

Fuente del artículo | Equipo de creación inteligente de ByteDance
Nos complace compartir con ustedes nuestro último modelo de gráfico vicenciano, SDXL-Lightning, que logra una velocidad y calidad sin precedentes y ahora está disponible para la comunidad.
Modelo: https://huggingface.co/ByteDance/SDXL-Lightning
Documento: https://arxiv.org/abs/2402.13929

Generación de imágenes ultrarrápida
La IA generativa está ganando atención mundial por su capacidad para crear imágenes impresionantes e incluso vídeos basados en indicaciones de texto. Sin embargo, los modelos generativos de última generación actuales se basan en la difusión, un proceso iterativo que transforma gradualmente el ruido en muestras de imágenes. Este proceso requiere enormes recursos informáticos y es lento. En el proceso de generación de muestras de imágenes de alta calidad, el tiempo de procesamiento de una sola imagen es de aproximadamente 5 segundos, lo que generalmente requiere múltiples llamadas (de 20 a 40 veces) a una enorme red neuronal. . Esta velocidad limita los escenarios de aplicaciones que requieren una generación rápida en tiempo real. Cómo acelerar la generación y al mismo tiempo mejorar la calidad es un área candente de investigación actual y el objetivo principal de nuestro trabajo.
SDXL-Lightning rompe esta barrera a través de una tecnología innovadora, la destilación adversa progresiva , para lograr velocidades de generación sin precedentes. El modelo es capaz de generar imágenes de muy alta calidad y resolución en sólo 2 o 4 pasos, reduciendo el coste y el tiempo computacional en un factor de diez. Nuestro método puede incluso generar imágenes en 1 paso para aplicaciones sensibles al tiempo de espera, aunque es posible que se sacrifique ligeramente algo de calidad.
Además de su ventaja de velocidad, SDXL-Lightning también ofrece un rendimiento significativo en calidad de imagen y supera a las tecnologías de aceleración anteriores en las evaluaciones. Logre una mayor resolución y mejores detalles manteniendo una buena diversidad y coincidencia entre imagen y texto.
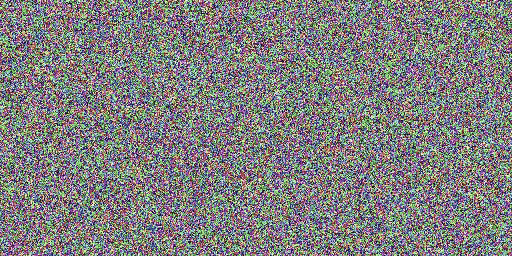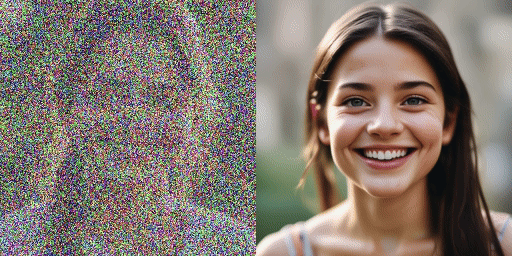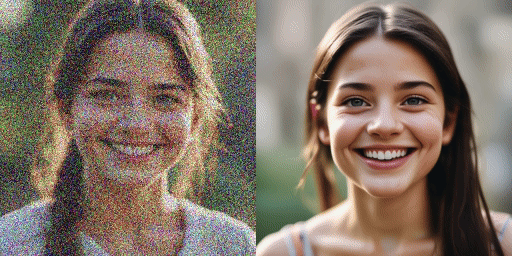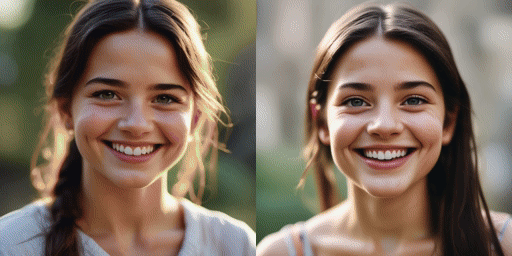 comparación de velocidad
comparación de velocidad
Modelo original (20 pasos), nuestro modelo (2 pasos)
Efecto modelo
Nuestro modelo puede generar imágenes en 1 paso, 2 pasos, 4 pasos y 8 pasos. Cuantos más pasos de inferencia haya, mejor será la calidad de la imagen.
Aquí están los resultados de nuestro proceso de 4 pasos:
Aquí están los resultados de nuestra construcción de 2 pasos:
En comparación con los métodos anteriores (Turbo y LCM), nuestro método genera imágenes significativamente mejoradas en detalle y más fieles al estilo y diseño del modelo generativo original.

