
¡Open-Sora se ha actualizado silenciosamente en la comunidad de código abierto! Una sola lente ahora admite la generación de video de hasta 16 segundos en resoluciones de hasta 720p y puede manejar cualquier relación de aspecto: texto a imagen, texto a video, imagen a video, video a video y generación de video de duración ilimitada. necesidades. Probemos el efecto.
Genere una escena de nieve navideña en pantalla horizontal y publíquela en el sitio B

Crea una pantalla vertical nuevamente y haz Douyin.

También puede generar vídeos largos con una sola toma de 16 segundos, ahora todo el mundo puede volverse adicto a la escritura de guiones.

¿Cómo jugar? Direcciones para llegar a GitHub: github.com/hpcaitech/Open-Sora
Lo que es aún mejor es que la última versión de Open-Sora sigue siendo de código abierto y está llena de sinceridad. El almacén contiene la última arquitectura de modelo, los últimos pesos de modelo, procesos de entrenamiento de tiempo múltiple/resolución/relación de aspecto/velocidad de cuadros, y recopilación de datos. y El proceso completo de preprocesamiento, todos los detalles de la capacitación, ejemplos de demostración y tutoriales detallados de introducción .
1. Interpretación integral de informes técnicos
Recientemente, el equipo de autores de Open-Sora lanzó oficialmente la última versión del informe técnico [1] en GitHub. A continuación, utilizaremos el informe técnico para interpretar las funciones, la arquitectura, los métodos de capacitación, la recopilación de datos, el preprocesamiento y otros. aspectos uno por uno.
1.1 Descripción general de las últimas funciones
