
Con el rápido avance de la tecnología de inteligencia artificial, OpenAI se ha convertido en uno de los líderes en este campo. Funciona bien en una variedad de tareas de procesamiento del lenguaje, incluida la traducción automática, la clasificación de texto y la generación de texto. Con el auge de OpenAI, han surgido muchos otros modelos de lenguajes grandes de código abierto de alta calidad, como Llama, ChatGLM, Qwen, etc. Estos excelentes modelos de código abierto también pueden ayudar a los equipos a crear rápidamente una excelente aplicación LLM.
Pero ante tantas opciones, ¿cómo podemos utilizar las interfaces OpenAI de manera uniforme y al mismo tiempo reducir los costos de desarrollo? ¿Cómo monitorear de manera eficiente y continua el rendimiento en ejecución de las aplicaciones LLM sin agregar complejidad de desarrollo adicional? GreptimeAI y Xinference brindan soluciones prácticas a estos problemas.
¿Qué es GreptimeAI?
GreptimeAI se basa en la base de datos de series temporales de código abierto GreptimeDB. Es un conjunto de soluciones de observabilidad para aplicaciones de modelos de lenguaje grandes (LLM). Actualmente es compatible con los ecosistemas LangChain y OpenAI. GreptimeAI le permite obtener una comprensión integral de los costos, el rendimiento, el tráfico y la seguridad en tiempo real, lo que ayuda a los equipos a mejorar la confiabilidad de las aplicaciones LLM.
¿Qué es Xinferencia?
Xinference es una plataforma de inferencia de modelos de código abierto diseñada para modelos de lenguaje grande (LLM), modelos de reconocimiento de voz y modelos multimodales, y admite la implementación privatizada. Xinference proporciona una API RESTful compatible con la API OpenAI e integra herramientas de desarrollo de terceros como LangChain, LlamaIndex y Dify.AI para facilitar la integración y el desarrollo de modelos. Xinference integra múltiples motores de inferencia LLM (como Transformers, vLLM y GGML), es adecuado para diferentes entornos de hardware y admite la implementación distribuida de múltiples máquinas. Puede asignar de manera eficiente tareas de inferencia de modelos entre múltiples dispositivos o máquinas para satisfacer las necesidades de múltiples máquinas. Modelo y computación de alta velocidad. Necesidades de implementación disponibles.
GreptimeAI + Xinference implementan/supervisan aplicaciones LLM
A continuación, tomaremos el modelo Qwen-14B como ejemplo para presentar en detalle cómo usar Xinference para implementar y ejecutar el modelo localmente. Aquí se mostrará un ejemplo, que utiliza un método similar a la llamada a función OpenAI (llamada a función) para realizar consultas meteorológicas y demuestra cómo usar GreptimeAI para monitorear el uso de aplicaciones LLM.
Regístrese y obtenga información de configuración de GreptimeAI
Visite https://console.greptime.cloud para registrar el servicio y crear el servicio AI. Después de saltar al AI Dashboard, haga clic en la página Configuración para obtener la información de configuración de OpenAI.
Inicie el servicio modelo Xinference
Es muy sencillo iniciar el servicio del modelo Xinference localmente. Solo necesita ingresar el siguiente comando:
xinference-local -H 0.0.0.0
Xinference iniciará el servicio localmente de forma predeterminada y el puerto predeterminado es 9997. El proceso de instalación de Xinference localmente se omite aquí. Puede consultar este artículo para la instalación.
Iniciar el modelo a través de la interfaz de usuario web
Después de iniciar Xinference, ingrese http://localhost:9997 en el navegador para acceder a la interfaz de usuario web.

Inicie el modelo desde la línea de comando
También podemos usar la herramienta de línea de comando de Xinference para iniciar el modelo. El UID del modelo predeterminado es qwen-chat (se accederá al modelo a través de este ID más adelante).
xinference launch -n qwen-chat -s 14 -f pytorch
Obtenga información meteorológica a través de la interfaz estilo OpenAI
Supongamos que tenemos la capacidad get_current_weatherde obtener información meteorológica para una ciudad específica llamando a la función, con parámetros locationy format.
