
С момента своего выпуска в конце 2022 года ChatGPT внес огромные изменения в области исследований и бизнеса в области искусственного интеллекта. Благодаря обучению с подкреплением, контролируемой точной настройке и обратной связи с человеком модели могут отвечать на человеческие вопросы и следовать инструкциям в широком спектре задач. После этого успеха интерес к LLM продолжал расти: в научных кругах и промышленности появились новые LLM, включая множество стартапов, ориентированных на LLM.
Хотя LLM с закрытым исходным кодом (например, GPT от OpenAI, Claude от Anthropic) в целом лучше, чем соответствующая модель с открытым исходным кодом, последняя добилась быстрого прогресса и утверждает, что обеспечивает эквивалентную или даже лучшую производительность, чем ChatGPT, при выполнении некоторых задач. Это не только оказывает глубокое влияние на исследование больших языковых моделей, но также имеет исключительную коммерческую ценность. В первую годовщину выпуска ChatGPT эта статья призвана предоставить всесторонний обзор успеха LLM с открытым исходным кодом и всесторонне исследовать задачи, которые, по утверждениям LLM с открытым исходным кодом, достигли или превысили уровень ChatGPT.
Примечание. Последняя версия этой статьи была обновлена 5 декабря и не включает недавно выпущенную первую большую модель MoE с открытым исходным кодом Mixtral (8x7B), которая, как утверждается, достигла или даже превзошла уровень LLaMA2 (70B) и GPT-. 3.5. (Следующий контент составлен и опубликован OneFlow. Пожалуйста, свяжитесь с нами для получения разрешения на перепечатку. Исходный текст: https://arxiv.org/pdf/2311.16989.pdf)
Автор | Хайлинь Чен, Фанкай Цзяо и др.
Компиляция OneFlow
Перевод|Вань Цзилинь, Ян Тин
1
введение
Год назад OpenAI выпустила ChatGPT, который быстро покорил сообщество искусственного интеллекта и весь мир. Это первый чат-бот на базе приложения, который может давать полезные, безопасные и подробные ответы на большинство вопросов, следовать инструкциям и даже признавать и исправлять предыдущие ошибки. Примечательно, что он превосходно справляется с задачами на естественном языке, которые обычно выполняются языковыми моделями, которые предварительно обучаются, а затем настраиваются индивидуально, например, обобщение или ответы на вопросы.
Будучи первым в своем роде приложением в своей области, ChatGPT привлек широкое внимание, привлекая 100 миллионов пользователей в течение двух месяцев после запуска, что намного быстрее, чем рост других популярных приложений, таких как TikTok или YouTube. [1] Поскольку ChatGPT может снизить затраты на рабочую силу, автоматизировать рабочие процессы и даже предоставить клиентам новые впечатления (Cheng et al., 2023), он также привлек огромные инвестиции.
Однако ChatGPT не является открытым исходным кодом, а контролируется частной компанией, поэтому большинство технических деталей остаются неизвестными. Хотя OpenAI утверждает, что следует процедурам, представленным в InstructGPT (также известном как GPT-3.5) (Ouyang et al., 2022b), его точная архитектура, данные предварительного обучения и данные тонкой настройки неизвестны. Закрытый исходный код приводит к нескольким ключевым проблемам.
Во-первых, поскольку мы не понимаем внутренних деталей процедур предварительного обучения и тонкой настройки, особенно когда известно, что LLM привык создавать вредный, неэтичный и недостоверный контент, нам трудно точно оценить потенциальные риски ChatGPT обществу. Во-вторых, сообщалось, что производительность ChatGPT со временем меняется, что затрудняет воспроизводимость результатов (Chen et al., 2023). В-третьих, в ChatGPT произошло несколько сбоев, причем два крупных сбоя произошли только в ноябре 2023 года, во время которых доступ к веб-сайту ChatGPT и его API был полностью заблокирован. В-четвертых, компании, которые используют ChatGPT, могут беспокоиться о высокой стоимости вызовов API, перебоях в обслуживании, владении данными, конфиденциальности и других проблемах, а также о других чрезвычайных ситуациях, таких как недавнее увольнение генерального директора Сэма Альтмана, сотрудники, вынуждающие совет директоров, и возможное возвращение Сэма. Корпоративная драма в зале заседаний.
