
Recientemente, la Conferencia Kangaroo Cloud Spring con el tema "Datos + IA, construyendo nueva productividad" llegó a una conclusión exitosa. La conferencia trajo una serie de productos digitales " +AI " y las últimas precipitaciones de la industria, con el objetivo de integrar estrechamente datos y. AI., rompiendo los límites tradicionales de la productividad y empoderando a las empresas para lograr un desarrollo digital más eficiente y de mayor calidad. En la reunión, Tou Tian, gerente de producto de Kangaroo Cloud Data Stack, presentó una nueva versión de Data Stack V6.2 que integra capacidades de inteligencia artificial . Esto no es solo una simple actualización del producto, sino que también representa la audaz predicción de Kangaroo Cloud. futuro. .
Data Stack V6.2: Maximizar el valor de los datos
En la era impulsada por los datos, estos se han convertido en el sustento de las empresas. Cómo gestionar y utilizar eficazmente estos datos es una cuestión que todas las empresas están explorando. El lanzamiento de Data Stack V6.2 tiene como objetivo precisamente resolver este desafío y ayudar a las empresas a aprovechar las olas del océano de datos.
El concepto central del recién lanzado Data Stack V6.2 es Data+AI . La nueva versión no solo proporciona las funciones básicas de la plataforma de big data, sino que también proporciona a las empresas análisis y aplicaciones de datos inteligentes a través de una integración profunda con la tecnología de IA . Esto significa que las empresas pueden utilizar la plataforma de pila de datos para lograr la integración de los sistemas de contenido de la industria, información de datos flexible y conveniente, cálculos del motor de análisis extremadamente rápidos y gestión y control integrales de la seguridad de los datos. Además, las soluciones de productos Kangaroo Cloud también cubren muchos aspectos, como el peso ligero, la gobernanza de datos y la creación de información. Todo esto está diseñado para ayudar a las empresas a optimizar los costos de almacenamiento informático, mejorar la calidad de los datos, promover estándares y especificaciones y, en última instancia, maximizar el valor de los datos.
1. Solución de centro de datos liviana, el procesamiento de datos es más eficiente
Al introducir los eficientes motores informáticos Doris y StarRocks , se logra una reconstrucción revolucionaria del rendimiento de la plataforma. Este movimiento innovador no solo mejora en gran medida la velocidad de procesamiento de datos, reduce los costos de almacenamiento y los costos de operación y mantenimiento, sino que también optimiza la eficiencia de las consultas y brinda una experiencia de operación de datos sin precedentes a las empresas. Las capacidades de consulta ad hoc y las capacidades de procesamiento analítico de alto rendimiento de Doris y StarRocks construyen conjuntamente una plataforma de procesamiento de datos potente y flexible. Los usuarios pueden hacer frente fácilmente a las necesidades de análisis en tiempo real de datos masivos y obtener información instantánea sobre los datos y soporte para la toma de decisiones. En este proceso, la precisión y confiabilidad de los datos están totalmente garantizadas, lo que proporciona un soporte de datos sólido para los negocios clave de la empresa, como la predicción de fallas, el marketing de precisión y la optimización de procesos.
y las capacidades de procesamiento analítico de alto rendimiento de Doris y StarRocks construyen conjuntamente una plataforma de procesamiento de datos potente y flexible. Los usuarios pueden hacer frente fácilmente a las necesidades de análisis en tiempo real de datos masivos y obtener información instantánea sobre los datos y soporte para la toma de decisiones. En este proceso, la precisión y confiabilidad de los datos están totalmente garantizadas, lo que proporciona un soporte de datos sólido para los negocios clave de la empresa, como la predicción de fallas, el marketing de precisión y la optimización de procesos.
2. Sistema integral de gobierno de datos para maximizar el valor corporativo
En Data Stack V6.2, hemos actualizado y redefinido integralmente la gobernanza de datos para satisfacer las crecientes necesidades de las empresas en la gestión de datos. Las cinco dimensiones del centro de gobierno de datos : almacenamiento, computación, calidad, especificación y valor, constituyen un sistema integral de gobierno de datos para garantizar la integridad, precisión y disponibilidad de los datos empresariales.
