
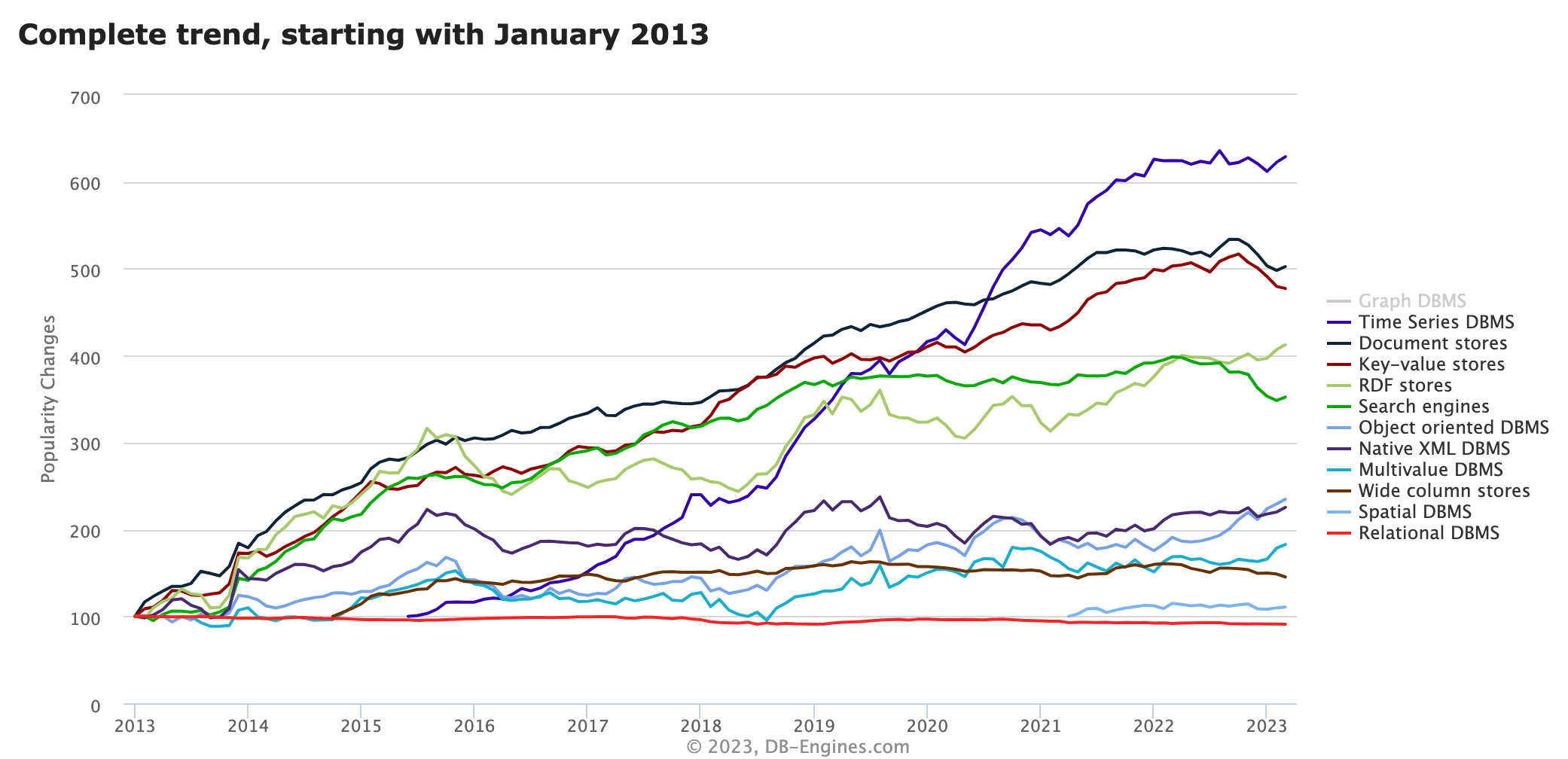
En los últimos años, la creciente popularidad del Internet de las cosas (IoT) y la necesidad de datos en tiempo real han llevado a un crecimiento significativo en la adopción de bases de datos de series temporales (TSDB). Según el ranking de DB-Engines, la popularidad de TSDB supera a la de cualquier otro tipo de base de datos, sólo superada por Graph DBMS .
Como herramienta importante para almacenar, gestionar y analizar datos de series de tiempo, es probable que la demanda de bases de datos de series de tiempo (TSDB) siga aumentando en el futuro. Si aún no sabe mucho sobre esto, este artículo presentará de manera integral qué es una base de datos de series temporales y por qué necesita una base de datos para datos de series temporales.
