Directorio de artículos

Pensamientos desencadenados por la pregunta de la entrevista "¿Redis es de un solo subproceso?"
Autor: Li Le
Fuente: IT Reading Ranking
Muchas personas se han encontrado con una pregunta de este tipo en la entrevista: ¿Redis es de un solo subproceso o de varios subprocesos? Esta pregunta es a la vez simple y compleja. Se dice que es simple porque la mayoría de la gente sabe que Redis tiene un solo subproceso, y se dice que es complejo porque la respuesta en realidad es inexacta.
¿No es Redis un solo subproceso? Iniciamos una instancia de Redis y la verificamos. El método de instalación e implementación de Redis es el siguiente:
// 下载
wget https://download.redis.io/redis-stable.tar.gz
tar -xzvf redis-stable.tar.gz
// 编译安装
cd redis-stable
make
// 验证是否安装成功
./src/redis-server -v
Redis server v=7.2.4
A continuación, inicie la instancia de Redis y use el comando ps para ver todos los hilos, como se muestra a continuación:
// 启动Redis实例
./src/redis-server ./redis.conf
// 查看实例进程ID
ps aux | grep redis
root 385806 0.0 0.0 245472 11200 pts/2 Sl+ 17:32 0:00 ./src/redis-server 127.0.0.1:6379
// 查看所有线程
ps -L -p 385806
PID LWP TTY TIME CMD
385806 385806 pts/2 00:00:00 redis-server
385806 385809 pts/2 00:00:00 bio_close_file
385806 385810 pts/2 00:00:00 bio_aof
385806 385811 pts/2 00:00:00 bio_lazy_free
385806 385812 pts/2 00:00:00 jemalloc_bg_thd
385806 385813 pts/2 00:00:00 jemalloc_bg_thd
¡En realidad hay 6 hilos! ¿No se dice que Redis es de un solo subproceso? ¿Por qué hay tantos hilos?
Puede que no comprenda el significado de estos seis subprocesos, pero este ejemplo al menos muestra que Redis no tiene un solo subproceso.
01 subprocesos múltiples en Redis
A continuación, presentamos las funciones de los 6 subprocesos anteriores una por una:
1) servidor redis:
El hilo principal se utiliza para recibir y procesar solicitudes de clientes.
2)jemalloc_bg_thd
jemalloc es un asignador de memoria de nueva generación, que la capa inferior de Redis utiliza para administrar la memoria.
3)bio_xxx:
Aquellos que comienzan con el prefijo bio son todos subprocesos asincrónicos y se utilizan para realizar algunas tareas que requieren mucho tiempo de forma asincrónica. Entre ellos, el subproceso bio_close_file se usa para eliminar archivos de forma asincrónica, el subproceso bio_aof se usa para vaciar archivos AOF de forma asincrónica en el disco y el subproceso bio_lazy_free se usa para eliminar datos de forma asincrónica (eliminación diferida).
