
Desde la aparición de ChatGPT a finales de 2022, la inteligencia artificial se ha convertido una vez más en el centro de atención del mundo, y la IA basada en grandes modelos de lenguaje (LLM) se ha convertido en un "pollo caliente" en el campo de la inteligencia artificial. En el año transcurrido desde entonces, hemos sido testigos del rápido progreso de la IA en los campos del texto Wensheng y las imágenes Wensheng, pero el desarrollo en el campo del vídeo Wensheng ha sido relativamente lento. A principios de 2024, OpenAI lanzó una vez más un éxito de taquilla: el modelo de video de Vincent Sora. La IA completó la última pieza del rompecabezas de creación de contenido.
Hace un año, un video de Smith comiendo fideos se volvió viral en las redes sociales. En la imagen, el actor tenía un rostro horrible, rasgos faciales deformados y estaba comiendo espaguetis en una postura retorcida. Esta terrible imagen nos recuerda que la tecnología de vídeo generado por IA estaba apenas en su infancia en ese momento.

Apenas un año después, un vídeo de IA de "mujeres de moda caminando por las calles de Tokio" generado por Sora volvió a incendiar las redes sociales. En marzo siguiente, Sora unió fuerzas con artistas de todo el mundo para lanzar oficialmente una serie de cortometrajes de arte surrealista que subvirtieron la tradición. El siguiente cortometraje "Air Head" fue creado por el famoso director Walter y Sora. La imagen es exquisita y realista, y el contenido es salvaje e imaginativo. Se puede decir que Sora "aplastó" los principales modelos de video de IA como Gen-2, Pika y Stable Video Diffusion cuando debutó.

La evolución de la IA es mucho más rápida de lo esperado. Podemos prever fácilmente que la estructura industrial existente, incluidos los vídeos cortos, los juegos, el cine y la televisión, la publicidad, etc., se remodelará en un futuro próximo. La llegada de Sora parece acercarnos un paso más a un modelo para la construcción de mundos.
¿Por qué Sora tiene una magia tan poderosa? ¿Qué tecnologías mágicas utiliza? Después de revisar el informe técnico oficial y muchos documentos relacionados, el autor explicará los principios técnicos detrás de Sora y la clave de su éxito en este artículo.
1 ¿Qué problema central quiere resolver Sora?
Para resumir en una oración, el desafío que enfrenta Sora es cómo transformar múltiples tipos de datos visuales en un método de representación unificado para que se pueda realizar un entrenamiento unificado.
¿Por qué necesitamos una formación unificada? Antes de responder a esta pregunta, primero echemos un vistazo a las ideas anteriores de generación de videos de IA convencionales de Sora.
1.1 Método de generación de video con IA en la era anterior a Sora
- Ampliar según el contenido de la imagen de un solo cuadro
Las extensiones basadas en imágenes de un solo cuadro utilizan el contenido del cuadro actual para predecir el siguiente cuadro. Cada cuadro es una continuación del cuadro anterior, formando así una secuencia de video continua (la esencia del video es una imagen que se muestra continuamente cuadro por cuadro). .
En este proceso, las descripciones de texto generalmente se utilizan para generar imágenes y luego se generan videos basados en las imágenes. Sin embargo, hay un problema con esta idea: el uso de texto para generar imágenes en sí es aleatorio. Esta aleatoriedad se amplifica dos veces cuando se usan imágenes para generar videos, y la controlabilidad y estabilidad del video final son muy bajas.
- Entrena directamente en todo el vídeo.
Dado que el efecto de vídeo basado en la derivación de un solo cuadro no es bueno, la idea se cambia a entrenar todo el vídeo.
Aquí, generalmente se selecciona un videoclip de unos segundos y se le dice al modelo lo que muestra el video. Después de mucho entrenamiento, la IA puede aprender a generar videoclips que sean similares en estilo a los datos de entrenamiento. El defecto de esta idea es que el contenido aprendido por la IA está fragmentado, es difícil generar vídeos largos y la continuidad de los vídeos es pobre.
