

¡El paradigma de generación visual de nueva generación "VAR: Visual Auto Regressive" ya está aquí! El modelo autorregresivo de estilo GPT supera por primera vez al modelo de difusión en la generación de imágenes , y se observan las leyes de escala y la capacidad de generalización de generalización de tareas de disparo cero similares a las del modelo de lenguaje grande :
论文标题:Modelado visual autorregresivo: generación de imágenes escalables mediante predicción de siguiente escala
Este nuevo trabajo llamado VAR fue propuesto por investigadores de la Universidad de Pekín y ByteDance . Ha estado en las listas calientes de GitHub y Paperwithcode y ha recibido mucha atención por parte de sus pares:
Actualmente, se han publicado el sitio web de la experiencia, los documentos, los códigos y los modelos:
- Sitio web de la experiencia: https://var.vision/
- Enlace del artículo: https://arxiv.org/abs/2404.02905
- Código fuente abierto: https://github.com/FoundationVision/VAR
- Modelo de código abierto: https://huggingface.co/FoundationVision/var
Introducción a los antecedentes
En el procesamiento del lenguaje natural, el modelo autorregresivo, tomando como ejemplos modelos de lenguaje grandes como las series GPT y LLaMa, ha logrado un gran éxito. En particular, la ley de escala y la generalización de tareas de disparo cero tienen una generalización de tareas de disparo cero muy impresionante. capacidades , mostrando inicialmente el potencial de conducir a una "inteligencia artificial general AGI".
