0. Zusammenfassung
Die schwach überwachte semantische Segmentierung (WSSS) auf Bildebene ist eine grundlegende und anspruchsvolle Computer-Vision-Aufgabe, die zum Szenenverständnis und zum autonomen Fahren beiträgt. Die meisten existierenden Methoden nutzen klassifizierungsbasierte Klassenaktivierungskarten (Class Activation Maps, CAMs) als anfängliche Pseudoetiketten, aber diese Methoden konzentrieren sich oft auf diskriminierende Bildbereiche und es fehlen angepasste Funktionen für Segmentierungsaufgaben. Um dieses Problem zu lindern, schlagen wir ein neuartiges Schema zur Aktivierungsregulierung und Neukalibrierung (AMR) vor, das den Spotlight-Zweig und den Kompensationszweig nutzt, um gewichtete CAMs zu erhalten und eine Neukalibrierungsüberwachung und aufgabenspezifische Konzepte bereitzustellen. Insbesondere verwenden wir ein Aufmerksamkeitsmodulationsmodul (AMM), um die Verteilung der Merkmalsbedeutung aus der Perspektive der Kanal-räumlichen Reihenfolge neu zu verteilen und so dazu beizutragen, Abhängigkeiten zwischen Kanälen und räumliche Kodierung explizit zu modellieren, um Aktivierungsreaktionen für die Segmentierung adaptiv zu modulieren. Darüber hinaus führen wir eine zweizweigübergreifende Pseudoüberwachung ein, die als semantische Ähnlichkeitsregularisierung zur gegenseitigen Verbesserung der beiden Zweige angesehen werden kann. Umfangreiche Experimente zeigen, dass AMR beim PASCAL VOC 2012-Datensatz eine Leistung auf dem neuesten Stand der Technik erzielt und nicht nur aktuelle Methoden mit Überwachungstraining auf Bildebene übertrifft, sondern auch einige Methoden übertrifft, die auf einer stärkeren Überwachung beruhen, wie z. B. Auffälligkeitsetiketten. Experimente beweisen, dass unser Schema Plug-and-Play-fähig ist und mit anderen Methoden kombiniert werden kann, um seine Leistung zu verbessern. Unser Code ist unter folgendem Link verfügbar:https://github.com/jieqin-ai/AMR
1. Einleitung
Die semantische Segmentierung ist aufgrund ihrer weit verbreiteten Verwendung in vielen Anwendungen eine grundlegende und kritische Aufgabe im Bereich Computer Vision. Ziel ist es, Vorhersagen auf Pixelebene von Bildern zu treffen und Bildteile zusammenzufassen, die zur gleichen Objektkategorie gehören. Obwohl in unterschiedlichem Ausmaß einige Fortschritte erzielt wurden, wurden die meisten der jüngsten Erfolge in vollständig überwachten Umgebungen erzielt (Chen et al., 2017, 2018). Das Erhalten solch feiner Anmerkungen auf Pixelebene bleibt eine schwierige Aufgabe, die einen erheblichen manuellen Aufwand erfordert. Um diese teuren und langwierigen Anmerkungen zu erleichtern, tendieren viele Studien dazu, schwache Überwachungsmethoden anzuwenden (Wu et al., 2020, 2021), wie etwa Bounding-Box-Überwachung (Dai, He und Sun, 2015), Graffiti-Überwachung (Lin et al. , 2016 Jahre), Punktüberwachung (Bearman et al., 2016) und Bildebenenüberwachung (Chang et al., 2020; Ahn und Kwak, 2018). Die schwache Überwachung auf Bildebene ist ein sehr vorteilhaftes Schema, da solche groben Anmerkungen mit der tatsächlichen Situation übereinstimmen und solche schwachen Bezeichnungen in der Praxis leichter zu erhalten sind. In unserer Arbeit konzentrieren wir uns auf das schwache Supervisionsparadigma auf Bildebene.
Frühere Methoden der schwach überwachten semantischen Segmentierung (WSSS) auf Bildebene (Lee et al., 2019; Singh und Lee, 2017; Wang et al., 2020b; Choe, Lee und Shim, 2020) verwenden meist Klassifizierungsnetzwerke, um Klassenaktivierung zu generieren Karten (CAMs) (Zhou et al., 2016) als anfängliche Pseudo-Labels für die Segmentierung. Dieses CAM ist jedoch für die Klassifizierung konzipiert und verfügt nicht über eine individuelle Optimierung der Segmentierungsmerkmale. Das heißt, der Klassifikator scheint nur die am stärksten diskriminierenden Bereiche hervorzuheben, und daher decken die erhaltenen CAM-Seeds nur einen Teil des Zielobjekts ab, der mit dem Spotlight-CAM übereinstimmt, wie in Abbildung 1 dargestellt. Um dieses Problem zu lösen, versuchen einige Methoden, den Bereich der diskriminierenden Reaktion zu erweitern und den anfänglichen CAM-Seed zu verbessern. SEAM (Wang et al., 2020b) fügt eine Äquivarianz-Regularisierung für verschiedene transformierte Bilder hinzu, um mehr Startregionen zu erhalten. In ähnlicher Weise hat (Wei et al., 2017) das Modell durch iteratives Löschen der CAM-Seeds auf andere Bereiche konzentriert. Diese Methoden formalisieren den Erweiterungsprozess jedoch normalerweise in eine komplexe Trainingsphase, z. B. iteratives Löschen, was zeitaufwändig ist und es schwierig macht, die optimale Anzahl von Iterationen zu bestimmen. Darüber hinaus stützt es sich stark auf die vom Klassifizierungsnetzwerk bereitgestellten Unterscheidungsbereiche, und es kann leicht passieren, dass weniger wichtige Bereiche übersehen werden.
