En el desarrollo moderno del aprendizaje profundo, generalmente confiamos en otros módulos para construir sistemas de software complejos como bloques de construcción. Este proceso suele ser rápido y efectivo. Sin embargo, cómo localizar y resolver rápidamente los problemas cuando se encuentran siempre ha preocupado a los diseñadores y mantenedores de sistemas de aprendizaje profundo debido a la complejidad y el acoplamiento del sistema.
Como miembro del equipo técnico de back-end de iQiyi, hemos registrado en detalle el proceso de resolución de problemas relacionados con la memoria del entrenamiento de aprendizaje profundo, con la esperanza de brindar algo de inspiración a los compañeros que están trabajando arduamente para resolver problemas espinosos.
fondo
Durante el último trimestre, hemos estado observando fenómenos OOM aleatorios de memoria de CPU en el clúster A100. Con la introducción del entrenamiento de modelos grandes, oom se volvió aún más insoportable, lo que nos hizo decidir resolver este problema.
Al recordar de dónde vengo, de repente me sentí iluminado. De hecho, alguna vez estuvimos muy cerca de la verdad del problema, pero nos faltó suficiente imaginación y nos perdimos.
proceso
Al principio, realizamos un análisis inductivo de los registros históricos. Se descubrieron varias reglas que tienen un gran significado orientativo para la solución final:
-
Este es un problema nuevo encontrado en el clúster A100 y no se ha encontrado en otros clústeres.
-
El problema está relacionado con el entrenamiento distribuido ddp de pytorch; no se han encontrado otros modos de entrenamiento que utilizan pytorch.
-
Este problema de OOM es bastante aleatorio, algunos ocurren en 3 horas y otros solo ocurren después de más de una semana.
-
El aumento de memoria ocurre durante OOM, básicamente completando el aumento del 10% al 90% en 1 minuto y medio, como se muestra en la siguiente figura:
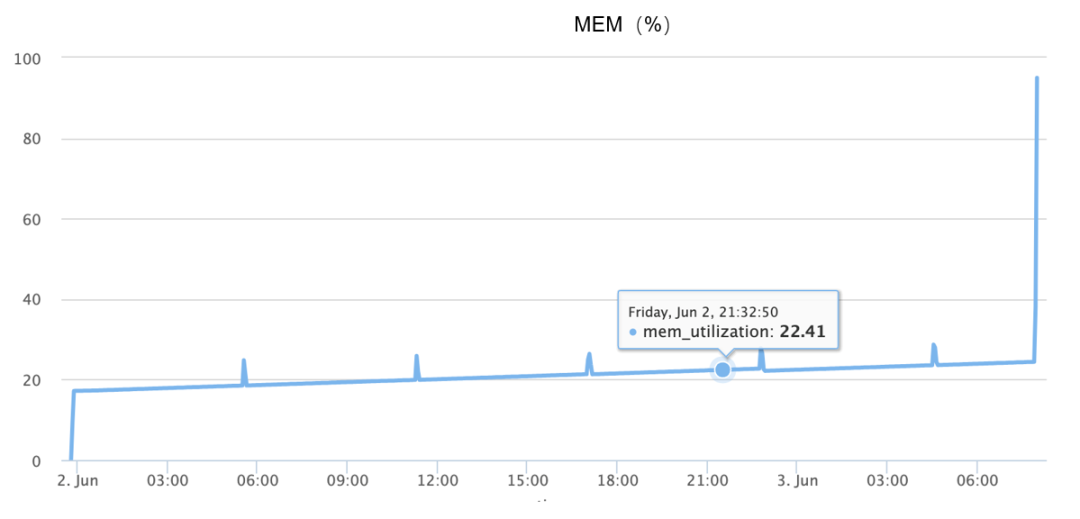
Aunque la información anterior está disponible, dado que el problema no se puede reproducir de manera confiable, al principio me basé completamente en la imaginación divergente, supuse muchas causas posibles, como por ejemplo:
-
¿Podría ser un problema de código, porque el objeto no se recicla, provocando pérdidas continuas de memoria?
-
¿Podría ser un problema con el asignador de memoria subyacente, similar al hecho de que el asignador PTMALLOC de glibc tiene demasiados fragmentos, por lo que en un momento determinado, las solicitudes repentinas de memoria conducen a una asignación de memoria continua?