¿Qué son los datos de series de tiempo?
Hablando de la popularidad de las bases de datos de series de tiempo en los últimos años, primero debemos hablar de los datos de series de tiempo. ¿Por qué se requiere una base de datos especialmente optimizada para su procesamiento? ¿No puede satisfacerlo una base de datos relacional general?
Los llamados datos de series de tiempo, desde una perspectiva muy popular, son algunos valores (Valor) que cambian con el tiempo. Al mismo tiempo, estos valores van acompañados de algunas etiquetas que consisten en Clave = Valor.
Generalmente incluye los siguientes tres atributos (de Wikipedia):
Series de tiempo
Un identificador único que consta de un nombre (a menudo llamado métrica) y una serie de etiquetas Clave=Valor (Etiquetas, o generalmente llamadas Etiquetas).
Par clave-valor (marca de tiempo, valor)
Los pares clave-valor se componen de marcas de tiempo y valores y, naturalmente, se ordenan según las marcas de tiempo. Estos pares clave-valor generalmente se denominan muestras.
Valor
El Valor en el punto 2 es generalmente un valor numérico, como temperatura, humedad, CPU, uso de memoria, etc., pero también puede ser cualquier estructura de datos (tanto estructurada como no estructurada).
Caso de datos de series temporales
Por ejemplo, tome una captura de pantalla del pronóstico del tiempo de 15 días de un sitio web meteorológico para Yuhang:
Analizando las dos líneas de temperatura máxima y temperatura mínima, los tres atributos aquí son:
- Los cronogramas son: a. Temperatura máxima diaria + <región=Yuhang> b. Temperatura mínima diaria + <región=Yuhang>.
- La secuencia compuesta por la marca de tiempo y el valor de la temperatura máxima es de 15 pares clave-valor del 29/8 al 06/09, y el valor es la temperatura máxima diaria. Las temperaturas mínimas son similares.
- Aquí el valor es la temperatura, es decir, un valor numérico. Por ejemplo, la temperatura más alta el 29/8 es de 36 grados Celsius y la temperatura más baja es de 25 grados Celsius.
Además de la información de previsión meteorológica, también existen datos de series temporales en los siguientes campos:
Precio de las acciones : permite a los analistas y comerciantes de acciones comprender la tendencia y dirección de un determinado precio de las acciones.
Monitoreo de Salud : Se utiliza en el campo médico para monitorear la frecuencia cardíaca u otros valores de salud de pacientes que puedan estar tomando ciertos medicamentos.
Sensores físicos para la industria y el Internet de las cosas : incluidos diversos sensores de temperatura, humedad, velocidad, aceleración, dirección, frecuencia cardíaca, oxígeno en sangre y otros sensores incluidos en varios teléfonos inteligentes, automóviles y hogares inteligentes, etc., que se utilizan ampliamente en la fabricación. , Industria médica y otras industrias generan cantidades masivas de datos sensoriales todo el tiempo y a intervalos fijos o irregulares, que se utilizan principalmente para el monitoreo diario y anormal de equipos y cuerpos humanos, y aplicaciones inteligentes basadas en esta minería masiva de datos (como. como optimización de la línea de producción de fabricación inteligente), conducción autónoma), etc.
Sensores de software : como monitoreo de sondas intrusivas en DevOps tradicionales, sondas no intrusivas en entornos nativos de la nube (como las populares soluciones de sondas no intrusivas actualmente basadas en eBPF y sondas de plano de datos Service Mesh), varios software El propósito principal de varios indicadores y los datos integrados son para monitorear aplicaciones de software diarias y anormales para garantizar el funcionamiento continuo y estable de los servicios comerciales. Junto con el desarrollo actual del campo AIOps, también se presentan requisitos más altos para la escala y granularidad del uso de datos de series de tiempo.
Características de los datos de series temporales.
- Los datos se generan con relativa frecuencia y de manera estable , y la frecuencia es generalmente estable y no cambia con los ciclos de actividad diurna de las personas. Hay muchos tipos de sensores, junto con una gran cantidad de etiquetas para industrias y ubicaciones geográficas, la escala de datos y los plazos son extremadamente grandes. Y la escala de esos datos está creciendo rápidamente con la popularidad de los dispositivos inteligentes (dispositivos portátiles, automóviles inteligentes, fabricación inteligente) y las demandas más sofisticadas de estas aplicaciones de datos por parte de la gente.
