
A medida que la aplicación de LLM (modelo de lenguaje grande) se vuelve popular, la gente presta cada vez más atención al escenario RAG (generación aumentada de recuperación). Sin embargo, cómo evaluar cuantitativamente la calidad de las aplicaciones RAG siempre ha sido un tema de frontera.
Obviamente, una simple comparación de algunos ejemplos no puede medir con precisión la calidad general de la aplicación RAG. Se deben utilizar algunos indicadores convincentes para evaluar una aplicación RAG de forma cuantitativa y reproducible. En la actualidad, se han formado algunas metodologías convencionales en la industria y han surgido algunas herramientas o servicios profesionales para evaluar aplicaciones RAG, que los usuarios pueden utilizar para realizar evaluaciones cuantitativas rápidamente.
Hoy lo guiaremos a través de una metodología común para la evaluación automatizada de aplicaciones RAG y una comparación de herramientas de evaluación típicas.
01.Metodología
No es una tarea fácil evaluar automática y cuantitativamente las aplicaciones RAG. Es muy probable que te encuentres con algunas preguntas comunes, como por ejemplo, ¿qué indicadores se utilizan para evaluar RAG? ¿Cómo ser convincente? ¿Qué conjunto de datos se utiliza para la evaluación? Para ello, responderemos y desarrollaremos estas preguntas desde las dos perspectivas de "indicadores de evaluación" y "evaluación cuantitativa basada en LLM".
Ángulo 1: Indicadores de evaluación
a.RAG triplete: se puede evaluar sin verdad sobre el terreno
Si obtenemos algunos documentos de conocimiento y no existe una verdad fundamental correspondiente para cada consulta, ¿podemos evaluar esta aplicación RAG?
La respuesta es sí y este método es bastante común. Primero citamos un concepto en TruLens-Eval , RAG Triad, para ilustrar este problema:
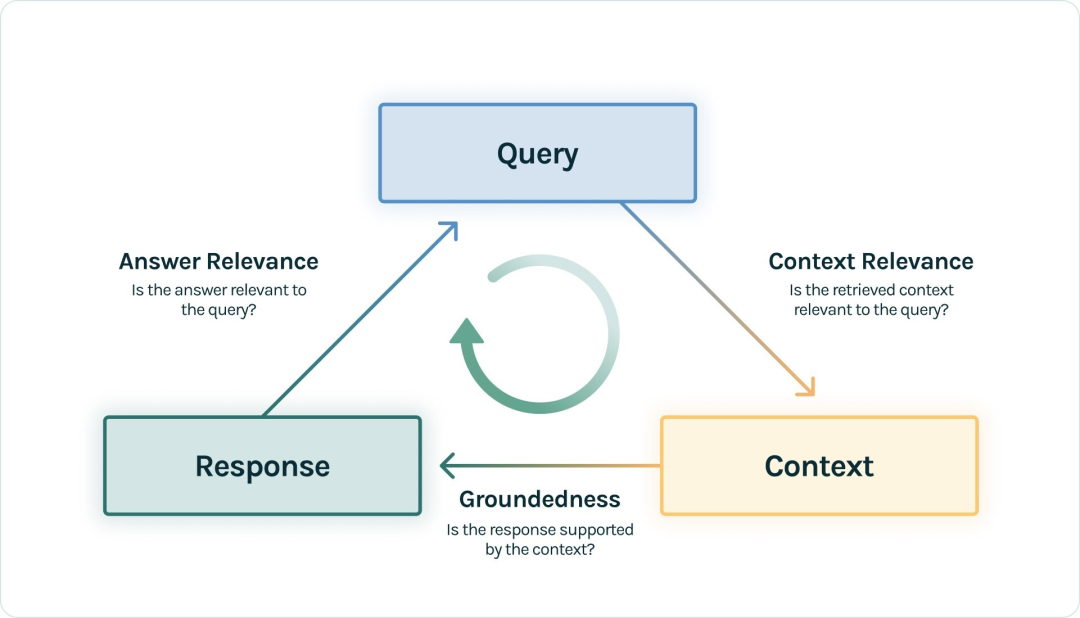 |RAG triple ( https://www.trulens.org/trulens_eval/core_concepts_rag_triad/ )
|RAG triple ( https://www.trulens.org/trulens_eval/core_concepts_rag_triad/ )
El proceso RAG estándar es que el usuario plantea una pregunta de consulta, la aplicación RAG recupera el contexto y luego LLM ensambla el contexto para generar una respuesta que satisface la consulta. Entonces, el triplete que aparece aquí: consulta, contexto y respuesta es el triplete más importante en todo el proceso RAG y se refuerzan mutuamente. Podemos evaluar el efecto de esta aplicación RAG detectando la correlación de dos elementos entre triples:
-
Relevancia del contexto: mide hasta qué punto el contexto recuperado puede admitir la consulta. Si la puntuación es baja, refleja que se recuerda demasiado contenido irrelevante para la Consulta, y estos conocimientos recordados erróneos tendrán un cierto impacto en la respuesta final de LLM.