Algunas personas pueden preguntar, ¿por qué no utilizar vídeos más largos para entrenar? La razón principal es que los videos son muy grandes en comparación con el texto y las imágenes, y la tarjeta gráfica tiene una memoria de video limitada y no puede soportar entrenamientos de video más largos. Bajo diversas restricciones, la cantidad de conocimiento de la IA es extremadamente limitada. Cuando se introduce contenido que “no conoce”, los resultados generados suelen ser insatisfactorios.
Por lo tanto, si desea superar el cuello de botella del vídeo con IA, debe resolver estos problemas centrales.
1.2 Desafíos en el entrenamiento de modelos de video
Los datos de vídeo vienen en varias formas, desde pantalla horizontal a pantalla vertical, desde 240p a 4K, diferentes relaciones de aspecto, diferentes resoluciones y diferentes atributos de vídeo. La complejidad y diversidad de los datos plantea grandes dificultades para el entrenamiento de la IA, lo que a su vez conduce a un rendimiento deficiente del modelo. Es por eso que estos datos de video deben representarse primero de manera unificada.
La tarea principal de Sora es encontrar una manera de convertir múltiples tipos de datos visuales en un método de representación unificado para que todos los datos de video puedan entrenarse de manera efectiva bajo un marco unificado.
1.3 Sora: Hitos hacia AGI
Nuestra misión es garantizar que la inteligencia artificial general beneficie a toda la humanidad. —— AbiertoAI
El objetivo de OpenAI siempre ha sido claro: lograr inteligencia artificial general (AGI), entonces, ¿qué importancia tiene el nacimiento de Sora para lograr el objetivo de OpenAI?
Para implementar AGI, el modelo grande debe comprender el mundo. A lo largo del desarrollo de OpenAI, el modelo GPT inicial permitió a la IA comprender texto (una dimensión, solo largo), y el modelo DALL·E lanzado posteriormente permitió a la IA comprender imágenes (dos dimensiones, largo y ancho), y ahora el modelo Sora. permite a la IA comprender el video (tridimensional, largo, ancho y tiempo).
A través de una comprensión integral de textos, imágenes y videos, la IA puede comprender gradualmente el mundo. Sora es la avanzada de OpenAI para AGI. Es más que un simple modelo de generación de video, como dice el título de su informe técnico [1]: "Un modelo de generación de video como simulador mundial".
La visión de Tuoshupai coincide con el objetivo de OpenAI. Los extensionistas creen que el uso de una pequeña cantidad de símbolos y modelos computacionales para modelar la sociedad humana y la inteligencia individual sentó las bases para la IA temprana, pero mayores dividendos dependen de mayores cantidades de datos y una mayor potencia informática. Cuando no podemos construir un modelo nuevo e innovador, podemos buscar más conjuntos de datos y utilizar mayor potencia informática para mejorar la precisión del modelo, intercambiar potencia informática de datos por potencia del modelo e impulsar la innovación en los sistemas informáticos de datos. En el sistema de computación de datos de modelo grande lanzado por Tuoshupai, los modelos matemáticos, los datos y los cálculos de la IA estarán perfectamente conectados y se reforzarán mutuamente como nunca antes, convirtiéndose en una nueva fuerza productiva que promueve el desarrollo de alta calidad de la sociedad [2].
2 Interpretación del principio de Sora
Sora no es el primer modelo de vídeo de Vincent que se lanza, entonces, ¿por qué está causando tanto revuelo? ¿Cuál es el secreto detrás de esto? Si describe el proceso de entrenamiento de Sora en una oración: el video original se comprime en un espacio latente a través de un codificador visual y se descompone en parches de espacio-tiempo, que se combinan con texto. Se utilizan restricciones condicionales para realizar el entrenamiento de difusión y la generación a través del transformador. Los bloques de imágenes finalmente se asignan nuevamente al espacio de píxeles a través del decodificador visual correspondiente.
