
Tanto Alibaba Cloud como Tencent Cloud han experimentado situaciones en las que todas las zonas de disponibilidad quedaron paralizadas al mismo tiempo debido a una falla de un componente. Este artículo explorará cómo reducir el dominio de fallas desde la perspectiva del diseño arquitectónico y minimizar las pérdidas comerciales cuando ocurren fallas, y tomará la práctica de estabilidad de Sealos como ejemplo para compartir experiencias y lecciones.
Abandonar maestro-esclavo y adoptar la arquitectura peer-to-peer
Se puede ver en el informe de fallas de Tencent Cloud que la falla de múltiples zonas de disponibilidad al mismo tiempo se debe básicamente a algunos componentes centralizados, como la API unificada, la autenticación unificada y otras fallas del sistema.
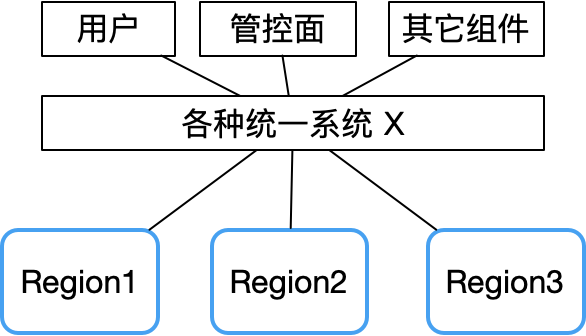
Por lo tanto, una vez que falla el sistema X, el dominio de falla será muy grande.
Por el contrario, una arquitectura descentralizada de igual a igual puede evitar bien este riesgo. Tomemos como ejemplo la red Bitcoin. Dado que no hay un nodo central, su estabilidad es mucho mayor que la de un clúster maestro-esclavo tradicional y es casi difícil de colgar.
Por lo tanto, Sealos absorbió completamente las lecciones de Alibaba Cloud y Tencent Cloud al diseñar zonas de disponibilidad múltiple y adoptó una arquitectura sin propietario. Todas las zonas de disponibilidad son autónomas. El principal problema es cómo se almacenan datos como las cuentas de usuario en múltiples zonas de disponibilidad. problema. Se convirtió en una estructura como esta:
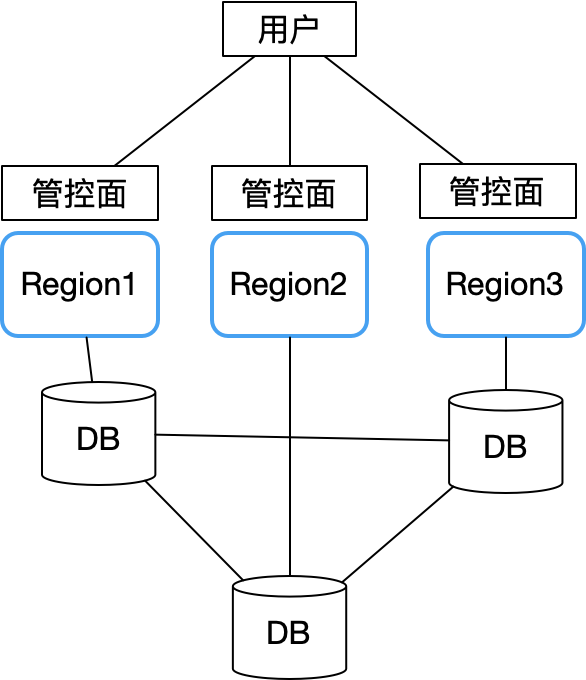
Cada zona de disponibilidad es completamente autónoma y solo sincroniza datos compartidos clave (como información de cuentas de usuario) a través de una base de datos distribuida entre regiones (usamos CockroachDB). Cada zona de disponibilidad está conectada al nodo local de la base de datos distribuida CockroachDB.
