadísticas el número y la probabilidad.
Dar un pequeño ejemplo, hemos dibujado dos veces de 0,1,2, a contar dos veces antes y puede haber sido el resultado de todo, vamos a dibujar un diagrama. Podemos ver todos los resultados después de dos extractos son 0-4,
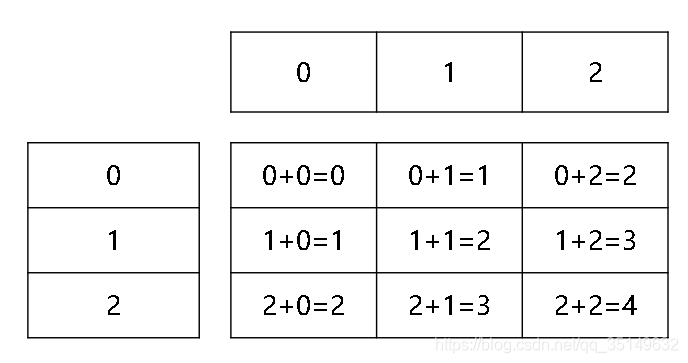
y luego dibujar el número de ocurrencias de cada resultado,

es nuestra tarea, cuando la extracción de una matriz n veces, n veces de resultados y estadísticas es una especie de cómo?
Léame tarea
esta pregunta porque no sé si hay una inducción matemática, pero si sólo desde el punto de partida del procedimiento, habrá las siguientes dos preguntas para reflexionar:
1. Generalidades puedo utilizar un bucle, pero la extracción de la enésima vez, significado n la necesidad de bucle, esto no tiene sentido, entonces la forma de sustituir el bucle?
2. Si elegimos la primera consecuencia n veces dibujado primer salvamento y luego se suman, entonces tenemos que enfrentar el problema de la matriz de almacenamiento latitudes altas, puede utilizar el árbol de resolver, pero la complejidad de la creación es relativamente alto. Así lo simple almacenamiento de datos es también un problema.
Aquí simplemente decir algo sobre las ideas de investigación de esta tarea,
en primer lugar a la primera pregunta si desea reemplazar más de un bucle, podemos utilizar operación de matriz numpy, o que realice la operación del ciclo operación repetitiva con la recursividad, podemos desear el trazado de la matriz de todas las impresiones posibles, tenemos que (0,1,2) estos tres números fueron dibujados, por ejemplo, se extrajo tres veces los resultados son los siguientes,
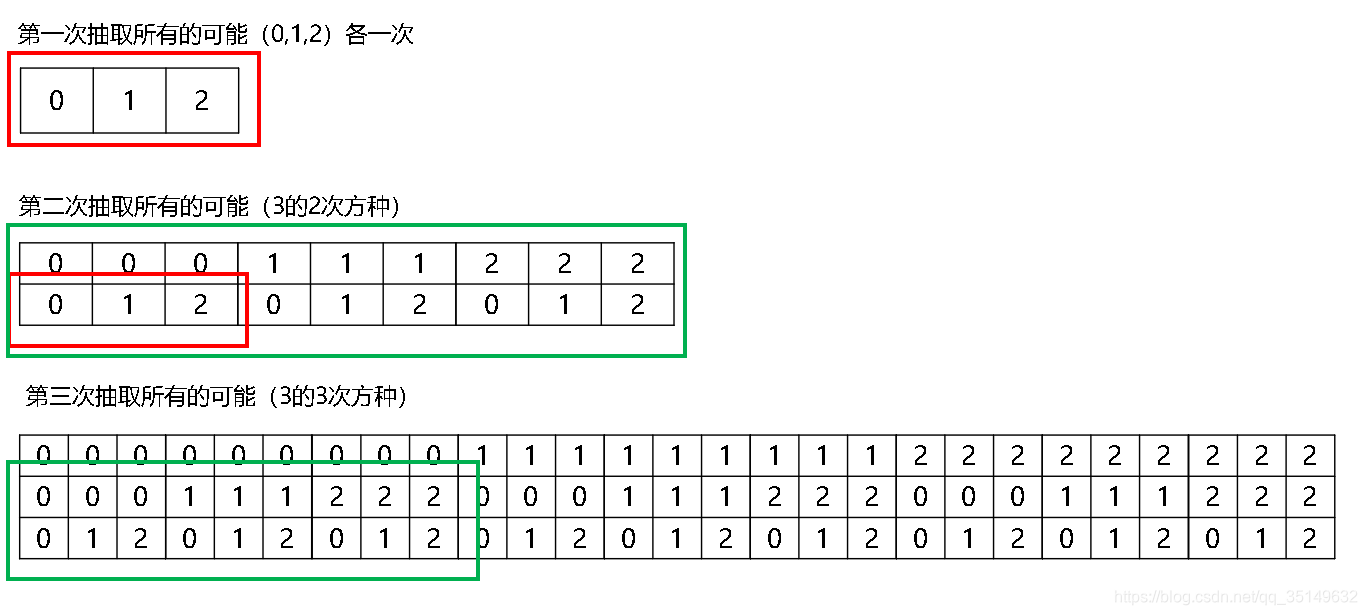
podemos encontrar todos los resultados de la extracción a aparecer, presenta aparente regularidad, podemos ver la primera línea de cada uno de lo posible, de acuerdo con el n 0, n el número 1, n 2 un están dispuestos de tal manera que la longitud de la longitud específica de la n-ésima potencia de la matriz original. A continuación se encuentra la primera fila de la ley, entonces unas filas detrás de la ley?