Um die oben genannten Probleme besser lösen zu können, schlagen wir ein neuartiges Aktivierungsregulierungs- und Rekalibrierungsschema namens AMR vor. Dieses Schema nutzt den Spotlight-Zweig und den Kompensationszweig, um ergänzende und aufgabenorientierte CAMs für WSSS bereitzustellen. Der Spotlight-Zweig stellt das grundlegende Klassifizierungsnetzwerk zur Generierung von CAMs dar und hebt typischerweise diskriminierende und klassifizierungsspezifische Bereiche hervor, wie z. B. den Kopf eines Pferdes und die Fenster eines Autos (siehe Abbildung 1). AMR lindert das Aufgabenlückenproblem bei der Durchführung von Segmentierungsaufgaben mithilfe klassifizierungsbasierter CAMs in früheren Arbeiten, was dazu beiträgt, mehr semantische segmentierungsspezifische Hinweise bereitzustellen. Darüber hinaus wird ein Aufmerksamkeitsmodulationsmodul (AMM) verwendet, um die Verteilung der Aktivierungsbedeutung aus der Perspektive der kanalräumlichen Reihenfolge neu zu ordnen und so dabei zu helfen, segmentierungsorientierte Aktivierungsreaktionen adaptiv zu regulieren. Die Beiträge von AMR lassen sich wie folgt zusammenfassen:
1. Nach unserem besten Wissen sind wir die ersten, die versuchen, Plug-in-Vergütungszweige in WSSS zu erkunden, um ergänzende Aufsicht und aufgabenspezifische CAMs bereitzustellen. Der Kompensationszweig kann die Schlüsselbereiche der Segmentierung ausgraben (z. B. die Beine des Pferdes und das Fahrgestell des Autos in Abbildung 1), was sehr wichtig ist, um den Anwendungsengpass klassifizierungsbasierter CAMs bei Segmentierungsaufgaben zu überwinden. Kompensations-CAMs helfen bei der Generierung segmentierungsorientierter CAMs, indem sie Spotlight-CAMs neu kalibrieren. Darüber hinaus führen wir eine Cross-Pseudo-Überwachung ein, um die Ausgabe-CAMs aus den Dualzweigen zu optimieren. Dies kann als semantische Ähnlichkeitsregularisierung angesehen werden, um zu vermeiden, dass CAMs, die zu sehr auf den Hintergrund konzentriert sind, kompensiert werden, und sie in die Nähe von Spotlight-CAMs zu bringen.
2. Wir haben ein Aufmerksamkeitsmodulationsmodul (AMM) entwickelt, um die Aktivierungskarte zu ermutigen, die Aufmerksamkeit gleichmäßig auf das gesamte Zielobjekt zu verteilen, indem Merkmale im Kanal und in räumlichen Dimensionen nacheinander moduliert werden. Mithilfe einer Modulationsfunktion wird die Verteilung aktivierter Merkmale neu angeordnet, um sekundäre Merkmale hervorzuheben und hervorstechende Merkmale zu benachteiligen, die vom Spotlight-Zweig erfasst wurden. Der kanalraumsequentielle Ansatz hilft dabei, die gegenseitige Abhängigkeit zwischen Kanälen und die räumliche Kodierung innerhalb des lokalen Empfangsfelds auf jeder Ebene explizit zu modellieren, um die segmentierungsorientierte Merkmalsantwort adaptiv anzupassen.
3. Unsere Methode erreicht einen mIoU von 68,8 % bzw. 69,1 % für den Validierungssatz und den Testsatz und erreicht damit eine neue, hochmoderne WSSS-Leistung für den PASCAL VOC2012-Datensatz (Everingham et al., 2015). Umfangreiche Experimente zeigen, dass AMR nicht nur die aktuellen Methoden übertrifft, die mithilfe der Überwachung auf Bildebene trainiert werden, sondern auch einige Methoden, die auf einer stärkeren Überwachung beruhen, wie z. B. Auffälligkeitsetiketten. Experimente zeigen auch, dass unser Schema Plug-and-Play-fähig ist und mit anderen Methoden kombiniert werden kann, um deren Leistung zu verbessern.
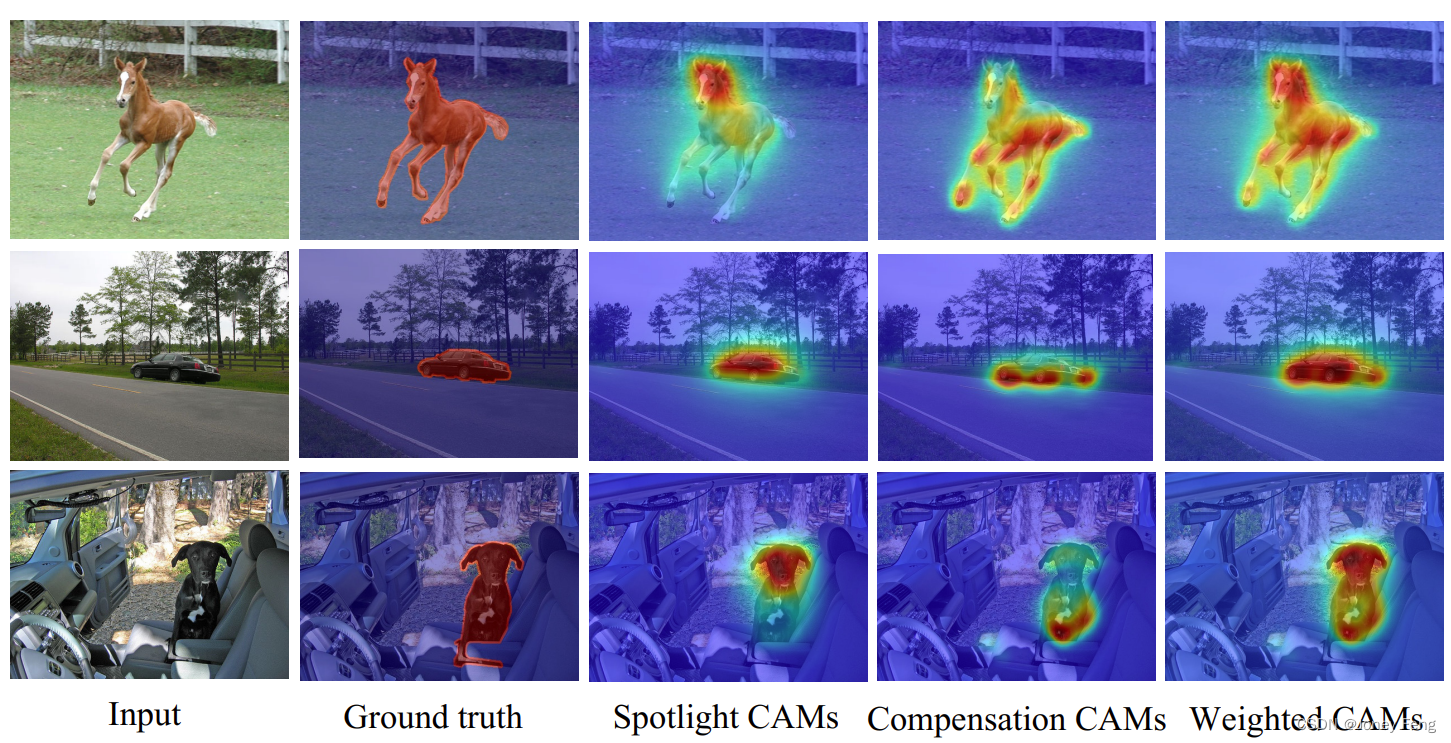
Abbildung 1: Visualisierung von CAMs im AMR-Schema. „Spotlight CAMs“ konzentrieren sich mehr auf Bereiche, die denen herkömmlicher CAMs ähneln. „Compensation CAMs“ helfen dabei, wichtige, aber leicht übersehene Bereiche aufzudecken. Spotlight-CAMs werden durch Kompensieren von CAMs neu kalibriert und erhalten außerdem „gewichtete CAMs“, wodurch stärker segmentierungsorientierte Konzepte bereitgestellt werden.