Sin embargo, en el campo de la generación de imágenes, los modelos autorregresivos generalmente van por detrás de los modelos de difusión: DALL-E3, Stable Diffusion3, SORA y otros modelos que han sido populares recientemente pertenecen a la familia Diffusion. Además, aún se desconoce si existe una "ley de escala" en el campo de la generación visual , es decir, si la pérdida de entropía cruzada del conjunto de prueba puede mostrar una tendencia a la baja predecible de la ley de potencia con el modelo o la sobrecarga de entrenamiento . para ser explorado.
Las poderosas capacidades y la ley de escala del modelo autorregresivo formal GPT parecen estar "bloqueadas" en el campo de la generación de imágenes:

El modelo autorregresivo va por detrás de muchos modelos de difusión en la lista de efectos de generación.
Centrándose en "desbloquear" la capacidad de los modelos autorregresivos y las leyes de escala, el equipo de investigación partió de la naturaleza inherente de las modalidades de imagen, imitó la secuencia lógica del procesamiento de imágenes humanas y propuso un nuevo paradigma de generación "visual autorregresivo": VAR, Visual AutoRegressive. Modelado, por primera vez, la generación visual autorregresiva de estilo GPT supera la Difusión en términos de efecto, velocidad y capacidades de escala, y marcó el comienzo de las Leyes de escala en el campo de la generación visual:

El núcleo del método VAR: imitar la visión humana y redefinir la secuencia autorregresiva de la imagen
Cuando los humanos perciben imágenes o pintan, primero tienden a obtener una visión general y luego a profundizar en los detalles. Este tipo de pensamiento de grueso a fino, desde captar el todo hasta ajustar finamente la parte, es muy natural:
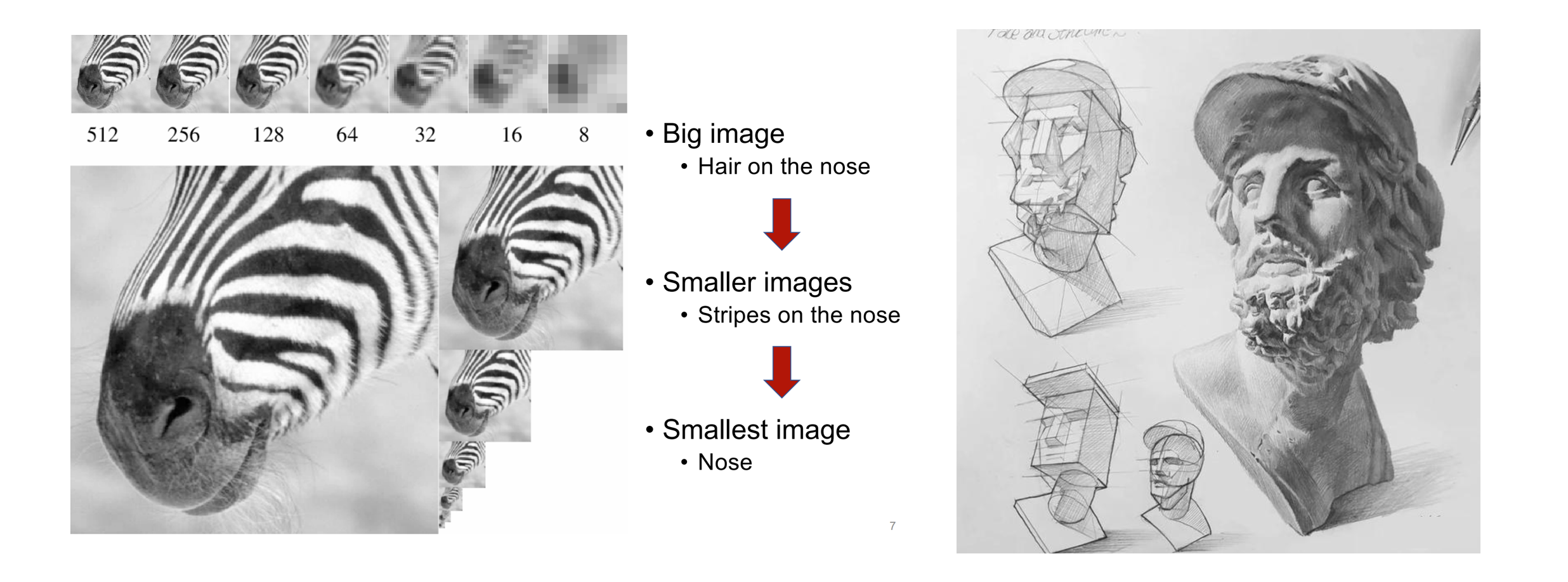
