
Autor: Lu Yufeng Fuente: Zhihu
Resumen
El desarrollo de MindNLP ha durado aproximadamente un año. En general, enfrenta muchos problemas y también va acompañado de una serie de impactos y desafíos planteados por LLM. Como marco de PNL recién llegado que depende de MindSpore para su crecimiento ascendente, en realidad necesita considerar cómo expandir su ecología.
Como dice el refrán: si no puedes vencerlo, únete. Pero para el mundo del código abierto, no hay necesidad de hablar sobre unirse. Es normal que usted y yo sean parte de mí. Además, en el momento en que se anunció oficialmente Pytorch2.1 + Ascend hace dos días. El injerto ecológico es sin duda la mejor solución. Basta de chismes y vayamos al grano.
01
Conjuntos de datos de MindNLP
Desde el comienzo del diseño de MindNLP, esperamos aprovechar al máximo todas las ventajas y características de MindSpore, incluida la programación de fusión funcional, funciones de gráficos dinámicos, motores de procesamiento de datos, etc. Aquí, el motor de procesamiento de datos se saca por separado y se analiza en detalle.
1.1Motor de procesamiento de datos MindSpore
Figura 1: Diagrama esquemático del motor de datos MindSpore Pipeline
Como se muestra en la figura, el diseño del motor de datos es pipeline [1], que es muy similar al conjunto de datos de Tensorflow y al conjunto de datos estilo mapa de Pytorch, y está dirigido principalmente al procesamiento de datos de alto rendimiento.
En una era en la que todo el mundo todavía realiza pequeñas modificaciones en los modelos y pequeños conjuntos de datos para actualizar las clasificaciones, el preprocesamiento de datos generalmente se realiza fuera de línea, de modo que Python se pueda usar para procesarlos de la manera más flexible posible y, por lo general, la gran memoria del servidor puede acomodarlo. Todos rellenarán todos los datos a la vez y luego abrirán múltiples procesos para procesarlos. Después de eso, cárguelo en Tensor y envíelo a la red para su entrenamiento. Pero aun así, si el conjunto de datos es un poco más grande, puede llevar horas o incluso días preprocesar el conjunto de datos.
El método Pipeline se centra en varias capacidades:
1. Carga bajo demanda
2. Procesamiento asincrónico
3. Paralelo
Entre ellos, 1 y 2 se pueden discutir en detalle. Tomando datos de texto como ejemplo, si se utiliza la lógica de preprocesamiento de carga de Python más simple (es decir, Pytorch Dataloader), el flujo de ejecución general es el siguiente:
数据集全量加载至内存 -> 全量遍历并预处理 -> 单条数据打包Batch -> 循环返回每个Batch
El método de carga de Pipeline es
Una descripción más vívida es: Ahora hay un puntero que apunta al comienzo del archivo del conjunto de datos cada vez que recuperamos un tamaño de lote de datos, y el puntero avanza según el tamaño del lote hasta que se recupera.
Obviamente, recuperar solo una cantidad adecuada de datos cada vez puede reducir en gran medida el consumo de memoria y las variables intermedias generadas durante el proceso de preprocesamiento también se pueden comprimir a un tamaño pequeño. Además, este método puede convertir el preprocesamiento de datos fuera de línea en línea:
取Batch size条数据加载 -> Batch size条数据遍历并预处理 -> 返回一个Batch
Figura 2: Proceso de datos y proceso de computación en red
La canalización de procesamiento de datos procesa datos continuamente y envía los datos procesados al caché en el lado del Dispositivo; después de la ejecución de un Paso, los datos del siguiente Paso se leen directamente desde el caché del Dispositivo. Mientras la red se entrena, también se procesan datos y cada uno realiza sus propias funciones.
Por supuesto, este método también es un arma de doble filo. Si bien mejora la utilización de la memoria y el rendimiento, también introducirá problemas de facilidad de uso. El mapa en la Figura 1 es un procesamiento asincrónico. Después de configurar cada operación de preprocesamiento de datos, no se ejecutará ni devolverá los resultados directamente. Esto no es amigable para los datos que requieren un control preciso y tiene muchas condiciones especiales, y es muy probable que ocurra la ejecución de la canalización. De repente se desencadena una anomalía.
Sin embargo, LLM ha cambiado esta situación. Todas las tareas se han convertido en Next Token Prediction y todo el procesamiento de datos también se ha convertido en limpieza + Tokenize. La cantidad de datos es enorme y, a menudo, la transmisión de datos en escenarios comerciales se convierte naturalmente en la solución óptima. probablemente la razón principal por la que Pytorch comenzó a crear canalizaciones y los conjuntos de datos de HuggingFace también son canalizaciones).