Cabe señalar que el subproceso principal distribuye tareas a subprocesos asincrónicos a través de la cola, y esta operación requiere bloqueo. La relación entre el hilo principal y el hilo asincrónico se muestra en la siguiente figura:
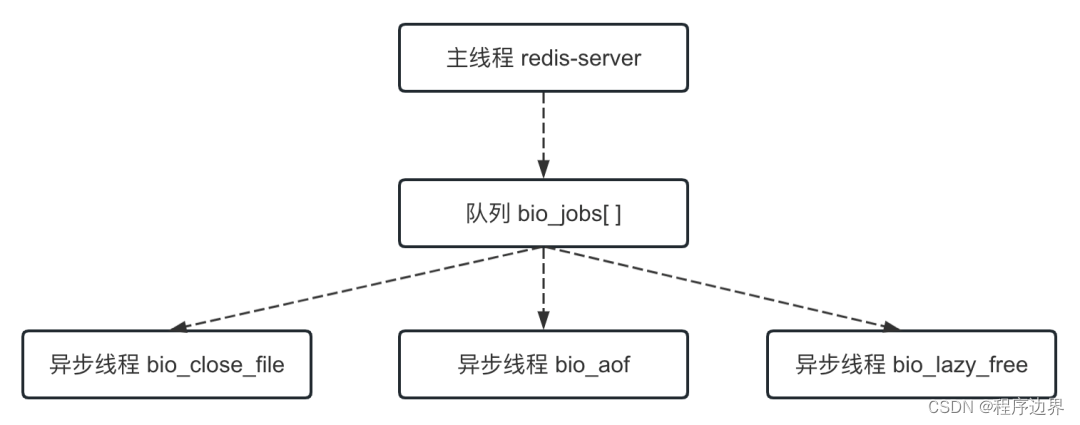
Hilo principal y hilo asíncrono Hilo principal y hilo asíncronoHilo principal y hilo asíncrono
Aquí tomamos la eliminación diferida como ejemplo para explicar por qué se debe utilizar el hilo asíncrono. Redis es una base de datos en memoria que admite múltiples tipos de datos, incluidas cadenas, listas, tablas hash, conjuntos, etc. Piénselo, ¿cuál es el proceso de eliminación de datos de tipo lista (DEL)? El primer paso es eliminar el par clave-valor del diccionario de la base de datos y el segundo paso es recorrer y eliminar todos los elementos de la lista (liberando memoria). Piense en lo que sucede si la cantidad de elementos en la lista es muy grande. Este paso llevará mucho tiempo. Este método de eliminación se llama eliminación sincrónica y el proceso es como se muestra en la siguiente figura:
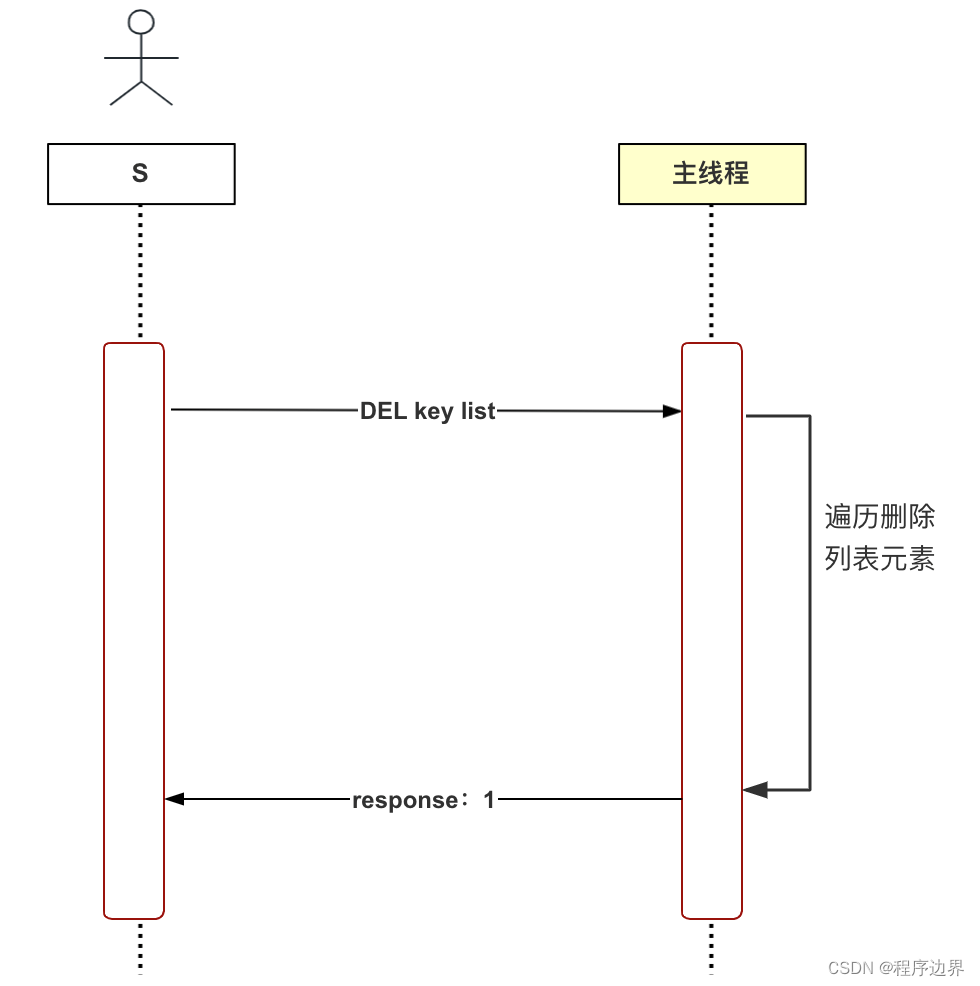
Diagrama de flujo de eliminación sincrónica Diagrama de flujo de eliminación sincrónicaDiagrama de flujo de eliminación sincrónica
En respuesta a los problemas anteriores, Redis propuso la eliminación diferida (eliminación asincrónica): cuando el hilo principal recibe el comando de eliminación (DESENLACE), primero elimina el par clave-valor del diccionario de la base de datos y luego distribuye la eliminación. tarea al hilo asincrónico bio_lazy_free, el segundo paso de la lógica que requiere mucho tiempo es ejecutado por el hilo asincrónico. El proceso en este momento se muestra a continuación:
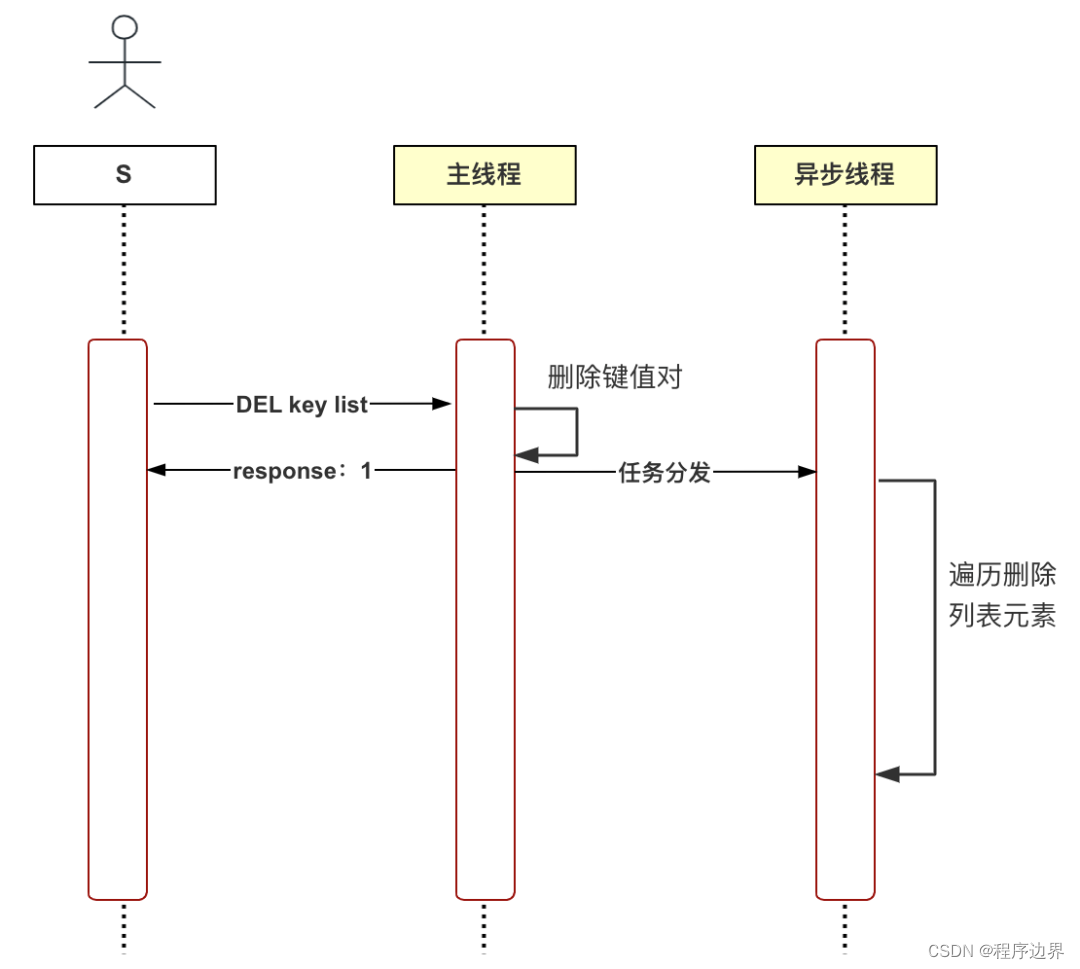
Diagrama de flujo de eliminación diferida Diagrama de flujo de eliminación diferidaDiagrama de flujo de eliminación diferida
02 E/S multiproceso
¿Redis es multiproceso? Entonces, ¿por qué siempre decimos que Redis es de un solo subproceso? Esto se debe a que la lectura de las solicitudes de comando del cliente, la ejecución de comandos y la devolución de resultados al cliente se completan en el hilo principal. De lo contrario, si varios subprocesos operan la base de datos en memoria al mismo tiempo, ¿cómo resolver el problema de concurrencia? Si un candado se bloquea antes de cada operación, ¿cuál es la diferencia entre este y un solo hilo?
Por supuesto, este proceso también ha cambiado en la versión Redis 6.0. Los funcionarios de Redis señalaron que Redis es una base de datos clave-valor basada en memoria. El proceso de ejecución de comandos es muy rápido. Lee la solicitud de comando del cliente y devuelve los resultados a el cliente (es decir, la E/S de red) generalmente se convierte en el cuello de botella de rendimiento de Redis.
Por lo tanto, en la versión Redis 6.0, el autor agregó la capacidad de E/S multiproceso, es decir, se pueden abrir múltiples subprocesos de E/S, las solicitudes de comandos del cliente se pueden leer en paralelo y los resultados se pueden devolver al cliente. en paralelo. La capacidad de subprocesos múltiples de E/S al menos duplica el rendimiento de Redis.