El banco de trabajo de gobernanza proporciona una interfaz de operación intuitiva, lo que hace que sea simple y eficiente iniciar, registrar, asignar y procesar tareas de gobernanza de datos. A través de esta plataforma, las empresas pueden mostrar el estado de la gobernanza de datos desde una perspectiva personal, desde una perspectiva de proyecto hasta una perspectiva panorámica, garantizando así que la calidad de los datos de cada enlace se monitoree y administre de manera efectiva. La función de inspección de código estandariza el código SQL mediante reglas de inspección SQL para evitar posibles problemas de gestión por adelantado. La gestión de archivos pequeños tiene como objetivo el problema de los archivos pequeños en los clústeres de Hadoop, optimizando el rendimiento y la escalabilidad del clúster mediante fusiones únicas o periódicas y mejorando la eficiencia del procesamiento de datos .
La gobernanza de datos de DataStack V6.2 no es solo una actualización de la tecnología, sino también una configuración de la cultura de datos empresarial. A través de un sistema de gobernanza de este tipo, las empresas pueden establecer un marco completo de gobernanza de datos , promover la estandarización y la estandarización de los datos y, en última instancia, maximizar el valor de los activos de datos.
3. La adaptación de Xinchuang de enlace completo admite una localización integral
En esta era de informatización e innovación de la información, somos muy conscientes de las necesidades de las empresas en cuanto a seguridad de los datos y controlabilidad independiente. Por lo tanto, nuestra plataforma no solo logra una cobertura de innovación de información de enlace completo en términos de servidores, sistemas operativos, chips, middleware, bases de datos de metadatos, motores informáticos, etc., sino que también realiza adaptaciones profundas en la protección de seguridad de todo el proceso.yla implementación privatizada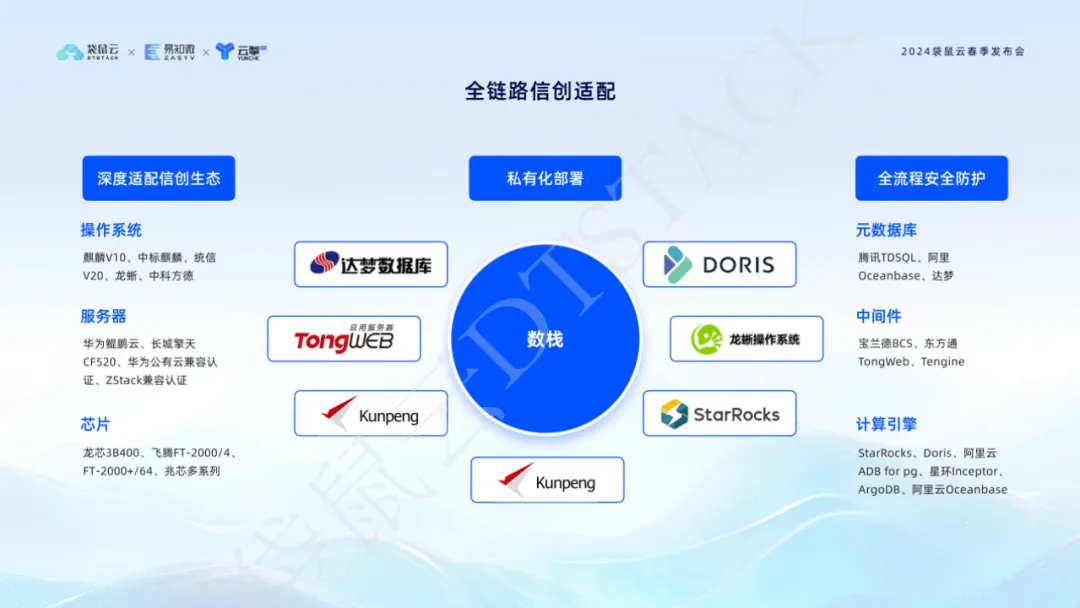
4. Innovar y superar las capacidades del lago de datos de Paimon para realizar un modelo de procesamiento de datos integrado de flujo por lotes.
