Forschung zum Lern- und Empfehlungsalgorithmus für die Darstellung heterogener Graphen basierend auf einem graphischen neuronalen Netzwerk
Verzeichnisaufbau
GNN-Recommendation/
gnnrec/ 算法模块顶级包
hge/ 异构图表示学习模块
kgrec/ 基于图神经网络的推荐算法模块
data/ 数据集目录(已添加.gitignore)
model/ 模型保存目录(已添加.gitignore)
img/ 图片目录
academic_graph/ Django项目模块
rank/ Django应用
manage.py Django管理脚本
Abhängigkeiten installieren
Python 3.7
CUDA 11.0
pip install -r requirements_cuda.txt
CPU
pip install -r requirements.txt
Lernen der Darstellung heterogener Graphen (Anhang)
Beziehungsbewusstes heterogenes graphisches neuronales Netzwerk mit kontrastivem Lernen (RHCO), basierend auf kontrastivem Lernen
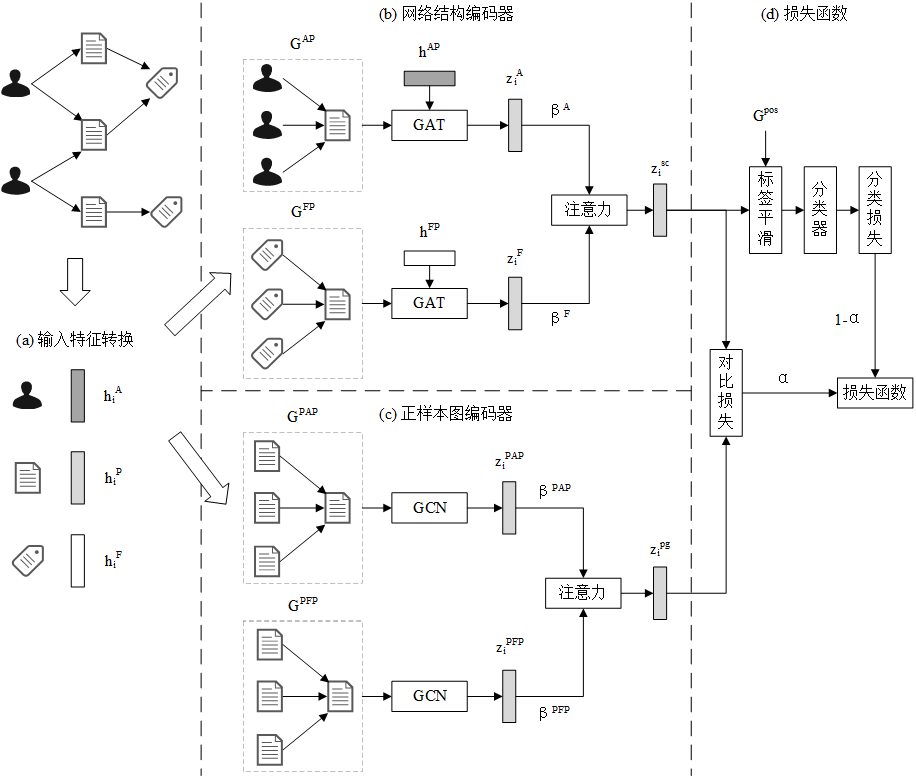
Experiment
Siehe Readme
Empfehlungsalgorithmus basierend auf einem graphischen neuronalen Netzwerk (Anhang)
Auf einem grafischen neuronalen Netzwerk basierender akademischer Empfehlungsalgorithmus (GARec)

Experiment
Siehe Readme
Django-Konfiguration
MySQL-Datenbankkonfiguration
- Datenbank und Benutzer erstellen
CREATE DATABASE academic_graph CHARACTER SET utf8mb4;
CREATE USER 'academic_graph'@'%' IDENTIFIED BY 'password';
GRANT ALL ON academic_graph.* TO 'academic_graph'@'%';
- Erstellen Sie die Datei .mylogin.cnf im Stammverzeichnis
[client]
host = x.x.x.x
port = 3306
user = username
password = password
database = database
default-character-set = utf8mb4
- Erstellen Sie eine Datenbanktabelle
python manage.py makemigrations --settings=academic_graph.settings.prod rank
python manage.py migrate --settings=academic_graph.settings.prod
- Oag-cs-Datensatz importieren
python manage.py loadoagcs --settings=academic_graph.settings.prod
Hinweis: Da der einmalige Import sehr lange dauert (ca. 9 Stunden), können Sie zur Vermeidung von Fehlern während des Vorgangs zunächst die Testdaten in data/oag/test zum Debuggen verwenden.