Para habilitar la capacidad de E/S multiproceso, primero debe modificar el archivo de configuración redis.conf:
io-threads-do-reads yes
io-threads 4
Los significados de estas dos configuraciones son los siguientes:
-
io-threads-do-reads: si se habilita la capacidad de E/S de subprocesos múltiples, el valor predeterminado es "no";
-
io-threads: el número de subprocesos de E/S, el valor predeterminado es 1, es decir, solo se utiliza el subproceso principal para realizar E/S de red y el número máximo de subprocesos es 128; esta configuración debe establecerse de acuerdo con número de núcleos de CPU. El autor recomienda configurar 2 ~ 3 para subprocesos de E/S de CPU de 4 núcleos, la CPU de 8 núcleos establece 6 subprocesos de E/S.
Después de activar la capacidad de E/S de subprocesos múltiples, reinicie la instancia de Redis y vea todos los subprocesos. Los resultados son los siguientes:
ps -L -p 104648
PID LWP TTY TIME CMD
104648 104648 pts/1 00:00:00 redis-server
104648 104654 pts/1 00:00:00 io_thd_1
104648 104655 pts/1 00:00:00 io_thd_2
104648 104656 pts/1 00:00:00 io_thd_3
……
Dado que establecemos io-threads en 4, se crearán 4 threads para realizar operaciones de E/S (incluido el thread principal). Los resultados anteriores están en línea con las expectativas.
Por supuesto, solo la fase de E / S utiliza subprocesos múltiples y el procesamiento de solicitudes de comando sigue siendo un subproceso único. Después de todo, existen problemas de concurrencia en las operaciones de datos de memoria de subprocesos múltiples.
