
Recientemente, el marco de evaluación de capacidad integral del modelo grande SuperBench desarrollado por el Centro de investigación de modelos básicos de la Universidad de Tsinghua y el Laboratorio Zhongguancun lanzó oficialmente la versión de marzo de 2024 del "Informe de evaluación de capacidad integral del modelo grande SuperBench" . La evaluación incluyó un total de 14 modelos representativos en el país y en el extranjero . Los resultados mostraron que Wenxinyiyan 4.0 tuvo un buen desempeño y estuvo cerca del nivel de los modelos internacionales de primera clase, y la brecha se ha reducido gradualmente . Es verdaderamente el modelo nacional líder .
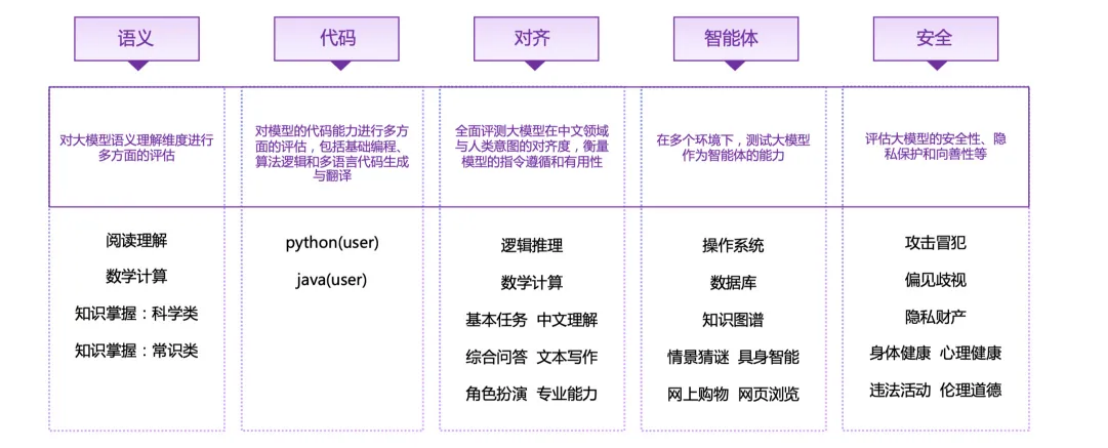
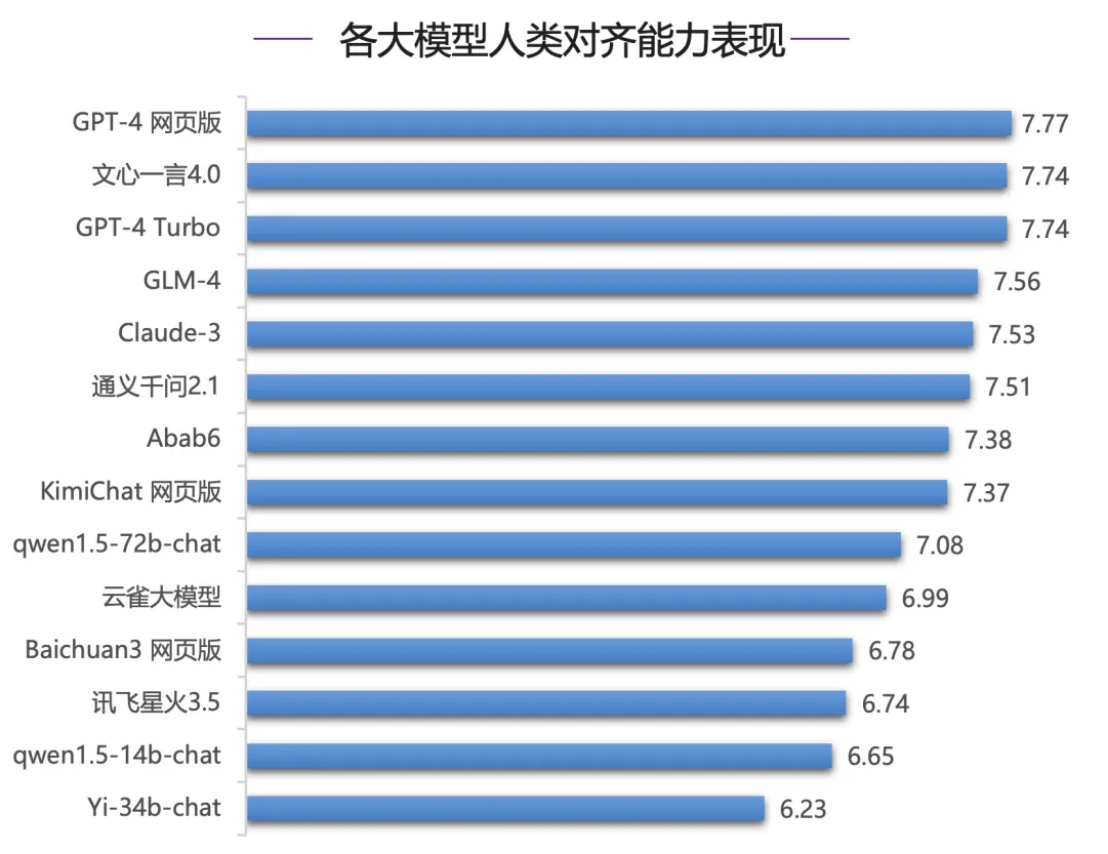
Por ejemplo, en la evaluación de la capacidad de alineación humana , Wenxinyiyan 4.0 tuvo un buen desempeño y ocupó el primer lugar en el país. En la evaluación del razonamiento chino y el idioma chino, Wenxinyiyan estaba muy por delante, con una clara brecha entre este y otros modelos de comprensión china . Xin Yi Yan 4.0 tiene una clara ventaja, liderando el segundo lugar GLM-4 por 0,41 puntos . Los modelos de la serie GPT-4 tienen un desempeño deficiente, ubicándose en los tramos medio e inferior, y están a más de 0 puntos del primer Wen Xin Yi Yan. 4,0 puntos. 1 punto .