En el modelo tradicional de procesamiento de datos, las empresas a menudo se enfrentan al dilema de desarrollar y mantener dos conjuntos de lógica de código: uno para el procesamiento por lotes y el otro para el procesamiento de secuencias en tiempo real. Esto no solo significa duplicar la carga de trabajo de desarrollo y mantenimiento, sino que también requiere procesar la lógica de fusión de datos entre los dos para garantizar que los dos sistemas estén en línea simultáneamente. Un modelo de este tipo no sólo aumenta el consumo de recursos, sino que también puede generar ambigüedad en los datos, lo que dificulta garantizar la precisión de los datos y reduce la confianza del personal empresarial en los resultados de los datos.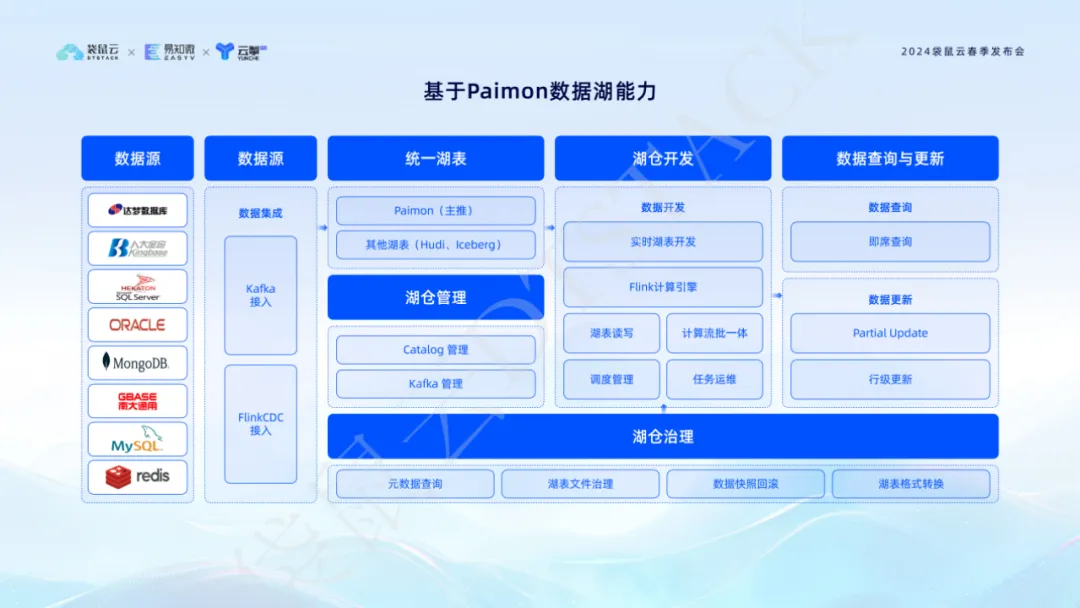
El avance innovador de la pila de datos implementa el modelo de procesamiento de datos integrado de flujo por lotes a través de las capacidades de Paimon Data Lake , resolviendo efectivamente los problemas anteriores. La plataforma proporciona desarrollo de tablas de lago en tiempo real y funciones de consulta ad hoc , lo que permite a los desarrolladores de datos procesar datos en tiempo real y por lotes simultáneamente en una única plataforma sin la necesidad de inversiones adicionales en recursos ni procesos complejos de sincronización de datos. Una solución integrada de este tipo no sólo reduce el uso de recursos informáticos y de almacenamiento, sino que también garantiza la coherencia y precisión de los datos, mejorando así el reconocimiento de los resultados del análisis de datos por parte del personal empresarial. Esta innovación brindará un fuerte apoyo a la transformación digital y la actualización inteligente de las empresas.
5. Las cuatro funciones principales de EasyMR están profundamente optimizadas para desbloquear una nueva experiencia informática y de procesamiento de big data.