С другой стороны, большие модели на языке с открытым исходным кодом потенциально компенсируют или обходят большинство ранее описанных проблем и, таким образом, открывают многообещающее направление. По этой причине исследовательское сообщество активно продвигает поддержание высокопроизводительной LLM в среде с открытым исходным кодом. Однако по состоянию на конец 2023 года широко распространено мнение, что LLM с открытым исходным кодом, такие как LLaMa-2 (Touvron et al., 2023) или Falcon (Almazrouei et al., 2023), отстают от соответствующих моделей с закрытым исходным кодом, таких как GPT3 OpenAI. .5 (ChatGPT) и GPT-4 (OpenAI, 2023b), Claude 2 от Anthropic или Bard 3 от Google, из которых GPT-4 обычно считается лучшей моделью с закрытым исходным кодом. Однако приятно видеть, что разрыв между моделями с открытым и закрытым исходным кодом постепенно сокращается, и LLM с открытым исходным кодом быстро догоняет его.
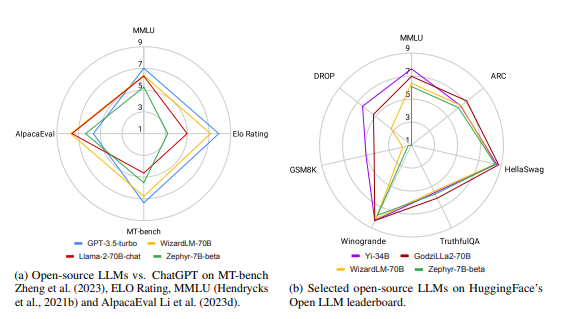
Рисунок 1: Обзор различных программ LLM по различным общим критериям.
Фактически, как показано на рисунке 1, лучший LLM с открытым исходным кодом показал лучшую производительность, чем GPT-3.5-turbo, в некоторых стандартных тестах. Однако это непростая задача для LLM с открытым исходным кодом. Ситуация продолжает развиваться: LLM с закрытым исходным кодом регулярно переучиваются на новых данных для обновлений, а LLM с открытым исходным кодом не отстают и постоянно выпускают новые версии. В настоящее время наборы данных и критерии оценки LLM сложны и разнообразны, что затрудняет выбор лучшего LLM.
Целью этой статьи является объединение недавних исследований LLM с открытым исходным кодом и предоставление обзора того, как они конкурируют или даже превосходят ChatGPT в различных областях. Наш вклад в основном включает в себя следующие три аспекта:
• Интегрировать различные оценки LLM с открытым исходным кодом и предоставить объективную и всестороннюю перспективу сравнения LLM с открытым исходным кодом и ChatGPT (см. Рисунок 1, Раздел 3.1).
• Систематически исследовались LLM с открытым исходным кодом, которые соответствуют или превосходят ChatGPT по производительности в различных задачах, и проводился соответствующий анализ (см. Рисунок 2, Раздел 3, Раздел 4.2). Мы также поддерживаем действующую веб-страницу для отслеживания последних обновлений моделей. [4]
• Проанализировать тенденцию развития LLM с открытым исходным кодом (раздел 4.1), передовой опыт обучения LLM с открытым исходным кодом (раздел 4.3) и возможные проблемы LLM с открытым исходным кодом (раздел 4.4).
Кому может быть полезен этот отчет? Это исследование направлено на то, чтобы помочь научным кругам и промышленности понять текущую ситуацию и будущий потенциал LLM с открытым исходным кодом. Для исследователей эта статья представляет собой тщательный обзор текущего прогресса и меняющихся тенденций в области LLM с открытым исходным кодом, указывая перспективные направления для будущих исследований. Для коммерческого сектора этот опрос предоставляет ценную информацию и рекомендации, которые помогут лицам, принимающим решения, оценить пригодность и преимущества внедрения LLM с открытым исходным кодом.