2. Verwandte Arbeiten
2.1. Schwach überwachte semantische Segmentierung
Mit der eingehenden Forschung zur semantischen Segmentierung, einerseits basierend auf Technologien wie AutoML (Li et al., 2021; Ren et al., 2021; Li et al., 2020, 2019; Xuefeng Xiao und Lianwen Jin , 2017; Xia und Ding, 2020) werden zur Verbesserung der Segmentierungsqualität eingesetzt. Andererseits ist die leichtgewichtige Annotation, die kostengünstig zu trainieren ist, ein WSSS auf Bildebene, das in den letzten Jahren umfassend untersucht wurde. Bestehende hochmoderne Methoden basieren häufig auf Seed-Regionen von Klassenaktivierungskarten (CAMs), die von Klassifizierungsnetzwerken generiert werden (Zhou et al., 2016). Die meisten dieser Bemühungen lassen sich in zwei Aspekte unterteilen: die Generierung hochwertiger CAM-Seeds und die Verbesserung von Pseudolabels. Einerseits erweitern einige Methoden direkt den Antwortbereich von CAMs, da die ursprüngliche Aktivierungskarte nur die diskriminierenden Bereiche des Bildes hervorhebt. (Wei et al., 2018) verwenden dilatierte Windungen mit unterschiedlichen Dilatationsraten, um den Zielbereich zu vergrößern. (Wang et al., 2020b) Erfassen Sie unterschiedliche Regionen aus transformierten Bildern in einem Klassifizierungsnetzwerk durch äquivariante Regularisierung. Andererseits konzentrieren sich einige Arbeiten auf die Verbesserung von Pseudo-Labels basierend auf anfänglichen CAMs. (Kolesnikov und Lampert, 2016) untersuchten drei Prinzipien zur Verbesserung von Seeds, nämlich Seeds, Extensions und Constraints. (Ahn und Kwak, 2018) lernt die Beziehung zwischen Pixeln und verbreitet ähnliche semantische Pixel durch einen Random-Walk-Algorithmus. Darüber hinaus verwenden einige Methoden (Yao et al., 2021; Lee et al., 2019) CAMs als Vordergrundhinweise und Salienzkarten (Zhang et al., 2019) als Hintergrundhinweise. (Yao et al., 2021) führten eine graphbasierte globale Argumentationseinheit ein, um Objekte in nicht hervorstechenden Regionen zu entdecken. Allerdings laufen diese Methoden iterativ und stochastisch ab und können zum Verlust kritischer Informationen führen. Um dieses Problem zu lösen, schlagen wir ein Aktivierungsmodulations- und Neukalibrierungsschema vor, um hochwertige CAMs zu erzeugen.
2.2.Aufmerksamkeitsmechanismus
Der Aufmerksamkeitsmechanismus (Wu, Hu & Yang, 2019; Wu, Hu & Wu, 2018) wird in Segmentierungsnetzwerken häufig verwendet, um den globalen Kontext von Bildern festzulegen. Nichtlokal (Wang et al., 2018a) ist der erste, der die Korrelation zwischen jedem räumlichen Punkt in der Feature-Map berücksichtigt. Dann schlug Asymmet (Zhu et al., 2019) ein asymmetrisches nicht-lokales Netzwerk vor, um die Verbindung des nicht-lokalen Netzwerks zu stärken. SE (Hu, Shen und Sun, 2018) lernt die Bedeutung von Kanalfunktionen durch die Berechnung der Interaktionen zwischen Kanälen. Im Anschluss an diese Arbeit verwendeten (Wang et al., 2020a) kanalbasierte Faltungen, um Interaktionen zu lernen. CBAM (Woo et al., 2018) nutzt räumliche und kanalbezogene Aufmerksamkeit, um wichtige Hinweise in kanalbezogenen und räumlichen Dimensionen hervorzuheben. (Cao et al., 2019) führt Fernabhängigkeiten in das Basisaufmerksamkeitsmodul ein. In diesem Artikel stellen wir ein Aufmerksamkeitsmodulationsmodul vor, um sekundäre, aber kritische Funktionen bei Segmentierungsaufgaben zu verbessern.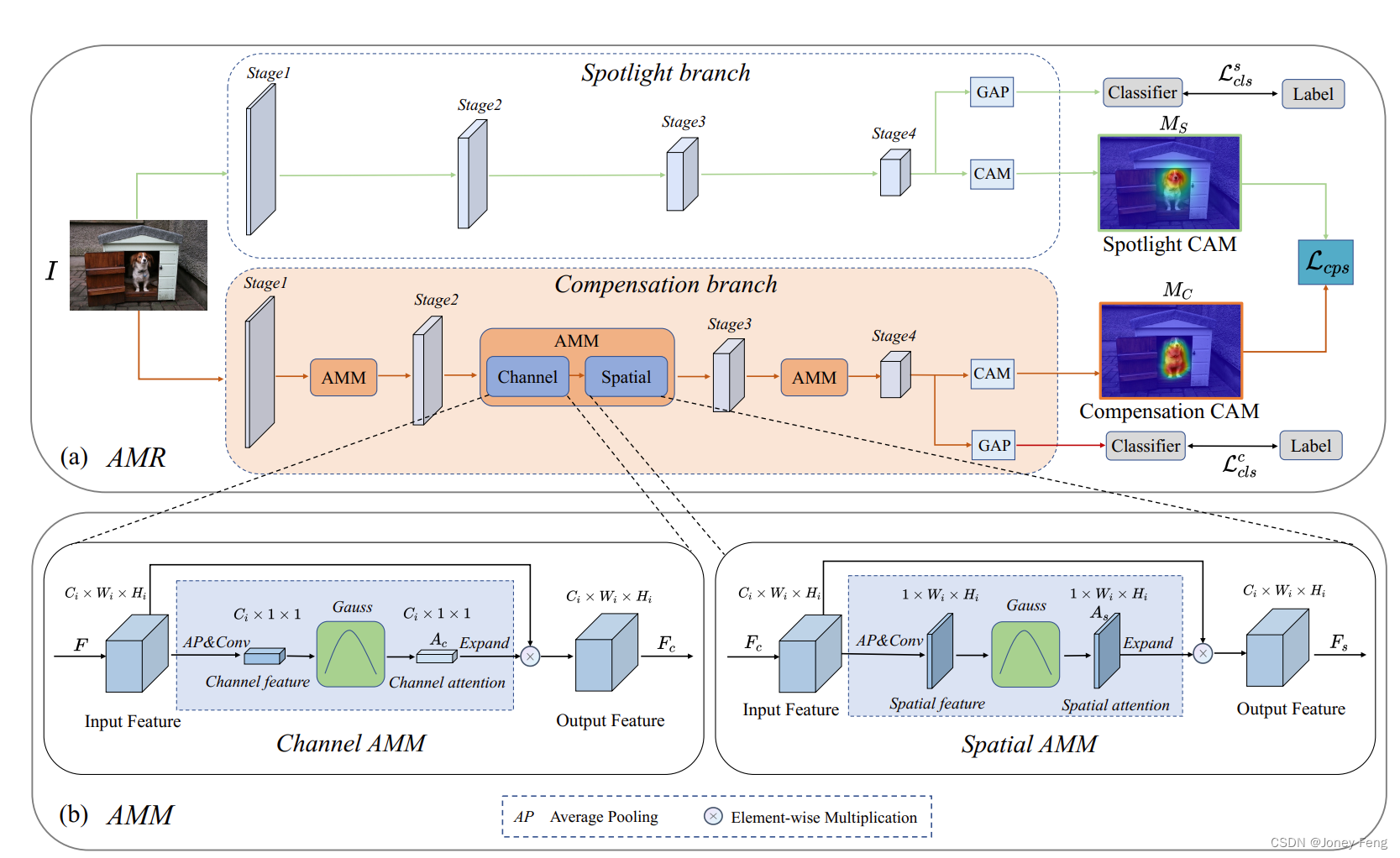