Como módulo de producto importante en la pila de datos, EasyMR representa nuestra comprensión profunda y la innovación continua del ecosistema de big data. Se basa en Hadoop de código abierto y se itera sincrónicamente con la comunidad de código abierto. Nuestro equipo de motores informáticos lo desarrolla de forma independiente y tiene características optimizadas y mejoradas de componentes principales como Spark, Flink y Paimon. Estas optimizaciones no solo mejoran el rendimiento y la estabilidad del procesamiento de datos, sino que también retribuyen a la comunidad y promueven la construcción conjunta del ecosistema Hadoop.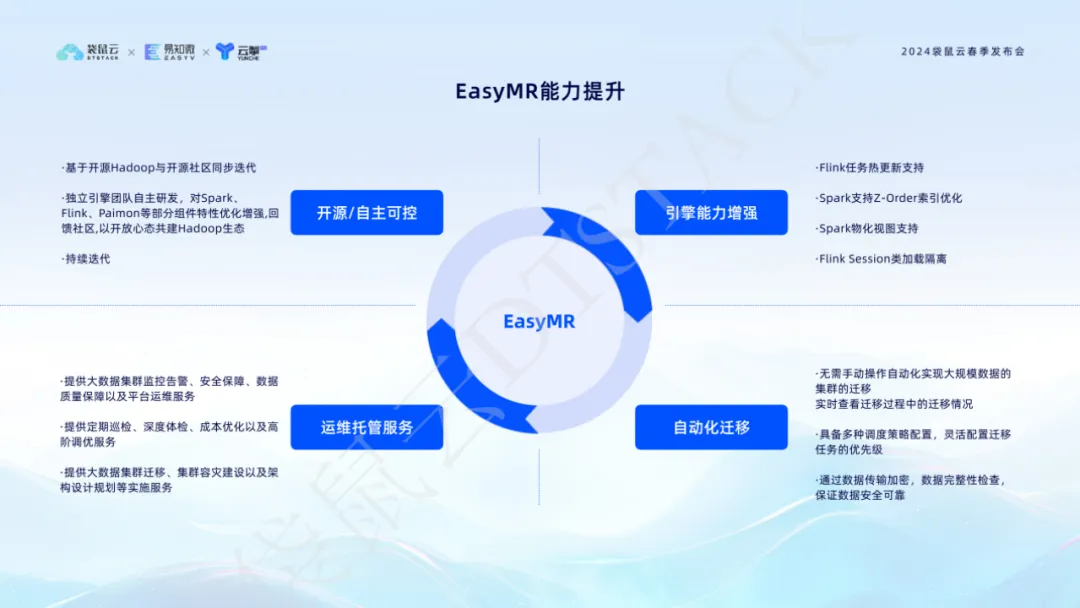
Las capacidades mejoradas de EasyMR se reflejan en muchos aspectos: admite actualizaciones en caliente de las tareas de Flink , lo que garantiza la continuidad y flexibilidad del negocio. La optimización del índice Z-Order de Spark y el soporte de vista materializada mejoran la eficiencia del procesamiento de datos y la velocidad de respuesta. El aislamiento de carga de clases de sesión de Flink garantiza la seguridad y confiabilidad del entorno operativo. Además, la función de migración automatizada de EasyMR hace que la migración de grupos de datos a gran escala sea fácil y sencilla, y monitorea el estado durante el proceso de migración en tiempo real para garantizar la seguridad y confiabilidad de los datos. A través de estas innovaciones y optimizaciones, EasyMR proporciona a los usuarios una plataforma de big data eficiente, inteligente y fácil de mantener, ayudando a las empresas a lograr un salto cualitativo en la gestión y el análisis de datos.