Finalmente, después de habilitar el subproceso múltiple de E/S, el flujo de ejecución del comando es el que se muestra a continuación:
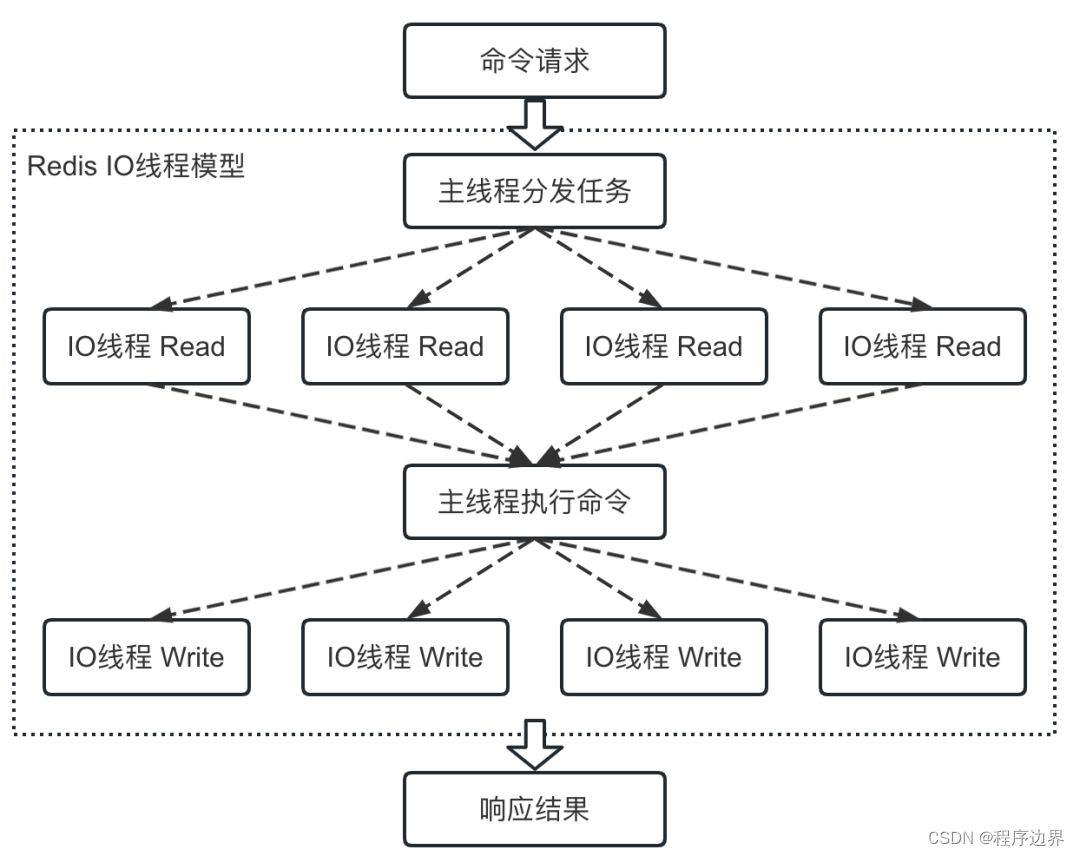
Diagrama de flujo de E/S multiproceso Diagrama de flujo de E/S multiprocesoDiagrama de flujo de subprocesos múltiples de E / S
03 Multiproceso en Redis
¿Redis tiene múltiples procesos? Sí. En algunos escenarios, Redis también creará múltiples subprocesos para realizar algunas tareas. Tomando la persistencia como ejemplo, Redis admite dos tipos de persistencia:
-
AOF (archivo solo para agregar): puede considerarse como un archivo de registro de comandos. Redis agregará cada comando de escritura al archivo AOF.
-
RDB (Redis Database): almacena datos en la memoria de Redis en forma de instantáneas. El comando GUARDAR se utiliza para activar manualmente la persistencia de RDB. Piénselo, si la cantidad de datos en Redis es muy grande, la operación de persistencia debe llevar mucho tiempo y Redis procesa las solicitudes de comando en un solo subproceso, por lo que cuando el tiempo de ejecución del comando GUARDAR es demasiado largo, inevitablemente afectará la ejecución de otros comandos.