La secuencia lógica de lo grueso a lo fino de la percepción humana de las imágenes (izquierda) y la creación de pinturas (derecha)
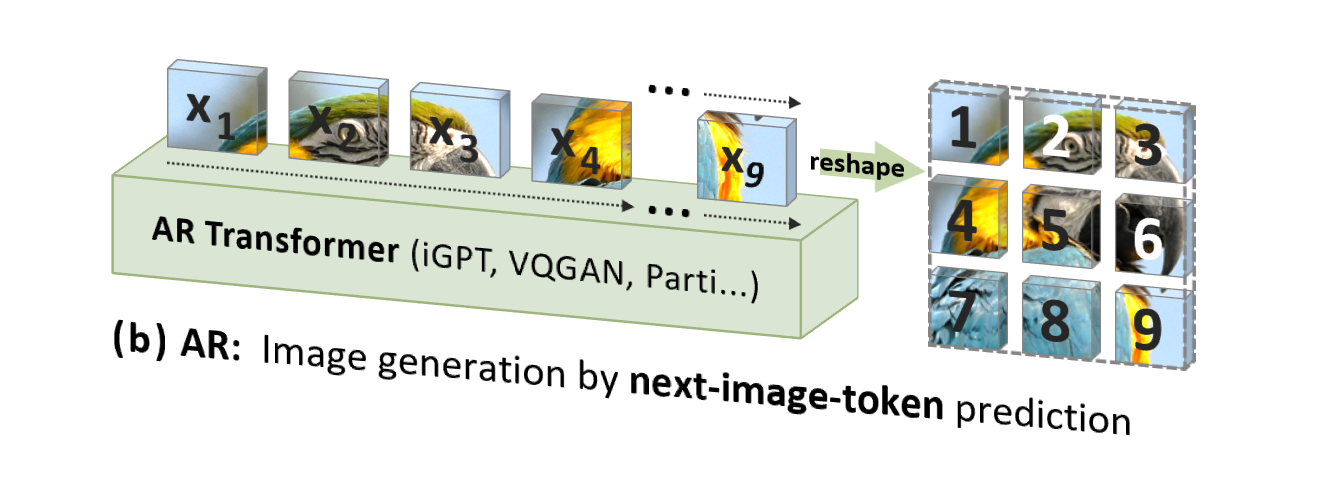
Sin embargo, la autorregresión de imágenes (AR) tradicional utiliza un orden que no está en línea con la intuición humana (pero es adecuado para el procesamiento por computadora), es decir, un orden ráster de arriba hacia abajo, línea por línea, para predecir tokens de imágenes uno por uno. :
VAR está "orientado a las personas", imita la secuencia lógica de la percepción humana o las imágenes creadas por humanos y genera gradualmente un mapa simbólico utilizando una secuencia de múltiples escalas desde el todo hasta los detalles:
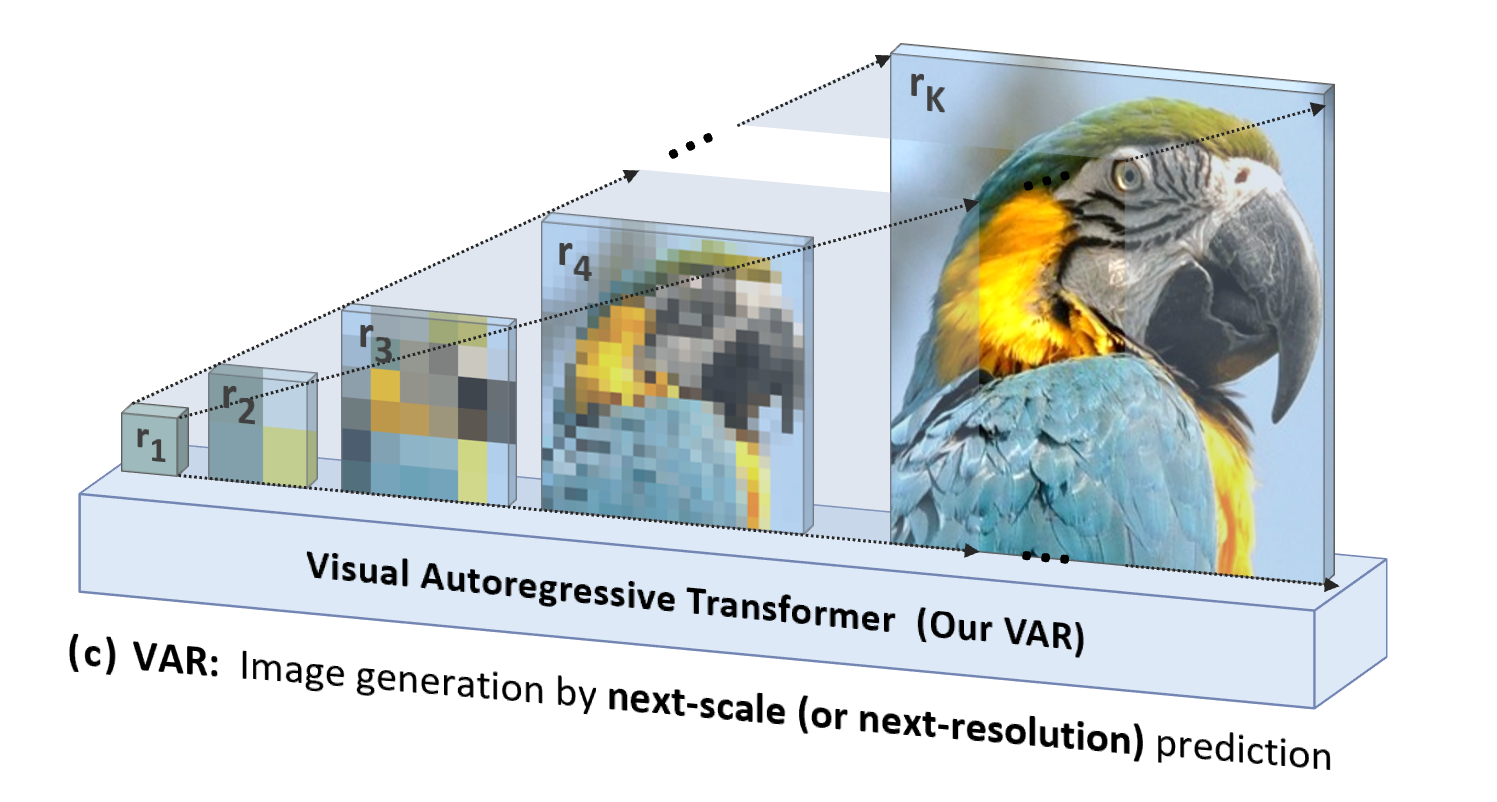
Además de ser más natural y estar en línea con la intuición humana, otra ventaja significativa que aporta VAR es que aumenta en gran medida la velocidad de generación: en cada paso de la autorregresión (dentro de cada escala), todos los tokens de imágenes se generan en paralelo a la vez; escalas Es autorregresivo. Esto hace que VAR sea decenas de veces más rápido que AR tradicional cuando los parámetros del modelo y los tamaños de imagen son equivalentes. Además, en el experimento, el autor también observó que VAR muestra un mayor rendimiento y capacidades de escalamiento que AR.
Detalles del método VAR: entrenamiento en dos etapas
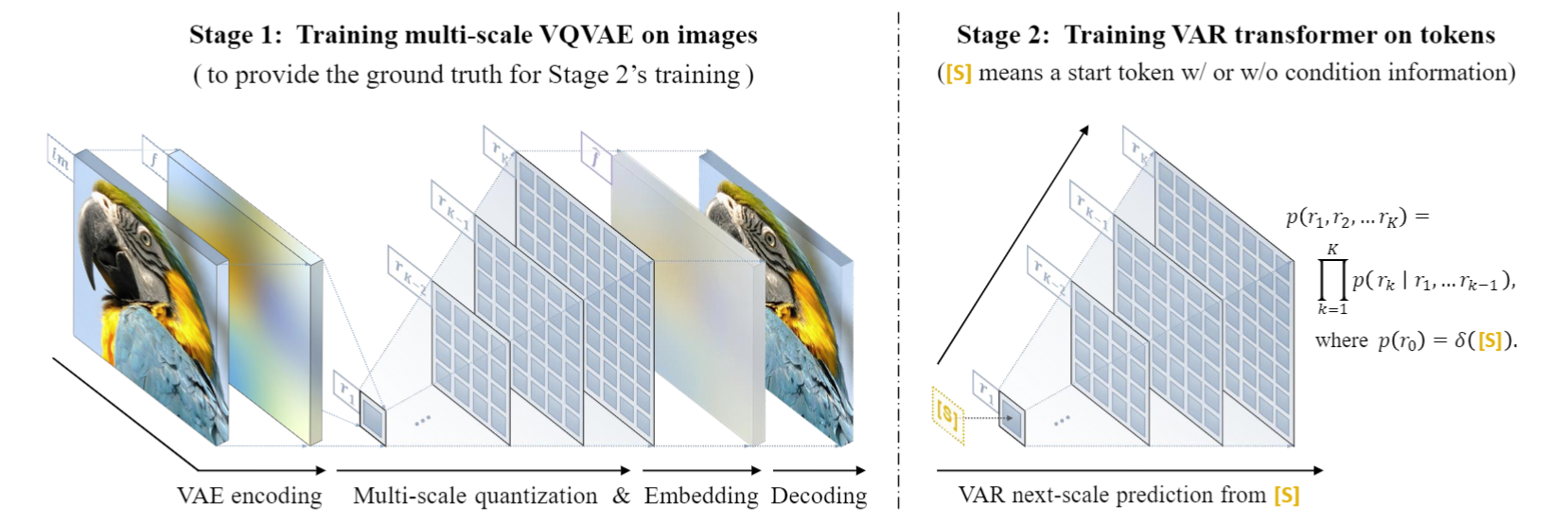
VAR entrena un codificador automático de cuantificación multiescala (VQVAE multiescala) en la primera etapa y entrena un transformador autorregresivo consistente con la estructura GPT-2 (combinado con AdaLN) en la segunda etapa.