De esta manera, una falla en una única zona de disponibilidad no afectará la continuidad del negocio en otras regiones. Solo cuando ocurre un problema general en el clúster de base de datos distribuida, el plano de control de todas las zonas de disponibilidad dejará de estar disponible. Afortunadamente, CockroachDB tiene un rendimiento excelente en tolerancia a fallas, recuperación ante desastres y respuesta a particiones de red, lo que reduce en gran medida la probabilidad de que ocurra esta situación. De esta manera, la arquitectura general es simple. Solo concéntrese en mejorar la estabilidad de la base de datos, monitorear y realizar pruebas destructivas.
Otro beneficio de esto es que brinda comodidad para la liberación en escala de grises y operaciones diferenciadas. Por ejemplo, las nuevas funciones se pueden verificar primero con poco tráfico en algunas áreas y luego lanzarlas por completo después de la estabilización. Diferentes áreas también pueden proporcionar servicios personalizados según las características de los grupos de clientes sin tener que ser completamente consistentes.
No existe un sistema absolutamente estable.
Todo el mundo se queja mucho de la estabilidad de la nube, pero todos los proveedores de la nube, sin excepción, han experimentado fallos. Lo más importante aquí es cómo converger. No es sólo una cuestión técnica, sino también organizativa. Los problemas de gestión también son un problema de costos. Compartiré esto con ustedes basándose en ejemplos específicos que encontramos durante el proceso empresarial.
Lecciones aprendidas de los fracasos de Sealos
Gran fallo de Laf el 17 de marzo de 2023
Este fue el primer gran fracaso que encontramos al iniciar un negocio. Nos dieron una bofetada apenas dos días después del lanzamiento del producto. La razón por la que recordamos ese momento con tanta claridad es que resultó ser la celebración del primer aniversario de la empresa. , y ni siquiera tuvimos tiempo de cortar el pastel. Duró hasta las tres de la noche.
La causa final del fallo fue muy extraña. Usamos servidores livianos por poco dinero . La virtualización de red de contenedores en servidores livianos provocaría la pérdida de paquetes. Al final, migramos todo el clúster a un servidor VPC normal, por lo que el problema se multiplicó. era estable. El sexo y el costo son inseparables.
Por lo tanto, mucha gente piensa que la nube pública es cara. En muchos casos, cuesta muchas veces resolver el 10% restante de los problemas.
Posteriormente, Laf encontró una serie de problemas de estabilidad relacionados con la base de datos, porque usó un modelo en el que varios inquilinos comparten una biblioteca MongoDB . La conclusión final fue que este camino no iba a funcionar y nos resultó difícil resolver el aislamiento de la base de datos. problema, por lo que ahora todos adoptaron el método de base de datos independiente y el problema finalmente se resolvió.
También está el problema de estabilidad en la puerta de enlace. Inicialmente elegimos un controlador Ingress no confiable , lo que causó problemas frecuentes, no nombraré el controlador específico. Finalmente, lo reemplazamos con Higress, lo que resolvió completamente el problema. Requiere menos recursos y es más estable. También estoy muy agradecido con el equipo de Alibaba Higress por su apoyo personal. Los problemas que exponemos también han ayudado a Higress a madurar, una situación en la que todos ganan.
En junio de 2023, se lanzó oficialmente nuestra nube pública Sealos. Uno de los mayores problemas que encontramos fue ser atacado por ataques CC con gran tráfico. Agregar protección puede resolverlo, pero también significa un aumento en los costos, por lo que hay que compensar. Los dos son muy confusos. Si no evitas la estabilidad, es difícil resolverla. Si la evitas, no podrás recuperar el costo vendiéndola. Más tarde, después de reemplazar la puerta de enlace, descubrimos que Envoy era realmente poderoso y podía resistir el tráfico de ataques. Antes de eso, usamos Nginx, que era integral. Además, lo mejor de K8 es su gran capacidad de autorreparación. Incluso si la puerta de enlace está caída, puede repararse automáticamente en 5 minutos, siempre que no esté caída al mismo tiempo, el negocio no se verá afectado.