Las capacidades de datos+IA hacen que el desarrollo de datos sea más inteligente
La tecnología de inteligencia artificial se ha convertido en la principal fuerza impulsora de la innovación empresarial y la mejora de la eficiencia. Al integrar tecnología de IA generativa , DataStack V6.2 ha realizado seis funciones principales: desarrollo inteligente, ajuste inteligente, diagnóstico inteligente, recuperación inteligente, análisis inteligente y verificación inteligente, lo que mejora en gran medida la eficiencia y la calidad del procesamiento de datos.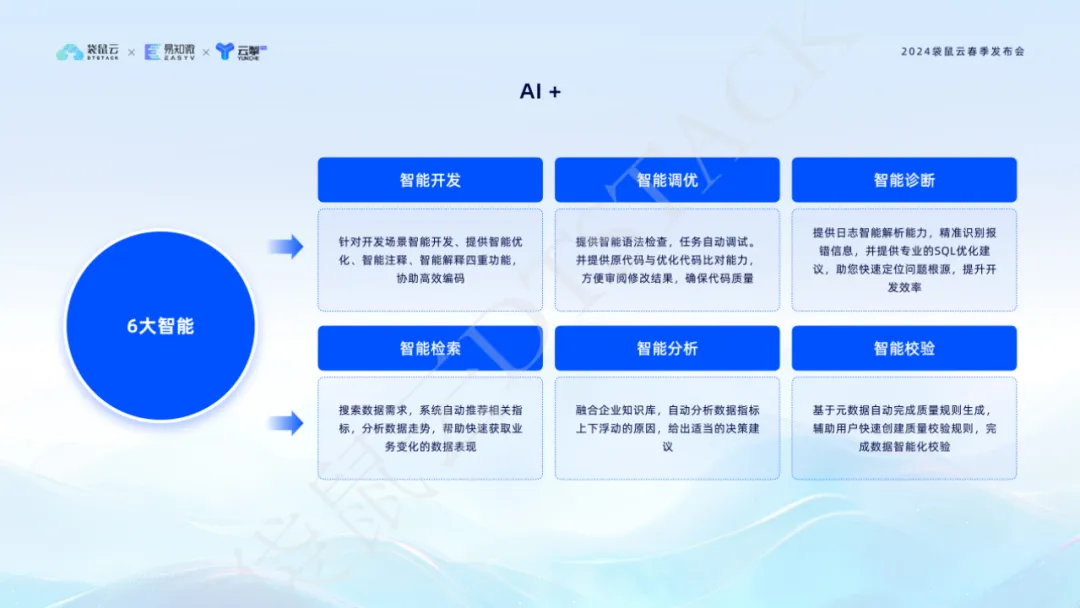
El ajuste inteligente puede optimizar automáticamente el código SQL y mejorar el rendimiento de la ejecución; el diagnóstico inteligente utiliza IA para analizar registros para localizar rápidamente problemas y proporcionar sugerencias de optimización profesionales que ayudan a comprender en profundidad las tendencias de los datos y brindar un sólido soporte para la toma de decisiones. Estas funciones no solo mejoran la eficiencia del desarrollo, sino que también garantizan la calidad del código y logran los objetivos comerciales con mayor precisión basándose en datos. La introducción de AI+ marca que estamos entrando en una nueva era de gestión de datos más inteligente y eficiente.
La función de ajuste inteligente AI + puede proporcionar sugerencias de optimización inteligentes cuando los desarrolladores escriben código en el editor, lo que permite a los estudiantes de desarrollo de datos revisar y comparar. Esto mejora la eficiencia y la calidad de la codificación, lo que permite a los estudiantes de desarrollo de datos centrarse más en la implementación de la lógica empresarial.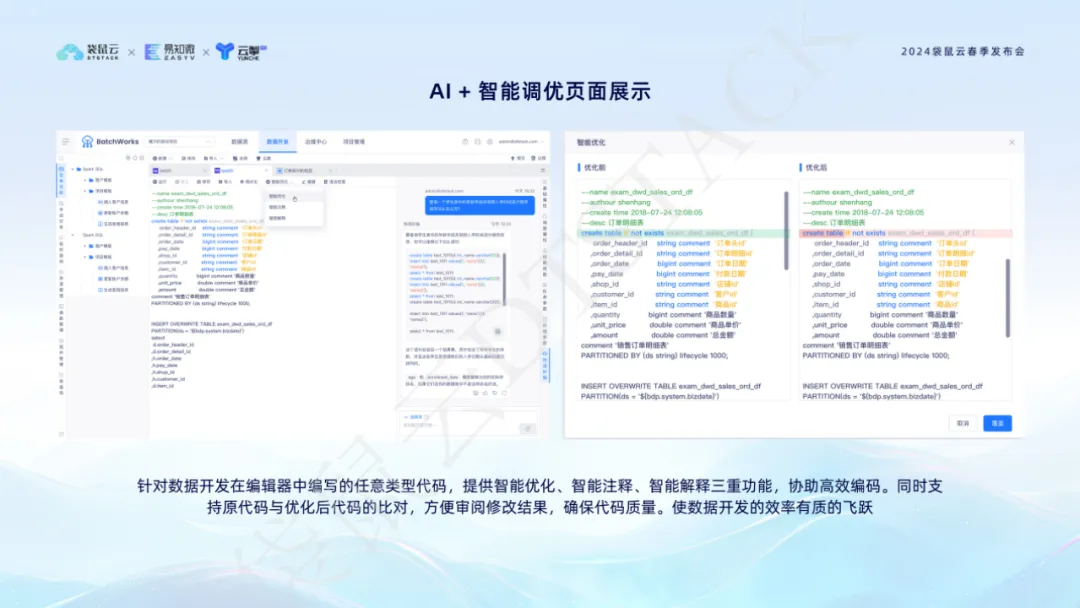