Como se muestra en la imagen de la izquierda, los detalles de la precuela de entrenamiento de VQVAE son los siguientes:
- Codificación discreta : el codificador convierte la imagen en un mapa de token discreto R = (r1, r2, ..., rk), con resoluciones de pequeña a grande.
- Continuización : r1 a rk primero se convierten en mapas de características continuas a través de la capa de incrustación, luego se interpolan uniformemente a la resolución máxima correspondiente a rk y se suman
- Decodificación continua : el mapa de características sumado se pasa a través del decodificador para obtener la imagen reconstruida y se entrena mediante una combinación de tres pérdidas: reconstrucción + percepción + confrontación.
Como se muestra en la figura de la derecha, una vez completado el entrenamiento VQVAE, se realizará la segunda etapa del entrenamiento Transformer autorregresivo:
- El primer paso de la autorregresión es predecir el mapa de token inicial 1x1 a partir del token **** inicial [S]
- En cada paso posterior, VAR predice el siguiente mapa de tokens a mayor escala basándose en todos los mapas de tokens históricos .
- Durante la fase de entrenamiento, VAR utiliza la pérdida de entropía cruzada estándar para supervisar la predicción de probabilidad de estos mapas de tokens.
- En la fase de prueba, el mapa de tokens muestreado se serializará, interpolará, sumará y decodificará con la ayuda del decodificador VQVAE para obtener la imagen final generada.
