1. Descripción general de los rastreadores
简单来说,爬虫就是获取网页并提取和保存信息的自动化程序,下面概要介绍一下。
(1) Obtener la página web
Lo primero que debe hacer el rastreador es obtener la página web, aquí está el código fuente de la página web. El código fuente contiene información útil de la página web, por lo que siempre que obtenga el código fuente, podrá extraer la información deseada de él.
Hablamos anteriormente sobre los conceptos de solicitud y respuesta. Cuando envía una solicitud al servidor del sitio web, el cuerpo de la respuesta devuelto es el código fuente de la página web. Por lo tanto, la parte más crítica es construir una solicitud y enviarla al servidor, luego recibir la respuesta y analizarla, entonces, ¿cómo implementar este proceso? No se puede interceptar el código fuente de una página web manualmente, ¿verdad?
No se preocupe, Python proporciona muchas bibliotecas para ayudarnos a lograr esta operación, como urllib, solicitudes, etc. Podemos usar estas bibliotecas para ayudarnos a implementar operaciones de solicitud HTTP. Tanto las solicitudes como las respuestas pueden representarse mediante la estructura de datos proporcionada por la biblioteca de clases. Después de obtener la respuesta, solo necesitamos analizar la parte del cuerpo de la estructura de datos, es decir , obtenemos el código fuente de la página web, de esta forma podemos utilizar un programa para implementar el proceso de obtención de páginas web.
(2) Extraer información
Después de obtener el código fuente de la página web, el siguiente paso es analizar el código fuente de la página web y extraer los datos que queremos de él. En primer lugar, el método más común es utilizar la extracción de expresiones regulares, que es un método universal, pero es más complicado y propenso a errores al construir expresiones regulares.
Además, dado que la estructura de las páginas web tiene ciertas reglas, también existen algunas bibliotecas que extraen información de la página web en función de los atributos del nodo de la página web, selectores CSS o XPath, como Beautiful Soup, pyquery, lxml, etc. Con estas bibliotecas, podemos extraer de manera eficiente y rápida información de la página web, como atributos de nodo, valores de texto, etc.
La extracción de información es una parte muy importante del rastreador, que puede organizar datos desordenados para que podamos procesarlos y analizarlos posteriormente.
(3) Guardar datos
Después de extraer información, generalmente guardamos los datos extraídos en algún lugar para su uso posterior. Hay varias formas de guardar aquí. Por ejemplo, se puede guardar simplemente como texto TXT o texto JSON, o se puede guardar en una base de datos, como MySQL y MongoDB, o se puede guardar en un servidor remoto, como operando con SFTP.
(4) Procedimientos automatizados
Cuando se trata de programas automatizados, significa que los rastreadores pueden completar estas operaciones en lugar de los humanos. En primer lugar, por supuesto que podemos extraer esta información manualmente, pero si el volumen es especialmente grande o queremos obtener una gran cantidad de datos rápidamente, igualmente debemos utilizar un programa. Un rastreador es un programa automatizado que completa el trabajo de rastreo en nuestro nombre. Puede realizar diversas operaciones de manejo de excepciones, reintentos de errores y otras operaciones durante el proceso de rastreo para garantizar que el rastreo continúe ejecutándose de manera eficiente.
2. El uso de rastreadores
Hoy en día ha llegado la era del big data y la tecnología de rastreo web se ha convertido en una parte indispensable de esta era. Las empresas necesitan datos para analizar el comportamiento de los usuarios, las deficiencias de sus propios productos, la información de la competencia, etc., y la primera condición para todo esto. es la recopilación de datos. El valor de los rastreadores web es en realidad el valor de los datos. En la sociedad de Internet, los datos no tienen precio y todo son datos. Quien tiene una gran cantidad de datos útiles tiene la iniciativa de tomar decisiones.