1.2Problemas de soporte del conjunto de datos de MindNLP
Como se mencionó anteriormente, el procesamiento de datos de MindNLP utiliza completamente el motor de procesamiento de datos MindSpore y ha admitido más de 20 conjuntos de datos en un año (comparado por torchtext). Sin embargo, en el uso real, es obvio que varias tareas de PNL requieren más que estos conjuntos de datos y es difícil adaptarse continuamente a un dominio abierto.
Además, el conjunto de datos de Shengsi MindSpore también ha causado algunos problemas. El principal problema es que MindSpore Dataset ha diseñado tres tipos de cargadores, a saber:
1. Cargador de conjuntos de datos específicos: como IMDBDataset, EnWik9Dataset, etc.
2. Cargador de resúmenes de texto: TextFileDataset
3. Cargador definido por el usuario: GeneratorDataset
Si usa 1, significa que necesita agregar adaptaciones continuamente; si usa 2, debe preprocesar formatos como xml, json, etc. antes de cargar. Esto va en contra del concepto de diseño de alta eficiencia de Pipeline. Todavía enfrentamos la necesidad de adaptación manual. La cantidad de desarrollo usando 3 significa que el primer paso en la Figura 1 vuelve a la carga completa, lo que obviamente no es lo que queremos. Sin embargo, debido a la necesidad de respaldar rápidamente el conjunto de datos, elegimos el método 1 + 3 como respaldo.
Esto no es eficiente y requiere una adaptación separada cada vez. ¿Existe entonces alguna solución permanente?
02
Injerto ecológico HuggingFace
La carga del conjunto de datos de MindNLP no quiere lograr más que dos cosas:
1. Admitir grandes conjuntos de datos sin adaptación
2. Utilice un Pipeline eficiente
Como no puede hacerlo usted mismo, confiemos en el poder de la ecología. Además del almacén de Transformers, HuggingFace ha desarrollado bibliotecas para diversos procesos de entrenamiento de IA. Los conjuntos de datos se han acumulado durante varios años y admiten una gran cantidad de conjuntos de datos. Y debido a que HuggingFace proporciona servicios de alojamiento, muchos conjuntos de datos nuevos también están directamente en el. Centro de conjuntos de datos. Publicar directamente en. Usando conjuntos de datos para resolver el problema 1, veamos el segundo problema.
De hecho, la mayoría de las personas que utilizan MindSpore Dataset eligen básicamente dos métodos de procesamiento:
1. Preprocesamiento sin conexión en MindRecord y luego cargar usando MindDataset
2. Cargue el conjunto de datos en la memoria y luego cárguelo usando un cargador/GeneradorDataset de conjunto de datos específico
Para poder realizar un preprocesamiento en línea, el método 1 obviamente no es recomendable, por lo que la idea de injertar conjuntos de datos de HuggingFace también es muy simple. He considerado dos ideas y las analizaré a continuación.
2. 1 Descarga del conjunto de datos de injerto
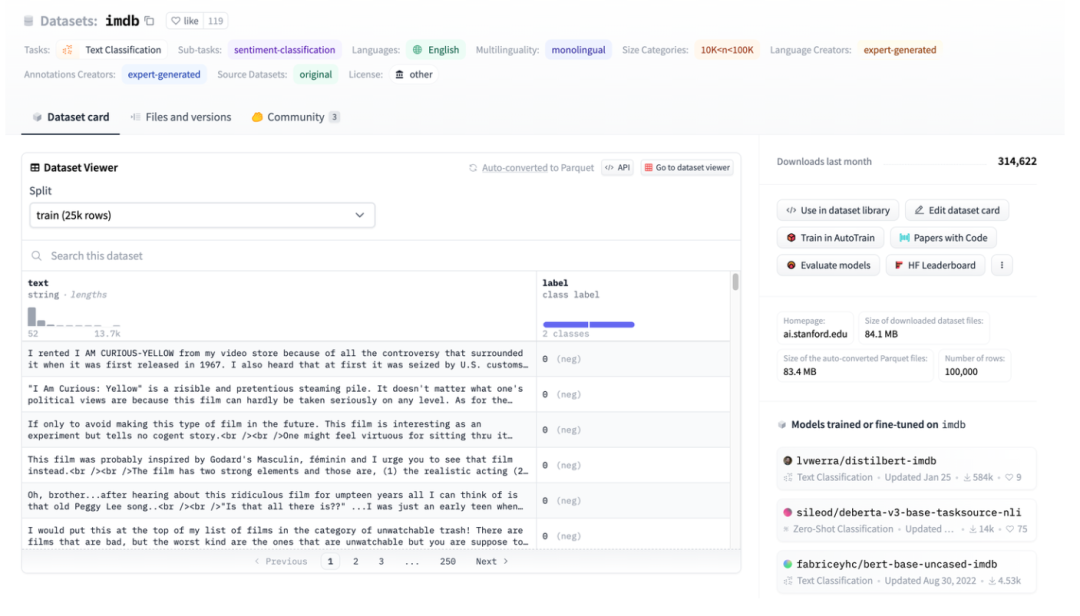 Figura 3: Ilustración del conjunto de datos HuggingFace, tomando IMDB como ejemplo
Figura 3: Ilustración del conjunto de datos HuggingFace, tomando IMDB como ejemplo
La Figura 3 es una captura de pantalla de la página imdb. Puede ver que los datos están bien estructurados. Luego use HuggingFace Datasets para descargarlos directamente y luego use directamente el cargador de datos abstractos TextFileDataset para leer los archivos procesados directamente.