El autor dijo que el marco autorregresivo de VAR es completamente nuevo y que la tecnología específica ha absorbido las fortalezas de una serie de tecnologías clásicas, como el VAE residual de RQ-VAE, StyleGAN y AdaLN de DiT, y el entrenamiento progresivo de PGGAN. En realidad, el VAR se apoya en gigantes y se centra en la innovación del propio algoritmo autorregresivo.
Comparación de efectos experimentales
Experimentos VAR en ImageNet condicional 256x256 y 512x512:
- VAR ha mejorado enormemente el efecto de AR, haciendo que AR deje de quedarse atrás con respecto a Diffusion .
- VAR solo requiere 10 pasos autorregresivos y su velocidad de generación supera con creces a AR y Difusión, e incluso se acerca a la eficiencia de GAN.
- Al ampliar VAR a 2B/3B , VAR ha alcanzado el nivel SOTA, mostrando una nueva y potencial familia de modelos generativos.

Lo interesante es que, en comparación con SORA y Diffusion Transformer (DiT), el modelo fundamental de Stable Diffusion 3 , VAR muestra:
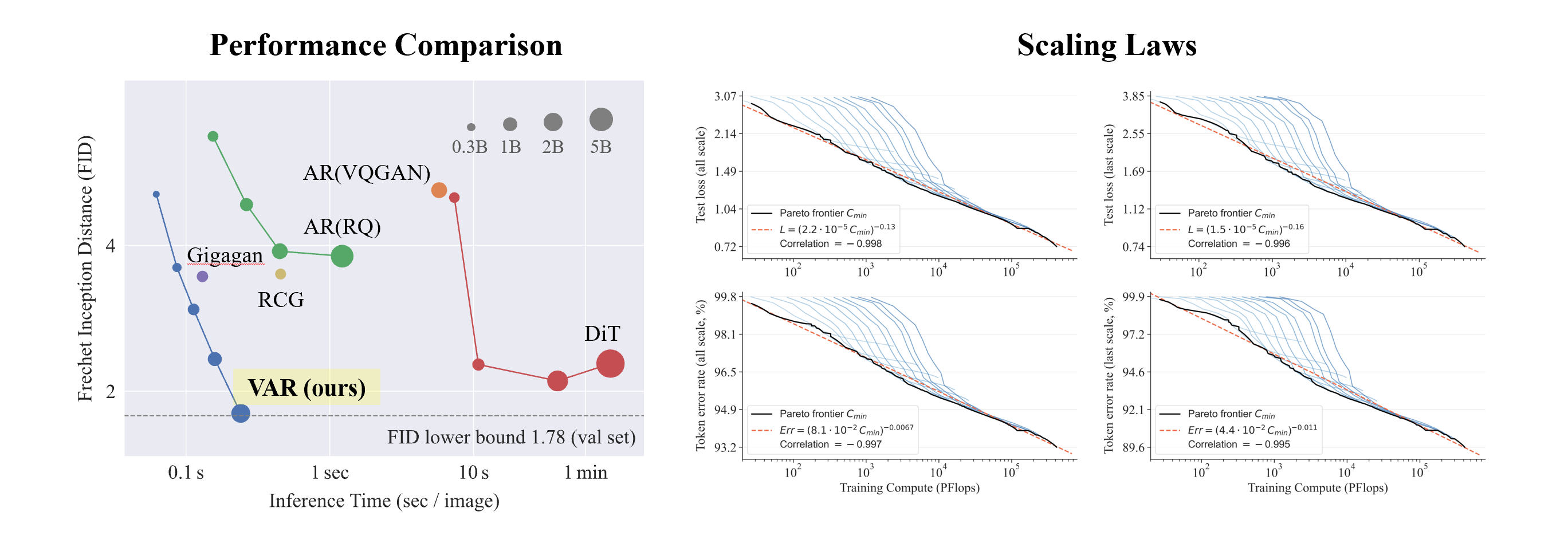
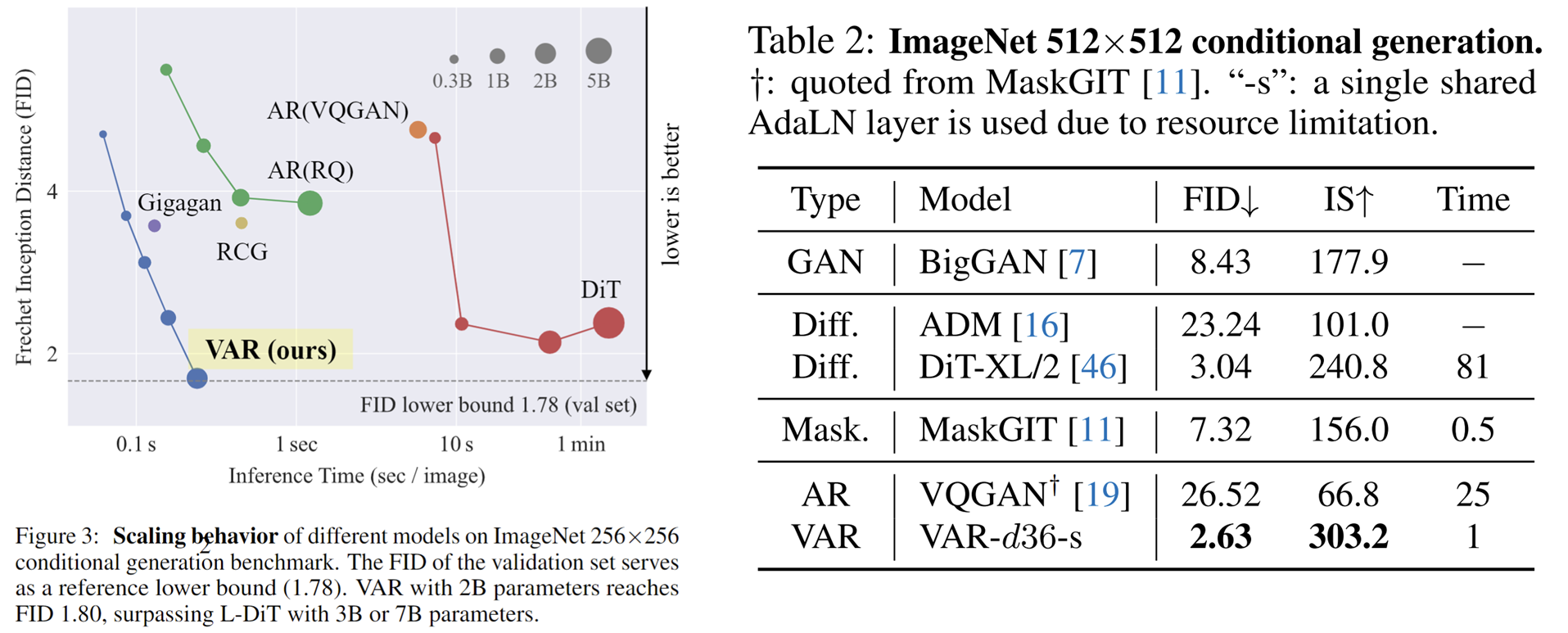
- Mejores resultados : después de la ampliación , VAR finalmente alcanzó FID=1,80, acercándose al límite inferior teórico de FID de 1,78 (conjunto de validación de ImageNet), significativamente mejor que el óptimo 2,10 de DiT.