Mejores prácticas para la convergencia de la estabilidad
Proceso de solución de problemas
Para mejorar continuamente la estabilidad del sistema, Sealos ha establecido internamente un estricto proceso de gestión de fallas:
Cada vez que ocurre una falla, se debe registrar detalladamente y realizar un seguimiento continuo. Muchas empresas finalizan el proceso de revisión de fallas, pero en realidad la revisión no es el propósito. La clave es formular medidas correctivas prácticas e implementarlas para evitar por completo que vuelvan a ocurrir fallas similares. Una vez completado el manejo de la falla, aún debe continuar observándolo durante un período de tiempo hasta que se confirme que el problema ya no ocurre.
En términos de objetivos de gestión, inicialmente definimos el objetivo de estabilidad y convergencia en el OKR del primer trimestre de 2024 de la siguiente manera:

Más tarde, descubrí que este OKR general estilo eslogan no era confiable y que la convergencia de la estabilidad necesitaba ser más específica. El resultado de este KR fue que no logramos lograrlo y casi no tuvo ningún efecto. En el proceso de convergencia, no es necesario florecer completamente. Concéntrese en unos pocos puntos centrales cada trimestre y continúe iterando durante algunos trimestres y la convergencia será muy buena.
Entonces, en el segundo trimestre fijamos objetivos más específicos:

La fijación de la estabilidad no puede limitarse simplemente a fijar un indicador, ni puede ser demasiado general. Requiere medidas concretas y visibles y métodos de medición específicos.
Por ejemplo, si se establece el 99,9%, ¿cómo lograrlo? Entonces, ¿cuál es la disponibilidad actual? ¿Cuáles son las cuestiones centrales que nos ocupan? ¿Cómo medir? ¿Lo que hay que hacer? ¿Quién lo hará? Las configuraciones no se limitan al tiempo disponible, sino que deben enumerarse en detalle, como el nivel de falla, la cantidad de fallas, la duración de la falla, la observación de fallas grandes del cliente, etc.
Es necesario separar categorías especiales y enumerar las prioridades, tales como: estabilidad de la base de datos, estabilidad de la puerta de enlace, grandes indicadores de disponibilidad del servicio al cliente, falla por sobrecarga de recursos de CPU/memoria.
También debemos centrarnos en monitorear grandes clientes, como Auto Chess, clientes comerciales FastGPT, Chongchunxue Studio, etc. (uso mensual de más de 30 núcleos, elija 5 típicos).
Hay un número limitado de problemas de estabilidad. Una vez que estos grandes clientes estén bien atendidos, los clientes pequeños básicamente pueden quedar cubiertos, no perseguir demasiados, concentrarse en resolver los problemas centrales de estabilidad actuales y luego asegurarse de establecer un proceso de seguimiento completo.
Los estudiantes que causen mal funcionamiento pueden ser castigados, se les deducirán sus bonificaciones o incluso se les expulsará. Como empresa nueva, normalmente no utilizamos medidas punitivas , porque las partes involucradas no quieren causar fallos y todos están trabajando duro para resolver el problema. Los que realmente pueden luchar son los que han resultado heridos . Prefiera incentivos positivos, como Si la frecuencia de fallas trimestrales disminuye, brinde algunos incentivos de manera adecuada .
Diseño arquitectónico sencillo.
La arquitectura del sistema está relacionada con la estabilidad desde el principio del diseño. Cuanto más compleja es la arquitectura, más fácil es tener problemas, por lo que muchas empresas no prestan atención a esto. A menudo participo en el diseño y revisión de la arquitectura de la empresa. Creo que el diseño es demasiado complejo para mí. La zona de disponibilidad múltiple de Sealos es un muy buen ejemplo. Para convertir algo complejo en un CRUD simple, solo necesita mejorar la estabilidad de la base de datos. El diseño de la estructura de la tabla de la base de datos es simple y resuelve muchos problemas de estabilidad.
Lo mismo ocurre con nuestro sistema de medición. Originalmente lo diseñamos para tener más de una docena de CRD, pero después de luchar durante más de medio año, la estabilidad no se pudo estabilizar, finalmente rediseñamos y seleccionamos el sistema. dos semanas para desarrollarse y estuvo estable en línea en un mes.