Figura 4: interfaz TextFileDataset
Puede ver que TextFileDataset solo necesita pasar la ruta del archivo o la lista de rutas para cargar. Sin embargo, encontré un problema durante la operación práctica: HuggingFace Datasets usa archivos Apache Arrow.
Figura 5: Introducción al formato de flecha de los conjuntos de datos de HuggingFace
Apache Arrow[2] es un estándar de formato de intercambio de datos de alto rendimiento, multisistema e independiente del lenguaje que no se puede copiar. Esto significa que el conjunto de datos de MindSpore no se puede leer de forma directa y sencilla. Aunque también se puede operar utilizando la biblioteca pyarrow, esto aumenta la complejidad y vuelve a un estado que requiere preprocesamiento antes de cargar. Sin embargo, resulta que las características de los archivos Arrow son más adecuadas para el conjunto de datos de MindSpore.
2. 2 Ventajas del formato Arrow
En el entorno Multiwalker, los robots bípedos intentan transportar su carga y caminar hacia la derecha. Varios robots transportan una carga grande y necesitan trabajar juntos, como se muestra en la siguiente imagen.
HuggingFace utiliza el formato Apache Arrow, que tiene varias ventajas obvias:
1. El formato estándar de Arrow permite lecturas sin copia, lo que prácticamente elimina toda la sobrecarga de serialización.
2. Arrow está orientada a columnas, por lo que consultar y procesar segmentos de datos o columnas de datos es más rápido.
3. Arrow trata cada conjunto de datos como un archivo asignado en memoria. Al acceder a datos parciales en un archivo grande, no es necesario cargar el archivo completo y varios procesos pueden compartir la memoria. El mapeo de memoria permite el uso de grandes conjuntos de datos en máquinas con una memoria de dispositivo relativamente pequeña; cargar el conjunto de datos completo de Wikipedia en inglés requiere solo unos pocos MB de RAM.
4. Al cargar datos, puede configurar los parámetros de transmisión para la carga de transmisión.
En este momento, volvamos atrás y observemos el diseño del motor de datos MindSpore: la carga bajo demanda, el procesamiento en línea y los conjuntos de datos HuggingFace son una combinación perfecta.
2.3 Adaptación de MindNLP
Dado que el archivo de flecha cargado por HuggingFace Datasets en sí es un archivo mapeado en memoria, no es necesario copiarlo a la memoria, y el uso del índice no lo cargará por completo, por lo que se puede usar directamente como fuente de datos de carga y enviar. directamente al GeneratorDataset para su uso.
Figura 6: Interfaz GeneratorDataset
La construcción de GeneratorDataset requiere principalmente datos de origen y el nombre de la columna correspondiente a cada columna de datos. Mirando hacia atrás en la Figura 3, puede ver que HuggingFace Datasets ha nombrado todas las columnas. El siguiente es el código central interceptado:
from mindspore.dataset import GeneratorDataset
from datasets import load_dataset as hf_load
......