Statische Dateien kopieren
python manage.py collectstatic --settings=academic_graph.settings.prod
Starten Sie den Webserver
export SECRET_KEY=xxx
python manage.py runserver --settings=academic_graph.settings.prod 0.0.0.0:8000
System-Screenshot
Suche nach Papieren
Papierdetails
Suche nach Wissenschaftlern
Details zum Gelehrten

Anhang
Empfehlungsalgorithmus basierend auf einem graphischen neuronalen Netzwerk
Datensatz
oag-cs – Ein akademisches Netzwerk im Computerbereich, das unter Verwendung akademischer Daten von OAG Microsoft aufgebaut wurde (siehe Readme )
Vorab trainierte Scheitelpunkteinbettungen
Verwenden Sie metapath2vec (Random Walk + Word2vec), um Scheitelpunkteinbettungen als Scheitelpunkteingabemerkmale des GNN-Modells vorab zu trainieren
- zielloser Spaziergang
python -m gnnrec.kgrec.random_walk model/word2vec/oag_cs_corpus.txt
- Wortvektoren trainieren
python -m gnnrec.hge.metapath2vec.train_word2vec --size=128 --workers=8 model/word2vec/oag_cs_corpus.txt model/word2vec/oag_cs.model
abrufen
Verwenden Sie das fein abgestimmte SciBERT-Modell (siehe Schritt 2 der Readme-Datei ), um die Abfragewörter in Vektoren zu kodieren, die Kosinusähnlichkeit mit dem vorberechneten Papiertitelvektor zu berechnen und Top-k zu ermitteln
python -m gnnrec.kgrec.recall
Beispiel für Rückrufergebnisse:
Graphisches neuronales Netzwerk
0.9629 Aggregation Graph Neural Networks
0.9579 Neural Graph Learning: Training Neural Networks Using Graphs
0.9556 Heterogeneous Graph Neural Network
0.9552 Neural Graph Machines: Learning Neural Networks Using Graphs
0.9490 On the choice of graph neural network architectures
0.9474 Measuring and Improving the Use of Graph Information in Graph Neural Networks
0.9362 Challenging the generalization capabilities of Graph Neural Networks for network modeling
0.9295 Strategies for Pre-training Graph Neural Networks
0.9142 Supervised Neural Network Models for Processing Graphs
0.9112 Geometrically Principled Connections in Graph Neural Networks
Empfehlungsalgorithmus basierend auf Wissensgraphen
0.9172 Research on Video Recommendation Algorithm Based on Knowledge Reasoning of Knowledge Graph
0.8972 An Improved Recommendation Algorithm in Knowledge Network
0.8558 A personalized recommendation algorithm based on interest graph
0.8431 An Improved Recommendation Algorithm Based on Graph Model
0.8334 The Research of Recommendation Algorithm based on Complete Tripartite Graph Model
0.8220 Recommendation Algorithm based on Link Prediction and Domain Knowledge in Retail Transactions