- Las características de cambio de datos son más similares al método Append-Only . Los datos se agregan continuamente y hay menos escenarios de actualización (pero todavía hay retrasos en los datos, especialmente en entornos de red débiles). Los datos generalmente se eliminan según el tiempo de vencimiento. Eliminar en lotes durante un período.
- En cuanto a las aplicaciones de datos, las más habituales son el seguimiento diario y anormal . A partir de estos datos se construyen informes de seguimiento visual y sistemas de alarma, seguidos de predicción de tendencias futuras, es decir, predicción de series temporales, especialmente en el ámbito financiero.
Por qué los datos de series temporales son tan importantes
Aunque los datos de series temporales no son un tipo de datos nuevo, su popularidad y uso han aumentado significativamente en los últimos años, según lo analizado por DB-Engines. Hay varios factores que no se pueden ignorar, entre ellos:
- El desarrollo de Internet y la digitalización de muchas industrias . Esto conduce directamente a la generación de datos de series temporales masivas, como el tráfico del sitio web, las actividades en las redes sociales y las lecturas de los sensores.
- Desarrollo de algoritmos de aprendizaje automático . Como la red neuronal recurrente (RNN) y la red de memoria a corto plazo (LSTM), estos algoritmos son adecuados para el análisis de datos de series de tiempo, lo que facilita a las personas la extracción de información valiosa de este tipo de datos, brindando a los datos de series de tiempo la oportunidad. para seguir generando valor.
- El auge del análisis predictivo . Esto hace que los datos de series temporales sean una herramienta importante para predecir tendencias y resultados futuros.
- necesidades en áreas como finanzas, atención médica y transporte . Existe una necesidad cada vez mayor de tomar decisiones en tiempo real en estos campos, y el análisis de datos de series temporales puede hacer frente a estas situaciones que cambian rápidamente.
¿Qué es una base de datos de series de tiempo?
La base de datos de series temporales (base de datos de series temporales), según la definición de Wikipedia, es una base de datos optimizada específicamente para el procesamiento de datos de series temporales. Es un tipo de base de datos de dominio y está diseñada para servicios de procesamiento de datos en campos comerciales específicos, como el procesamiento de bases de datos de gráficos, el almacenamiento de gráficos. recuperación., la base de datos de documentos se utiliza para el almacenamiento y recuperación de documentos semiestructurados, y el motor de búsqueda se utiliza especialmente para la recuperación de texto no estructurado.
Características de la base de datos de series temporales.
Para abordar las características y desafíos involucrados en los datos de series temporales descritos anteriormente, TSDB emplea una serie de técnicas. Algunas de estas características típicas incluyen:
Árbol de fusión estructurado de registros (árbol LSM)
LSM-tree es una estructura de datos basada en disco optimizada para cargas de trabajo con mucha escritura que permite la ingesta y el almacenamiento de datos eficientes mediante la fusión y compresión de datos en una serie de niveles. Esto reduce la amplificación de escritura y proporciona un mejor rendimiento de escritura en comparación con los árboles B tradicionales.
partición basada en el tiempo
Las bases de datos de series de tiempo generalmente dividen los datos en función de intervalos de tiempo, lo que hace que las consultas sean más rápidas y eficientes y facilita la retención y administración de los datos. Este enfoque ayuda a separar los datos recientes a los que se accede con frecuencia de los datos más antiguos a los que se accede con menos frecuencia, optimizando el almacenamiento y el rendimiento de las consultas.
compresión de datos
Las bases de datos de series temporales utilizan varias técnicas de compresión, como codificación delta, compresión Gorilla o codificación de diccionario para reducir los requisitos de espacio de almacenamiento. Estas técnicas aprovechan los patrones temporales y basados en valores en los datos de series temporales para permitir un almacenamiento eficiente sin perder la fidelidad de los datos.
Agregaciones y funciones integradas basadas en el tiempo
Las bases de datos de series temporales brindan soporte nativo para funciones basadas en el tiempo, como promedios móviles, porcentajes y agregaciones basadas en el tiempo. Estas capacidades integradas permiten a los usuarios realizar análisis complejos de series de tiempo de manera más eficiente y con menos sobrecarga computacional en comparación con las bases de datos tradicionales.
¿Por qué elegir una base de datos de series temporales?
De la introducción anterior, también tenemos una respuesta preliminar de por qué necesitamos una base de datos en el campo específico de la base de datos de series de tiempo.