-
¿Podría ser un problema de hardware?
-
¿Podría ser un error en alguna versión específica del software?
A continuación presentamos en detalle los dos primeros supuestos.
-
¿Es un problema con el código?
Para determinar si se trata de un problema de código, agregamos código de depuración a la escena donde ocurrió el problema y lo llamamos periódicamente. El siguiente código imprimirá todos los objetos que el módulo python gc actual no puede reciclar.
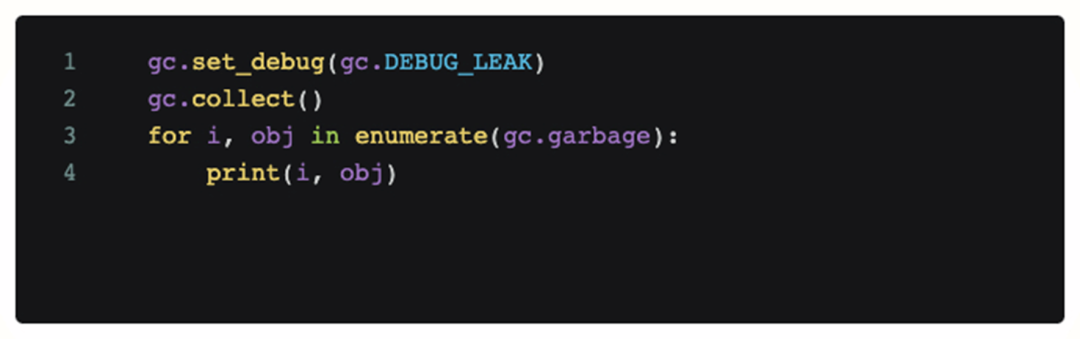 Sin embargo, después de agregar este código, el análisis de registro obtenido muestra que no hay ningún objeto inalcanzable que ocupe mucha memoria durante OOM, y el gc continuo no puede aliviar el OOM en sí. Entonces, en este punto, nuestra primera suposición es fallida y el problema no es causado por el código (pérdida de memoria).
Sin embargo, después de agregar este código, el análisis de registro obtenido muestra que no hay ningún objeto inalcanzable que ocupe mucha memoria durante OOM, y el gc continuo no puede aliviar el OOM en sí. Entonces, en este punto, nuestra primera suposición es fallida y el problema no es causado por el código (pérdida de memoria).
-
¿Es causado por el asignador de memoria?
En esta etapa, presentamos el asignador de memoria jemalloc. En comparación con el PTMALLOC predeterminado de glibc, su ventaja es que puede proporcionar una asignación de memoria más eficiente y un mejor soporte para la depuración de la asignación de memoria en sí.
-
¿Podría ser un problema con el asignador de memoria predeterminado?
-
Mejores herramientas de depuración y análisis
Para ver directamente el estado actual de jemalloc en Python sin modificar el código de la antorcha, usamos ctypes para exponer la interfaz de jemalloc directamente en Python:
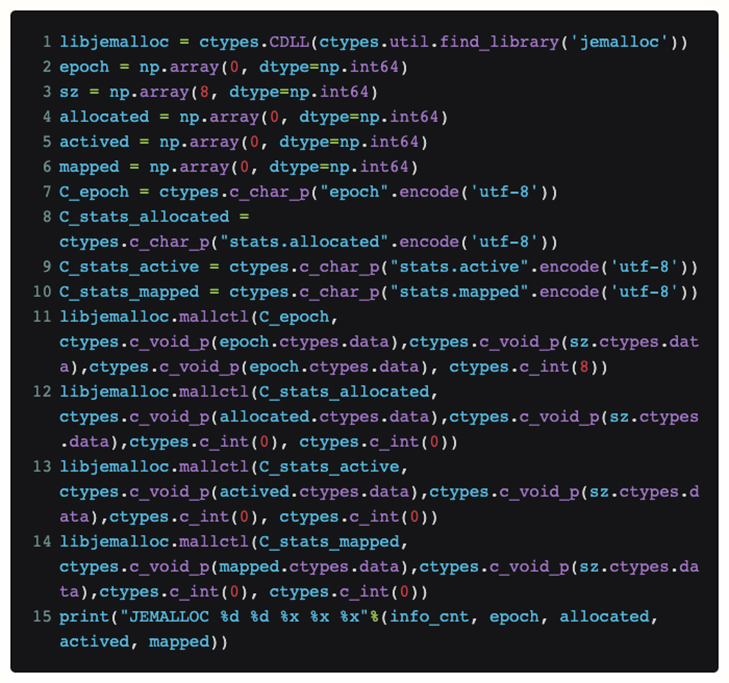
De esta manera, si ponemos este código en una función, podemos conocer periódicamente la solicitud [asignada] que jemalloc recibe actualmente desde la capa superior y el tamaño de memoria física real [mapeada] que solicita al sistema.