2.1 Red de compresión de vídeo
Sora primero convierte datos de video sin procesar en características de espacio latente de baja dimensión. Los datos de vídeo que vemos todos los días son demasiado grandes y primero deben convertirse en vectores de baja dimensión que la IA pueda procesar. En este caso, OpenAI se basa en un artículo clásico: Modelos de difusión latente[3].
El punto central de este artículo es refinar la imagen original en una característica espacial latente, que no solo puede retener la información de características clave de la imagen original, sino que también comprime en gran medida la cantidad de datos e información.
Es probable que OpenAI haya actualizado el codificador automático variacional (VAE) de las imágenes de este documento para admitir el procesamiento de datos de vídeo. De esta manera, Sora puede convertir una gran cantidad de datos de video originales en características de espacio latente de baja dimensión, es decir, extraer la información clave central del video, que puede representar el contenido clave del video.
2.2 Parches de espacio-tiempo
Para realizar un entrenamiento por vídeo de IA a gran escala, primero se debe definir la unidad básica de datos de entrenamiento. En el modelo de lenguaje grande (LLM), la unidad básica de formación es Token[4]. OpenAI se inspira en el éxito de ChatGPT: el mecanismo Token unifica elegantemente diferentes formas de texto: código, símbolos matemáticos y varios lenguajes naturales. ¿Podrá Sora encontrar su "Token"?
Gracias a los resultados de investigaciones anteriores, Sora finalmente encontró la respuesta: Patch.
- Transformador de visión (ViT)
¿Qué es un parche? Parche puede entenderse coloquialmente como un bloque de imágenes. Cuando la resolución de la imagen a procesar es demasiado grande, el entrenamiento directo no es práctico. Por lo tanto, en el artículo Vision Transformer [5] se propone un método: dividir la imagen original en bloques de imagen (Patch) del mismo tamaño, y luego serializar estos bloques de imagen y agregar su información de posición ( Position Embedding), de modo que las imágenes complejas se puede convertir en las secuencias más familiares de la arquitectura Transformer, utilizando el mecanismo de autoatención para capturar la relación entre cada bloque de imagen y, en última instancia, comprender el contenido de toda la imagen.