Esta actualización de Open-Sora incluye principalmente las siguientes características clave:
- Admite generación de videos largos;
- La resolución de generación de vídeo puede alcanzar hasta 720p;
- Un solo modelo admite cualquier relación de aspecto, diferentes resoluciones y duraciones: texto a imagen, texto a video, imagen a video, video a video y necesidades ilimitadas de generación de video;
- Propuso un diseño de arquitectura de modelo más estable que admita entrenamiento de tiempo múltiple/resolución/relación de aspecto/velocidad de fotogramas;
- El último proceso de procesamiento automático de datos es de código abierto;
1.2 Modelo de difusión espacio-temporal
Esta actualización de Open-Sora ha realizado mejoras clave en la arquitectura STDiT en la versión 1.0, con el objetivo de mejorar la estabilidad del entrenamiento y el rendimiento general del modelo. Para la tarea de predicción de secuencia actual, el equipo adoptó las mejores prácticas de modelos de lenguaje grandes (LLM) y reemplazó la codificación posicional sinusoidal en atención temporal con la codificación posicional rotacional más eficiente (incrustación RoPE).
Además, para mejorar la estabilidad del entrenamiento, se refirieron a la arquitectura del modelo SD3 e introdujeron aún más la tecnología de normalización QK para mejorar la estabilidad del entrenamiento de media precisión. Para respaldar los requisitos de capacitación de múltiples resoluciones, diferentes relaciones de aspecto y velocidades de cuadros, la arquitectura ST-DiT-2 propuesta por el equipo del autor puede escalar automáticamente la codificación de posición y manejar entradas de diferentes tamaños.