Después del proceso de reproducción real, finalmente se descubrió que los dos valores asignados y mapeados están muy cerca cuando ocurre OOM. Entonces nuestra hipótesis sobre la fragmentación de la memoria fracasa.
-
¿Qué causó exactamente el problema?
Cuando estábamos al final de nuestra cuerda, una vez más clasificamos los registros OOM existentes y descubrimos que había una dirección en la que no nos habíamos centrado antes: es decir, teníamos varias máquinas funcionando en momentos similares (1-2 minutos adyacentes) varias veces ) OOM ocurre.
Entonces, ¿qué explicación lógica hay para esta sincronicidad mágica? Los errores comunes no deberían provocar que dicha coherencia vuelva a ocurrir. Por tanto, puede haber alguna conexión inevitable entre ellos.
Entonces, ¿de dónde viene esta correlación? Para explorar esta cuestión, la perspectiva analítica cambia a la comunicación en red en la formación distribuida.
La sospecha inicial sobre la comunicación se centró en las máquinas que experimentaron OOM. Se sospechaba que se estaban comunicando entre sí por algún motivo, lo que causaría problemas entre sí. Por lo tanto, se agregó tcpdump al entrenamiento diario para monitorear el tráfico de la red.
Finalmente, después de unirme a tcpdump, capté la comunicación más cuestionable durante un OOM. Es decir, la máquina OOM recibió tráfico de escaneo de seguridad unos minutos antes de que ocurriera el problema.
posicionamiento final
Después de detectar al equipo de seguridad escaneando el objeto sospechoso, colaboramos con el equipo de seguridad para realizar un análisis y finalmente descubrimos que el problema OOM se podía reproducir de manera estable según el escaneo, por lo que la causa desencadenante era casi segura. Sin embargo, en este punto, solo podemos reproducir y cambiar la estrategia de escaneo de seguridad para evitar el problema de OOM. También necesitamos analizar más a fondo el código y finalmente localizarlo.
Después de analizar y posicionar el código, finalmente se determinó que el problema radica en el protocolo de entrenamiento distribuido DDP de pytorch. El código relevante es el siguiente:
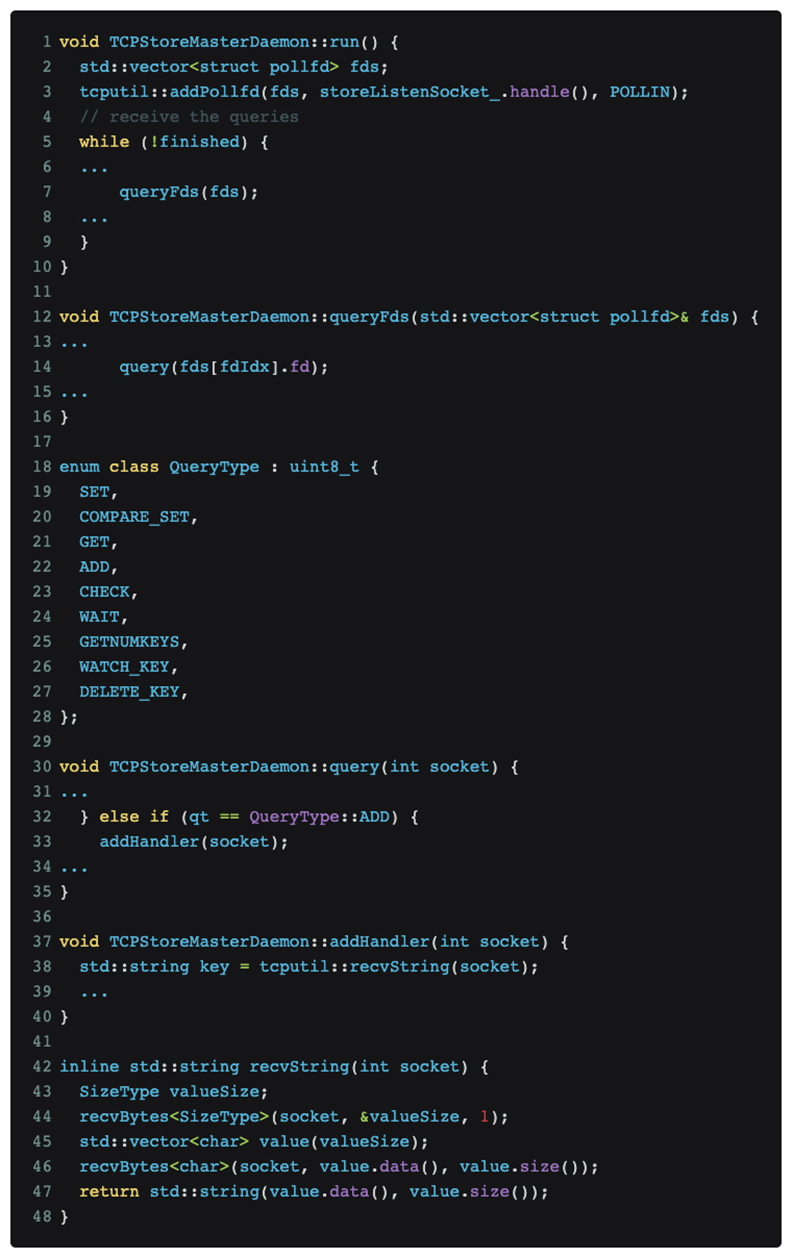
Como se muestra en la figura anterior, el entrenamiento distribuido de pytorch continúa escuchando mensajes en el puerto maestro.