Según las características, escala y aplicación de los datos de series temporales, la base de datos de series temporales puede realizar optimizaciones específicas: el almacenamiento adopta un algoritmo de compresión personalizado, el formato de almacenamiento adopta un formato de almacenamiento mixto de filas y columnas optimizado para escenarios de consulta y escritura masiva de series temporales; operadores de consulta Introduzca más funciones relacionadas con la ventana de tiempo para la sincronización, optimice el protocolo de consulta para los modelos de sincronización y adopte una estrategia de caducidad más flexible para la eliminación de datos .
Estas optimizaciones específicas de dominio pueden brindar a las bases de datos de series temporales grandes ventajas sobre las bases de datos de propósito general en términos de capacidades de dominio, rendimiento, costo, estabilidad y otras dimensiones.
Resumir
Las bases de datos de series temporales se han utilizado ampliamente en Internet de las cosas, análisis de datos financieros, sistemas de alarma y monitoreo, gestión de energía, aplicaciones de atención médica y otras industrias sensibles al tiempo. Al utilizar bases de datos de series de tiempo para analizar y predecir datos de series de tiempo, las empresas pueden obtener información valiosa de los datos, tomando así decisiones más informadas y obteniendo ventajas competitivas únicas.
Sin embargo, las bases de datos de series de tiempo y las bases de datos relacionales no son incompatibles, dado que los sistemas comerciales generalmente todavía usan ampliamente las bases de datos relacionales, ¿cómo se pueden combinar mejor y más convenientemente los datos de series de tiempo y los datos comerciales para generar un mayor valor comercial? La base de datos de la serie necesita resolver.
Acerca de Greptime:
Greptime Greptime Technology se compromete a proporcionar servicios de análisis y almacenamiento de datos eficientes y en tiempo real para campos que generan grandes cantidades de datos de series temporales, como automóviles inteligentes, Internet de las cosas y observabilidad, ayudando a los clientes a extraer el profundo valor de los datos. Actualmente existen tres productos principales:
-
GreptimeDB es una base de datos de series temporales escrita en lenguaje Rust. Es distribuida, de código abierto, nativa de la nube y altamente compatible. Ayuda a las empresas a leer, escribir, procesar y analizar datos de series temporales en tiempo real al tiempo que reduce los costos de almacenamiento a largo plazo.
-
GreptimeCloud puede proporcionar a los usuarios servicios DBaaS totalmente gestionados, que pueden integrarse altamente con la observabilidad, el Internet de las cosas y otros campos.
-
GreptimeAI es una solución de observabilidad diseñada para aplicaciones LLM.
-
La solución integrada de vehículo-nube es una solución de base de datos de series de tiempo que profundiza en los escenarios comerciales reales de las empresas automotrices y resuelve los puntos débiles comerciales reales después de que los datos de los vehículos de la empresa crecen exponencialmente.
GreptimeCloud y GreptimeAI han sido probados oficialmente. ¡Bienvenido a seguir la cuenta oficial o el sitio web oficial para conocer los últimos desarrollos! Si está interesado en la versión empresarial de GreptimDB, puede comunicarse con el asistente (busque greptime en WeChat para agregar el asistente).
Sitio web oficial: https://greptime.cn/
GitHub: https://github.com/GreptimeTeam/greptimedb
Documentación: https://docs.greptime.cn/
Gorjeo: https://twitter.com/Greptime
Holgura: https://www.greptime.com/slack
LinkedIn: https://www.linkedin.com/company/greptime
Un programador nacido en los años 90 desarrolló un software de portabilidad de vídeo y ganó más de 7 millones en menos de un año. ¡El final fue muy duro! Los estudiantes de secundaria crean su propio lenguaje de programación de código abierto como una ceremonia de mayoría de edad: comentarios agudos de los internautas: debido al fraude desenfrenado, confiando en RustDesk, el servicio doméstico Taobao (taobao.com) suspendió los servicios domésticos y reinició el trabajo de optimización de la versión web Java 17 es la versión Java LTS más utilizada. Cuota de mercado de Windows 10. Alcanzando el 70%, Windows 11 continúa disminuyendo. Open Source Daily | Google apoya a Hongmeng para hacerse cargo de los teléfonos Android de código abierto respaldados por Docker; Electric cierra la plataforma abierta Apple lanza el chip M4 Google elimina el kernel universal de Android (ACK) Soporte para la arquitectura RISC-V Yunfeng renunció a Alibaba y planea producir juegos independientes para plataformas Windows en el futuro