
El uso de bases de datos de series temporales (TSDB) ha sido común en diversas industrias durante décadas, especialmente en sistemas de control industrial y financiero. Sin embargo, el surgimiento de Internet de las cosas (IoT) ha provocado un aumento en la cantidad de datos de series temporales (datos de series temporales para abreviar), lo que ha impuesto mayores requisitos en cuanto al rendimiento de las bases de datos y los costos de almacenamiento, promoviendo así la necesidad de sistemas dedicados. Bases de datos de series temporales.
Frente a los problemas de la arquitectura obsoleta y la escalabilidad limitada de las soluciones de series temporales heredadas, surgió una nueva generación de bases de datos de series temporales que adoptan arquitecturas modernas que permiten el procesamiento distribuido y la expansión horizontal, así como una implementación flexible en la nube o en las instalaciones.
A finales de 2022, otro producto de gran éxito se unió a la pista de bases de datos de series temporales de código abierto y fue probado y producido por más de 60 empresas en solo un año, atrayendo a más de 70 contribuyentes de universidades y empresas clave en el país y en el extranjero: openGemini, La base de datos de series de tiempo distribuida de código abierto de Huawei se centra principalmente en el almacenamiento y análisis de datos de series de tiempo masivas. A través de la innovación tecnológica, simplifica la arquitectura del sistema empresarial, reduce el costo de almacenamiento de datos de series de tiempo masivas y mejora la eficiencia del almacenamiento y análisis. datos de series de tiempo.
Hoy invitamos a Xiang Yu, el líder de la comunidad openGemini, a hablar sobre su historia de código abierto~
01 Naciendo de necesidades internas y avanzando gradualmente hacia la autoinvestigación
La investigación y el desarrollo de openGemini surgieron originalmente de las propias necesidades de Huawei.
En 2019, con el establecimiento de Huawei Cloud, se construyeron centros de datos en Guangzhou, Shanghai, Beijing, Guizhou y Hong Kong, y se lanzaron más de 260 servicios en la nube. En promedio, se recopilan varios TB de datos de indicadores de monitoreo cada día. La solución original de big data se está viendo abrumada gradualmente. Cuanto mayor es la cantidad de datos, menor es la eficiencia de las consultas y el costo del almacenamiento de datos continúa aumentando. Existe una necesidad urgente de una base de datos de series temporales dedicada de alto rendimiento y alta escalabilidad.
En ese momento, no existían productos de bases de datos de series temporales útiles que pudieran mantenerse al día con el desarrollo de la demanda. InfluxDB sigue siendo una versión independiente, y Apache IoTDB y TDengine nacionales están lejos de cumplir con los requisitos de producción. Por lo tanto, Huawei está decidido a construir su propia base de datos, optimizar el procesamiento de datos y resolver problemas comerciales muy importantes en este momento. En este contexto nació openGemini.
Según Xiang Yu, en términos de selección de tecnología, inicialmente llevaron a cabo una transformación de clúster basada en el código abierto InfluxDB. Sin embargo, con el aumento del número de indicadores y el aumento de la frecuencia de recopilación, el aumento diario del volumen de datos ha alcanzado decenas de terabytes. En este momento, las fallas en la propia arquitectura de InfluxDB comenzaron a hacerse evidentes, afectando el rendimiento y la estabilidad del sistema. Por lo tanto, optaron por reconstruir la arquitectura y comenzaron el autodesarrollo del kernel openGemini.
02 Personalidad única, desempeño líder
Desde sus inicios, openGemini ha estado estrechamente vinculado a las necesidades comerciales de Huawei, por lo que cada diseño está lleno de consideraciones prácticas. Específicamente, openGemini se diferencia de otras bases de datos de series temporales en nueve "personalidades" principales:
Ventaja de rendimiento: entre la competitividad diferenciada de openGemini, el alto rendimiento es el más importante. En escenarios de datos masivos, openGemini mejora los escenarios de consultas simples en más de 2 veces, los escenarios de consultas medianas en más de 5 veces y los escenarios de consultas complejas en más de 10 veces en comparación con InfluxDB de código abierto. En comparación con otros productos similares de código abierto, openGemini también tiene ventajas obvias de rendimiento.