Далее мы сначала представим базовые концепции (раздел 2), затем предоставим углубленное исследование LLM с открытым исходным кодом, которые превосходят ChatGPT в различных областях (раздел 3), затем обсудим идеи и проблемы, связанные с LLM с открытым исходным кодом (раздел 4), и наконец, сделайте вывод (раздел 5).
2
фон
В этом разделе кратко описаны основные концепции, связанные с LLM.
2.1 Режим обучения
Предварительное обучение: все LLM полагаются на крупномасштабное предварительное обучение с самоконтролем на текстовых данных Интернета (Radford et al., 2018; Brown et al., 2020). LLM только для декодера следует цели моделирования причинного языка, то есть модель учится предсказывать следующий токен с учетом последовательности предыдущих токенов (Bengio et al., 2000). Согласно данным предварительного обучения, предоставленным LLM с открытым исходным кодом (Touvron et al., 2023a), источники текстовых данных включают CommonCrawl5, C4 (Raffel et al., 2020), GitHub, Wikipedia, книги, а также онлайн-обсуждения и обмен контентом, например как Reddit или StackOverFlow. Известно, что увеличение размера корпуса предварительного обучения может улучшить производительность модели и дополняет увеличение размера модели.Этот феномен называется законом масштабирования и подробно анализируется в (Hoffmann et al., 2022a). Сегодня размер корпуса предварительного обучения LLM может достигать от сотен миллиардов до триллионов слов (Touvron et al., 2023b; Penedo et al., 2023).
Точная настройка [8] : цель состоит в том, чтобы адаптировать предварительно обученный LLM к последующей задаче путем обновления весов с использованием существующей контрольной информации, которая обычно представляет собой набор данных, который на несколько порядков меньше, чем набор данных, используемый для предварительной настройки. обучение (Девлин и др., 2018). T5 (Raffel et al., 2020) — одна из первых моделей, включающая тонкую настройку в унифицированную структуру преобразования текста в текст, где каждая задача описывается инструкциями на естественном языке.
Тонкая настройка инструкций: позже объем тонкой настройки был расширен за счет обучения нескольким задачам (Wei et al., 2021a; Aribandi et al., 2021), где каждая задача описывается инструкциями на естественном языке. Управляемая точная настройка быстро завоевала популярность благодаря своей способности значительно улучшить производительность LLM с нулевым результатом, включая производительность при выполнении новых задач, не замеченных во время обучения.
Точная настройка стандартных инструкций и многозадачная контролируемая точная настройка (часто называемая SFT ) все еще могут не привести к созданию моделей, которые соответствуют намерениям человека, безопасны, этичны и безвредны, и могут быть дополнительно улучшены посредством обучения с подкреплением с участием человека. обратная связь ( RLHF ) (Ouyang et al., 2022b): Аннотаторы-люди оценивают выходные данные точно настроенной модели, а затем снова используется обучение с подкреплением для точной настройки модели (Ouyang et al., 2022b). Недавние исследования показали, что человеческая обратная связь может быть заменена обратной связью от LLM, процессом, называемым обучением с подкреплением на основе обратной связи ИИ ( RLAIF ) (Bai et al., 2022b). Прямая оптимизация предпочтений ( DPO ) обходит необходимость в RLHF соответствовать модели вознаграждения человеческим предпочтениям и напрямую использует цель перекрестной энтропии для точной настройки политики, тем самым более эффективно согласовывая LLM с человеческими предпочтениями.
В некоторых исследованиях при создании наборов данных для точной настройки многозадачных инструкций основное внимание уделяется качеству, а не количеству: Лима (Zhou et al., 2023a) использует только 1000 примеров для точной настройки Llama-65B, и результаты превосходят GPT-3, в то время как Alpagasus (Chen et al., 2023c) улучшил производительность Alpaca (Taori et al., 2023) за счет очистки набора данных для точной настройки инструкций, уменьшив количество примеров с 52 000 до 9 000.