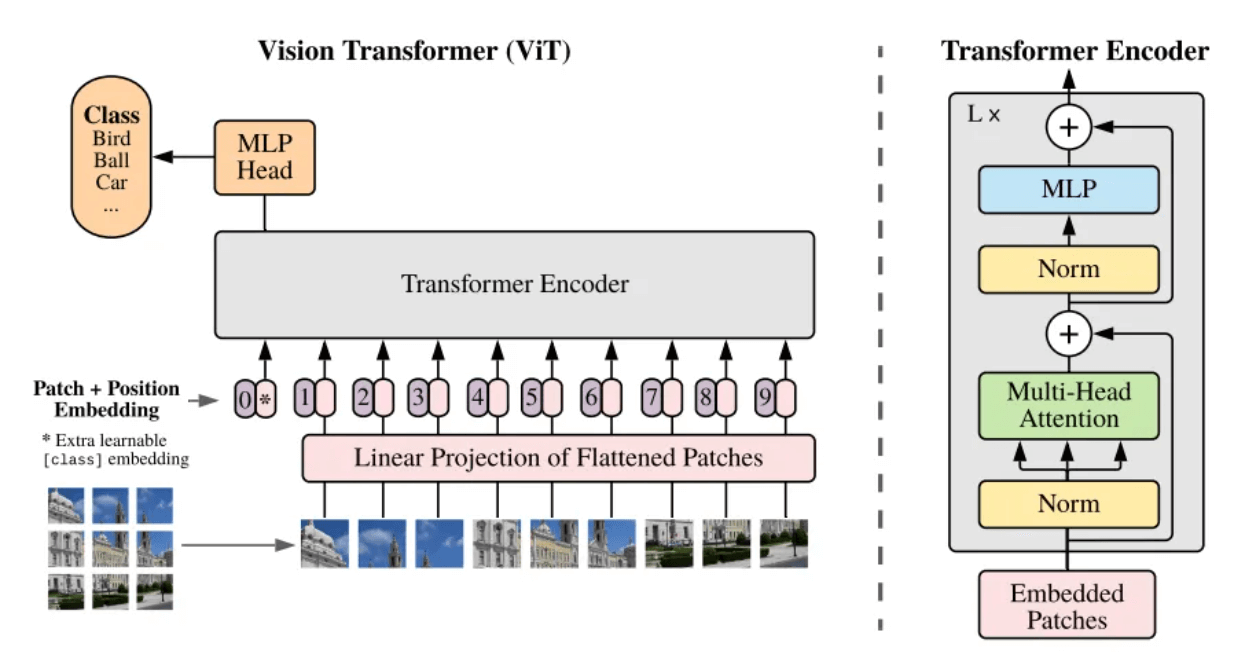
Estructura marco del modelo ViT[5]
El video puede verse como una secuencia de imágenes distribuidas a lo largo del eje del tiempo, por lo que Sora agrega la dimensión del tiempo, actualizando bloques de imágenes estáticas en parches de imágenes de espacio-tiempo (Spacetime Patches). Cada bloque de imagen espacio-temporal contiene información temporal e información espacial en el video. Es decir, un bloque de imagen espacio-temporal no solo representa un área espacial pequeña en el video, sino que también representa los cambios en esta área espacial durante un período de. tiempo.
Al introducir el concepto de parche, la correlación espacial se puede calcular para bloques de imágenes espacio-temporales en diferentes posiciones en un solo cuadro; la correlación temporal se puede calcular para bloques de imágenes espacio-temporales en la misma posición en cuadros consecutivos. Cada bloque de imagen ya no existe de forma aislada, sino que está estrechamente relacionado con los elementos que lo rodean. De esta manera, Sora es capaz de comprender y generar contenido de vídeo con ricos detalles espaciales y dinámica temporal.

Descomponer fotogramas de secuencia en bloques de imágenes espaciotemporales
- Resolución nativa (NaViT)
Sin embargo, el modelo ViT tiene una gran desventaja: la imagen original debe ser cuadrada y cada bloque de imagen debe tener el mismo tamaño fijo. Los videos diarios son solo anchos o altos y no hay videos cuadrados.
Por lo tanto, OpenAI encontró otra solución: la tecnología "Patch n' Pack" [6] en NaViT , que puede procesar contenido de entrada de cualquier resolución y relación de aspecto.
Esta tecnología divide el contenido con diferentes relaciones de aspecto y resoluciones en bloques de imágenes. Estos bloques de imágenes se pueden cambiar de tamaño según las diferentes necesidades. Los bloques de imágenes de diferentes imágenes se pueden empaquetar de manera flexible en la misma secuencia para una capacitación unificada. Además, esta tecnología también puede descartar bloques de imágenes idénticos en función de la similitud de las imágenes, lo que reduce significativamente el costo de capacitación y logra una capacitación más rápida.