Las principales áreas de aplicación actuales de los rastreadores web incluyen: motores de búsqueda, recopilación de datos, análisis de datos, agregación de información, seguimiento de productos competitivos, inteligencia cognitiva, análisis de la opinión pública, etc. Existen innumerables empresas relacionadas con el negocio de los rastreadores, como Baidu, Google, Tianyancha, Qi, Chacha, Xinbang, Feigua, etc. En la era del big data, los rastreadores tienen una amplia gama de aplicaciones y una gran demanda, aquí hay algunos ejemplos que están cerca de la vida:
-
**Requisitos laborales:** Obtenga información de contratación y estándares salariales en varias ciudades para seleccionar fácilmente los que más le convengan;
-
**Demanda de alquiler:** Obtenga información de alquiler en varias ciudades para seleccionar su vivienda favorita;
-
**Necesidades gourmet:** Obtén buenas críticas de varios lugares para que los amantes de la comida no se pierdan;
-
**Necesidades de compra:** Obtenga información sobre precios y descuentos del mismo producto de varios comerciantes para que las compras sean más asequibles;
-
**Necesidades de compra de automóviles: **Obtenga las fluctuaciones de precios de sus vehículos favoritos en los últimos años, así como los precios de varios modelos a través de diferentes canales, para ayudarlo a elegir su automóvil.
3. El significado de URI y URL
URI (Identificador uniforme de recursos), que es el Identificador uniforme de recursos, URI (Ubicación uniforme de recursos), que es el Localizador uniforme de recursos, por ejemplohttps://www. kuaidaili.com / es a la vez un URI y una URL. La URL es un subconjunto de la URI. Para enlaces web generales, se acostumbra llamarla URL. El formato de composición básico de una URL es el siguiente: sigue:
scheme://[username:password@]host[:port][/path][;parameters][?query][#fragment]
El significado de cada parte es el siguiente:
-
**esquema:** El protocolo utilizado para obtener recursos, como http, https, ftp, etc., no tiene un valor predeterminado. El esquema también se llama protocolo;
-
**nombre de usuario:contraseña:**Nombre de usuario y contraseña. En algunos casos, la URL requiere un nombre de usuario y contraseña para acceder. Esta es una existencia especial. Generalmente se usa al acceder a ftp. Indica explícitamente el nombre de usuario para acceder a los recursos. y contraseña, pero no es necesario que la escriba. Si no la escribe, es posible que se le solicite que ingrese su nombre de usuario y contraseña;
-
**host: **Dirección de host, que puede ser un nombre de dominio o dirección IP, comowww.kuaidaili.com, 112.66.251.209;
-
**puerto: **puerto, el puerto de servicio establecido por el servidor, el puerto predeterminado del protocolo http es 80, el puerto predeterminado del protocolo https es 443, por ejemplo https:// www.kuaidaili.com/ equivale ahttps://www.kuaidaili.com:443;
-
**ruta: **ruta se refiere a la dirección especificada de los recursos de red en el servidor. Podemos encontrar el host a través del host: puerto, pero hay muchos archivos en el host. Los archivos específicos se pueden ubicar a través de la ruta . Por ejemplohttps://www.baidu.com/file/index.html, la ruta es /file/index.html, lo que significa que accedemos /file/ index.html este archivo;
-
**parámetros: **parámetros, utilizados para especificar información adicional al acceder a un recurso. La función principal es proporcionar parámetros adicionales al servidor para representar algunas características de esta solicitud, como https://www.kuaidaili.com/dps;kspider, kspider es un parámetro, rara vez se usa ahora, la mayoría de ellos usan la parte de consulta como parámetro;
-
**query: **Consulta, debido a la consulta de ciertos tipos de recursos, si hay varias consultas, use & para separar los parámetros solicitados a través de GET, por ejemplo: https://www.kuaidaili.com/dps/?username=kspider&type=spider, la parte de la consulta es nombre de usuario=ksspider&type=spider, el nombre de usuario es kspider y el tipo es araña;
-
**fragmento: **Fragmento, un complemento parcial de la descripción del recurso, utilizado para identificar recursos secundarios, comohttps://www.kuaidaili.com/dps# kspider , kspider es el valor del fragmento:
-
Aplicación: enrutamiento de una sola página, anclaje HTML;
-
#es diferente de?, la cadena de consulta que sigue a?será llevada al servidor por la solicitud de red, pero el fragmento no se enviará a el servidor; < /span> -
Los cambios en el fragmento no harán que el navegador actualice la página, pero generarán un historial de navegación;
-
El navegador procesará los fragmentos según el tipo de medio del archivo (tipo MIME);
-
De forma predeterminada, el motor de búsqueda de Google ignorará
#y las siguientes cadenas. Si desea que el motor del navegador lo lea, debe seguir#Después de!, Google convertirá automáticamente el siguiente contenido al valor de la cadena de consulta_escaped_fragment_, como https. : //www.kuaidaili.com/dps#!kspider, convertido a https://www.kuaidaili.com/dps< a i=8>?escaped_fragment=kspider.