1.3 Entrenamiento en varias etapas
El informe técnico indica que Open-Sora utiliza un método de entrenamiento de múltiples etapas, donde cada etapa continúa entrenando en función de los pesos de la etapa anterior. En comparación con el entrenamiento de una sola etapa, este entrenamiento de múltiples etapas logra el objetivo de generar videos de alta calidad de manera más eficiente al introducir datos paso a paso.
- Etapa inicial: la mayoría de los videos usan una resolución de 144p y se combinan con imágenes y videos de 240p y 480p para el entrenamiento. El entrenamiento dura aproximadamente 1 semana y el tamaño total del paso es de 81k.
- La segunda etapa: aumentar la resolución de la mayoría de los datos de video a 240p y 480p, con un tiempo de entrenamiento de 1 día y un tamaño de paso de 22k.
- La tercera etapa: mejorada aún más a 480p y 720p, la duración del entrenamiento es de 1 día y se completa el entrenamiento de pasos de 4k. Todo el proceso de formación de varias etapas se completó en aproximadamente 9 días.
En comparación con la 1.0, la última versión mejora la calidad de la generación de vídeo en múltiples dimensiones.
1.4 Marco unificado de vídeo generador de imágenes/vídeo generador de vídeo
El equipo de autores afirmó que, según las características de Transformer, la arquitectura DiT se puede ampliar fácilmente para admitir tareas de imagen a imagen y de vídeo a vídeo. Propusieron una estrategia de enmascaramiento para respaldar el procesamiento condicional de imágenes y videos. Al configurar diferentes máscaras, se pueden admitir varias tareas de generación, que incluyen: video gráfico, video en bucle, extensión de video, generación autorregresiva de video, conexión de video, edición de video, inserción de cuadros, etc.