def load_dataset(...):
ds_ret = hf_load(path,
name=name,
data_dir=data_dir,
data_files=data_files,
split=split,
cache_dir=cache_dir,
features=features,
download_config=download_config,
download_mode=download_mode,
verification_mode=verification_mode,
keep_in_memory=keep_in_memory,
save_infos=save_infos,
revision=revision,
streaming=streaming,
num_proc=num_proc,
storage_options=storage_options,
)
if isinstance(ds_ret, (list, tuple)):
ds_dict = dict(zip(split, ds_ret))
else:
ds_dict = ds_ret
datasets_dict = {}
for key, raw_ds in ds_dict.items():
column_names = list(raw_ds.features.keys())
source = TransferDataset(raw_ds, column_names) if isinstance(raw_ds, Dataset) \
else TransferIterableDataset(raw_ds, column_names)
ms_ds = GeneratorDataset(
source=source,
column_names=column_names,
shuffle=shuffle,
num_parallel_workers=num_proc if num_proc else 1)
datasets_dict[key] = ms_ds
if len(datasets_dict) == 1:
return datasets_dict.popitem()[1]
return datasets_dict
Los pasos de procesamiento también son muy sencillos:
1. Cargue usando load_dataset de HuggingFace Datasets
2. Utilice clases de tránsito encapsuladas para la encapsulación.
3. Pasar GeneratorDataset
Para facilitar el uso, mantenemos la configuración de los parámetros de la interfaz load_dataset exactamente igual que los conjuntos de datos de HuggingFace, pero lo que se devuelve es una clase o Dict que puede ser procesado por el motor de datos de MindSpore, de modo que la conexión perfecta del Se pueden completar las capacidades de procesamiento de datos de Shengsi MindSpore.
Hablemos brevemente sobre la estructura de la clase de tránsito.
Los tipos de datos de HuggingFace Datasets incluyen Dataset e IterableDataset:
Hay dos tipos de objetos de conjunto de datos, un conjunto de datos y un conjunto de datos iterable. El tipo de conjunto de datos que elija utilizar o crear depende del tamaño del conjunto de datos. En general, un IterableDatase es ideal para grandes conjuntos de datos (¡piense en cientos de GB!) debido a su comportamiento lento y ventajas de velocidad, mientras que Datase es excelente para todo lo demás. Esta página comparará las diferencias entre un conjunto de datos y un conjunto de datos Iterable para ayudarle a elegir el objeto de conjunto de datos adecuado para usted.[3]
Al atravesar estos dos tipos de conjuntos de datos, se devuelve un dict, que no es compatible con el motor de procesamiento de datos de MindSpore. Por lo tanto, se crean dos clases de transferencia para leer los datos en el dict sin agregar otras operaciones adicionales. Para Dataset, construya una clase TransferDataset y léala en el método __getitem__.
class TransferDataset():
"""TransferDataset for Huggingface Dataset."""
def __init__(self, arrow_ds, column_names):
self.ds = arrow_ds
self.column_names = column_names
def __getitem__(self, index):
return tuple(self.ds[int(index)][name] for name in self.column_names)
def __len__(self):
return self.ds.dataset_size
Para transmitir datos IterableDataset, debe leerlo en el método __iter__ y construir TransferIterableDataset como un objeto iterable.
class TransferIterableDataset():
"""TransferIterableDataset for Huggingface IterableDataset."""
def __init__(self, arrow_ds, column_names):
self.ds = arrow_ds
self.column_names = column_names
def __iter__(self):
for data in self.ds:
yield tuple(data[name] for name in self.column_names)
En este punto, se ha completado un plan que requiere poco esfuerzo y puede injertar completamente los conjuntos de datos de HuggingFace. En comparación con Paddle NLP, la estrategia de injerto es simple y elegante.
03
en conclusión
Como marco de código abierto, en realidad hay una gran cantidad de recursos de código abierto que se pueden utilizar. La llamada expansión continua del ecosistema norte-sur no significa necesariamente adaptación. , y estarás feliz y sin preocupaciones. Esta vez, HuggingFace Datasets se incorpora al intercambio práctico de Shengsi MindSpore, lo que proporcionará una comprensión más profunda de Shengsi MindNLP y también ayudará a expandir el ecosistema de Shengsi MindSpore.
referencias
[1] https://www.mindspore.cn/docs/zh-CN/r2.1/design/data_engine.htm
[3] https://huggingface.co/docs/datasets/about_mapstyle_vs_iterable
Un programador nacido en los años 90 desarrolló un software de portabilidad de vídeo y ganó más de 7 millones en menos de un año. ¡El final fue muy duro! Google confirmó despidos, relacionados con la "maldición de 35 años" de los codificadores chinos en los equipos Python Flutter Arc Browser para Windows 1.0 en 3 meses oficialmente GA La participación de mercado de Windows 10 alcanza el 70%, Windows 11 GitHub continúa disminuyendo. GitHub lanza la herramienta de desarrollo nativo de IA GitHub Copilot Workspace JAVA. es la única consulta de tipo fuerte que puede manejar OLTP + OLAP. Este es el mejor ORM. Nos encontramos demasiado tarde.