Abbildung 2: Rahmen des AMR-Systems. (a) Stellt den gesamten AMR-Prozess dar. AMR besteht aus zwei Zweigen, nämlich dem Spotlight-Zweig und dem Compensation-Zweig. „GAP“ bedeutet globales durchschnittliches Pooling. (b) zeigt ein Schema eines AMM, dessen Ziel darin besteht, die Aktivierungskarte von Merkmalen kanalraumsequentiell zu modulieren.
3. Methodik
In diesem Abschnitt stellen wir zunächst kurz die traditionellen Methoden zur Generierung von CAMs vor. Anschließend stellen wir das Aktivierungsmodulations- und Rekalibrierungsschema (AMR) vor. Im nächsten Abschnitt werden die Motivation und Einzelheiten des vorgeschlagenen AMM vorgestellt. Abschließend veranschaulichen wir die Modulationsfunktion und die Trainingsverlustfunktion.
3.1. Vorbereitungsarbeiten im Vorfeld
Klassenaktivierungskarten (CAMs) (Zhou et al., 2016) stellen kategoriespezifische Antwortbereiche im Eingabebild I ∈ R3×H×W dar. Unter Verwendung eines Multi-Label-Klassifizierungsnetzwerks zur Codierung von Features für alle Kategorien können diese Feature-Maps F(I) ∈ RC×H×W genutzt werden, um Feature-Maps vor der endgültigen Klassifizierungsebene zu extrahieren. C stellt die Anzahl der Kanäle der Feature-Map dar. Dann führen wir einfach eine Matrixmultiplikation auf F(I) durch, um CAMs zu erzeugen.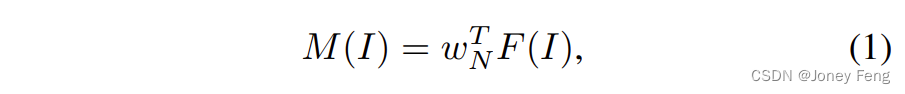
Wobei M(I) ∈ RN×H×W die erhaltenen CAMs sind. w T N sind die Gewichte der letzten vollständig verbundenen Schicht für N Kategorien. Allerdings sind diese CAMs klassifizierungsorientiert und ignorieren die Aufgabenspezifität der semantischen Segmentierung. Mit anderen Worten: Das Netzwerk wird durch einen klassifizierungsbasierten Verlust optimiert, sodass die Klassifizierungsaufgabe über einige diskriminierende Bereiche hinweg erfüllt werden kann. Dadurch wird die Leistung einer schwach überwachten semantischen Segmentierung beeinträchtigt, die die Ermittlung der vollständigen Grenzen des gesamten Objekts erfordert. Um dieses Problem zu lösen, schlagen wir das Schema der Aktivierungsmodulation und Neukalibrierung (AMR) vor, um anfängliche CAMs in aufgabenspezifischere CAMs neu zu kalibrieren.
3.2. Aktivieren Sie das Anpassungs- und Neukalibrierungsschema
Wir veranschaulichen das Aktivierungsmodulations- und Rekalibrierungsschema (AMR) in Abbildung 2. AMR umfasst die Spotlight-Branche und die Vergütungsfiliale. Der Spotlight-Zweig ähnelt früheren Methoden (Wei et al., 2017; Jiang et al., 2019; Lee, Kim und Yoon, 2021), die einen Klassifizierungsverlust verwenden, um sich selbst zu optimieren und Spotlight-CAMs MS zu generieren. Da der Spotlight-Zweig während des Trainings häufig informationsreiche Funktionen aktiviert, heben die erhaltenen CAMs hauptsächlich die diskriminierenden Bereiche des Zielobjekts hervor.