Desde el punto de color rojo y verde de vista, dibujado en una posible extracción de todos los tiempos será organizado en un no-primera línea de los resultados de todos los resultados, como se muestra, los primeros resultados aparecieron en 012 después de la segunda vez, con gestión. Utilizamos un procedimiento recursivo para los últimos datos utilizados en la siguiente generación, por lo que se puede obtener una completa resultados de la extracción.
Para la segunda pregunta, si somos salvos primero todos los resultados, podemos ver que el marco que necesitamos es
de crecimiento, esta estructura es muy razonable. Con el fin de resolver un problema de este tipo, combinamos nuestro objetivo es encontrar una variedad de resultados y por lo que el cálculo directo de cada dibujo y como resultado de un objeto iteración,

por lo que necesitamos para calcular un tiempo, una fila de 0,1,2 y el último atraídos y la operación de adición, proceso intermedio no tiene que considerar la construcción de una matriz no necesita demasiado para considerar los números hacia arriba, sólo es necesario establecer un número bien de la recursividad, puede obtener los resultados que queremos, y luego contar cada uno más y el número de ocurrencias. Las tareas se vuelven! Vamos a empezar con la realización del programa, cuando la mayoría de la numpy programa operativo, pero en algunos lugares puede ser debido a la operación de obra no calificada numpy es relativamente engorroso, el futuro será mejorado.
darse cuenta de la tarea :
Estamos aquí para extracto de [0,1,2,3,4,5] cuatro veces, y la distribución estadística de los resultados extraídos muestran,
import numpy as np
import copy
# 统计抽取累积和函数定义
def sumStatic(choiceList, k, n):
"""
描述:该函数用于统计对m个数字,放回随机抽样抽取n次,每次的值相加得到的和的所有可能结果,
以及可能结果出现的次数和概率的统计。
输入:
chiceList:输入的是一个np.array,是一个m维的行向量。我们将从choiceList中抽取数值进行加和计算;
k:循环控制变量,控制函数递归的次数,初始值为0,每递归一次k要增加1;
n:抽取次数,通过手动设定想要抽取多少次。
返回:
y:返回的是对于各种和的统计次数,并调用到下一个函数中,进行可视化的展示
"""
z = np.array([]) # 创建空np.array数组,方便结尾进行储存
store = [] # 创建空list,储存每一步的计算结果
k += 1
for i in range(d.shape[0]):
lists = copy.deepcopy(choiceList) # 对输入数组进行深拷贝
lists += d[i] # 对每个数组进行加和
store.append(lists) # 添加到list中
z = np.hstack(store) # 将list处理为一个行np.array
if k == (n - 1): # 如果递归次数到了n-1次,那么返回所有和的结果出现次数统计到可视化函数中
return distribution(np.bincount(z))
return sumStatic(z, k, n) # 如果没有到达既定的抽取次数,那么继续递归
# 统计次数可视化
def distribution(z):
number = np.argwhere(z)
#sum = np.sum(z)
for i in range(number.shape[0]):
print(number[i], "=====>", z[i],"次") # 输出每一个和的结果出现的概率
#如果想计算概率可以把sum和下面这个语句输出
#print(number[i], "=====>", round(z[i], 4))
n = int(input("[请输入你想抽取的次数]> "))
d = np.array([0, 1, 2, 3, 4, 5])
sumStatic(d, 0, n)
[请输入你想抽取的次数]> 4
[0] =====> 1 次
[1] =====> 4 次
[2] =====> 10 次
[3] =====> 20 次
[4] =====> 35 次
[5] =====> 56 次
[6] =====> 80 次
[7] =====> 104 次
[8] =====> 125 次
[9] =====> 140 次
[10] =====> 146 次
[11] =====> 140 次
[12] =====> 125 次
[13] =====> 104 次
[14] =====> 80 次
[15] =====> 56 次
[16] =====> 35 次
[17] =====> 20 次
[18] =====> 10 次
[19] =====> 4 次
[20] =====> 1 次
Algunas personas pueden querer a continuación trama, esto es relativamente simple, sólo es necesario número y Z puede ser trazada, podemos reconstruir la distribución,
def distribution(z):
x = np.argwhere(z)
X = np.reshape(x,(1,-1))[0]
plt.bar(X,z,color="#ffcfdc")
Lo mismo se puede invocar, trazamos una.
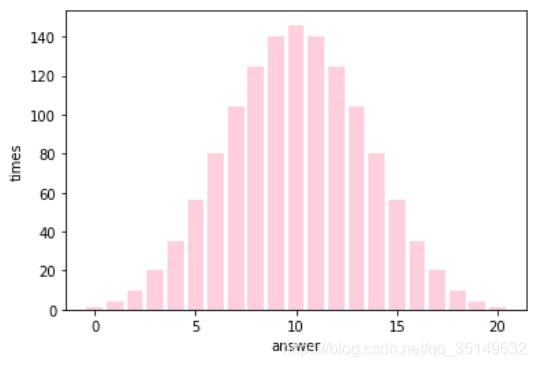
Conclusión
a esto, terminamos y para lograr esta distribución estadística acumulada, pero también es un problema, por ejemplo, cuando la muestra 400 cuando la dimensión teórica es el número 400 de potencia, el equipo funciona casi 5 no funciona, si después de una oportunidad, ver si se puede obtener una aproximación rápida reducción de dimensionalidad, o ser capaz de encontrar un hueco entre cada fórmula de gráfico de barras, si pueden conseguir, a continuación, que pronto será capaz de sacar los resultados estadísticos apropiados.
Gracias por leer.