Непрерывное предварительное обучение: относится к еще одному раунду предварительного обучения на предварительно обученной большой модели языка (LLM), обычно с использованием меньшего объема данных, чем на первом этапе. Этот процесс можно использовать для быстрой адаптации к новым областям или внедрения новых функций LLM. Например, непрерывное предварительное обучение используется в Lemur (Xu et al., 2023d) для улучшения возможностей кодирования и вывода, а в Llama-2-long (Xiong et al., 2023) для расширения контекстного окна.
Обоснование: Существует несколько альтернатив генерации последовательностей с использованием LLM для авторегрессионного декодирования, которые отличаются степенью случайности и разнообразием выходных данных. Увеличение параметра температуры во время процесса выборки может сделать выходные данные более разнообразными, а установка температуры на 0 возвращает к жадному декодированию, что может быть необходимо, когда требуется детерминированный выходной сигнал. Методы выборки top-k (Fan et al., 2018) и top-p (Holtzman et al., 2019) ограничивают пул токенов, доступных для выборки на каждом этапе декодирования.
Существует несколько методов, используемых для повышения скорости вывода, особенно при более длинных последовательностях, что становится трудноразрешимым из-за квадратичного роста сложности внимания с длиной входных данных. FlashAttention (Дао и др., 2022) ускоряет обучение и вывод за счет оптимизации операций чтения/записи между уровнями памяти графического процессора. FlashDecoding (Dao et al., 2023) параллельно загружает кэш ключ-значение (KV) в механизме внимания, увеличивая сквозную скорость до 8 раз. Спекулятивное декодирование (Leviathan et al., 2023; Chen et al., 2023b) использует дополнительную модель малого языка для аппроксимации распределения следующего токена из LLM, тем самым сохраняя производительность и одновременно ускоряя декодирование. vLLM (Kwon et al., 2023) использует алгоритм PagedAttention, который оптимизирует использование ключа внимания и памяти, чтобы ускорить вывод и обслуживание LLM.
2.2 Области задач и оценка
Правильная оценка возможностей LLM остается активной областью исследований из-за необходимости проведения разнообразных и обширных оценок. Наборы данных с ответами на вопросы (Joshi et al., 2017; Kwiatkowski et al., 2019; Lin et al., 2022) являются очень популярными критериями оценки, но недавно появились новые критерии, специально предназначенные для оценки LLM (Dubois et al., 2023). ; Бичинг и др., 2023; Чжэн и др., 2023).
3
LLM с открытым исходным кодом против ChatGPT
В главах мы рассмотрим возможности LLM в шести основных областях: возможности обобщения, возможности агентов, логические рассуждения (включая математические возможности и возможности кодирования), длинное текстовое моделирование, конкретные приложения (например, вопросы и ответы или обобщение) и надежность. Из-за ограниченного объема содержания заинтересованные читатели могут подробно прочитать раздел 3 оригинальной статьи (https://arxiv.org/pdf/2311.16989.pdf). Важные выводы этого раздела изложены в разделе 4.
4
обсуждать
4.1 Тенденции развития LLM
С тех пор как Браун и др. (2020) продемонстрировали, что модель GPT-3 может обеспечить потрясающую производительность при выполнении различных задач с нулевым и малым количеством шагов, люди начали вкладывать много энергии в разработку и продвижение больших языковых моделей (LLM). ). Одно из направлений исследований направлено на расширение шкалы параметров модели, включая Gopher (Rae et al., 2021), GLaM (Du et al., 2022), LaMDA (Thoppilan et al., 2022), MT-NLG (Smith et al., 2022), MT-NLG (Smith et al., 2022). al., 2022) et al., 2022) и PaLM (Chowdhery et al., 2022), при этом окончательный размер модели достигает 540 миллиардов параметров. Хотя эти модели демонстрируют отличные возможности, они представляют собой модели с закрытым исходным кодом, что ограничивает их широкое применение, поэтому люди постепенно становятся все более заинтересованными в разработке LLM с открытым исходным кодом (Zhang et al., 2022; Workshop et al., 2022). ).