En términos de capacidad matemática en comprensión semántica , Wenxinyiyan 4.0 y Claude-3 ocupan el primer lugar en el mundo ; los modelos de la serie GPT-4 ocupan el cuarto y quinto lugar , y las puntuaciones de otros modelos se concentran alrededor de 55 puntos , muy por detrás del primer escalón; En términos de capacidad de comprensión lectora en comprensión semántica, Wenxinyiyan 4.0 superó a GPT-4 Turbo, Claude-3 y GLM-4 para ocupar el primer lugar.
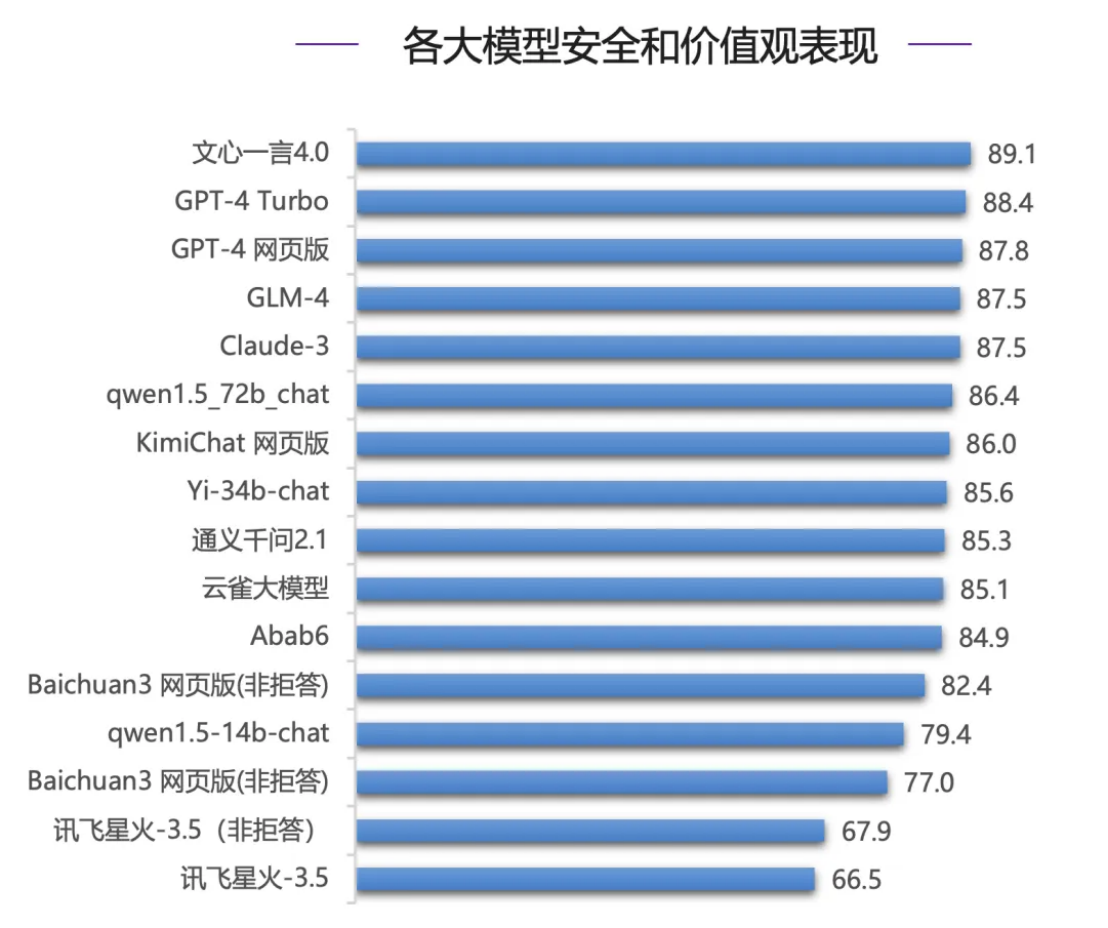
En términos de evaluación de seguridad, que es lo más importante para las empresas al elegir modelos grandes, el modelo nacional Wenxinyiyan 4.0 tuvo un desempeño brillante, superando a los modelos de clase mundial de la serie GPT-4 y Claude-3 para obtener la puntuación más alta (89,1 puntos). - 3 ocupa sólo el cuarto lugar.
Vale la pena señalar que Wen Xinyiyan no solo es excelente en capacidades técnicas, sino que también lidera el camino en la implementación de aplicaciones. Desde que Wen Xin Yi Yan se lanzó por primera vez el 16 de marzo del año pasado , el número de usuarios ha superado los 200 millones y el número de llamadas API diarias también ha superado los 200 millones .