Der Kompensationszweig ist so konzipiert, dass er als zusätzliche Überwachungsfunktion für Spotlight-CAMs dient. Es mildert das Problem der Aufgabenlücke bei der Durchführung von Segmentierungsaufgaben mithilfe klassifizierungsbasierter CAMs in früheren Arbeiten und trägt dazu bei, mehr semantische segmentierungsspezifische Hinweise bereitzustellen. Kompensierende Zweige können als Plug-and-Play-Komponenten betrachtet werden, die Schlüsselbereiche der Segmentierung erschließen, die von Spotlight-Zweigen leicht übersehen werden. Die erhaltenen Kompensations-CAMs MC helfen dabei, die Spotlight-CAMs MS neu zu kalibrieren, um die endgültigen gewichteten CAMs MW zu erzeugen, ausgedrückt wie folgt: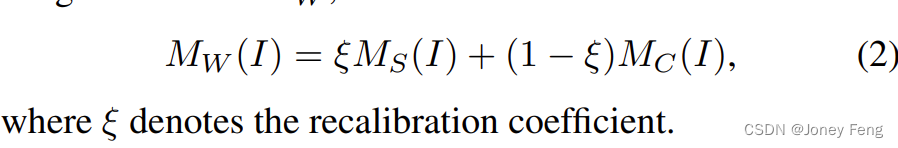
3.3. Aufmerksamkeitsregulierungsmodul
Es wird ein Aufmerksamkeitsmodulationsmodul (AMM) vorgeschlagen, das dazu beitragen soll, die Zweigextraktion weiterer Regionen zu kompensieren, die für semantische Segmentierungsaufgaben von entscheidender Bedeutung sind. Wie in Abbildung 2 dargestellt, umfasst AMM die Anpassung der Kanalaufmerksamkeit und der räumlichen Aufmerksamkeit. Wir geben zunächst das Merkmal F(I) in den Kanal AMM ein. Die gegenseitige Abhängigkeit zwischen Kanälen wird explizit durch durchschnittliches Pooling und Faltungsschichten modelliert, was die Empfindlichkeit gegenüber informationsreichen Merkmalen widerspiegelt. Inspiriert von (Jiang et al., 2019) entsprechen die empfindlichsten Merkmale diskriminierenden Regionen, sekundäre Merkmale stellen wichtige, aber leicht zu übersehende Regionen dar und langweilige Merkmale können Hintergrundkonzepte darstellen. Daher nutzen wir Modulationsfunktionen, um sekundäre Merkmale zu verbessern und die am stärksten und am wenigsten empfindlichen Merkmale zu unterdrücken. Die oben genannten Operationen können wie folgt ausgedrückt werden: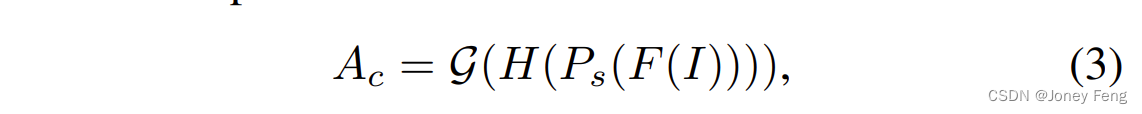
wobei Ac die Kanalaufmerksamkeitskarte ist. Wir bezeichnen Ps als die räumliche Durchschnitts-Pooling-Funktion und H als Faltungsschicht. Anschließend wird die Modulationsfunktion G verwendet, um die Verteilung der Merkmale neu zu verteilen und sekundäre Merkmale in der Kanaldimension hervorzuheben. Anschließend führen wir eine elementweise Multiplikation der Kanalaufmerksamkeitskarte und der Eingabe-Feature-Map durch, um neu zugewiesene Features zu generieren, definiert als: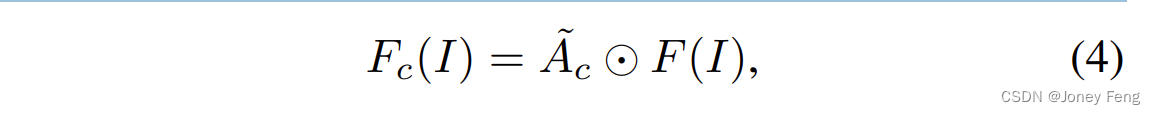
wobei A˜c die auf die Feature-Map-Dimension erweiterte Kanal-Aufmerksamkeitskarte darstellt. Fc(I) repräsentiert die Ausgabe-Feature-Map. Um interräumliche Beziehungen in räumlichen Dimensionen weiter zu modellieren, führen wir außerdem ein räumliches AMM ein, das unmittelbar auf das Kanal-AMM folgt. Konkret führen wir zunächst ein Kanaldurchschnitts-Pooling Pc für Fc(I) in der Kanaldimension durch und wenden dann die Faltungsoperation H auf sie an. Die Ausgabe-Feature-Map zeigt die Bedeutung von Features entlang der räumlichen Dimension. Anschließend führen wir eine Modulationsfunktionsoperation für die Ausgabe-Feature-Map durch, um sekundäre Aktivierungen hinzuzufügen. Der Implementierungsprozess kann wie folgt ausgedrückt werden: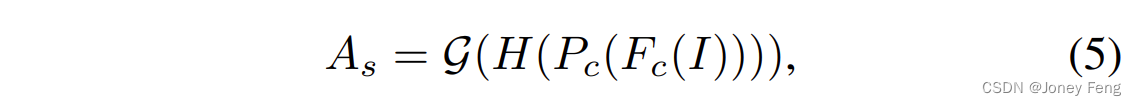
wobei As die räumliche Aufmerksamkeitskarte ist. Hohe Aktivierungswerte in As spiegeln Bereiche wider, die leicht übersehen werden. Anschließend führen wir eine elementweise Multiplikation zwischen der räumlichen Aufmerksamkeitskarte und der Kanal-Aufmerksamkeitskarte durch, um die modulierte Aufmerksamkeitskarte zu generieren. Dieser Prozess kann wie folgt ausgedrückt werden:

Abbildung 3: Schematische Darstellung der Modulationsfunktion. Die Werte auf der Achse stellen den Bereich der Aktivierungsverteilung dar. (a) stellt die ursprüngliche Aktivierungsverteilung dar. (b) stellt eine umverteilte Aktivierung dar, moduliert durch eine Gaußsche Funktion, um sekundäre Aktivierungen hervorzuheben.
3.4. Einstellfunktion
wobei µ und σ der Mittelwert und die Standardabweichung der Aktivierungskarte sind. Wir bilden die Aktivierungswerte in G entsprechend den Einstellungen von µ und σ ab. Wir visualisieren die Aktivierungsverteilung vor und nach der Modulation in Abbildung 3. Wir beobachten, dass die Gaußsche Projektion die wichtigsten und unwichtigsten Aktivierungen deutlich unterdrückt. Der Schwerpunkt liegt auf der sekundären Aktivierung, um leicht übersehene Regionen direkt zu extrahieren, was für Segmentierungsaufgaben von entscheidender Bedeutung ist. Darüber hinaus untersuchen wir die direkte Festlegung von Schwellenwerten, um die Wichtigkeitsverteilung zu ändern. Es ist jedoch schwierig, einen einheitlichen Schwellenwert festzulegen, der für alle Bilder gilt. Die experimentellen Ergebnisse für verschiedene Modulationsfunktionen sind in Tabelle 4 zusammengefasst.