Вместо масштабирования модели другое направление исследований изучает более эффективные стратегии или цели для предварительного обучения более мелких моделей, таких как Шиншилла (Hoffmann et al., 2022b) и UL2 (Tay et al., 2022). В дополнение к предварительному обучению люди также стремятся изучить точную настройку языковых моделей, таких как FLAN (Wei et al., 2021b), T0 (Sanh et al., 2021) и Flan-T5 (Chung et al., 2021b) и Flan-T5 (Chung et al., 2021b). др., 2022).
Год назад OpenAI запустила ChatGPT, который существенно изменил фокус исследований сообщества обработки естественного языка (NLP) (Qin et al., 2023a). Чтобы догнать OpenAI, Google и Anthropic запустили Bard и Claude соответственно. Хотя их производительность во многих задачах сравнима с ChatGPT, все же существует разрыв в производительности с последней моделью OpenAI GPT-4 (OpenAI, 2023b). Поскольку успех этих моделей в основном обусловлен обучением с подкреплением и обратной связью с человеком (RLHF) (Schulman et al., 2017b; Ouyang et al., 2022a), исследователи изучили различные улучшения RLHF (Yuan et al., 2023; Rafailov et al., 2023a). др., 2023), People, 2023б; Lee et al., 2023б).
Чтобы продвигать исследования больших моделей языков с открытым исходным кодом, Meta выпустила серию моделей LLaMA (Touvron et al., 2023a, b). С тех пор быстро появились модели с открытым исходным кодом, основанные на LLaMA. Одним из репрезентативных направлений исследований является использование данных инструкций для точной настройки LLaMA, включая Alpaca (Taori et al., 2023), Vicuna (Chiang et al., 2023), Lima (Zhou et al., 2023b) и WizardLM ( Сюй и др., 2023а). Текущие исследования также изучают агенты, которые улучшают LLM с открытым исходным кодом на основе LLaMA (Xu et al., 2023d; Zeng et al., 2023; Patil et al., 2023; Qin et al., 2023b), логических рассуждений (Roziere et al. , 2023; Luo et al., 2023a,c) и возможности долгоконтекстного моделирования (Tworkowski et al., 2023; Xiong et al., 2023; Xu et al., 2023b). Кроме того, вместо разработки LLM на основе LLaMA многие работы посвящены обучению с нуля мощных LLM, таких как MPT (Team, 2023), Falcon (Almazrouei et al., 2023), XGen (Nijkamp et al., 2023). , Phi (Gunasekar et al., 2023; Li et al., 2023e), Baichuan (Yang et al., 2023a), Mistral (Jiang et al., 2023a), Grok (xAI, 2023) и Yi (01ai, 2023). Мы считаем, что разработка более мощного и эффективного LLM с открытым исходным кодом для популяризации возможностей LLM с закрытым исходным кодом является многообещающим будущим направлением исследований.
4.2 Резюме
По общим возможностям Llama-2-chat-70B (Touvron et al., 2023b) превосходит GPT-3.5-turbo в некоторых тестах, но все же отстает в большинстве других задач. Благодаря четкой оптимизации прямых предпочтений Zephir-7B (Tunstall et al., 2023) приближается к производительности 70B LLM. WizardLM-70B (Xu et al., 2023a) и GodziLLa-70B (Филиппины, 2023 г.) способны достичь производительности, сравнимой с GPT-3.5-turbo, что указывает на то, что это многообещающее направление исследований.
В некоторых областях LLM с открытым исходным кодом превосходит GPT-3.5-turbo. Для агентов на основе LLM LLM с открытым исходным кодом может превзойти GPT-3.5-turbo в некоторых задачах за счет более обширной и конкретной предварительной подготовки и тонкой настройки. Например, Lemur-70B-chat (Xu et al., 2023d) лучше справляется с исследованием окружающей среды и отслеживанием обратной связи при выполнении задач кодирования. AgentTuning (Zeng et al., 2023) позволяет улучшить выполнение неизвестных задач агента.