- Velocidad más rápida : VAR puede generar una imagen 256 en menos de 0,3 segundos , que es 45 veces más rápido que DiT en 512, es 81 veces más rápido que DiT;
- Mejores capacidades de escala: como se muestra en la figura de la izquierda, el modelo grande DiT mostró saturación después de crecer a 3B y 7B , y no pudo acercarse al límite inferior de FID, mientras que VAR escaló a 2 mil millones de parámetros, su rendimiento continuó mejorando y; finalmente tocó el límite inferior del FID
- Utilización de datos más eficiente : VAR solo requiere un entrenamiento de 350 épocas, que es más que el entrenamiento de época DiT 1400 .
Estas evidencias de que es más eficiente, más rápido y más escalable que DiT brindan más posibilidades a la próxima generación de rutas de infraestructura de generación visual.
Experimento de la ley de escala
La ley de escala puede describirse como la "joya de la corona" de los grandes modelos de lenguaje. Investigaciones relevantes han determinado que en el proceso de ampliación de modelos de lenguaje autorregresivos a gran escala, la pérdida de entropía cruzada L en el conjunto de prueba disminuirá de manera predecible con la cantidad de parámetros del modelo N, la cantidad de tokens de entrenamiento T y la sobrecarga computacional. Cmin .Exponer la relación potencia-ley.
La ley de escala no solo hace posible predecir el rendimiento de modelos grandes basados en modelos pequeños, ahorrando gastos de cálculo y asignación de recursos, sino que también refleja la poderosa capacidad de aprendizaje del modelo AR autorregresivo. El rendimiento del conjunto de pruebas aumenta con N, T y. Cmín.
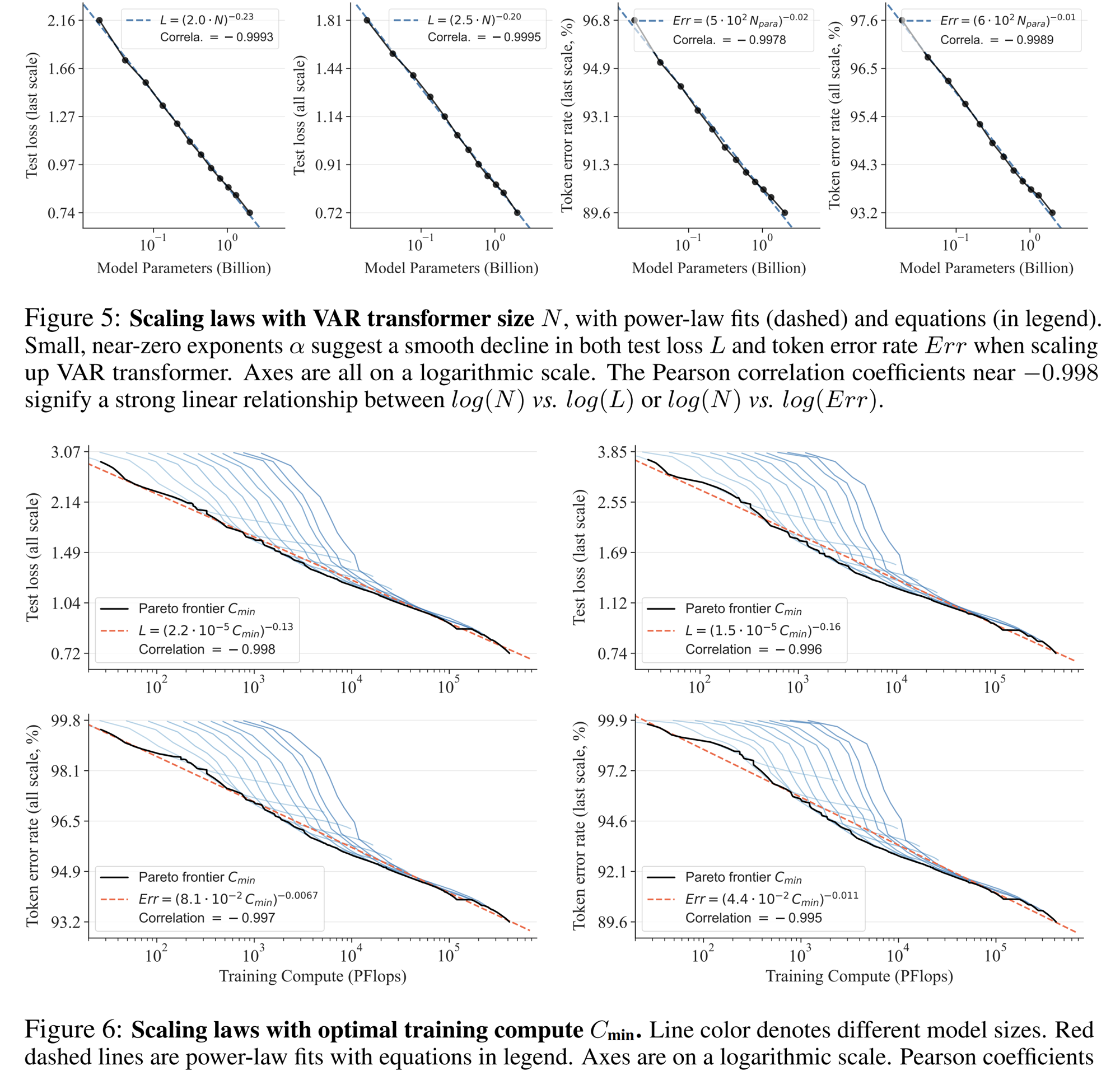