El rendimiento de escritura independiente anunciado oficialmente es el siguiente (la herramienta de prueba es TSBS, consulte la documentación del sitio web oficial de openGemini para obtener detalles relevantes de la prueba):

Comparación del rendimiento de consultas de una sola máquina anunciada oficialmente en escenarios de DevOps (latencia promedio, ms):

Comparación del rendimiento de consultas de una sola máquina anunciada oficialmente en escenarios de IoT (retraso promedio, ms):
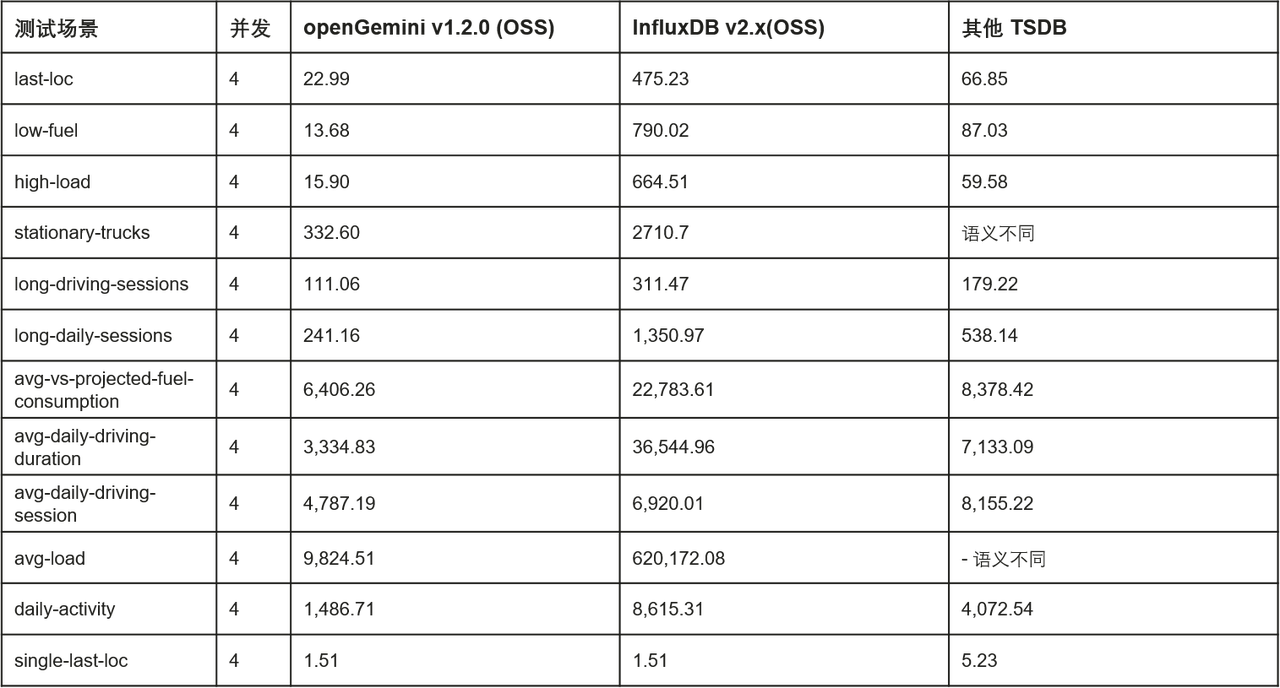
Además, openGemini ha lanzado una serie de funciones prácticas en almacenamiento y análisis de datos para construir una competitividad más diferenciada:
Arquitectura distribuida única : openGemini proporciona dos versiones: clúster independiente y distribuido. El clúster distribuido adopta la arquitectura en capas de procesamiento paralelo masivo MPP, que divide el motor informático, el motor de almacenamiento y la gestión de metadatos en componentes independientes. -store y ts-meta respectivamente. Los diferentes componentes admiten la expansión horizontal independiente, lo que permite responder de manera flexible a escenarios de aplicaciones complejos.