Configurar OpenAI y la interfaz de llamada
Acceda al puerto local de Xinference a través del SDK de Python de OpenAI, use GreptimeAI para recopilar datos, use chat.completionsla interfaz para crear una conversación y use para toolsespecificar la lista de funciones que acabamos de definir.
from greptimeai import openai_patcher
from openai improt OpenAI
client = OpenAI(
base_url="http://127.0.0.1:9997/v1",
)
openai_patcher.setup(client=client)
messages = [
{"role": "system", "content": "你是一个有用的助手。不要对要函数调用的值做出假设。"},
{"role": "user", "content": "上海现在的天气怎么样?"}
]
chat_completion = client.chat.completions.create(
model="qwen-chat",
messages=messages,
tools=tools,
temperature=0.7
)
print('func_name', chat_completion.choices[0].message.tool_calls[0].function.name)
print('func_args', chat_completion.choices[0].message.tool_calls[0].function.arguments)
detalles de herramientas
Llamada de funciones La lista de funciones (herramientas) se define a continuación, con los campos obligatorios especificados.
tools = [
{
"type": "function",
"function": {
"name": "get_current_weather",
"description": "获取当前天气",
"parameters": {
"type": "object",
"properties": {
"location": {
"type": "string",
"description": "城市,例如北京",
},
"format": {
"type": "string",
"enum": ["celsius", "fahrenheit"],
"description": "使用的温度单位。从所在的城市进行推断。",
},
},
"required": ["location", "format"],
},
},
}
]
El resultado es el siguiente, puede ver que obtuvimos chat_completionla llamada a la función generada por el modelo Qwen a través de:
func_name: get_current_weather
func_args: {"location": "上海", "format": "celsius"}
Obtenga el resultado de la llamada a la función y vuelva a llamar a la interfaz
Aquí se supone que hemos llamado a la función con los parámetros dados get_current_weathery hemos obtenido el resultado, y reenviamos el resultado y el contexto al modelo Qwen:
messages.append(chat_completion.choices[0].message.model_dump())
messages.append({
"role": "tool",
"tool_call_id": messages[-1]["tool_calls"][0]["id"],
"name": messages[-1]["tool_calls"][0]["function"]["name"],
"content": str({"temperature": "10", "temperature_unit": "celsius"})
})
chat_completion = client.chat.completions.create(
model="qwen-chat",
messages=messages,
tools=tools,
temperature=0.7
)
print(chat_completion.choices[0].message.content)
Resultados finales
El modelo Qwen eventualmente generará una respuesta como esta:
上海现在的温度是 10 摄氏度。
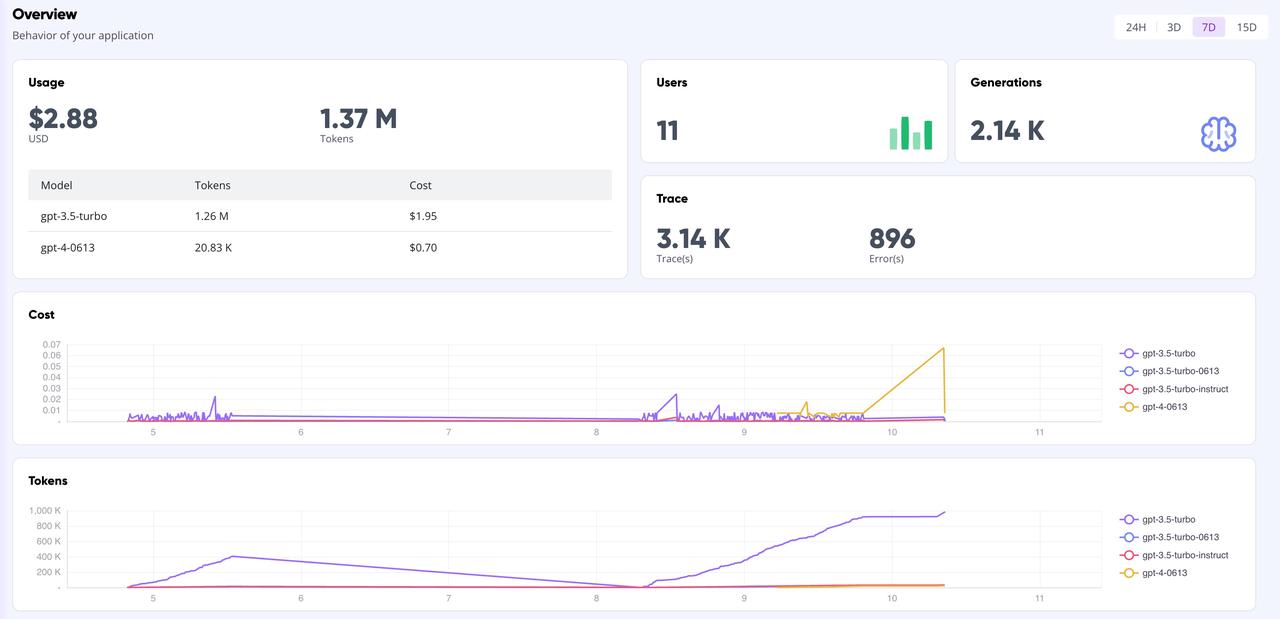
Cartelera de GreptimeAI
En la página del Panel de control de GreptimeAI, puede monitorear de manera integral y en tiempo real todos los datos de las llamadas según la interfaz OpenAI, incluidos indicadores clave como token, costo, latencia, seguimiento, etc. A continuación se muestra la página de descripción general del panel.