-
Dado que el objetivo del rastreador es obtener recursos, y los recursos se almacenan en un determinado host, cuando el rastreador rastrea datos, debe tener una URL de destino para obtener los datos, por lo que la URL es la base básica para que el rastreador obtener datos. Comprender con precisión la URL. El significado es muy útil para el aprendizaje del rastreador.
4. Proceso básico del rastreador.
- **Iniciar una solicitud:** Inicia una solicitud de Solicitud al servidor a través de la URL (igual que abrir un navegador e ingresar la URL para navegar por la web). La solicitud puede contener encabezados, cookies, servidores proxy, datos y otra información adicionales. Python proporciona muchas bibliotecas para ayudarnos a implementar Este proceso completa las operaciones de solicitud HTTP, como urllib, solicitudes, etc.;
- **Obtener el contenido de la respuesta:** Si el servidor responde normalmente, recibirá la Respuesta. La Respuesta es el contenido de la página web que solicitamos, incluido HTML (código fuente de la página web), datos JSON o datos binarios (video, audio, imágenes), etc.;
- **Análisis de contenido:** Después de recibir el contenido de la respuesta, es necesario analizarlo y extraer el contenido de los datos. Si es HTML (código fuente de la página web), se puede analizar utilizando un analizador de páginas web, como una expresión regular ( re), Beautiful Soup, pyquery, lxml, etc.; si se trata de datos JSON, se pueden convertir en un objeto JSON para su análisis; si se trata de datos binarios, se pueden guardar en un archivo para su posterior procesamiento;
- **Guardar datos:** Se puede guardar en un archivo local (txt, json, csv, etc.), o en una base de datos (MySQL, Redis, MongoDB, etc.), o en un servidor remoto, como usar SFTP.