Motor de alta cardinalidad: el problema de la alta cardinalidad (también conocido como el desastre de la dimensionalidad) hará que el índice invertido se expanda, lo que provocará un consumo excesivo de recursos de memoria y una reducción del rendimiento de lectura y escritura. Durante mucho tiempo ha afectado el desarrollo de bases de datos de series temporales. El motor openGemini de alta raíz resuelve completamente este problema al crear un índice disperso específico de series de tiempo, que es muy adecuado para su uso en monitoreo de redes, control de riesgos financieros, Internet de las cosas, transporte y otros campos.
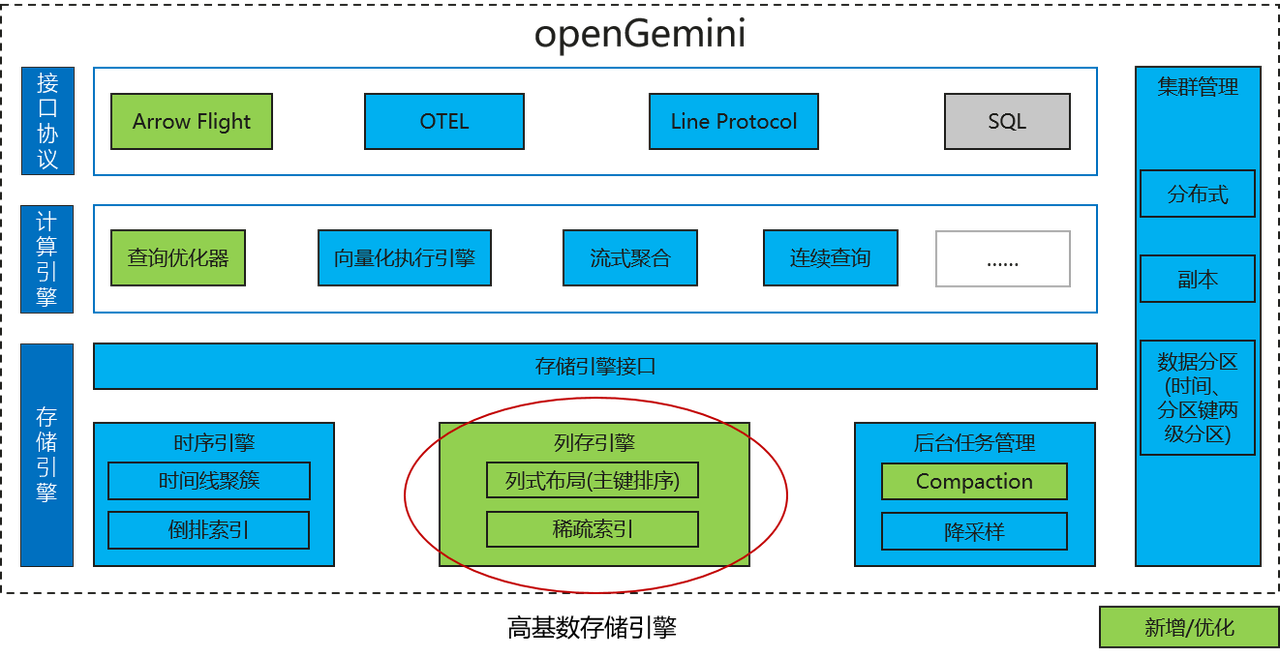
Recuperación de texto : los datos de texto son un tipo de datos común. openGemini admite la creación de índices en datos de texto, adopta un método de segmentación de palabras de aprendizaje dinámico, admite coincidencias precisas, de frases y aproximadas, y tiene un bajo uso de recursos de memoria y una alta eficiencia de recuperación.
Agregación de transmisión: la agregación de transmisión es un método de preagregación que reduce la resolución de datos mientras escribe datos. Su propósito es resolver el problema de los métodos de reducción de resolución tradicionales que leen una gran cantidad de datos históricos del disco para realizar cálculos, lo que resulta en una importante amplificación de E/S. El problema.