0.8167 Recommendation Algorithm Based on Graph-Model Considering User Background Information
0.8034 A Tripartite Graph Recommendation Algorithm Based on Item Information and User Preference
0.7774 Improvement of TF-IDF Algorithm Based on Knowledge Graph
0.7770 Graph Searching Algorithms for Semantic-Social Recommendation
Begriffsklärung unter Gelehrten
0.9690 Scholar search-oriented author disambiguation
0.9040 Author name disambiguation in scientific collaboration and mobility cases
0.8901 Exploring author name disambiguation on PubMed-scale
0.8852 Author Name Disambiguation in Heterogeneous Academic Networks
0.8797 KDD Cup 2013: author disambiguation
0.8796 A survey of author name disambiguation techniques: 2010–2016
0.8721 Who is Who: Name Disambiguation in Large-Scale Scientific Literature
0.8660 Use of ResearchGate and Google CSE for author name disambiguation
0.8643 Automatic Methods for Disambiguating Author Names in Bibliographic Data Repositories
0.8641 A brief survey of automatic methods for author name disambiguation
Gutes Rudern
Konstruieren Sie die Grundwahrheit
(1) Validierungssatz
Erfassen Sie die 100 besten Wissenschaftler in 20 Teilbereichen der künstlichen Intelligenz aus der von AMiner veröffentlichten AI 2000-Liste der weltweit einflussreichsten Wissenschaftler auf dem Gebiet der künstlichen Intelligenz
pip install scrapy>=2.3.0
cd gnnrec/kgrec/data/preprocess
scrapy runspider ai2000_crawler.py -a save_path=/home/zzy/GNN-Recommendation/data/rank/ai2000.json
Vergleichen Sie die Gelehrten des oag-cs-Datensatzes mit den Gelehrten und bestätigen Sie manuell einige Gelehrte mit höheren Rankings, die jedoch nicht übereinstimmen, wie im Grundwahrheitsüberprüfungssatz für das Gelehrtenranking
export DJANGO_SETTINGS_MODULE=academic_graph.settings.common
export SECRET_KEY=xxx
python -m gnnrec.kgrec.data.preprocess.build_author_rank build-val
(2) Trainingsset
Unter Bezugnahme auf die Berechnungsformel von AI 2000 wird die Rangliste der Wissenschaftler auf der Grundlage der gewichteten Summe der Anzahl der Zitationen von Arbeiten in einem bestimmten Bereich erstellt, die als Basis-Truth-Trainingssatz verwendet wird.
Berechnungsformel:
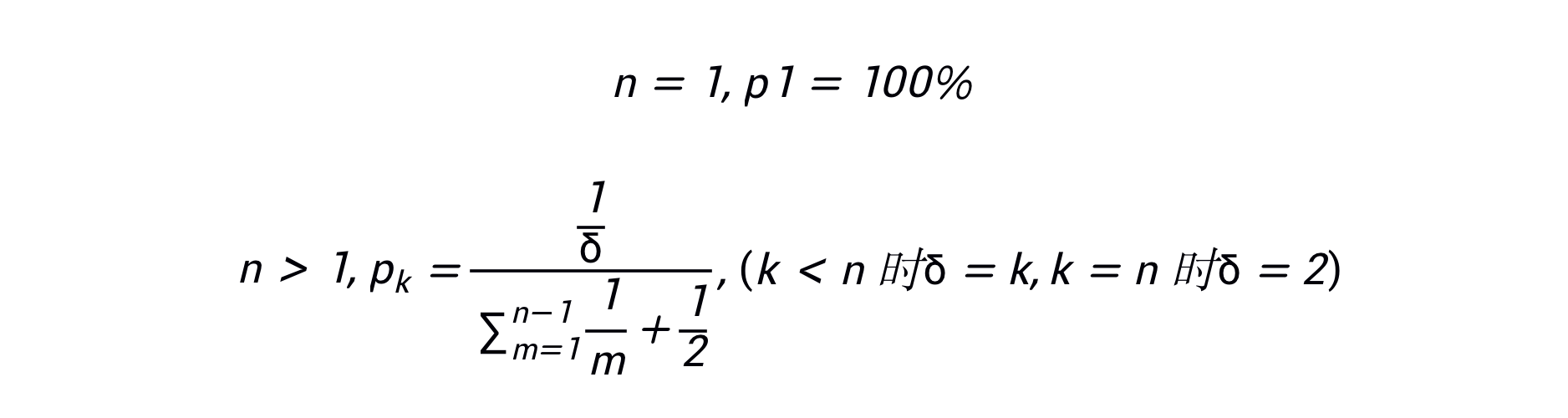
Das heißt: Unter der Annahme, dass ein Artikel n Autoren hat, beträgt das Gewicht des k-ten Autors 1/k, der letzte wird als korrespondierender Autor betrachtet und das Gewicht beträgt 1/2. Nach der Normalisierung beträgt die gewichtete Summe der Anzahl Die Anzahl der Zitate der Arbeit wird berechnet.
python -m gnnrec.kgrec.data.preprocess.build_author_rank