Retribuir a la comunidad, modelo abierto
La ola de código abierto se ha convertido en una fuerza clave para promover el rápido desarrollo de la inteligencia artificial, y ByteDance se enorgullece de ser parte de esta ola. Nuestro modelo se basa en SDXL, actualmente el modelo abierto más popular para imágenes de generación de texto, que ya cuenta con un ecosistema próspero. Ahora, hemos decidido abrir SDXL-Lightning a desarrolladores, investigadores y profesionales creativos de todo el mundo para que puedan acceder y aplicar este modelo para promover aún más la innovación y la colaboración en toda la industria.
Al diseñar SDXL-Lightning, consideramos la compatibilidad con la comunidad de modelos abiertos. Muchos artistas y desarrolladores de la comunidad han creado una variedad de modelos de generación de imágenes estilizadas, como estilos de dibujos animados y anime. Para admitir estos modelos, proporcionamos SDXL-Lightning como un complemento de aceleración, que se puede integrar perfectamente en estos diversos estilos de modelos SDXL para acelerar la generación de imágenes para varios modelos.
 Nuestro modelo también se puede combinar con el complemento de control ControlNet, actualmente muy popular, para lograr una generación de imágenes extremadamente rápida y controlable.
Nuestro modelo también se puede combinar con el complemento de control ControlNet, actualmente muy popular, para lograr una generación de imágenes extremadamente rápida y controlable.
 Nuestro modelo también es compatible con ComfyUI, actualmente la generación de software más popular en la comunidad de código abierto, y el modelo se puede cargar directamente para su uso:
Nuestro modelo también es compatible con ComfyUI, actualmente la generación de software más popular en la comunidad de código abierto, y el modelo se puede cargar directamente para su uso: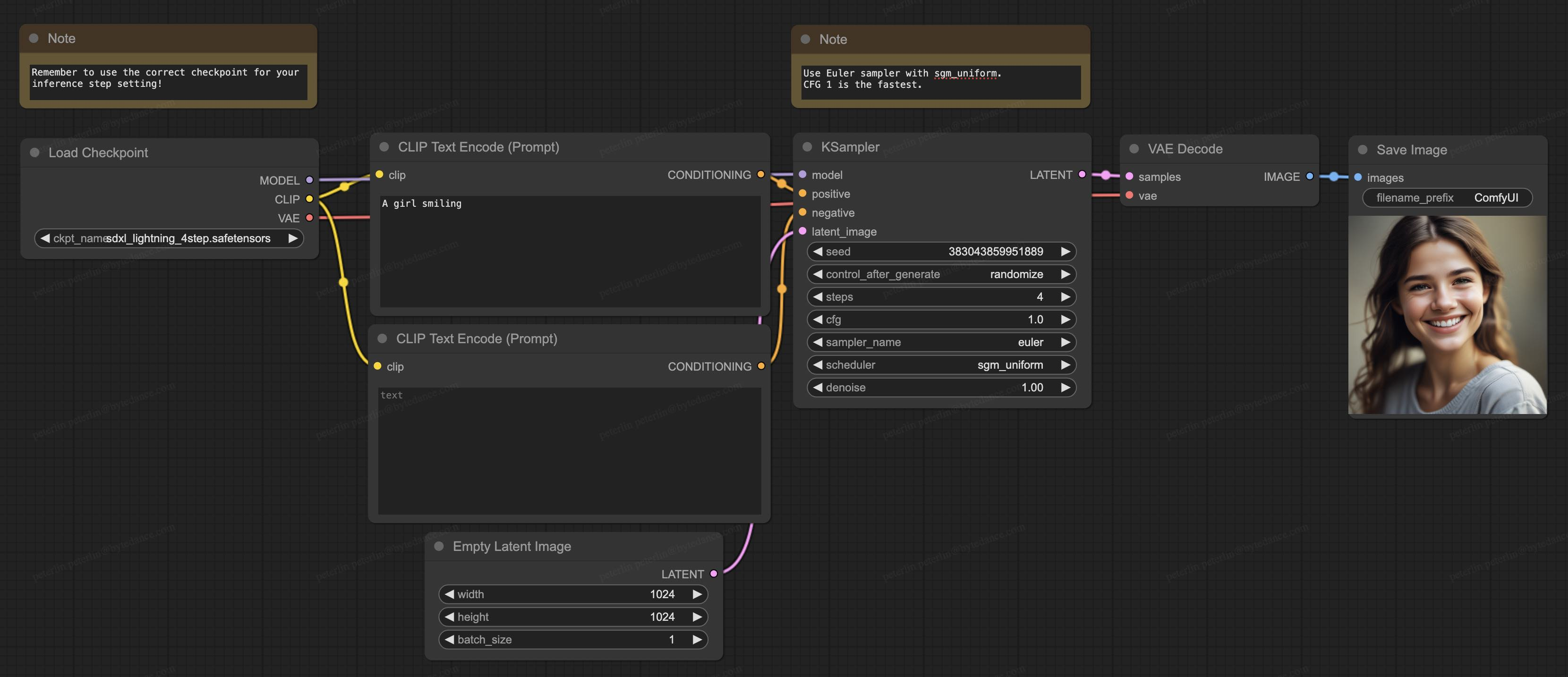
Acerca de los detalles técnicos
En teoría, la generación de imágenes es un proceso de transformación paso a paso del ruido a imágenes claras. En este proceso, la red neuronal aprende los gradientes en varias posiciones en el flujo de transformación.