Reducción de resolución multinivel : para los datos históricos existentes, los métodos de reducción de resolución tradicionales conservarán los detalles de los datos históricos. En algunos escenarios, los detalles de los datos históricos no son importantes y solo es necesario conservar las características de los datos. La función de reducción de resolución de varios niveles puede extraer las características de los detalles de los datos históricos y reemplazar los detalles de los datos históricos existentes, lo que puede reducirlos aún más. el costo en un 50%.
Detección y predicción de anomalías: la detección y predicción de anomalías es actualmente una de las aplicaciones más maduras del análisis de datos de series temporales y se utiliza ampliamente en escenarios como transacciones cuantitativas, detección de seguridad de redes y mantenimiento diario de centros de datos, equipos industriales y TI. infraestructura. openGemini proporciona una biblioteca de detección de anomalías, openGemini-castor, que encapsula algoritmos de detección para 13 escenarios de anomalías comunes. Tiene las ventajas de una velocidad de detección rápida, alta precisión e integración de flujos y lotes, lo que ayuda a las aplicaciones a mejorar la eficiencia del análisis de datos.
Almacenamiento por niveles de datos fríos y calientes : admite la transferencia de datos históricos al almacenamiento de objetos, lo que permite un método de bajo costo para retener datos históricos de forma permanente y también admite el análisis fuera de línea de big data. [Está previsto que esta función se lance en el segundo semestre]
Confiabilidad de los datos : admite múltiples copias informáticas para mejorar aún más la confiabilidad de los datos. [Está previsto que esta función se lance en el segundo semestre]

03 Centrarse en la experiencia del usuario, facilitando el comienzo
openGemini no solo tiene un rendimiento sólido, sino que su diseño único también puede brindar una experiencia muy cómoda en aplicaciones reales:
En términos de introducción , openGemini es totalmente compatible con InfluxDB v1. Al mismo tiempo, openGemini utiliza el mismo protocolo de línea que InfluxDB. El modelado de datos es simple y fácil de entender, y también es amigable para los desarrolladores de bases de datos relacionales. Finalmente, openGemini utiliza un lenguaje de consulta similar a SQL, que no requiere aprendizaje adicional y es fácil de comenzar. Para la implementación de clústeres, la comunidad también proporciona la herramienta de implementación con un solo clic Gemix, que ahorra mucho trabajo de configuración.
En términos de sistemas operativos , openGemini actualmente es compatible con los principales sistemas Linux (incluido openEuler), Windows y MacOS, lo que hace que el desarrollo y la depuración de aplicaciones sean más convenientes. El procesador admite arquitecturas X86 y ARM64.
En términos de natividad de la nube , openGemini proporciona Dockerfile e imágenes de Docker, lo que admite la implementación de Docker, K8s, KubeEdge y otras plataformas. Dado que la dirección IP cambia después de reiniciar el contenedor, openGemini ha agregado una función de nombre de dominio para garantizar que los nodos del clúster aún puedan mantener la conectividad después de reiniciar el contenedor. La comunidad también ha creado el proyecto openGemini-operator para facilitar la implementación de contenedores con un solo clic de los usuarios. openGemini admite la lectura y escritura remota de Prometheus y puede usarse como almacenamiento backend para que Prometheus resuelva su problema de capacidad de almacenamiento insuficiente. [Por cierto: openGemini también admitirá directamente PromQL, que actualmente se encuentra en desarrollo]
En términos de observabilidad , la comunidad ha desarrollado el componente ts-monitor, que se especializa en recopilar indicadores de nodos y núcleos. Está dividido en 19 subcategorías y más de 260 elementos. Puede usarse con Grafana para lograr un monitoreo integral del estado operativo. de openGemini. Por ejemplo, indicadores como la utilización de CPU y memoria, ancho de banda de escritura, latencia de escritura, concurrencia de escritura y QPS se pueden ver de un vistazo a través de la interfaz visual, lo que facilita la visualización del estado operativo, el ajuste del rendimiento de la base de datos y la ubicación precisa de los problemas. en cualquier momento.