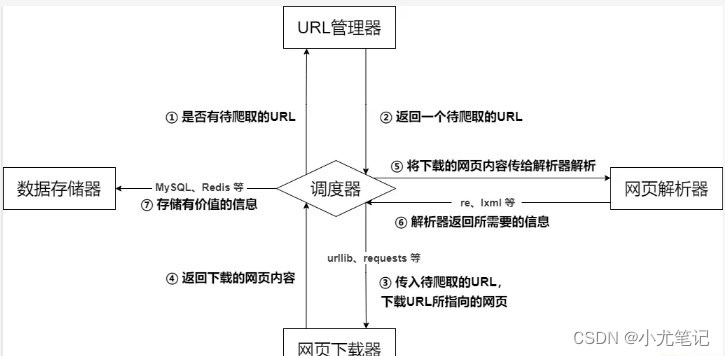
5. Arquitectura básica del rastreador.
La arquitectura básica del rastreador consta principalmente de cinco partes, a saber, el programador del rastreador, el administrador de URL, el descargador de páginas web, el analizador de páginas web y el recopilador de información:
- **Programador rastreador:** Equivalente a la CPU de una computadora. Es principalmente responsable de programar la coordinación entre el administrador de URL, el descargador y el analizador. Se utiliza para la comunicación entre varios módulos. Puede entenderse como la entrada y salida del rastreador Core, la estrategia de ejecución del rastreador se define en este módulo;
- **Administrador de URL: **Incluye direcciones URL que se rastrearán y direcciones URL rastreadas para evitar el rastreo repetido de URL y el rastreo en bucle de URL. Hay tres formas principales de implementar el administrador de URL, a través de la memoria, la base de datos y el caché. lograr;
- ** Descargador de páginas web: ** Responsable de descargar páginas web a través de URL, principalmente realizando el procesamiento de camuflaje correspondiente para simular el acceso al navegador y descargar páginas web.Las bibliotecas de uso común son urllib, solicitudes, etc .;
- **Analizador de páginas web:** Responsable de analizar la información de la página web. Puede extraer información útil según sea necesario y también puede analizarla de acuerdo con el método de análisis del árbol DOM. Como expresiones regulares (re), Beautiful Soup, pyquery, lxml, etc., que se pueden usar de manera flexible según la situación real;
- **Almacenamiento de datos:** Responsable de almacenar, mostrar y otros procesamientos de datos de la información analizada.
01
6. Protocolo de robots
El protocolo de robots, también conocido como protocolo de rastreo, reglas de rastreo, etc., significa que el sitio web puede crear un archivo robots.txt para indicarle al motor de búsqueda qué páginas se pueden rastrear y cuáles no, y el motor de búsqueda las identifica. leyendo el archivo robots.txt, si esta página puede ser rastreada. Sin embargo, este protocolo de robots no es un firewall y no tiene poder de aplicación. Los motores de búsqueda pueden ignorar por completo el archivo robots.txt y tomar una instantánea de la página web**. ** Si desea definir por separado el comportamiento de los robots de los motores de búsqueda al acceder a los subdirectorios, puede fusionar configuraciones personalizadas en robots.txt en el directorio raíz o utilizar metadatos de robots (metadatos, también conocidos como metadatos).
El acuerdo de robots no es una especificación, sino simplemente una convención, por lo que no garantiza la privacidad del sitio web, lo que comúnmente se conoce como "acuerdo de caballeros".
El significado del contenido del archivo robots.txt:
User-agent:*, donde * representa todos los tipos de motores de búsqueda, * es un carácter comodín- No permitir: /admin/, la definición aquí es prohibir el rastreo de directorios en el directorio de administración
- Disallow: /require/, la definición aquí es prohibir el rastreo de directorios en el directorio require.
- Disallow:/ABC/, la definición aquí es prohibir el rastreo de directorios en el directorio ABC
- No permitir:
/cgi-bin/*.htm, prohíbe el acceso a todas las URL con el sufijo “.htm” (incluidos los subdirectorios) en el directorio /cgi-bin/ - No permitir:
/*?*, no permite el acceso a todas las URL del sitio que contengan un signo de interrogación (?) - Disallow:/.jpg$, prohíbe rastrear todas las imágenes en formato .jpg en la página web
- Disallow:/ab/adc.html, prohíbe rastrear el archivo adc.html en la carpeta ab
- Permitir: /cgi-bin/, la definición aquí es permitir el rastreo de directorios en el directorio cgi-bin
- Permitir:/tmp, esta definición permite rastrear todo el directorio de tmp
- Permitir: .htm$, solo permite acceso a URLs con el sufijo “.htm”
- Permitir: .gif$, permite rastrear páginas web e imágenes en formato gif
- Mapa del sitio: mapa del sitio, indica a los rastreadores que esta página es un mapa del sitio
Verifique el protocolo de robots del sitio web. Simplemente agregue el sufijo robotst.txt a la URL del sitio web. Tome el proxy rápido como ejemplo:
https://www.kuaidaili.com/

02
- Bloquear el acceso de todos los motores de búsqueda a cualquier parte del sitio
- Deshabilite el rastreo de directorios en el directorio /doc/using/
- Está prohibido rastrear todos los directorios y archivos que comienzan con SDK en el directorio /doc/dev.