Los pasos específicos para generar una imagen son los siguientes: primero, tomamos una muestra aleatoria de una muestra de ruido en el punto inicial de la transmisión y luego usamos una red neuronal para calcular el gradiente. Según el gradiente en la posición actual, hacemos pequeños ajustes a la muestra y luego repetimos el proceso. Con cada iteración, las muestras se acercan a la distribución de la imagen final hasta que se obtiene una imagen clara.
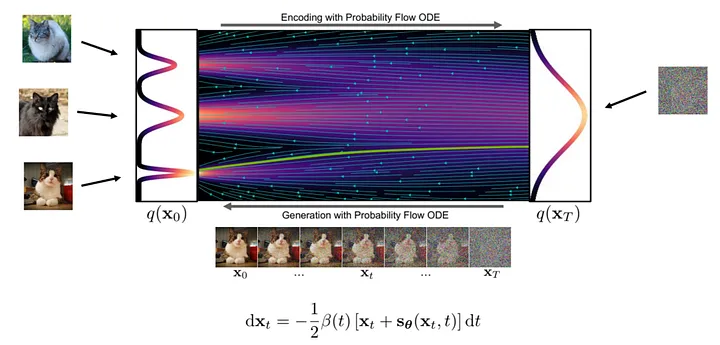 Figura: Proceso de generación ( imagen de : https://arxiv.org/abs/2011.13456 )
Figura: Proceso de generación ( imagen de : https://arxiv.org/abs/2011.13456 )
Dado que el flujo de generación es complejo y no lineal, el proceso de generación solo debe dar un pequeño paso a la vez para reducir la acumulación de errores de gradiente, por lo que se requieren cálculos frecuentes de la red neuronal, razón por la cual la cantidad de cálculo es grande.
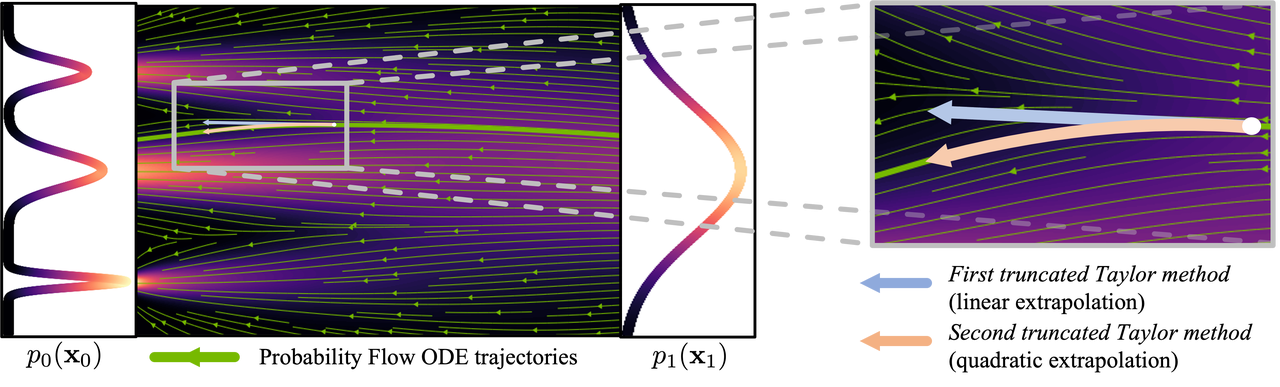 Figura: Proceso de curva ( imagen de : https://arxiv.org/abs/2210.05475 )
Figura: Proceso de curva ( imagen de : https://arxiv.org/abs/2210.05475 )
Para reducir el número de pasos necesarios para generar imágenes, se ha dedicado mucha investigación a encontrar soluciones. Algunos estudios proponen métodos de muestreo que reducen los errores, mientras que otros intentan hacer más lineal el flujo generado. A pesar de los avances en estos métodos, todavía requieren más de 10 pasos de inferencia para generar imágenes.