3.5.Verlustfunktion
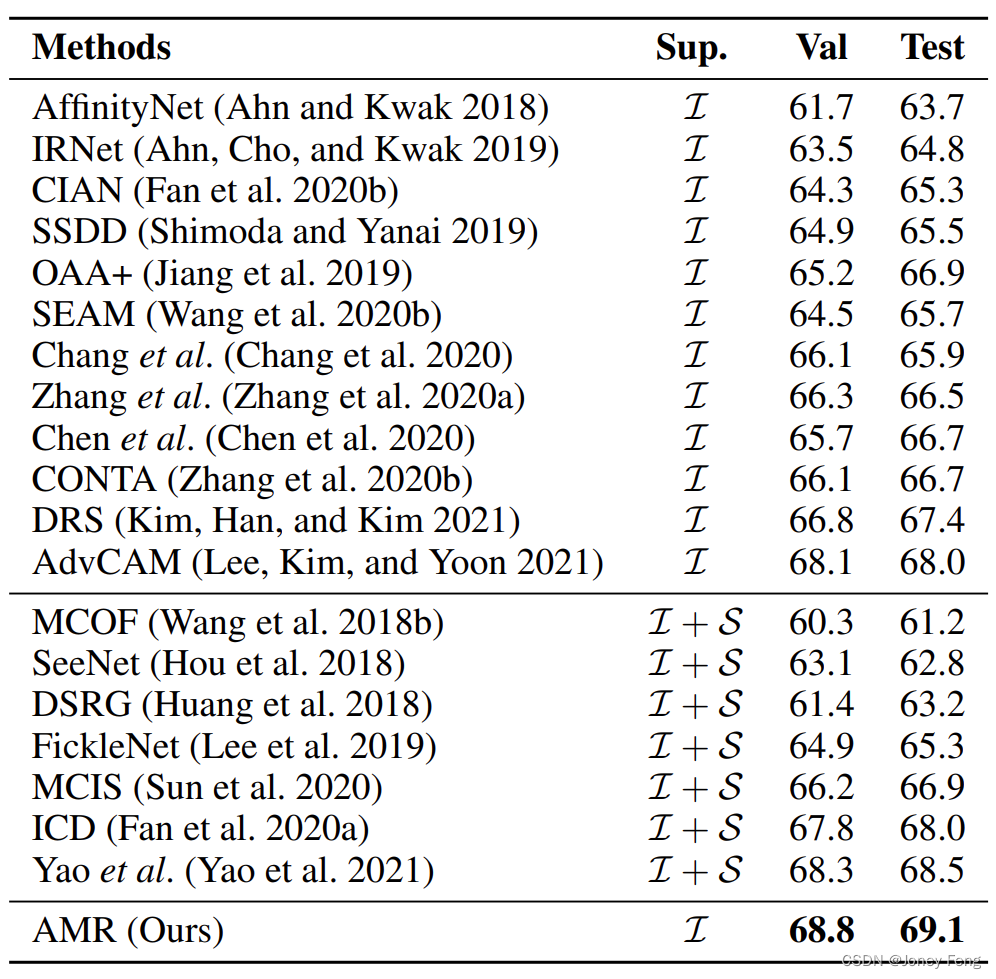
Während des Trainingsprozesses verwenden wir die globale Durchschnittspooling-Operation und die vollständig verbundene Schicht, um den vorhergesagten Wert Y zu erhalten, der die Kategoriewahrscheinlichkeit aller Kategorien darstellt. Schließlich verwenden wir für das Training eine Multi-Label-Soft-Edge-Loss-Funktion.  Tabelle 1: Vergleich mit modernsten Methoden für PASCAL VOC2012-Validierungs- und Testsätze. Alle Ergebnisse werden in mIoU (%) ausgewertet. I repräsentiert die Bezeichnung auf Bildebene und S repräsentiert die Bezeichnung für die Ausprägung.
Tabelle 1: Vergleich mit modernsten Methoden für PASCAL VOC2012-Validierungs- und Testsätze. Alle Ergebnisse werden in mIoU (%) ausgewertet. I repräsentiert die Bezeichnung auf Bildebene und S repräsentiert die Bezeichnung für die Ausprägung.
4. Experimentieren
4.1. Datensätze und Auswertungsstrategien
Wir evaluieren unsere Methode anhand des PASCAL VOC2012-Datensatzes (Everingham et al. 2015). Dieser Datensatz enthält 20 Vordergrundobjektkategorien und eine Hintergrundkategorie. Nach gängigen Methoden (Wei et al. 2017; Wang et al. 2020b) verwenden wir 10.582 Bilder zum Training, 1.449 Bilder zur Validierung und 1.456 Bilder zum Testen. Während des gesamten Schulungsprozesses verwenden wir zur Überwachung ausschließlich Klassenbezeichnungen auf Bildebene. Jedes Bild kann mehrere Kategoriebezeichnungen enthalten. Um die Leistung des Experiments zu bewerten, berechnen wir das durchschnittliche Schnittmenge-zu-Union-Verhältnis (mIoU) über alle Kategorien hinweg.
4.2. Einzelheiten zur Implementierung
Wir verwenden ResNet50 (He et al. 2016) als Backbone-Netzwerk von AMR. Wir trainieren für 8 Epochen mit Trainingsdaten mit einer Stapelgröße von 16. Die anfängliche Lernrate ist auf 0,01 und der Impuls auf 0,9 eingestellt. Wir verwenden den stochastischen Gradientenabstiegsalgorithmus zur Netzwerkoptimierung und legen einen Gewichtsabfall von 0,0001 fest. Wir haben auch einige typische Datenerweiterungsoperationen an den Trainingsbildern durchgeführt, wie z. B. zufällige Skalierung und horizontales Spiegeln. Nachdem wir CAMs erhalten haben, verwenden wir einen Random-Walk-Algorithmus, um die Pseudo-Labels zu optimieren. Nachdem wir die endgültigen Pseudo-Labels für die Segmentierung erhalten haben, verwenden wir DeepLab-v2 (Chen et al. 2017) und ResNet101 (He et al. 2016) als Backbone-Netzwerk für das Training, das auf ImageNet trainiert wird (Russakovsky et al. 2015). .
4.3. Vergleich mit aktuellen Methoden des Standes der Technik
Vergleich von bei semantischen Segmentierungsaufgaben. Wir führen Experimente mit DeepLab v2 (Chen et al. 2017) und Pseudo-Labels des Trainingssatzes durch. Wir berichten über die Ergebnisse der PASCAL VOC2012-Validierungs- und Testsätze, wie in Tabelle 1 dargestellt. Einerseits übertrifft AMR Methoden, die auf schwacher Überwachung auf Bildebene basieren, deutlich und erreicht eine Leistung auf dem neuesten Stand der Technik. Die mIoU der AMR erreichten 68,8 % im Validierungssatz und 69,1 % im Testsatz, was 2,0 % bzw. 1,7 % höher war als bei DRS (Kim, Han und Kim 2021). AMR hingegen erzielt auch bei feinkörnigeren Überwachungshinweisen bessere oder vergleichbare Ergebnisse. Beispielsweise übertrifft AMR (Yao et al. 2021) beim Validierungssatz um 0,5 % und beim Testsatz um 0,6 %, während letzterer eine zusätzliche Ausprägungsüberwachung verwendet. Dies ist ein ermutigendes Ergebnis, das zeigt, dass unsere Methode beeindruckende Ergebnisse erzielen kann, indem sie aus großen und kostengünstigen Anmerkungen lernt, was für praktische Anwendungen sehr vorteilhaft ist.