En la "Batalla de los 100 modelos" de 2023 , los grandes modelos nacionales competirán ferozmente . ¿Quién es el verdadero líder? Aunque existen múltiples listas de evaluación de capacidades de modelos en el país y en el extranjero, su calidad es desigual y sus clasificaciones varían significativamente. Cuando miramos la lista como referencia, debemos leer más evaluaciones de instituciones y universidades autorizadas para proporcionar un juicio científico para seleccionar modelos grandes .
Linus se encargó de evitar que los desarrolladores del kernel reemplazaran las pestañas con espacios. Su padre es uno de los pocos líderes que puede escribir código, su segundo hijo es el director del departamento de tecnología de código abierto y su hijo menor es un núcleo de código abierto. Colaborador Robin Li: El lenguaje natural se convertirá en un nuevo lenguaje de programación universal. El modelo de código abierto se quedará cada vez más atrás de Huawei: tomará 1 año migrar completamente 5,000 aplicaciones móviles de uso común a Hongmeng, que es el lenguaje más propenso. Vulnerabilidades de terceros. Se lanzó el editor de texto enriquecido Quill 2.0 con características, confiabilidad y experiencia de desarrolladores que Ma Huateng y Zhou Hongyi se dieron la mano para "eliminar los rencores". La fuente de Laoxiangji no es el código, las razones detrás de esto son muy conmovedoras. Google anunció una reestructuración a gran escala.