La función de diagnóstico inteligente AI + utiliza tecnología de inteligencia artificial para analizar de manera inteligente Spark SQL, Flink SQL y otros registros de tareas, identificar mensajes de error y brindar sugerencias profesionales de optimización de SQL para ayudar a localizar rápidamente la causa raíz del problema y mejorar la eficiencia del desarrollo del código. 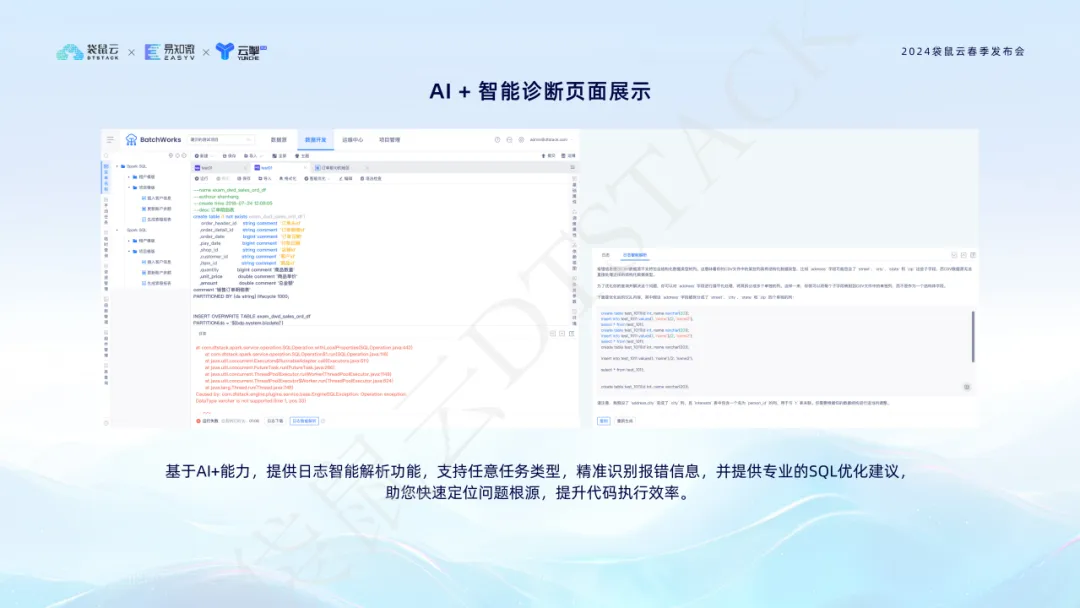 A través de la integración con AI+, la pila de datos no solo simplifica el proceso de desarrollo de datos, sino que también mejora la precisión y confiabilidad del procesamiento de datos, brindando un sólido soporte técnico para la toma de decisiones basada en datos de las empresas.
A través de la integración con AI+, la pila de datos no solo simplifica el proceso de desarrollo de datos, sino que también mejora la precisión y confiabilidad del procesamiento de datos, brindando un sólido soporte técnico para la toma de decisiones basada en datos de las empresas.
Productos + servicios, una nueva actualización de la estrategia de comercialización de productos de pila de datos
En este lanzamiento de producto, hemos redefinido la estrategia de comercialización de nuestros productos, con el objetivo de brindar soluciones de servicios flexibles y diversas para empresas con diferentes necesidades.  La serie de productos incluye la edición estándar, la edición profesional y la edición definitiva, y proporciona opciones de implementación de aplicaciones en la nube para satisfacer las necesidades de procesamiento de datos de empresas de diferentes tamaños. Además, también brindamos servicios de valor agregado, como la adaptación de Xinchuang y el almacén en el lago en tiempo real, así como versiones avanzadas y superiores de servicios de operación y mantenimiento sistemáticos, lo que garantiza que los clientes puedan disfrutar de un soporte integral, desde básico hasta avanzado.