El comando SAVE puede bloquear otras solicitudes, por esta razón Redis ha introducido el comando BGSAVE, que creará un subproceso para realizar operaciones de persistencia, de modo que no afecte al proceso principal al ejecutar otras solicitudes.
Podemos ejecutar manualmente el comando BGSAVE para verificar. Primero, use GDB para rastrear el proceso de Redis, agregar puntos de interrupción y dejar que el proceso secundario se bloquee en la lógica de persistencia. Como sigue:
// 查询Redis进程ID
ps aux | grep redis
root 448144 0.1 0.0 270060 11520 pts/1 tl+ 17:00 0:00 ./src/redis-server 127.0.0.1:6379
// GDB跟踪进程
gdb -p 448144
// 跟踪创建的子进程(默认GDB只跟踪主进程,需手动设置)
(gdb) set follow-fork-mode child
// 函数rdbSaveDb用于持久化数据快照
(gdb) b rdbSaveDb
Breakpoint 1 at 0x541a10: file rdb.c, line 1300.
(gdb) c
Después de configurar el punto de interrupción, use el cliente Redis para enviar el comando BGSAVE y los resultados son los siguientes:
// 请求立即返回
127.0.0.1:6379> bgsave
Background saving started
// GDB输出以下信息
[New process 452541]
Breakpoint 1, rdbSaveDb (...) at rdb.c:1300
Como puede ver, GDB actualmente está rastreando el proceso secundario y el ID del proceso es 452541. También puede ver todos los procesos a través del comando ps de Linux y los resultados son los siguientes:
ps aux | grep redis
root 448144 0.0 0.0 270060 11520 pts/1 Sl+ 17:00 0:00 ./src/redis-server 127.0.0.1:6379
root 452541 0.0 0.0 270064 11412 pts/1 t+ 17:19 0:00 redis-rdb-bgsave 127.0.0.1:6379
Puede ver que el nombre del proceso secundario es redis-rdb-bgsave, lo que significa que este proceso conserva instantáneas de todos los datos en archivos RDB.
Finalmente, considere dos preguntas.
- Pregunta 1: ¿Por qué utilizar un subproceso en lugar de un subproceso?
Debido a que RDB almacena instantáneas de datos de forma persistente, si se utilizan subprocesos, el subproceso principal y los subprocesos compartirán datos de la memoria y el subproceso principal también modificará los datos de la memoria mientras persiste, lo que puede provocar inconsistencia en los datos. Los datos de la memoria del proceso principal y del proceso secundario están completamente aislados y este problema no existe.
- Pregunta 2: Supongamos que se almacenan 10 GB de datos en la memoria de Redis. Después de crear un proceso hijo para realizar operaciones de persistencia, ¿el proceso hijo también necesita 10 GB de memoria en este momento? Copiar 10 GB de datos de memoria llevará mucho tiempo, ¿verdad? Además, si el sistema sólo tiene 15 GB de memoria, ¿aún se puede ejecutar el comando BGSAVE?
Aquí hay un concepto llamado copiar al escribir. Después de usar la llamada al sistema fork para crear un proceso hijo, los datos de la memoria del proceso principal y el proceso hijo se comparten temporalmente, pero cuando el proceso principal necesita modificar los datos de la memoria, el El sistema hará automáticamente una copia de este bloque de memoria para lograr el aislamiento de los datos de la memoria.