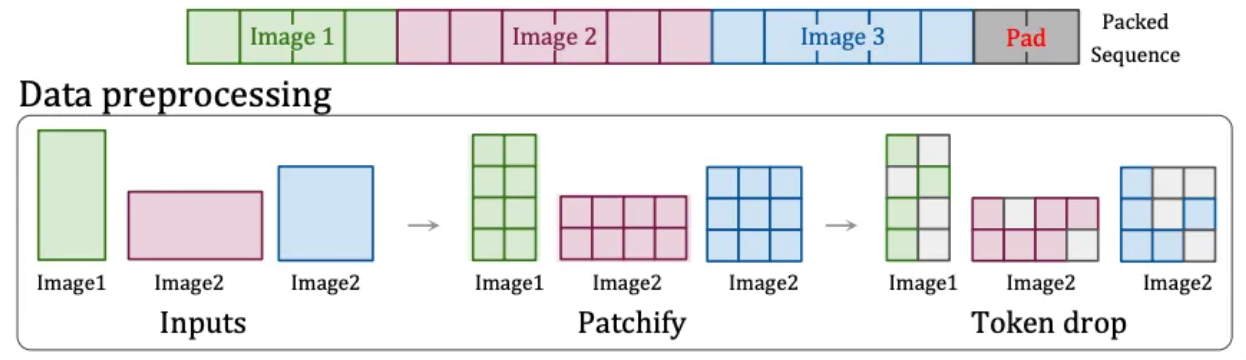
Tecnología Patch n'Pack[6]
Es por eso que Sora puede admitir la generación de videos de diferentes resoluciones y relaciones de aspecto. Además, entrenar con la relación de aspecto nativa puede mejorar la composición y el encuadre del vídeo de salida, porque al recortar inevitablemente se perderá información y el modelo fácilmente malinterpretará el contenido principal de la imagen original, lo que dará como resultado una imagen con solo una parte del contenido principal. cuerpo.
El papel que desempeñan los parches del espacio-tiempo es el mismo que el de Token en el modelo de lenguaje grande. Es la unidad básica de video. Cuando comprimimos y descomponemos un video en una serie de parches espaciotemporales, en realidad convertimos la información visual continua en. Una serie de unidades discretas que el modelo puede procesar y que son la base para el aprendizaje y la generación del modelo.
2.3 Descripción del texto del vídeo
A través de la explicación anterior, hemos entendido el proceso por el cual Sora convierte videos originales en vectores espacio-temporales finales entrenables. Pero hay un problema que debe resolverse antes del entrenamiento real: decirle al modelo de qué trata este video.
Para entrenar un modelo de video Wensheng, es necesario establecer una correspondencia entre texto y video . Durante el entrenamiento, se requiere una gran cantidad de videos con descripciones de texto correspondientes. Sin embargo, la calidad de las descripciones anotadas manualmente es baja e irregular, lo que afecta la calidad. resultados del entrenamiento. Por lo tanto, OpenAI tomó prestada la tecnología de resubtitulado [7] de su propio DALL·E 3 y la aplicó al campo del vídeo.
Específicamente, OpenAI primero entrenó un modelo de generación de subtítulos altamente descriptivo y utilizó este modelo para generar información de descripción detallada para todos los videos en el conjunto de entrenamiento de acuerdo con las especificaciones. Esta parte de la información de descripción del texto se combinó con los parches de imágenes espaciotemporales mencionados anteriormente durante la final. Después del entrenamiento y la comparación, Sora puede comprender y corresponder a los bloques de descripción de texto y de imagen de video.
Además, OpenAI también utilizará GPT para convertir las breves indicaciones del usuario en oraciones descriptivas más detalladas similares a las del entrenamiento, lo que permite a Sora seguir con precisión las indicaciones del usuario y generar videos de alta calidad.
2.4 Formación y generación de vídeos.
En el informe técnico oficial [1] se menciona claramente que Sora es un transformador de difusión, es decir, Sora es un modelo de difusión con Transformer como red troncal.
- Transformador de transmisión (DiT)
El concepto de difusión proviene del proceso de difusión en física, por ejemplo, cuando se deja caer una gota de tinta en agua, se extenderá lentamente con el tiempo. Esta difusión es el proceso de baja entropía a alta entropía. Se dispersará gradualmente de una gota a varias partes de agua.
Inspirado en este proceso de difusión nació el Modelo de Difusión. Es un modelo clásico de "dibujo" en el que se basan Stable Diffusion y Midjourney. Su principio básico es agregar ruido gradualmente a la imagen original, permitiéndole convertirse gradualmente en un estado de ruido completo, y luego revertir este proceso, es decir, eliminar ruido (Denoise) para restaurar la imagen. Al permitir que el modelo aprenda una gran cantidad de experiencias de inversión, el modelo eventualmente aprende a generar contenido de imagen específico a partir de la imagen de ruido.