ToolLLama (Qin et al., 2023b) позволяет лучше использовать инструменты. Gorilla (Patil et al., 2023) лучше пишет вызовы API, чем GPT-4.
Что касается логического рассуждения, WizardCoder (Luo et al., 2023c) и WizardMath (Luo et al., 2023a) улучшают возможности рассуждения за счет улучшенной точной настройки инструкций. Лемур (Xu et al., 2023d) и Phi (Gunasekar et al., 2023; Li et al., 2023e) достигли более высоких способностей благодаря предварительному обучению на данных более высокого качества.
Для моделирования длинного контекста Llama-2-long (Xiong et al., 2023) использует более длинные токены и большее контекстное окно для предварительного обучения, что приводит к повышению производительности в выбранных тестах. Сюй и др. (2023b) улучшили производительность семи длинных контекстных задач, объединив расширение контекстного окна с интерполяцией позиции и улучшением поиска. Что касается возможностей конкретного приложения, InstructRetro (Wang et al., 2023a) добился улучшения производительности при ответе на открытые вопросы за счет предварительного обучения с использованием поиска и точной настройки инструкций. Благодаря тонкой настройке для конкретных задач MentaLlama-chat-13B (Yang et al., 2023c) превосходит производительность GPT-3.5-turbo на наборах данных анализа психического здоровья. Radiology-Llama2 (Liu et al., 2023) может улучшить качество радиологических отчетов. Stru-Bench (Tang et al., 2023b) — это тонко настроенная модель 7B, которая улучшает генерацию структурированных ответов по сравнению с GPT-3.5-turbo, основной возможностью, поддерживающей задачи агента. Shepherd (Wang et al., 2023c) имеет только 7B параметров и способен достичь эквивалентной или лучшей производительности, чем GPT-3.5-turbo, при формировании обратной связи и оценки модели. Для заслуживающего доверия ИИ галлюцинации можно уменьшить за счет использования более качественных данных точной настройки (Lee et al., 2023a), методов контекстно-зависимого декодирования (Dhuliawala et al., 2023) и расширения внешних знаний, таких как Li et al. (2023c), Ю и др. (2023b), Пэн и др. (2023), Фэн и др. (2023), или многоагентный диалог (Коэн и др., 2023; Ду и др., 2023).
В таких областях, как безопасность искусственного интеллекта, GPT-3.5-турбо и GPT-4 по-прежнему непревзойденны. Поскольку модели GPT включают крупномасштабные RLHF (Bai et al., 2022a), обычно считается, что они ведут себя более безопасно и более этично. Это может быть более важно для коммерческих LLM, чем для LLM с открытым исходным кодом. Однако с демократизацией процесса RLHF (Бай и др., 2022b; Рафаилов и др., 2023a) LLM с открытым исходным кодом позволит добиться большего повышения производительности с точки зрения безопасности.
4.3 Секреты лучшего LLM с открытым исходным кодом
Обучение больших языковых моделей включает в себя сложные методы и требует большого количества ресурсов, включая сбор данных, предварительную обработку, разработку моделей и обучение. Несмотря на растущее количество программ LLM с открытым исходным кодом, к сожалению, подробные практики ведущих моделей часто держатся в секрете. Вот некоторые лучшие практики, признанные сообществом.
Данные: предварительное обучение предполагает использование триллионов токенов данных из общедоступных источников. С этической точки зрения крайне важно удалить все данные, содержащие личную информацию (Touvron et al., 2023b). В отличие от данных предварительного обучения, данные точной настройки меньше по количеству, но более высокого качества. LLM, точно настроенные с использованием высококачественных данных, показали лучшую эффективность в конкретных областях (Филиппины, 2023; Zeng et al., 2023; Xu et al., 2023d, a).