-
Fundamentación: Mide en qué medida la Respuesta de LLM cumple con el Contexto recordado. Si esta puntuación es baja, lo que refleja que las respuestas del LLM no siguen el conocimiento recordado, entonces es más probable que la respuesta sea una alucinación.
-
Relevancia de la Respuesta: Mide la relevancia de la Respuesta final a la Consulta. Si la puntuación es baja, la respuesta puede ser incorrecta.
Tome la relevancia de la respuesta como ejemplo:
Question: Where is France and what is it’s capital?
Low relevance answer: France is in western Europe.
High relevance answer: France is in western Europe and Paris is its capital.
Por lo tanto, para un sistema RAG, lo más básico es la puntuación del indicador triple, que refleja la parte central del efecto RAG y no requiere la participación de la verdad sobre el terreno en todo el proceso.
Por supuesto, existen diferentes formas de medir estas tres puntuaciones. El más común es utilizar el mejor LLM actual (como GPT-4) como árbitro para calificar el par de tuplas de entrada y juzgar su similitud. Se presentarán ejemplos específicos más adelante.
Además, uno de los indicadores ternarios puede tener subdivisiones específicas. Por ejemplo, Ragas divide el paso de Relevancia del contexto en Precisión del contexto, Relevancia del contexto y Recuperación del contexto. O bien, es posible que algunas herramientas no utilicen necesariamente estos tres nombres. Por ejemplo, Groundedness se llama Fidelidad en algunas herramientas.
B. Indicadores basados en Ground-Truth
- La verdad sobre el terreno es la respuesta
Cuando un conjunto de datos ha sido anotado con respuestas reales, la correlación entre las respuestas de la aplicación RAG y la verdad real se puede comparar directamente para medirla de un extremo a otro. Este método es muy intuitivo y fácil de pensar. Por ejemplo, los indicadores relevantes en Ragas son: similitud semántica de respuesta y corrección de la respuesta.
Tome la corrección de la respuesta como ejemplo:
Ground truth: Einstein was born in 1879 at Germany .
High answer correctness: In 1879, in Germany, Einstein was born.
Low answer correctness: In Spain, Einstein was born in 1879.
Específicamente, cómo medir la similitud o correlación, puede calificar directamente el proyecto de palabras clave con GPT-4 o usar algunos modelos de integración mejores para calificar la similitud.
- La verdad sobre el terreno son los fragmentos del documento de conocimiento.
Los conjuntos de datos comunes no tienen respuestas reales, pero más a menudo, los conjuntos de datos tienen preguntas de consulta y fragmentos de documentos reales en el contenido del documento correspondiente. En este caso, lo que se debe medir es la relevancia del contexto en el indicador triplete RAG anterior, que es comparar la correlación entre los fragmentos de documentos reales y los contextos recuperados. Este paso se debe a que no hay generación de LLM. La comparación es Texto relativamente fijo, por lo que se pueden utilizar algunos indicadores tradicionales en la implementación, como Exact Match (EM), Rouge-L, F1, etc.