04 Después de las pruebas internas de combate reales, devuélvalo al código abierto
Como base de datos de series de tiempo, openGemini se usa actualmente con mayor frecuencia en Internet de las cosas y en el monitoreo de operación y mantenimiento. En términos de procesamiento de datos masivos, tiene ventajas que las bases de datos comunes no pueden igualar. Al mismo tiempo, openGemini, como proyecto interno de Huawei, ha pasado la prueba de "su propia gente":
Huawei Cloud SRE utiliza openGemini como base de almacenamiento de datos de monitoreo. Se implementan un total de 25 clústeres en toda la red, con un tamaño máximo de clúster de 70 nodos. Ha resistido con éxito la prueba real de 40 millones de escrituras de datos por segundo y 50.000 concurrentes. consultas. En comparación con la solución original, cuando se realiza el mismo negocio, el retraso de un extremo a otro del sistema original se reduce en un 50%, los recursos de la CPU se pueden ahorrar en un 68%, los recursos de memoria se pueden ahorrar en un 50% y el disco duro Los recursos se pueden ahorrar en más del 90%.
La plataforma industrial de IoT de Huawei Cloud ha estado utilizando la versión independiente de InfluxDB antes. Desde que cambió a openGemini, ya no tiene que preocuparse por el rendimiento. El rendimiento de las consultas y de un extremo a otro se ha triplicado. los accesos a dispositivos han aumentado al nivel de millones.
Xiang Yu presentó que openGemini se originó a partir de código abierto y se benefició mucho del proyecto de código abierto InfluxDB. Por lo tanto, siguiendo el espíritu del código abierto, todos los códigos de openGemini son de código abierto. Espera que más empresas y desarrolladores de todo el mundo se beneficien. y también espera que a través de la comunidad abierta La plataforma, junto con los desarrolladores, promueva conjuntamente la innovación tecnológica y comparta resultados de código abierto.
En la actualidad, openGemini solo tiene una versión de código abierto y un servicio en la nube. No planea involucrarse en versiones comerciales fuera de línea y está dispuesto a donar a la fundación. En la actualidad, la comunidad todavía tiene muchas imperfecciones. A continuación, la comunidad enriquecerá aún más las herramientas ecológicas de openGemini (como herramientas de migración de datos, SDK, integración ecológica de big data, etc.), interfaces de gestión visual, documentos, etc.
"En la actualidad, la planificación técnica de la comunidad generalmente se centrará en los tres escenarios de aplicación importantes de Internet de las cosas, el monitoreo y la observabilidad de operación y mantenimiento, y fortalecerá la compatibilidad ecológica y el desarrollo de capacidades centrales de las tecnologías relacionadas. Estamos comenzando a demostrar el próximo arquitectura de software de generación de openGemini", dijo Xiang Yu.
"A corto plazo, openGemini no considerará escenarios relacionados con la industria, porque los escenarios comerciales en el campo industrial son muy complejos, los requisitos en tiempo real son extremadamente altos, los fosos de los fabricantes de software industrial son muy profundos y las cosas que Las bases de datos de series de tiempo son limitadas. Además, la comunidad carece de experiencia en la industria. No sabemos lo suficiente sobre este escenario. Después de eso, consideraremos buscar algunos socios en el campo industrial, como proveedores de software industrial. proveedores, etc., para cooperar y mejorar juntos”, dijo Xiang Yu.
Página de inicio del sitio web oficial de openGemini: https://www.openGemini.org/
Dirección de código abierto de openGemini: https://github.com/openGemini
¡Compañero pollo deepin-IDE de "código abierto" y finalmente logró el arranque! Buen chico, Tencent realmente ha convertido Switch en una "máquina de aprendizaje pensante" Revisión de fallas de Tencent Cloud del 8 de abril y explicación de la situación Reconstrucción de inicio de escritorio remoto de RustDesk Cliente web Base de datos de terminal de código abierto WeChat basada en SQLite WCDB marcó el comienzo de una actualización importante Lista de abril de TIOBE: PHP cayó a un mínimo histórico, Fabrice Bellard, el padre de FFmpeg, lanzó la herramienta de compresión de audio TSAC , Google lanzó un modelo de código grande, CodeGemma , ¿te va a matar? Es tan bueno que es de código abierto: herramienta de edición de carteles e imágenes de código abierto