Архитектура модели. Хотя большинство LLM используют архитектуру Transformer, состоящую только из декодера, они также используют различные методы для оптимизации эффективности. Лама-2 использует внимание призраков для улучшения управления многоходовым диалогом (Touvron et al., 2023b). Mistral (Jiang et al., 2023b) использует внимание скользящего окна для обработки контекстов увеличенной длины.
Обучение. Процесс контролируемой точной настройки (SFT) с использованием данных точной настройки инструкций имеет решающее значение. Для получения высококачественных результатов требуются десятки тысяч SFT-аннотаций, например, Llama-2 использует 27540 аннотаций (Touvron et al., 2023b). Разнообразие и качество данных имеют решающее значение (Xu et al., 2023a). На этапе RLHF алгоритм оптимизации проксимальной политики (PPO) (Schulman et al., 2017a) часто отдается предпочтение для лучшего согласования поведения модели с человеческими предпочтениями и инструкциями, поэтому оптимизация проксимальной политики играет решающую роль в повышении безопасности LLM. Альтернативой PPO является оптимизация прямых предпочтений (DPO) (Рафаилов и др., 2023а). Например, Zephyr-7B (Tunstall et al., 2023) использует дистиллированный DPO и показывает производительность, сравнимую с 70B-LLM в различных общих тестах, даже превосходя GPT-3.5-turbo на AlpacaEval.
4.4 Уязвимости и потенциальные проблемы
Загрязнение данных во время предварительного обучения. Эта проблема становится все более заметной, особенно после выпуска базовых моделей без общедоступных источников корпуса предварительного обучения. Отсутствие прозрачности может предвзято относиться к истинным возможностям обобщения больших языковых моделей (LLM). Помимо того, что контрольные данные аннотируются экспертами или более крупными моделями и вручную интегрируются в обучающий набор, основная причина проблемы загрязнения данных заключается в том, что источник сбора контрольных данных был включен в корпус предварительного обучения. Хотя эти модели намеренно не обучаются с использованием контролируемых данных, они все равно могут получить точные знания. Поэтому крайне важно решить проблему обнаружения корпусов предварительного обучения LLM (Shi et al., 2023), изучить совпадение существующих тестов и широко используемых корпусов предварительного обучения и оценить переоснащение тестов (Wei et al. , 2023). Это имеет решающее значение для повышения лояльности и надежности LLM. В дальнейшем будущие направления могут включать в себя создание стандартизированных методов раскрытия подробностей корпусов предварительного обучения и разработку методов уменьшения загрязнения данных на протяжении всего жизненного цикла разработки модели.
Разработка согласования с закрытым исходным кодом. В сообществе все большее внимание уделяется приложениям RLHF, использующим общие данные о предпочтениях для согласования. Однако из-за нехватки высококачественных общедоступных наборов данных о предпочтениях и предварительно обученных моделей вознаграждения только несколько LLM с открытым исходным кодом применили RLHF с улучшенным согласованием. Несколько инициатив (Bai et al., 2022a; Wu et al., 2023; Cui et al., 2023) были предложены в попытке внести свой вклад в сообщество открытого исходного кода. Однако мы по-прежнему сталкиваемся с проблемой нехватки разнообразных, высококачественных и масштабируемых данных о предпочтениях в сложных сценариях рассуждений, программирования и безопасности.
Трудности в постоянном улучшении базовых возможностей моделей: Прорывы в базовых возможностях, описанные в этой статье, раскрывают некоторые сложные проблемы: (1) Во время предварительного обучения значительные усилия были вложены в изучение улучшенных комбинаций данных для улучшения построения более мощных моделей. надежность базовой модели. Однако стоимость этой попытки высока и нереалистична для практического применения. (2) Модели, превосходящие GPT-3.5-turbo или GPT-4 по производительности, в основном использующие знания из моделей с закрытым исходным кодом и дополнительные экспертные аннотации. Несмотря на свою эффективность, чрезмерная зависимость этого подхода от дистилляции знаний может скрыть проблемы, которые могут возникнуть при распространении этих методов на модели учителей.