Según el informe, es probable que el método de Sora reemplace la arquitectura U-Net en el modelo Diffusion original con la arquitectura Transformer con la que está más familiarizado. Porque según la experiencia en otras tareas de aprendizaje profundo, en comparación con U-Net, los parámetros de la arquitectura Transformer son altamente escalables. A medida que aumenta el número de parámetros, la mejora del rendimiento de la arquitectura Transformer será más obvia.
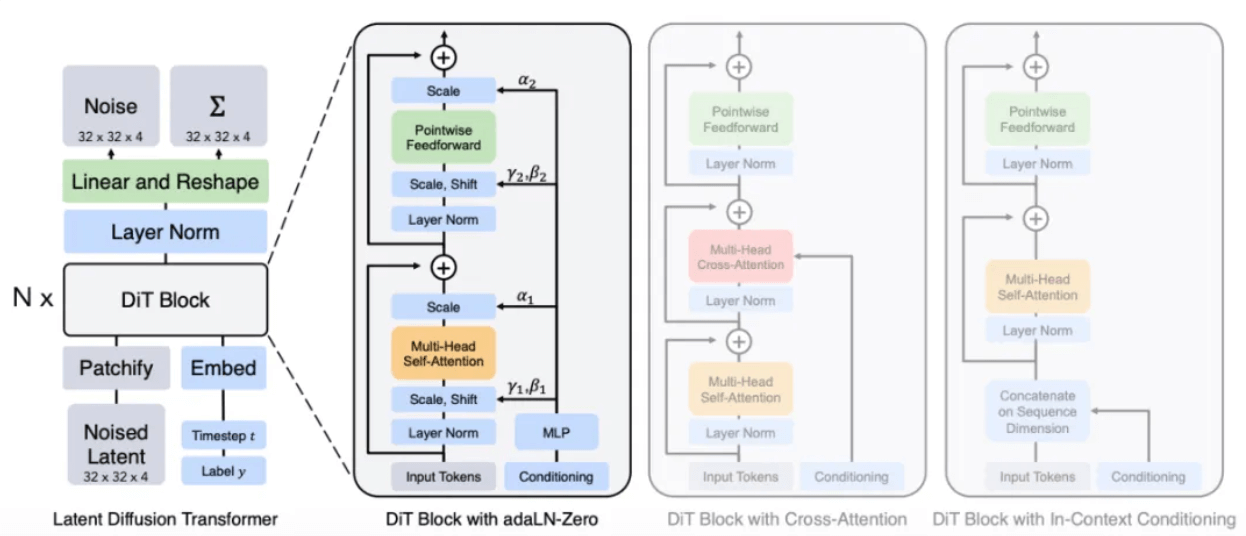
Arquitectura del modelo DiT[8]
A través de un proceso similar al modelo de difusión, se proporcionan parches de ruido (e información condicional como indicaciones de texto) durante el entrenamiento, y se agrega ruido y se elimina el ruido repetidamente, y finalmente el modelo aprende a predecir los parches originales.

Restaurar el parche de ruido al parche de imagen original
- Proceso de generación de vídeo.
Finalmente, resumimos todo el proceso de Sora generando videos a partir de texto.
Cuando el usuario ingresa una descripción de texto, Sora primero llamará al modelo para expandirlo a una oración de descripción de video estándar y luego generará un bloque de imagen espacio-temporal inicial a partir del ruido basado en la descripción. basado en el bloque de imagen espacio-temporal existente y las condiciones de texto, se especula que se generará el siguiente bloque de imagen espacio-temporal (similar a GPT que predice el siguiente token en función del token existente) y, finalmente, la representación potencial generada se asigna nuevamente a. el espacio de píxeles a través del decodificador correspondiente para formar un vídeo.