La serie de productos incluye la edición estándar, la edición profesional y la edición definitiva, y proporciona opciones de implementación de aplicaciones en la nube para satisfacer las necesidades de procesamiento de datos de empresas de diferentes tamaños. Además, también brindamos servicios de valor agregado, como la adaptación de Xinchuang y el almacén en el lago en tiempo real, así como versiones avanzadas y superiores de servicios de operación y mantenimiento sistemáticos, lo que garantiza que los clientes puedan disfrutar de un soporte integral, desde básico hasta avanzado.
La estrategia de comercialización de productos de Datastack no solo se centra en la venta de productos, sino que también se centra en la optimización y actualización continua de los servicios. Al proporcionar dos vías de actualización del producto y actualización de la versión, ayuda a las empresas a garantizar la adaptabilidad continua y la naturaleza prospectiva de la plataforma de datos. Esta estrategia no sólo mejora la experiencia del cliente, sino que también sienta una base sólida para el desarrollo a largo plazo de productos de pila de datos.
Tres casos importantes de prácticas de productos para ayudar a las empresas a la transformación digital
1. Un banco: implementación de una evaluación del desempeño basada en IA
Sobre la base de los indicadores de evaluación del desempeño acumulados, combinados con la propia base de conocimientos de la empresa, el banco utiliza capacidades de procesamiento de datos y análisis inteligente de IA para mejorar significativamente la eficiencia de la gestión y el nivel de gobernanza de la evaluación del desempeño.
Nuestra solución ayudó al banco a realizar la transformación de informes de indicadores a paneles de indicadores y luego a BI conversacional de indicadores, lo que redujo en gran medida el costo para los empleados de obtener y utilizar datos, hizo que los estándares de evaluación fueran más científicos y rigurosos, y el contenido de la evaluación más completo. , asegurando que el banco Existe una estrecha conexión entre el desempeño general y el desempeño individual de los empleados. A través de la atribución inteligente y las sugerencias inteligentes de la IA, los bancos pueden rastrear los resultados del desempeño de los empleados en tiempo real, identificar problemas de manera oportuna y realizar ajustes, promoviendo así la coherencia de los empleados y los objetivos organizacionales y la mejora continua del desempeño. Esta transformación no sólo optimiza la gestión de recursos humanos del banco, sino que también aporta una mayor eficiencia operativa y resultados comerciales a toda la organización.
2. Una marca de licores china: centro de datos liviano
A través de Data Stack, la marca ha establecido una plataforma de marketing unificada, que ayuda a las empresas a realizar capacidades de análisis multidimensionales, como el intercambio de datos , etiquetas inteligentes y gestión de indicadores, y proporciona un sólido soporte de datos para el marketing de precisión, la optimización de procesos, etc.  La plataforma adopta una solución intermedia de datos liviana y la combina con las capacidades informáticas de alto rendimiento de StarRocks para permitir a las empresas de licores lograr una gestión de datos eficiente y un análisis instantáneo. Las funciones de consulta de baja latencia y carga rápida de datos de StarRocks permiten a las empresas responder rápidamente a los cambios del mercado y lograr predicción de fallas y marketing de precisión. En comparación con el ecosistema tradicional de Hadoop, una solución intermedia de datos tan liviana tiene un excelente rendimiento de consultas, procesamiento de datos en tiempo real, alta concurrencia y fácil mantenimiento en escenarios donde el volumen de datos es pequeño, lo que la convierte en una solución ideal para aplicaciones rápidas. análisis de datos, promueve la transformación digital de las empresas licoreras.