Кроме того, люди ожидают, что LLM будет действовать как агент и предоставлять разумные объяснения для поддержки принятия решений. По сути, оптимизация посредством дистилляции знаний или экспертных аннотаций сама по себе не может постоянно улучшать базовые возможности LLM и, скорее всего, приблизится к верхнему пределу. Будущие направления исследований могут включать изучение новых методологий, таких как парадигмы обучения без присмотра или самоконтроля, для достижения дальнейшего прогресса в базовых возможностях LLM, одновременно смягчая связанные с этим проблемы и затраты.
5
Подведем итог
В этом отчете мы систематически рассматриваем высокопроизводительные LLM с открытым исходным кодом, которые превосходят или догоняют ChatGPT в различных задачах через год после его выпуска (раздел 3). Кроме того, мы предоставляем углубленное понимание и анализ больших моделей языков с открытым исходным кодом и исследуем потенциальные проблемы (раздел 4). Мы считаем, что этот опрос поможет изучить будущее направление развития LLM с открытым исходным кодом и будет стимулировать дальнейшие исследования и разработки в этой области, помогая преодолеть разрыв между моделями с открытым и закрытым исходным кодом.
DeepCache и OneDiff ускоряют итерации SDXL в 3 раза
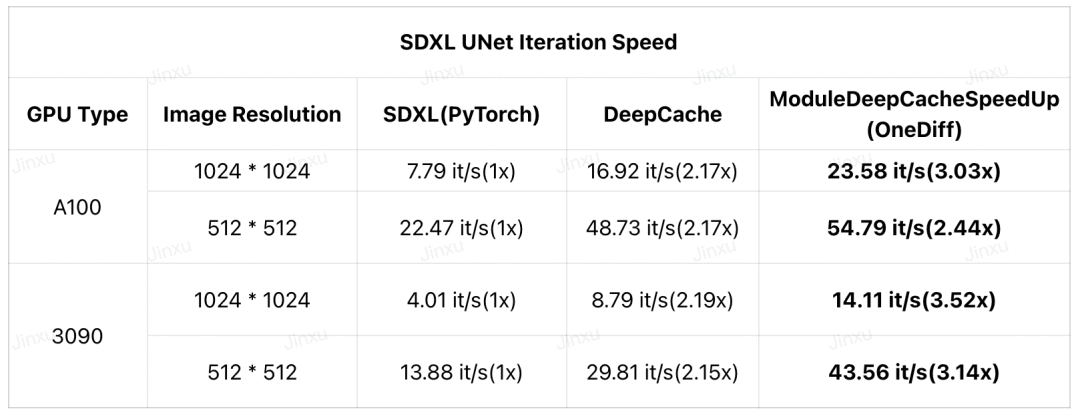
Недавно DeepCache предлагает новую парадигму ускорения диффузионных моделей, не требующую обучения и почти без потерь. Теперь OneDiff представил новый узел ComfyUI (скомпилированный модуль DeepCache) под названием ModuleDeepCacheSpeedup , который увеличивает скорость итерации SDXL в 3,5 раза на RTX 3090 и в 3 раза на A100 .
Пример : https://github.com/Oneflow-Inc/onediff/pull/426.
Руководство по использованию : https://github.com/Oneflow-Inc/onediff/tree/main/onediff_comfy_nodes#installation-guide.
Все остальные смотрят
-
Практические советы по тонкой настройке больших языковых моделей с помощью LoRA
-
Опыт и уроки, извлеченные из крупномасштабных сервисов ChatGPT
-
Десять лет аппаратного обеспечения машинного обучения: изменения производительности и тенденции
-
История эволюции больших моделей на языке с открытым исходным кодом: в ногу с LLaMA 2
-
Руководство по распределенному обучению и эффективной настройке больших языковых моделей
-
На пути к 100-кратному ускорению: полнофункциональная оптимизация вывода Transformer
Источник OneFlow: github.com/Oneflow-Inc/oneflow/ ![]() http://github.com/Oneflow-Inc/oneflow/
http://github.com/Oneflow-Inc/oneflow/