Por lo tanto: ¡ un diseño simple es crucial para la estabilidad!
Monitoreo moderado, dirigido
La vigilancia es un arma de doble filo: demasiada no es suficiente. Muchas fallas de Sealos fueron causadas por el monitoreo. Prometheus ocupaba demasiados recursos y el servidor API estaba abrumado, lo que a su vez causó nuevos problemas de estabilidad. Después de aprender nuestra lección, cambiamos a una solución de monitoreo más liviana como VictoriaMetrics, mientras controlamos estrictamente la cantidad de indicadores de monitoreo. Herramientas como Uptime Kuma son muy útiles. Pueden probarse entre sí en todas las regiones y encontrar problemas a tiempo.
Lo mismo ocurre con las llamadas. Hay miles de alarmas todos los días. ¿Qué hay de guardia? Entonces, aquí básicamente comenzamos desde 0 y sumamos cosas lentamente. Por ejemplo, primero lo hacemos desde la perspectiva de la "estabilidad final del negocio del gran cliente". Por ejemplo, si un contenedor falla, si hay una llamada. , el teléfono probablemente sonará sin parar. Luego, agregue lentamente cosas como que el host no está listo. En teoría, el host no está listo y no debería afectar el negocio. A medida que el sistema madure gradualmente, eventualmente será posible hacer que el host no esté listo sin la necesidad de estar de guardia.
No tengas miedo de pasar vergüenza al reportar fallas
El informe de revisión de Tencent Cloud fue muy bueno. Explicó sinceramente las razones del fracaso, analizó objetivamente lo que no era suficiente y prometió rectificarlo activamente. Este tipo de actitud franca y responsable hace que sea más fácil ganarse la confianza de los usuarios. Por el contrario, mantener el problema en secreto por temor a la fermentación de la opinión pública equivale a beber veneno para saciar la sed. En cambio, hace que los usuarios sientan que es una caja negra opaca y no saben qué sucederá en el futuro . Los clientes que realmente aman sus productos y están dispuestos a crecer con usted pueden tolerar errores sin principios. La clave es mostrar sinceridad y acciones para una mejora real.
Resumir
El servicio de nube pública Sealos lleva más de un año lanzado y ha acumulado más de 100.000 usuarios registrados. Con sus excelentes funciones, experiencia y rentabilidad, muchos desarrolladores lo prefieren y algunos grandes clientes también han comenzado a intentar migrar sus negocios a nuestra nube Sealos. Entre ellos se encuentran algunos productos de Internet a gran escala. Por ejemplo, el juego "Happy Auto Chess" tiene más de 4 millones de usuarios activos .
De cara al futuro, creemos que a través de la gestión sistemática de fallas, continuaremos convergendo en la estabilidad. A través de un diseño de arquitectura simple y eficiente, una estrategia de monitoreo constante y complementada con una actitud de comunicación abierta y honesta, Sealos, una nube que fue. nutrido y desarrollado por una pequeña empresa nacional de código abierto, definitivamente ¡Se convertirá en una nube muy avanzada!
Linus tomó el asunto en sus propias manos para evitar que los desarrolladores del kernel reemplacen las pestañas con espacios. Su padre es uno de los pocos líderes que puede escribir código, su segundo hijo es el director del departamento de tecnología de código abierto y su hijo menor es un núcleo. Colaborador de código abierto Huawei: tomó 1 año convertir 5000 aplicaciones móviles de uso común Migración completa a Hongmeng Java es el lenguaje más propenso a vulnerabilidades de terceros Wang Chenglu, el padre de Hongmeng: el código abierto Hongmeng es la única innovación arquitectónica. En el campo del software básico en China, Ma Huateng y Zhou Hongyi se dan la mano para "eliminar rencores". Ex desarrollador de Microsoft: el rendimiento de Windows 11 es "ridículamente malo " " Aunque lo que Laoxiangji es de código abierto no es el código, las razones detrás de él. Son muy conmovedores. Meta Llama 3 se lanza oficialmente. Google anuncia una reestructuración a gran escala.