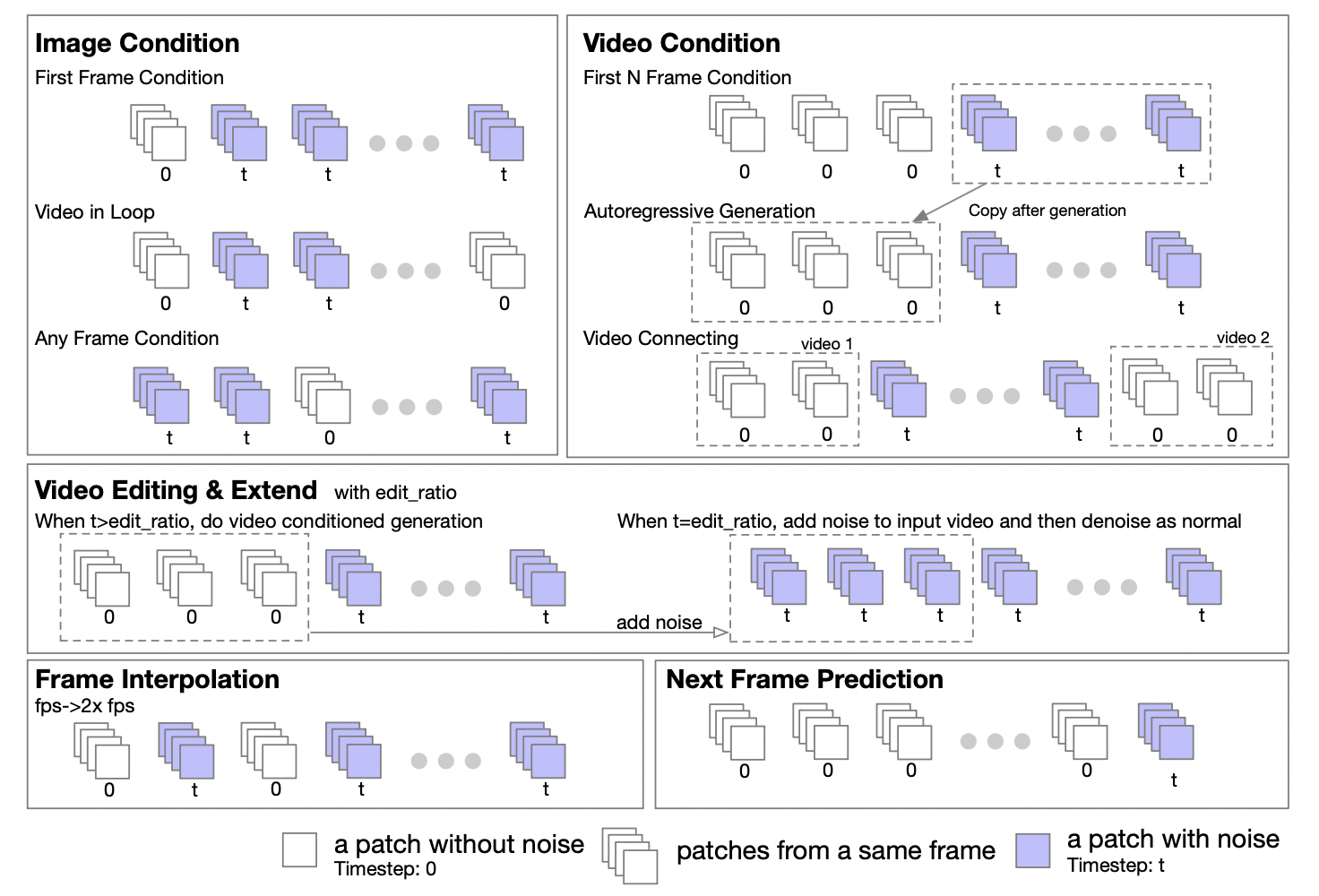
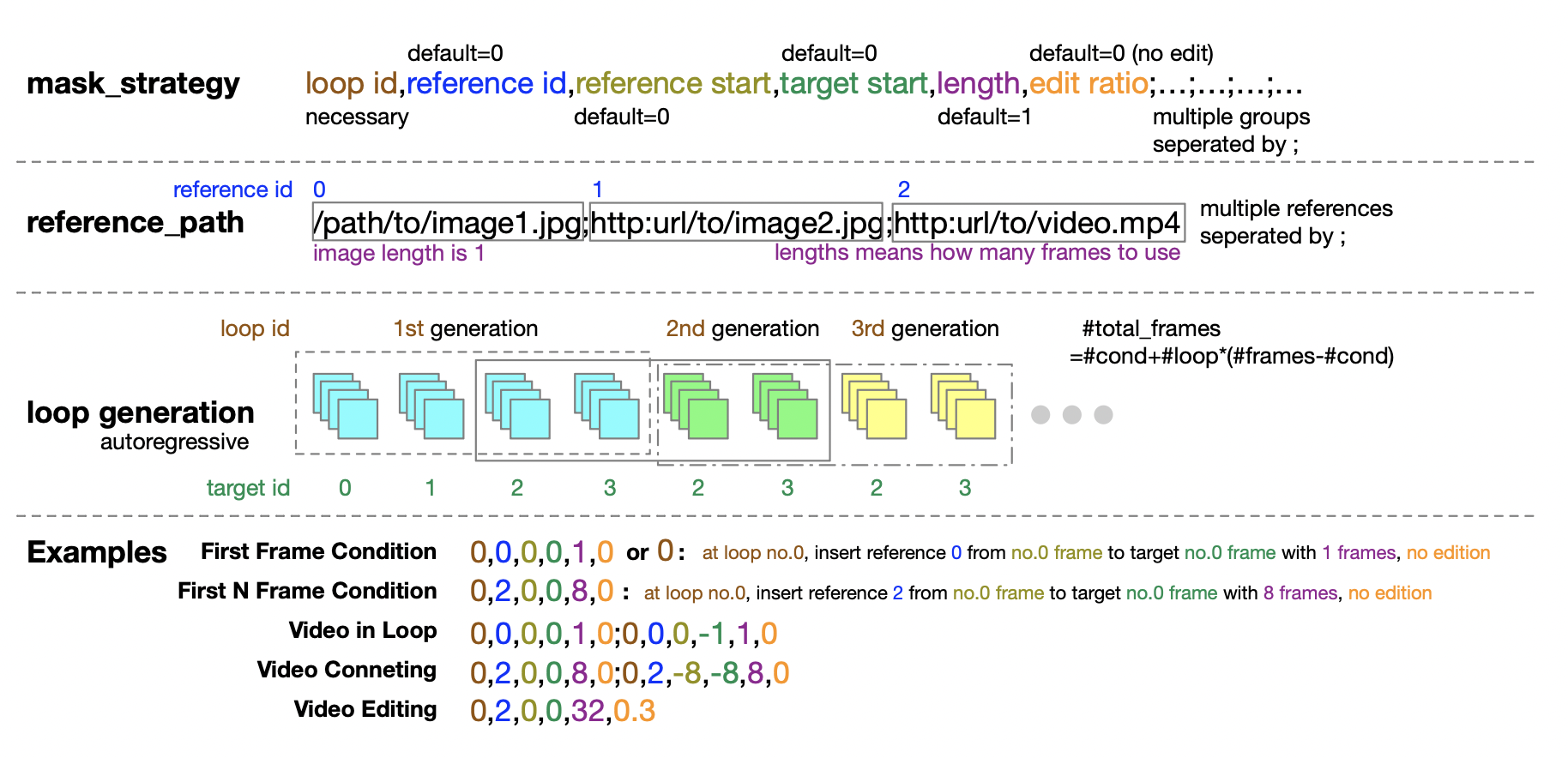
Inspirándose en el método UL2[2], introdujeron una estrategia de enmascaramiento aleatorio en la etapa de entrenamiento del modelo. Específicamente, se trata de seleccionar y desenmascarar fotogramas aleatoriamente durante el proceso de entrenamiento, incluido, entre otros, desenmascarar el primer fotograma, los primeros k fotogramas, los siguientes k fotogramas, cualquier k fotograma, etc. El informe también reveló que, según experimentos en Open-Sora 1.0, al aplicar la estrategia de enmascaramiento con un 50% de probabilidad, el modelo puede aprender mejor a manejar el condicionamiento de imágenes con solo unos pocos pasos. En la última versión de Open-Sora, adoptaron un método de preentrenamiento desde cero utilizando una estrategia de enmascaramiento.
Además, el equipo de autores también proporciona cuidadosamente una guía detallada para la configuración de la política de enmascaramiento para la etapa de inferencia. La forma de tupla de cinco números proporciona una gran flexibilidad y control al definir la política de enmascaramiento.
1.5 Admite entrenamiento de tiempo múltiple/resolución/relación de aspecto/velocidad de fotogramas
El informe técnico de OpenAI Sora [3] señala que el entrenamiento utilizando la resolución, relación de aspecto y duración del video original puede aumentar la flexibilidad de muestreo y mejorar los fotogramas y la composición. En este sentido, el equipo de autores propuso una estrategia de agrupación.