A través de experimentos, los investigadores observaron que VAR exhibe una ley de potencia Ley de escala que es casi idéntica a LLM : los investigadores entrenaron 12 tamaños de modelos, con un número de parámetros de modelo de escala que oscilaban entre 18 millones y 2 mil millones, y la cantidad total de cálculo abarcó 6 órdenes de magnitud, el número total máximo de tokens alcanza los 305 mil millones, y se observa que la pérdida del conjunto de prueba L o la tasa de error del conjunto de prueba y N, entre L y Cmin muestran una relación de ley de potencia suave, y el ajuste es bueno. :
En el proceso de ampliación de los parámetros del modelo y el volumen de cálculo, se puede ver que la capacidad de generación del modelo mejora gradualmente (como las franjas del osciloscopio a continuación):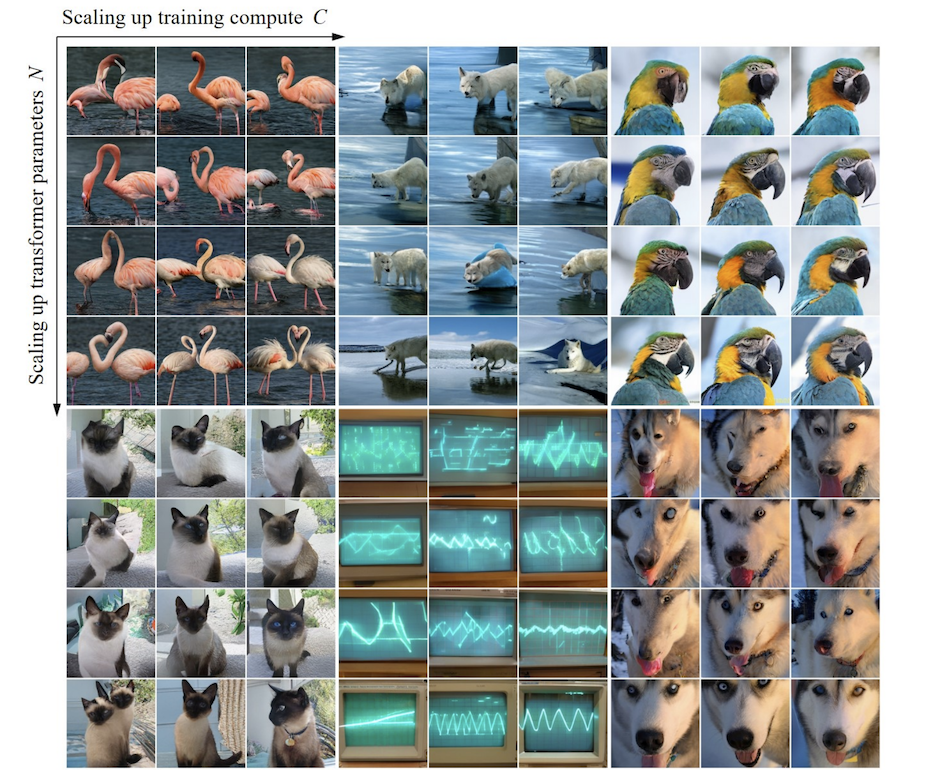
Experimento de tiro cero
Gracias a la excelente propiedad del modelo autorregresivo de que puede utilizar el mecanismo de fuerza del profesor para forzar que ciertos tokens permanezcan sin cambios, VAR también exhibe ciertas capacidades de generalización de tareas de muestra cero. El transformador VAR entrenado en la tarea de generación condicional puede generalizarse a algunas tareas generativas sin ningún ajuste fino, como la finalización de imágenes (pintura interna), la extrapolación de imágenes (pintura exterior) y la edición de imágenes (edición de condiciones de clase). ), y logró ciertos resultados:
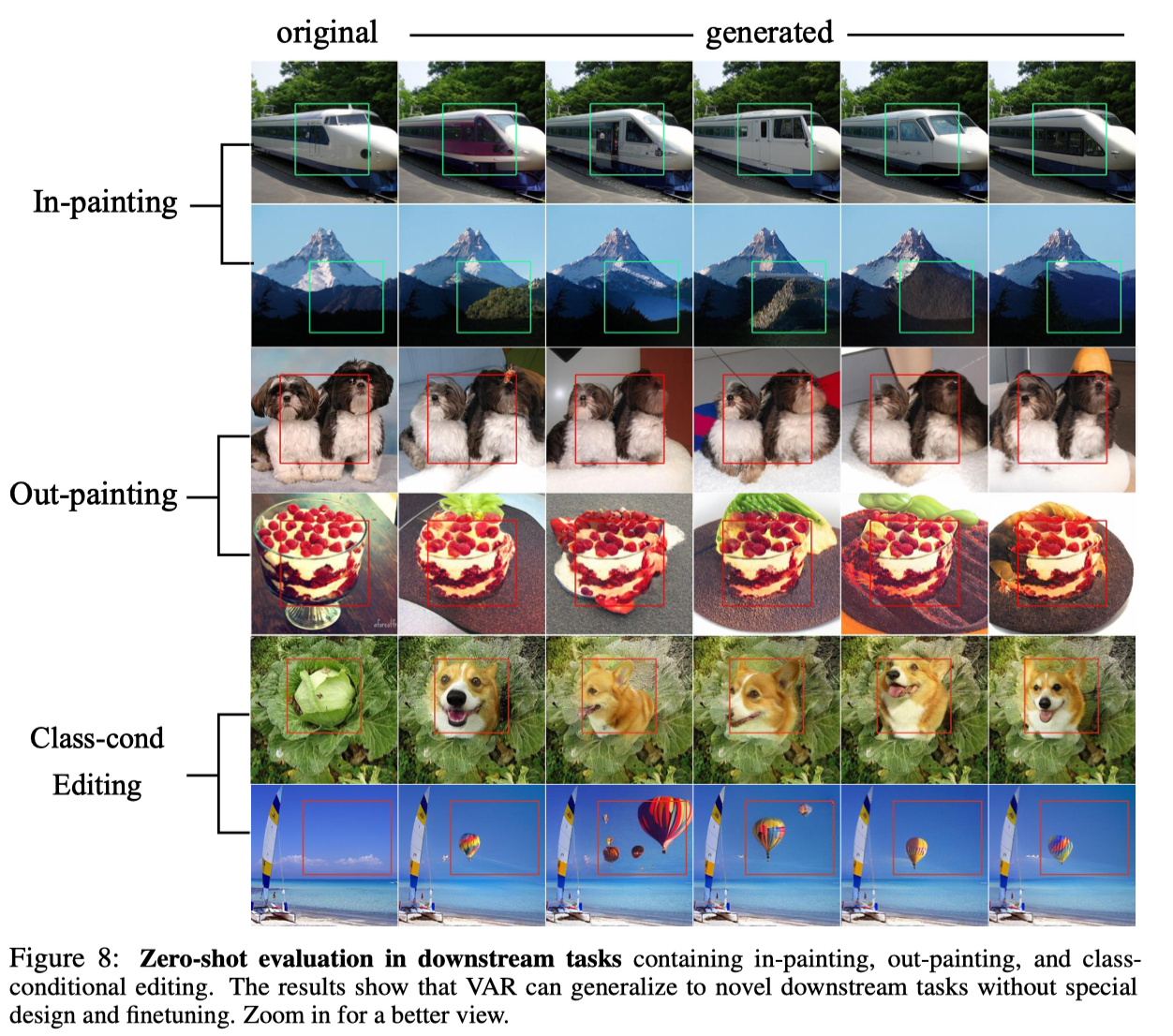
en conclusión
VAR proporciona una nueva perspectiva sobre cómo definir la secuencia autorregresiva de imágenes, es decir, la secuencia de gruesa a fina, desde contornos globales hasta ajuste fino local . Si bien es consistente con la intuición, un algoritmo autorregresivo de este tipo brinda buenos resultados: VAR mejora significativamente la velocidad y la calidad de generación del modelo autorregresivo, lo que hace que el modelo autorregresivo supere al modelo de difusión por primera vez