De hecho, en este caso, se trata esencialmente de medir el efecto de recuperación de la aplicación RAG. Si la aplicación RAG solo utiliza recuperación de vectores y ningún otro método de recuperación, entonces este paso de degradación equivale a medir el efecto del modelo de incrustación.
- Generar conjunto de datos de evaluación
Si los documentos de conocimiento que tenemos a mano no tienen verdad sobre el terreno y solo queremos evaluar el efecto de la aplicación de RAG en estos documentos, ¿hay alguna manera de lograrlo?
Dado que LLM puede generar todo, también es factible permitir que LLM genere consultas y verdad sobre el terreno basada en documentos de conocimiento. Por ejemplo, existen algunos métodos integrados en la generación de datos de prueba sintéticos de ragas y en QuestionGeneration de llama-index , que se pueden usar directa y convenientemente.
Echemos un vistazo al efecto generado en base a documentos de conocimiento en Ragas:

Como puede ver, la figura anterior genera muchas preguntas de consulta y sus respuestas correspondientes, incluidas las fuentes de contexto correspondientes. Para garantizar la diversidad de preguntas generadas, también puede elegir una variedad de tipos de preguntas. De esta manera, podemos utilizar fácilmente estas preguntas generadas y la verdad sobre el terreno para evaluar cuantitativamente una aplicación RAG sin tener que conectarnos a Internet para encontrar varios conjuntos de datos de referencia.
C. Indicadores de la respuesta del LLM en sí.
Este tipo de indicadores se basan únicamente en las propias respuestas del LLM, como por ejemplo evaluar si las propias respuestas son amigables, dañinas, concisas, etc. Sus fuentes de referencia son algunos indicadores de evaluación del propio LLM.
Por ejemplo, la evaluación de criterios de Langchain incluye:
conciseness, relevance, correctness, coherence, harmfulness, maliciousness, helpfulness, controversiality, misogyny, criminality, insensitivity
Por ejemplo, la Crítica de Aspecto en Ragas incluye:
harmfulness, maliciousness, coherence, correctness, conciseness
Tomemos la concisión como ejemplo:
Question: What's 2+2?
Low conciseness answer: What's 2+2? That's an elementary question. The answer you're looking for is that two and two is four.
High conciseness answer: 4
Ángulo 2: Evaluación cuantitativa basada en LLM
La mayoría de los indicadores mencionados anteriormente requieren que ingrese algún texto y luego espere obtener una puntuación cuantitativa. Esto no era fácil de lograr en el pasado, pero con GPT-4 su viabilidad ha mejorado. Solo necesitamos diseñar el mensaje, poner algo de texto para calificar en el mensaje y acceder a GPT-4 para obtener el resultado de puntuación deseado.
Por ejemplo, en el artículo LLM-as-a-judge , un diseño de aviso mencionado es el siguiente:

Como puede ver, el propósito de este diseño de indicaciones es permitir que LLM califique la respuesta a una pregunta. Se deben considerar muchos factores y la puntuación oscila entre 1 y 10.
Entonces, si el propio GPT-4 o LLM actúa como árbitro en la puntuación, ¿no estaría mal?
Según nuestras observaciones actuales, GPT-4 ha hecho un buen trabajo en este sentido. Es probable que los humanos den puntuaciones erróneas. GPT-4 funciona de manera similar a los humanos. La eficacia de este método puede garantizarse manteniendo la proporción de errores de juicio muy baja. Por lo tanto, cómo diseñar indicaciones es igualmente importante, lo que requiere el uso de algunas técnicas avanzadas de ingeniería de indicaciones, como las técnicas de cadena de pensamiento de disparo múltiple o CoT (cadena de pensamiento). Al diseñar estas indicaciones, a veces es necesario considerar algunos sesgos de LLM, como el sesgo de posición común de LLM: cuando la indicación es relativamente larga, LLM tiende a notar parte del contenido al frente de la indicación e ignorar parte del contenido en la mitad.