¿Cómo implementarlo específicamente? A través de una lectura en profundidad del informe técnico publicado por el autor, aprendimos que el llamado cubo es un triplete de (resolución, número de fotogramas, relación de aspecto). Predefinen una variedad de relaciones de aspecto para videos con diferentes resoluciones para cubrir los tipos de relaciones de aspecto de video más comunes. Antes de que comience cada ciclo de entrenamiento epoch, reorganizan el conjunto de datos y asignan muestras a los grupos correspondientes según sus características. Específicamente, pusieron cada muestra en un grupo cuya resolución y duración de cuadro son menores o iguales a esa característica de video.
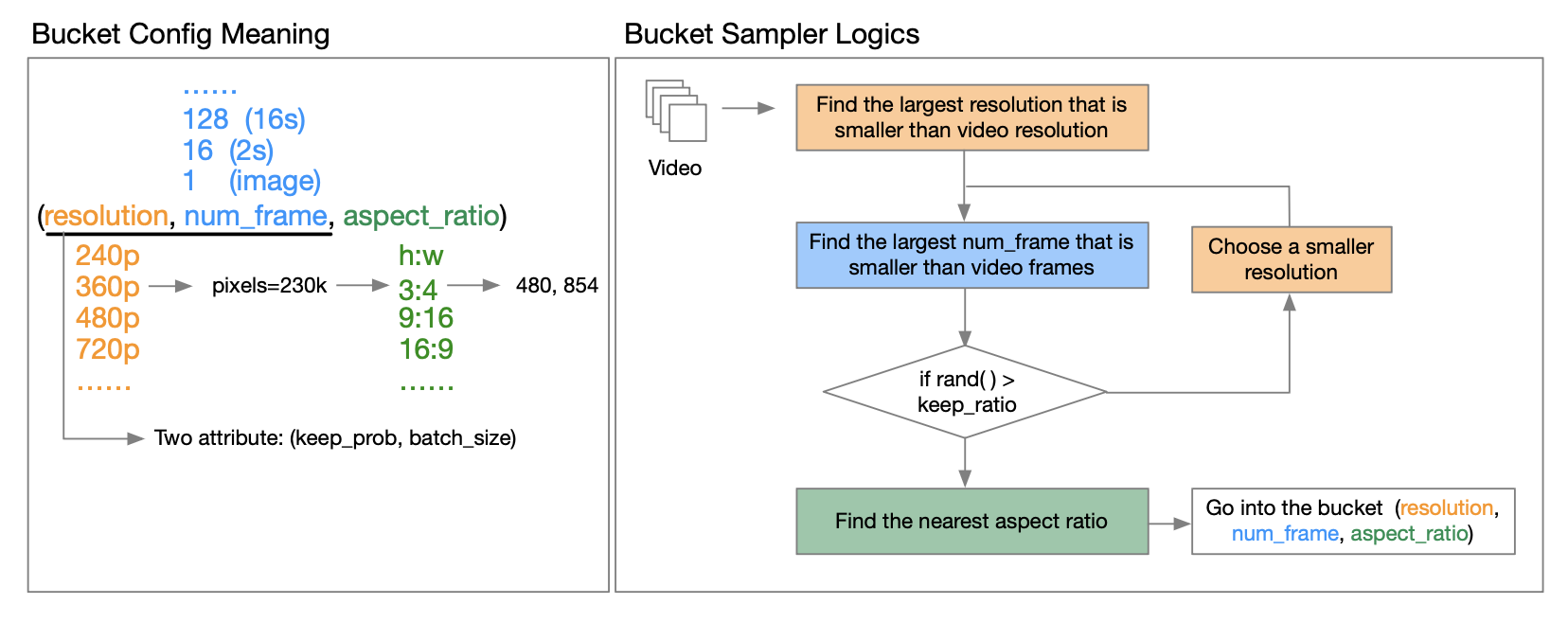
Para reducir los requisitos de recursos computacionales, introducen dos atributos (resolución, número de cuadros) para cada uno keep_proby para reducir los costos computacionales y permitir el entrenamiento en múltiples etapas. batch_sizeEsto le permite controlar la cantidad de muestras en diferentes depósitos y equilibrar la carga de la GPU buscando un buen tamaño de lote para cada depósito. Esto se explica en detalle en el informe técnico. Los amigos interesados pueden leer el informe técnico en GitHub para obtener más información.
Dirección de GitHub: github.com/hpcaitech/Open-Sora
1.6 Proceso de recopilación y preprocesamiento de datos
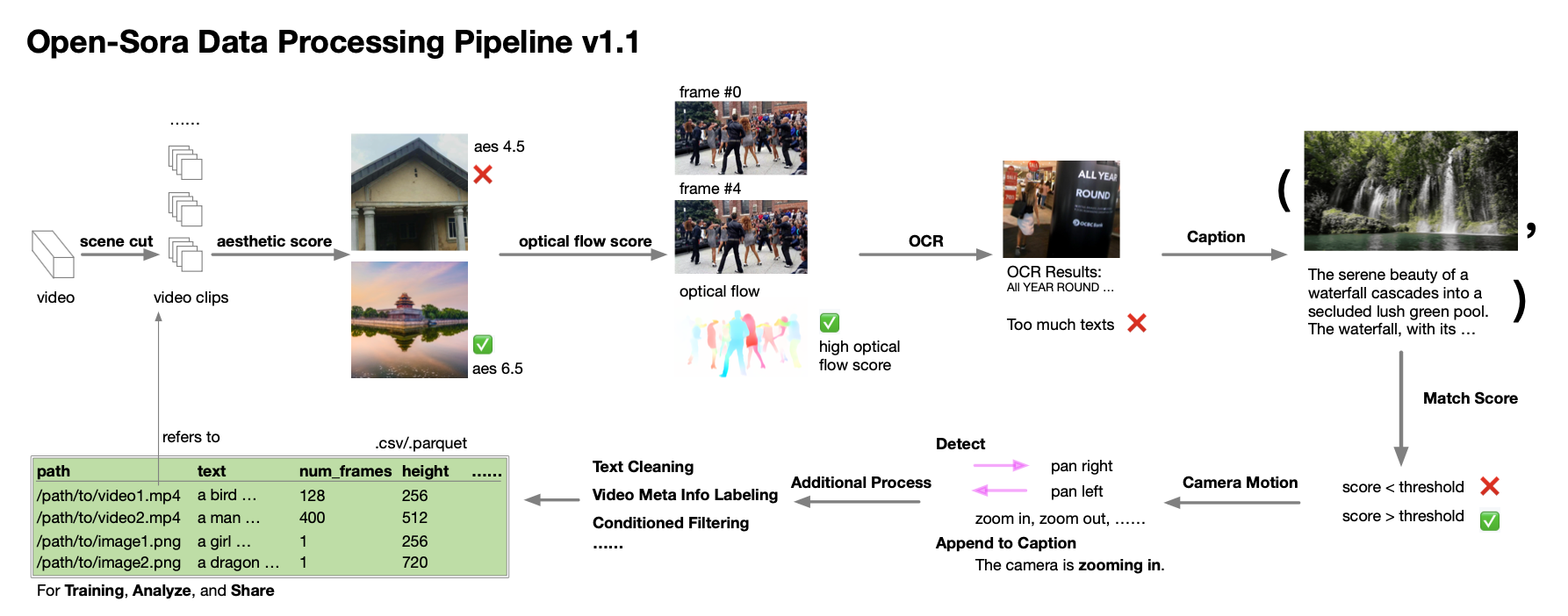