en muchos aspectos . Al mismo tiempo, VAR exhibe leyes de escala y generalización de tiro cero similares a LLM. Los autores esperan que las ideas, las conclusiones experimentales y el código abierto de VAR puedan contribuir a la exploración de la comunidad del uso del paradigma autorregresivo en el campo de la generación de imágenes y promover el desarrollo de algoritmos multimodales unificados basados en la autorregresión en el futuro.
Acerca del equipo de Comercialización-GenAI de Bytedance
El equipo de ByteDance Commercialization-GenAI se enfoca en desarrollar tecnología avanzada de inteligencia artificial generativa y crear soluciones técnicas líderes en la industria que incluyen texto, imágenes y videos. Al utilizar la IA generativa para realizar un flujo de trabajo creativo automatizado, proporciona a los anunciantes instituciones y creadores que mejoran la eficiencia creativa e impulsan. valor.
Hay más puestos abiertos en la dirección de generación visual y LLM del equipo. Bienvenido a prestar atención a la información de contratación de ByteDance.
¡Compañero pollo deepin-IDE de "código abierto" y finalmente logró el arranque! Buen chico, Tencent realmente ha convertido Switch en una "máquina de aprendizaje pensante" Revisión de fallas de Tencent Cloud del 8 de abril y explicación de la situación Reconstrucción de inicio de escritorio remoto de RustDesk Cliente web Base de datos de terminal de código abierto WeChat basada en SQLite WCDB marcó el comienzo de una actualización importante Lista de abril de TIOBE: PHP cayó a un mínimo histórico, Fabrice Bellard, el padre de FFmpeg, lanzó la herramienta de compresión de audio TSAC , Google lanzó un modelo de código grande, CodeGemma , ¿te va a matar? Es tan bueno que es de código abierto: herramienta de edición de carteles e imágenes de código abierto