El flujo de ejecución del comando BGSAVE se muestra en la siguiente figura:
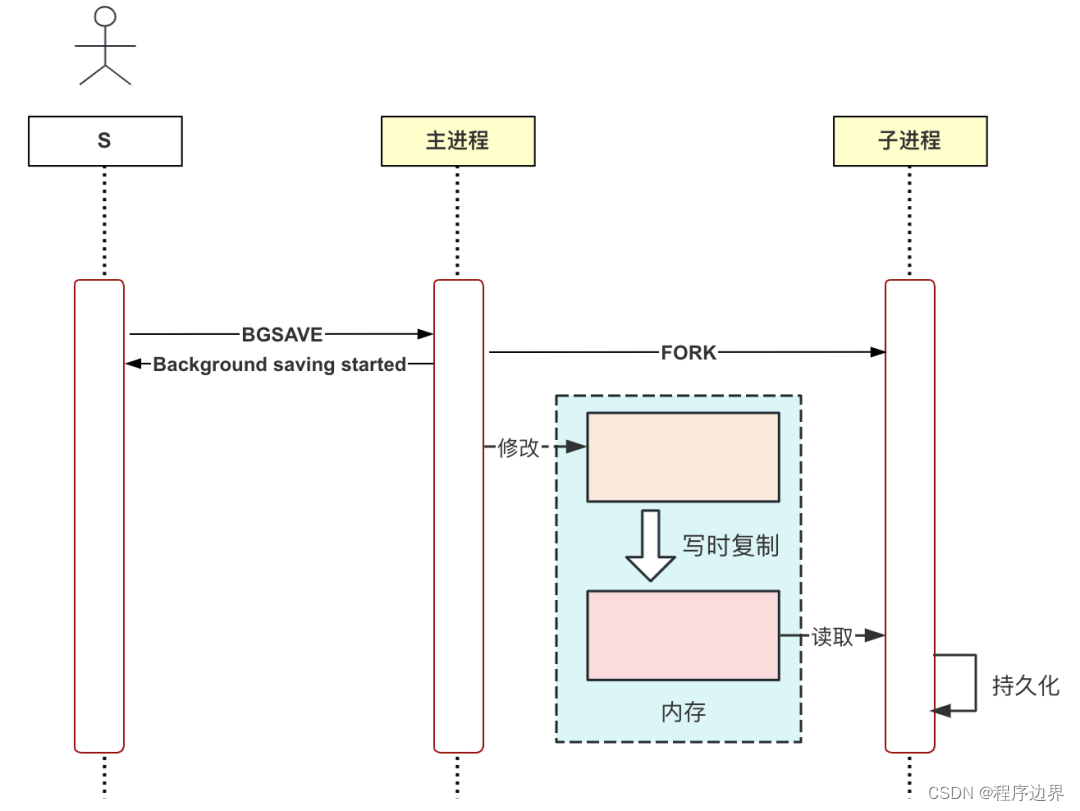
Proceso de ejecución de BGSAVE Proceso de ejecución de BGSAVEProceso de ejecución de BGS A V E
04 Conclusión
El modelo de proceso / modelo de subprocesos de Redis todavía es relativamente complejo. Aquí solo presentamos brevemente el subproceso múltiple y el procesamiento múltiple en algunos escenarios, y los propios lectores aún no han estudiado el subprocesamiento múltiple y el procesamiento múltiple en otros escenarios.
Sobre el autor
Li Le: Experto en desarrollo de Golang en TAL y máster en la Universidad de Ciencia y Tecnología Electrónica de Xi'an. Trabajó en Didi y está dispuesto a profundizar en la tecnología y el código fuente. Es coautor de "Uso eficiente de Redis: aprenda sobre almacenamiento de datos y clústeres de alta disponibilidad en un solo libro" y "Redis5" Diseño y análisis de código fuente "" Diseño subyacente de Nginx y análisis de código fuente ".
▼Lectura ampliada

"Uso eficiente de Redis: aprenda sobre almacenamiento de datos y clústeres de alta disponibilidad en un solo libro" "Uso eficiente de Redis: aprenda sobre almacenamiento de datos y clústeres de alta disponibilidad en un solo libro""Uso eficiente de Redis : aprenda sobre almacenamiento de datos y clústeres de alta disponibilidad en un solo libro "
Palabras recomendadas: profundice en la estructura de datos de Redis y la implementación subyacente, y supere los problemas del almacenamiento de datos de Redis y la gestión de clústeres.