3 El potencial de la informática de datos
Al observar el informe técnico de Sora, podemos encontrar que, de hecho, Sora no ha logrado un gran avance en tecnología, pero ha integrado bien el trabajo de investigación anterior. Después de todo, ninguna tecnología aparecerá de repente. La razón más crítica del éxito de Sora es la acumulación de datos y potencia informática.
Sora muestra efectos de escala obvios durante el proceso de capacitación. La siguiente figura muestra que para insumos fijos y semillas, a medida que aumenta la cantidad de cálculo, la calidad de las muestras generadas mejora significativamente.

Comparación de efectos bajo potencia informática básica, 4 veces potencia informática y 32 veces potencia informática
Además, al aprender de grandes cantidades de datos, Sora también demostró algunas habilidades inesperadas.
➢ Consistencia 3D: Sora es capaz de generar videos con movimientos dinámicos de cámara. A medida que la cámara se mueve y gira, los personajes y los elementos de la escena siempre mantienen patrones de movimiento consistentes en el espacio tridimensional.
➢Consistencia a largo plazo y persistencia del objeto: en planos generales, las personas, los animales y los objetos mantienen una apariencia consistente incluso después de ser ocluidos o salir del encuadre.
➢Interactividad mundial : Sora puede simular comportamientos que afectan el estado del mundo de una manera sencilla. Por ejemplo, en el vídeo que describe la pintura, cada trazo deja una marca en el lienzo.
➢Simular el mundo digital: Sora también puede simular vídeos de juegos, como "Minecraft".
Estas propiedades no requieren un sesgo inductivo explícito hacia los objetos 3D, etc., son puramente un fenómeno de efectos de escala.
4 Sistema informático de datos de modelo grande Tuoshupai
El éxito de Sora demuestra una vez más la eficacia de la estrategia de "un mayor poder hace milagros": la expansión continua de la escala del modelo promoverá directamente la mejora del rendimiento, que depende en gran medida de una gran cantidad de conjuntos de datos de alta calidad y ultra- La potencia informática a gran escala es indispensable.
Al comienzo de su creación, Tuoshupai posicionó su misión como "computación de datos, solo para nuevos descubrimientos", y nuestro objetivo es crear un "juego de modelo infinito". Su sistema de computación de datos de modelos grandes utiliza tecnología nativa de la nube para reconstruir el almacenamiento y la computación de datos, con un almacenamiento único y computación de datos de múltiples motores, lo que hace que los modelos de IA sean más grandes y más rápidos, y actualiza integralmente el sistema de big data a la era de los modelos grandes.
En el sistema informático de datos de modelo grande, todo el mundo y sus movimientos se pueden digitalizar en datos. Los datos se pueden utilizar para entrenar el modelo inicial y luego se agregan al sistema informático de datos. El proceso continúa iterando y explorando infinitamente la inteligencia de IA. En el futuro, Tuoshupai continuará explorando el campo de los datos, fortaleciendo las capacidades de investigación de tecnología central, trabajando con socios de la industria para explorar las mejores prácticas en la industria de elementos de datos y promoviendo la toma de decisiones inteligente digital.
Nota: El informe técnico oficial de OpenAI solo muestra el método de modelado general y no incluye ningún detalle de implementación. Si hay algún error en este artículo, corríjame y comuníquese conmigo.
referencias:
- [1] Modelos de generación de vídeo como simuladores del mundo
- [2] Sistema informático de datos de modelo grande: teoría
- [3] Síntesis de imágenes de alta resolución con modelos de difusión latente
- [4] Atención es todo lo que necesitas
- [5] Una imagen vale 16 × 16 palabras: transformadores para el reconocimiento de imágenes a escala
- [6] Patch n'Pack: NaViT, un transformador de visión para cualquier relación de aspecto y resolución
- [7] Mejora de la generación de imágenes con mejores subtítulos
- [8] Modelos de difusión escalables con transformadores