La plataforma adopta una solución intermedia de datos liviana y la combina con las capacidades informáticas de alto rendimiento de StarRocks para permitir a las empresas de licores lograr una gestión de datos eficiente y un análisis instantáneo. Las funciones de consulta de baja latencia y carga rápida de datos de StarRocks permiten a las empresas responder rápidamente a los cambios del mercado y lograr predicción de fallas y marketing de precisión. En comparación con el ecosistema tradicional de Hadoop, una solución intermedia de datos tan liviana tiene un excelente rendimiento de consultas, procesamiento de datos en tiempo real, alta concurrencia y fácil mantenimiento en escenarios donde el volumen de datos es pequeño, lo que la convierte en una solución ideal para aplicaciones rápidas. análisis de datos, promueve la transformación digital de las empresas licoreras.
3. Empresa del grupo estatal municipal de Beijing: Full Link Xinchuang
Para resolver los problemas de la transformación digital empresarial y los requisitos de innovación de la información, este cliente estableció una " plataforma de big data de innovación de información de enlace completo ".  La plataforma está profundamente adaptada al ecosistema de Xinchuang y logra una protección de seguridad de proceso completo y una implementación privatizada desde servidores, sistemas operativos, chips, bases de datos de metadatos de aplicaciones, middleware y motores informáticos. A través de esta adaptación de innovación de información de enlace completo , el grupo no solo resolvió el problema de las islas de datos, sino que también cumplió con los estrictos requisitos del país para la innovación de información y garantizó la seguridad y controlabilidad de los datos. Esta iniciativa ha mejorado significativamente las capacidades de gobernanza de datos del grupo, ha sentado una base de datos sólida para el desarrollo a largo plazo de la empresa y también ha proporcionado a otras empresas estatales una valiosa experiencia práctica en innovación de la información.
La plataforma está profundamente adaptada al ecosistema de Xinchuang y logra una protección de seguridad de proceso completo y una implementación privatizada desde servidores, sistemas operativos, chips, bases de datos de metadatos de aplicaciones, middleware y motores informáticos. A través de esta adaptación de innovación de información de enlace completo , el grupo no solo resolvió el problema de las islas de datos, sino que también cumplió con los estrictos requisitos del país para la innovación de información y garantizó la seguridad y controlabilidad de los datos. Esta iniciativa ha mejorado significativamente las capacidades de gobernanza de datos del grupo, ha sentado una base de datos sólida para el desarrollo a largo plazo de la empresa y también ha proporcionado a otras empresas estatales una valiosa experiencia práctica en innovación de la información.
Lo anterior es la introducción al lanzamiento de DataStack V6.2. No es solo un producto, sino también un resumen de nuestra profunda comprensión y práctica de la gobernanza de big data y el análisis inteligente. Creemos que Data Stack V6.2 puede ayudar a más empresas a maximizar el valor de los datos y promover su transformación digital.
Dirección de descarga del "Libro técnico del sistema de indicadores industriales": https://www.dtstack.com/resources/1057?src=szsm
Dirección de descarga del "Informe técnico del producto Dutstack": https://www.dtstack.com/resources/1004?src=szsm
Dirección de descarga del "Libro técnico sobre prácticas de la industria de gobernanza de datos": https://www.dtstack.com/resources/1001?src=szsm
Para aquellos que quieran saber o consultar más sobre productos de big data, soluciones industriales y casos de clientes, visite el sitio web oficial de Kangaroo Cloud: https://www.dtstack.com/?src=szkyzg
Linus se encargó de evitar que los desarrolladores del kernel reemplazaran las pestañas con espacios. Su padre es uno de los pocos líderes que puede escribir código, su segundo hijo es el director del departamento de tecnología de código abierto y su hijo menor es un núcleo de código abierto. Colaborador Robin Li: El lenguaje natural se convertirá en un nuevo lenguaje de programación universal. El modelo de código abierto se quedará cada vez más atrás de Huawei: tomará 1 año migrar completamente 5,000 aplicaciones móviles de uso común a Hongmeng, que es el lenguaje más propenso. Vulnerabilidades de terceros. Se lanzó el editor de texto enriquecido Quill 2.0 con características, confiabilidad y experiencia de desarrolladores que Ma Huateng y Zhou Hongyi se dieron la mano para "eliminar los rencores". La fuente de Laoxiangji no es el código, las razones detrás de esto son muy conmovedoras. Google anunció una reestructuración a gran escala.