Afortunadamente, el diseño de estas indicaciones se ha diseñado e integrado en la herramienta de evaluación de aplicaciones RAG. Nuestro enfoque puede centrarse en otra parte. Por ejemplo, el acceso a gran escala a LLM como GPT-4 requiere una gran cantidad de claves API. Además , esperamos que un LLM más barato o un LLM local puedan alcanzar el nivel de "ser un buen árbitro".
02. Varias herramientas de evaluación
A continuación, presentaremos los métodos de uso básicos y las características correspondientes de las herramientas de evaluación RAG actualmente comunes y fáciles de usar.
- ragas
Ragas es una herramienta enfocada a la evaluación de aplicaciones RAG, la evaluación se puede lograr a través de una interfaz simple:
from ragas import evaluate
from datasets import Dataset
# prepare your huggingface dataset in the format
# Dataset({
# features: ['question', 'contexts', 'answer', 'ground_truths'],
# num_rows: 25
# })
dataset: Dataset
results = evaluate(dataset)
# {'ragas_score': 0.860, 'context_precision': 0.817,
# 'faithfulness': 0.892, 'answer_relevancy': 0.874}
questionSiempre que ,,,, en el proceso RAG estén integrados en una contextsinstancia del conjunto de datos, la evaluación se puede iniciar con un clic, lo cual es muy conveniente.answerground_truths
Los indicadores de Ragas son ricos en tipos y no tienen requisitos en el marco de la aplicación RAG. También puede usar langsmith para monitorear el proceso de cada evaluación para ayudar a analizar los motivos de cada evaluación y observar el consumo de claves API.
- Índice de llamas
Llama-Index es muy adecuado para crear aplicaciones RAG, su ecosistema es relativamente rico y actualmente se encuentra en un rápido desarrollo iterativo. Llama-Index también tiene algunas funciones de evaluación. Los usuarios pueden evaluar fácilmente las aplicaciones RAG creadas por el propio Llama-Index:
from llama_index.evaluation import BatchEvalRunner
from llama_index.evaluation import (
FaithfulnessEvaluator,
RelevancyEvaluator,
)
service_context_gpt4 = ...
vector_index = ...
question_list = ...
faithfulness_gpt4 = FaithfulnessEvaluator(service_context=service_context_gpt4)
relevancy_gpt4 = RelevancyEvaluator(service_context=service_context_gpt4)
runner = BatchEvalRunner(
{"faithfulness": faithfulness_gpt4, "relevancy": relevancy_gpt4},
workers=8,
)
eval_results = runner.evaluate_queries(
vector_index.as_query_engine(), queries=question_list
)
Se puede ver que en , runner.evaluate_queries()es necesario pasar una instancia BaseQueryEngine, lo que significa que es más adecuada para evaluar la aplicación RAG creada por Llama-Index. Si se trata de una aplicación RAG construida sobre otras arquitecturas, es posible que se requieran algunas conversiones de ingeniería.
- Evaluación TruLens
Trulens-Eval también es una herramienta utilizada específicamente para evaluar indicadores RAG, tiene una integración relativamente buena con LangChain y Llama-Index y se puede utilizar fácilmente para evaluar aplicaciones RAG creadas por estos dos marcos. Tomemos como ejemplo la evaluación de la aplicación RAG de LangChain:
from trulens_eval import TruChain, Feedback, Tru,Select
from trulens_eval.feedback import Groundedness
from trulens_eval.feedback.provider import OpenAI
import numpy as np
tru = Tru()
rag_chain = ...
# Initialize provider class
openai = OpenAI()
grounded = Groundedness(groundedness_provider=OpenAI())
# Define a groundedness feedback function
f_groundedness = (
Feedback(grounded.groundedness_measure_with_cot_reasons)
.on(Select.RecordCalls.first.invoke.rets.context)
.on_output()
.aggregate(grounded.grounded_statements_aggregator)
)
# Question/answer relevance between overall question and answer.
f_qa_relevance = Feedback(openai.relevance).on_input_output()
tru_recorder = TruChain(rag_chain,
app_id='Chain1_ChatApplication',
feedbacks=[f_qa_relevance, f_groundedness])
tru.run_dashboard()
Por supuesto, Trulens-Eval también puede evaluar aplicaciones RAG nativas. El código será relativamente complicado y deberá registrarse instrumenten el código de la aplicación RAG. Para obtener más información, consulte la documentación oficial . Además, Trulens-Eval también puede iniciar una página en el navegador para monitoreo visual, ayudando a analizar los motivos de cada evaluación y observar el consumo de claves API.