El equipo de autores incluso proporciona orientación detallada sobre la recopilación y el procesamiento de datos. Según el informe técnico, durante el proceso de desarrollo de Open-Sora 1.0, se dieron cuenta de que la cantidad y calidad de los datos son extremadamente críticas para cultivar un modelo de alto rendimiento, por lo que trabajaron para expandir y optimizar el conjunto de datos. Establecieron un proceso de procesamiento de datos automatizado que sigue el principio de descomposición de valores singulares (SVD) y cubre la segmentación de escenas, el procesamiento de subtítulos, la puntuación y el filtrado de diversidad, así como el sistema de gestión y especificación del conjunto de datos.
Asimismo, comparten desinteresadamente scripts relacionados con el procesamiento de datos con la comunidad de código abierto. Los desarrolladores interesados ahora pueden utilizar estos recursos, combinados con informes técnicos y código, para procesar y optimizar de manera eficiente sus propios conjuntos de datos.
2. Evaluación integral del desempeño
Habiendo dicho tantos detalles técnicos, disfrutemos de los efectos de última generación de video de Open-Sora y relajémonos.
Lo más destacado de esta actualización de Open-Sora es que puede capturar y transformar la escena en su mente en un video en movimiento a través de una descripción de texto. Las imágenes e imaginaciones que pasan por su mente ahora pueden grabarse permanentemente y compartirse con otros. Aquí, el autor probó varias sugerencias diferentes como punto de partida.
2.1 Paisaje
Por ejemplo, el autor intentó generar un vídeo de un recorrido por un bosque invernal. No mucho después de que cayera la nieve, los pinos se cubrieron de nieve blanca. Agujas de pino oscuras y copos de nieve blancos estaban esparcidos en capas claras.