El escaneo de Nmap [nmap -sS -sV] desencadenó el tipo de mensaje QueryType::ADD, que es el número del cuadro verde [03] en la parte de datos que se muestra en la imagen tcpdump anterior, lo que provocó que pytorch intentara usar recvString función para preasignar un búfer para recibir lo que considera mensajes de seguimiento. Pero esta longitud del búfer se analiza utilizando un tipo uint64_t [little-endian] después de [03], que es el número del cuadro rojo [e0060b0000], que es 962174058496 bytes. Se entiende que este valor significa que se recibirán datos de 1T y pytorch. Después de que el asignador de memoria solicite la memoria correspondiente, el asignador de memoria solicitará además la página física correspondiente del kernel. Dado que nuestro clúster de entrenamiento de GPU no está configurado con una tabla de páginas enorme, Linux solo puede satisfacer gradualmente la solicitud de memoria de 1T del asignador de memoria en las interrupciones de páginas faltantes de acuerdo con la granularidad de 4K, lo que significa que se necesita aproximadamente 1 minuto para asignar toda la memoria. El OOM observado anteriormente probablemente ocurre en respuesta a un rápido crecimiento de la memoria de aproximadamente 1 minuto.
solución
Después de conocer la causa y el efecto, la solución pasa a ser natural:
1. A corto plazo: cambiar la política de análisis de seguridad para evitar
2. A largo plazo: comuníquese con la comunidad para fortalecer la solidez [ 1 ]
Resumir
Después de completar el seguimiento del proceso de investigación del problema OOM, descubrimos que durante este proceso, en realidad habíamos realizado una ronda efectiva de pruebas de herramientas relacionadas con la memoria y métodos de depuración.
Durante este proceso, descubrimos que hay algunos puntos en común que pueden usarse como referencia en investigaciones y desarrollo posteriores:
-
Jemalloc puede proporcionar un análisis cuantitativo muy eficaz de los problemas de memoria y puede capturar problemas subyacentes relacionados con la memoria en sistemas de programación híbridos como Python+C.
-
Memoria. Teníamos grandes expectativas al respecto durante el proceso de depuración, pero al final descubrimos que el área donde Memray puede funcionar mejor sigue siendo el lado de Python puro y no es capaz de sistemas de programación híbridos como pytorch DDP.
A veces todavía necesitamos pensar en los problemas desde una dimensión más amplia. Por ejemplo, si el proceso de comunicación con servicios externos no relacionados no se incluye en la consideración, no se descubrirá la causa raíz real.
Quizás tú también quieras ver