Vergleich von CAM- und Pseudo-Tags. Unsere Methode zielt darauf ab, segmentierungsspezifisches CAM bereitzustellen, um die Qualität von Pseudo-Labels zu verbessern. Um die Wirksamkeit unserer Methode bei der Generierung von CAM und Pseudo-Labels zu überprüfen, fassen wir die CAM- und Pseudo-Label-Ergebnisse mehrerer konkurrierender Methoden im PASCAL VOC2012-Trainingssatz zusammen (siehe Tabelle 2). Die Ergebnisse zeigen, dass AMR 56,8 % bzw. 69,7 % mIoU auf CAM- bzw. Pseudo-Labels erreichte. Unsere Methode übertrifft die hochmoderne SEAM-Methode (Wang et al. 2020b) bei CAM um 1,4 % und die CONTA-Methode (Zhang et al. 2020b) bei Pseudo-Labeling um 1,8 %. Es ist erwähnenswert, dass die SEAM-Methode (Wang et al. 2020b) Wide ResNet38 (Wu, Shen und Van Den Hengel 2019) als Backbone-Netzwerk verwendet und in ihrer Arbeit eine bessere Leistung als ResNet50 erzielt. Experimentelle Ergebnisse zeigen, dass unser kompensiertes CAM die Qualität des anfänglichen CAM und der Pseudoetiketten effektiv verbessern kann. Um zu veranschaulichen, wie AMR die Qualität von Pseudoetiketten verbessert, zeigen wir das AMR-generierte CAM in Abbildung 4. Aus dieser Abbildung können wir die folgenden Beobachtungen ziehen: i) Das vom Spotlight-Zweig generierte Spotlight-CAM konzentriert sich hauptsächlich auf den diskriminierenden Bereich. ii) Kompensiertes CAM hebt Bereiche hervor, die für das Ziel wichtig sind, aber leicht übersehen werden. Dies liegt daran, dass AMM dabei hilft, Aktivierungskarten zu modulieren, um sekundäre Funktionen hervorzuheben. iii) Die gewichtete CAM enthält vollständigere Regionen als die Spotlight-CAM, was mit der Art der semantischen Segmentierungsaufgabe übereinstimmt. 
Abbildung 4: Visualisierungsergebnisse von CAM, die mit unserer Methode auf dem VOC2012-Trainingssatz generiert wurden. (a) Eingabebild. (b) Spotlight CAM, generiert vom Spotlight-Zweig. (c) Kompensations-CAM, generiert vom Kompensationszweig. (d) Gewichtetes CAM, erhalten durch Zusammenführung zweier komplementärer CAMs.
Tabelle 2: Qualitätsergebnisse (mIoU) von Pseudo-Labels auf VOC2012-Trainingsbildern. Die Spalte „CAM“ stellt die anfänglichen CAM-Seeds dar, die vom Klassifizierungsnetzwerk generiert wurden. „Pseudo“ steht für verfeinerte Pseudobezeichnungen für die überwachte Segmentierung.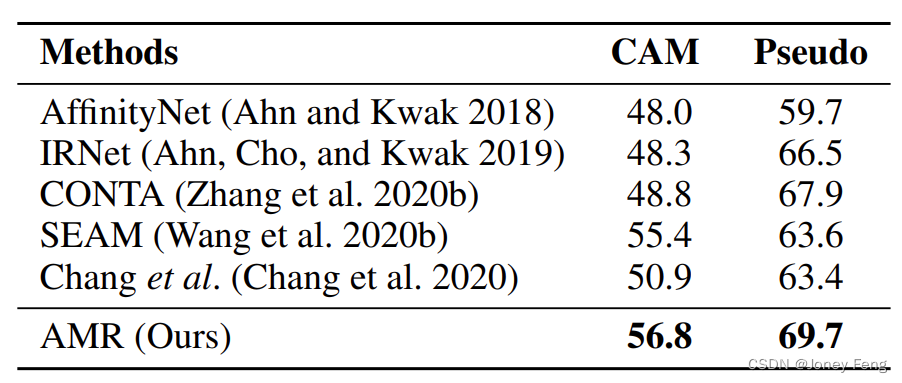
Tabelle 3: Vergleich der verschiedenen Effekte der einzelnen Komponenten in unserem Ansatz. „Baseline“ stellt ein einzelnes Klassifizierungsnetzwerk dar. „AMMc“ und „AMMs“ stehen für das vorgeschlagene Kanal-AMM bzw. räumliche AMM. Lcps steht für semantische Regularisierung.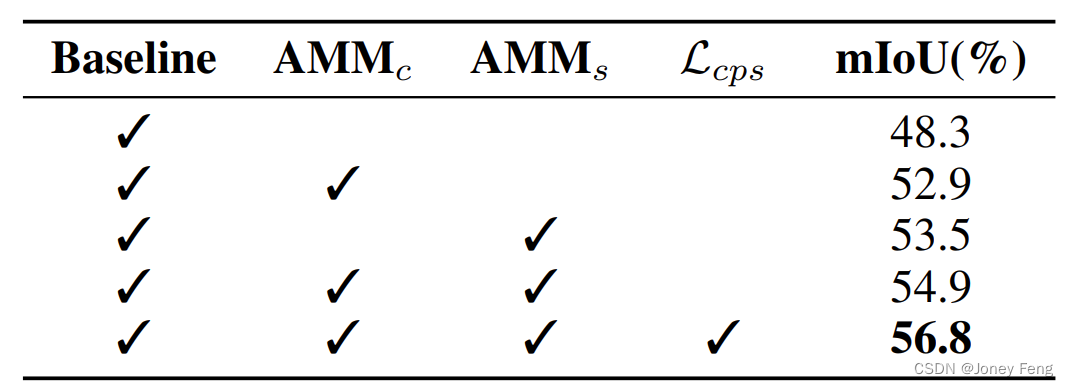
Tabelle 4: Vergleich verschiedener Modulationsfunktionen. Evaluierung von mIoU mithilfe von CAM von VOC2012-Trainingsbildern.