O, en una noche tranquila, te encuentras en un bosque oscuro como el que se describe en innumerables cuentos de hadas, con el profundo lago brillando bajo las brillantes estrellas que cubren todo el cielo.

La vista nocturna de la bulliciosa isla desde el aire es aún más hermosa. Las cálidas luces amarillas y el agua azul en forma de cinta hacen que la gente se sienta atraída instantáneamente por el tiempo libre de las vacaciones.

La ciudad está repleta de tráfico, y los edificios altos y las tiendas callejeras con luces aún encendidas a altas horas de la noche tienen un sabor diferente.

2.2 Organismos naturales
Además de los paisajes, Open-Sora también puede restaurar varias criaturas naturales. Ya sea una pequeña flor roja,

Ya sea un camaleón que gira lentamente la cabeza, Open-Sora puede generar vídeos más realistas.

2.3 Diferentes resoluciones/relaciones de aspecto/duraciones
El autor también realizó una variedad de pruebas rápidas y proporcionó muchos videos generados para su referencia, incluidos diferentes contenidos, diferentes resoluciones, diferentes relaciones de aspecto y diferentes duraciones.



El autor también descubrió que con un solo comando simple, Open-Sora puede generar videoclips de múltiples resoluciones, rompiendo por completo las limitaciones creativas.



2.4 Vídeo de Tusheng
También podemos alimentar a Open-Sora con una imagen estática y hacer que genere un video corto.

Open-Sora también puede conectar inteligentemente dos imágenes fijas. Haga clic en el vídeo a continuación y lo llevará a experimentar los cambios de luz y sombra desde la tarde hasta el anochecer.

2.5 Edición de vídeo
Para otro ejemplo, queremos editar el video original con solo un simple comando, el bosque originalmente brillante marcó el comienzo de una fuerte nevada.


2.6 Generar imágenes de alta definición
También podemos habilitar Open-Sora para generar imágenes de alta definición:

Vale la pena señalar que los pesos de los modelos de Open-Sora se han puesto a disposición del público en su comunidad de código abierto de forma gratuita. Dado que también admiten la función de empalme de video, esto significa que tiene la oportunidad de crear una historia breve con una historia de forma gratuita para hacer realidad su creatividad.
Dirección de descarga de peso: github.com/hpcaitech/Open-Sora
3. Limitaciones actuales y planes futuros
Aunque Open-Sora ha logrado un buen progreso en la reproducción de modelos de video Vincent similares a Sora, el equipo de autores también señaló humildemente que los videos generados actualmente aún deben mejorarse en muchos aspectos, incluidos los problemas de ruido durante el proceso de generación, la falta de tiempo. consistencia, mala calidad de generación de personajes y bajas puntuaciones estéticas.
Con respecto a estos desafíos, el equipo de autores declaró que darán prioridad a resolverlos en el desarrollo de la próxima versión para lograr estándares más altos de generación de video. Los amigos interesados pueden continuar prestando atención. Esperamos con ansias la próxima sorpresa que nos traiga la comunidad Open-Sora.
Dirección de GitHub: github.com/hpcaitech/Open-Sora
referencias:
[1] https://github.com/hpcaitech/Open-Sora/blob/main/docs/report_02.md
[2] Tay, Yi, et al. "Ul2: Unificando paradigmas de aprendizaje de idiomas". Preimpresión de arXiv arXiv:2205.05131 (2022).
[3] https://openai.com/research/video-generación-modelos-as-world-simulators
Decidí renunciar al código abierto Hongmeng Wang Chenglu, el padre del código abierto Hongmeng: El código abierto Hongmeng es el único evento de software industrial de innovación arquitectónica en el campo del software básico en China: se lanza OGG 1.0, Huawei contribuye con todo el código fuente. Google Reader es asesinado por la "montaña de mierda de códigos" Fedora Linux 40 se lanza oficialmente Ex desarrollador de Microsoft: el rendimiento de Windows 11 es "ridículamente malo" Ma Huateng y Zhou Hongyi se dan la mano para "eliminar rencores" Compañías de juegos reconocidas han emitido nuevas regulaciones : los regalos de boda de los empleados no deben exceder los 100.000 yuanes Ubuntu 24.04 LTS lanzado oficialmente Pinduoduo fue sentenciado por competencia desleal Compensación de 5 millones de yuanes