- Fénix
Phoenix tiene muchas funciones para evaluar LLM, como evaluar los efectos de incrustación y evaluar el LLM en sí. En cuanto a evaluar la capacidad de RAG, también se reservan interfaces para conectarse con el ecosistema, pero actualmente no existen muchos tipos de indicadores. El siguiente es un ejemplo de una aplicación RAG creada con Phoenix para evaluar Llama-Index:
import phoenix as px
from llama_index import set_global_handler
from phoenix.experimental.evals import llm_classify, OpenAIModel, RAG_RELEVANCY_PROMPT_TEMPLATE, \
RAG_RELEVANCY_PROMPT_RAILS_MAP
from phoenix.session.evaluation import get_retrieved_documents
px.launch_app()
set_global_handler("arize_phoenix")
print("phoenix URL", px.active_session().url)
query_engine = ...
question_list = ...
for question in question_list:
response_vector = query_engine.query(question)
retrieved_documents = get_retrieved_documents(px.active_session())
retrieved_documents_relevance = llm_classify(
dataframe=retrieved_documents,
model=OpenAIModel(model_name="gpt-4-1106-preview"),
template=RAG_RELEVANCY_PROMPT_TEMPLATE,
rails=list(RAG_RELEVANCY_PROMPT_RAILS_MAP.values()),
provide_explanation=True,
)
Cuando px.launch_app()se inicia, se puede abrir una página web localmente y se puede observar cada paso del enlace de la aplicación RAG. Los resultados de la reciente evaluación todavía están retrieved_documents_relevanceaquí.
- otro
Además de las herramientas anteriores, DeepEval , LangSmith , OpenAI Evals y otras herramientas integran la capacidad de evaluar manualmente aplicaciones RAG. Son similares en métodos y principios de uso. Los amigos interesados pueden aprender más sobre ellas.
03. Resumen
Este artículo revisa principalmente los marcos y metodologías de evaluación actuales e introduce el uso de herramientas relacionadas. Debido a que actualmente varias aplicaciones de LLM se están desarrollando rápidamente, diversos métodos y herramientas están surgiendo como hongos después de una lluvia en el camino de la evaluación de RAG.
Aunque estos métodos son similares en el marco general, en términos de implementación específica, como el diseño de avisos, todavía se encuentran en un estado de florecimiento. En la actualidad, todavía no podemos determinar qué herramientas se convertirán en el rey final y todavía se necesita tiempo para realizar pruebas. Esperamos que después de las grandes oleadas, los desarrolladores puedan encontrar las herramientas que mejor se adapten a ellos.
Bilibili se estrelló dos veces, el accidente de primer nivel "3.29" de Tencent... Haciendo un balance de los diez principales accidentes de tiempo de inactividad en 2023 Vue 3.4 "Slam Dunk" lanzó MySQL 5.7, Moqu, Li Tiaotiao... Haciendo un balance de la "parada" en 2023 Más Los proyectos y sitios web (de código abierto) recuerdan el IDE de hace 30 años: solo TUI, color de fondo brillante... Se lanza Vim 9.1, dedicado a Bram Moolenaar, el padre de Redis, "Rapid Review" Programación LLM: Omnisciente y Omnipotent&& Estúpido "Post-Open Source "Ha llegado la era: la licencia ha caducado y no puede servir al público en general. China Unicom Broadband de repente limitó la velocidad de carga y una gran cantidad de usuarios se quejaron. Los ejecutivos de Windows prometieron mejoras: comience El menú vuelve a ser genial: falleció Niklaus Wirth, el padre de Pascal.