Resumir
Si está utilizando modelos de código abierto para crear aplicaciones LLM y desea utilizar el estilo OpenAI para realizar llamadas API, entonces usar Xinference para administrar el modelo de inferencia y GreptimeAI para monitorear la operación del modelo es una buena opción. Ya sea que esté realizando análisis de datos complejos o consultas diarias simples, Xinference puede proporcionar capacidades de gestión de modelos potentes y flexibles. Al mismo tiempo, combinado con la función de monitoreo de GreptimeAI, puede comprender y optimizar de manera más eficiente el rendimiento y el consumo de recursos del modelo.
Esperamos sus intentos y agradecemos el intercambio de experiencias y conocimientos utilizando GreptimeAI y Xinference. ¡Exploremos juntos las infinitas posibilidades de la inteligencia artificial!
Pocos conocimientos sobre Greptime:
Greptime Greptime Technology se fundó en 2022 y actualmente está mejorando y construyendo tres productos: la base de datos de series temporales GreptimeDB, GreptimeCloud y la herramienta de observabilidad GreptimeAI.
GreptimeDB es una base de datos de series temporales escrita en lenguaje Rust. Es distribuida, de código abierto, nativa de la nube y altamente compatible. Ayuda a las empresas a leer, escribir, procesar y analizar datos de series temporales en tiempo real al tiempo que reduce los costos de almacenamiento a largo plazo. proporcionar a los usuarios un servicio DBaaS totalmente administrado que puede integrarse altamente con observabilidad, Internet de las cosas y otros campos. GreptimeAI está hecho a medida para LLM y proporciona monitoreo de enlace completo de costos, rendimiento y procesos de generación;
GreptimeCloud y GreptimeAI han sido probados oficialmente. ¡Bienvenido a seguir la cuenta oficial o el sitio web oficial para conocer los últimos desarrollos!

Sitio web oficial: https://greptime.cn/
GitHub: https://github.com/GreptimeTeam/greptimedb
Documentación: https://docs.greptime.cn/
Gorjeo: https://twitter.com/Greptime
Holgura: https://greptime.com/slack
LinkedIn: https://www.linkedin.com/company/greptime/
Un programador nacido en los años 90 desarrolló un software de portabilidad de vídeo y ganó más de 7 millones en menos de un año. ¡El final fue muy duro! Los estudiantes de secundaria crean su propio lenguaje de programación de código abierto como una ceremonia de mayoría de edad: comentarios agudos de los internautas: debido al fraude desenfrenado, confiando en RustDesk, el servicio doméstico Taobao (taobao.com) suspendió los servicios domésticos y reinició el trabajo de optimización de la versión web Java 17 es la versión Java LTS más utilizada. Cuota de mercado de Windows 10. Alcanzando el 70%, Windows 11 continúa disminuyendo. Open Source Daily | Google apoya a Hongmeng para hacerse cargo de los teléfonos Android de código abierto respaldados por Docker; Electric cierra la plataforma abierta Apple lanza el chip M4 Google elimina el kernel universal de Android (ACK) Soporte para la arquitectura RISC-V Yunfeng renunció a Alibaba y planea producir juegos independientes para plataformas Windows en el futuro