Otro método es la destilación de modelos, que puede generar imágenes de alta calidad en menos de 10 pasos de inferencia. En lugar de calcular el gradiente en la posición de flujo actual, la destilación del modelo cambia el objetivo de la predicción del modelo para predecir directamente la siguiente posición de flujo más lejana. Específicamente, entrenamos una red de estudiantes para que prediga directamente el resultado de la red de maestros después de completar el razonamiento de varios pasos. Una estrategia de este tipo puede reducir significativamente el número de pasos de inferencia necesarios. Al aplicar este proceso repetidamente, podemos reducir aún más el número de pasos de inferencia. Investigaciones anteriores han denominado este enfoque destilación progresiva.
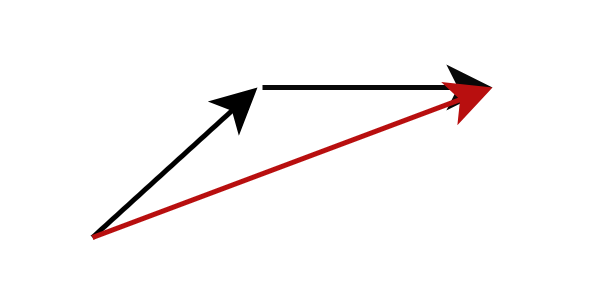 Figura: Destilación progresiva , la red de estudiantes predice el resultado de la red de profesores después de varios pasos
Figura: Destilación progresiva , la red de estudiantes predice el resultado de la red de profesores después de varios pasos
En la práctica, las redes de estudiantes suelen tener dificultades para predecir con precisión las posiciones futuras de los flujos. El error se amplifica a medida que se acumula cada paso, lo que hace que las imágenes producidas por el modelo comiencen a volverse borrosas con menos de 8 pasos de inferencia.
Para resolver este problema, nuestra estrategia no es forzar que la red de estudiantes coincida exactamente con las predicciones de la red de maestros, sino hacer que la red de estudiantes sea consistente con la red de maestros en términos de distribución de probabilidad. En otras palabras, la red de estudiantes está entrenada para predecir una ubicación probabilísticamente posible, e incluso si esta ubicación no es completamente precisa, no la penalizamos. Este objetivo se logra a través del entrenamiento adversario, que introduce una red discriminativa adicional para ayudar a lograr una distribución coincidente de los resultados de la red de estudiantes y maestros.
Esta es una breve descripción de nuestros métodos de investigación. En nuestro artículo técnico ( https://arxiv.org/abs/2402.13929 ), proporcionamos un análisis teórico más profundo, una estrategia de capacitación y detalles de formulación específicos del modelo.
Más allá de SDXL-Lightning
Aunque este estudio explora principalmente cómo utilizar la tecnología SDXL-Lightning para la generación de imágenes, el potencial de aplicación de nuestro método de destilación adversa progresiva propuesto no se limita a imágenes estáticas. Esta innovadora tecnología también se puede utilizar para generar vídeo, audio y otros contenidos multimodales de forma rápida y con alta calidad. Le invitamos sinceramente a experimentar SDXL-Lightning en la plataforma HuggingFace y esperamos sus valiosos comentarios y sugerencias.
Modelo: https://huggingface.co/ByteDance/SDXL-Lightning
Documento: https://arxiv.org/abs/2402.13929
¡Compañero pollo deepin-IDE de "código abierto" y finalmente logró el arranque! Buen chico, Tencent realmente ha convertido Switch en una "máquina de aprendizaje pensante" Revisión de fallas de Tencent Cloud del 8 de abril y explicación de la situación Reconstrucción de inicio de escritorio remoto de RustDesk Cliente web Base de datos de terminal de código abierto WeChat basada en SQLite WCDB marcó el comienzo de una actualización importante Lista de abril de TIOBE: PHP cayó a un mínimo histórico, Fabrice Bellard, el padre de FFmpeg, lanzó la herramienta de compresión de audio TSAC , Google lanzó un modelo de código grande, CodeGemma , ¿te va a matar? Es tan bueno que es de código abierto: herramienta de edición de carteles e imágenes de código abierto