4.4. Ablationsstudien
Verfügbarkeit von Kernkomponenten. Um die Wirksamkeit der Kernkomponenten in unserem Ansatz zu überprüfen, fügen wir nach und nach jede Schlüsselkomponente hinzu, basierend auf einem einzigen Klassifizierungsnetzwerk, das nur den Spotlight-Zweig enthält (als „Basislinie“ bezeichnet). Wir vergleichen die Leistung verschiedener Komponenten mit der Variante „Baseline“ in Tabelle 3. Wie in Tabelle 3 gezeigt, erhöhen AMMc und AMMs den mIoU von CAM auf 52,9 % bzw. 53,5 %. Das gesamte AMM erreichte 54,9 % mIoU. Darüber hinaus tragen kreuzweise pseudoüberwachte LCPs dazu bei, die Leistung um 1,9 % zu verbessern. Das gesamte Framework erreicht die beste Performance von 56,8 %. Diese Ablationsexperimente demonstrieren die Wirksamkeit jeder Kernkomponente unseres Ansatzes.
Die Wirksamkeit der Modulationsfunktion. In Tabelle 4 vergleichen wir die Ergebnisse für verschiedene Modulationsfunktionen, dargestellt in Abbildung 3. Die Modulationsfunktion „Schwellenwert“ setzt die Aktivierung auf 1, wenn der Schwellenwert überschritten wird, und auf 0, wenn die Aktivierung unter dem Schwellenwert liegt. Dadurch kann eine Verbesserung um 1,8 % gegenüber dem Ausgangswert erzielt werden, da die wichtigsten Funktionen erhalten bleiben und einige der weiteren verbessert werden wichtige Funktionen. Kleine Aktivierungen. Die Funktion „Gauss“ erreichte 56,8 % mIoU und belegte damit den ersten Platz unter allen Kandidatenfunktionen. Dies kann daran liegen, dass die Gaußsche Funktion die Aktivierungskarte entsprechend umverteilen kann, um einige wichtige Konzepte aufzudecken, die leicht übersehen werden.
Gültigkeit des Rekalibrierungskoeffizienten. Um den optimalen Rekalibrierungskoeffizienten (ξ) zu ermitteln, geben wir die Ergebnisse in Tabelle 5 an. ξ stellt den Beitrag des Spotlight-CAM zum gewichteten CAM dar. Wir stellen fest, dass die Einstellung von ξ auf 0,5 das beste Ergebnis liefert, nämlich 56,8 %. Wenn der Wert von ξ erhöht oder verringert wird, nimmt die Leistung erheblich ab, wahrscheinlich weil dadurch das Gleichgewicht der Flächenkompensation zwischen den beiden CAMs zerstört wird. Wenn sich der Koeffizient 0,1 oder 0,9 nähert, nähert sich das Framework einem einzelnen Zweig an, was zu erheblichen Leistungseinbußen führt.
4.5. Allgemeine Diskussion
Um die Verallgemeinerung von AMR zu überprüfen, erweitern wir das vorgeschlagene AMR auf zwei hochmoderne Methoden, nämlich IRNet (Ahn, Cho und Kwak 2019) und SEAM (Wang et al. 2020b). Wir behalten die ursprünglichen Trainingseinstellungen aus ihrer Arbeit bei und vergleichen die Ergebnisse des ersten CAM. Wie in Tabelle 6 gezeigt, erreicht unsere Methode eine Verbesserung von 8,5 % mIoU im IRNet. Für das Basis-SEAM konvertieren wir das Klassifizierungs-Backbone-Netzwerk in Wide ResNet38 (Wu, Shen und Van Den Hengel 2019), was mit SEAM identisch ist. Die Ergebnisse zeigen, dass AMR die Qualität von CAM um 2,5 % verbessert, was die Kombination unserer Methode mit anderen Methoden zur Verbesserung der Generalisierung und Robustheit segmentierungsbasierter CAM zeigt.
4.6. Segmentierungsergebnisse visualisieren
Wie in Abbildung 5 dargestellt, vergleichen wir die Segmentierungsergebnisse unserer Methode mit IRNet (Ahn, Cho und Kwak 2019) auf dem Validierungssatz von PASCAL VOC2012 (Everingham et al. 2015). Wie aus der Abbildung hervorgeht, führen die Ergebnisse von IRNet (Ahn, Cho und Kwak 2019) häufig zu Fehleinschätzungen in einigen unklaren Bereichen. Im Gegenteil, unsere Methode durchsucht erfolgreich mehr Regionen, die zum Zielobjekt gehören, und erzielt so eine bessere Segmentierungsleistung.
Abbildung 5: Qualitative Ergebnisse des PASCAL VOC2012-Validierungssatzes. (a) Eingabebild. (b) Echtes Etikett. (c) Segmentierungsergebnisse von IRNet (Ahn, Cho und Kwak 2019). (d) Segmentierungsergebnisse unserer Methode.
Tabelle 5: Vergleich mit verschiedenen Rekalibrierungskoeffizienten. mIoU wird auf CAM von VOC2012-Trainingsbildern ausgewertet.
Tabelle 6: Generalisierungsergebnisse von AMR auf IRNet (Ahn, Cho und Kwak 2019) und SEAM (Wang et al. 2020b).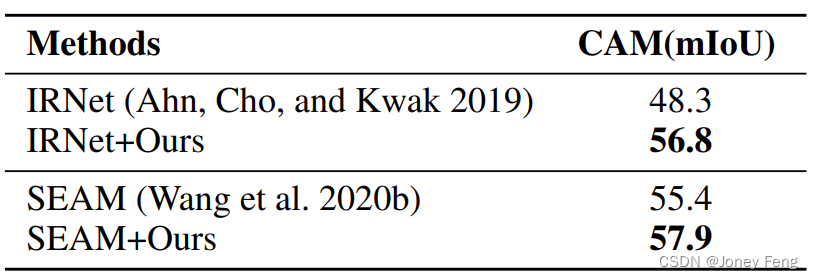
5. Schlussfolgerung
In diesem Artikel schlagen wir ein neuartiges Aktivierungsregulierungs- und Kalibrierungsschema (AMR) für die schwach überwachte semantische Segmentierung (WSSS) vor, das einen Spotlight-Zweig und einen Plug-and-Play-Kompensationszweig verwendet, um gewichtetes CAM zu erhalten und eine stärker semantische Segmentierung zu ermöglichen Konzepte. Ein AMM-Modul dient dazu, die Verteilung der Merkmalsbedeutung aus der Perspektive der Kanalraumreihenfolge neu zu ordnen, was dazu beiträgt, einige Bereiche hervorzuheben, die für die Segmentierungsaufgabe von entscheidender Bedeutung sind, aber leicht übersehen werden. Umfangreiche Experimente wurden mit dem PASCAL VOC2012-Datensatz durchgeführt und die Ergebnisse zeigen, dass AMR bei der schwach überwachten semantischen Segmentierung Spitzenleistungen erzielt.